1. Introduction
With the rapid development of autonomous driving and intelligent transportation systems, 3D object detection, as one of the core tasks in environmental perception, plays a crucial role in safe driving, path planning, and decision control. Traditional 3D object detection methods typically rely on sensors such as LiDAR [
1] and radar to acquire spatial depth information [
2,
3]. However, these sensors are often costly and may underperform in complex scenarios. Therefore, achieving efficient and accurate 3D object detection using only cameras has become an important research direction in visual perception [
4].
In purely visual 3D object detection, depth and semantic features are critical elements. Depth features, representing spatial geometric information extracted from images, reflect objects’ shape, position, and relative distance to the camera. While depth features are essential for 3D localization, geometric information alone often lacks semantic understanding, making it difficult to distinguish between different object categories or scene elements accurately. On the other hand, semantic features represent the category, structure, and contextual information of objects in the image, helping the detection system recognize the type of objects and their contextual relationships within the scene. Therefore, effectively fusing depth and semantic features is key to improving the performance of 3D object detection.
Existing methods that primarily utilize depth features can be divided into two categories: explicit extraction methods, represented by [
5,
6,
7,
8,
9], and transformer-based methods, defined by [
10,
11,
12]. Explicit extraction methods model images’ depth distribution by predicting each pixel’s depth information, allowing a more accurate estimation of the scene’s geometric structure. However, these methods often overlook the importance of semantic information in object detection tasks, failing to fuse depth distribution with semantic information, which limits feature utilization and detection accuracy. On the other hand, transformer-based methods embed 3D information into the model through positional encoding without explicitly predicting depth information, simplifying the model structure. However, the high memory consumption due to the quadratic complexity of transformers remains unresolved, and the lack of explicit depth prediction results in lower accuracy for long-range object detection. Additionally, constrained by traditional convolutional attention mechanisms, existing methods cannot fully exploit long-range dependencies and cross-feature information in images, limiting the extraction of high-precision features.
Meanwhile, transformers have undeniable advantages in handling temporal issues in 3D object detection tasks. Unlike traditional convolutional neural networks (CNNs), self-attention mechanisms can effectively capture global dependencies in images, and temporal attention modules such as [
13] can efficiently process temporal information in dynamic scenes, giving them unique advantages in complex tasks like multi-view fusion and cross-frame object tracking. However, challenges such as high computational complexity, insufficient spatial local feature extraction, and limited modeling capability for long-term temporal information remain significant obstacles in current applications.
In recent years, architectures based on state space models (SSMs) [
14] have provided new insights into addressing these issues. Compared to the quadratic complexity of traditional transformer models, ref. [
14] reduces computational complexity to O(N) through structured state space and selective scanning mechanisms, enabling lower-cost processing of ultra-long sequences (e.g., tens of thousands of tokens). This characteristic offers significant advantages in tasks requiring long-term historical memory. However, since [
14] is primarily designed for sequence modeling, it lacks explicit modeling capabilities for spatial local correlations and spatial positional information. Although images can be flattened into sequences for processing [
15], this operation disrupts the spatial structure of images, making it difficult for the model to capture local features and geometric structures effectively.
We adopt the convolutional layer design from [
16] while innovatively incorporating a feature scaling function layer and proposing the Long-Range Attention (LRSA) module to better adapt to 3D object detection tasks. Furthermore, we connect multiple LRSAs in series to achieve optimal feature extraction performance. By combining LRSA with a cross-task detection head, we propose the Local Spatial Cross-task Detection Head (LSCH) architecture to replace conventional feature extraction tasks. LSCH integrates large-kernel attention mechanisms and cross-task detection methods, utilizing multi-scale large-kernel attention mechanisms to extract image information at different scales, thereby capturing detailed and global information in images while fully exploiting long-range dependencies to establish relationships between distant pixels. This aids in understanding the overall semantics of complex images. Ultimately, multi-task distillation generates depth predictions and semantic features carrying cross-task information. Additionally, this paper proposes a Long-Temporal Perception Module (LTPM) to extract and fuse temporal details in images. Drawing inspiration from the module architecture of [
17], we innovatively adapt this framework to the domain of 3D object detection by integrating conventional linear attention mechanisms with Mamba. Considering that recursive computation of state matrices is not ideal for visual models, we use positional encoding to replace recursive computation, allowing it to function as a state matrix in visual tasks. This achieves the goal of adapting to non-causal data like images while extracting long-range spatiotemporal features.
