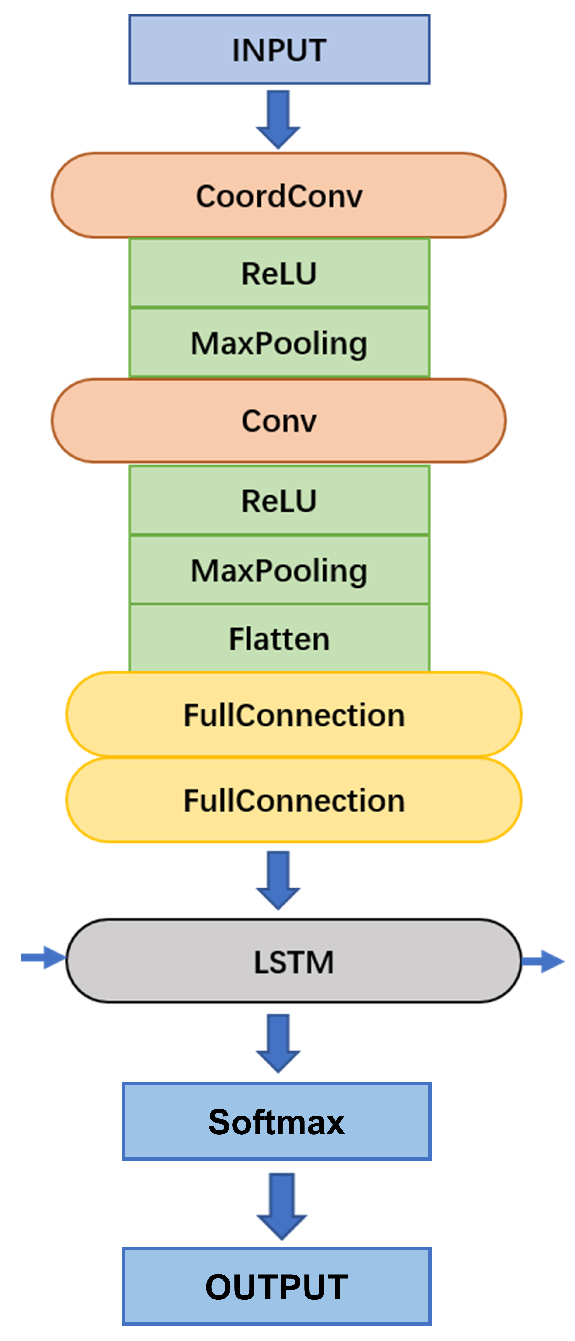
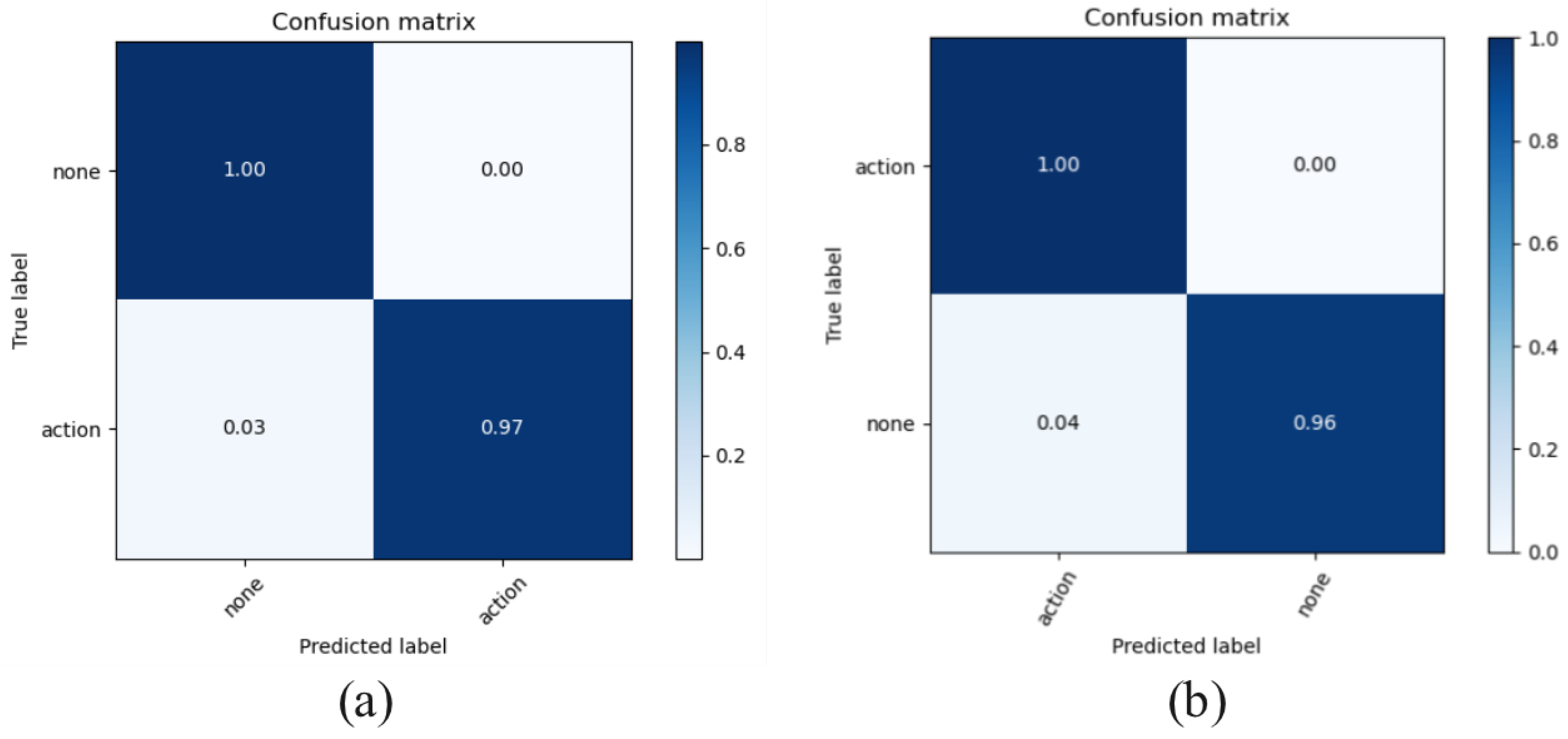
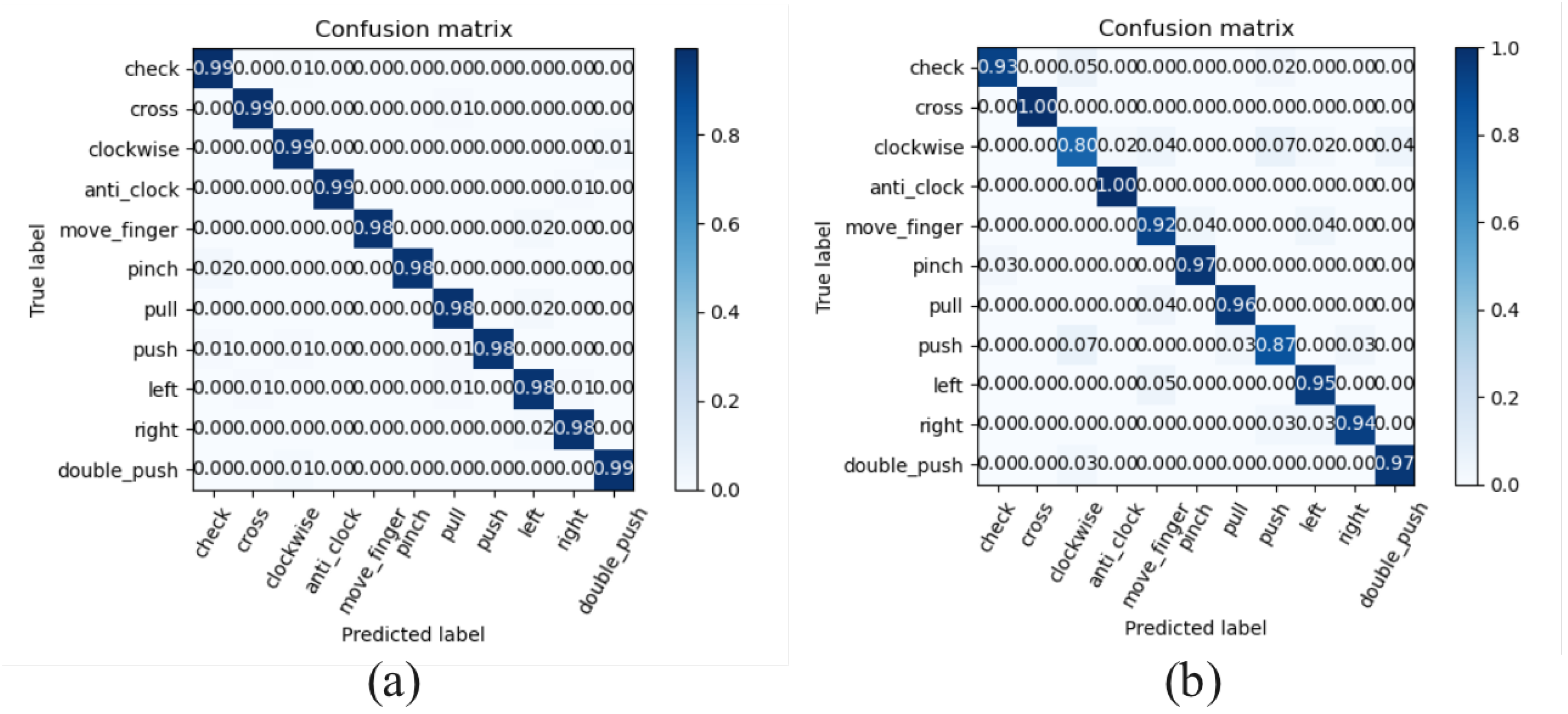
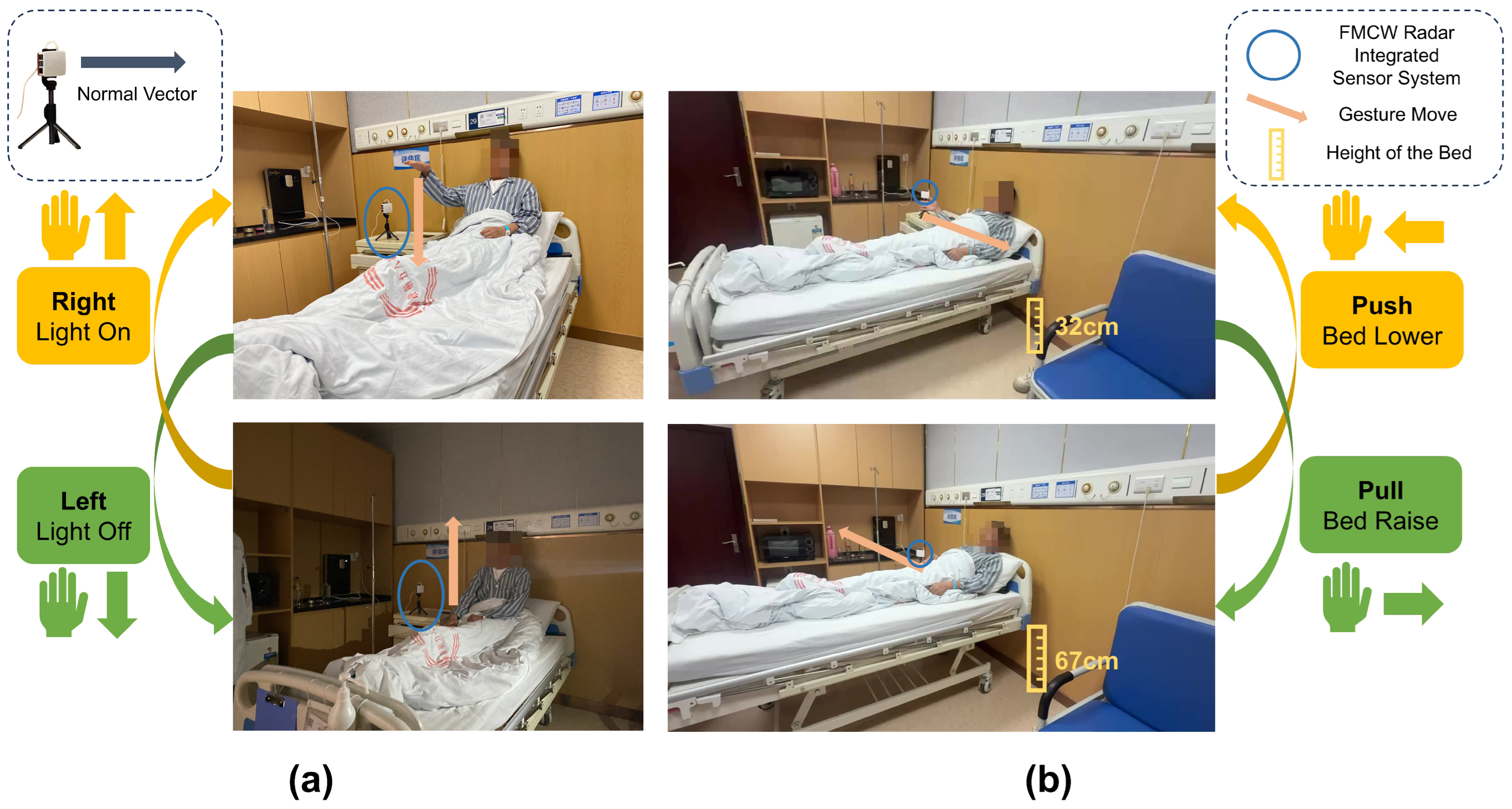
3.1.2. Signal Processing
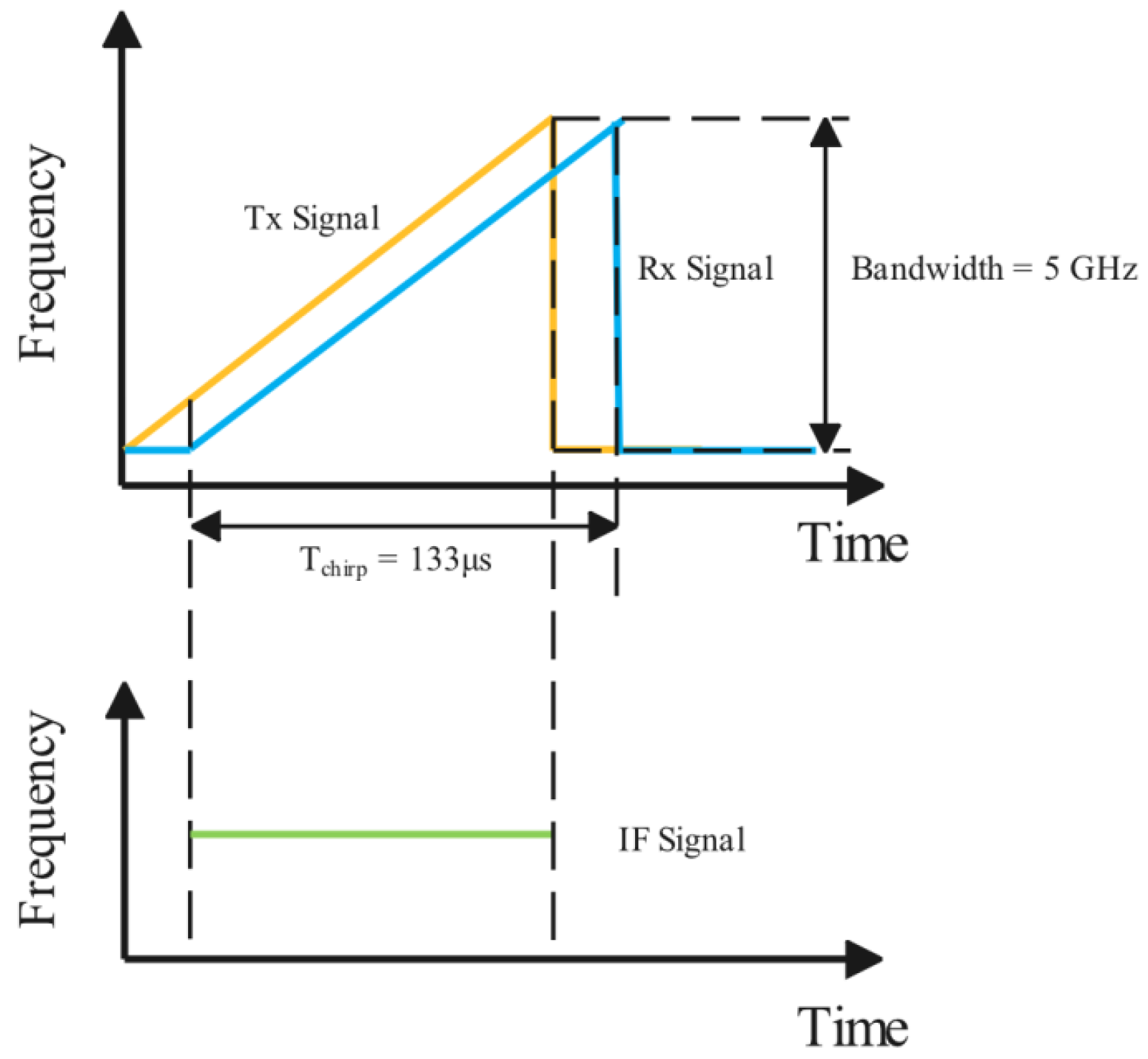
In FMCW radar, the transmitted signal is modulated by a set of sine waves with increasing frequency. In
Figure 5, by mixing the TX and RX waves, the IF signal is a sine wave with a certain frequency and phase. The frequency of the IF signal is proportional to the range of the object, and the phase change is caused by the relative velocity of the object to the radar. The FMCW waveform parameters govern the range and Doppler velocity resolutions, which can be optimized to enhance hand gesture detection. The resolution of range and Doppler
and
are listed as follows:
where
c is the speed of light, and
B is the bandwidth of the FMCW wave shown in
Figure 5.
is the wavelength of the radar.
is the chirp time, which is set to 128 μs, and
is the delay between the end of the last chirp and the start of the next. The sum of them is set to 505.64 μs and
N is the number of chirps in one frame is set to 32. The frame rate is set to 24 frames per second (fps) in order to meet the real-time requirement of hand-gesture detection.
