1. Introduction
With the rapid advancement of 3D perception technology, point cloud data have become a critical data modality across various domains such as geographic information systems, autonomous driving, robot navigation, and augmented reality. A key application lies in autonomous driving, where point clouds facilitate road detection, obstacle recognition, and pedestrian tracking, thereby playing an essential role in environmental perception and positioning [
1,
2,
3,
4,
5]. Furthermore, 3D point clouds are widely utilized in intelligent manufacturing, modern medicine, art design, and cultural heritage preservation, highlighting their broad applicability across disciplines [
6,
7,
8].
Point cloud data are primarily acquired through LiDAR (Light Detection and Ranging) sensors and multi-view photogrammetry techniques. These methods offer unmatched precision in capturing surface morphology and object characteristics [
9]. Structurally, point clouds are represented as multi-dimensional attribute matrices and are commonly stored in formats such as .bin, .pcd, .ply, .txt, and .csv [
10,
11]. The evolution of 3D perception technology has resulted in an exponential increase in the volume of point cloud data. High-precision multi-beam LiDAR systems can now capture millions of points per frame by significantly enhancing angular resolution and scanning frequency [
12]. Advances in solid-state LiDAR, particularly in channel integration and signal processing, have substantially improved the capacity of automotive perception systems to generate dense point clouds within short time intervals [
3,
13,
14,
15,
16]. This provides detailed information for scene reconstruction, enabling the detection and quantification of road defects in point cloud data, as well as supporting applications that require large-scale point cloud datasets—such as large-scale bridge construction—by delivering high-quality, dense point clouds tailored to these demanding tasks [
17,
18]. However, in data processing workflows for applications like autonomous driving and large-scale point cloud Level of Detail (LOD) visualization [
19], the sheer volume of point cloud data presents significant challenges in registration, segmentation, and visualization [
6,
20,
21,
22]. The surge in data volume leads to non-linear increases in computational complexity, imposing significant costs on storage and transmission [
23,
24,
25]. Under these circumstances, point cloud downsampling has emerged as a vital preprocessing technique, offering three primary advantages:
Reduction of computational complexity: Large volumes of point cloud data present significant challenges to point cloud processing algorithms. Directly processing massive point clouds can impose a substantial computational burden. Downsampling mitigates this issue by reducing the number of points through predefined sampling rules and logic, thereby effectively lowering the computational load in subsequent processing stages [
11,
26].
Improvement of data quality: Appropriate downsampling algorithms can effectively address inconsistencies in point density that arise during raw data acquisition due to factors such as equipment limitations and environmental conditions. These inconsistencies can negatively affect downstream processing tasks. For instance, in point cloud registration, varying point densities may lead to poor alignment between point sets [
27,
28]. Similarly, in aerial surveying, spliced point clouds often contain numerous redundant points caused by longitudinal and lateral overlaps, which can degrade both processing speed and modeling accuracy [
29,
30].
Integration of deep learning: With the rapid development of deep learning, various models for point cloud registration, classification, and segmentation have emerged. Notable examples include Qi’s PointNet [
31] and PointNet++ [
26], Li’s PointCNN [
32], and Yang’s RITNet [
4], which serve as foundational architectures for point cloud data processing. In deep-learning applications, downsampling techniques based on the farthest-point sampling algorithm have gained widespread adoption due to their ability to preserve global features and standardize input formats [
33]. These techniques enable point clouds to meet specific network input requirements—such as the standardized 2048-point input required by the PointNet series—while retaining critical feature information.
Current point cloud downsampling methods can be categorized into three primary approaches: rule-based sampling, deep-learning-based sampling, and geometric feature-based sampling. Firstly, the rule-based downsampling methods are regarded as the most convenient methods, including random sampling, uniform sampling, and voxel-based sampling, which prioritize computational simplicity and efficiency. However, they exhibit notable limitations, such as edge detail degradation and inadequate accuracy for complex or high-precision applications [
16,
34,
35]. Secondly, the deep-learning-based downsampling methods face several technical challenges in resource-constrained engineering environments, including dependency on large labeled datasets for training, resulting in high memory consumption and computational overhead, which hinders real-time processing capabilities [
34]. High costs are associated with data acquisition and annotation, often leading to performance degradation and poor generalization in data-scarce or cross-domain scenarios due to overfitting. Thirdly, the geometric feature-based downsampling strategies, such as farthest-point sampling (FPS) and curvature-aware sampling, offer distinct advantages. FPS, in particular, has become a standard preprocessing module in many prominent deep-learning models (e.g., PointCNN, PointNet++) [
20,
36,
37,
38,
39] due to its uniform spatial coverage and topological preservation properties. However, the geometric feature-based dowsampling strategies often encounter significant computational burdens, and their low operational efficiency severely hinders their application in practical engineering. Although the FPS algorithm is highly authoritative in terms of preserving global features, it suffers from its greedy iterative distance calculation, resulting in exponentially increasing complexity with larger point clouds, creating severe performance bottlenecks in CPU-based implementations [
34,
37]. In high-precision applications, FPS typically consumes 30–70% of a neural network’s runtime, with this proportion scaling with data size [
3,
40,
41]. While there are some GPU-based optimizations to improve efficiency, they lack universality and remain unsuitable for resource-constrained environments. In many practical engineering applications, the feasibility of lightweight deployment is of great significance.
