
Unified Probabilistic and Similarity-Based Position Estimation from Radio Observations



Abstract
1. Introduction
1.1. Background
1.2. Scope
1.3. Related Work
1.4. Outline
2. Context
2.1. Existing Particle Filter System
2.2. Optimized Log-Distance Model
2.3. Binned Skew Normal FTM Model
3. Proposed Methodology
3.1. Fingerprints and Radio Observation Preprocessing
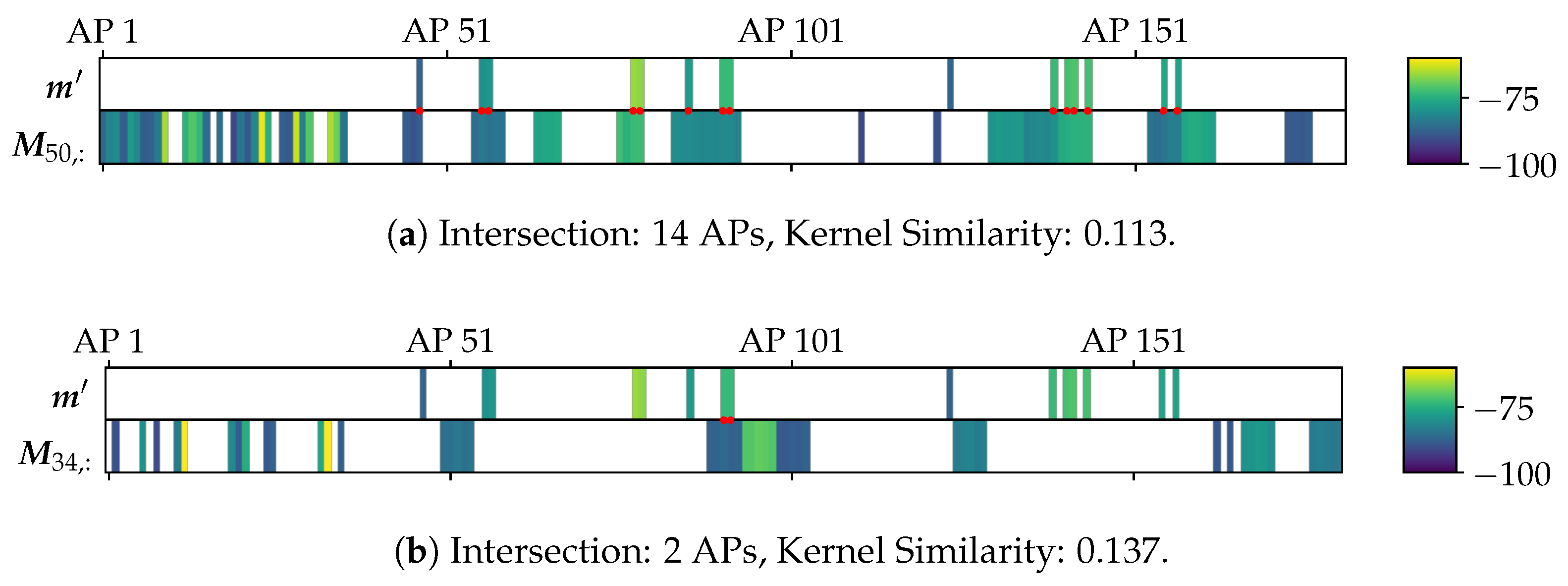
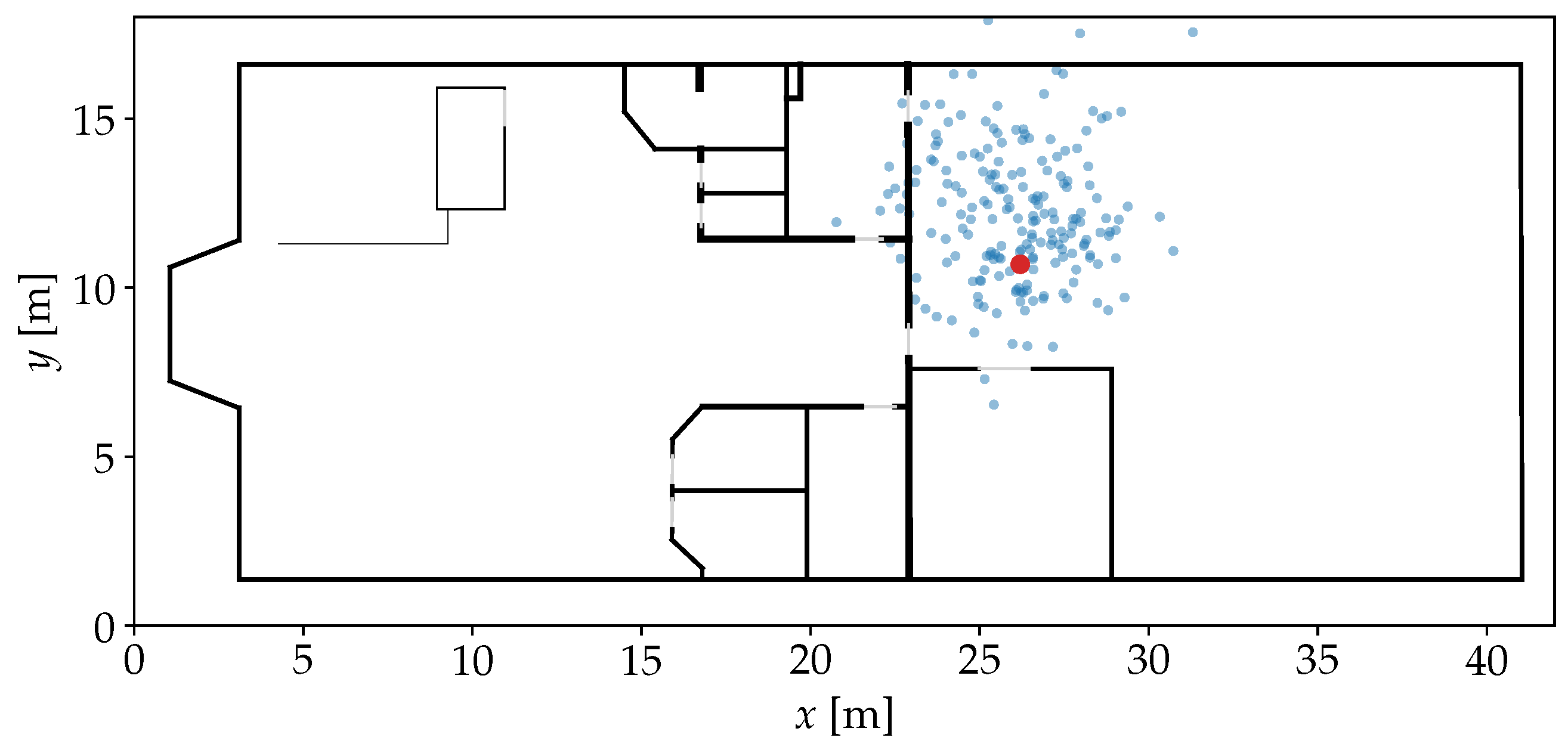
3.2. Observation Comparison with a Kernel Function
3.3. Position Density Estimation
3.3.1. Kernel Density Estimation
3.3.2. Dirichlet Process Gaussian Mixture Model
4. Experiments and Results
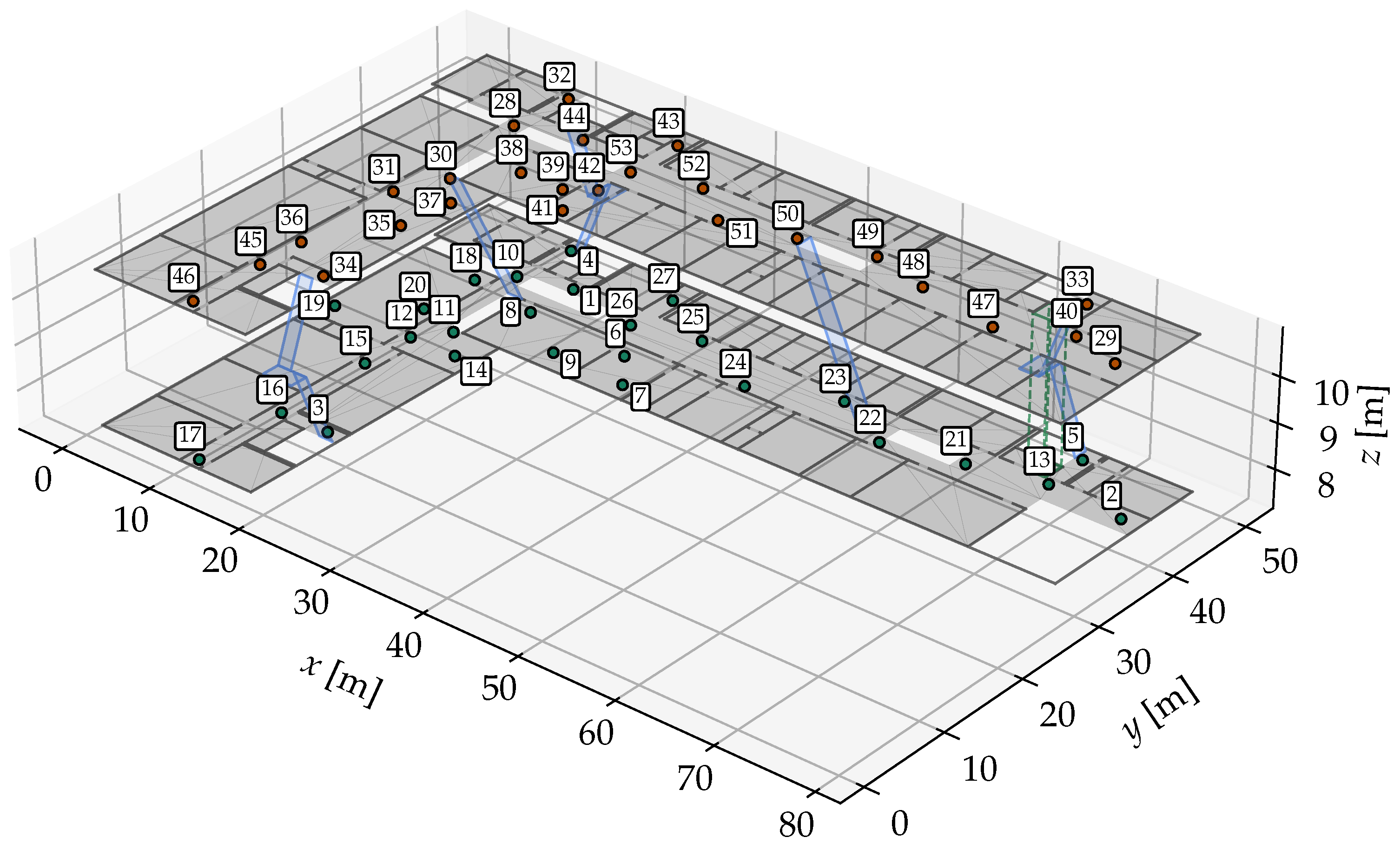
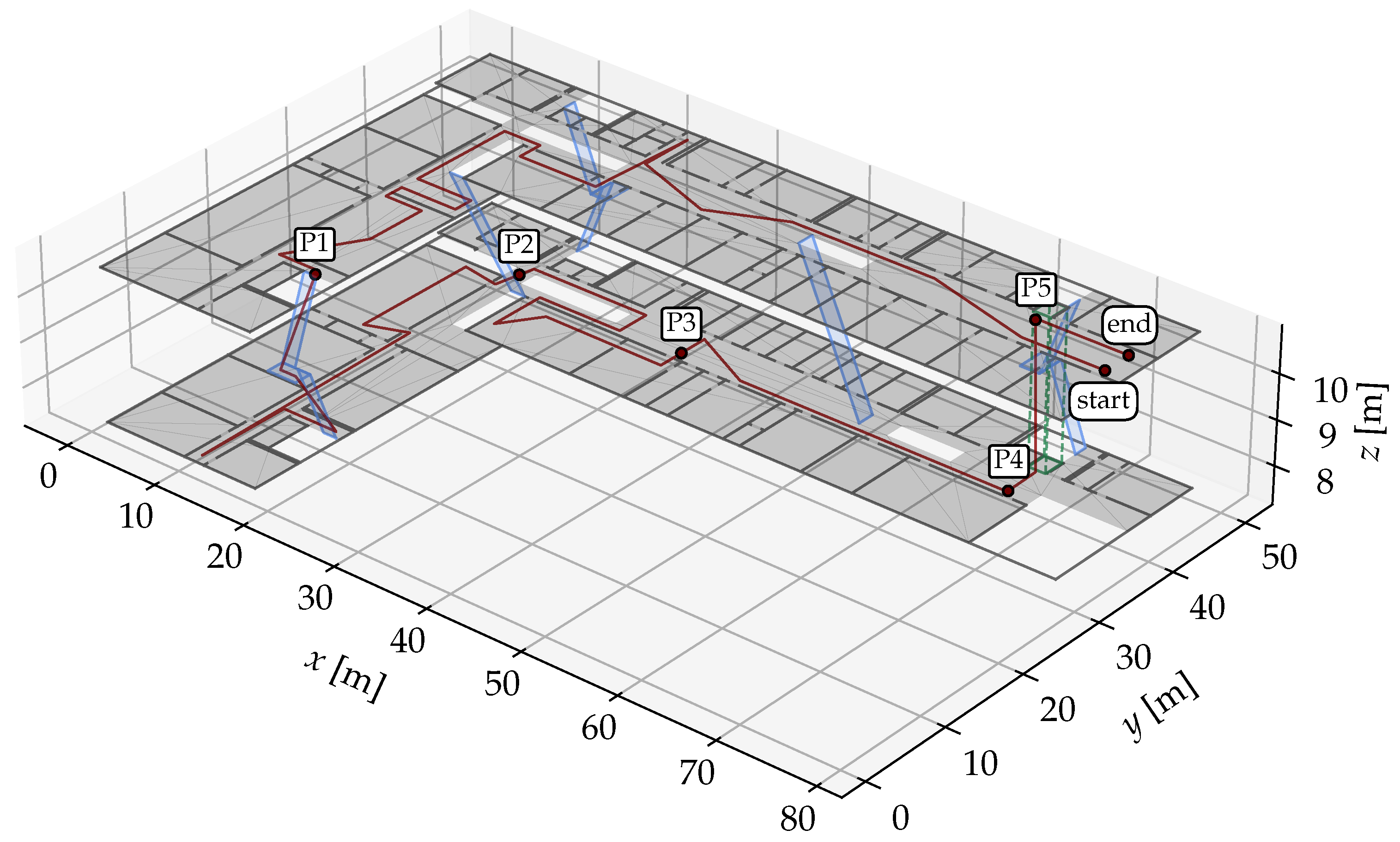
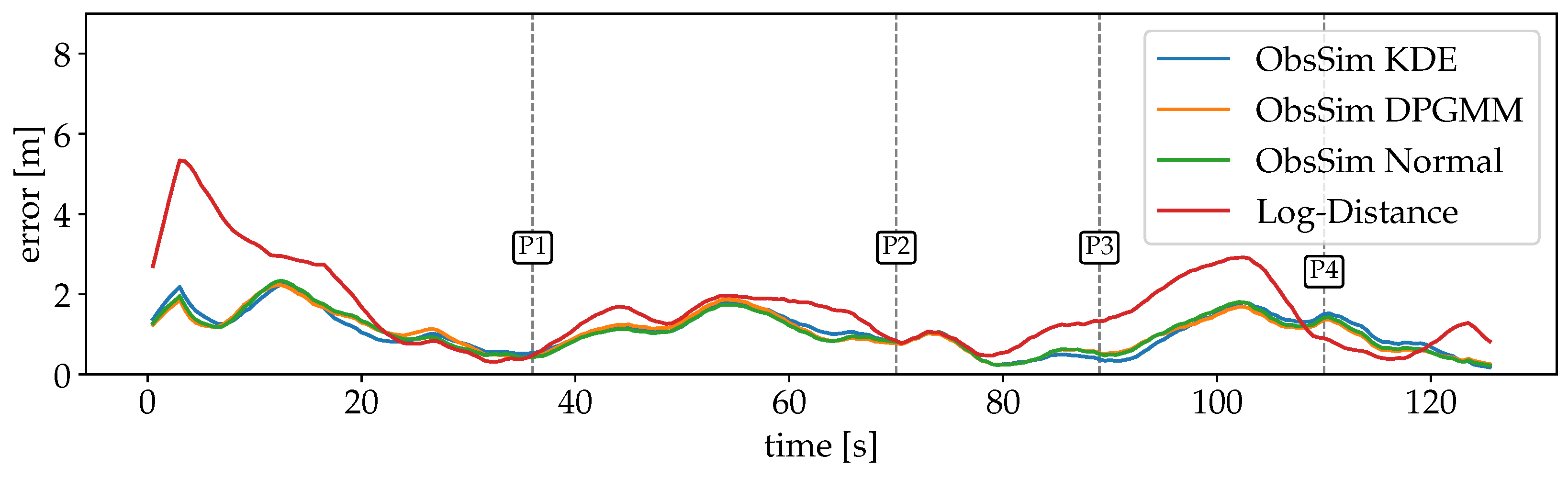
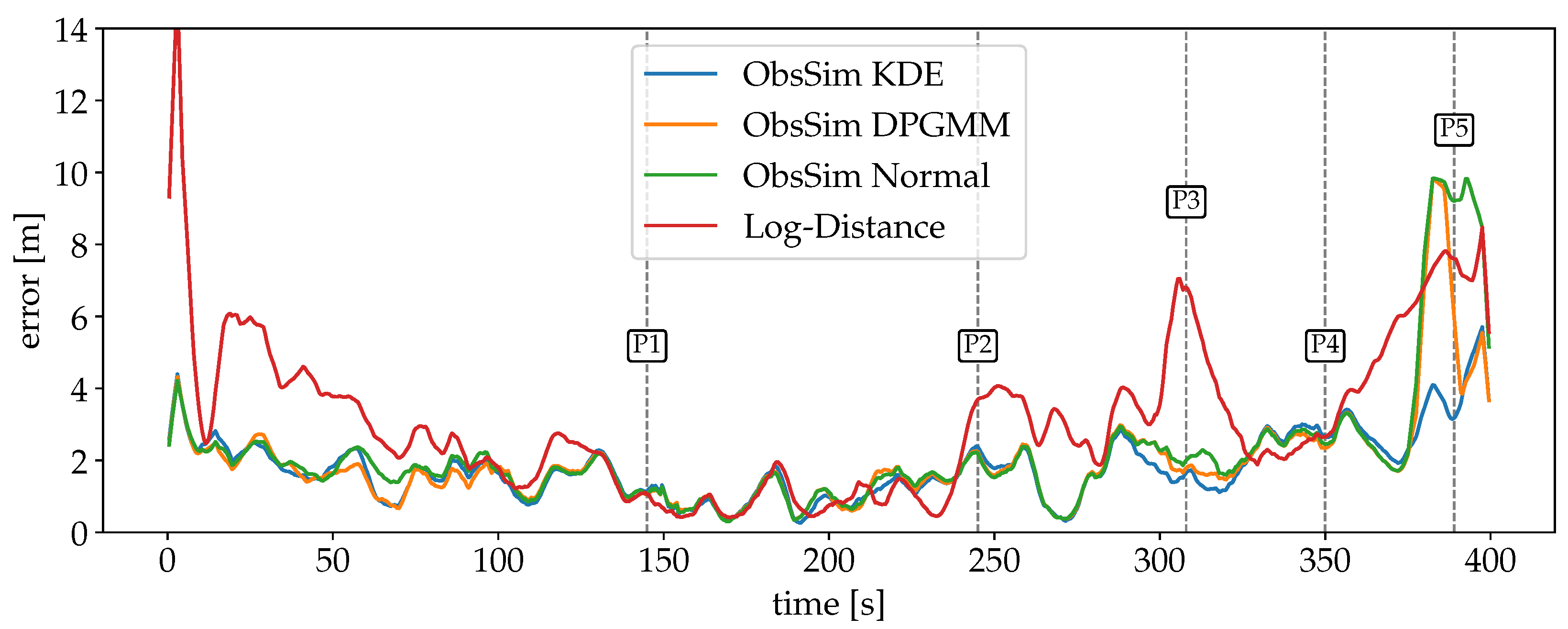
4.1. Setup and Evaluation Criteria
4.2. Experiment Scenarios
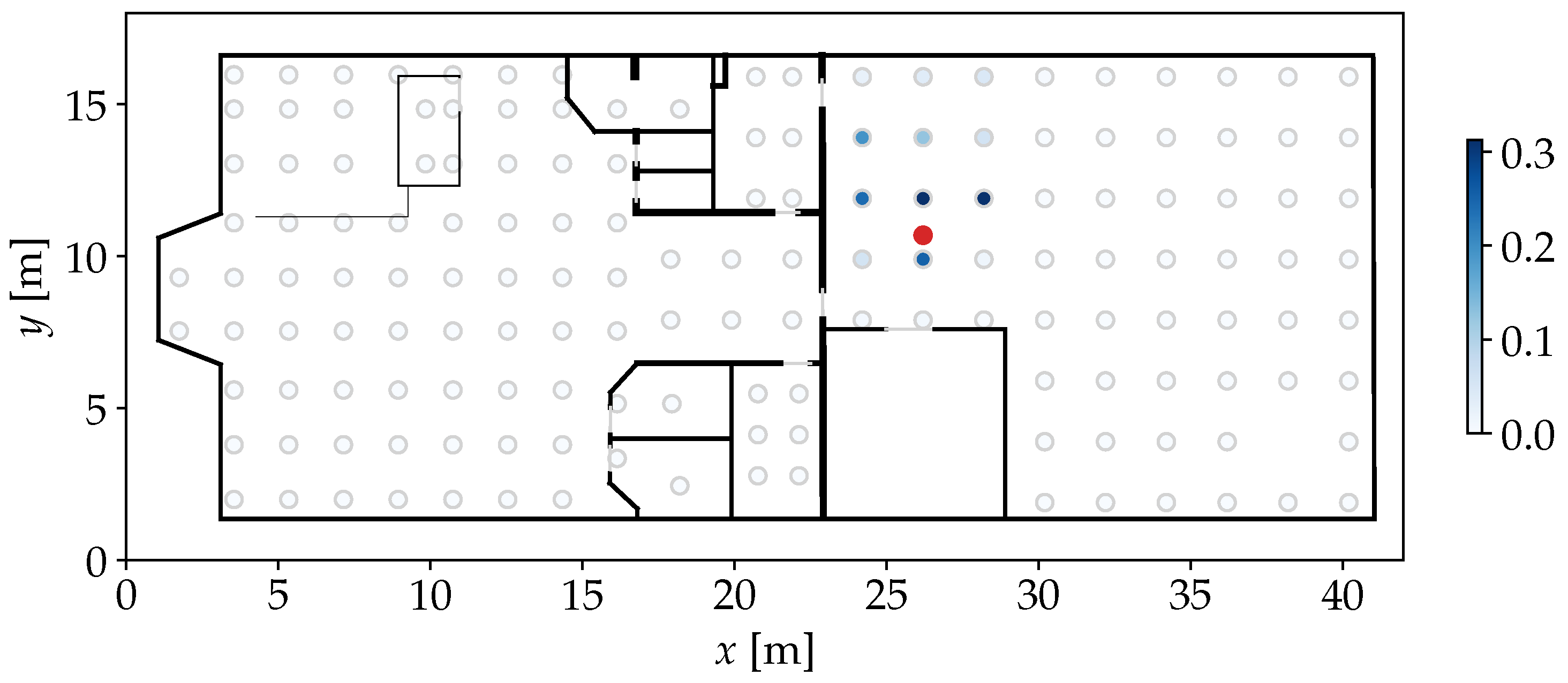
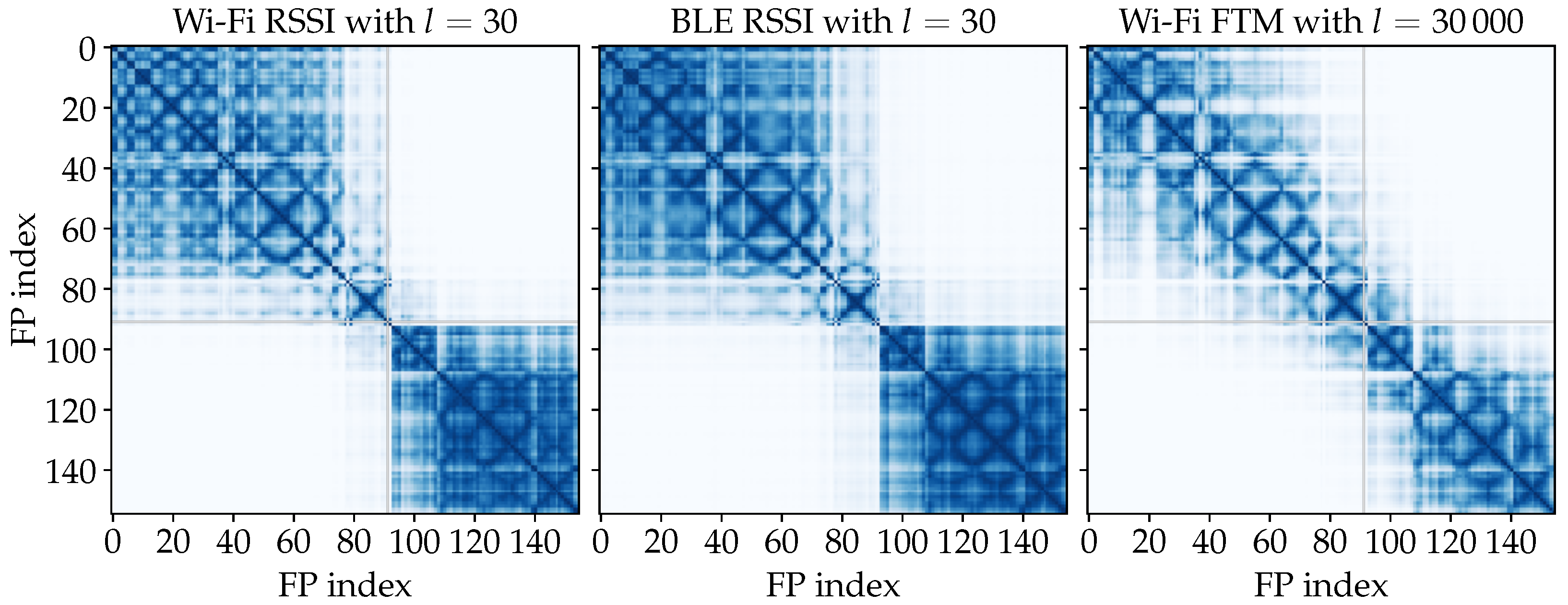
4.3. Preliminary Analysis
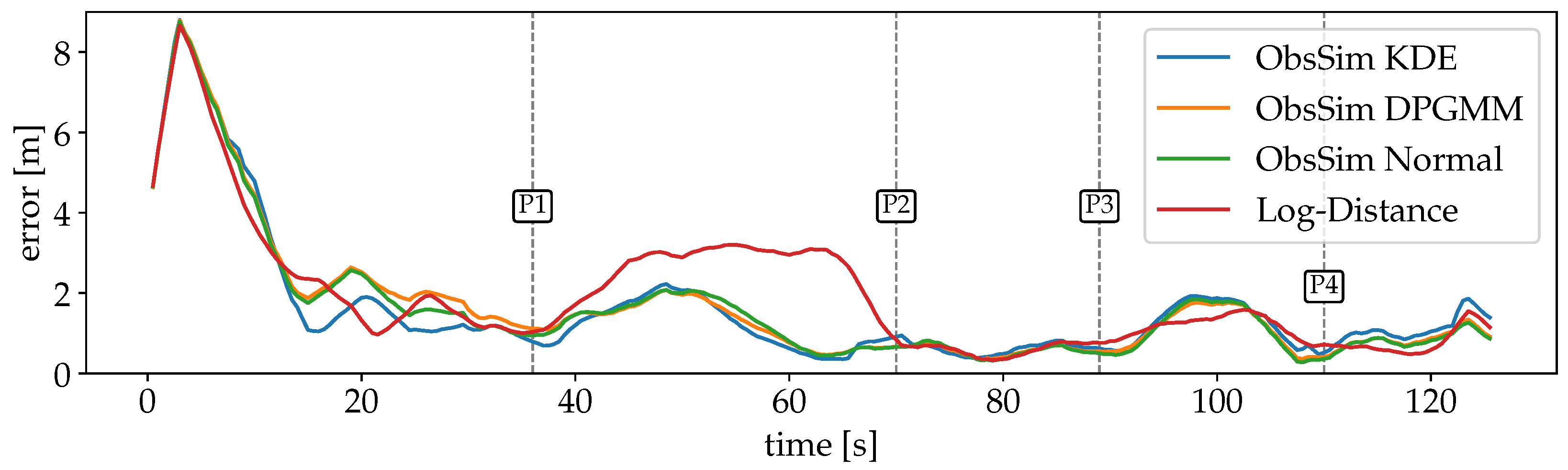
4.4. Discussion of the Results
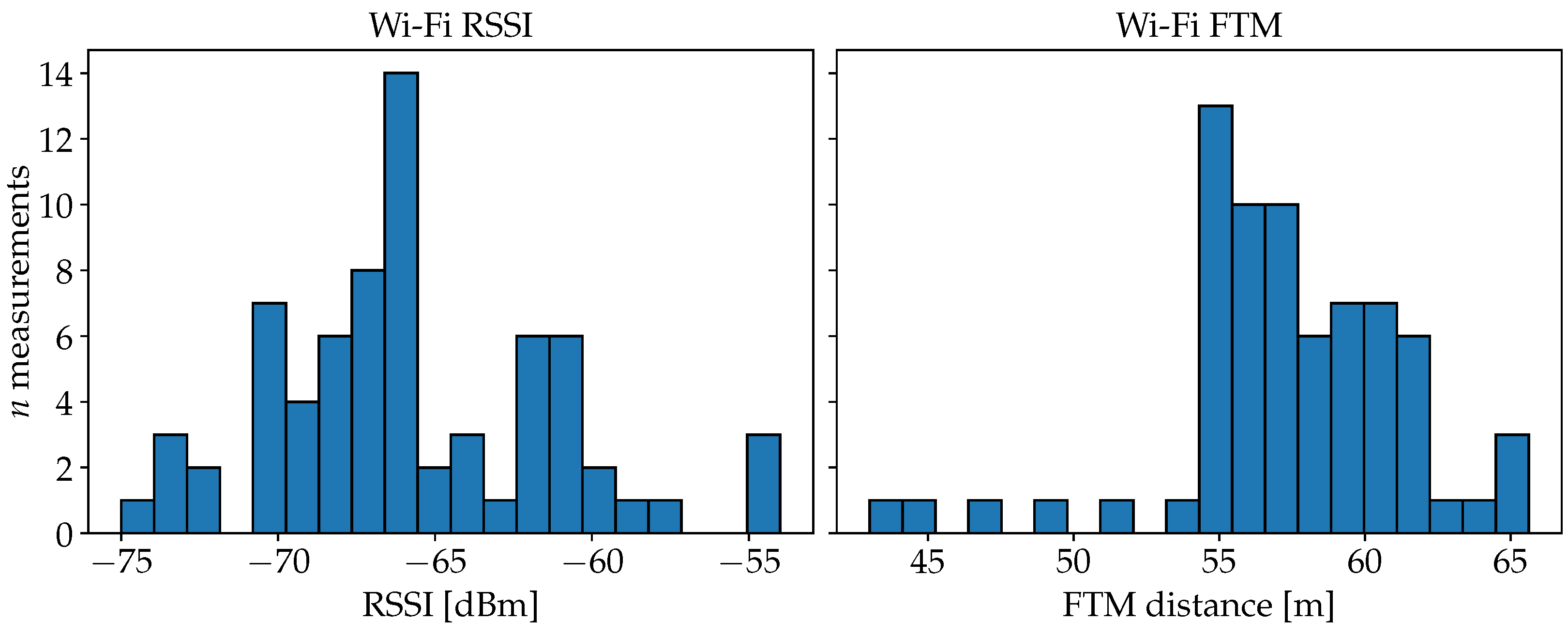
4.4.1. Radio Signal Strength for Wi-Fi and BLE