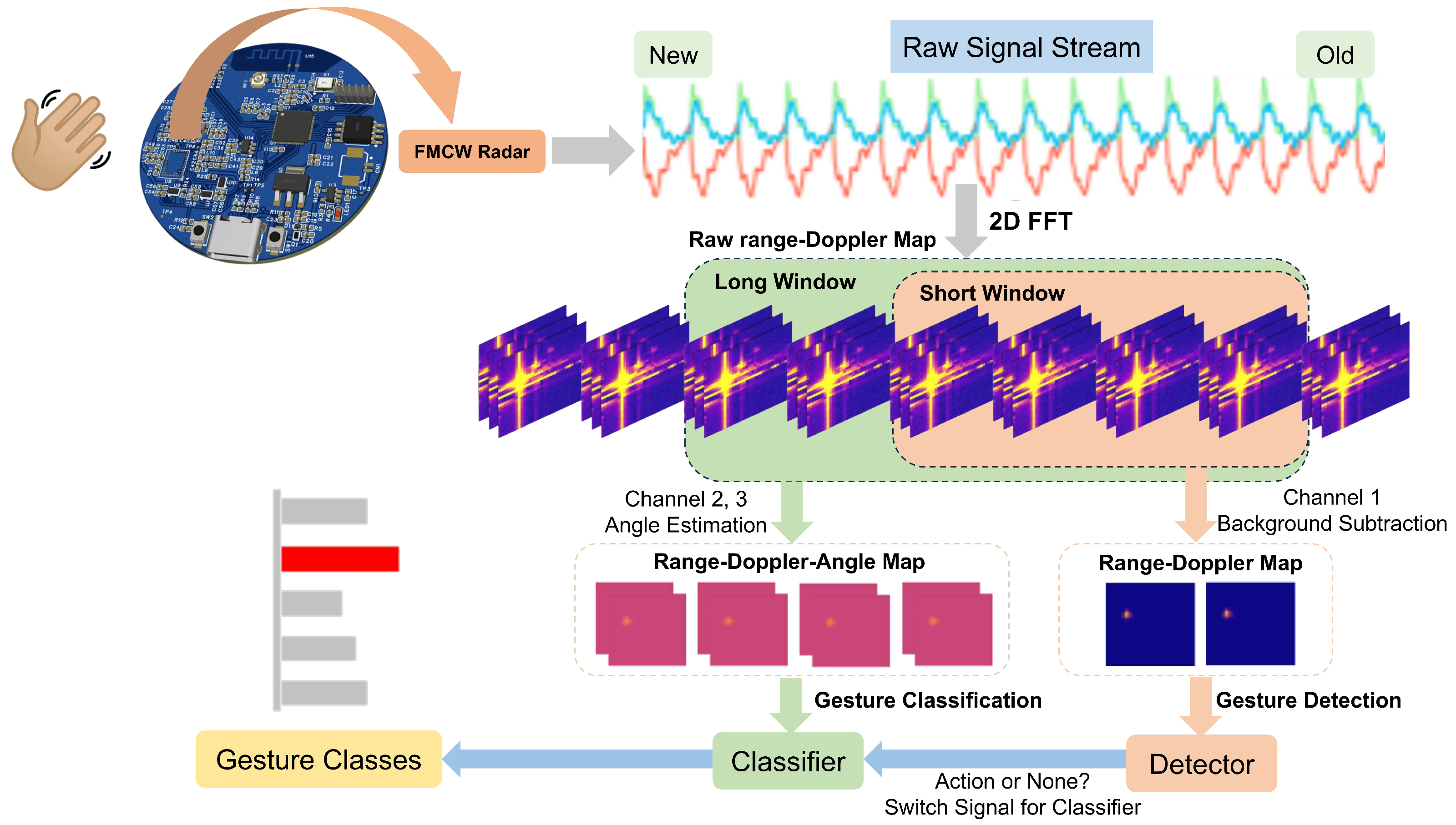
The signal processing pipeline for FMCW radar gesture recognition consists of three main stages as illustrated in
Figure 6: 2D FFT transformation, phase calibration, and clutter suppression. Each stage is essential for extracting accurate Doppler information from the multichannel radar data.
Calibration
The second stage of
Figure 6 illustrates the calibration process.
