1. Introduction
Emotion recognition is a fundamental component of affective computing and human–computer interaction, with significant implications across healthcare, education, and consumer technologies [
1,
2]. Traditional methods primarily rely on observable cues such as facial expressions or speech. However, these external indicators can be intentionally controlled or masked, limiting their reliability in representing genuine emotional states [
3]. Physiological signals—such as heart rate, blood volume pulse (BVP), and skin conductance—regulated by the autonomic nervous system (ANS), offer a more authentic and less voluntarily modifiable reflection of emotional states, making them ideal for unobtrusive affective computing [
4].
Extensive psychophysiological research has firmly established that emotional states trigger characteristic, transient changes in cardiovascular activity [
4]. Heart rate variability (HRV), defined by fluctuations in intervals between heartbeats, reflects ANS activity, distinctly correlating with emotional regulation processes [
5]. Additionally, pulse waveform morphology captures vascular tone variations associated directly with emotional arousal [
6]. Notably, these physiological responses are transient, sparsely distributed, and exhibit non-uniform temporal patterns [
4,
7]—highlighting a critical gap in current approaches: effective identification and the interpretation of emotionally salient temporal segments amidst noisy physiological signals.
Recent advancements in remote photoplethysmography (rPPG) enable unobtrusive, camera-based monitoring of cardiovascular activity by measuring subtle skin color variations induced by cardiac pulse waves [
8]. This technique allows scalable affective computing applications across diverse industrial contexts due to the proliferation of camera-equipped devices (e.g., smartphones, laptops, and surveillance systems), significantly broadening the practical utility of emotion recognition technology [
9].
Despite promising potential, recognizing emotions exclusively from unimodal temporal rPPG signals has significant unresolved challenges. Firstly, emotional physiological responses often manifest briefly and sporadically rather than continuously, complicating effective temporal analysis [
4]. Secondly, rPPG signals inherently suffer from noise and artifacts from subject motion and environmental lighting changes compared to contact-based methods, impairing robust interpretation of subtle emotional cues [
8,
9]. Thirdly, typical session-level annotations induce a weak-label Multiple Instance Learning (MIL) scenario [
10], necessitating sophisticated models to pinpoint informative temporal segments accurately, a challenge recently tackled in rPPG with domain adaptation techniques [
11]. Fourthly, recognizing valence (the pleasantness of an emotion) from physiological signals remains inherently more challenging than arousal (the intensity of an emotion) as its correlates are more complex and less directly tied to general ANS activation [
4,
12]. Furthermore, large-scale, deep-learning-ready rPPG corpora remain rare; most public datasets contain <50 participants and fewer than 10 sessions per subject, thereby limiting the statistical power of data-hungry models such as LSTM or Transformer variants [
13,
14].
Consequently, we deliberately restrict our first evaluation to the well-controlled MAHNOB-HCI benchmark—which provides a relatively large number of sessions per subject—to isolate the intrinsic capabilities and limits of temporal-only rPPG before tackling cross-dataset generalization in future work in
Section 5.2.
Our study explicitly addresses these challenges by proposing a novel deep learning framework. By processing signals in short, localized temporal chunks, we effectively isolate and analyze transient physiological responses. We introduce a Multi-scale Temporal Dynamics Encoder (MTDE), physiologically motivated by multi-rate ANS response characteristics [
5,
15] and designed to capture subtle temporal patterns across different timescales [
16]. Furthermore, an adaptive sparse attention mechanism leveraging α-Entmax and entropy regularization explicitly identifies and prioritizes temporally sparse emotional segments, emulating selective human attentional processes [
17,
18,
19]. A novel Gated Temporal Pooling mechanism robustly aggregates chunk-level information, effectively filtering noise through joint temporal weighting and feature-level gating [
20].
Critically, we employ a physiologically inspired, three-phase curriculum learning strategy—exploration, discrimination, and exploitation—mirroring human attentional refinement and developmental learning principles [
21,
22]. This systematic training approach addresses weak-label issues, temporal sparsity, and signal noise incrementally, enabling stable, progressive learning from complex, noisy temporal data. To robustly evaluate our method, we employ weighted F1-scores, addressing class imbalance more objectively compared to prior work such as that by Mellouk & Handouzi [
23]. This work therefore establishes a transparent baseline that future research in cross-dataset generalization and domain adaptation can build upon. Our evaluations on the MAHNOB-HCI dataset show promising results: for arousal, it achieves an accuracy of 66%, an F1-score of 0.7429, and a weighted F1-score of 0.6224; for valence, it achieves an accuracy of 62.3%, an F1-score of 0.6667, and a weighted F1-score of 0.6227, underscoring our model’s effectiveness despite inherent challenges.
Our contributions explicitly bridge critical research gaps, providing clear advancements:
Focused Temporal Analysis of rPPG: This method establishes foundational insights into the capabilities and limitations of using exclusively temporal physiological information, providing a rigorous benchmark.
Multi-scale Temporal Dynamics Encoder (MTDE): This effectively captures physiologically meaningful ANS responses across multiple timescales, addressing complexity in subtle temporal emotional signals.
Adaptive Sparse Attention: This method precisely identifies transient, emotionally relevant physiological segments amidst noisy rPPG data, significantly enhancing robustness.
