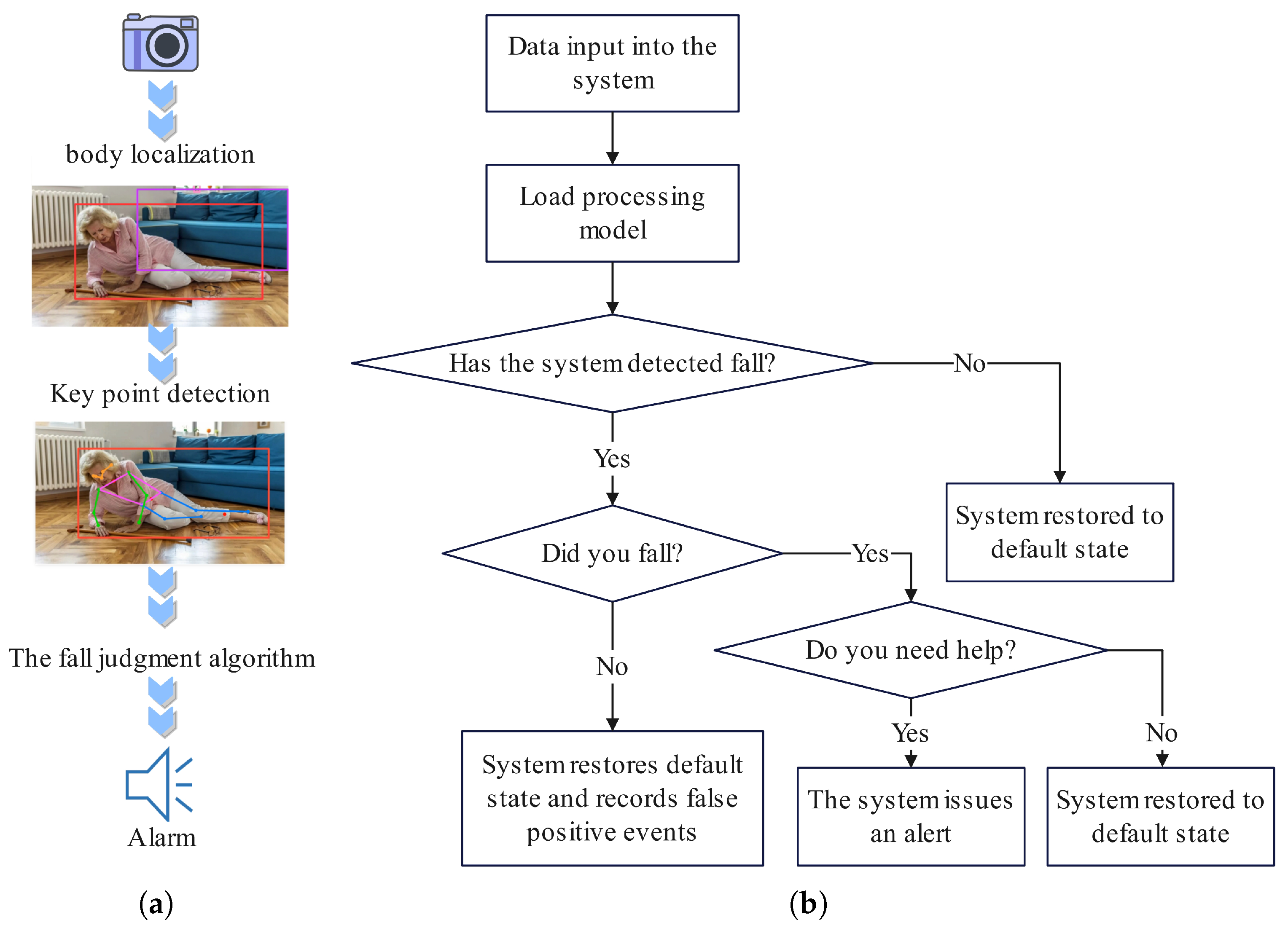
3.2.1. Data Pre-Processing
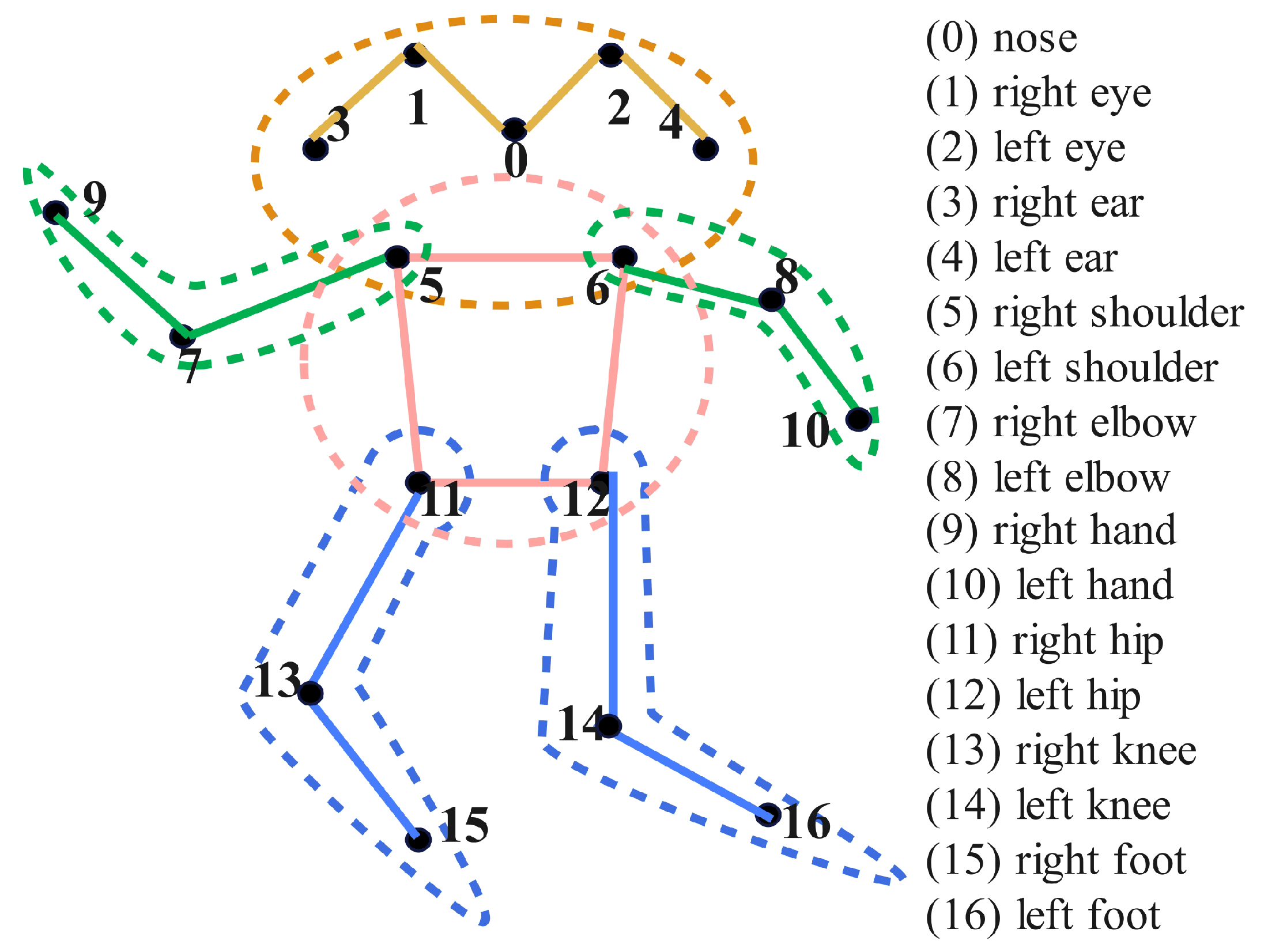
To better enable the model to learn the connection of human key points, the 17 human key points are grouped into four categories for training: head, arms, body, and legs. The numbering of key points and their corresponding body parts are illustrated in
Figure 2. The experimental results are shown in
Table 1, the results indicate that group training can enhance the model’s ability to learn the connection relationships of key points. By constraining the human body, the proposed algorithm enhances the perception of relationships between key points, which facilitates the model to locate human key points in occluded scenarios successfully.
To better deal with the issue of detection failures due to occlusions, random erasing [
38] is applied before training to improve the generalization ability of network to various levels of occlusion. Random erasing involves occluding an image with rectangular boxes of arbitrary size at random positions, replacing the occluded regions with the average pixel value of ImageNet [
39], and generating new image data. Random erasing can be categorized into three types:
(1) Random occlusion on the entire image (Image Random Erasing, IRE).
(2) Random occlusion of key points within the bounding box of the detected human, provided that the bounding-box prediction is successful (Key-Point Random Erasing, KRE).
(3) Simultaneous random occlusion on the entire image and on the key points locations (Image/Key-Point Random Erasing, I-KRE).
