
TCN-MAML: A TCN-Based Model with Model-Agnostic Meta-Learning for Cross-Subject Human Activity Recognition

 ,
,  ,
,  and
and
Abstract
1. Introduction
- We proposed a novel TCN-MAML model for effective few-shot cross-subject human activity recognition using Wi-Fi signals. To the best of our knowledge, this study is the first to explore the unique integration of Temporal Convolutional Networks with the MAML algorithm for HAR, which surpasses state-of-the-art methods in performance.
- Three augmentation methods specifically designed for Wi-Fi signals were proposed. These methods incorporate variations into the original signals to effectively expand the dataset and enrich its diversity. The application of these proposed augmentation techniques resulted in over 10% improvement in test accuracy compared to the baseline model trained without any augmentation.
- This study is the first to conduct realistic cross-subject experiments by partitioning the HHI dataset into two non-overlapping subsets, where the model was trained on one subset and tested on the other. The proposed approach yields a remarkable recognition accuracy of 99.60% on new subjects.
2. Related Work
2.1. Wi-Fi-Based Human Activity Recognition (HAR)
2.2. Few-Shot Learning-Based HAR Approaches
2.3. Recent Advances in Deep Learning-Based Wi-Fi HAR
3. Proposed Method
3.1. Preliminaries
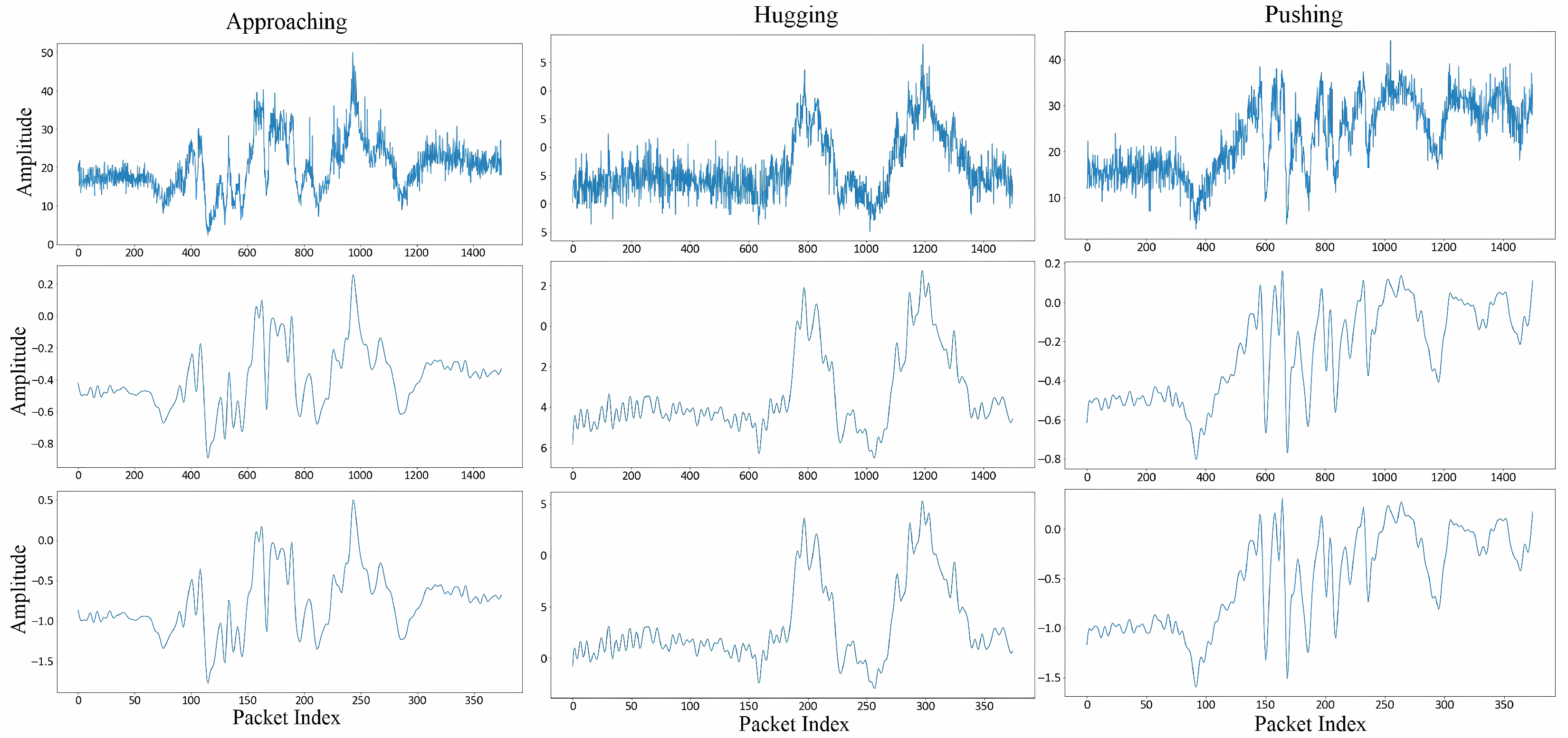
3.1.1. The HHI CSI Dataset
3.1.2. Problem Definition
3.2. Preprocessing
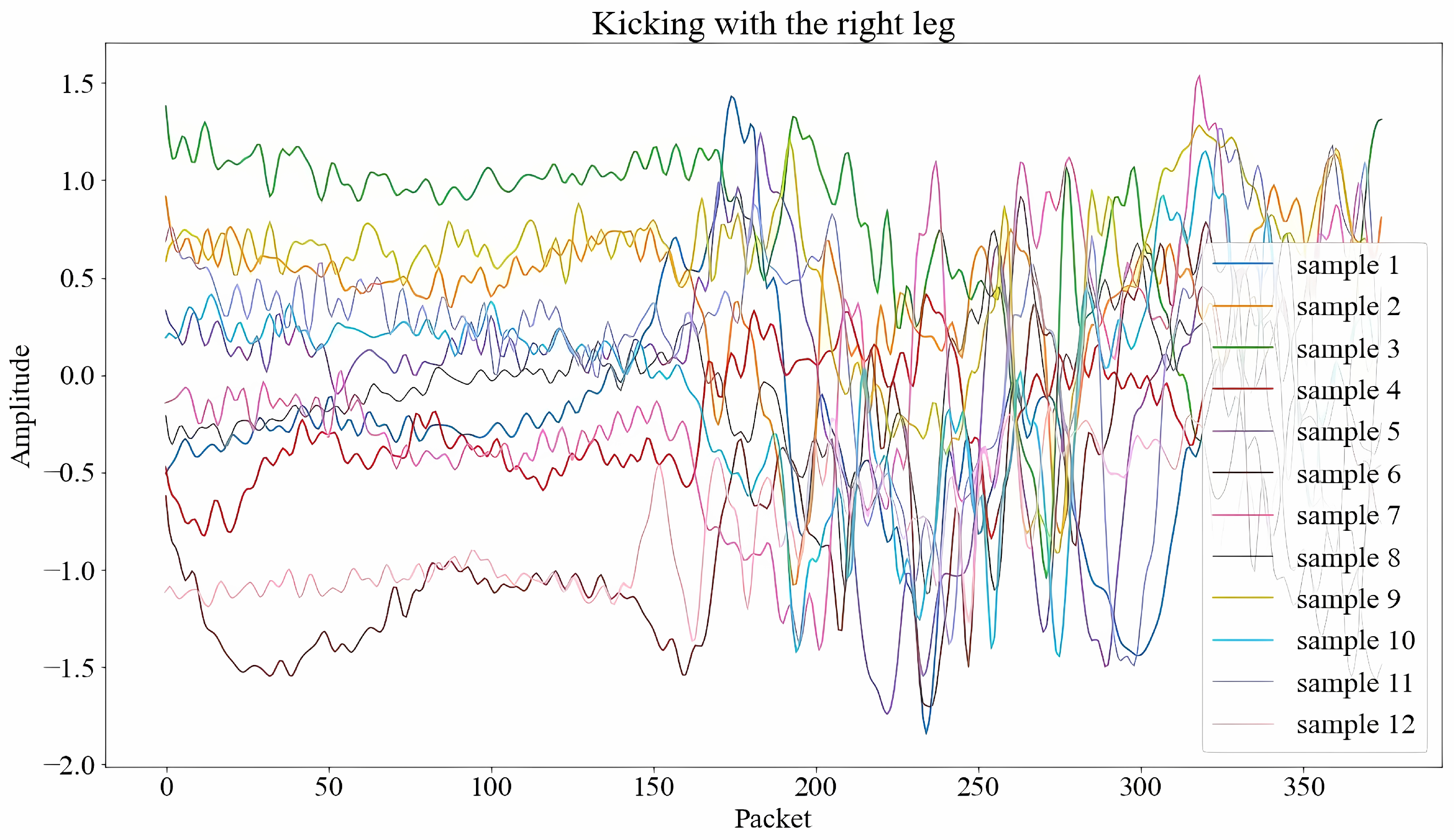
3.3. Data Augmentation
3.3.1. Random Dropout
3.3.2. Inter-Class Mixing
3.3.3. Intra-Class Mixing
3.4. TCN-MAML Model
3.4.1. TCN Model
3.4.2. TCN with MAML
- : model parameters before task i adaptation;
- : task-specific parameters after m inner-loop updates;
- : learning rates for inner- and outer-loop updates, respectively;
- , : support and query sets sampled from task ;
- , : ground truth labels for the support and query sets;
- : model parameterized by ;
- : task-specific loss function;
- M: number of inner-loop updates.