Specifically, our contributions include the following: (1) We propose the Long-Range Cross-task Detection Head (LSCH), which combines multi-scale large-kernel convolution and cross-task information to optimize the perception of depth and semantic information in object detection tasks. (2) We propose the Long-Temporal Perception Module (LTPM), which effectively extracts and utilizes long-term temporal features in images by analyzing and combining the advantages of linear attention and Mamba, addressing the limitations of existing methods in short-term temporal feature extraction. (3) We integrate the above modules with a baseline to form a novel end-to-end 3D object detection framework, LST-BEV. Our experiments demonstrate that LST-BEV achieves a 2.1% improvement in mAP and a 2.7% improvement in NDS on the nuScenes validation dataset compared to the baseline.
This paper is structured as follows:
Section 1 states the research objectives and briefly outlines our contributions and achievements.
Section 2 reviews related work in the relevant research, covering three key areas: Vision-Based 3D Object Detection, The Image Super-Resolution Task, and Linear Attention Mechanism.
Section 3 describes our proposed methods—the Long-Range Cross-Task Detection Head (LSCH) and Long-Term Temporal Perception Module (LTPM).
Section 4 presents the datasets and experimental results used for training and comparison, including multiple comparative experiments and ablation studies, demonstrating our proposed model’s advantages. Finally,
Section 5 concludes our work with a comprehensive discussion and analysis of the limitations. We have included
Appendix A at the end of the article to explain the abbreviations and metrics used throughout the paper.
3. Method
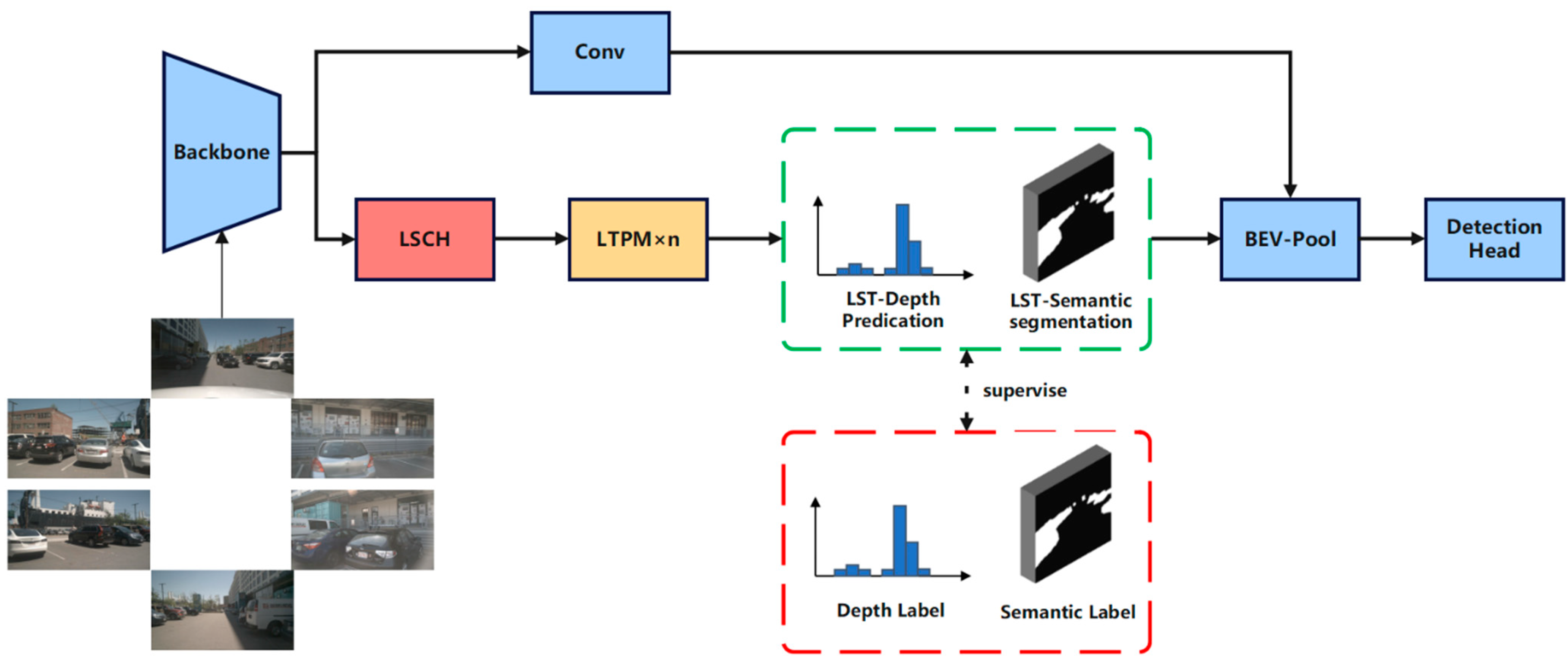
This section introduces LST-BEV, a novel multi-view 3D object detection framework designed to enhance detection performance by generating high-precision BEV features. It incorporates semantic-aware BEV pooling [
36], long-range cross-task detection heads (LSCH), and multiple long-term temporal perception modules (LTPM).
