1. Introduction
The use of personal protective equipment (PPE) by electrical workers plays a crucial role in ensuring the safety of workers during electrical operations and maintaining the normal operation of the power grid. The work environment for live-line workers is highly hazardous. According to a report by the U.S. Occupational Safety and Health Administration (OSHA), there were 1254 live-line work accidents involving 1399 workers in the United States between 2010 and 2022. Among these, 817 were injured, and 582 workers died (a fatality rate of 41.6%) [
1]. This not only poses a threat to workers’ lives but also causes immeasurable losses to the power supply system. However, even after relevant departments provide safety training to live-line workers, violations may still occur due to subjective and objective factors [
2,
3]. Therefore, an external supervision method is needed to confirm whether personnel are properly wearing protective equipment, thereby reducing the safety hazards associated with live-line work.
Currently, personnel equipment detection primarily relies on sensor-based and image-based methods. Sensor-based detection is divided into traditional PPE detection and intelligent PPE detection. Traditional PPE detection includes scanning radio frequency identification (RFID) tags attached to personal protective equipment using RFID technology [
4,
5,
6,
7] and detecting the wearing status of equipment by workers using pressure [
8] or human body sensors [
9]. Intelligent PPE detection can monitor physiological parameters, environmental conditions, and potential hazards, providing workers with real-time feedback and early warning systems [
10]. Examples include an intelligent platform for workplace safety using the Jetson-based monitoring of environmental variables in the workplace [
11], a safety monitoring system using a Raspberry Pi (Sony UK TEC, Pencoed, UK) to monitor individuals’ physiological parameters and environmental conditions [
12], and the construction of a dataset of skeletal information to determine risky behaviors using the ST-GCN algorithm [
13]. However, the actual deployment effectiveness of these systems in power work environments remains to be verified, especially given the limited signal transmission range during high-altitude operations and the susceptibility of communication devices to interference in high-electric-field environments. Additionally, sensor-based methods incur high costs in terms of installation and maintenance [
14] and have low detection efficiency (a single set of equipment can only be applied to a single worker, requiring multiple sets for multi-person operations).
In contrast, visual-based methods use cameras to record images or videos of the work site, which are then analyzed to verify PPE compliance. This approach provides richer information about the scene, enabling a faster, more accurate, and comprehensive understanding of complex construction sites [
15]. Traditional visual method examples include, but are not limited to, video-based monitoring methods that use facial features, motion, and color information [
16], image-based edge detection [
17], and directional gradient histogram (HOG) methods [
18] to detect safety helmets. Other examples use HOG-based features and machine learning algorithms, such as support vector machines (SVM) [
19] and k-nearest neighbors (kNN), to detect whether a person is wearing a safety vest [
20].
Recent advances in deep learning have facilitated the application of convolutional neural networks (CNNs) and object-detection models for PPE detection. Existing studies contain approaches based on improved target detection algorithms, such as Faster R-CNN and different variants of the YOLO family (including YOLOv5-CBAM-DCN, YOLOX, and optimized YOLOv7, etc.) in [
21,
22,
23,
24,
25]; and, secondly, detection systems incorporating post-processing show enhanced utility such as the fusion of pose detection to recognize offending movements, etc. [
26]; in addition, some innovative approaches such as multi-task learning frameworks and graph neural networks provide new solutions for small-sample scenarios and specific protective equipment detection [
27,
28]. These studies not only promote the development of protective-equipment-detection technology but also provide important references for model selection and optimization in practical applications [
14,
29].