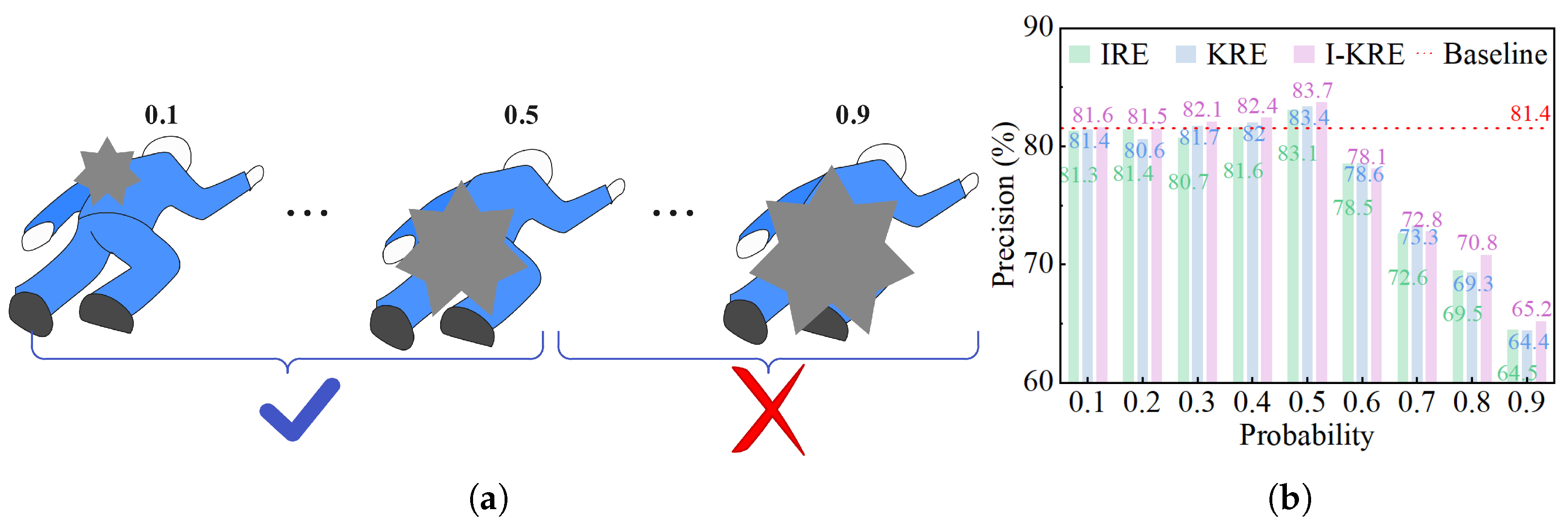
During training, the degree of occlusion is determined for the proportion of the area covered by the rectangular box. Therefore, choosing an appropriate occlusion ratio is an important step.
Figure 3 shows examples of random occlusion ratios and the experimental results for three occlusion methods at different occlusion ratios. The results show that the optimal performance is achieved when the erasing ratio is 0.5.
3.2.2. Network Structure Design
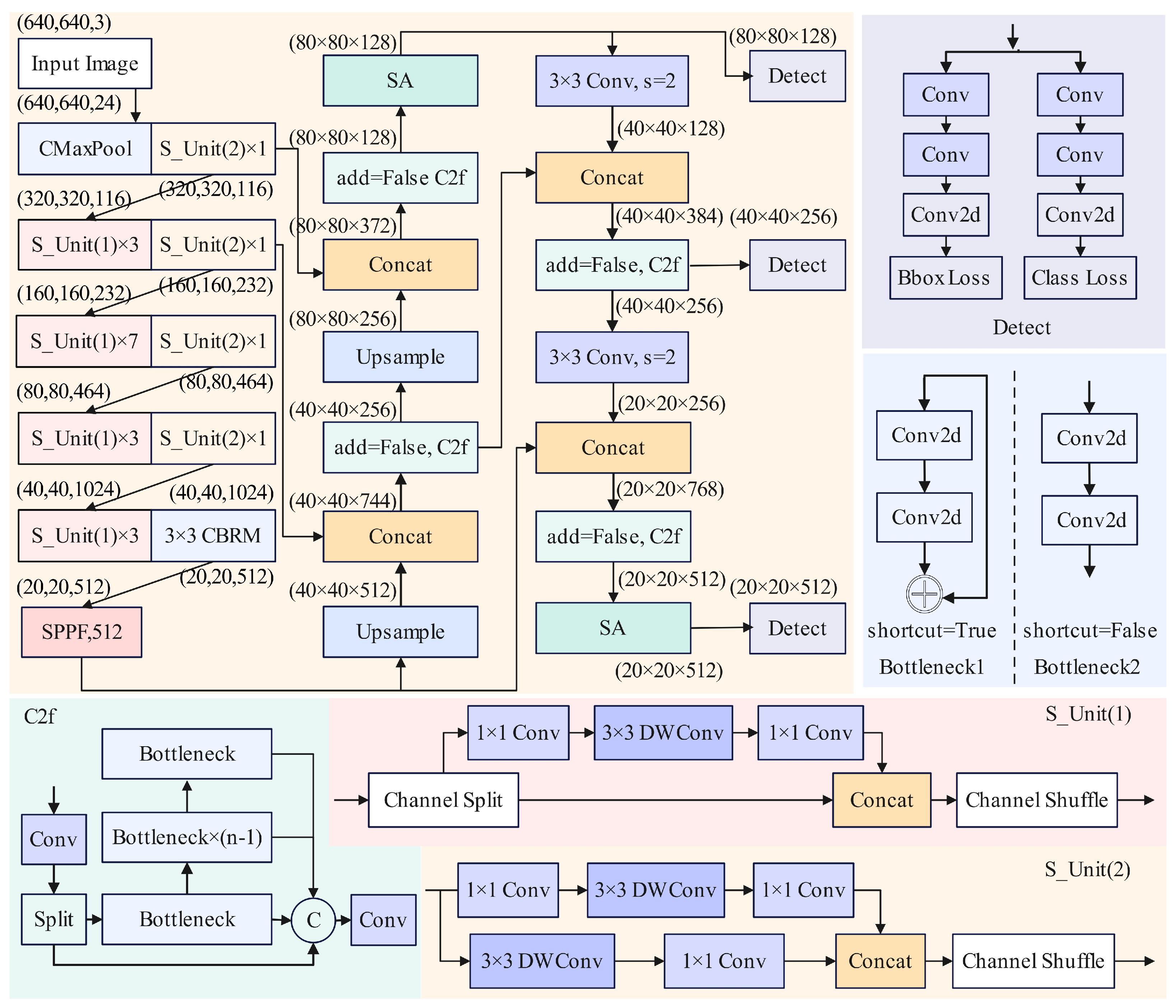
Figure 4 shows the network structure of the improved YOLOv8. The ShuffleNetV2 [
40] network, which has channel shuffle, point-wise group convolution, and consists of basic units with depth-wise separable convolutions and down-sampling units, serves as the lightweight backbone of the improved YOLOv8.
