1. Introduction
China, the birthplace of tea, boasts a rich tea culture deeply cherished by its populace [
1]. The nation attaches great importance to the preservation and advancement of tea culture, actively promoting the high-quality development of the tea industry [
2]. In this context, ensuring high quality and yield in tea production is particularly crucial [
3]. However, tea diseases significantly impact both yield and quality [
4]. Therefore, research into tea disease detection holds substantial practical significance for the tea industry. Efficient and timely identification of these diseases is critical for prompt intervention to prevent widespread crop damage, making real-time or near real-time detection capabilities highly desirable for on-site diagnosis using mobile devices or for rapid.
Traditional tea disease detection relies on the visual expertise of tea farmers, a method prone to misjudgment and omission, suffering from low efficiency and high subjectivity. With the evolution of computer vision [
5], plant disease detection technologies have been widely adopted in agriculture [
6], including machine learning methods such as SVM (Support Vector Machines) [
7] and K-NN (K-Nearest Neighbor) algorithms [
8]. For instance, Sun et al. [
9] proposed an SVM-based tea disease detection method. While these machine learning algorithms overcome the misjudgment potential inherent in manual diagnosis and reduce resource demands, their efficacy largely depends on manually designed features and requires careful feature selection. Consequently, achieving high recognition accuracy is challenging in noisy scenarios, such as those with uneven illumination.
The advent of deep learning has propelled significant progress in plant disease detection technology [
10]. Deep learning-based plant disease detection models are broadly categorized into three types. The first encompasses basic image classification models, such as AlexNet [
11], ResNet [
12], DenseNet [
13], and other CNN (Convolutional Neural Network) architectures. For example, Muh Hanafi et al. [
14] proposed an automatic tea disease detection method based on the ResNet architecture. These models offer significant advantages in feature extraction, transfer learning, and performance improvement, but also present shortcomings regarding computational resources, overfitting risks, and model complexity.
The second type includes two-stage object detection models, such as R-CNN [
15], Faster R-CNN [
16], and their derivatives. For example, in 2022, Chen et al. [
17] developed a tea disease and insect pest recognition framework using Faster R-CNN, and Li et al. [
18] proposed a tea disease detection model combining Mask R-CNN with wavelet transform. While these two-stage algorithms can detect leaf diseases more accurately, their large network models and slow detection speeds result in poor practical application performance.
The third category comprises single-stage object detection models, like SSD (Single Shot Multibox Detector) [
19], YOLO (You Only Look Once) [
20], and their improved versions. For instance, Li et al. [
21] introduced a lightweight tea disease recognition system based on MobileNetV3, and Xue et al. [
22] proposed the YOLO-Tea model, an enhancement of the YOLOv5 architecture. Both studies indicate that existing methods still have room for improvement in feature expression and cross-scenario adaptability. In 2024, Ye et al. [
23] proposed YOLOv8-RMDA, a lightweight, high-precision model based on an improved YOLOv8 architecture. By incorporating the MixSPPF hybrid pooling module, RFCBAM attention mechanism, a dynamic detection head, and an IoU loss function, they effectively addressed the trade-off between accuracy and real-time performance for tea leaf disease detection in complex backgrounds while also reducing model complexity. The YOLO series, in particular, has gained prominence for its effective balance between speed and accuracy, with lightweight variants like YOLOv8n providing a promising baseline for developing efficient models suitable for deployment on resource-constrained edge devices, a key consideration for practical agricultural applications.
Single-stage detectors like YOLO provide an effective balance of speed and accuracy, yet the computer vision landscape is rapidly advancing with architectures like Vision Transformers (ViTs) and Foundation Models excelling on general benchmarks. However, their application in specialized domains such as agricultural disease detection is often hindered by substantial computational and data requirements, particularly for edge deployment. Thus, optimizing efficient, adaptable architectures like the YOLO series for domain-specific challenges remains a crucial research direction for field-deployable solutions; this study focuses on enhancing YOLOv8 for this purpose.
Current tea disease research often overlooks detection in complex natural environments, where model generalization is severely impacted by issues unique to tea cultivation: Frequent leaf occlusion within dense canopies, feature ambiguity from uneven illumination on glossy leaves, and missed detection of minute, early-stage lesions critical for timely management. These acute challenges necessitate tailored optimizations beyond general-purpose models.
This study employs object detection to identify and localize tea diseases. While real-time semantic segmentation has become increasingly viable with state-of-the-art models [
24], our choice of object detection was guided by the specific goals and practical constraints of this project. The primary objective of rapid disease identification and localization is effectively met by the bounding box outputs. Critically, the significantly lower annotation workload for creating bounding boxes, compared to the pixel-wise masks required for segmentation, made the development of our large-scale, multi-class ‘Tea Datasets’ feasible. Therefore, object detection offered the most practical and scalable pathway to develop a robust model for this application, balancing actionable output with development cost and maintaining efficiency for potential on-device use.