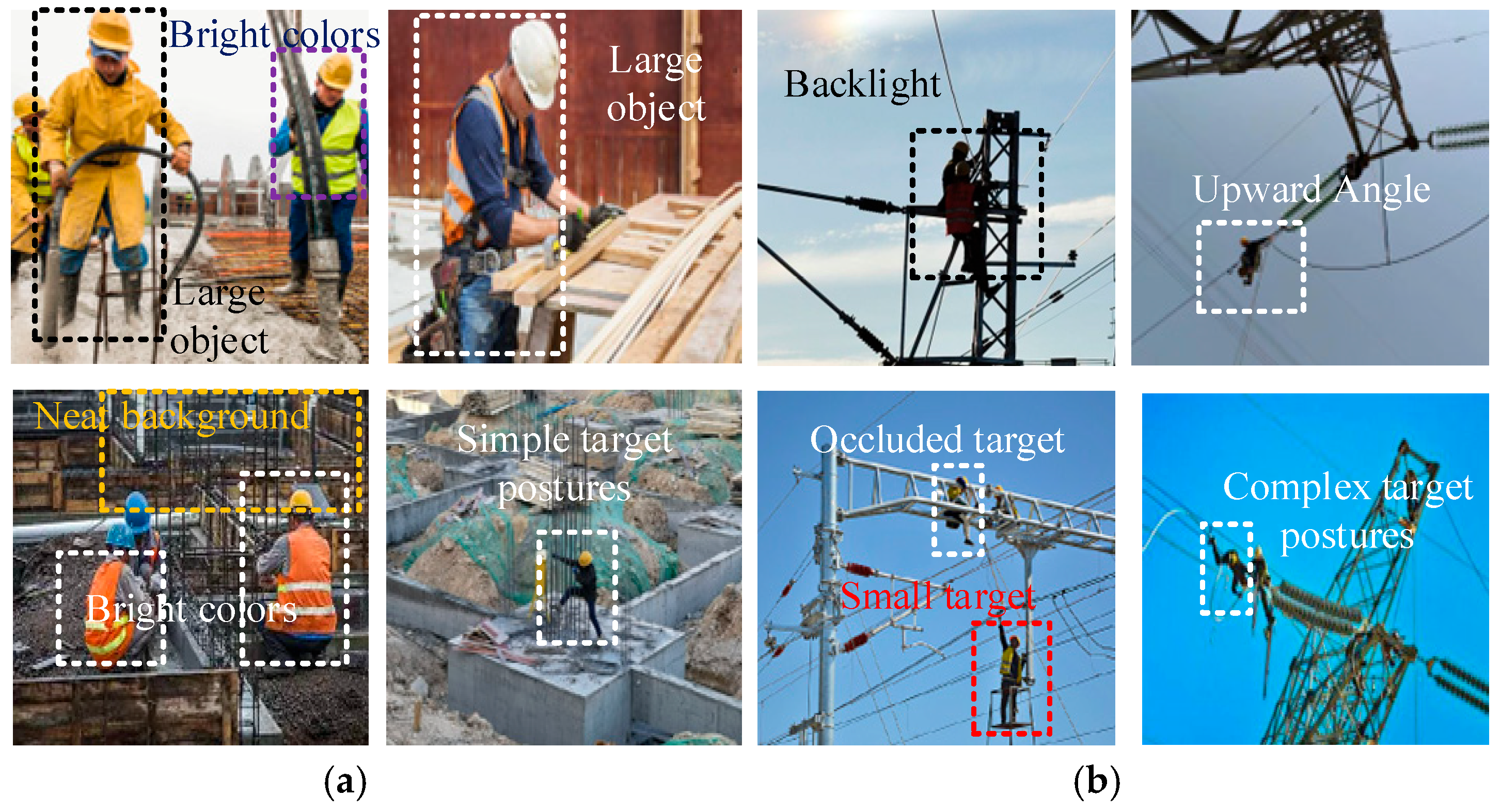
However, a major limitation of existing research is the insufficient attention paid to the detection of personal protective equipment (PPE) in the power industry. This sector typically involves outdoor working conditions, high altitudes, and exposure to environmental complexity and equipment variability. Most models are developed and validated in relatively controlled environments or using generic PPE datasets, which limits their applicability in power engineering environments. As shown in
Figure 1, PPE detection in power operation scenarios differs significantly from that in general construction environments. Images are typically taken from overhead or downward angles, with workers being small targets with complex postures and backgrounds often containing elements such as power towers and cables. This makes traditional PPE-detection models unsuitable for PPE identification in the power industry.
There also exist PPE-detection methods applicable to the power industry (including scenarios such as work-at-height and power operations), such as PPE-detection models for work-at-height based on the UAV perspective [
30,
31] and PPE-detection based on high-voltage scenarios [
32]. Other similar studies such as the detection models of safety equipment applied to construction sites working at a height [
33,
34] and a variety of high-risk scenarios, such as high-altitude work zones, power chemical, and tunnel underground work [
35], also provide research ideas for PPE detection in the power industry. These methods perform well in the scenarios they address but are limited by the number of targets they focus on (according to the China Electric Power Construction Safety Work Procedures, high-altitude workers must wear safety helmets, insulated clothing, etc., in addition to safety belts; according to the US NFPA 70E (US Electrical Safety Standard) [
36], rubber insulated gloves and sleeves, insulated boots, hard hats, safety goggles/masks, etc., are explicitly required in arc hazard zones. Therefore, the aforementioned object-detection systems are not well-suited for practical applications) are relatively limited [
30,
31,
32,
33,
34], their effectiveness in other high-altitude work environments (such as power tower maintenance or bridge construction) has not been thoroughly validated [
35], and no practical method has been proposed to effectively address these applications. Therefore, it is necessary to develop a PPE detection model specifically tailored to power operation scenarios, which should have the following characteristics: 1. applicable to power operation scenarios, 2. capable of detecting multiple types of safety protective equipment, 3. capable of meeting real-time detection requirements.
In this work, we introduce the concept of Power Engineering Personal Protective Equipment (PEPPE) detection and propose a novel model—Multi-scale Re-Calibration Detection Transformer (MRC-DETR)—tailored to the operational characteristics and safety requirements of power environments. Building on the DETR architecture, MRC-DETR incorporates structural enhancements to improve its ability to detect small objects, handle occlusions, and identify various PEPPE items under dynamic and high-risk conditions. Our model achieved good accuracy and detection performance based on the PEPPE dataset, as shown in
Figure 2.
