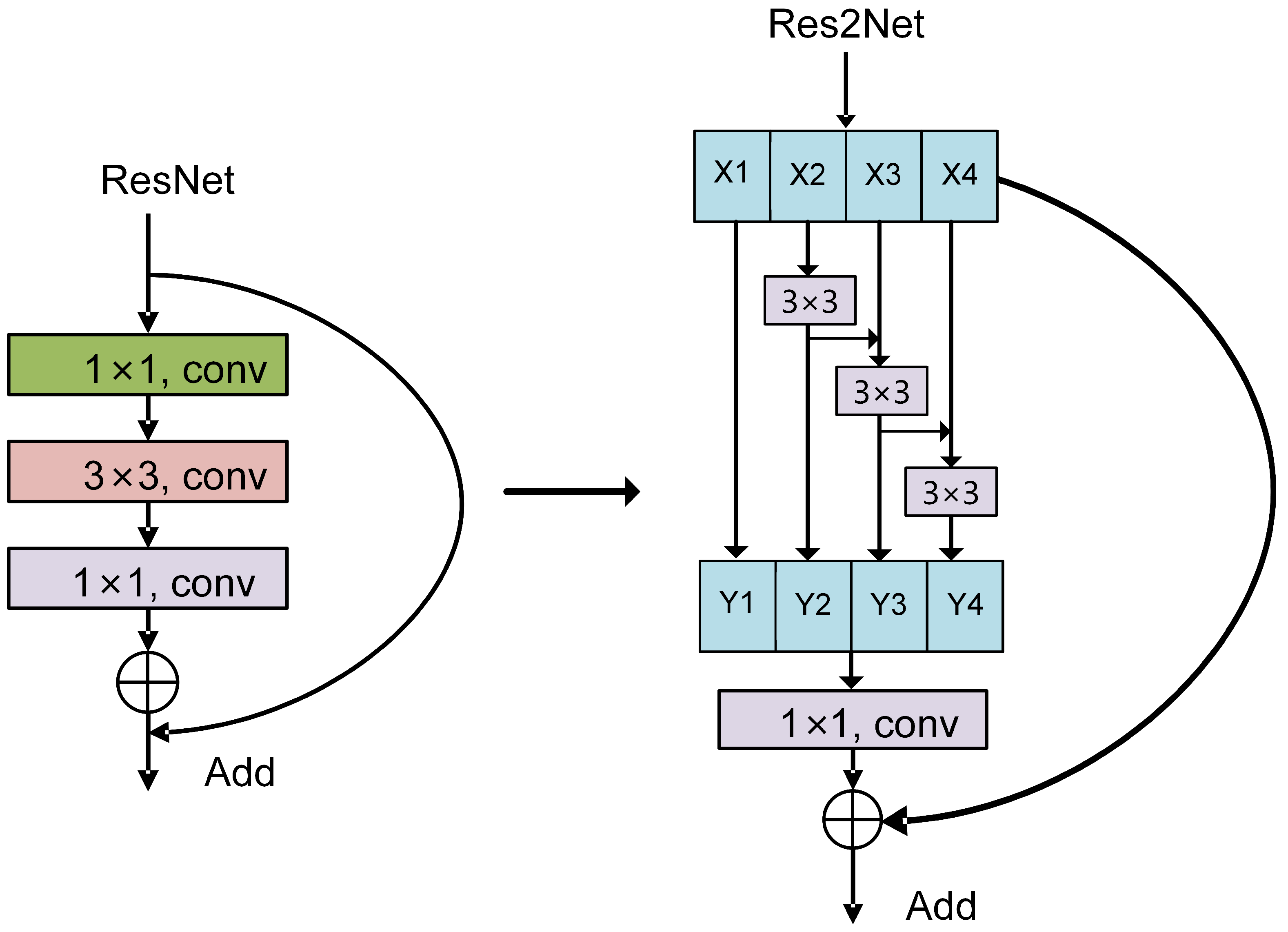
This section provides a comprehensive evaluation of the proposed Sparse-Attention-driven Res2Net model through extensive experiments to analyze its classification performance and effectiveness. Comparative experiments first examine the convergence behavior and generalization capacity of the proposed model by analyzing accuracy and loss iteration curves. The classification precision across various categories is quantitatively assessed using confusion matrices, offering insights into its discriminative capability. Additional evaluations on the COCO dataset further validate the model’s adaptability to diverse and complex scenarios. The ability to distinguish categories within the feature space is visualized through t-SNE dimensionality reduction, revealing the separability of high-dimensional features. Class activation mapping is employed to highlight critical regions of attention, intuitively demonstrating the model’s focus on relevant features in fine-grained classification tasks. Finally, ablation studies isolate the contributions of the Sparse Attention module and the multi-scale feature extraction block, validating the soundness and novelty of the proposed architecture.