Figure 1 illustrates the overall structure of LST-BEV.
LSCH and LTPM will, respectively, extract long spatial dependencies and long temporal dependencies from the image, enhancing the model’s contextual and trend-awareness capabilities. Ultimately, they generate deep predictions with spatiotemporal features and semantic awareness, which are supervised by the projected point cloud on the image through BEVDepth. The depth values of the projected points serve as depth labels, while the points within the 3D detection box represent the foreground. The total loss is as follows:
Here, Ldet denotes the object detection loss in the detection head, LLST-D represents the depth label loss, and LLST-S corresponds to the semantic foreground loss.
BEV-Pool [
36] is a semantic-aware pooling layer that performs semantic segmentation based on the semantic information encoded in image features. It computes a foreground score for each feature, where features with lower scores are likely to contain irrelevant information for 3D object detection. During the BEV pooling process, such features are filtered out by discarding their corresponding virtual points. This mechanism ensures that only valuable foreground information and meaningful virtual points are preserved in the final BEV representation. The final depth predictions and semantic awareness are input into the BEV-Pool to generate high-precision BEV feature maps.
3.1. Long-Range Cross-Task Detection Head (LSCH)
In autonomous driving scenarios, one of the challenges faced by 3D object detection tasks is the multi-scale nature of targets and complex contextual dependencies. For example, a distant vehicle may occupy a small pixel area, while a nearby pedestrian may occupy a larger pixel area. A large receptive field is required to capture global information to detect these targets, rather than just local features accurately. Traditional convolutional neural networks, due to their fixed receptive fields and small convolution kernels, such as (3 × 3), cannot capture both local details and global context information simultaneously, leading to limited detection accuracy.
Semantic features provide high-level knowledge of 3D objects, such as category information, object properties (e.g., material, shape, etc.), and relationships with the scene. This semantic information can be shared across tasks, helping the model understand the context of objects during detection. However, experiments show that using a single branch for both semantic awareness and depth prediction results in suboptimal solutions for both tasks. Specifically, when the depth branch is used to predict semantic features, the results tend to be suboptimal, reducing the accuracy of BEV feature predictions.