Based on the aforementioned analysis, this paper presents DFPS, an efficient downsampling algorithm designed for the global feature preservation of large-scale point cloud data. The proposed DFPS algorithm enhances conventional sampling methodology through two key innovations: an adaptive grid partitioning mechanism that optimizes spatial sampling logic, and a multithreaded parallel computing architecture that accelerates processing throughput. Notably, the algorithm’s lightweight design ensures GPU-independent operation, making it particularly suitable for resource-constrained engineering applications.
The remaining part of this article is arranged as follows:
Section 2 elaborates on the DFPS algorithmic framework, including its operational workflow and fundamental principles.
Section 3 presents comprehensive experimental validation, featuring comparative analyses of sampling efficiency and quality assessment, which collectively demonstrate DFPS’s superior performance as a 3D point cloud downsampling solution.
Section 4 concludes with a discussion of DFPS’s distinctive characteristics, applicable domains, and potential engineering applications.
2. Methodology
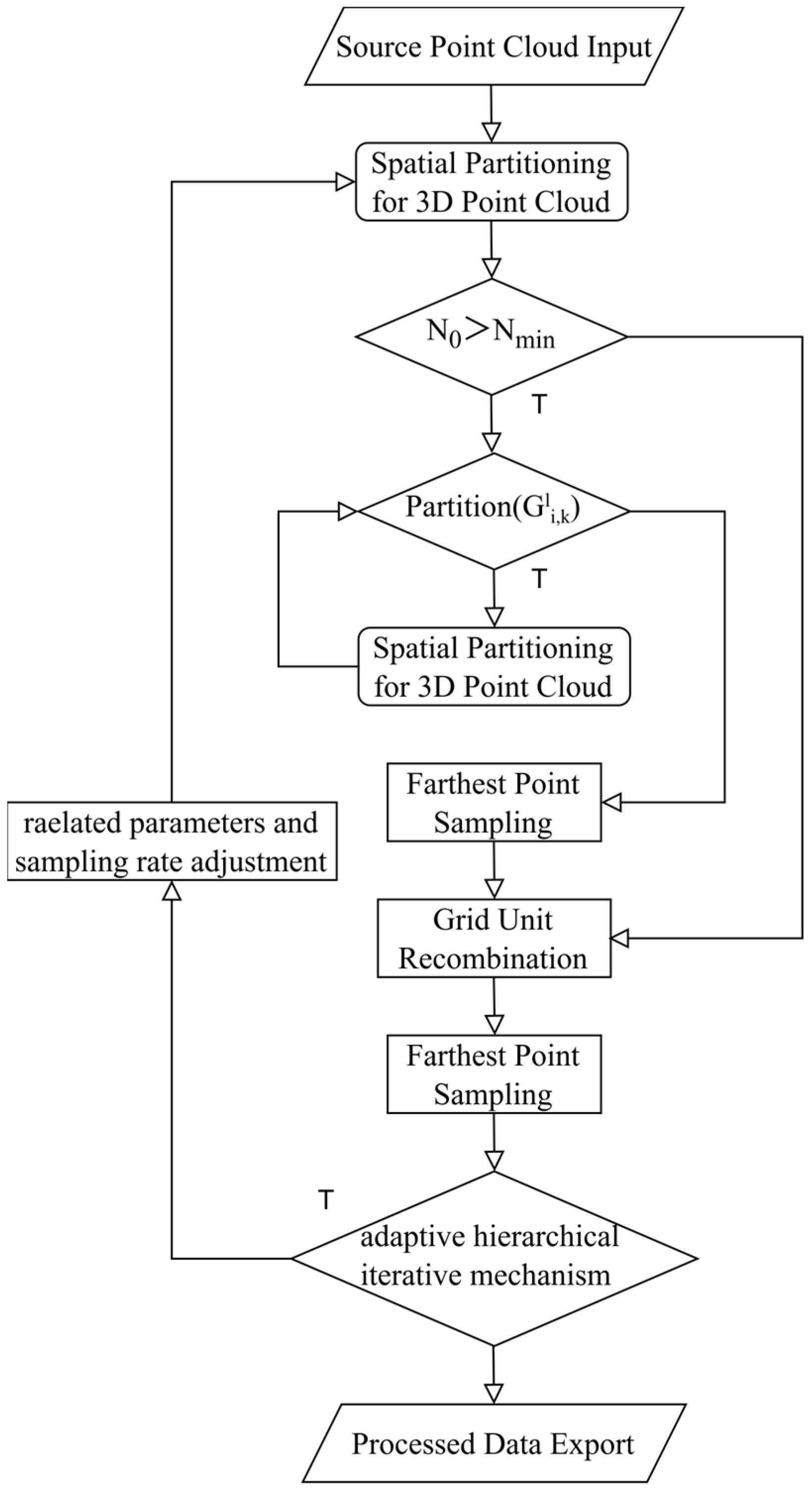
The DFPS algorithm employs an adaptive hierarchical grid partitioning mechanism for iterative farthest-point sampling. This mechanism systematically incorporates critical factors, including the hardware performance of the experimental equipment, the scale of the point cloud data, and the diverse processing objectives for point clouds. Through an iterative optimization process, the algorithm performs dynamic grid partitioning, thereby achieving a rational and efficient multi-level grid division of the entire point cloud dataset. The adaptive hierarchical iterative mechanism can be used to control the number of point cloud outputs to match the preset sampling rate. A distinctive feature of DFPS is its adjustable parameter β, which enables manual calibration of the weight assigned to preserving local details, catering to varying requirements in point cloud data processing tasks. Apart from the adaptive hierarchical grid partitioning mechanism, the algorithm incorporates a multithreaded parallel acceleration architecture, ensuring computational efficiency during the downsampling process of point clouds. The comprehensive logical framework of the DFPS algorithm is illustrated in
Figure 1, demonstrating its systematic workflow.
As illustrated in
Figure 1, the sampling process adopts an iterative farthest-point sampling approach to ensure both processing efficiency and sampling accuracy. The implementation follows these steps: Firstly, the raw data undergo spatial partitioning into eight equal segments. The system then evaluates whether the initial point cloud count N
0 exceeds N
min, where N
min represents the predetermined threshold for initiating the adaptive hierarchical grid partitioning mechanism. This threshold is typically set to a relatively small value (such as 256) to prevent the DFPS adaptive hierarchical grid partitioning mechanism from reducing processing speed when handling small-scale point clouds. If N
0 ≤ N