4.1. Comparative Experimental Analysis
In the comparative experiments, five well-established architectures were selected for performance benchmarking against the proposed Sparse-Attention-driven Res2Net model. These include VGG-19, ResNet-50, MobileNetV2, Inception-v1, and EfficientNet-v1. The detailed network configurations of these baseline models are presented in
Table 3.
Each of these architectures has a solid foundation in image classification tasks, offering distinct strengths yet accompanied by certain limitations. By contrasting our model with these representatives, we aim to comprehensively assess the performance advantages of the proposed method in fine-grained categorization scenarios.
4.1.1. Analysis of Training Processes Using Different Methods
The performance evaluation of the Sparse-Attention-driven Res2Net model and five other methods was illustrated using six graphs, depicting the training and validation accuracy and loss trends for each model, as shown in
Figure 4.
The Sparse-Attention-driven Res2Net demonstrated rapid and consistent convergence during both training and validation, with accuracy stabilizing within the first 15 iterations. This performance is attributed to the synergy between the Sparse Attention mechanism and multi-scale feature fusion, significantly accelerating the optimization process. Furthermore, the steep decline in training and validation loss indicates that the model effectively reaches a global or near-global optimum. The relatively low fluctuation in validation loss highlights its robust feature extraction capabilities and resistance to noise.
In contrast, EfficientNet-v1 and ResNet-50, while strong in feature extraction, exhibited slower convergence rates, stabilizing after approximately 30 iterations. Both models also showed notable fluctuations in validation loss during the intermediate training stages, reflecting suboptimal optimization efficiency and limited generalization for complex features. MobileNetV2 and Inception-v1 performed less effectively, with smaller improvements in training and validation accuracy and slower convergence. The flat loss reduction further suggests limited capacity in capturing fine-grained features. VGG-19 lagged significantly behind, showing minimal improvement in accuracy and substantial fluctuations in validation loss. This underperformance is likely due to structural limitations that hinder its ability to adapt to complex feature representations, resulting in inferior generalization and optimization compared to modern architectures. In contrast, the Sparse-Attention-driven Res2Net outperformed VGG-19 in both convergence speed and accuracy while achieving a balance between performance and efficiency by reducing model parameters and inference time.
4.1.2. Analysis of Test Results and Evaluation Indicators Using Different Methods
To validate the stability of model performance, each model was independently run five times. The mean and standard deviation of accuracy, precision, recall, and F1 score were recorded. The detailed results for the various evaluation metrics are presented in
Table 4. From the perspective of key classification metrics, the Sparse-Attention-driven Res2Net demonstrates the best overall performance, achieving an accuracy of 98.46%, precision of 98.50%, recall of 98.40%, and an F1 score of 98.45%. The testing outcomes and evaluation metrics are summarized in
Table 4. These results indicate that the model possesses outstanding reliability and stability in classification tasks. Following closely are EfficientNet-v1 with an F1 score of 98.10%, and ResNet-50 with an F1 score of 97.88%. Both models also exhibit strong classification capabilities, though they slightly lag behind the Sparse-Attention-driven Res2Net in balancing precision and recall.
In contrast, MobileNetV2 and Inception-v1 deliver moderate performance, while VGG-19 falls significantly behind with an F1 score of only 86.75%, highlighting the limitations of traditional deep networks in contemporary classification challenges. Regarding parameter scale, the Sparse-Attention-driven Res2Net contains merely 4.5 million parameters—about 18% of ResNet-50’s size and just 3.1% of VGG-19’s. Despite this substantial parameter reduction, the model’s performance remains nearly unaffected, thanks to the efficient design of its Sparse Attention mechanism. Additionally, the inference time for the Sparse-Attention-driven Res2Net is approximately 4 ms per sample, significantly faster than EfficientNet-v1’s 6 ms and VGG-19’s 8 ms, demonstrating excellent inference efficiency. Although slightly slower than MobileNetV2’s 3 ms, the latter’s classification effectiveness is noticeably weaker, indicating that the Sparse-Attention-driven Res2Net strikes a commendable balance between performance and efficiency.