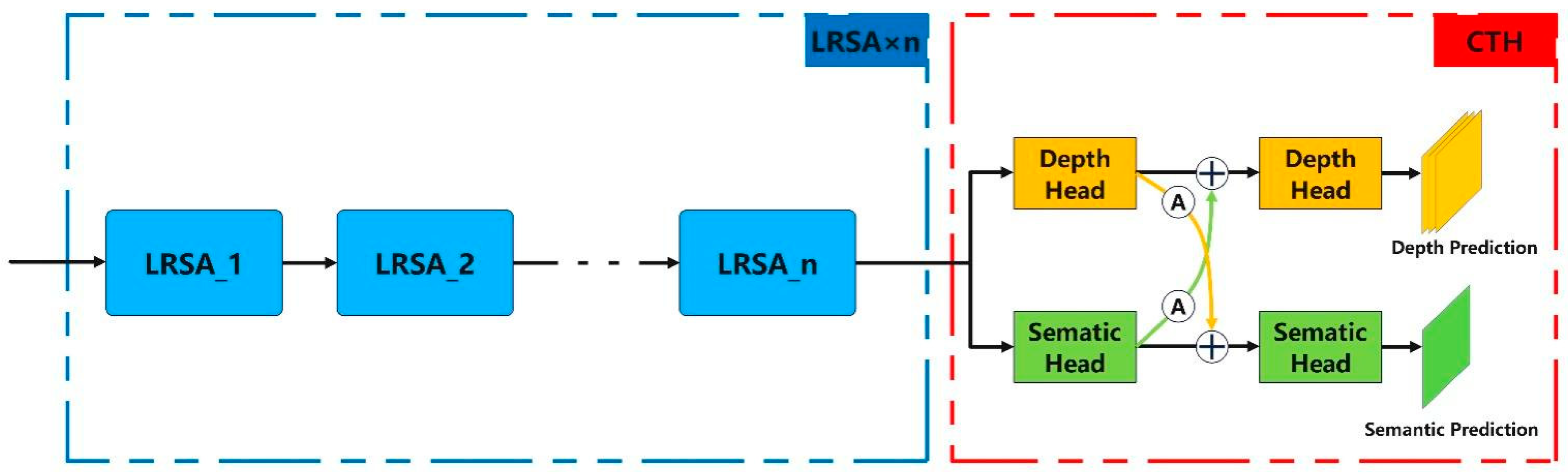
This paper improves multi-scale large-kernel convolutions to address these issues and applies them to the autonomous driving object detection domain. A Long-Range Cross-Task Detection Head (LSCH) is proposed. By leveraging the significant receptive field characteristics of large-kernel convolutions (5 × 5, 7 × 7, 9 × 9), LSCH better captures long-range dependencies and multi-scale features present in the scene while simultaneously generating high-precision depth predictions and semantic information. Specifically, LSCH consists of two main parts: multiple Long-Range Attention (LRSA) and a Cross-Task Detection Head (CTH), with the overall structure shown in
Figure 2.
LRSA, as an improved multi-scale large-kernel convolution, effectively enlarges the receptive field and captures long-range dependencies between distant regions in the image while simultaneously handling fine-grained features, alleviating the limitations of small convolution kernels. Furthermore, LRSA can flexibly adjust the size and combination of convolution kernels based on the task. By designing convolution kernels at different scales, the model can adapt to the feature extraction requirements of various tasks, making it an effective method for extracting long-range features. Cross-task detection can significantly enhance the model’s multi-tasking ability, strengthening the synergy between tasks, sharing feature representations, and improving detection accuracy. In object detection tasks, integrating and utilizing both depth predictions and semantic information is crucial for enhancing detection accuracy, improving scene understanding, and adapting to the demands of complex environments. Based on this, the proposed LSCH demonstrates significant advantages in extracting high-precision, long-range information and better meeting the needs of complex scene understanding in real-world applications.
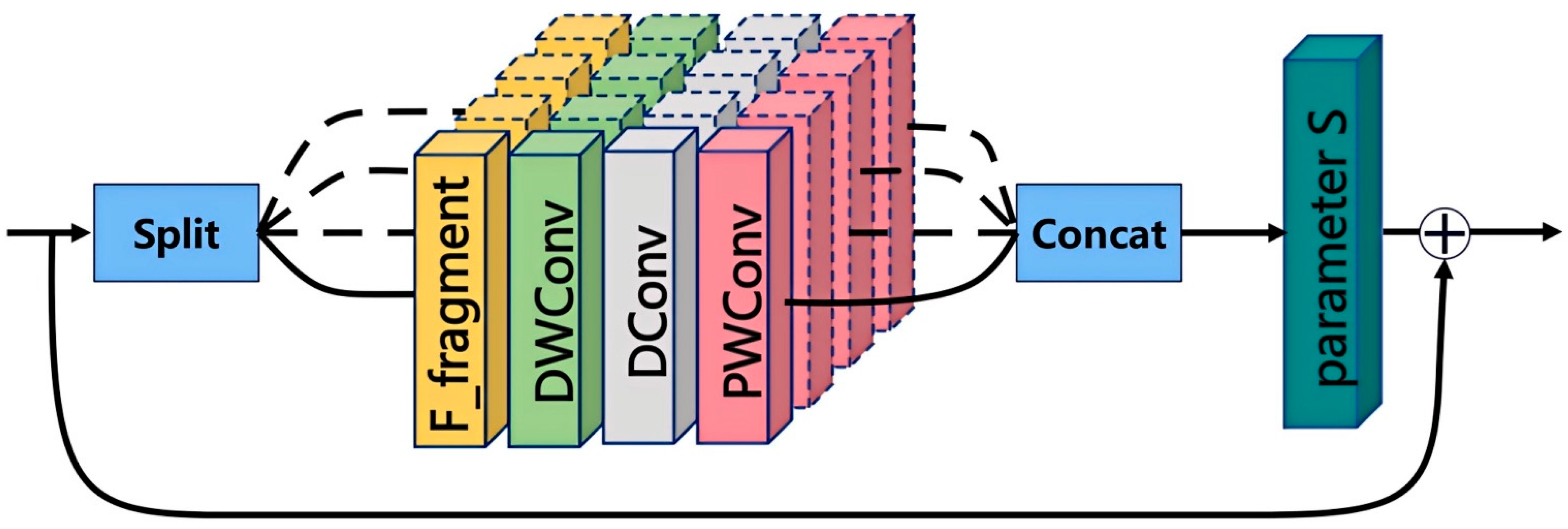
3.1.1. Long-Range Attention (LRSA)
To fully leverage the advantages of large-kernel convolutions with large receptive fields while avoiding excessive feature mixing and retaining more local features, thus enhancing multi-scale feature representation, we propose Long-Range Spatial Attention (LRSA). The core idea is to segment the input features along the channel dimension and apply convolution kernels of different sizes to sub-features at various scales, capturing global context while preserving local details. The structure of LRSA is shown in
Figure 3.