4. Experiments
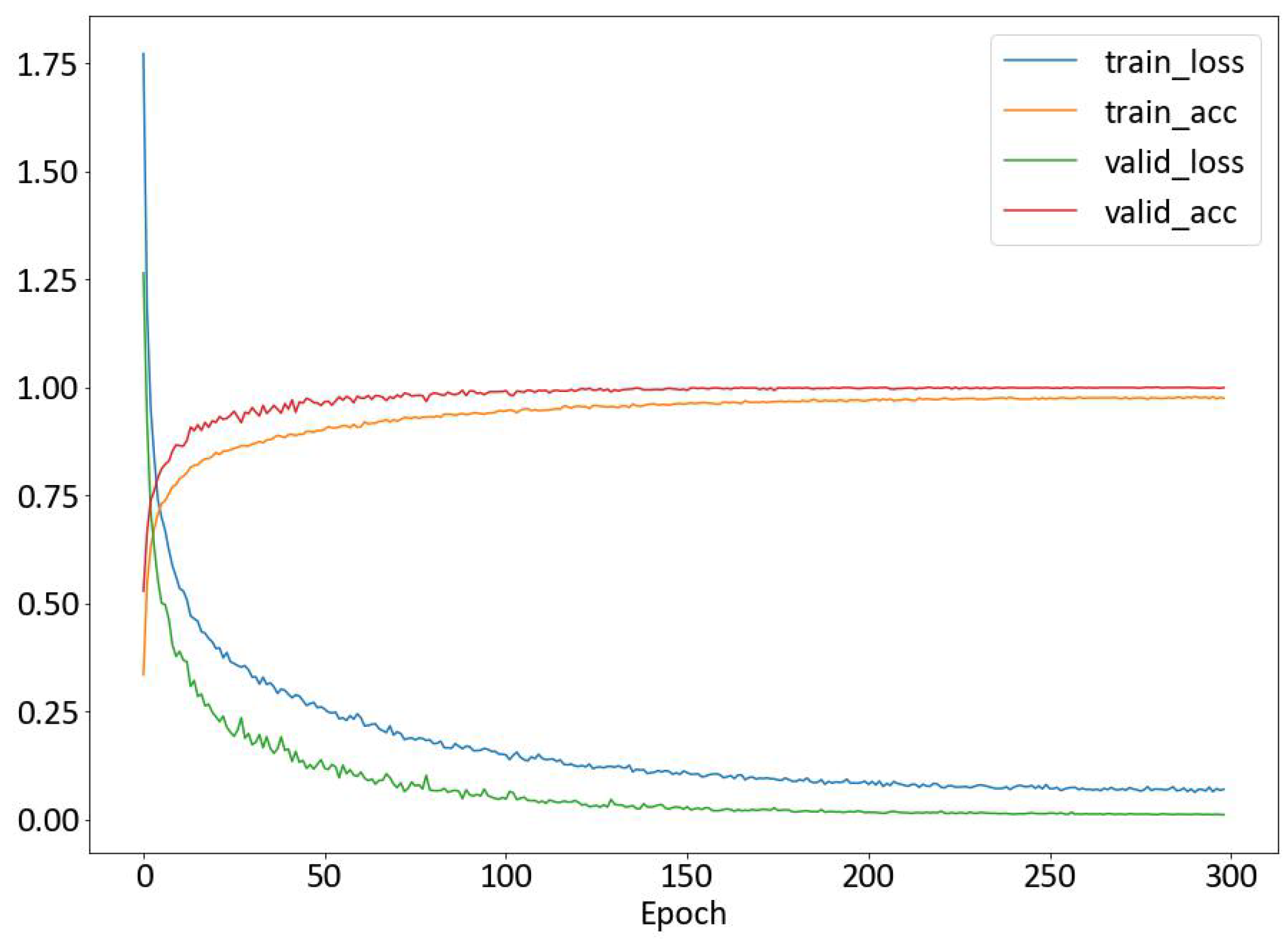
4.1. Experimental Setup
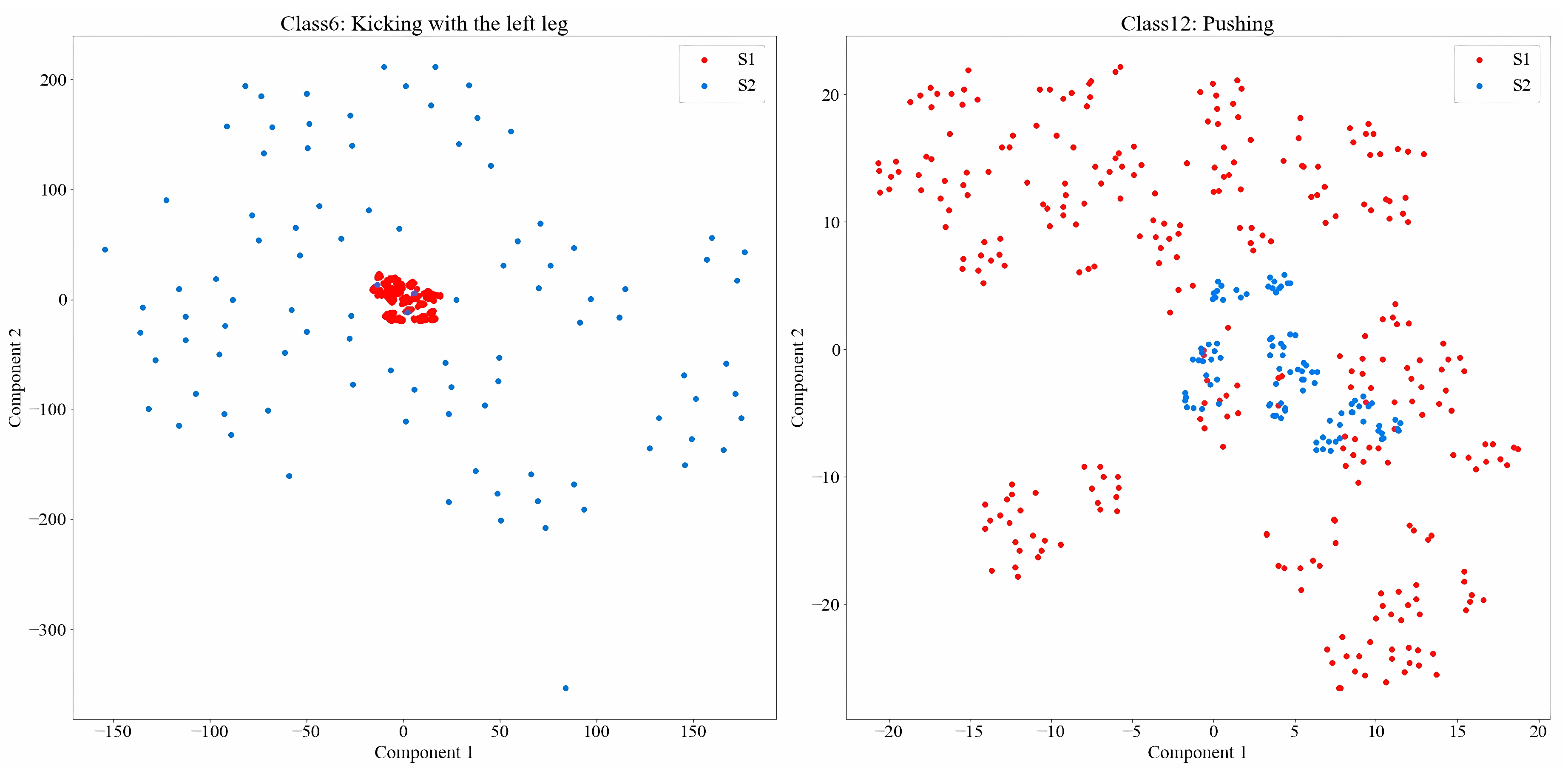
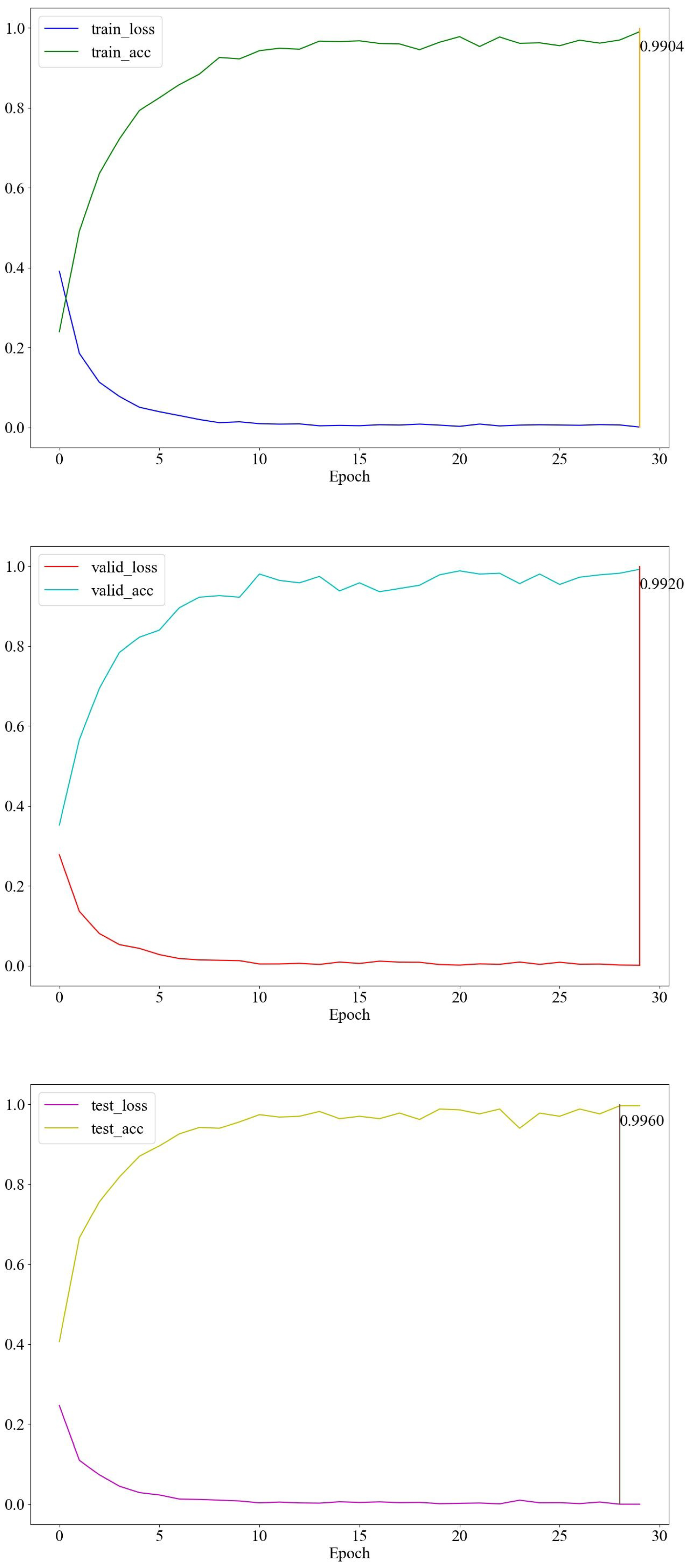
4.2. Performance Evaluation
Cross-Subject Recognition Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Münzner, S.; Schmidt, P.; Reiss, A.; Hanselmann, M.; Stiefelhagen, R.; Dürichen, R. CNN-based sensor fusion techniques for multimodal human activity recognition. In Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 158–165. [Google Scholar]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl. Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Shafiqul, I.M.; Jannat, M.K.A.; Kim, J.W.; Lee, S.W.; Yang, S.H. HHI-AttentionNet: An enhanced human-human interaction recognition method based on a lightweight deep learning model with attention network from CSI. Sensors 2022, 22, 6018. [Google Scholar] [CrossRef] [PubMed]
- Alazrai, R.; Awad, A.; Baha’A, A.; Hababeh, M.; Daoud, M.I. A dataset for Wi-Fi-based human-to-human interaction recognition. Data Brief 2020, 31, 105668. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.H.; Ara, J.M.K.; Rahman, M.H.; Yang, S. A study of real-time physical activity recognition from motion sensors via smartphone using deep neural network. In Proceedings of the 2021 5th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 17–19 December 2021; IEEE: Piscatawy, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Ma, Y.; Zhou, G.; Wang, S. WiFi sensing with channel state information: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Lin, C.Y.; Lin, C.Y.; Liu, Y.T.; Chen, Y.W.; Shih, T.K. WiFi-TCN: Temporal Convolution for Human Interaction Recognition based on WiFi signal. IEEE Access 2024, 12, 126970–126982. [Google Scholar] [CrossRef]