The superior convergence speed and stability in classification performance of the Sparse-Attention-driven Res2Net are closely linked to the introduced Sparse Attention mechanism. By comparison, ResNet-50 and EfficientNet-v1, while performing well, exhibit relatively slower convergence and less potential for performance improvement. MobileNetV2 and Inception-v1, designed with a lightweight focus, sacrifice some classification accuracy, whereas VGG-19 markedly underperforms relative to the other models.
4.1.3. Visual Analysis of Confusion Matrix
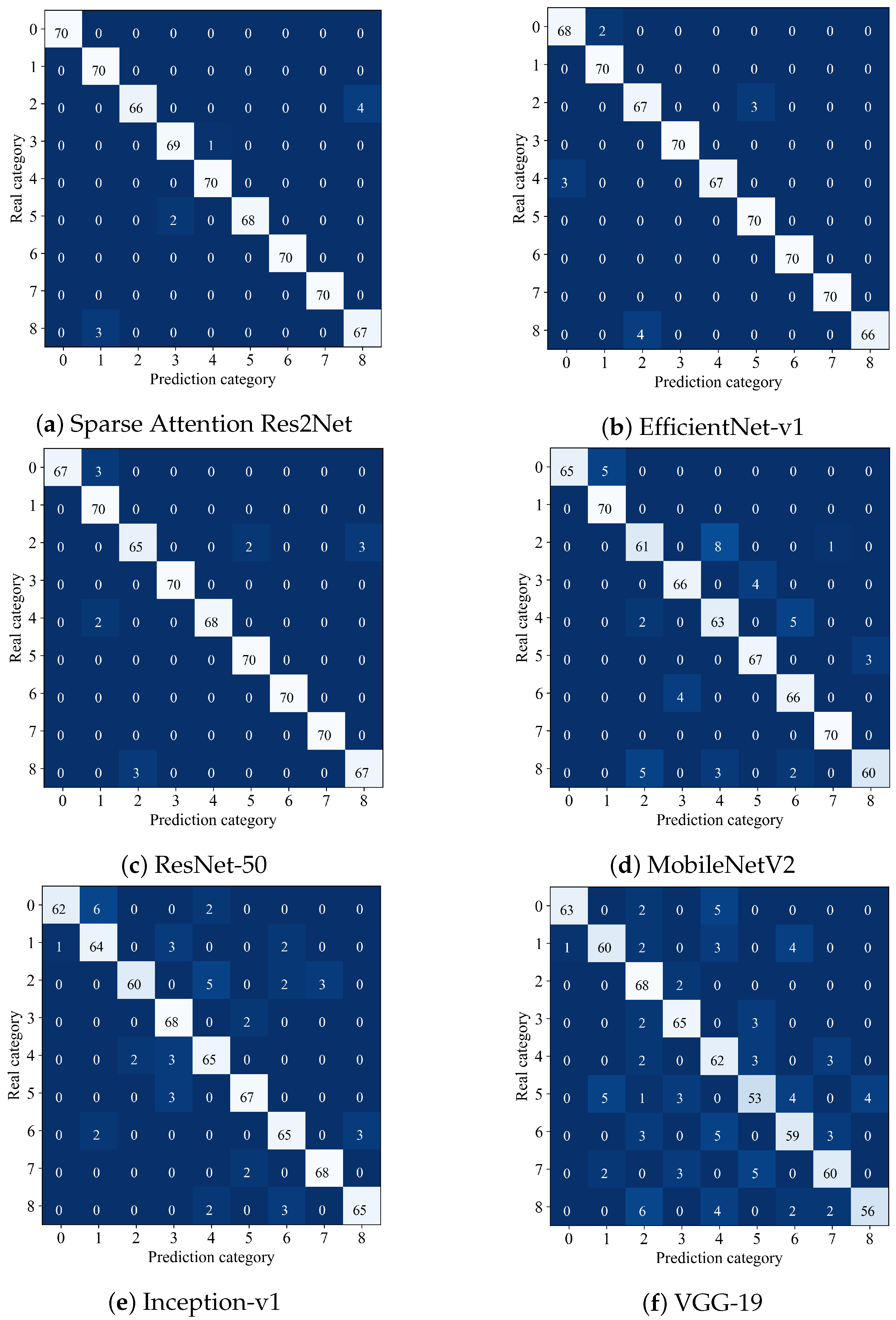
To further evaluate the classification capabilities of the proposed model alongside five other comparative methods, the confusion matrix serves as an intuitive and effective analytical tool.
Figure 5 shows the confusion matrix results of six comparison methods, the matrix’s horizontal axis represents the predicted categories, while the vertical axis corresponds to the actual categories. The values within the matrix clearly reveal each model’s accuracy and misclassification distribution across different classes.