4.4.2. Fine Timing Measurement for Wi-Fi
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hegarty, C.J.; Chatre, E. Evolution of the Global Navigation SatelliteSystem (GNSS). Proc. IEEE 2008, 96, 1902–1917. [Google Scholar] [CrossRef]
- Gustafsson, F.; Gunnarsson, F.; Bergman, N.; Forssell, U.; Jansson, J.; Karlsson, R.; Nordlund, P.J. Particle filters for positioning, navigation, and tracking. IEEE Trans. Signal Process. 2002, 50, 425–437. [Google Scholar] [CrossRef]
- Bullmann, M.; Fetzer, T.; Ebner, F.; Ebner, M.; Deinzer, F.; Grzegorzek, M. Comparison of 2.4 GHz WiFi FTM- and RSSI-Based Indoor Positioning Methods in Realistic Scenarios. Sensors 2020, 20, 4515. [Google Scholar] [CrossRef] [PubMed]
- Bahl, P.; Padmanabhan, V. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No.00CH37064), Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar] [CrossRef]
- Torres-Sospedra, J.; Montoliu, R.; Trilles, S.; Belmonte, Ó.; Huerta, J. Comprehensive analysis of distance and similarity measures for Wi-Fi fingerprinting indoor positioning systems. Expert Syst. Appl. 2015, 42, 9263–9278. [Google Scholar] [CrossRef]