- Ahad, M.A.R. Activity recognition for health-care and related works. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1765–1766. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: New York, NY, USA, 2017; pp. 1126–1135. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Kabir, M.H.; Rahman, M.H.; Shin, W. CSI-IANet: An inception attention network for human-human interaction recognition based on CSI signal. IEEE Access 2021, 9, 166624–166638. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Moustafa, N.; Mohammad, N. H2HI-Net: A dual-branch network for recognizing human-to-human interactions from channel-state information. IEEE Internet Things J. 2021, 9, 10010–10021. [Google Scholar] [CrossRef]
- Mettes, P.; Van der Pol, E.; Snoek, C. Hyperspherical prototype networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhou, Z.; Wang, F.; Yu, J.; Ren, J.; Wang, Z.; Gong, W. Target-oriented semi-supervised domain adaptation for WiFi-based HAR. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, Online, 2–5 May 2022; IEEE: Piscatway, NJ, USA, 2022; pp. 420–429. [Google Scholar]
- Zhang, Y.; Chen, Y.; Wang, Y.; Liu, Q.; Cheng, A. CSI-based human activity recognition with graph few-shot learning. IEEE Internet Things J. 2021, 9, 4139–4151. [Google Scholar] [CrossRef]
- Wang, D.; Yang, J.; Cui, W.; Xie, L.; Sun, S. CAUTION: A Robust WiFi-based human authentication system via few-shot open-set recognition. IEEE Internet Things J. 2022, 9, 17323–17333. [Google Scholar] [CrossRef]
- Sousa, C.; Fernandes, V.; Coimbra, E.A.; Huguenin, L. Subcarrier selection for har using csi and cnn: Reducing complexity and enhancing accuracy. In Proceedings of the 2024 IEEE Virtual Conference on Communications (VCC), Online, 3–5 December 2024; IEEE: Piscatawy, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Shahverdi, H.; Nabati, M.; Fard Moshiri, P.; Asvadi, R.; Ghorashi, S.A. Enhancing CSI-based human activity recognition by edge detection techniques. Information 2023, 14, 404. [Google Scholar] [CrossRef]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11 n traces with channel state information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part v 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Graves, A.; Graves, A. Long short-term memory. Supervised Seq. Label. Recurr. Neural Netw. 2012, 385, 37–45. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Yang, J.; Chen, X.; Zou, H.; Wang, D.; Xu, Q.; Xie, L. EfficientFi: Toward large-scale lightweight WiFi sensing via CSI compression. IEEE Internet Things J. 2022, 9, 13086–13095. [Google Scholar] [CrossRef]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using WiFi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Predef. Embed. 1 | New Subj.Adapt. 2 | Extra Data 3 | Feature Engr 4 | General HAR 5 |
|---|---|---|---|---|---|
| ProtoNet | O | X | X | X | O |
| TOSS | X | O | O | X | O |
| CSI-GDAM | X | X | O | O | O |
| CAUTION | X | X | X | O | X |