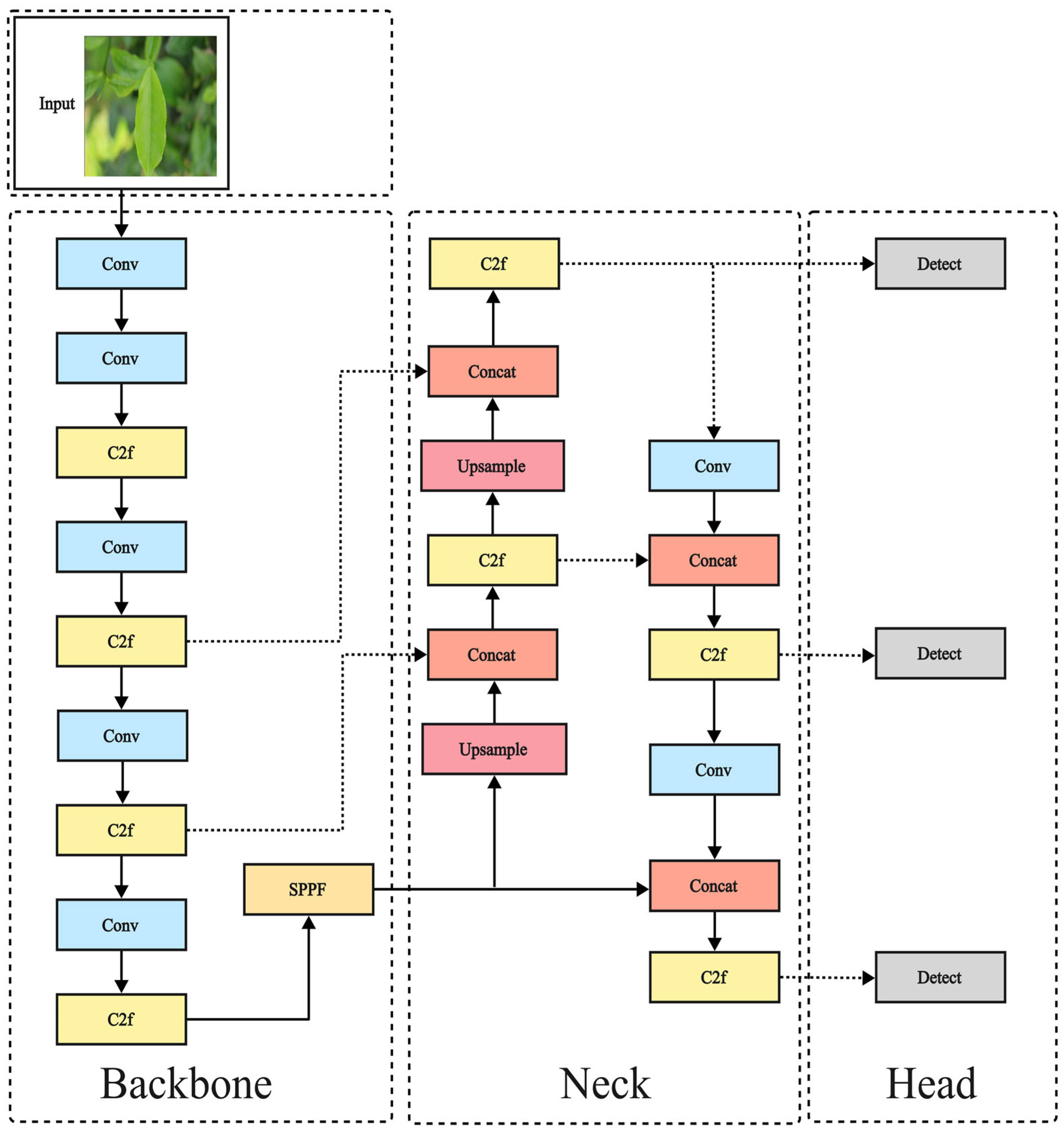
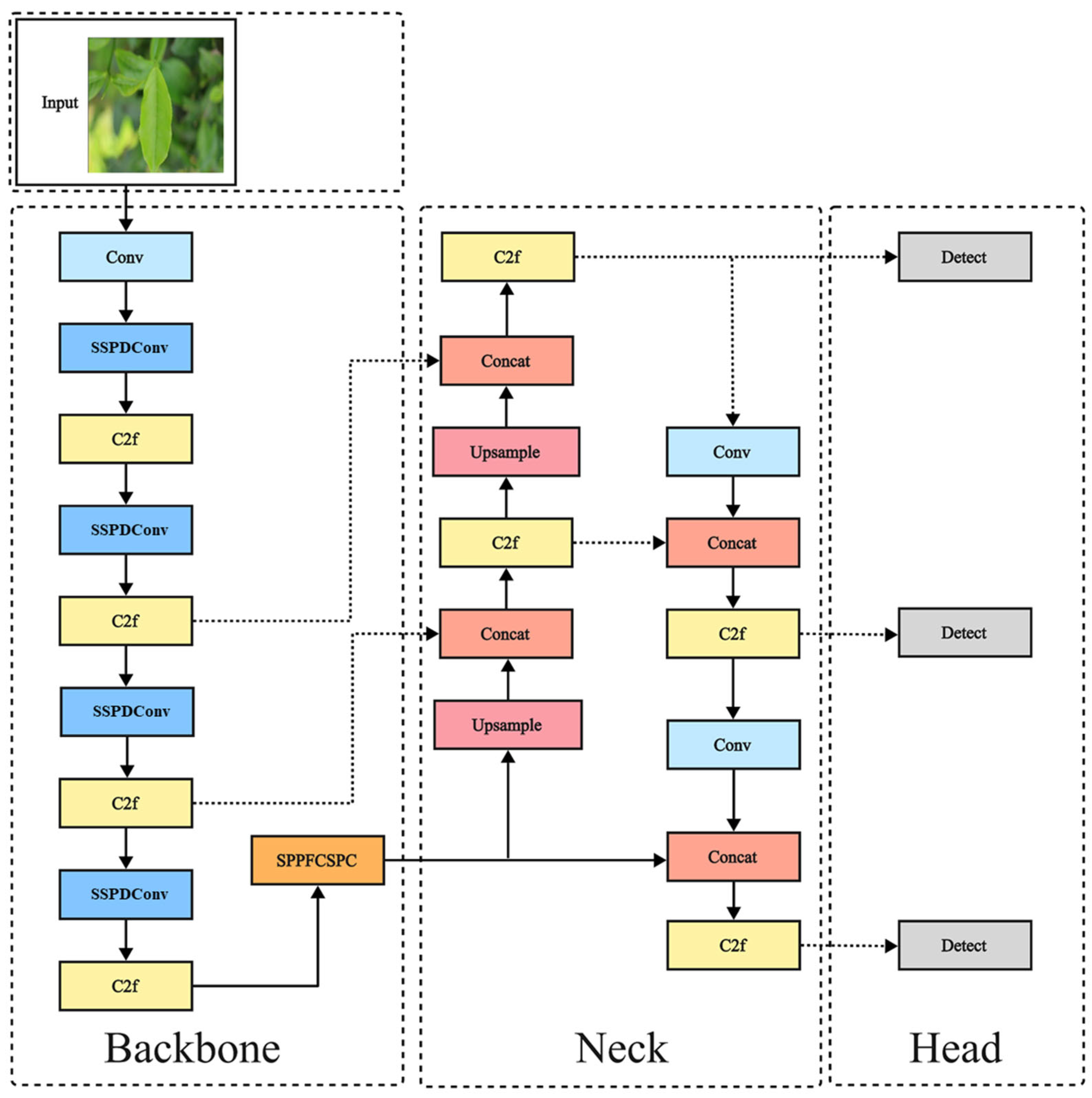
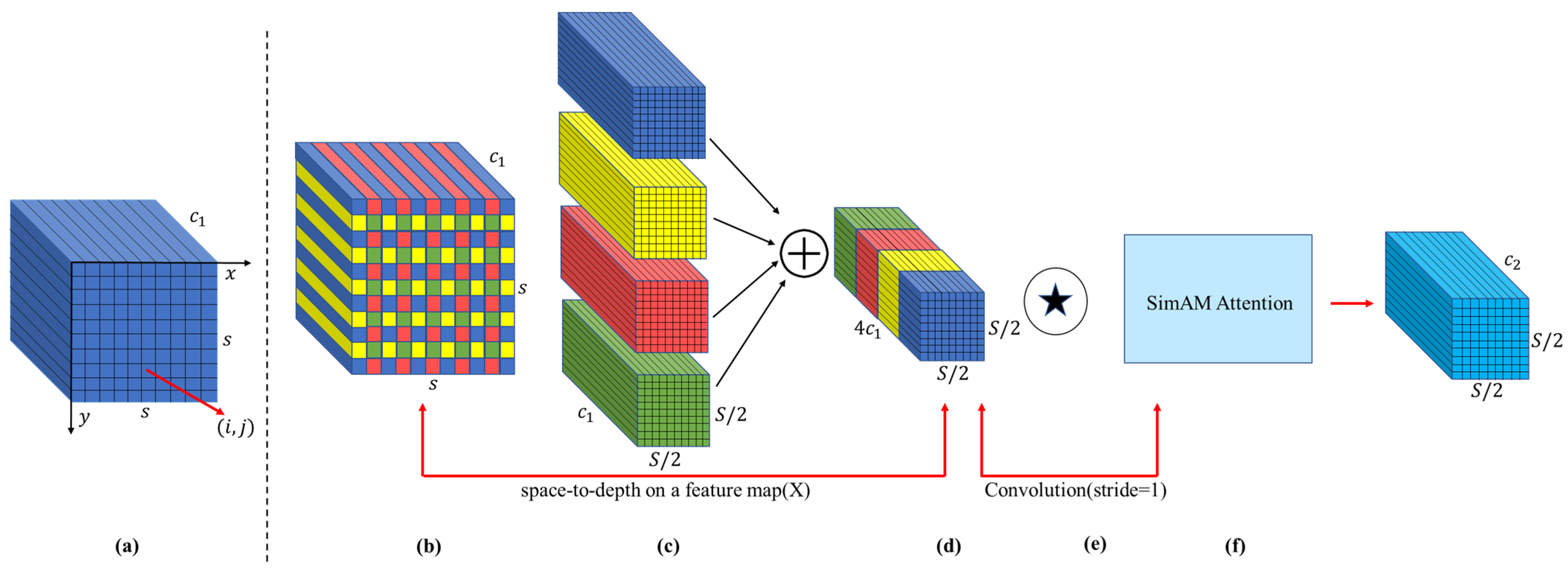
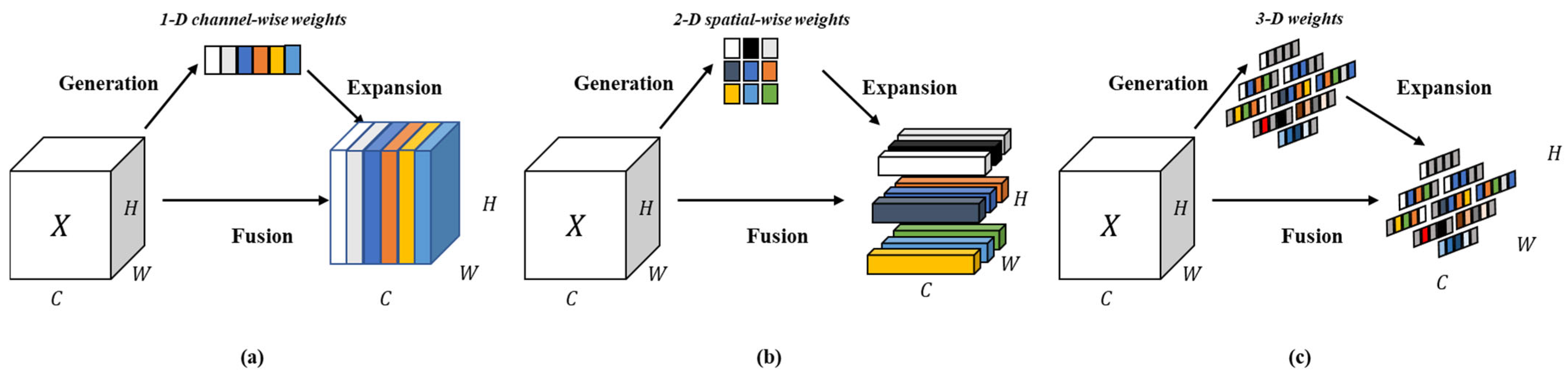
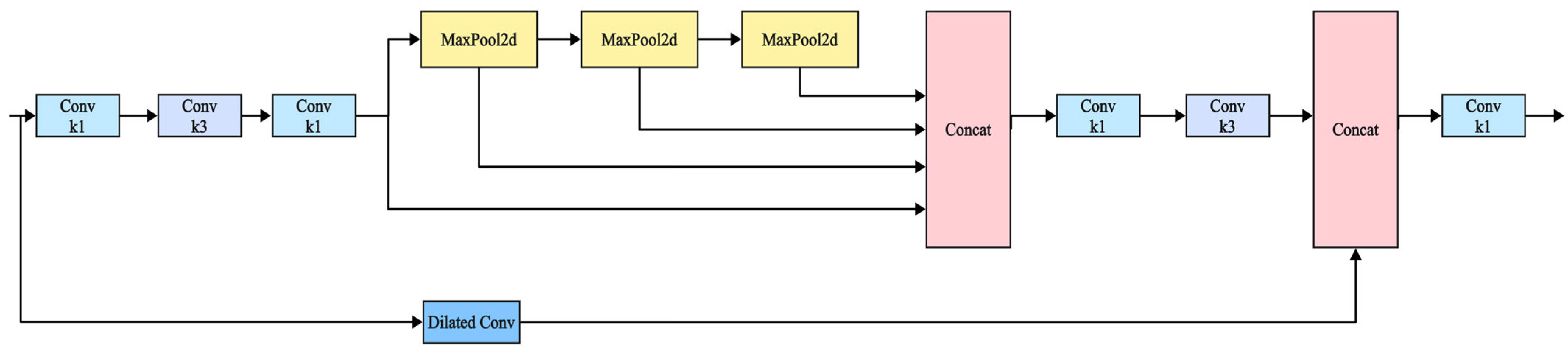
Therefore, to achieve rapid and accurate identification of tea diseases in complex backgrounds, this paper proposes a novel improved YOLOv8 model, YOLO-SSM (YOLOv8 incorporating SSPDConv, ESPPFCSPC, and MPDIoU). The novelty of this work lies not in the creation of entirely new fundamental algorithms, but in the strategic and synergistic integration of specifically adapted components designed to optimize performance for this particular domain. This includes the introduction of an SSPDConv (SPD-SimAM-Convolution) module, which is integrated into the YOLOv8 backbone to enhance global information extraction, thereby improving the model’s recognition capability in complex backgrounds. Concurrently, the ESPPFCSPC (Enhanced Spatial Pyramid Pooling Fast with Cross Stage Partial Connection) module is introduced to replace the original Spatial Pyramid Pooling module, extracting data features through dual channels to enhance feature representation quality and address problems of feature loss under occlusion and feature ambiguity from uneven illumination. Furthermore, the MPDIoU (Multi-Point Distance Intersection over Union) loss function is employed to improve the localization and recognition of small lesion areas, tackling the issue of missed small target detections. Finally, the improved YOLOv8n model is trained on self-made and public datasets to validate its detection performance.