The backbone has channels of 24, 116, 232, and 464. This design effectively reduces computation and parameters while enabling initial feature extraction. Additionally, the C2f module, which inherits the ELAN cross-stage connection idea from YOLOv7 [
41], enriches gradient flow information. The basic unit named S_Unit(1) splits channels into two branches in any order. One branch remains unchanged, while the other first performs a 1 × 1 convolution to change the number of channels, followed by a 3 × 3 depth-wise separable convolution to better extract features. Subsequently, another 1 × 1 convolution adjusts channel dimensions to ensure both branches have the same number of channels. Finally, the two branches are fully connected, and a channel mixing operation is performed to enable information sharing across channels. The down-sampling unit named S_Unit(2), with a stride of 2 in the depth-wise separable convolution, increases the receptive field, halves the feature map size, doubles the number of channels, and applies channel shuffle to ensure thorough communication and utilization of different channels.
Only when the algorithm accurately captures subtle changes in the human body can the system better distinguish between elderly individuals’ daily activities and accidental falls. The improved backbone network produces feature maps of size 20 × 20, which are fed into a serial Spatial Pyramid Pooling Fast (SPPF) module [
42]. This module implements max pooling with scales of 5, 9, and 13. During the construction of the entire network model, cross-stage connections are employed to prevent gradient vanishing or explosion, enhance the network’s feature extraction capability, and improve the accuracy of localization information.
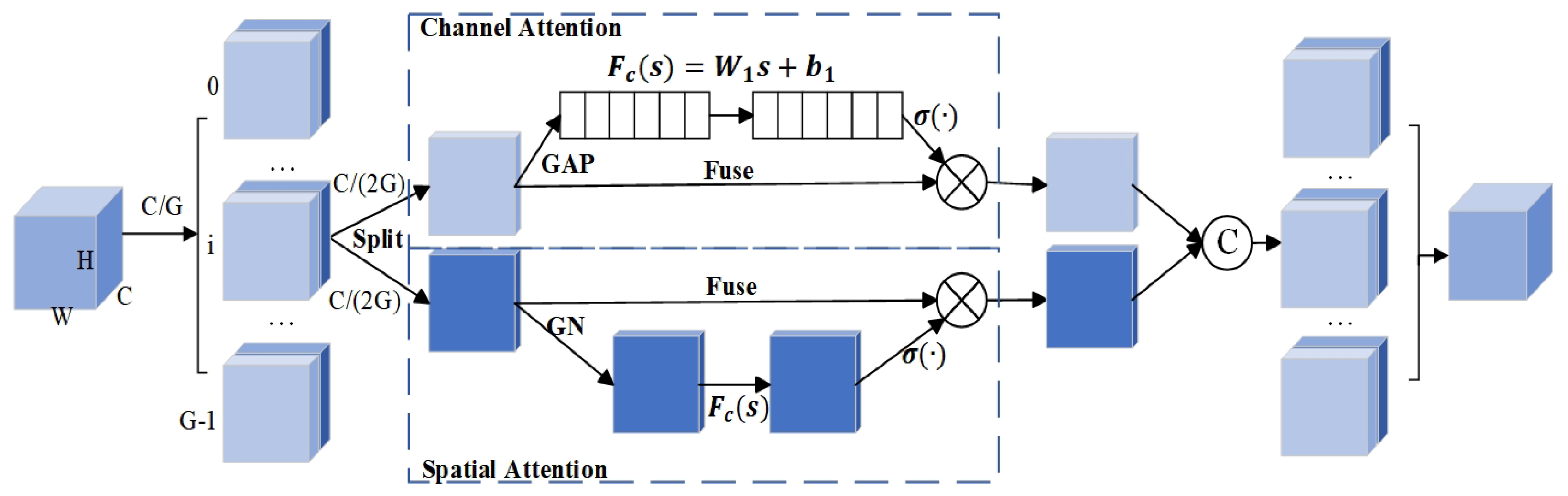
At the same time, adding the mix attention mechanism is named Shuffle Attention (SA) [
43,
44] to obtain the information of channels. The structure of SA is shown in
Figure 5. In the improved network, the SA mechanism processes feature maps as follows: Let the feature map output by the network backbone be
, where
C represents the number of channels, and
H and
W are the height and width of the feature map, respectively. The feature map
I is divided into two groups for parallel processing. After grouping, denote the two sub-feature groups as
and
. The number of channels is
in each sub-feature group, i.e.,
.