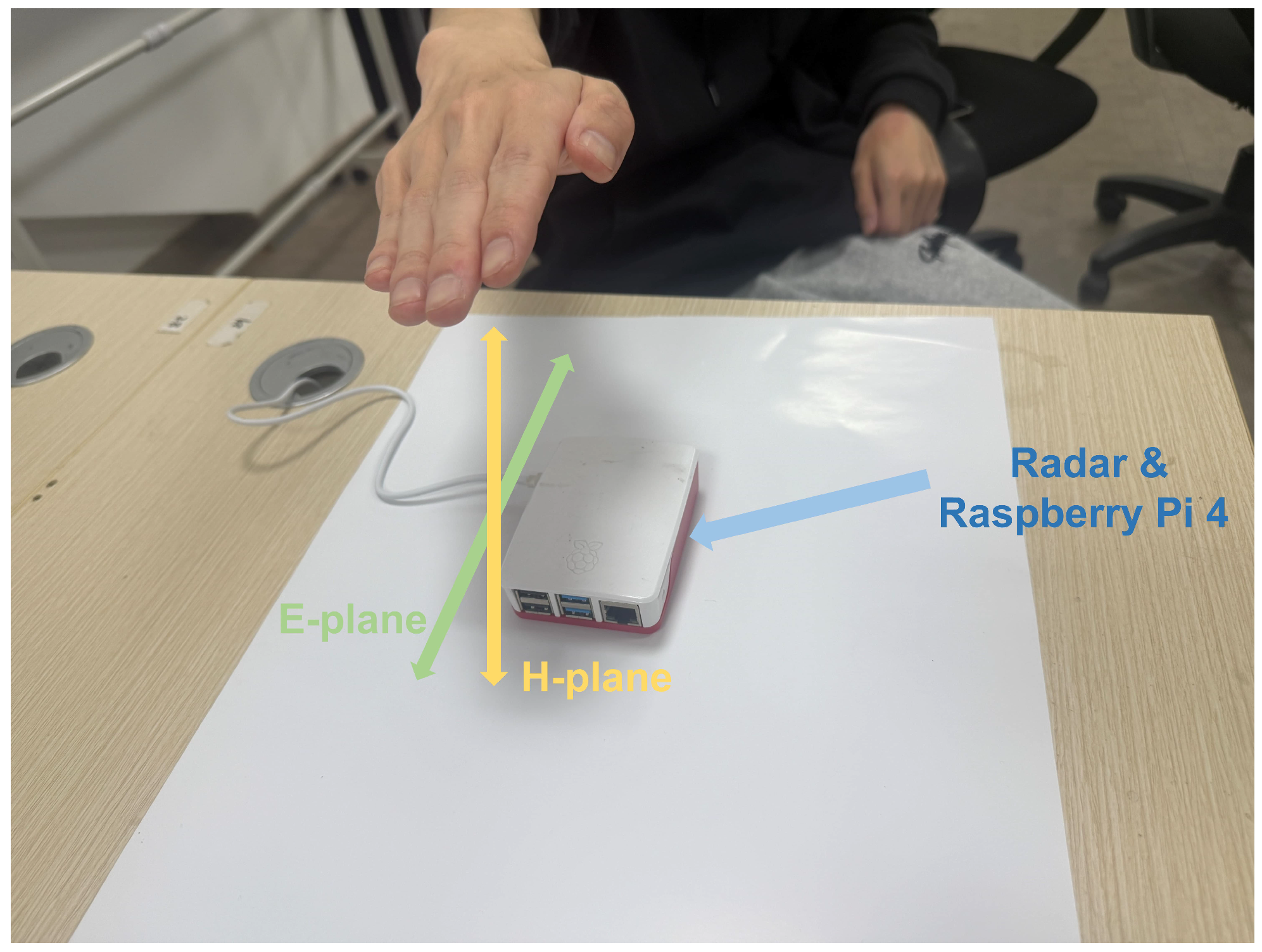
Figure 7 shows the range profiles of antennas Rx2 and Rx3 in the E-plane, with a target 0.5 m from the radar.
Figure 6a,b display the amplitude and phase before calibration, showing similar amplitudes but inconsistent phases due to incomplete electromagnetic shielding, which may cause errors in angle estimation without correction.
Figure 6c,d display the calibrated range profiles, where amplitude and phase align well at the corner reflector’s location after calibration.
Phase calibration assumes echo signals from a distant target in far-field conditions (target distance ≫ 5 mm wavelength at 60 GHz) are identical across channels when incident from the array’s normal direction, with equal amplitude and phase. A fixed phase offset between receiver antennas can be corrected using zero-degree calibration: place a corner reflector at boresight (zero-degree E-plane and H-plane) at a known distance, calculate the phase difference, and use it as a calibration matrix.
The calibration matrix should be a complex matrix
M with a shape
that can be applied to Rx2 and Rx3 complex data pairs
before angle estimation.
where
refers to the calibrated data pair.
The result shows that the amplitude and phase in each plane are well aligned at the location of the corner reflector after the calibration procedure.
Clutter Suppression
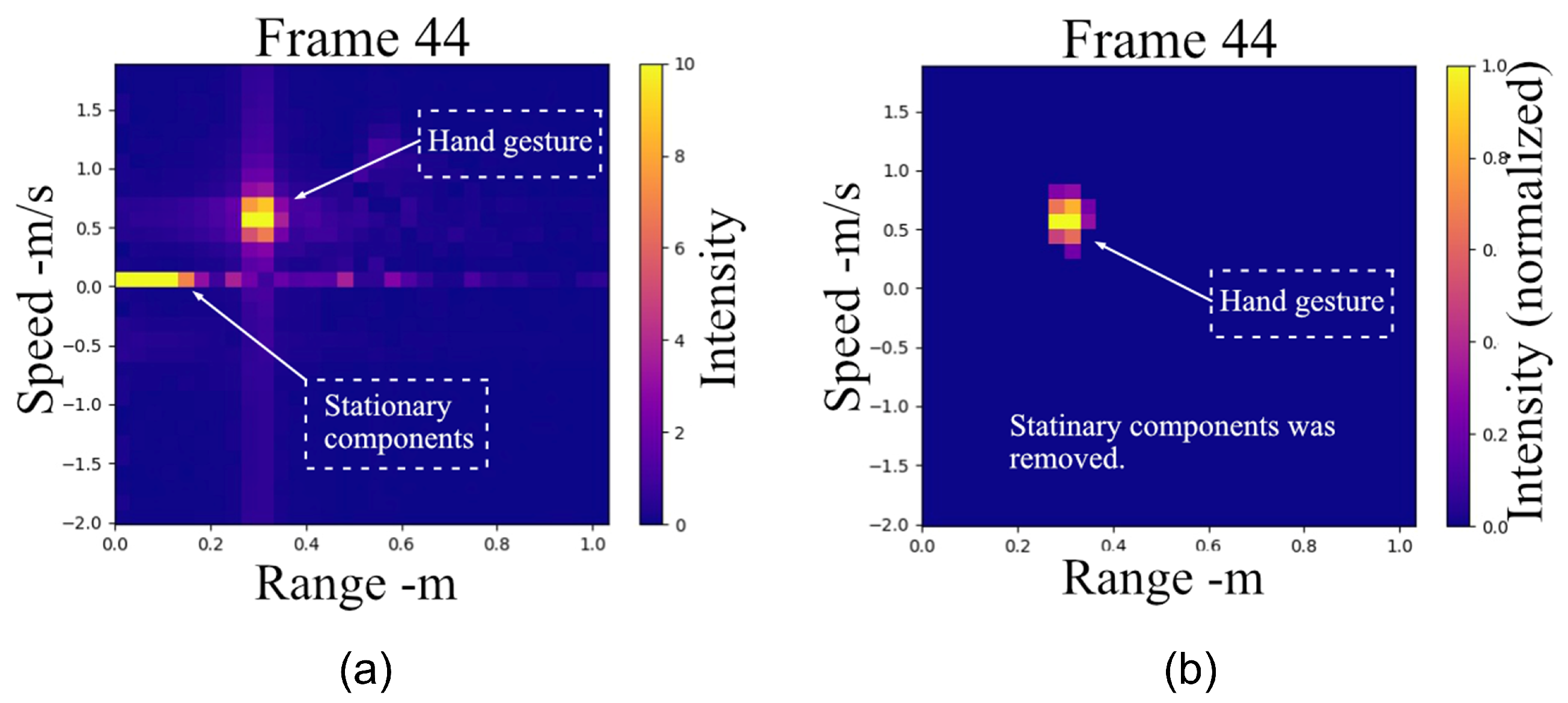
The final stage of
Figure 6 demonstrates the clutter suppression process. The RDM is a crucial representation that combines target range and Doppler frequency information, but it is often contaminated by clutter. Clutter can originate from various sources, such as ground reflections, stationary objects, or other unwanted echoes, which can mask the presence of moving targets and degrade the performance of target detection and identification. In the context of suppressing clutter in the range, and the Doppler map shown in