3. Results and Discussion
This section outlines the experimental setup and specific details and subsequently provides an in-depth analysis and discussion of the experimental results.
3.1. Experimental Data
This study employed a dual-scheme approach for dataset construction, establishing a multi-source dataset by integrating data acquired online with field-collected samples. Recognizing that models trained on simple backgrounds often exhibit performance degradation in complex environments, particular emphasis was placed on augmenting the collection of disease samples under such challenging conditions.
Online data acquisition utilized a multi-source integration strategy. An automated web crawler system, guided by semantic labels such as “tea disease characteristics” and “tea disease spots,” performed targeted collection from platforms including Google Images and the CABI (Centre for Agriculture and Biosciences International) database. Simultaneously, plant disease data resources from platforms like Kaggle and Roboflow were incorporated. The initial dataset underwent a two-stage refinement process: first, blurry and low-resolution images were discarded; subsequently, manual screening was conducted to ensure the accuracy of disease labeling.
Field collection was undertaken in July and August 2024 at a tea garden in Huimin Town, Lancang Lahu Autonomous County, Pu’er City, Yunnan Province. High-resolution mobile devices were used for stereoscopic image acquisition across various time periods and under diverse lighting conditions to obtain original images of typical tea diseases. This field-collected data were then augmented using strategies such as random affine transformations and color space perturbations, resulting in an enhanced subset of 1500 field samples. This augmentation effectively improved the diversity of the data distribution and the model’s scene adaptability. The specific data augmentation methods are detailed in
Table 1, and an example of an augmented image is presented in
Figure 6.
In this study, a ‘complex background’ is defined as a natural environment characterized by multiple visual features, including color heterogeneity, texture diversity, and morphological randomness. To establish a quantitative evaluation system for background complexity, an algorithm incorporating color region segmentation and edge detection was developed. This algorithm assesses image background complexity by quantifying the number of pixels within each distinct color region and along detected edges, subsequently applying an appropriate threshold for classification. An illustrative example of this process is provided in
Figure 7.
The background complexity evaluation algorithm utilizes the following metrics:
Color Histogram Entropy: This metric indicates the uniformity of color distribution. A low entropy value signifies a more concentrated color distribution, whereas a high entropy value suggests a more uniform distribution.
Color Proportion: This refers to the ratio of pixels belonging to the most prevalent color in the entire image. A critical threshold of 60% is established; images exceeding this threshold are classified as having a simple background.
Edge Proportion: This is the ratio of edge pixels to the total pixels in the image. Based on experimental results, a critical threshold of 1.5% is set. Images with an edge pixel proportion below this threshold are considered to have a simple background.
By integrating the multi-source data acquired online and through field collection and subsequently filtering it using the aforementioned background complexity evaluation algorithm, a standardized dataset, termed ‘Tea Datasets,’ was constructed. This dataset is designed to accurately reflect the characteristics of natural scenes. It encompasses eight typical tea diseases—namely; mosquito bites; red spider damage; black rot; leaf rust; white spot; algae leaf spot; gray blight; and brown blight—along with a healthy leaf control group. The total sample size is 6560 images, compiled over a data collection and processing period of two months. Sample images from this dataset are presented in
Figure 8, and the specific distribution of samples across categories is detailed in
Table 2.
In parallel, this study also utilized the public dataset ‘Tea Leaves Disease Datasets’ [
34] to further validate the proposed model’s effectiveness and generalization capabilities. This dataset encompasses three common tea diseases: algal leaf spot, gray blight, and brown blight. The distribution of labels for each category within this public dataset is detailed in
Table 3. By incorporating this public dataset and facilitating comparisons with existing methods, the performance of our model under diverse data conditions was evaluated, thereby providing a more comprehensive assessment of its robustness and applicability.
Tea disease detection in natural environments is significantly challenged by complex factors such as leaf occlusion, uneven illumination, and small lesion areas. Most existing public datasets are predominantly based on laboratory settings or simple backgrounds, failing to fully capture the diversity and complexity of disease presentation in real-world scenarios. For instance, dense leaf occlusion can obscure critical lesion features, while variations in light intensity may mask the texture information of low-contrast lesions. Furthermore, the accurate detection of minute lesions is crucial for effective early disease prevention and control.
To systematically evaluate the model’s robustness in practical applications, this study curated specific subsets from the self-constructed ‘Tea Datasets.’ An ‘occlusion subset’ was formed by selecting samples exhibiting leaf occlusion. An ‘illumination disturbance subset’ was created by choosing samples with uneven illumination and further augmented by programmatically adjusting image brightness and contrast. Finally, a ‘small lesion subset’ was compiled by selecting images based on the proportional area of the lesions. These subsets were then combined to construct a comprehensive ‘complex scene dataset’ that encompasses instances of occlusion, uneven illumination, and small lesions. The specific distribution of samples within this dataset is detailed in
Table 4, and representative images are presented in
Figure 9.
3.2. Experimental Details
The experimental platform for this study utilized the Ubuntu 22.04 LTS operating system. Hardware specifications included an AMD Ryzen 5 5600X processor, 16 GB of DDR4 RAM, and an AMD Radeon RX 6700 XT graphics card with 10 GB of VRAM. The PyTorch 2.5.0 deep learning framework was employed. All input images from both the self-built and public datasets were resized to a fixed resolution of 640 × 640 pixels before being fed into the models for both training and evaluation. Training configuration parameters were set as follows: 150 epochs, a batch size of 32, an initial learning rate of 1 × 10−2, a momentum coefficient of 0.937, and a weight decay coefficient of 5 × 10−4. The Stochastic Gradient Descent (SGD) optimizer was used. The dataset was partitioned into training (70%), validation (20%), and test (10%) sets, following a 7:2:1 ratio.
Model evaluation was performed using a comprehensive suite of quantitative metrics, including
Precision: The proportion of correctly identified positive samples among all samples predicted as positive. It is calculated as
Recall: The proportion of correctly identified positive samples among all actual positive samples. It is calculated as
Mean Average Precision (mAP): The arithmetic mean of Average Precision (AP) values across all classes. It is calculated as
where
is the total number of classes (9 and 3, respectively, for the datasets in this study).
Complexity: Measured in Giga Floating-point Operations Per Second (GFLOPs) to quantify the model’s computational load.
Model Size: Assessed by the total number of parameters and the storage space occupied (e.g., in megabytes, MB).