| TCN-MAML (Ours) | X | O | X | X | O |
| Component | Parameter | Value |
|---|---|---|
| TCN Backbone | Number of Layers | 3 |
| Dilation Rates | 1, 2, 4 | |
| Number of Filters | 30, 50, 75 | |
| Kernel Size | 15 | |
| Dropout Rate | 0.1 | |
| Output Shape | Final TCN Output Dimension | |
| FCN Classifier | Number of Dense Layers | 2 |
| First Dense Layer Neurons | 128 | |
| Second Dense Layer Neurons | 64 | |
| Dropout Rate | 0.1 | |
| Output Layer Neurons | ||
| Batch Size | 32 | |
| Meta-learning Outer Learning Rate | ||
| Task-level Inner Update Learning Rate | ||
| Inner-loop Adaptation Steps | 5 | |
| Inner-loop Testing Steps | 10 |
| Dataset | Testing Accuracy (%) |
|---|---|
| NTU-Fi HAR | 99.12 |
| UT-HAR | 98.66 |
| HHI | 99.6 |
| Method | Accuracy (%) |
|---|---|
| TCN-AA (Ours) | 99.60 |
| SVM | 86.21 |
| CSI-IANet | 91.30 |
| DCNN | 88.66 |
| HHI-AttentionNet | 95.47 |
| GraSens | 86.00 |
| E2EDLF | 86.30 |
| Attention-BiGRU | 87.00 |
| H2HI-Net | 96.39 |
| Augmentation Method | Accuracy (%) | Loss | ||||
|---|---|---|---|---|---|---|
| Train | Valid | Test | Train | Valid | Test | |
| Raw data | 100 | 67.2 | 87.0 | 0.001 | 1.098 | 0.553 |
| Raw + Dropout | 99.7 | 84.2 | 94.6 | 0.002 | 0.184 | 0.109 |
| Raw + Intra-mixing (30%) | 98.8 | 86.5 | 94.9 | 0.008 | 0.178 | 0.055 |
| Raw + Intra-mixing (20%) | 98.2 | 83.1 | 90.9 | 0.01 | 0.192 | 0.069 |
| Raw + Inter-mixing (30%) | 99.7 | 77.8 | 93.3 | 0.006 | 0.234 | 0.082 |
| Raw + Inter-mixing (20%) | 98.8 | 76.8 | 89.3 | 0.01 | 0.223 | 0.09 |
| Augmentation Method | Accuracy (%) | Loss | ||||