Gated Temporal Pooling: This method sophisticatedly aggregates emotional information across temporal chunks, effectively mitigating noise and irrelevant features.
Curriculum Learning Strategy: This method systematically addresses learning complexities associated with weak labels, noise, and temporal sparsity, ensuring robust, stable model learning.
3. Methodology
This section delineates the methodology employed in our study for emotion recognition from remote photoplethysmography (rPPG) signals. We describe the dataset utilized, the preprocessing steps, the overall framework architecture, the detailed components of our model, the physiologically inspired curriculum learning strategy, the evaluation metrics and comparative baseline, and the experimental setup.
3.1. Dataset and Experimental Protocol
3.1.1. MAHNOB-HCI Dataset
We employ the publicly available MAHNOB-HCI multimodal emotion dataset, which comprises recordings from 27 subjects who viewed 20 emotional film clips [
28]. The dataset represents one of the most comprehensive multimodal emotion databases with synchronized physiological signals, facial videos, and subjective ratings. After excluding unusable data from 3 subjects, a total of 527 valid sessions were utilized for this study. The dataset provides synchronized facial videos and ground-truth physiological signals, including electrocardiogram (ECG) data recorded at a 256 Hz sampling rate.
All videos were downsampled to 30 fps, a rate validated as sufficient for capturing subtle cardiovascular dynamics and maintaining HRV analysis accuracy. Studies have demonstrated that frame rates of 30 fps or higher preserve the temporal resolution necessary for accurate heart rate variability measurements. For classification, the self-reported valence and arousal ratings (on a 1–9 scale) were binarized into “low” (ratings 1–4) and “high” (ratings 5–9) classes by thresholding at the midpoint (4.5), following established protocols in affective computing research [
33].
3.1.2. Data Partitioning and Protocol Rationale
To maximize the data available for our deep learning model, the 527 sessions were partitioned into training (80%), validation (10%), and testing (10%) sets using a session-based random split. We acknowledge that a strict subject-independent split is the gold standard for evaluating generalization. However, as established in systematic reviews, the landscape of public cardiovascular-based emotion datasets is characterized by limited scale; a comprehensive survey of 18 such datasets revealed that most include fewer than 50 participants, with many offering limited session diversity per subject [
6]. This data scarcity poses a significant challenge for training data-hungry deep learning models.
Consequently, we opted for this subject-mixed protocol to facilitate a thorough investigation of our proposed architecture’s capabilities on a rich set of session data. We explicitly acknowledge that this protocol may lead to an overestimation of the model’s generalization capability to entirely unseen subjects, a limitation that, along with the challenges of cross-dataset validation, is further addressed in our discussion (
Section 5.1).
3.1.3. A Two-Stage Process for Optimal Method Selection
To ensure a high-quality physiological input, we conducted a rigorous, two-stage experiment to select the optimal rPPG method. The MAHNOB-HCI dataset provides ground-truth physiological signals, including ECG data; however, it does not include raw contact-based photoplethysmography (PPG) signals for direct comparison. As a ground-truth heart rate (HR), we processed the dataset’s raw ECG signals; R-peaks were detected using the Pan–Tompkins algorithm [
34] with a 0.5–40 Hz band-pass filter, and the resulting inter-beat intervals (IBIs) were used to calculate HR (HR = 60/IBI), which was then resampled to 30 Hz.
First, a broad comparison of traditional unsupervised algorithms against state-of-the-art deep learning models was conducted on our target dataset. The accuracy of the extracted signals was measured against the ECG-based ground-truth using Mean Absolute Error (MAE) in beats per minute (bpm) and Root Mean Square Error (RMSE). As summarized in
Table 1, deep-learning-based methods demonstrated vastly superior accuracy, with PhysFormer [
30] and PhysMamba [
32] (both pre-trained on UBFC-rPPG) emerging as the top two performers.
Second, to make a final selection, we conducted a head-to-head analysis focusing on signal quality (SNR) and computational efficiency (VRAM usage). This test was performed using the standard UBFC-rPPG intra-dataset protocol [
35]. The results in
Table 2 clearly favor PhysMamba, which achieved a significantly higher SNR (3.67 vs. 0.25) and lower VRAM usage.
3.1.4. Final Method and Implementation
While our validation on MAHNOB-HCI yielded an MAE of 5.38 bpm for HR estimation, our primary goal is to obtain a high-fidelity BVP waveform for learning subtle affective features. Research has demonstrated that the morphological characteristics of PPG signals contain essential physiological information for emotion recognition, with signal quality being more critical than absolute HR accuracy for the effective classification of affective state [
6,
36,
37]. Therefore, based on its superior signal quality (SNR) and computation efficiency, PhysMamba [
32] was selected as the optimal front-end extractor. For implementation, the selected model was applied to 128-frame chunks of the videos using the DiffNormalized scheme [
38].