The main contributions of this work can be summarized as follows:
1. We designed a Multiscale Enhanced Boundary Attention (MEBA) module that optimizes the model’s feature representation by integrating multi-scale features, significantly improving the model’s ability to represent small and occluded targets in complex scenes.
2. We proposed the Multi-scale Re-Calibration Detection Transformer (MRC-DETR), which uses knowledge distillation methods to improve the performance of lightweight models for real-time detection in resource-constrained environments.
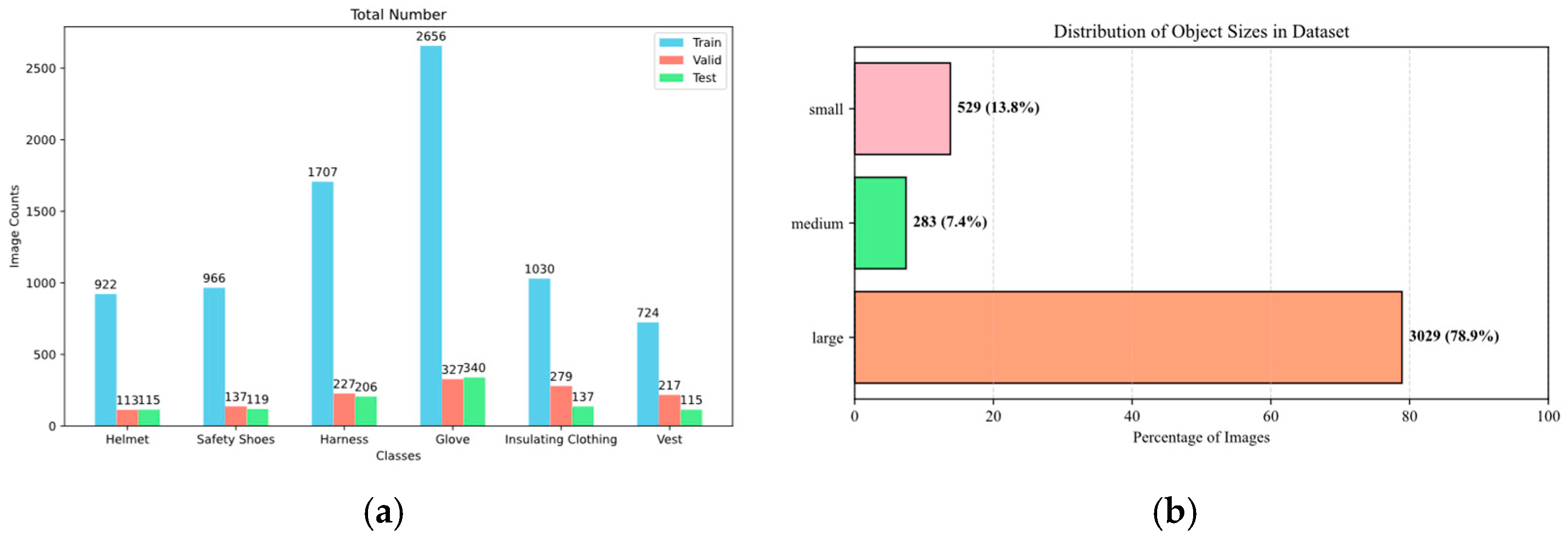
3. We established a PEPPE dataset focused on personal protective equipment for electrical engineering, which includes multiple types of personal protective equipment for electrical engineering. Finally, we deployed the optimized model on edge devices to achieve real-time PEPPE detection in electrical work scenarios, laying the technical foundation for future practical applications.
3. Method
The design objective of MRC-DETR is to significantly reduce the computational overhead while maintaining model detection accuracy, thereby enabling the efficient real-time detection of PEPPE. The model aims to enhance feature extraction and fusion capabilities, particularly addressing the challenges of detecting small and occluded objects in complex environments, such as high-altitude operations and power maintenance. To achieve this goal, MRC-DETR balances accuracy and lightweight design in its structural design, driven by the following two key design motivations:
1. MRC-DETR achieves the efficient aggregation and enhancement of features at different scales by constructing a multi-level backbone network based on the Moga-CSP module and a feature fusion structure (MRC-Fusion Encoder) incorporating the Multiscale Enhanced Boundary Attention (MEBA) module. The MEBA module enhances the model’s perception of small and edge objects in complex backgrounds through a multi-scale boundary enhancement strategy, significantly improving the feature representation quality.
2. Given the resource constraints on deployed devices in power operation environments, MRC-DETR introduces a distillation mechanism to transfer knowledge from a more complex and accurate teacher model to a lightweight student model. The distillation process employs a dual strategy combining feature-based knowledge distillation and logit-based distillation, enabling the student model to maintain detection performance close to the teacher model while offering advantages in inference speed and resource consumption.