Specifically, for the input feature map
X = ℝC×H×W, LRSA splits the features along the channel dimension into
n sub-parts, denoted as
x1,
x2,
…,
x3, where each sub-part has a scale of
. Each sub-part
xi is then input into
n different large-kernel convolution blocks, denoted as LKA
n. Each LKA consists of three main components: depthwise convolution (DepthwiseConv,
fDWC()), dilated convolution (DilatedConv,
fDC()), and point-wise convolution (Point-wiseConv,
fPC()), which the following formula can express:
Specifically, we design four different scales for the LKA: {1, 3, 1}, {3, 5, 1}, {5, 7, 1}, and {7, 9, 1}, where {a, b, c} represent the kernel sizes for depthwise convolution, dilated convolution, and pointwise convolution, respectively. Larger-scale LKAs are effective at capturing long-range dependencies in features, while smaller-scale LKAs are more inclined to preserve local textures and fine details. Additionally, LRSA addresses the vanishing gradient problem in deep network training through residual connections. The final computation formula for LRSA can be expressed as
Here, S denotes the feature scaling function, and LKA(X) × S represents the scaled output of the LKA.
3.1.2. Cross-Task Detection Head (CTH)
In autonomous driving scenarios, 3D object detection tasks not only require accurate localization of the targets but also need to understand the semantic information of the objects (e.g., category, attributes, etc.) and their contextual relationships with the environment. However, traditional detection methods treat depth prediction and semantic segmentation as completely independent tasks, leading to feature extraction and utilization limitations. Research has shown that task-specific and cross-task information is crucial for obtaining a global optimal solution for multi-task learning. To address this issue, we propose the Cross-Task Detection Head (CTH), which aims to fully utilize depth perception, semantic segmentation information, and the complementary information between them through a multi-task distillation mechanism.
Specifically, the input features
F pass through detection heads for depth prediction and semantic segmentation, generating features
FD that carry depth information and
FS that carry semantic information, respectively. To achieve cross-task detection, we introduce a multi-task distillation module (MTD), which consists of several cross-attention modules, denoted as Att. Each attention module performs a weighted convolution operation to fuse the features of the two tasks, enabling the transfer and sharing of cross-task information. The attention module can be expressed as:
Here, Conv() denotes a 3 × 3 gated convolution operation; ⊙ represents element-wise multiplication; and σ refers to the Sigmoid activation function. With this design, the attention module dynamically adjusts feature weights based on the importance of the task, allowing the result to simultaneously incorporate feature information from both x and y, thereby achieving an effective fusion of cross-task information.
Based on cross-task feature fusion, CTH enables the bidirectional transfer of depth and semantic features through a multi-task distillation module. Specifically, depth feature
FD and semantic feature
FS are weighted and fused through the attention module to generate
FD_S and
FS_D, which carry cross-task information. The calculation formulas are as follows:
It is evident that CTH automatically extracts cross-task information from one task’s features using these attention modules and adds it to the features of other tasks, resulting in depth and semantic features that carry cross-task information. The fused cross-task information is then fed into their respective detection heads, which predict high-precision depth distributions and semantic segmentation. These predictions are subsequently used to generate BEV features.