3.3. Ablation Experiment
This study implemented structural optimizations within the YOLOv8n architecture to enhance detection performance. To validate the efficacy of these modifications, ablation experiments were conducted, and the results are presented in
Table 5 and
Table 6.
Figure 10 illustrates the progression of the accuracy curve throughout the training process. The training performance metrics stabilized after approximately 150 iterations, indicating that the model successfully achieved convergence.
Both our proposed YOLO-SSM and the baseline YOLOv8n were trained for 150 epochs, with performance analyzed via precision, recall, mAP@0.5, and computational complexity.
Ablation studies on our self-built dataset (
Table 5) revealed specific module contributions. Replacing CIoU with MPDIoU yielded a 2.5% mAP increase, significantly enhancing bounding box prediction accuracy and stability, especially for localizing small, indistinct early-stage tea lesions. SSPDConv alone contributed a 2.2% mAP rise by bolstering feature expression and suppressing common field-imagery background interference through its SPD transformation and SimAM attention, effectively capturing finer lesion details despite a slight increase in computational load. ESPPFCSPC added a 2.3% mAP improvement, demonstrating its effectiveness in expanding the receptive field with dilated convolution to capture broader spatial context, beneficial for varied lesion sizes and partially obscured targets in dense tea canopies. Cumulatively, the integrated YOLO-SSM achieved an 89.8% mAP on this dataset, a significant 3.9% total improvement over YOLOv8n, justifying the 1.1 GFLOPs computational increase with its enhanced ability to detect challenging tea diseases through combined strengths in detail preservation (SSPDConv), multi-scale understanding (ESPPFCSPC), and precise small target localization (MPDIoU).
On the public dataset (
Table 6), SSPDConv again demonstrated a significant impact, improving mAP by 3.2% due to its enhanced adaptability to diverse complex backgrounds via dynamic feature fusion, with a moderate 1.0 GFLOPs increase. ESPPFCSPC contributed a 2.4% mAP gain by optimizing multi-scale feature aggregation. MPDIoU yielded a 0.9% mAP improvement; while modest in aggregate here, its primary strength in enhancing localization robustness for minute objects remains crucial for early disease detection. The final YOLO-SSM achieved 68.5% mAP on this public dataset, a notable 4.3% improvement over YOLOv8n. This gain, with a manageable 1.1 GFLOPs increase, underscores the synergistic benefits of the modules in handling complex backgrounds, multi-scale features, and localization, justifying the moderate complexity increase for the achieved accuracy vital for disease identification.
Further comparative validation of the improved modules against their original counterparts confirmed their benefits. SSPDConv improved mAP by 0.6% and 0.7% over SPDConv, with enhanced recall, particularly for small/occluded targets, attributable to SimAM, without significant computational rise on the public set. ESPPFCSPC, using dilated convolution, improved mAP by 0.5% and 0.9% over SPPFCSPC, showing better adaptability to complex backgrounds with stable computational load on the self-built set. In essence, SSPDConv boosts recall for target-dense scenes, while ESPPFCSPC effectively balances accuracy and efficiency.
Overall, YOLO-SSM demonstrated significant accuracy improvements on both datasets. MPDIoU showed more prominent optimization effects on the self-built dataset, while SSPDConv’s dynamic feature fusion was more adaptable on the public dataset. Despite a slight increase in computational load from module stacking, YOLO-SSMs balanced design surpasses YOLOv8n in overall performance, validating the modules’ generalization and effectiveness.
In summary, the meticulously designed YOLO-SSM architecture enhanced detection accuracy, achieving 3.9% and 4.3% mAP improvements over the baseline on self-built and public datasets, respectively, with its efficacy validated by systematic ablation experiments.
3.4. Comparative Experiment
To further ascertain the superiority of the YOLO-SSM model, this study conducted comparative experiments against contemporary state-of-the-art models. Specifically, the advanced tea disease detection model YOLO-RMDA, previously cited, and the high-performance model PP-YOLOE [
35], which is well-suited for complex backgrounds, were reproduced for this comparison. PP-YOLOE is a high-performance, single-stage object detection model that enhances feature extraction capabilities through deformable convolution and introduces an adaptive feature fusion module to dynamically adjust multi-scale feature weights. These features significantly improve its detection performance for small and occluded targets, demonstrating excellent efficacy in complex background scenarios. The performance of YOLO-SSM was benchmarked against YOLO-RMDA, PP-YOLOE, YOLOv11n [
36], and other classic mainstream object detection models on both datasets. The comparative results are presented in
Table 7 and
Table 8.
As evidenced in
Table 7 and
Table 8, YOLO-SSM demonstrates significant comprehensive advantages when compared to contemporary high-performance models.
On the self-made dataset, YOLO-SSM achieved an mAP of 89.7%, surpassing YOLO-RMDA by 3.6%, with corresponding increases in precision and recall of 7.7% and 6.9%, respectively. On the public dataset, its mAP was 0.7% higher than that of YOLO-RMDA, and precision increased by a notable 10.8%, validating the strong generalization capability of YOLO-SSM for complex disease characteristics. However, the computational complexity of YOLO-SSM is 4.3 GFLOPs higher than YOLO-RMDA, and its parameter count is also larger, indicating that YOLO-RMDA maintains an advantage in extreme lightweight scenarios.
When compared with PP-YOLOE, YOLO-SSM exhibited mAP improvements of 1.5% and 0.3% on the self-made and public datasets, respectively, while concurrently reducing both the number of parameters and computational load. This highlights the efficiency of YOLO-SSMs lightweight design. Although PP-YOLOE achieves a higher recall rate by leveraging a powerful backbone network, its substantial computational complexity severely limits its potential for edge deployment. In contrast, YOLO-SSM strikes a balance between accuracy and efficiency through the detail preservation mechanism of SSPDConv and the multi-scale feature extraction capabilities of ESPPFCSPC.
YOLO-SSM also performs commendably against other high-performance models proposed in recent years. Compared to YOLOv11n, its mAP improved by 3% on both the self-made and public datasets, with an associated increase in precision, suggesting that the MPDIoU loss function offers more accurate localization of small targets. Relative to the baseline YOLOv8n, YOLO-SSM improved mAP by 3.8% and 2.7% on the self-made and public datasets, respectively, with only a marginal increase in computational complexity, thereby proving the efficiency of its dynamic feature fusion strategy.
In comparison with classic models, YOLO-SSM effectively overcomes the traditional accuracy limitations of lightweight architectures. For instance, its mAP on the self-made dataset increased by 4.6% compared to YOLOv5s. Against SSD, YOLO-SSM achieved a substantial mAP improvement of 18.6% on the self-made dataset while also reducing model size. Furthermore, compared to Faster R-CNN, YOLO-SSM increased mAP by 16.5% on the self-made dataset with a significantly smaller computational workload, fully reflecting the accuracy and efficiency advantages of single-stage models in agricultural applications.