Each of the sub-feature groups and is further divided into subgroups. After the second-stage grouping, the number of channels becomes in each sub-branch. Suppose the sub-branches obtained from the second-stage grouping of are and , and those from are and . Then, . One of the branches (e.g., and ) is used to capture channel information. Through a specific channel attention operation, important information in the channel dimension of the feature map is mined. The other branch (e.g., and ) is used to acquire spatial information. A spatial attention mechanism focuses on important regions in the spatial dimension of the feature map.
Finally, a shuffle operation is performed on the features after channel information capture and spatial information acquisition to fuse the features from different branches, resulting in the final feature representation I. The activation function in the ShuffleNetV2 module uses the ReLU function, and the Sigmoid function is used in the SA module. In summary, the SA mechanism achieves effective utilization of channel and spatial information, thereby improving the performance of the network. The head module predicts the object’s feature map, outputting the location of bounding box for the person and behavioral state category of objects.
- B.
Key-Point Detection Approach
Existing human pose estimation networks can be categorized into two types: one type obtains low-resolution features though high-to-low resolution convolutions and then recovers high-resolution images by progressively up-sampling from encoded low-resolution features. The other type continuously retains high resolution, integrating the multi-scale fusion concept while concurrently interacting with information at different resolutions. Clearly, high resolution maximally preserves the spatial information of image features and provides richer semantic expression. Therefore, for the sensitive issue of detecting key points with inherent variations and complex connection types, HRNet is chosen as the baseline model for key-point detection.
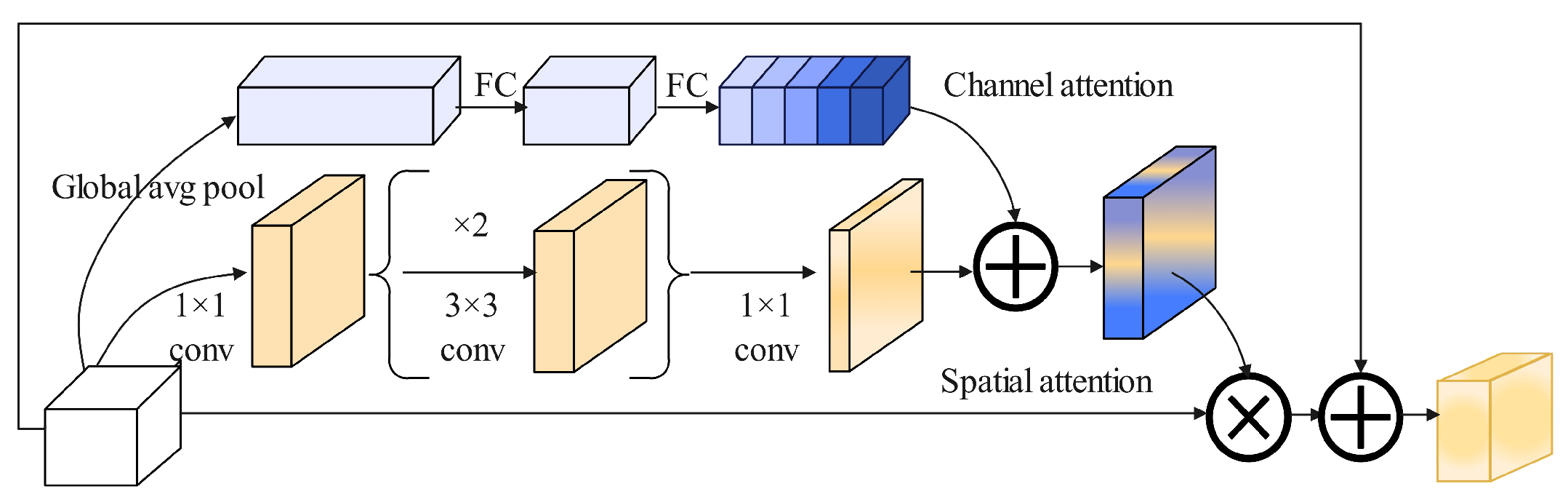
Figure 6 shows the improved HRNet network, which will be referred to as BAM-HRNet in the subsequent description. HRNet achieves strong semantic information and precise positioning by performing information interaction through parallel branches of different resolutions. However, retaining high-resolution features to the maximum extent can cause the network to focus excessively on spatial information while neglecting channel information. For fall detection tasks with high precision requirements, a single feature enhancement structure can reduce the model’s generalization ability. Therefore, after fusing different resolution features, a Bottleneck Attention Module (BAM) is introduced to improve the structure. This module considers both spatial and channel information, enhancing the model’s ability to capture pairwise relationships between pixels and reducing the model’s over-reliance on single-spatial-pixel information.