3.1. Model Structure Design
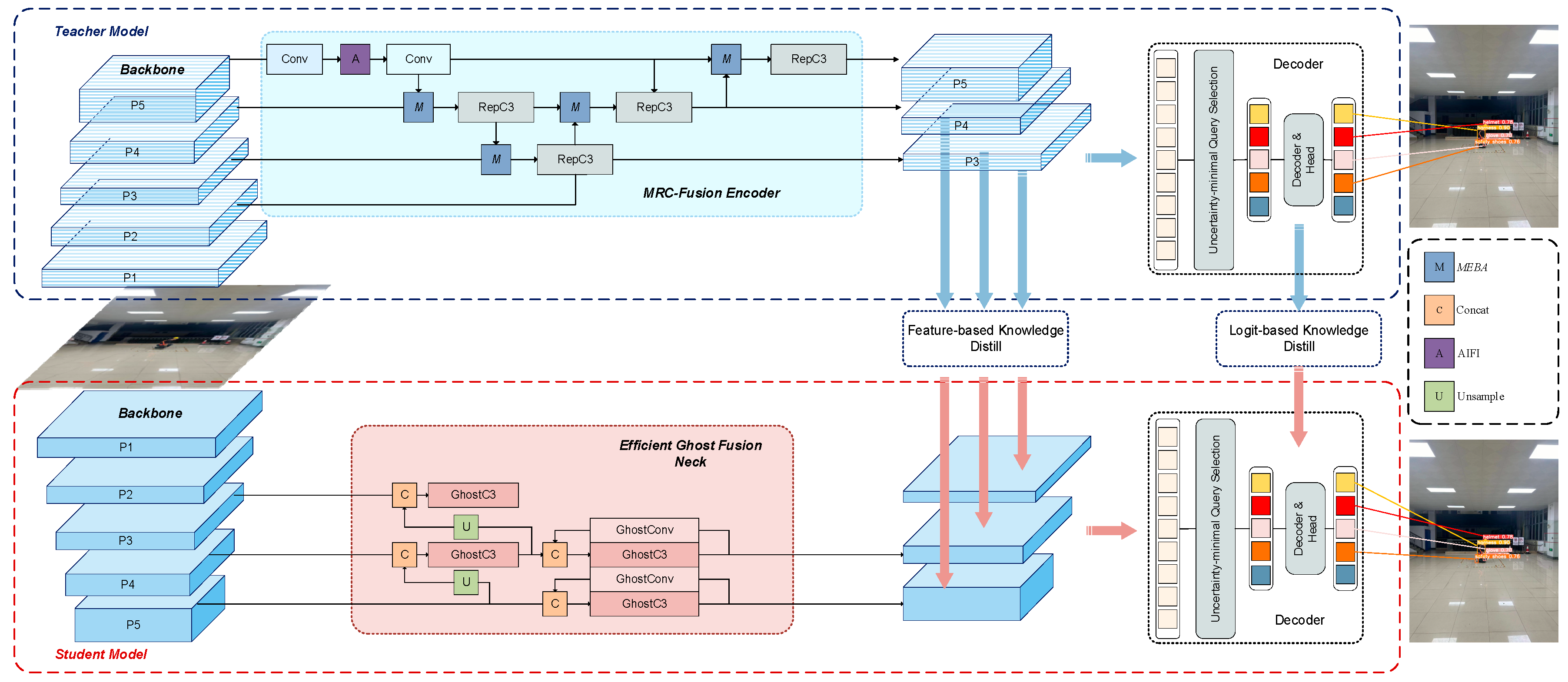
The overall structure of MRC-DETR is shown in
Figure 3. MRC-DETR adopts a teacher–student architecture to improve the PEPPE detection performance in complex power operation scenarios. The teacher model constructs the MRC-Fusion Encoder, which combines a multi-scale feature enhancement module (MEBA), an AIFI attention mechanism, and a deep convolutional module (RepC3) to strengthen the expression capabilities of small objects and boundary information. The multi-scale features outputted are not only used for final decoding but also transferred to the student model through feature-level and logit-level knowledge distillation, guiding it to learn more precise feature representations.
The student model adopts a lightweight design, embedding the Efficient Ghost Fusion Neck, which uses the Ghost module for efficient feature reconstruction and fuses multi-scale features to adapt to resource-constrained scenarios. Although MRC-DETR adopts a distillation network framework, resulting in a seemingly large and complex model, only the small “student” network is deployed on the terminal device. This approach ensures the efficiency and accuracy of the final model.
3.1.1. Backbone
Power Engineering Personal Protective Equipment detection requires high accuracy in identifying details and boundaries, high accuracy in identifying equipment locations, and strong adaptability to complex backgrounds. The model must balance local details and the overall structure under different lighting conditions and angles to ensure the accuracy of target identification while maintaining robustness in complex visual environments.