min, the system performs grid merging followed by immediate grid recombination. If N
0 > N
min, the process proceeds with the adaptive hierarchical grid partitioning mechanism. This mechanism combines first-round farthest-point sampling to enable dynamic adjustment of local detail weights while significantly reducing the computational load for second-round farthest-point sampling.
The adaptive hierarchical grid partitioning determination mechanism serves as the core component of the DFPS algorithm’s iterative optimization process. This determination rule, denoted as
, governs the adaptive partitioning logic throughout the hierarchical grid construction.
Here,
denotes the number of point clouds within the k-th unit of the i-th partition segment at the l-th hierarchical level (
). The parameter
represents the point cloud partitioning threshold, defined as the minimum point cloud count required to initiate a partition. This threshold is determined immediately after loading the raw data into the system, with its calculation formula expressed as follows:
Here,
serves as an adjustable parameter, typically initialized to 1, which globally modulates the partitioning threshold. For instance, when enhanced preservation of local details is required in practical applications, reducing β decreases
, thereby lowering the partitioning threshold.
is the parameter of the adaptive hierarchical iterative mechanism, and it is adjusted during the adaptive hierarchical iteration process.
represents the total point count in the raw dataset, while
denotes the CPU core count and
indicates the base clock frequency of the processor.
corresponds to the initial block size of the raw data, and
signifies the minimum resolution threshold, implemented to prevent resource inefficiency caused by excessive partitioning in extreme cases.
is quantified by the grid block dimensions after successive partitioning operations, with its determination formula expressed as:
When the adaptive hierarchical grid partitioning condition evaluates to True, the corresponding point cloud undergoes octant segmentation. Each resulting grid partition is dynamically assessed against the point cloud partitioning threshold
until meeting the iteration termination criterion. This iterative approach enables independent first-round farthest-point sampling (at the designated sampling rate) for all grid partitions. The sampled point sets
from each grid partition are subsequently aggregated:
. The unified point set S then undergoes second-round farthest-point sampling, producing a 50% sampled output for the adaptive hierarchical iterative mechanism’s evaluation. This iterative framework simultaneously regulates the final output point cloud’s sampling rate. Firstly, we claim that
, let
. Then,
.
Here, represents the number of iterations, n is the target number of iterations, and is the approximation value of the sampling rate calculated in the i-th iteration, while a is the target sampling rate. At this point, the true value of the sampling rate in the i-th iteration is . When the adaptive hierarchical iteration mechanism is determined to be true, parameter adjustments are made: for γ in , , where is the γ value after the last iteration adjustment, and for , .