While the proposed YOLO-SSM model introduces additional modules leading to a moderate increase in computational complexity, the achieved mAP improvements of 3.9% and 4.3% on the self-made and public datasets, respectively, represent a worthwhile trade-off for the challenging domain of in-field tea disease detection. The significance of these gains is further underscored by the model’s enhanced ability to detect small and occluded targets, which are critical for early disease intervention and often missed by less complex models.
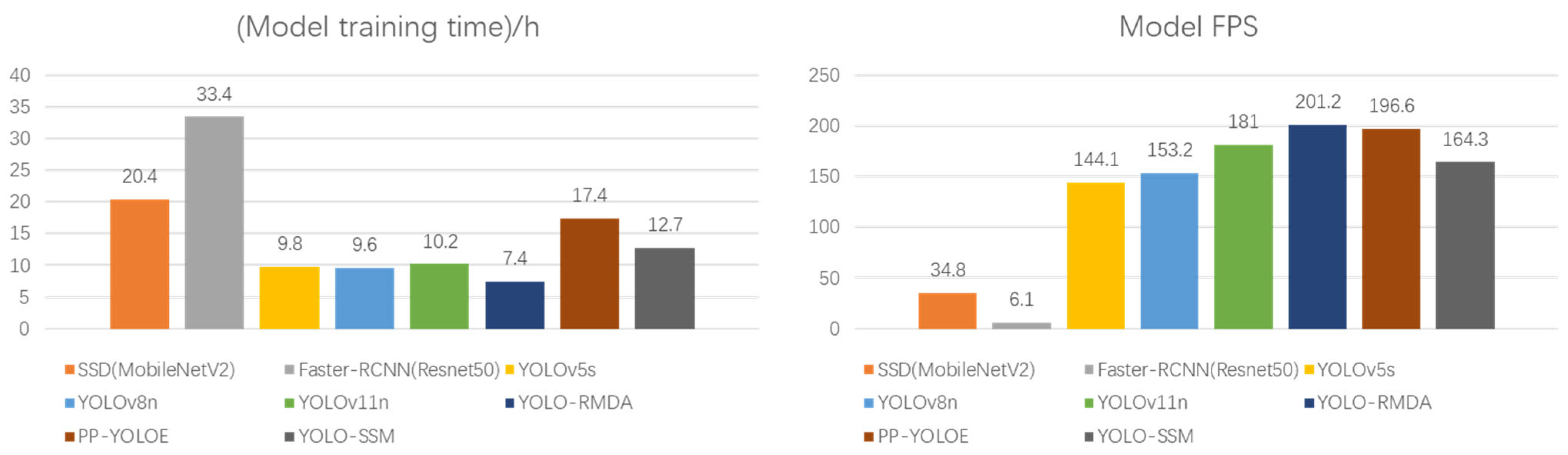
Further analysis, in conjunction with
Figure 11, reveals that YOLO-SSM achieves higher accuracy with a comparatively low computational workload. This is attributed to the synergistic combination of the SSPDConv module, which incorporates an attention mechanism, and the dual-channel ESPPFCSPC spatial pyramid pooling structure. The model’s inference speed and training time are maintained within a deployment-friendly range, verifying its potential for deployment on edge devices. The experimental results collectively demonstrate that YOLO-SSM has reached an advanced level in terms of accuracy, robustness, and engineering applicability, offering an efficient and reliable solution for agricultural disease detection.
3.5. Model Robustness Analysis and Performance Verification in Complex Scenes
To assess the practical detection capabilities of YOLO-SSM in complex natural environments, this study utilized a self-constructed dataset specifically designed to represent such challenging scenarios. This ‘complex scene dataset’ encompasses key interference factors, including leaf occlusion, uneven illumination, and small lesion areas. Through experiments on this dataset, a systematic analysis was conducted to identify the core factors that significantly impact model performance in real-world application scenarios. The experimental results are presented in
Table 9.
In occlusion scenarios, where tea leaves frequently overlap and obscure crucial lesion details, YOLO-SSM achieved an mAP of 82.1%, surpassing the baseline YOLOv8n model by 4.2%. Both precision and recall rates were simultaneously optimized, indicating that the SSPDConv module effectively mitigates detail loss caused by leaf occlusion. This is attributed to its space-to-depth conversion and SimAM attention mechanism, which validate its capability to retain local features. In scenes with uneven illumination, a common challenge arising from sunlight reflection on glossy tea leaves and shadows cast by dense foliage, the mAP of YOLO-SSM increased to 74.5%, a significant improvement of 6.8% over YOLOv8n. The ESPPFCSPC module, by employing dilated convolution, expands the receptive field and adaptively enhances the contextual feature expression of low-contrast lesions, thereby significantly improving detection stability. For small lesion areas, which represent critical early stages of tea diseases often indistinguishable or missed by general detectors in field conditions, YOLO-SSM achieved a recall rate of 67.2%, a substantial increase of 16.1% compared to YOLOv8n. This validates that the MPDIoU loss function, through its multi-point distance optimization strategy, effectively enhances sensitivity for small target localization and addresses the issue of missed detections for minute lesions. These experimental results collectively demonstrate that YOLO-SSM exhibits superior adaptability and reliability in actual complex scenes, providing robust technical support for the accurate detection of tea diseases.
3.6. Cross-Validation Experiment
To further evaluate the stability and generalization performance of the proposed YOLO-SSM model, a 5-fold cross-validation experiment was conducted on the self-built ‘Tea Datasets’. In this procedure, the dataset was randomly partitioned into five equally sized folds. For each of the five iterations, one distinct fold was reserved as the test set, while the remaining four folds were utilized for training the model. Consistent hyperparameters, as detailed in
Section 3.2, were maintained across all folds, and no fold-specific hyperparameter tuning was performed, ensuring an unbiased assessment of the model’s inherent robustness.
The comprehensive results of this 5-fold cross-validation are presented in
Table 10. The YOLO-SSM model demonstrated a high degree of consistency in its performance across the different data partitions. Specifically, the precision values ranged from 90.3% to 90.8%, mAP@0.5 values from 89.4% to 89.8%, and recall rates from 83.9% to 84.6%.
The average performance metrics across these five folds were an average precision of 90.6% (±0.19%), an average mAP@0.5 of 89.6% (±0.16%), and an average recall of 84.2% (±0.28%). The minimal variation in performance across the folds, as indicated by the low standard deviations, underscores the stability and robust generalization capabilities of the YOLO-SSM model. This cross-validation approach effectively mitigates potential biases that might arise from a single, fixed data split and provides a more comprehensive and reliable assessment of the model’s practical effectiveness in the context of tea disease detection.