3.2. Overall Framework
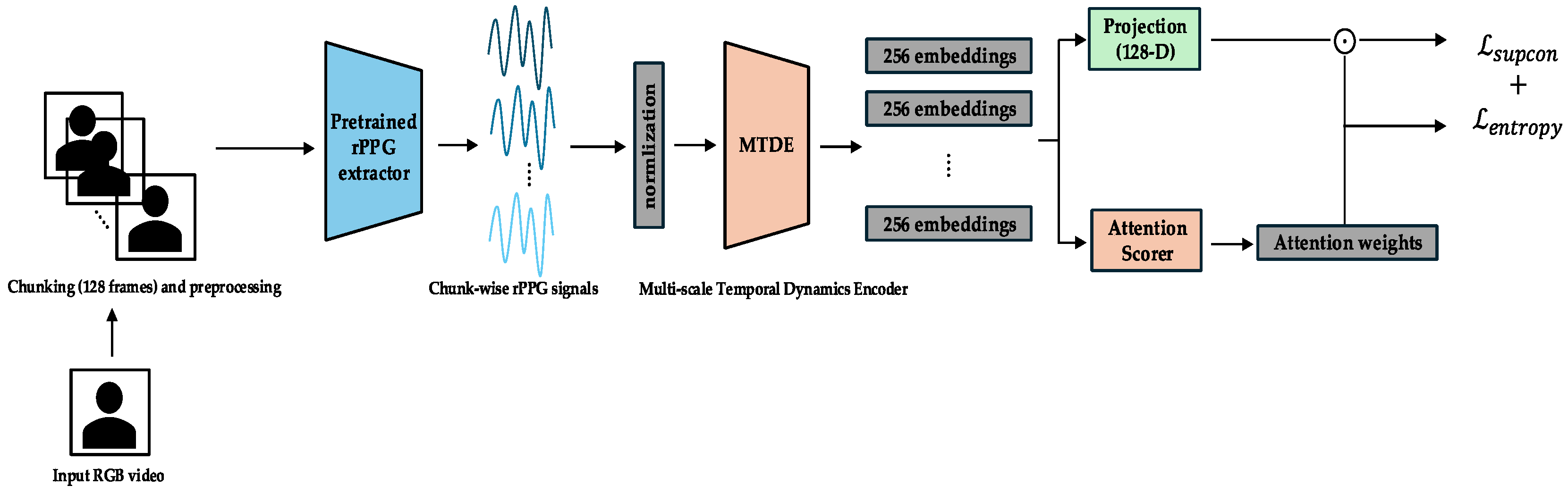
The complete end-to-end pipeline, together with its three curriculum phases, is shown in
Figure 1. Raw RGB video is segmented into 128-frame chunks (≈4 s at 30 fps) and converted to rPPG waveforms by a pretrained PhysMamba extractor. Each chunk is then encoded by the Multi-scale Temporal Dynamics Encoder (MTDE). Depending on the training phase, different modules become active: the projection head and
in Phase 0 (
Figure 2), the chunk auxiliary classifier and Top-K α-Entmax attention in Phase 1 (
Figure 3), and the Gated Pooling plus session classifier in Phase 2 (
Figure 4). At inference time, the green-outlined path in
Figure 1 (MTDE → α-Entmax → Gated Pooling → Main Classifier) constitutes the operational model.
Our emotion recognition model processes the 1D temporal rPPG signal, derived from the video, in fixed-length, non-overlapping temporal chunks of 128 frames (approximately 4 s at 30 fps). This specific chunk size was strategically chosen for multiple reasons. Firstly, it aligns with the temporal window used by the robust PhysMamba rPPG extractor [
32] and common processing units in the rPPG-Toolbox framework [
38]. Secondly, and crucially, prior work [
23] has demonstrated that a 4-s segmentation size yields optimal performance for emotion classification from contactless PPG signals, reinforcing its appropriateness for capturing pertinent physiological dynamics within the temporal domain. Physiologically, a
4-s window is well-suited as it typically encompasses several cardiac cycles (e.g., approximately 4–7 heartbeats at a resting heart rate of 60–100 bpm). Analyzing physiological patterns such as heart rate variability (HRV) [
5,
15] or subtle pulse waveform changes, which are known to reflect autonomic nervous system dynamics [
39] and have been effectively used for affective computing [
6] over this duration, allows for the capture of meaningful short-term autonomic nervous system (ANS) modulations, which are widely recognized as crucial indicators of emotional states.
Each temporal chunk is processed using the Multi-scale Temporal Dynamics Encoder (MTDE), yielding a 256-dimensional feature embedding. The embeddings are scored by the attention scoring module (AttnScorer) via α-Entmax attention and, in parallel, forwarded to the Gated Pooling module (Gated Pooling). Gated Pooling integrates the attended and feature-gated embeddings into a single session representation from which the main classifier predicts the valence and arousal labels using only the aggregated temporal information. Phase-specific modules that augment this core path are illustrated in
Figure 2 (Phase 0),
Figure 3 (Phase 1), and
Figure 4 (Phase 2) and are detailed in the curriculum learning section (
Section 3.4).
3.3. Training Modules
This section provides a detailed description of the core modules constituting our emotion recognition framework.
3.3.1. rPPG Extraction Front-End (PhysMamba)
As determined by our selection process (
Section 3.1.3), the UBFC-rPPG-pretrained PhysMamba model [
32,
38]—chosen for its superior SNR and lower VRAM footprint—serves as the rPPG extraction front-end in our framework. Its primary role is to extract a refined, denoised 1D temporal rPPG (blood- volume pulse, BVP) signal from raw facial video frames.