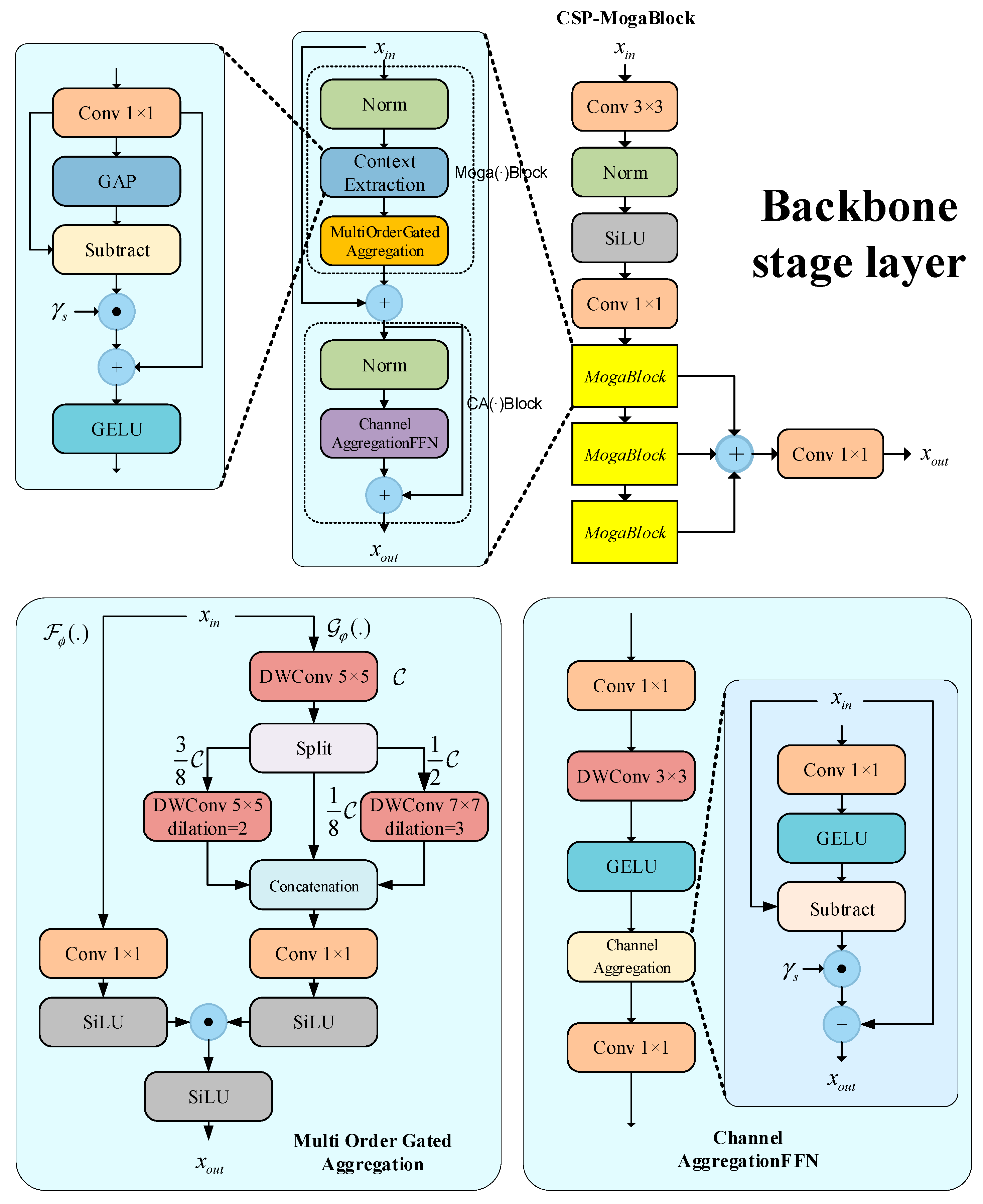
The proposed backbone network effectively captures multi-scale, multi-order features through its hierarchical structure. As shown in
Figure 4, the backbone consists of multiple Layer Stages, each containing a convolutional module (3 × 3 convolution, BatchNorm, and SiLU activation function) and a CSP-MogaBlock. Each CSP-MogaBlock comprises three Mogablocks, enabling the network to progressively extract and contextualize features at different resolutions and scales.
The structure of Mogablocks is divided into gated aggregation units and channel aggregation units. In the gated aggregation units, the feature decomposition module (FD) is used to extract local and global features:
Among them,
FD(
·) is a feature decomposition module, and
Moga(
·) is a multi-order gate aggregation module, including gate
Fφ(
·) and context branch
Gψ(
·). In order to force the network to focus on multi-order interactions,
FD(
·) can be used to dynamically exclude trivial interactions.
In this context,
γs is the scaling factor, and GAP(·) denotes global average pooling. This module enhances feature diversity through reweighted complementary interactions. To capture features at different scales, three parallel deep convolutions with different expansion rates are used for high-, medium-, and low-level features, respectively. The output features of these convolutions are concatenated into a multi-scale feature map
YC. The gated aggregation mechanism uses the SiLU activation function to adaptively fuse features, and the final output is as follows:
The channel aggregation module (CA) is used to enhance feature interaction between channels. It includes channel normalization, multi-scale depth convolution, and channel mixing mechanisms:
CA(·) is defined as follows:
where
γc is the channel scaling factor. Each stage of the backbone consists of multiple Moga Blocks and a channel aggregation block. This structure enables the network to extract features at different scales in a hierarchical manner. The output of each stage is downsampled and fed into the next stage for further processing.