- Sun, W.; Xue, M.; Yu, H.; Tang, H.; Lin, A. Augmentation of Fingerprints for Indoor WiFi Localization Based on Gaussian Process Regression. IEEE Trans. Veh. Technol. 2018, 67, 10896–10905. [Google Scholar] [CrossRef]
- Torres-Sospedra, J.; Silva, I.; Pendão, C.; Meneses, F.; Moreira, A. Hyperparameterless k-NN for Wi-Fi Fingerprinting. In Proceedings of the 2024 International Conference on Localization and GNSS (ICL-GNSS), Antwerp, Belgium, 25–27 June 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Std 802.11-2020; IEEE Standard for Information Technology—Telecommunications and Information Exchange between Systems-Local and Metropolitan Area Networks—Specific Requirements-Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications. IEEE: Piscataway Township, NJ, USA, 2021; pp. 1–4379. [CrossRef]
- Guo, G.; Chen, R.; Ye, F.; Peng, X.; Liu, Z.; Pan, Y. Indoor Smartphone Localization: A Hybrid WiFi RTT-RSS Ranging Approach. IEEE Access 2019, 7, 176767–176781. [Google Scholar] [CrossRef]
- Horn, B.K.P. Round-Trip Time Ranging to Wi-Fi Access Points Beats GNSS Localization. Appl. Sci. 2024, 14, 7805. [Google Scholar] [CrossRef]
- Jimenez, A.; Seco, F.; Prieto, C.; Guevara, J. A comparison of Pedestrian Dead-Reckoning algorithms using a low-cost MEMS IMU. In Proceedings of the 2009 IEEE International Symposium on Intelligent Signal Processing, Budapest, Hungary, 26–28 August 2009; pp. 37–42. [Google Scholar] [CrossRef]
- Chen, Z.; Zou, H.; Jiang, H.; Zhu, Q.; Soh, Y.C.; Xie, L. Fusion of WiFi, Smartphone Sensors and Landmarks Using the Kalman Filter for Indoor Localization. Sensors 2015, 15, 715–732. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhou, B.; Huang, P.; Xue, W.; Li, Q.; Zhu, J.; Qiu, L. Kalman Filter-Based Data Fusion of Wi-Fi RTT and PDR for Indoor Localization. IEEE Sens. J. 2021, 21, 8479–8490. [Google Scholar] [CrossRef]
- Harle, R. A Survey of Indoor Inertial Positioning Systems for Pedestrians. IEEE Commun. Surv. Tutor. 2013, 15, 1281–1293. [Google Scholar] [CrossRef]