PhysMamba operates on non-overlapping 128-frame chunks (≈4 s at 30 fps). Each chunk is first pre-processed with the DiffNormalized scheme [
32,
38], which computes frame-wise ratio differences normalized by the standard deviation, thereby enhancing subtle blood flow changes. The resulting 1D BVP waveform—produced without any additional per-session rescaling or band-pass filtering—constitutes the exclusive input to the downstream emotion recognition modules.
3.3.2. Multi-Scale Temporal Dynamics Encoder (MTDE)
The MTDE’s purpose is to learn rich feature representations by capturing physiological dynamics across various temporal scales within each 128-frame BVP chunk. The design is physiologically grounded in the principle that the autonomic nervous system (ANS) modulates the cardiac pulse through multiple superimposed rhythms [
40], with sympathetic and parasympathetic activities contributing to distinct frequency components of heart rate variability [
15]. While these rhythms are classically studied via heart rate variability (HRV) frequency bands [
41], our model does not compute HRV metrics explicitly. Instead, it learns features directly from the BVP waveform that are implicitly sensitive to the physiological processes underlying these HRV bands.
As detailed in
Appendix A, the MTDE comprises two main stages: a SlimStem and a Multi-Scale Temporal Block (MSTB). The SlimStem consists of two sequential 1D convolutional layers for initial noise reduction and low-level feature extraction, conceptually akin to early sensory filtering. The subsequent MSTB implements our physiology-aligned strategy, featuring a three-branch architecture using dilated convolutions. Each branch is designed to have an effective receptive field (RF) that spans one of the key ANS timescales:
Short-scale branch (RF
0.2 s): This scale is sensitive to rapid beat-to-beat changes in pulse morphology, reflecting high-frequency dynamics driven by parasympathetic (vagal) fluctuations, analogous to the HF-like band of HRV [
4].
Medium-scale branch (RF
2.2 s): This branch targets slower oscillations from the interplay between sympathetic and parasympathetic systems (e.g., baroreflex), operating in a window comparable to the LF-like band [
4].
Long-scale branch (RF
4.3 s): This branch integrates very slow modulations across the entire chunk, reflecting hormonal or thermoregulatory influences, which are thought to contribute to the VLF-like band [
41]. Here, as the chunk is limited to 128 frames, the three RFs cover only the order-of-magnitude ranges rather than exact periods.
Outputs from the three MSTB branches are concatenated and passed through a SoftMax-based temporal attention pooling layer. This final step aggregates multi-scale information into a single, fixed-size 256-dimensional embedding (, where 56) for each chunk.
3.3.3. AttnScorer
The AttnScorer’s function is to evaluate each chunk embedding (
) and assign it a single scalar relevance score. This module is directly inspired by the physiological principle that autonomic responses to emotional stimuli are often transient and sparsely distributed in time [
42]. Its purpose is therefore to learn to identify these brief, emotionally salient moments.
Architecturally, it consists of a 2-layer MLP with GELU activation (
Appendix B). The raw attention scores are adaptively normalized using σ-γ scaling (a running-std gain control), a mechanism analogous to biological sensory normalization [
43]. These scores are then transformed using α-Entmax attention [
18,
44], encouraging a sparse selection of salient chunks, which mirrors the selective focus of biological attention mechanisms [
20].
3.3.4. Gated Pooling
The Gated Pooling module aggregates the sequence of chunk embeddings (
) into a single, noise-resilient session-level representation (
). Its design is a direct response to the noisy nature of rPPG signals, where even within an emotionally salient chunk, not all feature dimensions are equally reliable [
8].
It implements a learned, content-aware aggregation via two parallel mechanisms [
45]. First, it uses the sparse attention scores (
) from the AttnScorer as temporal weights. Second, it computes a learned gate vector
that modulates each dimension via element-wise product (
), The final representation is computed as
This feature-level gating is pivotal, allowing the model to selectively amplify robust feature dimensions while suppressing those potentially corrupted by noise, a process inspired by neural gating and inhibition [
46].
3.3.5. Auxiliary Components
These modules are active only during specific curriculum phases (
Section 3.4) to support learning objectives. The ChunkProjection module (Phase 0) is an MLP head for normalized embeddings used by the Supervised Contrastive Loss [
47]. The ChunkAuxClassifier module (Phase 1) is a classifier attached before Gated Pooling module, predicting session labels from individual chunks to pretrain the MTDE for local discrimination. It is used to initialize the Main Classifier in Phase 2.
3.3.6. Main Classifier
The Main Classifier receives the final aggregated session representation vector and predicts final emotion labels (low/high valence/arousal) via fully connected layers.
3.4. Training Curriculum
Our training employs a three-phase curriculum learning strategy, a methodology inspired by the developmental principle that meaningful learning occurs by progressively increasing the difficulty of training samples [
21]. This structured approach is conceptually analogous to human skill acquisition, moving from broad feature perception to fine-grained discrimination and finally to integrated decision-making [
22,
48]. It systematically addresses the challenges of noisy, temporally sparse, and weakly labeled time-series data to achieve stable and effective learning. The specific pipeline configuration and module activations during each phase are illustrated in
Figure 2,
Figure 3 and
Figure 4. Detailed hyperparameters for each phase are provided in
Appendix C.
