This section will introduce the technical specifics of the LVID-SLAM system from six different angles. First, in the initial part, we present the system framework and the fundamental process. In the second part, we demonstrate the principle of the object detection algorithm. In the third part, we rigorously derive the geometric principles of the epipolar constraint approach. This approach is used to determine dynamic features. In the fourth part, we demonstrate the principle of removing dynamic objects. Then, in the fifth part, we propose how to use IMU to assist in position tracking. Finally, we propose a method for constructing a dense octree semantic map.
3.1. System Overview
When exploring autonomous robot navigation technology in dynamic environments, the reliability of pose estimation becomes a core metric for evaluating its performance. ORB-SLAM3 [
3] is an advanced feature-based Simultaneous Localization and Mapping (SLAM) system that has demonstrated strong performance in a range of complex situations. It relies on efficient feature extraction and matching algorithms to estimate the robot’s pose accurately. The proposed LVID-SLAM system is built upon ORB-SLAM3 and incorporates three key parallel processes: tracking, local mapping, and loop closure detection. Numerous widely utilized public datasets have been employed to confirm the efficacy of ORB-SLAM3.
Therefore, LVID-SLAM chooses ORB-SLAM3 as the basic architecture to offer global localization and mapping functionalities. As
Figure 1 shows, the LVID-SLAM system creates two additional parallel threads: a dense mapping thread and an object detection thread. These significantly enhance the efficiency of system operation through a multi-threaded coordination mechanism. Additionally, IMU pre-integration is realized based on a vision-inertial tight coupling architecture to compensate for the shortcomings of pure vision pose estimation and greatly enhance the system’s robustness.
First, semantic information can be obtained in the object detection thread to complete the dynamic attribute classification of the detected target while maintaining real-time performance. The input image is grayed out, ORB feature points are extracted, and multi-scale iterative calculations are performed using the Lucas–Kanade (LK) optical flow pyramid based on the extracted feature points to accurately analyze the motional pattern of feature points between frames. Combined with the dynamic region determined by object detection, the RANSAC algorithm is used to solve the fundamental matrix, significantly improving the precision of dynamic feature point removal. Since our system does not use time-consuming semantic segmentation methods, but instead uses a more efficient object detection algorithm, each thread can run cooperatively without blocking, ensuring the real-time operation of the system. Pure vision is affected by insufficient feature point extraction or visual degradation along epipolar lines, leading to miscalculations in position estimation. IMU sensors provide prior motion data, including velocity, rotation, and translation. For IMU pre-integration over a period of time, a relatively accurate position at the current moment can be estimated based on the position at the previous moment without being affected by light, compensating for the shortcomings of pure vision. In the dense mapping thread, a dense octree map is generated based on the sparse mapping output of ORB-SLAM3 [
35]. The dense octree map not only contains richer texture information but also allows for more flexible real-time updates. Through the fusion of semantic information derived from the object detection thread, we generate a semantic map that supports advanced tasks. To reduce the system’s computational load, only keyframes are used for mapping during the local mapping process, effectively eliminating information redundancy between adjacent frames.
3.2. Object Detection Thread
A dynamic object detection thread is added in LVID-SLAM, with SSD [
10] being adopted to perform object detection and obtain semantic information. Based on their experience and cognition, humans assign semantic information to objects in their surroundings. When memorizing unfamiliar environments, they naturally disregard dynamic objects, such as cars and people, while using prior knowledge to record stationary objects, such as trees and buildings. The SLAM system’s inability to interpret the semantic level of the surrounding environment will result in difficulties in the distinction between static and dynamic objects. SSD is used to locate dynamic objects within the input image in order to obtain their semantic labels. These semantic labels can effectively assist in completing object classification tasks. The identified targets are divided into different dynamic levels based on common sense. Level I (absolutely static targets) includes public facilities and backgrounds, which are generally assumed to be stationary; Level II (potentially static objects) has a certain probability of movement, including bottles, chairs, tables, sofas, dining tables, and televisions; Level III (potentially dynamic objects) has a high probability of movement, including vehicles and pedestrians; Level IV (dynamic objects) refers to freely moving individuals: mainly animals such as birds, dogs, cats, and sheep. Specific descriptions are shown in
Figure 2.
These dynamic categories are assumed to be pre-trained and are typically present in everyday environments. If additional object categories are required, the model can be fine-tuned based on the PASCAL VOC 2007 [
36] dataset. Object detection efficiency is crucial because maintaining real-time performance is critical for SLAM systems. Due to the lightweight SSD algorithm used, the object detection thread does not need to segment the edges of objects in detail like the semantic segmentation algorithm. Our system does not need to wait too long to cause system blockage. The lightweight SSD ensures the efficiency of object detection while ensuring the real-time performance of the system.