|---|---|---|---|---|---|---|
| Train | Valid | Test | Train | Valid | Test | |
| Raw data | 100 | 67.2 | 87.0 | 0.001 | 1.098 | 0.553 |
| (Raw+Dropout)/2 | 99.1 | 67.2 | 88.6 | 0.008 | 0.305 | 0.133 |
| (Raw+Intra-mixing (30%))/2 | 100 | 66.4 | 90.0 | 0.001 | 0.361 | 0.141 |
| (Raw+Intra-mixing (20%))/2 | 99.2 | 63.5 | 87.0 | 0.006 | 0.372 | 0.158 |
| (Raw+Inter-mixing (30%))/2 | 99.0 | 64.0 | 87.6 | 0.008 | 0.35 | 0.172 |
| (Raw+Inter-mixing (20%))/2 | 95.6 | 65.0 | 82.6 | 0.012 | 0.363 | 0.188 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-Y.; Lin, C.-Y.; Liu, Y.-T.; Chen, Y.-W.; Ng, H.-F.; Shih, T.K. TCN-MAML: A TCN-Based Model with Model-Agnostic Meta-Learning for Cross-Subject Human Activity Recognition. Sensors 2025, 25, 4216. https://doi.org/10.3390/s25134216
Lin C-Y, Lin C-Y, Liu Y-T, Chen Y-W, Ng H-F, Shih TK. TCN-MAML: A TCN-Based Model with Model-Agnostic Meta-Learning for Cross-Subject Human Activity Recognition. Sensors. 2025; 25(13):4216. https://doi.org/10.3390/s25134216
Chicago/Turabian StyleLin, Chih-Yang, Chia-Yu Lin, Yu-Tso Liu, Yi-Wei Chen, Hui-Fuang Ng, and Timothy K. Shih. 2025. "TCN-MAML: A TCN-Based Model with Model-Agnostic Meta-Learning for Cross-Subject Human Activity Recognition" Sensors 25, no. 13: 4216. https://doi.org/10.3390/s25134216
APA StyleLin, C.-Y., Lin, C.-Y., Liu, Y.-T., Chen, Y.-W., Ng, H.-F., & Shih, T. K. (2025). TCN-MAML: A TCN-Based Model with Model-Agnostic Meta-Learning for Cross-Subject Human Activity Recognition. Sensors, 25(13), 4216. https://doi.org/10.3390/s25134216