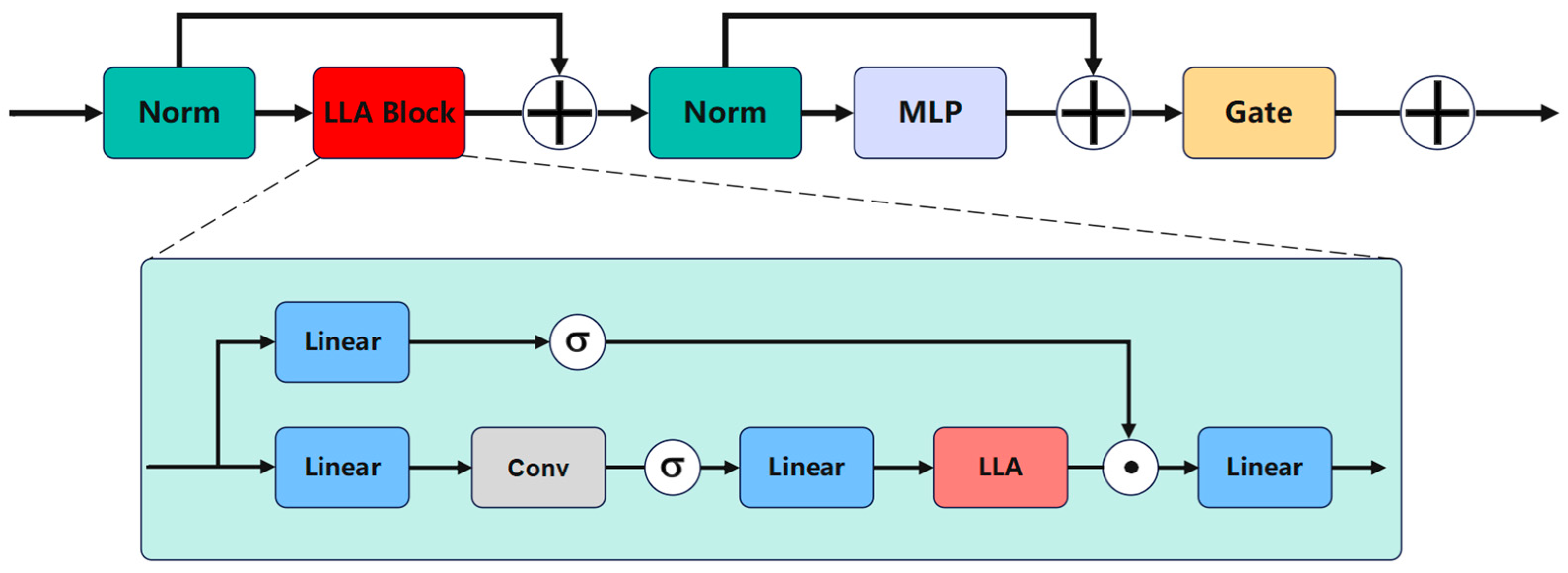
3.2. Long-Term Temporal Perception Module (LTPM)
In 3D object detection, modeling temporal information is crucial for understanding the motion trends of objects in dynamic scenes. Traditional convolutional neural networks (CNNs) and transformers have certain limitations when handling long-term temporal information: CNNs have a limited receptive field, making it challenging to capture long-range dependencies, while transformers, although capable of capturing global information through self-attention mechanisms, suffer from high computational complexity, especially when processing long sequences, resulting in significant memory and computational overhead. To address these issues, we propose the Long-Term Temporal Perception Module (LTPM), which combines the advantages of linear attention mechanisms and the Mamba architecture. This effectively captures long-term temporal features while maintaining linear computational complexity. The structure of LTPM is shown in
Figure 4.
Here, Norm denotes the normalization layer, whose primary function is to independently normalize the features of each sample. This operation effectively stabilizes the training process and accelerates convergence.
Traditional linear attention mechanisms reduce the computational complexity of attention calculations to O(
N) using kernel tricks, enabling efficient processing of long sequence data. The core idea is to transform the interaction between queries and keys into convolution operations, thus avoiding explicit dot-product calculations. The formula is expressed as follows:
Here, WQ, WK, and WV represent the projection matrices, and Q, K, and V represent the query, key, and value matrices, respectively. Qi, Ki, and Vi denote independent queries, keys, and values, while ϕ represents the kernel function. However, linear attention still faces challenges when processing long-term temporal information, such as information loss, position encoding loss, and difficulties in modeling long-range dependencies.
As a variant of linear attention, Mamba employs a structured state space and selective scanning mechanism, which enables it to handle ultra-long sequences with a complexity of O(N). The core idea is to recursively model the input sequence using state matrix A, thereby capturing long-term temporal dependencies. However, state matrix A is highly sensitive to the input sequence and causal data, making it unsuitable for non-causal data such as images. Moreover, the Mamba architecture is primarily designed for sequence modeling tasks, lacking the ability to model spatial local correlations and position information explicitly.