When the value is False, no parameter adjustment is performed. The sampling rate is set as , the final sample is taken, and the final result is output.
DFPS dynamically determines the maximum point count per grid cell based on the computational capabilities of the target hardware. The input point cloud is partitioned into hierarchical grids using a subdivision methodology analogous to octree structures, with a critical distinction: DFPS automatically increases partitioning depth in densely populated regions to ensure uniform point distribution across all grids, thereby maximizing efficiency gains from multithreaded parallelization. By adopting a dynamic and hierarchical downsampling method, it is more suitable for processing extremely large point cloud data, avoiding the memory usage problem caused by the logic of the farthest-point sampling itself. This strategy balances local feature preservation with global structural coherence, ensuring optimal preservation of critical feature information in the final sampled output. The core objective of farthest-point sampling is to achieve non-uniform and efficient sampling of the original point cloud by iteratively selecting the point that is farthest from the set of already sampled points. The algorithm process is described in
Figure 2 with the attached diagram illustrating the principle of FPS [
39]:
With a point cloud set , the iterative process of farthest-point sampling for generating a downsampled subset is formally defined as follows:
Randomly select a seed point and initialize the set as .
Conduct iterative sampling: for each iteration , compute the minimum Euclidean distance from each candidate point to the current sampled set S: . Identify the candidate point with the largest minimum distance: . Lastly, augment the sampled set: .
Furthermore, DFPS introduces a multithreaded parallel acceleration architecture that synergistically optimizes computational efficiency through two complementary parallelism strategies:
Acceleration for entire progress: This architecture parallelizes computations across adaptively partitioned grids. For instance, in the illustrated example, the initial point cloud is decomposed into eight grid blocks through one iteration of adaptive partitioning. Each grid block is assigned to an independent thread, enabling concurrent processing of localized farthest-point sampling (FPS) operations.
Acceleration for the single grid: Within each grid block, the algorithm further implements fine-grained parallelism during critical computational phases, such as the calculation of minimum Euclidean distances in FPS. This intra-grid parallelization exploits multi-core capabilities to accelerate distance metric evaluations and candidate point selection.
As depicted in the
Figure 3, this dual-layered acceleration mechanism operates at both the global grid decomposition level and the local per-grid computation level. The hierarchical approach minimizes computational redundancy while maximizing hardware resource utilization, particularly in scenarios involving recursive grid decomposition. By decoupling coarse-grained task parallelism from fine-grained data parallelism, DFPS achieves near-linear scalability with respect to available CPU cores, establishing a robust foundation for real-time processing of billion-scale point clouds.
3. Related Experiments
To validate the effectiveness and robustness of DFPS, the experiment consists of two modules. The first module focuses on verifying the operational efficiency of DFPS, while the second module is the feature preservation performance test.
3.1. Verification of DFPS Operational Efficiency
The operational efficiency evaluation involves comparative analysis among DFPS, standardized FPS (Farthest-Point Sampling), and FPS_After (a baseline optimized version incorporating only multithreading and point cloud data access optimization). The comparison is conducted under different sampling ratios (1/8, 1/16, 1/32) and varying point cloud scales. Synthetic spherical point clouds with uniform sizes were generated as experimental data, covering point quantities ranging from 29 to 220 (i.e., 512 to 1,048,576 points). These datasets represent typical processing requirements for initial point clouds in practical applications.
All tests were not conducted on high-performance computing devices, but rather on an Intel
® Core™ i7-9750H CPU @ 2.60 GHz platform. Three tables (
Table 1,
Table 2 and
Table 3) present the average computation time (derived from 20 repeated executions for each point cloud scale) required by different downsampling methods to process multi-order point cloud magnitudes under specified sampling rates.