- Fetzer, T.; Ebner, F.; Bullmann, M.; Deinzer, F.; Grzegorzek, M. Smartphone-Based Indoor Localization within a 13th Century Historic Building. Sensors 2018, 18, 4095. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Hwang, B.; Jeong, J.P. Particle Filtering-Based Indoor Positioning System for Beacon Tag Tracking. IEEE Access 2020, 8, 226445–226460. [Google Scholar] [CrossRef]
- Zou, H.; Chen, Z.; Jiang, H.; Xie, L.; Spanos, C. Accurate indoor localization and tracking using mobile phone inertial sensors, WiFi and iBeacon. In Proceedings of the 2017 IEEE International Symposium on Inertial Sensors and Systems (INERTIAL), Kauai, HI, USA, 28–30 March 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Nguyen, D.V.; Charette, R.D.; Nashashibi, F.; Dao, T.K.; Castelli, E. Wifi fingerprinting localization for intelligent vehicles in car park. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Isard, M.; Blake, A. CONDENSATION—Conditional Density Propagation for Visual Tracking. Int. J. Comput. Vis. 1998, 29, 5–28. [Google Scholar] [CrossRef]
- Friis, H. A Note on a Simple Transmission Formula. Proc. IRE 1946, 34, 254–256. [Google Scholar] [CrossRef]
- Ebner, F.; Fetzer, T.; Deinzer, F.; Grzegorzek, M. On Wi-Fi Model Optimizations for Smartphone-Based Indoor Localization. ISPRS Int. J. Geo-Inf. 2017, 6, 233. [Google Scholar] [CrossRef]