3.4.1. Phase 0 (Epochs 0–14): Exploration and Representation Learning
Cognitive/Computational Link: This initial phase corresponds to “pervasive exploration” observed in human learning, where a system first captures a wide array of sensory inputs to build a general understanding of the feature space before focusing on specific tasks. This aligns with classic models of attention where an initial, broad orientation precedes focused analysis [
49].
Objective: The primary objective is to train the MTDE and related components (AttnScorer and ChunkProjection) to produce robust and diverse embedding representations for individual temporal chunks. During this phase, the Gated Pooling module and the Main Classifier are not used for the primary loss computation.
Primary Losses: The total loss in Phase 0 is a combination of the Supervised Contrastive Loss and an Entropy Regularization Loss. The Supervised Contrastive Loss (
) [
47] is applied to the normalized embeddings from the ChunkProjection. This loss encourages embeddings from chunks originating from the same session (sharing the same label) to be closer in the representation space while pushing embeddings from different sessions apart.
The training in this phase is guided by a combination of two loss functions. The primary objective is the Supervised Contrastive Loss (
), defined as
Here,
is the set of anchor indices in the batch,
is the set of all indices in the batch except
,
is the set of indices of positive samples (same label) of
,
represents the normalized embedding vectors, and
is the temperature parameter. To complement this, an Entropy Regularization Loss (
) is applied to the AttnScorer’s internal SoftMax attention output. Weighted by
, this loss encourages a more uniform initial attention distribution, promoting a broader exploration of temporal features. This exploration is critical for preventing the model from prematurely converging on spurious patterns—a known risk related to the memorization capacity of deep networks, especially in the presence of noisy labels [
50].
The overall loss for this phase combines both objectives.
3.4.2. Phase 1 (Epochs 15–29): Chunk-Level Discrimination and Attentional Refinement
Cognitive/Computational Link: This second phase corresponds to the establishment of selective attention. After the initial exploration, learning resources are focused on task-relevant signals. By using the AttnScorer and Focal Loss on only the Top-K chunks, our model progressively narrows its attentional focus, mimicking how neural systems learn to prioritize information-rich stimuli over time [
51].
Objective: The objective is to significantly enhance the discriminative capacity of the individual chunk embeddings and to refine the AttnScorer’s ability to identify emotionally salient temporal segments. During this phase, the ChunkProjection module is frozen, while the MTDE, AttnScorer, and ChunkAuxClassifier are actively trained.
Primary Losses: The main objective is driven by a chunk-level classification task using the ChunkAuxClassifier. To handle class imbalance and focus on challenging examples, we employ Focal Loss [
52] with
(
Appendix C):
The primary loss function for Phase 1 is the chunk-level Focal Loss (
), calculated as
Here, we use a formulation where is the model’s estimated probability for the target class, is a class-balancing weight, and is the focusing parameter.
Critically, this loss is calculated only for the Top-K chunks selected based on the AttnScorer’s α-Entmax output. The Top-K ratio,
, is strategically annealed downwards as training progresses. This forces the model to progressively focus its discriminative learning resources on the most salient segments, a process that mimics how human attention narrows onto key details within a stimulus [
53].
Furthermore, this phase prepares the model for the next stage of training. The session-level cross-entropy loss () is scheduled to be introduced from epoch 25, with its weight gradually ramping up. While the parameters for session-level components are unfrozen to allow for preparatory fine-tuning, is not yet included in the total loss. This staged activation facilitates a smoother transition to Phase 2.
This staged activation strategy enables the model to begin adapting the session-level representation and pooling dynamics without prematurely influencing the optimization objective, thus facilitating a smoother transition to Phase 2 training. The overall loss for this phase is .
3.4.3. Phase 2 (Epochs ≥ 30): Session-Level Exploitation and Fine-Tuning
Physiological/Cognitive Link: The final phase is analogous to evidence integration for decision-making [
54]. The system leverages its refined representations and focused attention to weigh and combine the most reliable evidence distributed over time to form a final, consolidated judgment [
55].
Objective: The objective is to optimize the entire end-to-end pipeline for the final session-level emotion recognition task. The ChunkAuxClassifier is removed, and the Main Classifier is initialized with its weights. The MTDE, AttnScorer, Gated Pooling, and Main Classifier are all fine-tuned.
Primary Loss Function: The sole objective function in this phase is applying the session-level cross-entropy loss () to the output of the Main Classifier based on the Gated Pooling session embedding.
In this phase, the model is optimized using a session-level cross-entropy loss:
Here, is the one-hot encoded ground-truth label for the session, and is the predicted probability distribution from the Main Classifier over classes.
To achieve optimal session-level performance, key parameters are carefully scheduled to exploit the attentional patterns learned in the previous phase. Specifically, the AttnScorer is fine-tuned at a reduced learning rate (see schedule in
Appendix C). Simultaneously, the
value for the α-Entmax transformation within the Gated Pooling module is annealed from 1.5 (at epoch 30) to 1.8 (at epoch 50). This increase in
promotes higher sparsity in the temporal attention weights, further refining the model’s focus onto the most crucial temporal segments for the final prediction.