3.3. Epipolar Geometry
During object detection, potential dynamic objects—such as seated individuals or parked vehicles—are frequently identified. When solely employing deep learning-based object detection algorithms, feature points identified on the surfaces of humans and vehicles are classified as dynamic features. However, for people sitting still and vehicles with their engines turned off, their feature points still have value for pose estimation. Geometric methods are necessary to detect potential dynamic objects. In this part, epipolar geometry constraints are used to determine the dynamic points between adjacent frames. First, ORB feature points were acquired with the use of the Optical Flow Pyramid. Edge areas and dynamic feature points are removed, and the remaining stable feature points are used to generate a fundamental matrix with a high level of confidence. Using the epipolar geometry principle, the fundamental matrix calculation determines the deviation distances of feature points within the current frame from their corresponding epipolar lines within the two frames. The more different the deviation distance, the higher the possibility that the feature point belongs to an object that is moving. In multi-view geometry constraints, epipolar geometry is used to analyze whether feature points tend to be static or dynamic. In general, only static elements satisfy the epipolar constraint. As shown in
Figure 3:
P: The map point detected in adjacent frames and by the camera at the same position;
: The map point where map point P is moved;
: This image shows map point P within frame ;
: This image shows map point P within frame ;
and : These are the optical centres of frames and ;
Baseline: The line connecting the optical centers and ;
Epipole (): The point at which the baseline intersects with the image planes and , respectively;
Epipolar Plane: The plane is determined by the baseline and the map point P;
Epipolar Lines (): The lines are formed by the epipolar plane intersecting the image planes and ;
: The lines are formed by the epipolar plane intersecting the image planes and .
The
, and
homogeneous coordinates are defined as
, and
, as follows:
The image pixel coordinate system is used to represent the coordinate values of the feature points as x and y.
The following formula can be used to calculate the epipolar line
of the current frame, with the fundamental matrix
being calculated from the optical flow pyramid:
Next, the offset distance
D is defined as the distance between the feature point
and its corresponding epipolar line. The expression of the offset distance is as below:
If the feature point
P is stationary, the offset distance should be zero. However, due to noise and other uncertainties, the offset distance is usually non-zero, though it remains under the empirically determined threshold, denoted by the symbol
. As shown in
Table 1, for the empirical threshold
, usually if the threshold
is too large, when the
is greater than 0.6 the system cannot recognize too many dynamic feature points, resulting in a large pose error, affecting the overall pose estimation of the system. If the
is set too small, some static feature points will be regarded as dynamic feature points and removed, resulting in too few feature points, and a large number of available static feature points will be mistakenly removed, which will affect the subsequent local mapping. Therefore, we finally chose a threshold of 0.4, which can not only not affect the overall pose estimation but also ensure that there are enough available feature points. When point
P moves to point
, the calculated value of
D is usually larger compared to the empirical threshold
. As shown in
Figure 3a, the red line denotes the offset distance
D. It is impossible to determine whether or not a feature point is moving based on visual reprojection error when it moves in the direction of the epipolar line. If, in
Figure 3b, feature point
P moves along the extension line of
, when point
P moves to
, the projection point on the polar plane is
, and
is still on epipolar line
. Calculating
D using Formula (3) gives a value of zero, but in this special case the visual reprojection error actually degrades and fails.
3.4. Dynamic Object Removal Strategy
In reality, all objects can be categorized as either dynamic or static. If only object detection is performed, for a person sitting quietly on a chair, object detection will, based on prior information, most likely regard it as a dynamic object and filter out feature points that can be used for local mapping. Or, if a person is walking and holding a book, the book is in dynamic motion at that moment. If such potential dynamic objects are not correctly filtered out, it will affect the subsequent pose estimation. Our approach is to first filter out dynamic objects and potential dynamic objects using dynamic prior information by using the object detection thread. As shown in
Figure 2, different weight values are assigned to different objects. The probability of being judged as dynamic increases with the size of the value.
The Optical Flow Pyramid is used to establish a relatively reliable fundamental matrix, which is then employed to detect if feature points are moving or stationary. If the dynamic feature points of the epipolar geometry test overlap with the results of the object detection as dynamic objects, they can be judged as dynamic. A relatively reliable fundamental matrix can be employed to extract dynamic feature points from potential dynamic objects by applying limit constraints.