To reduce the overall size of the network, two 3 × 3 convolutional layers with a stride of 2 are used to decrease the image size to one-quarter of the original. Then, BottleNeck blocks with 1 × 1 convolutions, and multiple activation functions are employed for feature extraction. The module allows more layers to be used with lower computational resources, enabling the Basic Block to apply more non-linear transformations for feature learning. Subsequently, the extracted features are processed through up-sampling and down-sampling operations to obtain features at corresponding resolutions, with Basic Fusion completing the information integration from different receptive fields. Afterward, under the premise of maintaining high resolution, multi-resolution parallel transmission is achieved to facilitate seamless feature information interaction across different scales. At each stage of the BAM-HRNet network, the size description of the characteristic diagram is shown in
Table 2.
To mitigate the model’s over-reliance on spatial information, the BAM is integrated during the three-stage transmission, considering both channel and spatial information. This integration enhances the model’s capability to capture pairwise pixel relationships and enables effective learning of more critical information. To preserve the advantages of high-resolution feature extraction, the highest-resolution transmission path in the network remains unaltered, while only features from other scales (excluding the largest scale) undergo channel information exchange. After completing the three stages, features of different scales are fused again via up-sampling to effectively capture key image information. Note that the approach of fusing multi-scale features through up-sampling and down-sampling operations will be elaborated with Algorithm 1.
| Algorithm 1 Multi-scale Feature Fusion Algorithm |
- 1:
Input: Number of input branches , Number of output branches , Number of channels in the first branch c - 2:
Output: Fused feature map - 3:
Initialize list - 4:
fortodo - 5:
Calculate number of channels - 6:
Create a sequence containing 4 Basic Blocks and add it to - 7:
end for - 8:
Initialize list as an empty list - 9:
fortodo - 10:
Initialize as an empty list - 11:
for to do - 12:
if then - 13:
Add an Identity operation to - 14:
else if then - 15:
Add convolution, with the number of channels changing from to + BN + Up to - 16:
Scaling factor is - 17:
else if then - 18:
Add convolution, with the number of channels remaining the same + BN to - 19:
end if - 20:
end for - 21:
end for - 22:
Apply ReLU activation function - 23:
Forward pass (forward): - 24:
for each input branch do - 25:
Apply Basic Block to the branch - 26:
end for - 27:
Fuse features from each branch - 28:
Process fused features with ReLU activation - 29:
return Fused feature map
|
For BAM [
45],
Figure 7 illustrates the BAM network structure. it is primarily divided into two branches: channel and spatial attention. In the channel attention branch, the feature map
I undergoes global average pooling to produce a channel vector
. This vector performs encoding of global information for each channel. To estimate the data of cross-channel from the vector of channels
, MLP with one hidden layer is used.
To reduce parameters, the size of hidden activation is set to
, where
r is the reduction ratio. After the MLP, a Batch Normalization (BN) layer [
46] is added to adjust the output scale of the spatial branch. The channel attention calculation is Equation (
1).
The spatial attention branch produces the spatial attention map
to emphasize or suppress features at different spatial locations, which helps determine which spatial positions require more focus. Dilated convolutions are used to expand the receptive field. The literature [
47] has demonstrated that dilated convolutions are more effective than standard convolutions in constructing spatial feature maps. Specifically, when features
are mapped to
, a 1 × 1 convolution is used to aggregate and compress the feature maps along the channel dimension. For convenience, the channel branch uses the same reduction ratio. Subsequently, two 3 × 3 dilated convolutions are applied to leverage contextual information. Finally, a 1 × 1 convolution is used to reduce the features back to the spatial attention map
to adjust the scale. Batch Normalization layer is applied at the end of the spatial branch. The spatial attention is computed as Equation (
2).
where
C denotes the convolution operation, and BN represents the batch normalization operation. The superscript indicates the size of convolution filters. Channel reduction is performed using two 1 × 1 convolutions, while the intermediate 3 × 3 dilated convolution is used to aggregate contextual information with a larger receptive field.
After obtaining the channel attention
and spatial attention
from the two attention branches, we combine them to produce the final 3D attention map
, Equation (
3).
Due to the different shapes of the two attention maps, they are first expanded to the same shape
before merging [
48,
49]. Element-wise addition is chosen to achieve efficient gradient flow. After merging, a Sigmoid function is applied to obtain the final 3D attention map within the range from 0 to 1. Then the 3D attention map is element-wise multiplied with the input feature map
I and added to the original input frame to obtain the refined feature map
, Equation (
4).