Figure 6, several methods have been developed to address this problem. One commonly used approach is the moving-target-indicator (MTI) technique, which exploits the fundamental difference between target and clutter characteristics. Clutter echoes typically exhibit much larger magnitudes than target echoes but possess zero or very low Doppler frequencies due to their stationary nature. In contrast, moving targets generate relatively high Doppler frequencies. The MTI method leverages this distinction by treating the time-averaged intensity of each pixel in the range-Doppler map as background noise. The clutter matrix can then be subtracted from the RDM with a scaling factor
. The resulting matrix
represents the RDM with MTI applied:
where
represents the historical average of the RD matrix. Another method widely adopted in computer vision tasks is the Gaussian Mixture Model-based background segmentation algorithm [
28,
29]. However, constructing a background model with Gaussian kernels is computationally expensive and challenging to meet real-time requirements.
Therefore, we propose a more efficient clutter extraction method based on adaptive weighting of static objects:
The normalized matrix
represents the temporal gradient of each pixel in the RDM between time
t and time
. By element-wise multiplying the
with the mean RD matrix calculated from a sequence of frames, static noise can be effectively removed since their corresponding weights in
approach zero due to minimal temporal variations. Essentially, this mask serves as an enhanced, adaptive version of the scaling factor
in the conventional MTI algorithm, providing pixel-wise weighting based on temporal changes rather than using a uniform scaling factor.
Figure 8 illustrates an example comparing the RDM before and after applying our method.
3.1.3. Multiple Feature Fusion
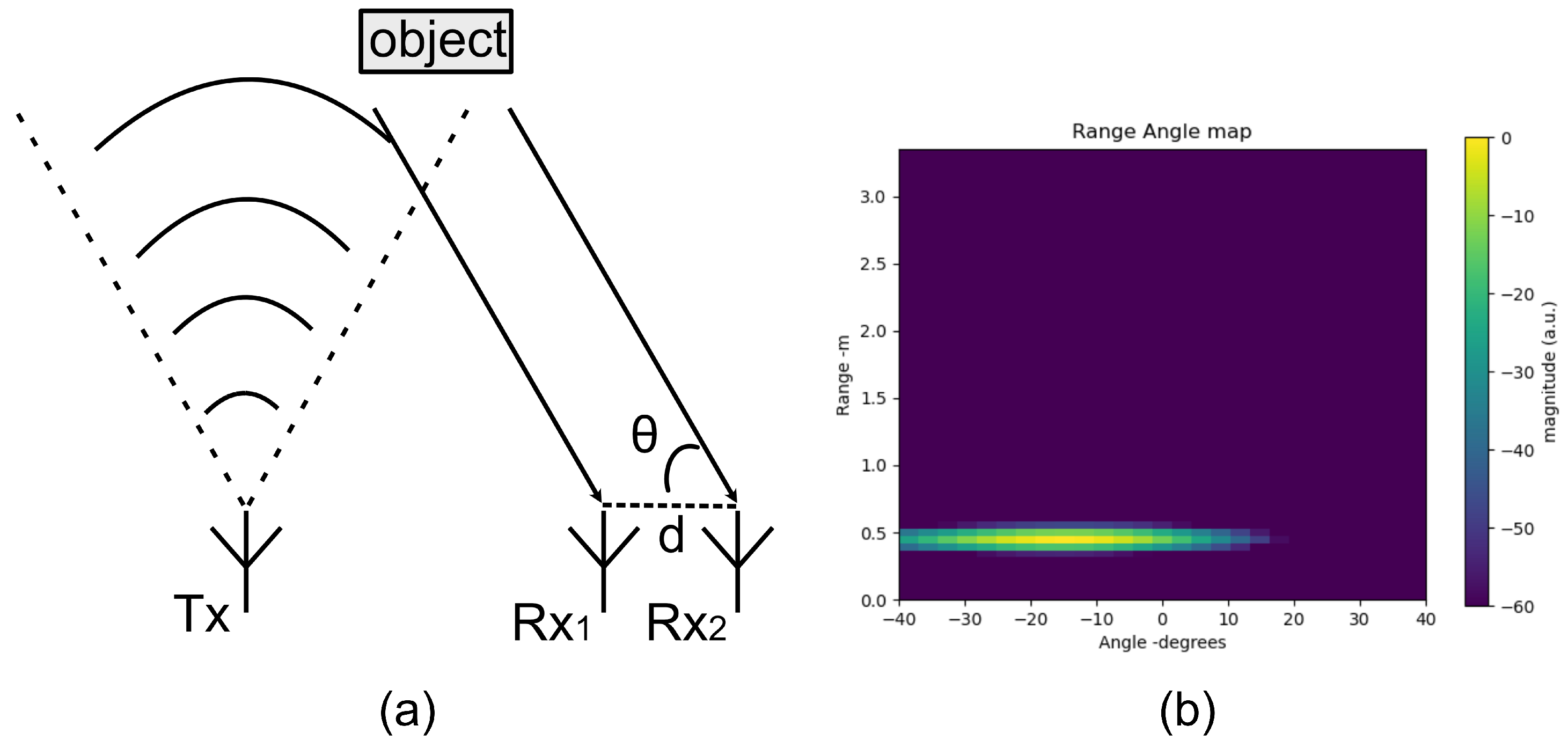
The principle of azimuth and elevation angle estimation with radar is similar to that of a stereo camera. By calculating the phase angle difference of points with the same position in the complex-valued range-Doppler map, the angle of arrival (AOA) of the object in azimuth and the elevation of object
j is listed from the phase difference of extracted points in the same positions of complex valued RD spectrums belonging to two receiving antennas as follows:
where
is the phase of a complex value,
is the
j-th complex value in range-Doppler from the
i-th receiving antenna.