The specific dynamic feature point Culling algorithm is shown in Algorithm 1.
| Algorithm 1 Dynamic Object Culling Algorithm |
- Input:
Previous frame’s feature points, ; Current frame’s feature points, ; Previous frame’s static feature points, ; Current frame’s static feature points, ; Previous frame, ; Current frame, ; Dynamic object culling threshold, ; Number of feature points threshold, ; - Output:
The set of dynamic feature points in the current frames, ; - 1:
; - 2:
Culling dynamic feature points at the edges; - 3:
for each matched pair in do - 4:
if ) then - 5:
Append - 6:
end if - 7:
- 8:
end for - 9:
if then - 10:
; - 11:
else if then - 12:
; - 13:
end if - 14:
for each matched pair in do - 15:
if () then - 16:
Append to - 17:
end if - 18:
end for
|
3.5. Position Estimation Using IMU Pre-Integration
There are still significant limitations when using only a camera as a sensor. As a low-frequency observation device, cameras can provide rich visual information, but the quality of their data is limited by external lighting conditions and highly dynamic scenes. The effectiveness of visual information is significantly reduced, greatly reducing the robustness of SLAM systems. Additionally, pure vision may also suffer from the phenomenon of feature point degradation along polar lines. In contrast, IMU observations have a higher frequency, which can partially bridge the gaps between discrete visual observation frames and enhance the direct correlation between frames. As a sensor sensitive to internal states, IMU observations generally do not change significantly due to the appearance of external moving objects, even when visual reprojection degrades, providing a good complement to visual sensors. However, IMUs also have their own issues, such as long-term drift and error accumulation. These issues prevent IMU from being used alone for long-term pose estimation, necessitating the continuous calibration of IMU parameters and estimation results using visual data.
The following equation shows that, in frame i, when there are sufficient feature points, the visual odometer can function normally, and the camera coordinates
can be obtained through the world coordinate system
and the transformation matrix
to obtain a relatively accurate
. The specific formula is as follows:
If there are too many dynamic objects or insufficient light, causing the camera to collect too few feature points, it is impossible to determine in the above equation, and using only the visual sensor may cause the pose estimate for the current frame to fail. If visual loss tracking is lost, the pre-integration of the IMU can be used to calculate the camera’s current position.
As shown in
Figure 4, between two successive keyframes k = i and k = j, the iteration interval of the IMU between the two keyframes is
, which is shorter than the iteration time of the keyframes. The IMU data are relatively reliable in the short term. Due to the short IMU iteration interval, we assume that the error in the pre-integration process can be ignored. The definitions of short-term rotation, velocity, and position increments are from [
37], as shown below:
Visual inertial tight coupling optimization can be regarded as a minimum optimization problem for keyframes: each frame contains rotation, translation, velocity, gyroscope, and accelerometer, and a set of k + 1 frame state values is given as follows:
A set of
l three-dimensional point state values is also given:
The final error (reprojection error and inertial residual) is expressed by the following equation, which is given in reference [
3]:
where
denotes the visual reprojection error and
denotes the robust kernel function, which serves to regulate the visual reprojection error, where
denotes the inertial residual, as expressed in [
3] as follows:
is a set of keyframes of the observed 3D points. If the visual reprojection error is large, the overall error will also be large, affecting the system’s overall accuracy. Through the adjustment of the kernel function , this error can be reduced when the visual error is large.
3.6. Dense Octree Semantic Mapping
ORB-SLAM3 itself has the function of constructing sparse point cloud maps. Although computationally efficient, the resulting sparse point clouds lack detailed environmental information and are unsuitable for applications requiring high-precision surface reconstruction or dense mapping. In addition, the original mapping function has limited robustness in dynamic environments. LVID-SLAM employs dense octree maps for semantic mapping while retaining the sparse point cloud maps provided by ORB-SLAM3. Octree mapping divides three-dimensional space into progressively smaller voxels through recursive division. Unoccupied empty areas can be skipped directly, saving storage and computing resources.
The octree only stores information about occupied or regions of interest, while unoccupied space is represented at a lower resolution, avoiding wasted storage space. The octree allows for real-time dynamic updates to the map, making it useful for robotic mapping and exploration in dynamic scenes. Octree nodes can be merged when sensor data are updated, and the octree can dynamically insert, delete, or update point cloud data to adapt to dynamically changing environments.