3.2.3. Improving Fall Detection Methods
According to key points
and the bounding box
of humans to detect falls,
and
represent the horizontal and vertical coordinates of the top-left corner of the bounding box.
and
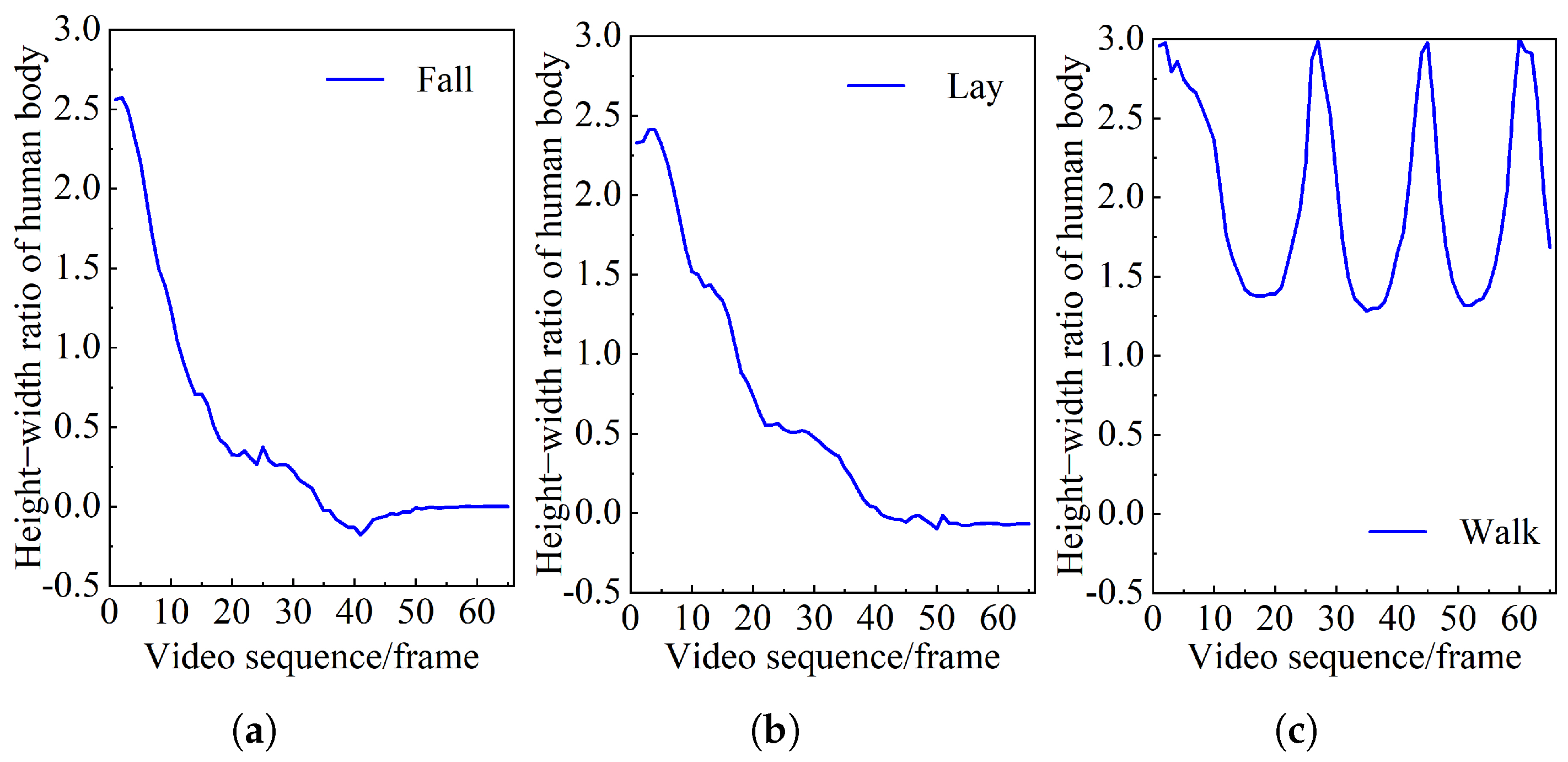
represent the horizontal and vertical coordinates of the bottom-right corner of the bounding box. When a person falls, the aspect ratio of the corresponding bounding box will also change. Therefore, the aspect ratio of the human bounding box can be used as a criterion for detecting fall events. The aspect ratio can be defined by Equation (
5).