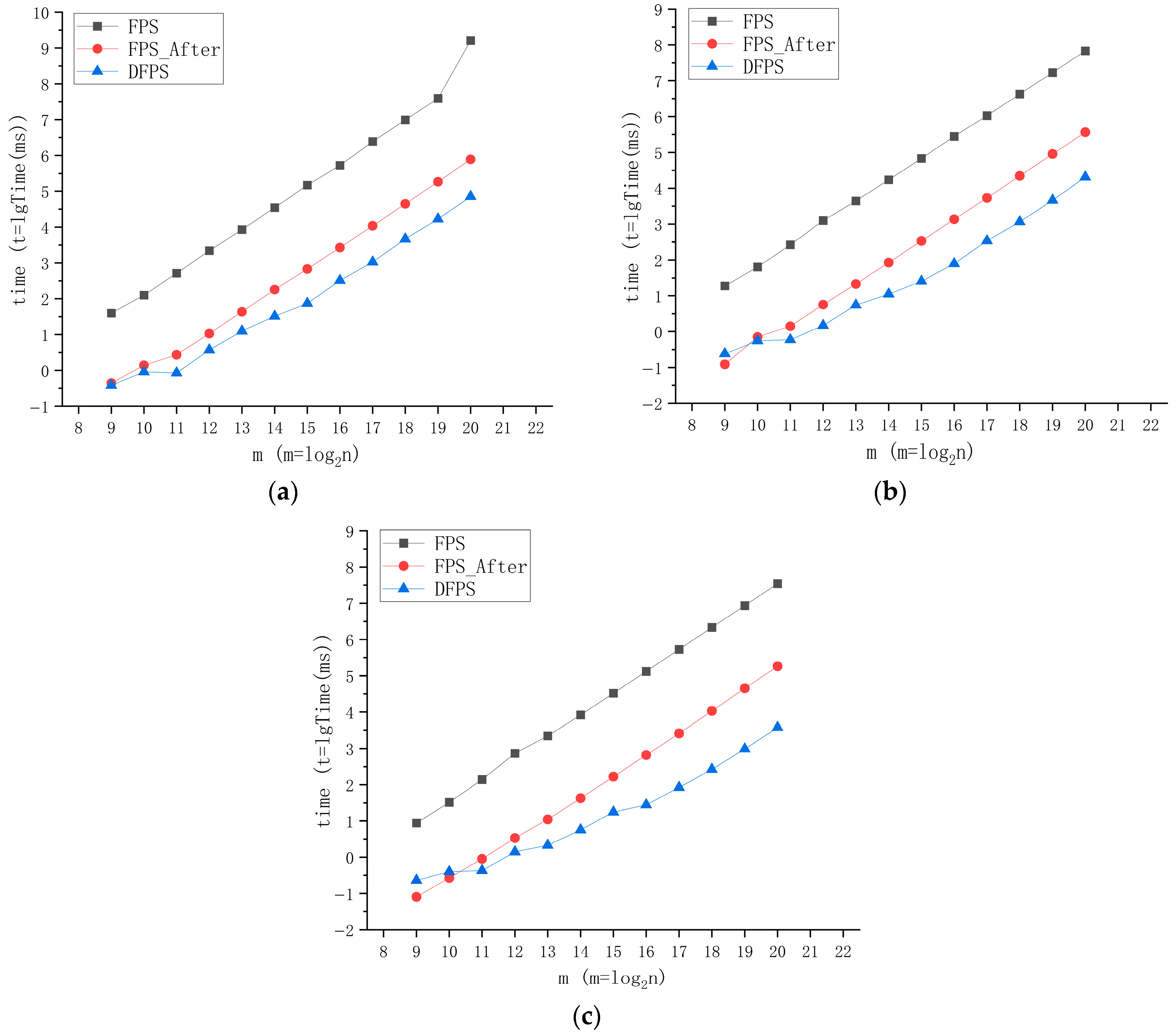
In order to compare the speed changes of each method more intuitively, the data in the above tables are visualized. Since the times increase exponentially with the number of points, logarithmic representation is adopted to make the effect comparison more convenient: m represents the total number of points, and Time represents the average running time required by the method for a certain number of points at this sampling rate, as shown in
Figure 4.
As evidently illustrated in the preceding figure, DFPS exhibits exceptional computational efficiency. The results demonstrate that the processing speed of DFPS for point cloud data has significantly improved, particularly when handling large-scale point cloud datasets. Owing to the inherent computational logic of DFPS, while there is only a marginal improvement in the calculation performance for small-scale point cloud data, DFPS demonstrates remarkably strong processing capabilities for large-scale point cloud data. The processing delay for millions of point cloud data has been reduced from approximately 161,665 s using the original FPS method to approximately 71.64 s with DFPS (12.5% sampling rate), representing an efficiency improvement of over 2200 times. As the sampling rate requirement decreases, this improvement becomes even more pronounced: the processing time is reduced from approximately 35,060 s with the original FPS method to approximately 3.78 s with DFPS (3.125% sampling rate), achieving an efficiency improvement of nearly ten thousand times.
In the ablation study presented in
Figure 5, the performance of the adaptive hierarchical grid partitioning mechanism in managing point cloud data is evaluated. For smaller point clouds, due to unavoidable inherent computational overheads such as hierarchical grid calculations and decomposition, the speed advantage of the adaptive hierarchical grid partitioning sampling logic employed by DFPS is not significant. However, as the volume of the point cloud increases and the target sampling rate decreases, the computational superiority of DFPS’s adaptive farthest-point downsampling becomes increasingly prominent. Compared to the FPS variant (FPS_After) that solely employs a multithreaded parallel acceleration architecture, the farthest-point downsampling method based on an adaptive hierarchical grid partitioning mechanism achieves tens of times better performance, with this performance gap widening substantially as the point cloud scale expands and the sampling rate diminishes. At a sampling rate of 3.125%, the performance enhancement for a million-point cloud dataset reaches nearly 60 times. This underscores the exceptional scalability and efficiency of the adaptive hierarchical grid partitioning mechanism in large-scale processing scenarios. These findings ultimately confirm the substantial speed advantage of DFPS over traditional farthest-point sampling methods, especially in applications demanding real-time processing of large-scale point clouds.