The Sparse Attention Res2Net achieves the highest accuracy of 98.46%, demonstrating superior overall classification precision and robust fine-grained discrimination ability. Although minor misclassifications exist, the overall performance remains exceptional. EfficientNet-v1 closely follows with an accuracy of 98.12%, showing strong performance in multiple categories; however, slight misjudgments in certain classes cause it to slightly underperform compared to Sparse Attention Res2Net. ResNet-50 attains 97.89%, with near-perfect classification in some categories, yet noticeable confusion between specific classes highlights the challenges in fine-grained categorization. As a lightweight architecture, MobileNetV2 performs well in certain categories but suffers from a reduced overall accuracy of 93.32% due to a higher rate of misclassification. Inception-v1 and VGG-19 exhibit comparatively weaker performance, with accuracies of 92.68% and 86.73%, respectively. Both show significant misclassification issues, particularly in some critical categories, underscoring their limitations in fine-grained recognition tasks.
Analysis of the confusion matrices for different models reveals notable differences in classification performance. The Sparse Attention Res2Net shows excellent results with a clear main diagonal, indicating very high accuracy. However, there is some confusion between class 3 (Huckleberry) and class 8 (Walnut), with four misclassified samples, as well as between class 6 (Lychee) and class 4 (Cactus Fruit), with two misclassifications. This suggests high feature similarity between these pairs, highlighting the need to further enhance the model’s ability to capture fine-grained details. EfficientNet-v1 achieves an overall accuracy close to the Sparse Attention Res2Net, but has more scattered errors. Notably, class 5 (Passion Fruit) is misclassified as class 1 (Papaya) three times, and class 3 is misclassified as class 6 three times. This may relate to EfficientNet’s weaker adaptation to complex backgrounds and challenges in distinguishing features near class boundaries. ResNet-50 maintains relatively high accuracy but shows more evident confusion than the previous two models. Specifically, class 3 is misclassified as class 6 twice, and class 8 as class 3 three times. This indicates some limitations in its convolutional feature extraction for fine-grained classification and suggests a need for stronger regularization to better separate boundary samples. MobileNetV2, as a lightweight model, performs as expected but experiences significant confusion with complex classes. Most samples of class 3 (eight samples) are misclassified as class 5, and notable confusion exists between classes 6 and 8. This reflects limited feature extraction capability and sensitivity to background noise. Inception-v1 shows a more scattered error distribution, indicating some feature differentiation ability. However, there are five misclassifications between classes 5 and 3, and three cross-classifications between classes 8 and 7 (Tangelo). This suggests limited network depth leading to overlapping feature spaces, especially among highly similar classes. VGG-19 exhibits a relatively clear main diagonal but the most pronounced off-diagonal confusion. Samples of class 5 are spread across classes 3, 6, and 8, reflecting poor adaptation to complex backgrounds. The shallow network struggles to extract fine-grained features under such conditions, resulting in weak classification of boundary samples.