In this paper, the space source signal is a narrow-band signal, the time required for the signal to pass through the array length is far less than the signal coherence time, and the signal envelope has little change in the antenna array propagation time. Assume that the signal carrier is
, in space, in the form of plane waves, propagating along the direction of the beam angle
, and the signal of the receiving antenna 1 is
, then the signal
at d for receiving antenna 2 is
where
is the delay time from antenna 1 to antenna 2, which can be ignored here
d is the distance of the receiving antennas, and
is the wavelength.
Therefore, the matrix signal is expressed as follows:
where
M is the number of receiving antennas, and
is the desired direction.
And the desired direction is expressed by the complex matrix as
The principle of digital beam forming is to stack signals in a certain direction in the same phase at the receiving end, so as to form a narrow beam in the target direction to improve the beam pointing ability in a certain direction.
Compared with classical subspace-based DOA estimation methods, such as the Music algorithm and the ESPIRT algorithm, the DBF method requires less computation and has higher robustness for fewer antenna arrays. In
Figure 9, the two antennas mentioned specifically refer to Rx1 and Rx2. These two receive antennas are used to illustrate the calculation of the angle in the E-plane. For the angle calculation in the H-plane, Rx2 and Rx3 are employed based on the same principle. Due to space limitations, the details of the H-plane calculation are not repeated here.
In some recent works, the researchers have tried to represent the spatial information as the Angle-Time Map (ATM) [
8,
30]. As multiple channels, these spatial feature maps will be fed into various feature extractors, for instance, a CNN-based network. The spatial information was utilized in these methods to replace one dimension of RDM. However, the methods of expressing the temporal information integrated from the perspective of image recognition (adopting the idea of image recognition) require a fixed time length, which is a significant obstacle for practical applications.
This paper considers the impact of varying action length (action complexity, motion speed, duration, etc.) by decoupling spatial information from temporal information and excluding temporal information from the feature map. For each frame of the radar signal, the current gesture angle is expressed in the form of a Range-Angle Map (RAM). Spatial information is represented by a continuous time series of frames.