Experimental results show that state matrix
A provides two key attributes to the model: local bias and position information. This demonstrates that the state matrix
A in the classical Mamba model can be replaced by an appropriate position encoding. It supplies the model with local bias and position information, making it suitable for non-auto-regressive vision models. Therefore, we propose the Long-Term Temporal Linear Attention (LLA), which can be expressed as:
Here, represents the position encoding, which is used to provide local bias and position information. Through this approach, LLA is able to effectively capture long-range dependency features while maintaining linear complexity.
Finally, we design a Mamba-like module structure, where the LLA-Block replaces the selective SSM, and the MLP module from the linear attention transformer is added. Based on this, we introduce a learnable gating mechanism (Gate), allowing the model to adjust the strength of its outputs adaptively. This enhancement improves the model’s ability to capture complex temporal features.
4. Experiments
This section introduces the dataset and experimental setup used in our study, followed by a comparison with previous state-of-the-art multi-view 3D object detection methods. Finally, we conduct a series of ablation experiments and a comprehensive analysis to demonstrate the effectiveness of various components, namely LSCH and LTPM, in our proposed LST-BEV framework.
4.1. Dataset and Metrics
NuScenes is a large-scale autonomous driving benchmark dataset. It consists of 750 scenes for training, 150 for validation, and 150 for testing. Each scene lasts about 20 s, and key samples are annotated at a frequency of 2 Hz. The data for each sample is collected from six cameras, one LiDAR, and five radars. For 3D object detection, the nuScenes detection score (NDS) is introduced to evaluate various aspects of the nuScenes detection task. In addition to the mean average precision (mAP), NDS is also associated with five types of true-positive (TP) metrics, including the mean translation error (mATE), mean scale error (mASE), mean orientation error (mAOE), mean velocity error (mAVE), and mean attribute error (mAAE).
The mAP (mean Average Precision) is used to comprehensively evaluate the model’s detection capabilities across all target categories, including recall and localization accuracy, while the NDS (NuScenes Detection Score) is a weighted composite of mAP and five true-positive errors (mATE, mASE, mAOE, mAVE, and mAAE). Given that the NDS already incorporates all mTP errors and that mAP + NDS can cover over 80% of performance analysis requirements, this paper opts to use mAP + NDS for detailed analysis in select comparative experiments and all ablation studies to highlight the core findings and maintain data conciseness.
4.2. Implementation Detail
The BEVPool network structure was improved based on MMDetection3D (MMDetection3D 1.4.0) and two NVIDIA GeForce RTX 4090 GPUs (ASUS Suzhou Factory, Suzhou, Jiangsu, China). The model was trained using the AdamW optimizer with gradient clipping. We used ResNet-50 as the image backbone during training and downsampled the images to a resolution of 256 × 704 as input, training for 24 epochs. The model parameters are as follows: Training time: 42 h 53 min; Number of parameters: 83.29 M; FPS: 9.1 img/s.
4.3. Main Result
4.3.1. Comparison with Both Previous Classic Approaches and SOTA Methods
We compared LST-BEV with classic multi-view 3D detection methods on the nuScenes test set, and the results are shown in
Table 1. The experimental results in
Table 1 demonstrate that our proposed model maintains significant accuracy advantages over conventional baseline methods across different backbone architectures and input image resolutions. However, due to the limited number and quality of GPUs available for training, we were unable to use high-precision backbones, such as V2-99, Swin-B, or ResNet-101, and high-resolution images as inputs, which prevented us from directly comparing our experimental results with existing state-of-the-art (SOTA) methods. Nevertheless, we reproduced several state-of-the-art 3D object detection methods using ResNet-50 as the backbone. We compared them with our proposed method on the nuScenes validation dataset, as shown in
Table 2. It can be observed that LST-BEV achieved the best detection results, with a 2.1% improvement in mAP and a 2.7% improvement in NDS over its baseline (i.e., BEVPool), demonstrating its notable potential and advantages. Moreover, even when employing lower input resolutions and a less complex backbone, our model outperforms CAPE by +1.5% mAP and +7.8% NDS and surpasses FCOS3D by +1.9% mAP and +6.9% NDS.