4.1.4. T-SNE Visualization
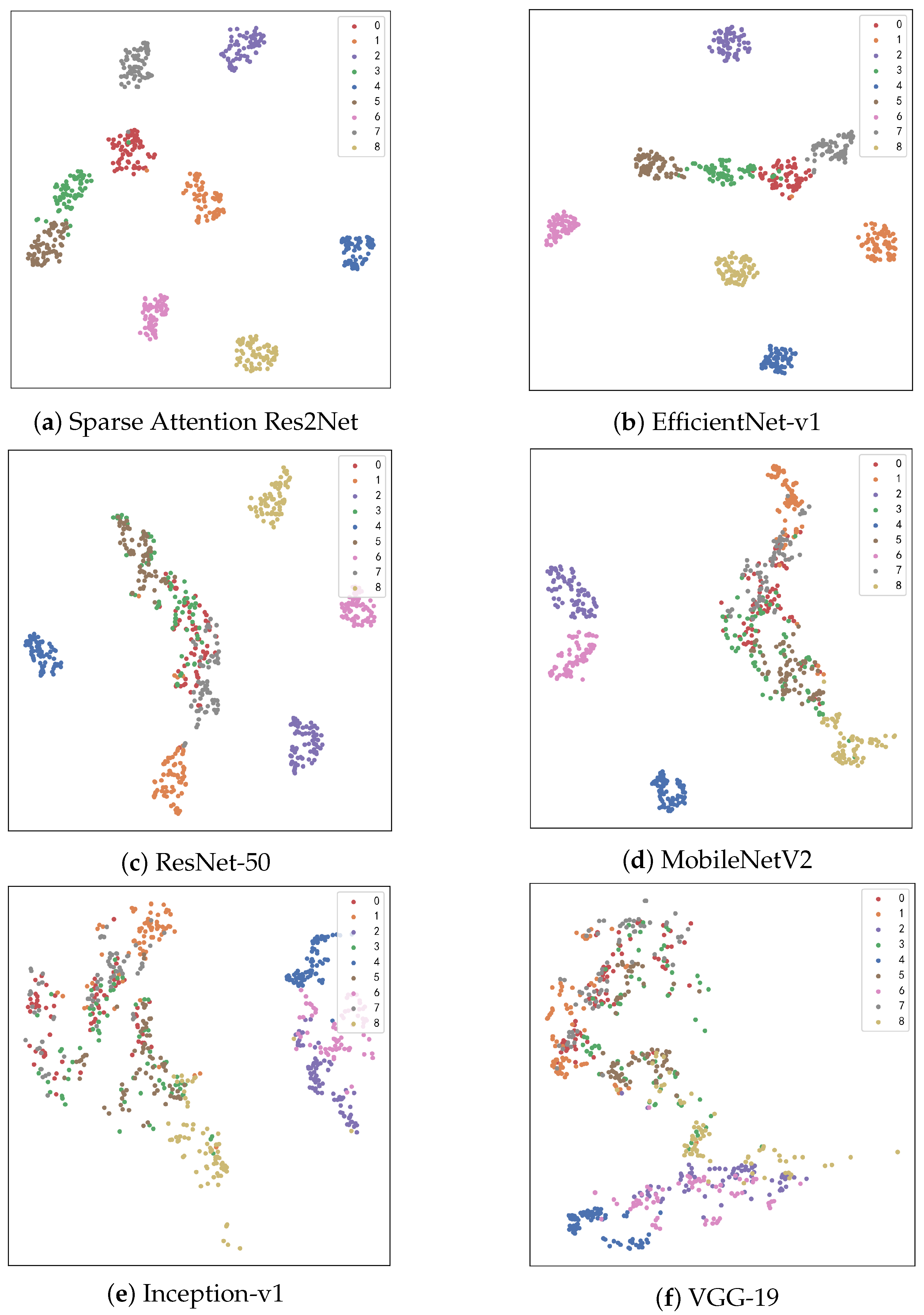
T-Distributed Stochastic Neighbor Embedding (t-SNE) is a nonlinear dimensionality reduction technique that projects high-dimensional data into a two-dimensional space, providing researchers with an intuitive visualization of sample distributions. Using t-SNE visualization, we conducted an in-depth comparison of how different models perform within the feature space, with results illustrated in
Figure 6.
The Sparse-Attention-driven Res2Net, owing to its outstanding classification accuracy and feature extraction capability, demonstrates a clear advantage in the feature space. Samples from each category form compact clusters with distinct separation between classes. In comparison, EfficientNet-v1 and ResNet-50 also show relatively good clustering effects, though their inter-class separability is slightly inferior.
Due to their smaller parameter counts or architectural constraints, MobileNetV2 and Inception-v1 exhibit more dispersed clustering, with some degree of overlap between categories. The conventional model VGG-19, limited by weaker feature extraction capacity, shows a mixed sample distribution and poor inter-class separation.
This analysis reveals a significant correlation between model accuracy and the clarity of feature distribution: models with higher accuracy tend to produce tighter feature clusters and more distinct class boundaries. These findings further substantiate the superior ability of the Sparse-Attention-driven Res2Net to efficiently extract discriminative features and differentiate categories.
4.1.5. Visual Analysis of Class Activation
Class activation mapping (Grad-CAM) is an intuitive visualization technique for deep learning models that reveals which regions of an image a model focuses on during classification tasks. By generating heatmaps over input images, Grad-CAM assists researchers in understanding the features underlying the model’s decision-making process, thereby guiding model refinement. The specific results are shown in
Figure 7.
In this study, we perform Grad-CAM visualization analysis on six comparative methods using two fruit categories—Pitahaya Red and Walnut—as examples, to examine how different models highlight key feature regions.
The Sparse-Attention-driven Res2Net model exhibits exceptional feature extraction capability. For both Pitahaya Red and Walnut classification, the heatmaps clearly indicate that the model concentrates on the core characteristic regions, such as the skin texture of the Pitahaya and the surface details of the Walnut, while effectively suppressing background noise. This focused attention aligns well with the model’s high classification accuracy.