On this basis, CSP-MogaBlock, as an extension to MogaBlock, refers to the design idea of a CSP module and contains multi-layer stacked MogaBlock modules in its structure, to realize deeper feature transfer and more effective parameter sharing. In the forward propagation process, CSP-MogaBlock contains three Moga-Block modules; then, the final output is x = C2f(x, M1, M2, M3), where Mi is the i-th MogaBlock.
3.1.2. Fusion Encoder
The MRC-Fusion Encoder is a key component of MRC-DETR, designed to enhance the model’s ability to perceive small and occluded objects in complex scenes through multi-scale feature fusion. This module stacks multiple RepC3 units for deep feature extraction while introducing skip connections between different scales to enhance the transmission and fusion of semantic information. To further improve the recognition accuracy in boundary regions, we designed a Multiscale Enhanced Boundary Attention (MEBA) module, which performs the fine-grained modeling of low-level (L), medium-level (M), and high-level (H) features. Through an attention mechanism, it dynamically adjusts the fusion weights of these features, thereby strengthening the feature expression capabilities in boundary-sensitive regions. This fusion strategy not only improves the overall detection performance but also provides a more distinctive feature foundation for subsequent knowledge distillation.
The MEBA Module Structure Diagram is shown in
Figure 5. The MEBA includes several multiple recalibration attention unit (MRAU) blocks that adaptively extract mutual representations from three inputs (I1, I2, and I3) before fusion. As shown in
Figure 1, shallow, mid-level, and deep-level information are inputted into the three MRAU blocks in different ways to compensate for the missing spatial boundary information of high-level semantic features and the missing semantic information of low-level features. Finally, the outputs of the three MRAU blocks are concatenated together after 3 × 3 convolution. This aggregation strategy achieves a robust combination of multiple features and refines the rough features.
The functional process for MRAU blocks can be represented as follows:
In this module, T1, T2, and T3 represent three input features at different scales. We employ three learnable linear mapping functions, Wα, Wβ, and Wγ (implemented as 1 × 1 convolutions), to compress the channel dimensions of the input features to 32, thereby generating corresponding attention feature maps. The Sigmoid function is used to produce attention weight maps, while the ⊙ symbol denotes element-wise multiplication.
The notation ㊀(T1′) represents the inversion of the attention map, which serves to emphasize background regions or suppress specific areas. Through the differential operation on feature T1, more refined and complete prediction results can be extracted from the coarse initial estimation.
In this process, the 1 × 1 convolution is treated as a linear mapping operation. All parameters, Wα, Wβ, and Wγ, are trainable parameters within the network and are automatically optimized during model training, thus eliminating the need for the manual setting of weight coefficients α, β, and γ. Thus, the MEBA output can be represented as Z = C3×3(Concat((k1, k2, k3)), where ki = MPAUi(F1, F2, F3), and C3×3 is the 3 × 3 convolution with batch normalization and the ReLU activation layer. F1, F2, and F3 are three different dimensional features in the backbone. This multi-scale feature aggregation and recalibration mechanism enables MEBA to accurately identify and localize the safe wearing of power equipment, which significantly improves the detection performance.