3.5. Evaluation Metrics
Model performance was quantitatively evaluated using standard metrics on the independent test set. These metrics were chosen to provide a comprehensive and robust assessment, particularly considering potential class imbalances.
Performance was measured using accuracy and the weighted F1-score. The weighted F1-score is particularly valuable in the presence of class imbalances as it accounts for performance on all classes weighted by their frequency, providing a more objective measure than simple accuracy or macro-averaged metrics in such scenarios.
Weighted F1-score: This metric is calculated based on the precision (), recall (), and F1-score () for each individual class . The formulas for these class-specific metrics are
The overall weighted F1-score is then computed as the average of the class F1-scores, weighted by the number of samples in each class (
):
Here, is the total number of samples in the test set, and is the number of classes. In addition to these primary metrics, we also analyze the confusion matrix to gain insights into the model’s performance across different classes and the types of errors made.
3.6. Baseline
To contextualize the performance of our proposed framework, we selected the CNN-LSTM model by Mellouk & Handouzi [
23] as our primary baseline. This choice was based on its status as the most domain-equivalent benchmark: it is a recent deep learning work that, similar to our study, uses contactless PPG for emotion recognition with approximately 4-s segments on the MAHNOB-HCI dataset.
However, a direct comparison faces significant limitation. Because Mellouk & Handouzi [
23] did not make their source code available and do not disclose their specific test partition, it is impossible to run their model on our exact data split. Therefore, while we utilize their reported results for a comparative analysis, their performance should be interpreted as indicative rather than directly comparable. Our study mitigates this challenge by rigorously detailing our data split (
Section 3.1) and employing the weighted F1-score (
Section 3.5) to provide a more robust assessment that accounts for potential class imbalance. This approach establishes a clearer and more reproducible benchmark for future work.
Furthermore, to ensure a comprehensive evaluation and robustly validate our specific architectural choices, we implemented and compared our framework against a diverse set of alternative architectures. As detailed in
Appendix E, these include a standard Temporal Convolutional Network (TCN), a 1D-CNN+LSTM hybrid model, and variants of our own model with different aggregation (Bi-LSTM) and attention (SE block) mechanisms. These extensive comparisons provide a clear justification for our design choices over various alternatives.
3.7. Experimental Setup
All experiments were conducted on a system with Ubuntu 20.04, Python 3.8, and PyTorch 2.1.2 (+CUDA 12.1), running on a single NVIDIA RTX 4080 GPU. A consistent batch size of 8 was used for all training phases of the emotion recognition model. Each item within a batch consisted of the complete sequence of temporal chunks belonging to a single session, ensuring that chunks from different sessions were never mixed within a sequence.
To manage GPU memory during the initial data preparation stage, long sessions were processed by the rPPG extractor in smaller segments (e.g., 24 chunks at a time). The resulting BVP waveforms were then concatenated to reconstruct the full session sequence before being used as input for model training.
For optimization, we employed the AdamW optimizer with a CosineAnnealingLR schedule. The learning rates were set to , , and for Phases 0, 1, and 2, respectively, with weight decay set to in Phase 0 and for the subsequent phases.
In terms of computational resources, our proposed emotion recognition modules are lightweight. The front-end PhysMamba extractor consumes approximately 9.8 GiB of VRAM, while our entire pipeline has a maximum GPU memory consumption of 14.5 GiB under our batch configuration. This indicates that our downstream modules (MTDE, attention, etc.) add only about 4.7 GiB to the baseline load. The complete model has a total of 197,892 trainable parameters (164,996 for inference). On the aforementioned hardware, the average training time was approximately 4.1 min per epoch, and the average inference time for a 2-min session was 0.66 s, confirming the model’s efficiency and suitability for practical applications.