- Bullmann, M.; Fetzer, T.; Ebner, M.; Kastner, S.; Deinzer, F.; Grzegorzek, M. Data Driven Sensor Model for Wi-Fi Fine Timing Measurement. In Proceedings of the 2022 IEEE 12th International Conference on Indoor Positioning and Indoor Navigation (IPIN), Beijing, China, 5–8 September 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef]
- Roos, T.; Myllymäki, P.; Tirri, H.; Misikangas, P.; Sievänen, J. A probabilistic approach to WLAN user location estimation. Int. J. Wirel. Inf. Netw. 2002, 9, 155–164. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Moon, T. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Teh, Y.W. Dirichlet process. Encycl. Mach. Learn. 2010, 1063, 280–287. [Google Scholar]
- Blei, D.M.; Jordan, M.I. Variational inference for Dirichlet process mixtures. Bayesian Anal. 2006, 1, 121–143. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ObsSim | Log-Dist | ||||
|---|---|---|---|---|---|
| l | h | ||||
| Scenario | all | KDE | KDE | DP./Norm. | - |
| #1 (Wi-Fi) | 3.0 | 0.5 | 5.0 | 5.0 | 3.0 |
| #1 (BLE) | 3.0 | 0.5 | 12.0 | 8.0 | 5.0 |
| #2 (Wi-Fi) | 12.0 | 0.5 | 7.0 | 5.0 | 7.0 |
| Result | Mean | Median | 75 % Qnt. | 90 % Qnt. | Std. Dev. |
|---|---|---|---|---|---|
| ObsSim KDE | 1.65 | 1.03 | 1.86 | 2.89 | 1.86 |
| ObsSim DPGMM | 1.70 | 1.23 | 1.86 | 2.89 | 1.83 |
| ObsSim Normal | 1.66 | 1.18 | 1.86 | 2.77 | 1.83 |
| Log-Distance | 1.97 | 1.38 | 2.71 | 3.28 | 1.79 |
| Result | Mean | Median | 75 % Qnt. | 90 % Qnt. | Std. Dev. |
|---|---|---|---|---|---|
| ObsSim KDE | 1.07 | 1.05 | 1.43 | 1.82 | 0.58 |
| ObsSim DPGMM | 1.07 | 1.02 | 1.38 | 1.78 | 0.56 |
| ObsSim Normal | 1.06 | 0.98 | 1.39 | 1.78 | 0.58 |
| Log-Distance | 1.64 | 1.42 | 2.03 | 3.10 | 1.16 |
| Result | Mean | Median | 75 % Qnt. | 90 % Qnt. | Std. Dev. |
|---|---|---|---|---|---|
| ObsSim KDE | 1.82 | 1.72 | 2.32 | 2.97 | 1.02 |
| ObsSim DPGMM | 1.95 | 1.74 | 2.28 | 2.94 | 1.48 |
| ObsSim Normal | 2.16 | 1.81 | 2.36 | 3.00 | 1.85 |
| Log-Distance | 3.13 | 2.62 | 3.99 | 6.25 | 2.44 |
| Result | Mean | Median | 75 % Qnt. | 90 % Qnt. | Std. Dev. |
|---|---|---|---|---|---|
| ObsSim KDE | 1.20 | 0.88 | 1.31 | 2.03 | 1.38 |