3.7. Visual Comparison Verification
Visual analysis offers a spatial mapping basis for verifying algorithm performance. By visualizing the spatial coordinates, size parameters, and classification labels of the target bounding boxes, the spatial resolution capabilities and decision reliability of the detection system can be intuitively assessed [
37]. As illustrated in
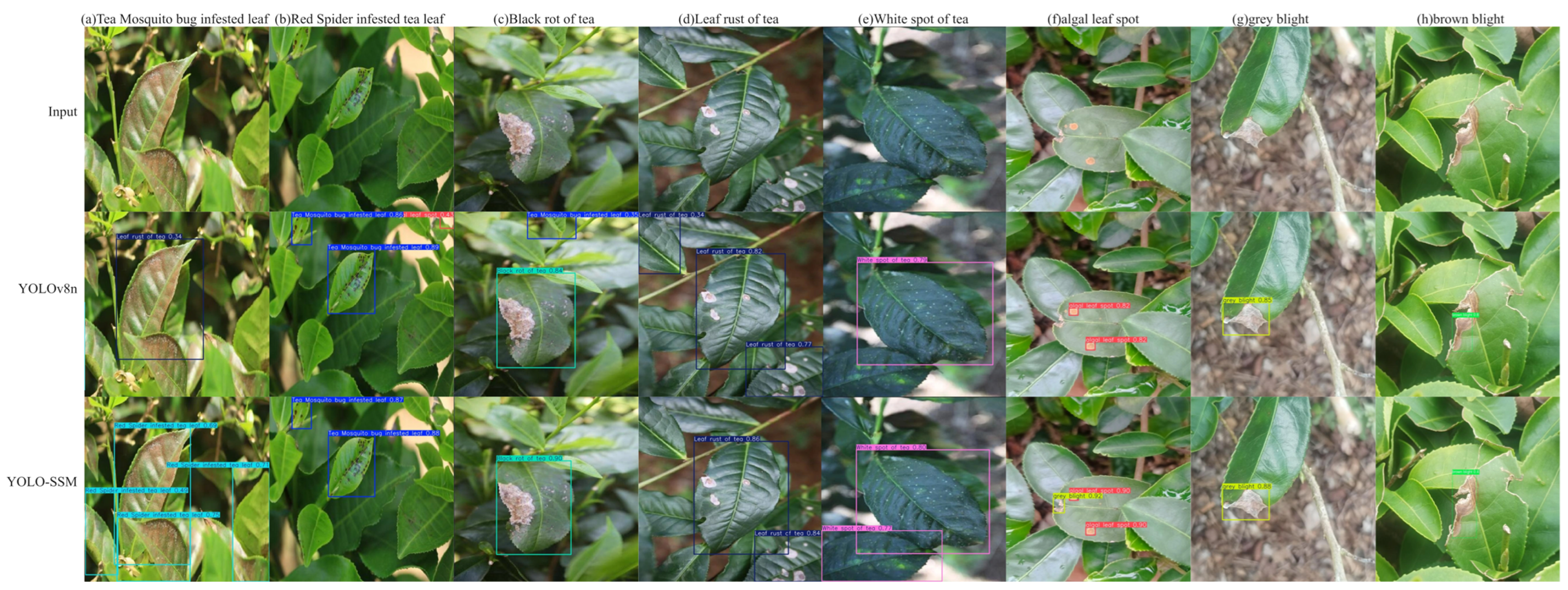
Figure 12, several observations can be made:
As illustrated in
Figure 12, a visual comparison of detection results reveals several key performance differences between YOLO-SSM and the baseline YOLOv8n model:
Figure 12a: In a scenario with mosquito-bitten tea leaves, YOLO-SSM successfully detected all instances. In contrast, the baseline model misclassified these mosquito-bitten leaves as leaf rust.
Figure 12b–d: For these samples, the improved YOLO-SSM model accurately identified all true diseased areas, whereas the baseline model produced false detection by incorrectly identifying healthy leaf portions or non-disease artifacts as diseased.
Figure 12e: The baseline model failed to detect a leaf exhibiting white spot disease, which YOLO-SSM correctly identified.
Figure 12f: In a complex scenario involving multiple co-occurring disease types, the baseline YOLOv8n model missed certain disease spots, detecting only the algae leaf spot area. While YOLO-SSM successfully detected the gray blight area, it did miss a small target area of algae leaf spot. This particular missed detection for algae leaf spot by YOLO-SSM is likely attributable to an insufficient number of training samples for this specific disease, leading to suboptimal feature extraction.
Figure 12g: For the gray blight detection image, YOLO-SSM demonstrated a higher prediction confidence score compared to the baseline model for the correctly identified disease.
Figure 12h: YOLO-SSM was able to completely detect the diseased area of brown blight, while the baseline model only identified a portion of it.
The visual comparisons highlight the superior robustness of our proposed YOLO-SSM algorithm, particularly under challenging conditions with complex backgrounds. This enhanced performance, evident in its ability to accurately identify subtle, overlapping, or partially occluded diseased areas, is driven by three key innovations: The SSPDConv module enhances feature discrimination, the ESPPFCSPC module improves feature map resolution and information integrity, and the MDPIoU loss function refines the localization of small targets.
To assess the YOLO-SSM model’s proficiency in identifying individual tea diseases, a confusion matrix was employed for visual evaluation and analysis. In a confusion matrix, diagonal elements represent instances where the model correctly detected and classified the disease. Conversely, off-diagonal elements indicate targets that were either not detected (missed detections) or misclassified. The intensity of color along the diagonal corresponds to the prediction accuracy for each respective category. The confusion matrix for the YOLO-SSM model evaluated on the self-made dataset is presented in
Figure 13.
As depicted in
Figure 13, the YOLO-SSM model demonstrated excellent detection performance for three specific diseases: Tea leaves bitten by mosquitoes, tea leaves infested by red spiders, and leaf rust. This high accuracy is likely attributable to the relatively large lesion areas and distinct disease characteristics associated with these conditions, resulting in very few missed detections or false positives by the model. The model also exhibited excellent detection efficacy for black rot and white spot disease. This particular observation might be influenced by the smaller number of samples for black rot and white spot disease in the dataset, potentially leading to a degree of overfitting for these categories. Future studies could further validate the model’s identification capabilities for these two diseases by augmenting the dataset with more samples.
Conversely, the model showed comparatively poorer detection results for algal leaf spot, gray blight, and brown blight, with instances of both false positives and missed detections. This reduced performance is likely due to the smaller sample sizes for these three diseases in the self-made dataset, coupled with the fact that their lesion spots are often small and share similar visual characteristics. Consequently, this study introduced a public dataset to further evaluate the model’s ability to identify these particular diseases. Although the YOLO-SSM model did not achieve perfect detection across all categories, it accurately identified the majority of tea diseases, underscoring its overall effectiveness in the context of tea disease detection.