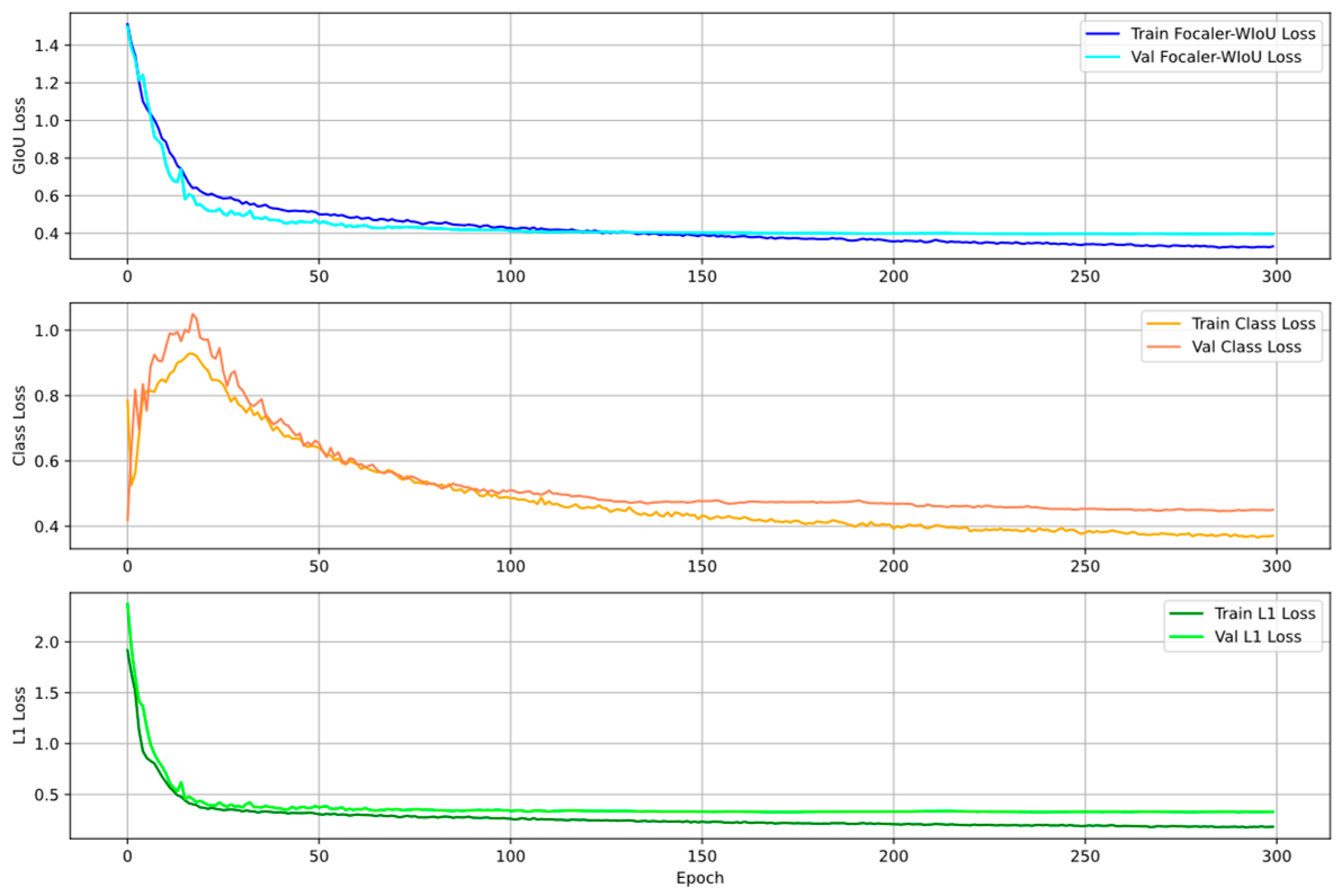
3.2. Loss Function
In the real world, the working background of electric workers exists in the field environment, and this complex environment often leads to the degradation of the bounding box localization ability for target detection. Therefore, we introduce Focaler-WIoU as the loss function of MRC-DETR, aiming to improve the model’s ability to focus on difficult samples, and at the same time, not to let the model “count” too much in the low-quality bounding box regression.
The WIoU (Wise IoU) loss function aims to improve object-detection performance by adjusting the gradient gain of the anchor frame, especially in complex environments such as grid operations, dealing with occlusions, and small objects in images. In WIoU, the quality of the anchor frame is described using outliers, where smaller outliers indicate higher quality. The authors assign smaller gradient gains to anchor frames with lower outliers to focus the bounding box regression on anchor frames of medium quality. Smaller gradient gains are assigned to anchor frames with larger outliers, thus effectively preventing low-quality samples from generating significant detrimental gradients. The formula is calculated as follows:
Among them, β is defined as the outlier degree to describe the quality of the anchor box, and δ and α are both adjustable parameters used to control the outlier degree. RWIoU ∈ [1, e) significantly amplifies the LIoU for anchor boxes of average quality. LIoU ∈ [0, 1] significantly reduces RWIoU for high-quality anchor boxes. It also reduces attention to the center-point distance when anchor boxes overlap well with object boxes.
However, WIoU is deficient in dealing with the distribution of hard and easy samples and cannot pay sufficient attention to hard-to-detect samples. To address this problem, we introduce Focaler-WIoU inspired by Focaler-IoU. Focaler-IoU effectively improves the performance of the model in different detection tasks by paying more attention to hard samples. Focaler-WIoU, on this basis, dynamically adjusts the gradient gain of the samples to prioritize hard samples while taking care of the easy samples, thus realizing a more balanced and effective training process. This improvement enables Focaler-WIoU to significantly improve the detection accuracy and robustness in complex environments, especially in scenes with many occlusions and small targets.
The formula of Focaler-WIoU is as follows:
where
IoU is the original IoU value and [
d,
u] ∈ [0, 1]. By adjusting the values of
d and
u, we can make IoU-focaler focus on different regression samples.
3.3. Knowledge Distillation
In the real world, devices such as surveillance cameras, drones, etc., are often used to monitor the wearing of PPE by power personnel in real time; however, specialized computing devices such as graphical processing units, tensor processing units, and high-performance computing clusters are rarely available, so deploying an object-detection model is challenging. Inspired by knowledge distillation techniques, we use a hybrid distillation approach to reduce network parameters to facilitate deployment on resource-constrained devices with a two-part strategy: (1) logic distillation and (2) feature distillation.