This divergence in performance trajectories conclusively validates the effectiveness of the adaptive hierarchical grid partitioning architecture in balancing algorithmic efficiency with scalability. The trend underscores two critical insights:
The adaptive hierarchical grid partitioning mechanism achieves optimal resource utilization only when the point cloud scale and sampling complexity surpass a critical threshold, beyond which its hierarchical parallelism significantly outperforms flat multithreaded implementations. Considering the difference is only at the level of 10-1 milliseconds, this issue can be disregarded in the vast majority of engineering applications. If the task has certain requirements for timeliness, a judgment mechanism can be added subsequently.
The algorithmic advantage amplifies inversely with sampling rate, demonstrating DFPS’s capability to maintain sublinear time complexity under aggressive downsampling requirements—a capability absent in conventional FPS variants, which affirms that the adaptive hierarchical grid partitioning mechanism is not merely an auxiliary optimization but a fundamental enabler of scalable, high-performance point cloud processing.
3.2. DFPS Feature Preservation Performance Test
Lightweight processing of large-scale point cloud data is a critical preprocessing step in point cloud data analysis. In most point cloud processing algorithms, high-quality input data significantly influence the processing outcome, and effective point cloud data downsampling is essential. The farthest-point sampling (FPS) algorithm is widely acknowledged for its superior feature retention capabilities. However, whether the DFPS algorithm with an adaptive hierarchical grid partitioning mechanism can achieve comparable global feature retention to the FPS algorithm remains to be experimentally validated. This module evaluates the global feature retention capability through visual observation and comparison. To intuitively demonstrate the sampling quality of DFPS and validate its effectiveness, a test module is designed using large-scale airborne point cloud data, which include both large-scale airborne marine survey data and large-scale airborne land survey data.
3.2.1. Experiments on Marine Survey Data
The marine survey data were acquired by the MAPPER-20kU unmanned aerial vehicle-mounted water and land detection laser radar developed by the Shanghai Institute of Optics and Fine Mechanics, Chinese Academy of Sciences, China. This system conducted on-site airborne blue–green laser radar measurements in Jiuzhaigou, China, as well as in a shallow sea region in Danzhou City, Hainan Province, China.
Table 4 provides detailed parameter information for the MAPPER-20kU unmanned aerial vehicle-mounted water and land detection laser radar.
Figure 6 shows the comparison effect of global and local visual observation results obtained by downsampling the airborne blue–green laser bathymetric data of Wuhua Sea (containing 6,091,468 points) and the airborne blue–green laser bathymetric data of the shallow sea area of Danzhou (a partial view) (containing 8,261,654 points) through the DFPS algorithm with a 2% sampling rate.
As demonstrated in the figure above, even at extremely low sampling rates, the DFPS algorithm demonstrates a robust capability to preserve global features. By comparing the processing results before and after using the Wufahai data (as shown in
Figure 7a,b) and the local data from the Danzhou shallow sea area (as shown in
Figure 7c,d), it is evident that edge terrain features and relatively flat central areas with micro-topographic height variations have been effectively retained. Furthermore, by eliminating a significant amount of redundant data caused by heading overlap and side overlap, the overall density of the point cloud becomes more consistent, thereby reducing the computational burden associated with large-scale data processing and large-scale point cloud visualization. Due to the vast amount of data in airborne point clouds and the substantial redundancy caused by heading and side overlaps, directly processing high-density point clouds would impose an immense computational burden. Appropriate downsampling not only removes redundant data caused by swath overlap and reduces point cloud density to enhance processing speed but also smooths the point cloud data, standardizes its density, and suppresses point cloud layers to improve modeling accuracy. The sampled data can serve as high-quality input for subsequent point cloud data processing. For instance, the processing of airborne blue–green laser bathymetry data from Wuhua Sea (comprising 6,091,468 points) took only 43 s, further illustrating the efficiency of DFPS in handling large-scale data.
3.2.2. Experiments on Land Survey Data
The land survey data were obtained by the VSurs-ARL airborne LiDAR system of Qingdao Xiushan Mobile Measurement Co., Ltd. (Qingdao, China) for several local areas of the campus of Shandong University of Science and Technology. The VSurs-ARL airborne LiDAR system is a brand-new high-end LiDAR system with an ultra-long measurement range, which is mounted on light manned aircraft, unmanned helicopters, vertical take-off and landing fixed-wing aircraft, and multi-rotor unmanned aerial vehicle platforms. It is equipped with a full-frame mirrorless camera and a high-precision MEMS integrated navigation system, making it highly suitable for applications in strip mapping scenarios with high point density requirements, such as power line inspection and corridor mapping. Through high-precision scanning, more comprehensive and detailed original data can be acquired. After downsampling and preprocessing, the data can serve as more representative input for subsequent point cloud semantic segmentation and target recognition tasks in the region.