In contrast, EfficientNet-v1 and ResNet-50 also identify the main regions, but their heatmaps show some degree of dispersed attention, occasionally activating irrelevant areas. MobileNetV2 and Inception-v1 display weaker feature localization, with heatmaps spreading over broader zones, which may diminish the efficiency of key feature extraction. The traditional VGG-19 network demonstrates the least precise attention, with heatmaps often emphasizing background or irrelevant regions, reflecting its limited feature extraction ability.
Integrating Grad-CAM heatmaps with classification performance comparisons reveals a direct correlation between feature localization and classification effectiveness. The Sparse-Attention-driven Res2Net achieves efficient categorization by accurately capturing target region features, substantially enhancing model robustness and offering a reliable solution for applications in complex backgrounds. This analytical approach provides valuable insights for model improvement and optimization, further highlighting Res2Net’s strengths in fine-grained classification tasks.
4.1.6. Analysis of Attention Mechanism Operation Details
In
Figure 8, dragon fruit is used as an example to demonstrate the feature extraction effects of the Res2Net Block and the Sparse Attention module.
Figure 8a displays the first 48 feature channels extracted by the Res2Net Block, showing the model’s ability to capture multi-scale local features such as the net-like texture of the skin and edge contours. However, some feature channels still respond to background areas like the white background, which may introduce noise.
Figure 8b shows the feature output after adding Sparse Attention. Through sparsification, the unique textures of the dragon fruit’s skin and the flesh areas are further emphasized, indicating the attention mechanism’s enhanced ability to dynamically weight important regions. Meanwhile, responses in the background are significantly reduced. Sparse Attention effectively suppresses irrelevant features, allowing the model to focus more on key parts of the fruit.
Additionally, multiple channels exhibit consistent responses in local regions, such as reinforced activation around the edges and center of the dragon fruit, demonstrating Sparse Attention’s capacity to refine multi-scale feature expression and compensate for Res2Net’s limitations in capturing global features. Overall, the comparison reveals that Sparse Attention dynamically adjusts feature weights to strengthen the dragon fruit’s distinctive visual patterns while markedly reducing background noise, thereby improving the model’s adaptability to fine-grained classification tasks.
4.1.7. Comparison Between Standard Attention and Sparse Attention
In this study, the Sparse Attention mechanism was integrated after the third residual block of the Res2Net architecture, operating on feature maps with 256 channels and spatial dimensions of 56 by 56. Three Sparse Attention layers were employed in total. Unlike traditional global attention, Sparse Attention calculates attention weights only within fixed local windows along the channel dimension, avoiding the high-complexity interactions among all global feature points and thus significantly reducing computation. This mechanism combines spatial local integration with dynamic weighting across channels, maintaining sensitivity to important local regions while greatly cutting down redundant calculations.
Table 5 compares the FLOPs of standard global attention and the Sparse Attention used here under the same input conditions. The Sparse Attention module requires about 90 million FLOPs, whereas global attention typically exceeds 200 million, reducing computational load by roughly 55 percent. This optimization greatly lowers the overall computational complexity of the model while preserving its ability to extract fine-grained features, providing a technical foundation for real-time applications in resource-limited environments.
4.2. Validation on Different Dataset
4.2.1. COCO Dataset
The COCO dataset [
38] is a widely used large-scale, high-quality dataset in the field of image classification. It includes rich background information and complex contextual scenes, reflecting the challenges of real-world applications. Covering 80 categories, the dataset contains over 330,000 images and more than 1.5 million annotated object instances. Its diversity and comprehensiveness make it an essential benchmark for evaluating model robustness and generalization capability.
To assess the applicability and performance of the Sparse-Attention-driven Res2Net model on a large-scale dataset, this study selected five representative categories from the COCO dataset: Person, Car, Dog, Chair, and Bottle. These categories are rich in samples, varied in distribution, and highly representative. A total of 1000 samples were randomly selected from each category to form a subset, which was divided into training 70 percent, validation 15 percent, and testing 15 percent sets to ensure balanced sample distribution, as detailed in
Table 6.
Experiments on the COCO dataset provided an in-depth analysis of the Sparse-Attention-driven Res2Net model’s performance in feature extraction, adaptability to diverse scenarios, and resistance to background noise. The scale, orientation, and background complexity of COCO samples, along with real-world interference factors, offered a more challenging evaluation environment for the model’s generalization and robustness. This experimental design aims to address potential limitations of earlier experiments due to relatively small dataset sizes, further validating the proposed method’s applicability and practical value in broader application scenarios.