The octree map contains semantic information passed by the object detection thread. Semantic information is associated with the bounding box regions. In LVID-SLAM, dense mapping does not use every frame of the image but instead maps based on keyframes generated by the tracking thread, significantly improving mapping efficiency. First, ordered 3D points are generated based on the transformation matrix of the keyframes and depth image. Depth values that are not within the preset threshold range are discarded, and the remaining point cloud generates a local point cloud map. Next, the octree map is integrated with semantic data from the object recognition thread. To remove dynamic object point clouds, the current pixel is determined to be inside or out of the dynamic object detection box, and only pixels outside the detection box are used for mapping. Then, the local point cloud is converted and updated to the octree map. The map is voxel-filtered to optimize noise and reduce point cloud density. Statistical filtering is used to calculate the standard deviation and average value of the neighborhood of points in the point cloud. To optimize point cloud quality, outlier points exceeding the threshold are removed. After constructing the octree map, a semantic mapping is created with semantic information, and objects detected by object detection are displayed by cubes of different colors. The center of gravity coordinates of different semantic objects are obtained through a 3D point cloud, and finally, the processed octree map and semantic map are converted to ROS format for publication.







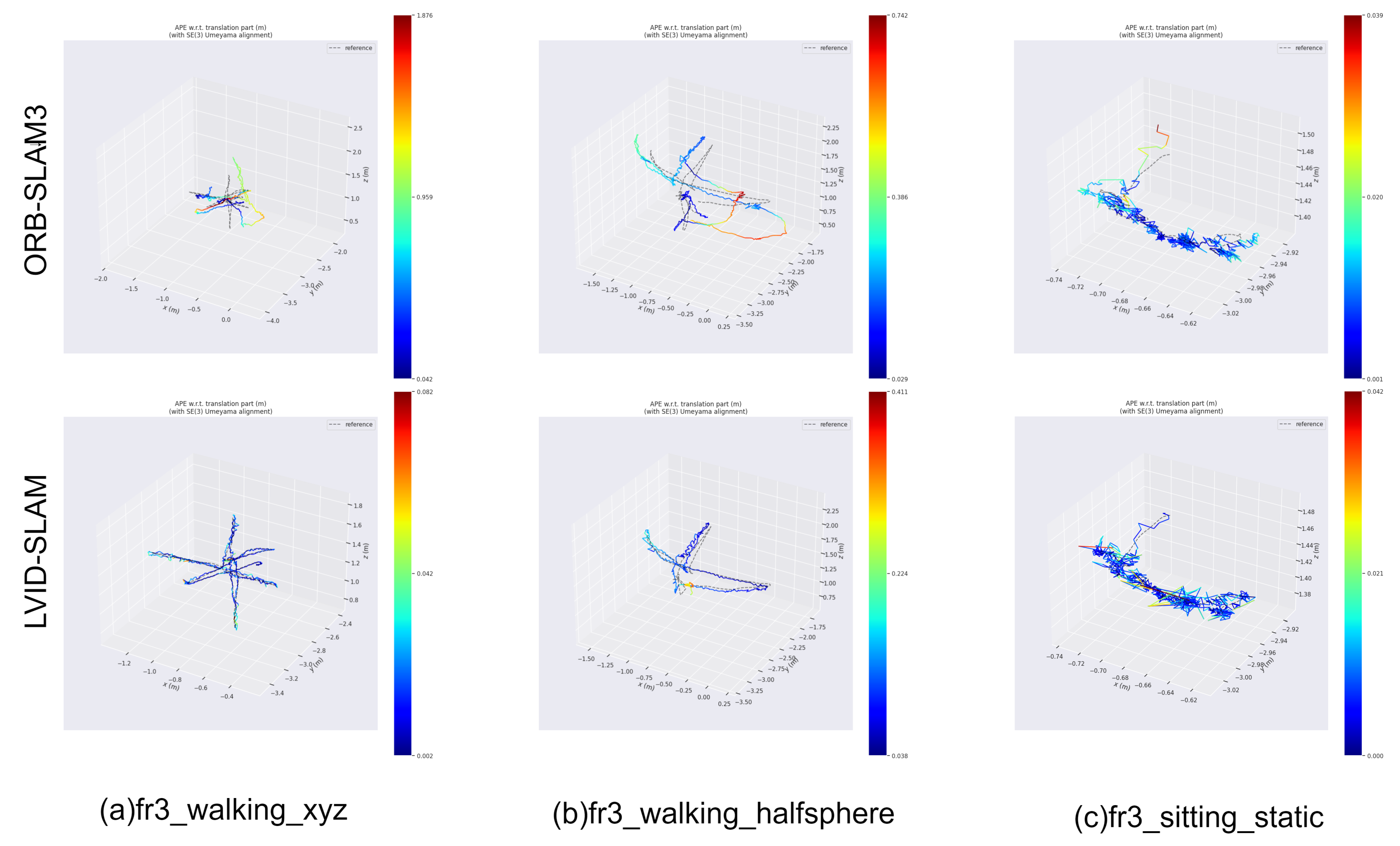







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}