Table 5 provides the relevant detailed parameter information of the VSurs-ARL airborne LiDAR system and
Figure 8 presents the product images of the VSurs-ARL Airborne Laser Radar System.
Figure 9 shows the data of the campus of Shandong University of Science and Technology (a partial view), which contains 8,492,248 points. Through the DFPS algorithm, a 5% sampling rate downsampling was performed, and the comparison effect diagram of the global and local visual observation is obtained:
Figure 9 provides a comparative analysis of pre-processed and post-processed airborne survey data from Shandong University of Science and Technology, China (partial study area). The results demonstrate that under low sampling rate (at 5%) conditions, the DFPS algorithm effectively preserves critical geospatial features, including vegetation distribution, road inflection points, and terrain–object boundary characteristics, as visually verifiable through the comparative visualization. Simultaneously, the DFPS algorithm achieves substantial noise suppression and successfully eliminates interference from dynamic objects (e.g., vehicular movements). Further examination of the lower-left subfigure in panel (a) reveals that the raw data exhibit pronounced striation artifacts originating from the LiDAR profile scanning mechanism, which introduces both data redundancy and adverse impacts on computational efficiency and visual interpretability during downstream processing. In contrast, the corresponding subfigure in panel (b) demonstrates the complete elimination of striation patterns through the implementation of DFPS, along with a more homogenized density distribution, higher quality, and more concise input point cloud, thus creating optimized input conditions for subsequent spatial data processing workflows, such as point cloud semantic segmentation and target recognition.
3.2.3. Quantitative Analysis of Sampling Effects
Section 3.2.1 and
Section 3.2.2 have preliminarily demonstrated through visual inspection that DFPS exhibits strong global feature retention capabilities, even at low sampling rates. To enhance the rigor and persuasiveness of this claim, we conduct a quantitative analysis of DFPS’s sampling performance. Point cloud downsampling aims to reduce data volume while preserving the original geometric characteristics. However, due to varying objectives—such as improving computational efficiency or enabling comprehensive feature extraction—a universally consistent metric for quantifying feature preservation is lacking. The chamfer distance addresses this challenge by measuring overall shape discrepancies between two point clouds through a bidirectional nearest neighbor search (the calculation formula is as follows [
42]), thereby symmetrically quantifying differences.
Here, and represent two point cloud datasets that need to calculate the Chamfer distance. The approach effectively mitigates the bias inherent in one-way distance measurements. Notably, the bidirectional computation ensures that the sparsity of the downsampled point cloud does not distort the evaluation results, unlike one-way distance methods. Therefore, we adopt the Chamfer distance as our evaluation metric.
In
Section 1, it is mentioned that the farthest-point sampling algorithm, which has demonstrated excellent performance in preserving global features, has gained widespread recognition and has been incorporated into various neural networks. To demonstrate that the DFPS algorithm maintains a comparable level of global feature retention as the FPS algorithm, it suffices to show that the Chamfer distance between point clouds processed by the DFPS and FPS algorithms remains minimal. To enhance the credibility of the verification, the data used in this section are derived from a partial view of the campus of Shandong University of Science and Technology. The sampling rate starts at 20% and decreases gradually by 2.5% in each step until reaching 2.5%. The experiments include voxel downsampling and uniform downsampling as control methods for comparative analysis.
From
Table 6, it is evident that DFPS sampling achieves results closer to farthest-point sampling when compared to voxel downsampling and uniform downsampling. This similarity in performance holds true both under medium retention conditions (such as 20% sampling rate) and low retention conditions (such as 2.5% sampling rate). When combined with the visual comparisons presented in
Section 3.2.1 and
Section 3.2.2, these findings strongly support the conclusion that DFPS is an efficient downsampling algorithm, particularly well-suited for global feature extraction from large-scale point cloud data.
4. Conclusions
This paper addresses the issues of excessive redundant points in large-scale laser point cloud data processing, which negatively impact the efficiency of subsequent point cloud data processing. Additionally, it highlights the inability of traditional downsampling algorithms to adequately preserve global features. To tackle these challenges, a DFPS (Dynamic Farthest-Point Sampling) downsampling algorithm based on an adaptive hierarchical grid partitioning mechanism is proposed. Through experimental validation, DFPS significantly enhances the algorithm’s running speed while ensuring the integrity of both global and local features of the point cloud. This provides a novel technical approach for large-scale laser point cloud data processing under resource-constrained environments.