4.2.2. Testing and Evaluation Metrics on Comparative Datasets
Six models were trained on 3500 training samples from the COCO dataset and validated on 750 samples to save the best-performing models. Subsequently, the models were tested on the remaining 750 samples. To validate the stability of model performance, each model was independently run five times, and the mean and standard deviation of accuracy, precision, recall, and F1 score were recorded. The detailed evaluation results are presented in
Table 7.
In the COCO dataset experiments, the Sparse-Attention-driven Res2Net model continued to demonstrate outstanding performance, achieving an accuracy of 97.85%, precision of 97.89%, recall of 97.82%, and F1 score of 97.86%, all ranking the highest. This indicates its adaptability to complex backgrounds and diverse categories. However, compared to its performance on the Fruits-360 dataset, there was a slight decline, reflecting the higher demands on generalization and feature extraction abilities posed by large-scale, complex datasets.
EfficientNet-v1 and ResNet-50 followed closely, with accuracy dropping to 97.63% and 97.21%, respectively, highlighting limitations in optimization efficiency and feature capture in complex scenarios. Lightweight models MobileNetV2 and Inception-v1 achieved accuracies of 94.87% and 94.35%, respectively, further validating their limited feature extraction capacity when handling diverse and complex samples. VGG-19 performed the worst, with an accuracy of only 89.52%, demonstrating that its shallow feature extraction capability struggles to address the high complexity of contextual interference and background noise in the COCO dataset.
The complexity of the COCO dataset far exceeds that of the Fruits-360 dataset. High inter-class similarity and diverse background information present significant challenges for models. For example, the Bottle category may include samples with varying materials, shapes, and backgrounds, whereas fruit classification tasks have more uniform category features. The Sparse-Attention-driven Res2Net effectively captures key features and suppresses background noise, showcasing its advantages in complex scenarios. In contrast, other models, particularly lightweight models and VGG-19, exhibit significant deficiencies in feature extraction and generalization under these conditions.
Regarding metric trends, all models experienced declines in accuracy and recall on the COCO dataset, indicating that complex scenes impact the classification ability of boundary samples. Sparse-Attention-driven Res2Net and EfficientNet-v1 showed minimal drops in precision, reflecting their more cautious and accurate classification in complex scenarios. The F1 score trends aligned with accuracy, further confirming the comprehensive performance advantage of the Sparse-Attention-driven Res2Net.
In summary, the Sparse-Attention-driven Res2Net model’s results on the COCO dataset validate its superior applicability and robustness. However, they also highlight the need for further optimization of attention mechanisms and feature fusion methods in larger-scale and more complex scenarios. The performance of EfficientNet-v1 and ResNet-50 indicates untapped potential, while lightweight models and traditional deep networks need to find a better balance between feature extraction capacity and parameter efficiency.
4.2.3. Visual Analysis of t-SNE on Comparative Datasets
Figure 9 presents the t-SNE visualization results of six models on the COCO dataset, offering an intuitive comparison of their feature space performance. The Sparse-Attention-driven Res2Net model exhibits compact clusters with relatively clear boundaries in the feature space, demonstrating strong class separation and fine-grained feature capture capabilities. While some overlap remains between different categories, the overall separation is significantly better than that of other models.
In comparison, EfficientNet-v1 and ResNet-50 perform moderately well in the t-SNE visualizations. They successfully distinguish most categories but exhibit noticeable overlap at the cluster boundaries, particularly between similar categories. This suggests that their feature extraction capabilities are limited in complex background conditions, affecting their ability to differentiate subtle differences.
Lightweight models MobileNetV2 and Inception-v1 show more dispersed cluster distributions with fuzzy boundaries and significant overlap between categories. This indicates weaker feature representation capabilities, making it difficult for these models to capture fine-grained features in complex backgrounds. These limitations are particularly pronounced in scenarios involving similar categories or substantial background interference.
VGG-19 performs the worst, with loose and heavily overlapping clusters in the t-SNE plot. Many category samples are almost entirely mixed, reflecting poor feature extraction and generalization capabilities. This model struggles to handle the complex and diverse scenes in the COCO dataset, resulting in inferior classification performance.
Overall, these t-SNE analyses highlight differences in cluster compactness and boundary clarity across models in the feature space. They provide further support, from the perspective of data distribution, for the conclusion that the Sparse-Attention-driven Res2Net achieves superior performance on the COCO dataset.
4.3. Ablation Experiment
Ablation experiments were designed to evaluate the individual contributions of key components in our proposed model. By systematically modifying or removing elements, we aimed to gain insights into their impact on performance and validate their necessity in achieving high accuracy and robustness. The results of the ablation experiment in this article are shown in
Table 8.