To investigate the interpretability of the model’s decision-making mechanism, this study employed the Grad-CAM (Gradient-weighted Class Activation Mapping) technique [
38] to visualize network feature responses. The resulting heatmaps are presented in
Figure 14. A comparative analysis of these heatmaps reveals that YOLO-SSM exhibits significantly more concentrated attention in regions corresponding to disease locations. The activation intensity within these key areas is higher for YOLO-SSM compared to the baseline model, and there is a greater spatial overlap with the actual pathological feature areas. This enhanced focus is attributed to the attention guidance provided by the SSPDConv module and the feature refinement capabilities of the ESPPFCSPC module, thereby validating the effectiveness of these improved modules in enhancing model interpretability and suppressing background noise.
Observing
Figure 14a–c, the heatmaps generated by the baseline model fail to completely encompass the diseased areas. In contrast, the heatmaps from YOLO-SSM accurately focus on these regions. This indicates that the YOLO-SSM model, through its SSPDConv convolutional structure combined with the attention mechanism, effectively reduces interference from complex backgrounds, enabling the model to concentrate more precisely on the diseased areas.
Further analysis of
Figure 14d–f reveals that while both models can generally locate the diseased areas, the baseline model allocates less attention to the critical regions and exhibits instances of false background activation. Conversely, YOLO-SSM demonstrates significantly greater attention to the key diseased areas and a lower false activation rate for non-diseased background regions. These experiments collectively show that YOLO-SSM effectively suppresses complex background interference and achieves precise focus on diseased areas, thereby verifying its advantages in feature selection and noise immunity.
3.8. Error Analysis
To further probe the differences in model behavior, a qualitative error analysis was performed, focusing on instances where the baseline YOLOv8n model failed and YOLO-SSM succeeded, or vice versa.
Figure 15, a comparison of YOLOv8n and YOLO-SSM on detections, illustrates typical error cases.
Figure 15a presents a scenario where YOLOv8n incorrectly identified a leaf as a Tea Mosquito bug-infested leaf (false detection). The Grad-CAM for YOLOv8n indicates strong activation on this non-disease element. YOLO-SSM, however, avoided this false detection, and its Grad-CAM shows minimal activation in that area, indicating better discrimination against background noise and confusing visual patterns. In
Figure 15b, YOLOv8n failed to detect a small grey blight lesion. The corresponding Grad-CAM visualization for YOLOv8n shows weak and unfocused activation in the target region. In contrast, YOLO-SSM correctly identified this lesion, and its Grad-CAM clearly highlights concentrated attention on the lesion, demonstrating its superior sensitivity to such subtle features. These targeted visualizations underscore how the architectural modifications in YOLO-SSM lead to more reliable feature learning and attention allocation, particularly in challenging cases.
To provide a more granular and insightful analysis of the performance gains offered by YOLO-SSM, we conducted a detailed error diagnosis inspired by the TIDE (A Toolkit for Identifying Detection Error) [
39] framework. This approach decomposes the overall error into specific components, allowing us to understand not just that our model is better, but why and how it improves upon the baseline. The analysis focuses on key error types, including classification error (
), localization error (
), background error (
), missed detection error (
), false positives (
), and false negatives (
). The comparative results on the self-built dataset are presented in
Table 11.
As detailed in
Table 11, a TIDE-inspired error analysis confirms that YOLO-SSMs +3.8 mAP50 improvement stems from systematic error reduction. The most substantial gain is a +7.7 point decrease in False-Positive errors, indicating superior precision. This enhanced ability to suppress background interference is primarily attributed to the SSPDConv module’s integrated SimAM attention.
Crucially, YOLO-SSM also reduces Missed Detection errors by +2.8 points, a vital improvement for a reliable diagnostic tool. This enhanced sensitivity is driven by the MPDIoU loss function, which aids small-target localization, and SSPDConv’s detail preservation. Furthermore, the +1.3 points reduction in Localization error further validates MPDIoUs effectiveness in producing tighter bounding boxes. Modest but important reductions in Classification and Background errors suggest the synergistic combination of SSPDConv and ESPPFCSPC yields richer, more discriminative features.
In conclusion, this analysis demonstrates that YOLO-SSMs accuracy gains are achieved through targeted architectural enhancements that systematically reduce false alarms, missed detections, and localization errors for the challenging task of tea disease identification.
4. Conclusions
This paper introduced YOLO-SSM, a model developed through targeted improvements and optimizations of the YOLOv8n architecture. Specifically, the integration of the SSPDConv convolution module enhanced the model’s information extraction capabilities and allowed for the capture of richer spatial context information. The original model’s spatial pyramid pooling structure was optimized by employing the dual-channel ESPPFCSPC module for feature extraction, thereby refining multi-scale feature expression and further augmenting feature representation capabilities. Additionally, the loss function was replaced with MPDIoU to improve the model’s target localization accuracy, leading to more precise optimization of prediction results.
Through comprehensive training on both self-constructed and public datasets, complemented by extensive experimental validation, visualization analysis, and thorough comparisons with mainstream and baseline models, the proposed YOLO-SSM model demonstrated significant enhancements in object detection performance. Notably, YOLO-SSM achieved a mean Average Precision (mAP@0.5) of 89.8% on our self-built ‘Tea Datasets’ and 68.5% on the public ‘Tea Leaves Disease Datasets,’ representing substantial improvements of 3.9% and 4.3%, respectively, over the baseline YOLOv8n model. These quantitative gains underscore its superior capability, particularly in addressing the specific challenges of leaf occlusion, uneven illumination, and small target detection prevalent in complex tea plantation backgrounds. This includes improved detection of occluded targets and small targets, thereby confirming the overall effectiveness of the model for practical tea disease management and agricultural applications. Furthermore, while the primary focus of this work was to optimize a model for tea disease detection, future research could explore the generalizability of the proposed SSPDConv and ESPPFCSPC modules on broader object detection benchmarks, such as COCO, to assess their potential for wider applicability.
Looking ahead, integrating multi-modal data presents a promising frontier for advancing tea disease detection. Advanced fusion techniques that combine visual information with other data modalities can significantly enhance system robustness and accuracy. Inspiration can be drawn from sophisticated architectures like ‘Divide-and-Conquer’ triple-flow networks [
40] used in RGB-Thermal salient object detection. Such strategies effectively manage inter-modality discrepancies and improve resilience to noisy sensor inputs by concurrently processing modality-specific and complementary information streams. Adapting these principles—potentially through specialized feature modulators or dynamic aggregation modules for tea leaf imagery combined with other sensor data—could yield more comprehensive and robust diagnostic systems for tea diseases; especially in challenging field conditions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}