4.1. Research Summary
The DFPS algorithm incorporates an adaptive multi-level grid partitioning mechanism that synergistically combines dynamic recursive sampling logic with farthest-point sampling principles. Through recursive subdivision of point clouds into computational resource-optimized grid units and implementation of a multithreaded parallel acceleration architecture, the system achieves substantial computational efficiency enhancements. This approach resolves the serialization bottleneck inherent in conventional FPS iterative processes while reducing constructor invocations to optimize memory utilization, thereby achieving balanced workload distribution and refined memory access patterns. Comparative experiments reveal that DFPS demonstrates order-of-magnitude performance enhancements ranging from ~10× to ~60× compared to a non-adaptive hierarchical grid partitioning mechanism and a multi-thread-only optimized variant, with acceleration effects becoming progressively pronounced at lower sampling rates. The adaptive grid architecture enables DFPS to maintain significant processing speed advantages across point clouds spanning three orders of magnitude (103–106 points). On an Intel i7-9750H platform, DFPS reduces processing latency for million-point clouds from 161,665 s (baseline FPS at 12.5% sampling) to 71.64 s (2200× acceleration), with further efficiency gains observed at reduced sampling rates: 35,060 s (baseline FPS at 3.125%) versus 3.78 s (9278× acceleration). In addition to its high processing efficiency, DFPS exhibits robust global feature retention and effective redundant point elimination capabilities. By employing visual observation and quantitative analysis (with the chamfer distance as the measurement index), it is evident that DFPS can effectively preserve global feature information even at low sampling rates. It excels in retaining micro-topography details while efficiently eliminating redundant points, thereby providing high-quality input for subsequent point cloud data processing and computations. Furthermore, leveraging a lightweight multithreaded design on the CPU, DFPS operates independently of GPU heterogeneous computing, thus avoiding reliance on specialized frameworks such as CUDA. This enables seamless deployment in resource-constrained environments, including airborne systems and mobile devices, making it especially suitable for the downsampling of large-scale laser depth point clouds following stitching.
4.2. Application Prospects
The DFPS algorithm has been empirically validated for computational efficiency and operational robustness. Its superior capability in preserving global structural features, coupled with high-throughput processing performance, establishes it as a general-purpose solution for large-scale point cloud datasets. This methodology effectively addresses critical challenges, including redundant data elimination and computational overhead reduction in downstream processing pipelines. Furthermore, the integration of adaptive dynamic sampling with multi-scale feature retention mechanisms demonstrates significant potential for diverse engineering applications.
- 1.
High-Precision Point Cloud Processing Applications
DFPS exhibits distinctive capabilities in precision-critical operations, including point cloud registration, semantic segmentation, and object classification. Conventional registration methodologies suffer from accuracy degradation induced by heterogeneous feature space distributions stemming from density variations. DFPS mitigates this limitation by establishing density-uniform point distributions, thereby enhancing alignment precision in overlapping regions. For semantic segmentation tasks, the algorithm’s adaptive hierarchical grid partitioning mechanism ensures comprehensive retention of both global topological characteristics and local geometric minutiae during redundancy removal. This dual-scale preservation property enables deep-learning frameworks to achieve enhanced discriminative performance on fine-grained features, particularly in texture-deficient regions such as road boundaries and foliage edges. As neural network-based point cloud analysis remains an active research frontier, DFPS serves as a preprocessing module that optimally balances computational efficiency with semantic consistency for the algorithm based on the deep-learning method.
- 2.
Hierarchical Multi-Resolution Management for Ultra-Scale Point Cloud
The advancement of laser scanning hardware has precipitated exponential growth in point cloud data volumes. Post-stitching processing of bathymetric point clouds in large-scale maritime environments routinely generates datasets exceeding hundreds of millions of sampling points. DFPS’s adaptive hierarchical architecture demonstrates seamless interoperability with Level of Detail (LOD) theory, enabling multi-resolution visualization and computational management of ultra-scale point clouds through GPU-accelerated processing pipelines. Integrated with a viewpoint-adaptive resolution control mechanism, the algorithm dynamically adjusts sampling densities in response to observational proximity thresholds. Spatially varying sampling strategies across resolution hierarchies ensure optimal preservation of global geometric features during rendering while maintaining perceptual fidelity, thereby substantially mitigating computational overhead in DFPS-LOD integrated systems. This framework implements tiered data streaming: low-resolution proxies facilitate real-time interaction on mobile/web platforms, whereas cloud-hosted full-resolution datasets empower semantic parsing of navigation-critical features, including reef formations and submerged structures. The DFPS-LOD synergy consequently establishes a paradigm-shifting solution to storage-computation-visualization constraints inherent in large-scale digital twin ecosystems for coastal cities and oceanic environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}