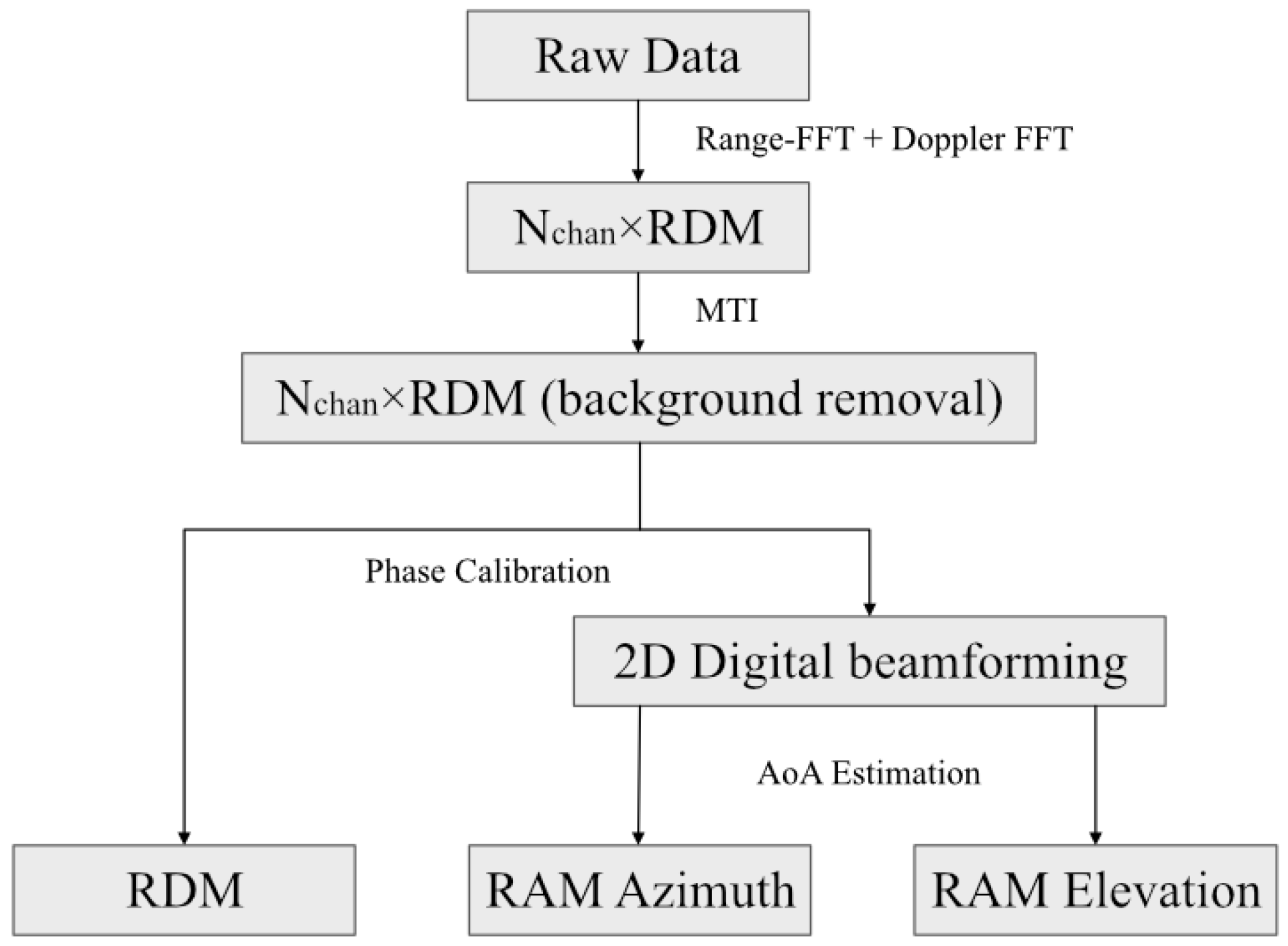
The procedure to extract spatially continuous multidimensional gesture features in this paper is summarized in
Figure 10. First, the
are calculated frame by frame from the raw radar data based on range-FFT and Doppler-FFT. The clutter extraction method, MTI, mentioned above, is applied to obtain background noise removal RDM. Prior to angle information estimation, the phase noise between each receiving antenna is precisely calibrated as described earlier to obtain better target angle information, which is of significant importance for sensing subtle and accurate gestures. In the zenith angle plane and in the azimuth angle plane, a 2D digital beamforming method is used to compute the AoA signal, respectively.
Generally, target detection can be implemented in the range Doppler domain or range–angle domain. In this article, the range Doppler domain is mainly used rather than the range–angle domain because the Doppler resolution is high, which helps sensing a target located in different positions and with different velocities. However, the angular resolution is very low for the used antenna array, which is not enough to resolve accurate information in the angular dimension. However, for many gestures with similar motion trajectories, such as left swipe and right swipe, their corresponding RDMs show the same process of the distance changing from large to small and then back to large, and the speed changing from negative to positive. It is difficult to distinguish these gestures solely based on the change in distance and speed. At this time, the help of angle information is indispensable and plays a critical role in assisting judgment.
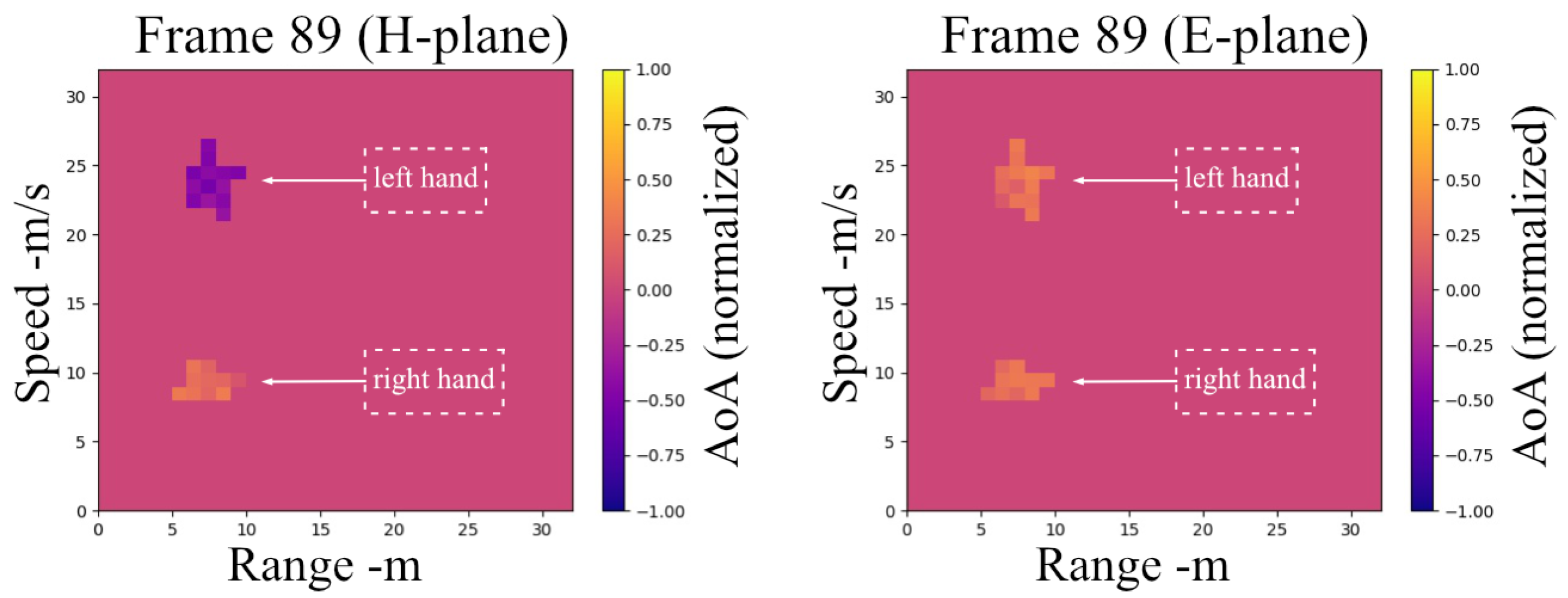
As a consequence, for every frame of radar data, the data are organized into tensors with three components, as cube-
, including the following: range-Doppler, range-angle (E-plane), range-angle (H-plane) (
Figure 11), as depicted in
Figure 12. The cube has dimensions as
, where N stands for range bins, M for Doppler samples/angle samples, and 3 for the three-dimensional attributions. Each element of the cube can be described as follows:
where
and
.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}