5. Discussion
Our proposed framework demonstrates promising capabilities in recognizing emotions exclusively from temporal remote photoplethysmography (rPPG) signals, achieving competitive arousal classification performance (66.04% accuracy; 61.97% weighted F1-score) and outperforming the CNN-LSTM baseline [
23]. This superior arousal performance stems from our physiologically inspired temporal modeling and neuro-cognitively motivated learning strategy. The Multi-scale Temporal Dynamics Encoder (MTDE) effectively captures ANS modulations across timescales [
4,
15,
39,
40,
41], showing that it is adept at detecting rapid pulse morphology changes indicative of sympathetic activation. The adaptive sparse α-Entmax attention [
17] mirrors human selective attention [
18,
19,
43,
51,
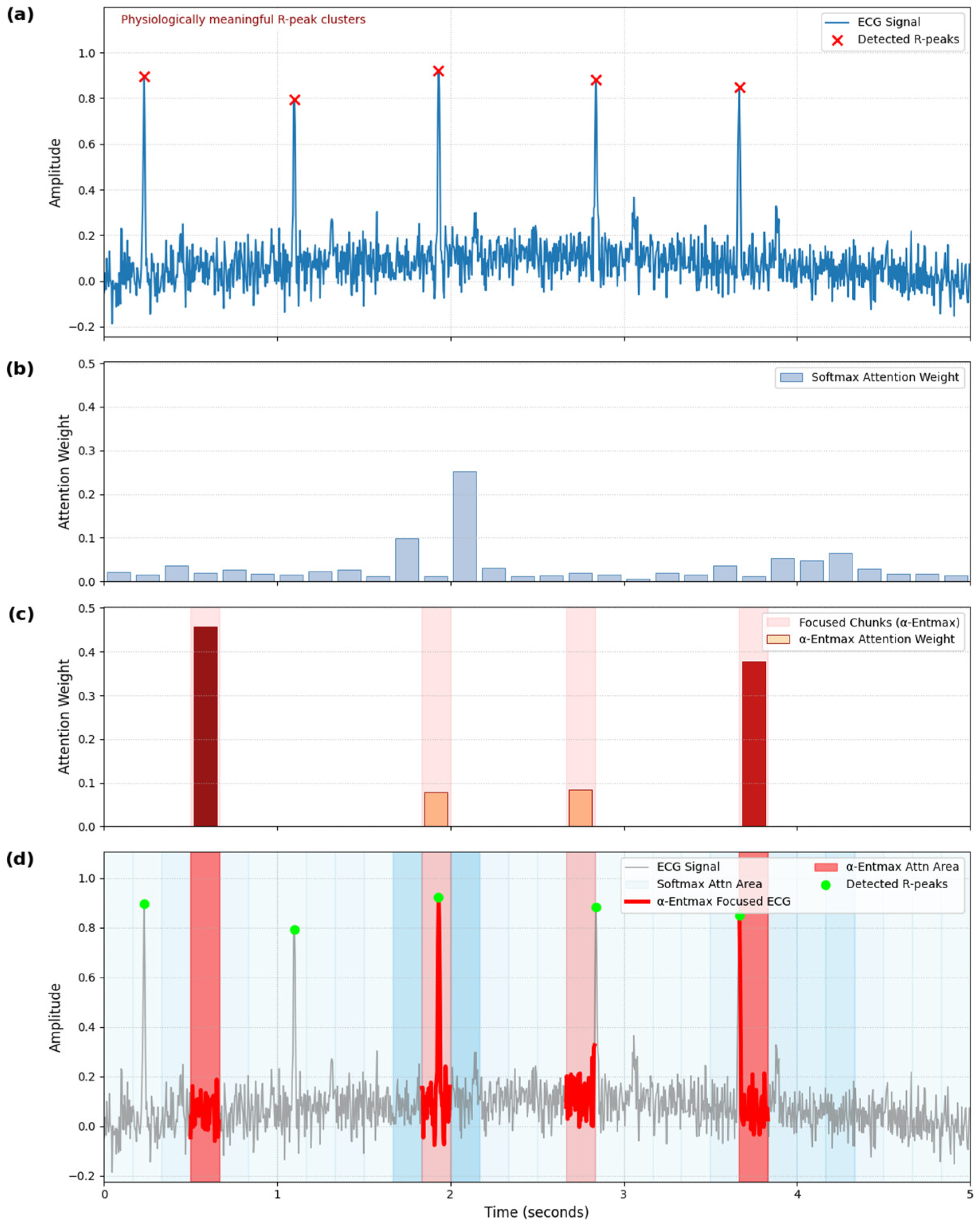
53], precisely identifying transient, salient physiological events like R-peak clusters (
Figure 5) [
59,
60]. Robust aggregation via Gated Pooling [
20,
45], inspired by neural gating principles [
46], further mitigates noise. Critically, our staged curriculum learning strategy [
21], analogous to human skill acquisition [
22,
48,
49], ensured stable and effective learning by systematically addressing data challenges [
50]. Our ablation studies (
Section 4.2) validate each component’s significant contribution to these gains.
Conversely, valence recognition remains significantly challenging with temporal rPPG signals. Our model achieved lower valence performance (62.26% accuracy; 62.26% weighted F1-score) compared to Mellouk & Handouzi’s baseline [
23] (accuracy: 73.50%; weighted F1-score: 73.14%). This discrepancy highlights fundamental physiological limitations and inherent methodological constraints in valence detection using only temporal, spatially averaged rPPG data.
Physiologically, arousal is largely driven by sympathetic nervous system (SNS) activation [
4,
56], manifesting as acute, high-magnitude cardiovascular changes. These “event-like” shifts are well-captured by our framework’s design. In contrast, valence involves more intricate and subtle physiological responses, including a complex interplay between the sympathetic and parasympathetic nervous systems (PNS) [
4,
57] and higher-order cortical processing not directly reflected in peripheral cardiovascular changes. Positive valence often involves parasympathetic activation, while negative valence can manifest as nuanced patterns of co-activation or withdrawal, less pronounced than arousal’s overt responses.