| ObsSim DPGMM | 1.16 | 0.88 | 1.34 | 1.80 | 1.35 |
| ObsSim Normal | 1.12 | 0.86 | 1.22 | 1.75 | 1.36 |
| FTM Distance | 2.16 | 1.72 | 3.63 | 4.00 | 1.82 |
| Binned Skew Normal | 1.88 | 1.73 | 2.39 | 3.26 | 1.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Werner, M.; Bullmann, M.; Fetzer, T.; Deinzer, F. Unified Probabilistic and Similarity-Based Position Estimation from Radio Observations. Sensors 2025, 25, 4092. https://doi.org/10.3390/s25134092
Werner M, Bullmann M, Fetzer T, Deinzer F. Unified Probabilistic and Similarity-Based Position Estimation from Radio Observations. Sensors. 2025; 25(13):4092. https://doi.org/10.3390/s25134092
Chicago/Turabian StyleWerner, Max, Markus Bullmann, Toni Fetzer, and Frank Deinzer. 2025. "Unified Probabilistic and Similarity-Based Position Estimation from Radio Observations" Sensors 25, no. 13: 4092. https://doi.org/10.3390/s25134092
APA StyleWerner, M., Bullmann, M., Fetzer, T., & Deinzer, F. (2025). Unified Probabilistic and Similarity-Based Position Estimation from Radio Observations. Sensors, 25(13), 4092. https://doi.org/10.3390/s25134092