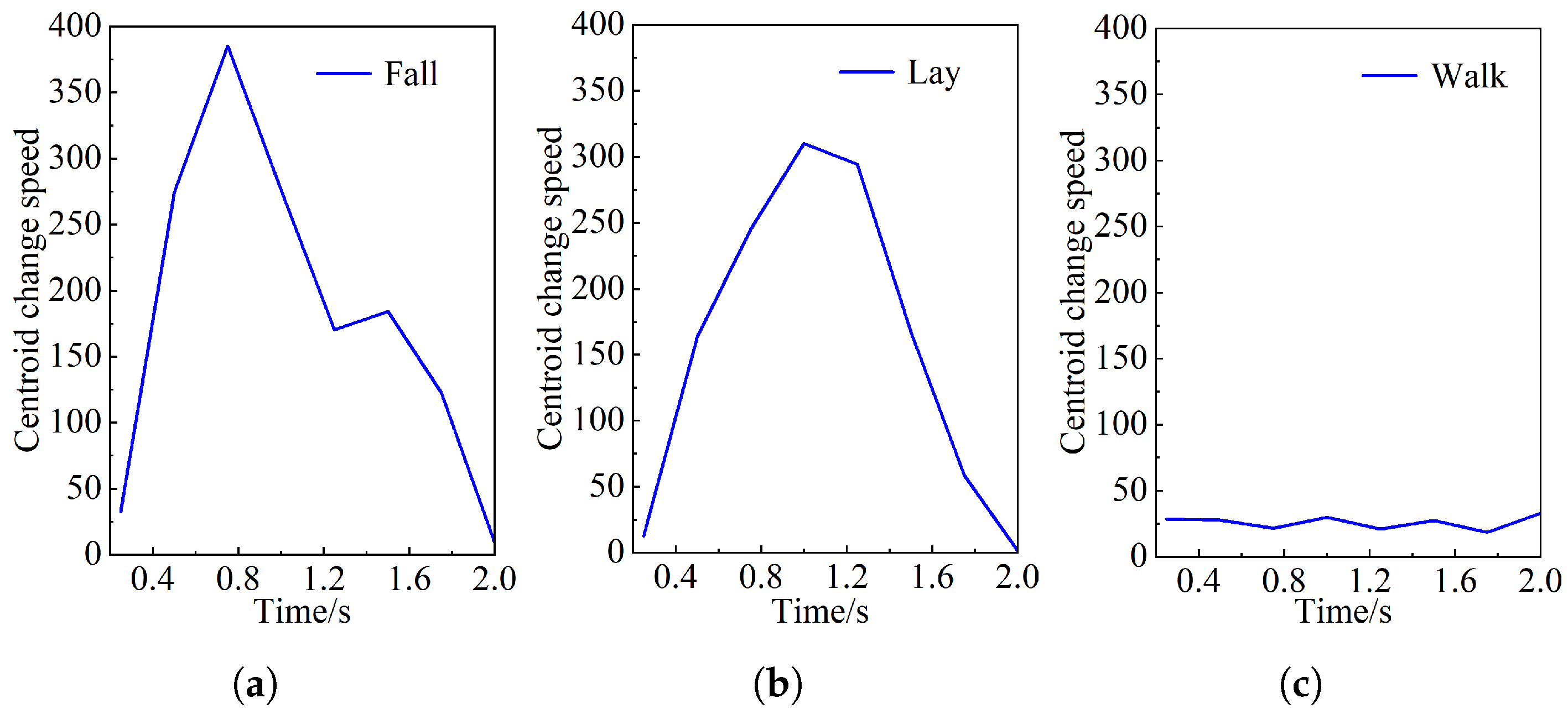
When a fall occurs, the center of mass of the human body also continuously descends. The descent rate of the body’s center of mass is defined by Equation (
6).
where
is the vertical coordinate of the centroid’s initial position and
is the vertical coordinate of the centroid’s new position after a period of time
. By using the neck
, the centroid
, and the projection point of the upright human torso on the ground as the main key points for judgment, the state threshold
that can distinguish between falls and other daily activities is determined by analyzing the coordinate change information of these key points.
The key points numbered 0 and 18 form a planar vector
, and the key points numbered 18 and 19 form another planar vector
. The direction vector
of the
x axis represents the true direction of the ground. The angle between
and
,
is
,
. Therefore, the rate of change of the angle
between the human torso and the ground is defined by Equation (
7).
During falling, the values of
A,
V, and
continuously change [
43]. By finding the thresholds that distinguish between different states, it is possible to determine whether a fall has occurred. The classification will be divided into three states: walking, lying, and falling. The detection system is configured to issue an alert exclusively when a fall is detected, indicating an accidental fall event. The fall judgment algorithm is detailed in Algorithm 2.
| Algorithm 2 The fall judgment algorithm |
- 1:
Input: Video frame sequence, , - 2:
Output: The status of judgment - 3:
, - 4:
fortodo - 5:
Calculate the aspect ratio A of the frame[i] - 6:
if then - 7:
Calculate centroid velocity V and trunk tilt angle of the frame[i] - 8:
, .append(A) - 9:
if and then - 10:
continue - 11:
end if - 12:
if then - 13:
if and then - 14:
- 15:
break - 16:
end if - 17:
end if - 18:
end if - 19:
if then - 20:
break - 21:
end if - 22:
end for - 23:
ifthen - 24:
return Fall - 25:
end if
|








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}