4.3.2. VisualizationBEV
Figure 5 presents a set of detection results in complex scenarios. The results demonstrate that LST-BEV maintains accurate object classification and precise localization even under challenging conditions with various obstructions such as containers and electrical boxes. This indicates that our model achieves high detection accuracy while exhibiting strong robustness against environmental interference.
4.4. Ablation Study
4.4.1. Component Analysis
We used SA-BEVPool as the baseline and evaluated the contributions of LSCH and LTPM, with the results shown in
Table 3. After incorporating LSCH, mAP and NDS increased by 1.6% and 1.1%, respectively. After incorporating LTPM, mAP increased by 0.5% and NDS increased by 1.6%. Ultimately, the complete LST-BEV model achieved a total improvement of 2.1% in mAP and 2.7% in NDS, validating the effectiveness of our improvements. We attribute this improvement to LSCH’s ability to extract long-distance features and LTPM’s capability to capture and fuse long-term temporal dependencies. This addresses the limitations of previous object detection methods, which were constrained by local receptive fields and short-term dependencies, thereby enhancing detection accuracy in complex scenes.
4.4.2. Ablation Experiments on the Long-Range Cross-Task Detection Head (LSCH)
The LSCH consists of n Long-Range Spatial Attention (LRSA) modules and one Cross-Task Detection Head (CTH). Through multiple experiments, we further validated the effectiveness of each module and determined the optimal number of LRSA modules. The results are presented in
Table 4. Our CTH and a single LRSA module improved the performance of the LSCH by 1.0% mAP and 0.6% NDS, and 0.5% mAP and 0.5% NDS, respectively. The maximum improvement, achieved with two LRSAs, was 0.6% mAP and 0.6% NDS.
We attribute this improvement to the LSCH’s ability to capture long-range spatial features, allowing the model to better capture the targets’ long-distance dependencies. Furthermore, the CTH’s cross-task feature fusion of depth prediction and semantic information enables complementary and synergistic utilization of different features, effectively enhancing detection accuracy.
4.4.3. Ablation Experiments on Long-Term Temporal Perception Module (LTPM)
In this section, we first validate the effectiveness of the Long-Term Perception Module (LTPM) and demonstrate the necessity of gated convolutions. Ultimately, we identify the optimal number of LTPMs, as shown in
Table 5. The LTPM without gated convolutions and the LTPM with gated convolutions improve the baseline by 0.1% and 0.3% mAP, respectively. The most significant improvement is achieved when two LTPMs are used, resulting in a 0.5% mAP and a 1.6% NDS increase. Notably, the experimental data indicate that, after employing LTPM, the NDS shows a more pronounced improvement than the mAP. This suggests that LTPM enhances detection accuracy and effectively corrects direction and scale errors. We attribute this improvement to adding long-term sequence features, which enable the model better to understand the target’s motion trends and speed differences. Moreover, these features assist the model in more accurately recognizing scale variations, thereby improving the overall detection performance.
5. Conclusions and Discussion
This paper proposes LST-BEV to extract and utilize long-range and long-term sequential features from images. LSCH effectively captures long-range dependencies in the image while extracting cross-task information by combining the improved large-kernel attention LRSA and the cross-task detection head CTH. This leads to the generation of high-precision depth predictions and semantic information with long-range features. LTPM integrates the advantages of linear attention mechanisms and Mamba, utilizing position encoding to replace recursive state matrices, enabling fast temporal information extraction within limited storage space. Experimental results demonstrate that LST-BEV achieves significant improvements over the baseline and exhibits substantial advantages compared to other state-of-the-art models.
Research and experiments demonstrate that effectively extracting and utilizing long-range multimodal cross-task fusion information and long-term temporal features is critical for improving accuracy in 3D object detection tasks for autonomous driving. Experimental results indicate that long-range multi-scale feature extraction and cross-task feature fusion can effectively address the inability to capture long-range dependencies and insufficient feature utilization in object detection, thereby significantly enhancing detection precision. Furthermore, the effective extraction and utilization of long-term temporal information enable the model to better understand and predict object motion trends, improving overall detection performance.
However, it should be noted that, due to limitations in the quantity and quality of GPUs available for training, we were unable to employ high-precision backbone networks or high-resolution images as inputs, resulting in experimental outcomes that cannot be directly compared with state-of-the-art (SOTA) methods. Additionally, since our approach extracts, utilizes, and fuses multiple image features, the model requires increased parameter processing and training time, imposing additional burdens on model instantiation and real-time detection. This remains an area for future research.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}