The baseline model, Res2Net, was selected as a foundation due to its multi-scale feature extraction capabilities. The proposed method enhances Res2Net with Sparse Attention mechanisms and advanced multi-scale feature aggregation, resulting in a notable accuracy improvement to 98.46%. This demonstrates the effectiveness of integrating these features for fine-grained classification tasks.
When Res2Net was replaced with traditional residual blocks, a significant performance drop was observed, with accuracy falling to 94.87%. This indicates the critical role of Res2Net’s multi-scale design in capturing detailed features. Furthermore, removing both Sparse Attention and multi-scale aggregation reduced accuracy to 91.52%, underscoring the combined importance of these components. Sparse attention selectively focuses on relevant regions, while multi-scale aggregation ensures the capture of features across varying resolutions.
Additional experiments targeted specific components. Reducing the connection density in the Sparse Attention mechanism led to an accuracy drop to 97.18%, emphasizing the importance of balanced connectivity for effective feature interaction. Similarly, reducing the resolution in the multi-scale feature aggregation process decreased accuracy to 95.78%, highlighting the need for detailed feature aggregation to maintain classification precision.
These ablation studies validate the necessity of each component in the proposed method. They also provide theoretical support for design decisions, demonstrating how Sparse Attention and multi-scale aggregation synergistically contribute to superior performance. This systematic evaluation reinforces the model’s design and highlights its advantages over conventional architectures.
4.4. Applicability of the Method Dataset in This Article
The dynamic Sparse-Attention-driven Res2Net model excels in tasks with clear features and prominent textures, particularly in fine-grained classification scenarios. Its ability to extract multi-scale features combined with a dynamic attention mechanism enables precise capture of both local and global information, significantly enhancing classification performance. This makes the model highly adaptable and generalizable to datasets with distinct texture differences or well-defined category boundaries.
However, in datasets with complex backgrounds, the model may be affected by distracting features, resulting in dispersed attention distribution or redundant features, which limit its classification capabilities. The increased presence of interference in complex scenes exacerbates the difficulty of feature extraction. Additionally, in small-sample or sparse data scenarios, the dynamic Sparse Attention’s reliance on adequate sample support for weight learning may lead to unstable attention distribution, negatively impacting the model’s performance and stability.
To address these challenges, improving the model’s adaptability is crucial. One approach is to enhance the attention mechanism by integrating global and local attention or incorporating contrastive learning techniques to strengthen feature representation and reduce the influence of background interference. Additionally, adopting methods such as adversarial data augmentation, transfer learning, and generative adversarial networks can effectively improve the model’s generalization ability and stability in small-sample tasks.
Further optimization of dynamic Sparse Attention can be achieved by introducing background suppression mechanisms to dynamically evaluate and mitigate the impact of distracting background features. Regularization techniques can also be employed to refine Sparse Attention distributions, enhancing robustness in complex data scenarios. These improvements will provide both theoretical and practical support for achieving superior performance across a broader range of datasets and tasks.
4.5. Limitations and Challenges of the Method Described in This Article
Although the Sparse Attention-enhanced Res2Net framework achieves a remarkable balance between multi-scale feature modeling and computational efficiency, it has certain limitations. First, its generalization ability in other domains remains to be validated, as its sparsification strategy and feature modeling may require adjustment to accommodate different data characteristics. Second, while Sparse Attention reduces computational complexity, its real-time performance might still be constrained when handling ultra-high-resolution images or operating in resource-limited embedded systems. Furthermore, the model’s reliance on high-quality annotated data increases the cost of data acquisition in practical applications, and the adaptability of the sparsification strategy in complex scenarios requires further optimization. Finally, hardware implementation of the framework may face performance bottlenecks in sparse matrix operations, necessitating further refinement to suit specific hardware architectures. These limitations provide avenues for future improvements and contribute to a more comprehensive evaluation of the method’s practical applicability and potential.
To address the demands of multi-resolution discernibility and real-time UAV vision detection, the Sparse Attention-enhanced Res2Net model can be extended and optimized in several ways. Introducing cross-scale feature fusion modules could enhance its ability to detect targets at varying scales. Adjusting the sparsification strategy would make attention computations more efficient, further reducing computational complexity. Optimizing the model size through quantization and pruning, combined with embedded hardware acceleration technologies, could improve real-time inference performance. Moreover, adversarial data augmentation and adaptive weighting mechanisms tailored to the complex environments faced by UAVs could enhance the model’s robustness across different scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}