Furthermore, subtle spatial variations in facial blood flow patterns [
58] may carry valence-related cues, but our single, unidimensional temporal rPPG signal inherently loses this information. Cognitively, arousal often correlates with immediate, attention-grabbing physiological “events,” whereas valence requires integrating more subtle, sustained, and context-dependent patterns over longer temporal windows [
42,
54,
55]. Our framework’s strong inductive bias towards transient, high-magnitude physiological events, effective for arousal, is thus less suited for these nuanced valence patterns. These findings strongly suggest that while temporal rPPG robustly reflects general ANS arousal, recognizing nuanced affective dimensions like valence likely necessitates multimodal integration (e.g., facial expressions and electrodermal activity) or advanced spatial–temporal rPPG analysis.
Regarding practical applicability, our approach demonstrates notable computational efficiency. Considering that it achieves an inference speed of approximately 0.66 s for a two-minute video segment on an NVIDIA RTX 4080 GPU, our model operates faster than real time. Its compact size (164,996 parameters) further facilitates deployment in resource-constrained scenarios (e.g., mobile devices and edge computing), significantly enhancing the viability of our temporal-only rPPG approach for unobtrusive affective computing where dedicated sensors or multiple modalities may not be feasible. This highlights the potential of specialized temporal models even within unimodal signal limitations.
5.1. Limitations
Our study, despite advancing temporal rPPG-based emotion recognition, presents several limitations informing future research. Firstly, our evaluation is confined to the MAHNOB-HCI dataset. This was a deliberate choice to rigorously investigate the capabilities and limits of temporal-only rPPG in a controlled environment with sufficient per-subject session data for deep learning. However, as reviewers noted, its limited scale (527 sessions) and diversity may constrain generalization to unseen subjects or broader contexts.
Secondly, our restriction to temporal-only rPPG, the scope of this foundational investigation, inherently excludes valuable spatial rPPG information or complementary affective cues from other modalities. As evidenced by lower valence performance (
Section 5), this highlights the constraints of relying solely on a spatially averaged temporal pulse signal for nuanced affective dimensions.
A further limitation involves the explicit validation of our physiologically inspired mechanisms. While qualitative analysis (
Section 4.3) and ablation studies (
Section 4.2) demonstrated that our attention mechanisms prioritize physiologically meaningful regions and multi-scale encoding’s effectiveness, deeper statistical correlation analyses with established physiological markers (e.g., specific HRV components) were beyond this study’s initial scope, which focused on implicit learning from the BVP waveform. Our current model thus abstracts and emulates neuro-physiological principles, and further work is needed to fully mimic and quantitatively validate these complex biological processes within its learned representations.
5.2. Future Work
Addressing identified limitations, several clear avenues exist for future research building upon our temporal processing foundations.
Firstly, to enhance generalization and robustness, validating our framework on larger, more diverse datasets (e.g., DEAP and WESAD) is crucial. This includes exploring scenarios with limited per-subject data but broad subject ranges, assessing adaptability to new individuals even without extensive calibration. We aim to develop personalization strategies (e.g., few-shot subject calibration, meta-learning, and transfer learning) for robust performance across varied populations and conditions.
Secondly, to improve nuanced affective dimensions like valence, future work should expand beyond unimodal temporal rPPG. This includes integrating spatial–temporal rPPG analyses preserving regional blood flow patterns and multimodal fusion with complementary affective cues (e.g., facial expressions and electrodermal activity). Evaluating our model on alternative emotional elicitation methods, such as large-scale VR-based datasets, would further strengthen validation and assess domain generalization.
Finally, building upon our current work that abstracts and draws inspiration from neuro-physiological mechanisms, a critical future direction is to develop models that more deeply mimic and quantitatively validate these biological processes. This involves conducting deeper analyses into learned representations, potentially exploring their statistical correlation with specific, well-defined physiological markers beyond HR estimation. Such research would provide critical insights into which physiological dynamics and temporal patterns best indicate different emotional states, fostering more interpretable, scientifically grounded affective computing models that genuinely replicate biological information processing rather than merely using biological analogies.
Collectively, our results establish foundational benchmarks and methodological insights for future advancements in unimodal physiological emotion recognition, clearly defining both the capabilities and inherent limitations of relying solely on temporal-only rPPG signals. Our approach’s comprehensive physiological and cognitive grounding, combined with rigorous evaluation, ensures robust, interpretable, and applicable outcomes, advancing the state of the art in this challenging area.
6. Conclusions
We introduced a physiologically inspired deep learning framework for recognizing emotional states exclusively from temporal remote photoplethysmography (rPPG). Our approach systematically addresses critical limitations—temporal sparsity, signal noise, and weak labeling—through the Multi-scale Temporal Dynamics Encoder (MTDE), adaptive sparse attention, Gated Temporal Pooling, and a structured three-phase curriculum learning strategy. Empirical evaluation confirmed competitive performance in arousal classification (66.04% accuracy; 61.97% weighted F1-score), surpassing previous deep learning baselines. Conversely, lower performance in valence classification (62.26% accuracy) reveals fundamental physiological constraints in using solely temporal cardiovascular signals, clearly demarcating the capability boundaries of unimodal rPPG signals.
These results establish robust methodological benchmarks and highlight promising directions for future exploration: incorporating spatially resolved rPPG analysis or multimodal integration could significantly enhance nuanced emotional inference. This study provides critical foundational insights and clear guidelines to advance affective computing towards more accurate, reliable, and interpretable physiological emotion recognition.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}