3.3.1. Logic Distillation
Logic distillation focuses on aligning the student model with the teacher model’s output predictions. This approach is particularly well suited for target detection tasks because it allows the student model to mimic the teacher model’s predictions in terms of classification and localization.
Logic distillation loss consists of the following three components:
Categorical Loss
Lcls: a binary cross-entropy loss was used to measure the similarity of categorical predictions between the student and teacher models, treating the categorical predictions of the teacher model as soft labels and encouraging the class distributions of the student model to be close to them.
where
σ denotes the Sigmoid function and sscore and tscore are the predicted scores of the student and teacher models, respectively.
Boundary box L1 loss
LL1: The L1 loss was used to measure the difference between the student model and the teacher model bounding box predictions. This loss guides the student model to more closely approximate the bounding box output of the teacher model.
IoU loss
LIoU: To capture the IoU differences in bounding box predictions between student and teacher models, generalized IoU (GIoU) loss is used. This helps the student model to align with the bounding box of the teacher model in terms of location and shape.
Combining the above three losses and setting the weighting factors
α,
β, and
γ, respectively, the final logical distillation losses are as follows:
With this logic distillation strategy, the student model better simulates the predictions of the teacher model based on both the classification and edge localization tasks, resulting in improved detection accuracy.
3.3.2. Feature Distillation
In addition to logic distillation, feature distillation allows student models to learn from the intermediate feature representations of teacher models. In this study, we utilize Channel-Wise Distillation (CWD) [
49], which aligns the feature responses of the teacher and student networks at the channel level, thereby effectively transferring the spatial attention and semantic structure.
We specifically apply Class-Wise Distillation (CWD) to three detection head-connected layers in both the teacher and student models—layers that directly contribute to the generation of bounding box predictions. These layers were selected because they represent critical stages in the model pipeline, where rich semantic features and localization information are integrated to produce the final object-detection outputs.
We specifically select layers 15, 17, and 19 from the teacher model, as well as layers 15, 18, and 21 (as shown in
Figure 3) from the student model, for feature distillation. These layers are directly connected to the detection heads and represent various spatial scales and semantic levels within the feature hierarchy. They correspond to the final stages of feature extraction that are responsible for detecting small, medium, and large objects. The slight differences in layer indices reflect the structural simplification of the student model; however, the selected layers are functionally aligned. By choosing these layers, we ensure that the student model receives multi-scale and semantically rich supervision from the teacher, thereby preserving the critical knowledge necessary for object classification and localization. This targeted distillation strategy enhances the student model’s ability to generalize across different object sizes and improves the overall detection accuracy.
To enable a meaningful comparison and alignment at the channel level, we apply softmax normalization across the spatial dimensions of each feature channel in the teacher model. This normalization treats each channel as a spatial probability distribution, emphasizing discriminative regions and enhancing the comparability of features between the teacher and student representations.
By aligning key detection-related layers using Class-Wise Distillation (CWD), we ensure that the student model inherits the teacher’s high-level spatial awareness and channel-wise semantic discrimination. This inheritance is crucial for tasks such as PEPPE detection, which involves small and overlapping objects in complex scenes.
Using the Kullback–Leibler (KL) scatter, the CWD loss measures the difference between teacher and student features over channels. This loss encourages students to capture similar spatial patterns and semantic information by minimizing the information difference between teacher and student feature representations.
where
KL denotes KL scatter, and
Softmax and
LogSoftmax normalize the feature map in the channel dimension, respectively.
The total feature distillation loss is the sum of all selection layer CWD losses. The total loss of the student model is as follows:
where
λ is a weighting factor for the equilibrium logistic distillation and characteristic distillation contributions.
6. Summary
In this paper, we propose an MRC-DETR-based detection model for power operation and protection equipment, which effectively solves the problems of the insufficient detection accuracy, low efficiency, and limited applicability faced by the traditional methods in power operation scenarios through several technological innovations. First, we propose the MEBA module, which optimizes the multi-scale feature fusion mechanism and enhances the model’s ability to capture subtle features in complex environments. Second, we propose MRC-DETR, which significantly reduces the number of parameters and computational complexity of the model while maintaining the detection performance through the knowledge distillation technique, making it more suitable to be deployed on resource-constrained edge devices. Finally, we deploy MRC-DETR in edge devices to realize the real-time detection requirement, and the experimental results show that the model has important practical application value in power operation scenarios.
However, this research still has some limitations: current models can only detect the wearing status of protective equipment, but cannot effectively verify compliance with equipment wearing, such as critical safety hazards like helmets that are not securely fastened or seat belts that are not properly buckled. The accurate identification of these issues is critical to ensure safe power operations. In addition, the generalizability problem of MRC-DETR still needs to be improved. Future research should focus on developing methods for detecting equipment wear compliance and on improving the generalizability issue of the model to further improve the efficiency of PEPPE identification.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}