
Research on Acoustic Scene Classification Based on Time–Frequency–Wavelet Fusion Network


Abstract
1. Introduction
2. Methods
2.1. Data Augmentation
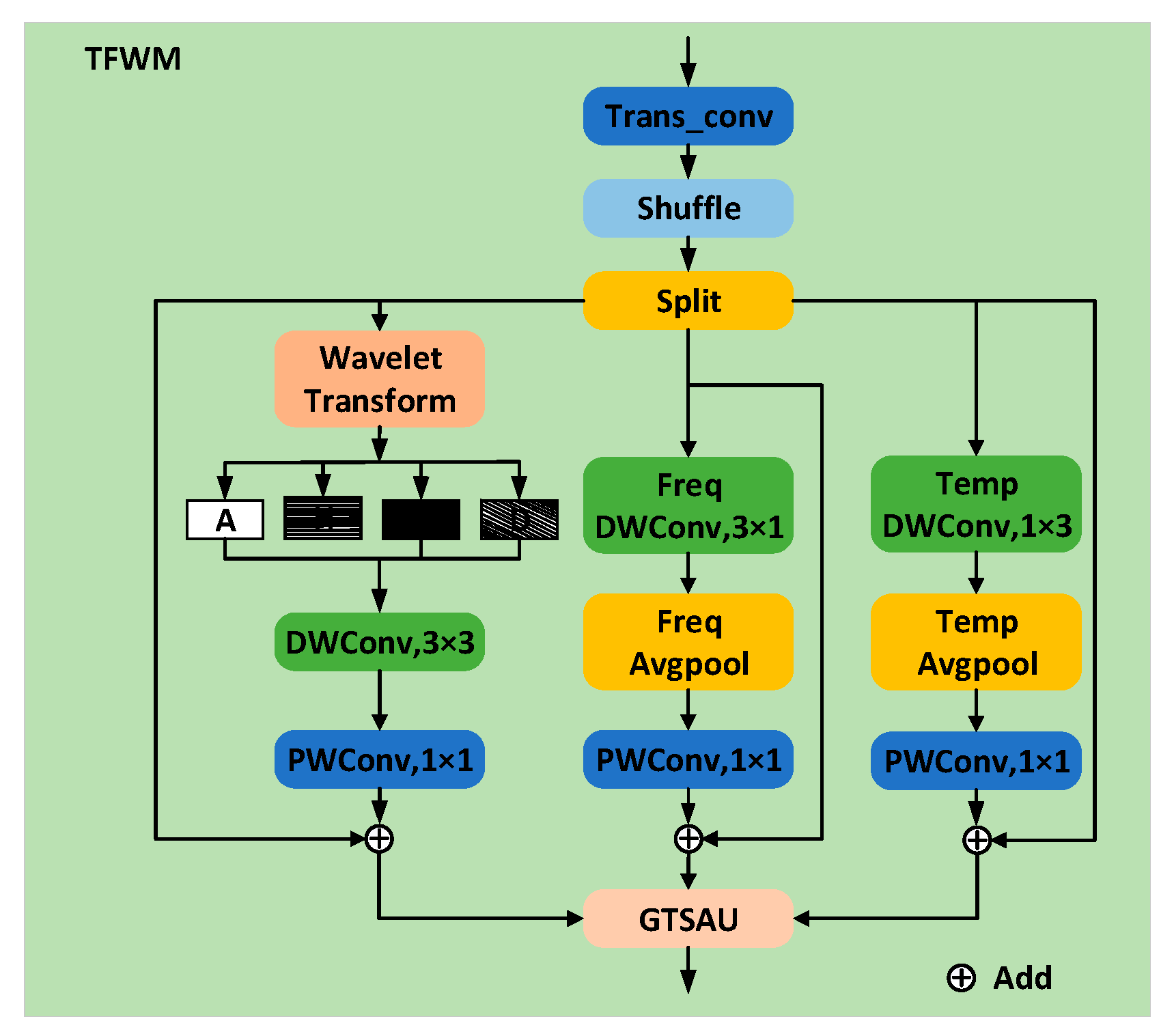
2.2. Time–Frequency–Wavelet Module
2.3. Gated Temporal–Spatial Attention Unit
2.4. VSS Module Based on Mamba Model
2.5. KAN Layers
2.6. Dataset and Experimental Setup
3. Results
3.1. Classifier Selection
3.2. Ablation Experiments
3.3. Comparison with Other Methods
3.4. Generalization Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASC | Acoustic scene classification |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| SSM | State space model |
| AuM | Audio Mamba |
| AST | Audio Spectrum Transformer |
| MLPs | Multilayer Perceptrons |
| KAN | Kolmogorov–Arnold Network |
| HPSS | Harmonic-Shock Source Separation |
| CNN | Convolutional Neural Network |
| TF-SepNet | Time–Frequency Separate Network |
| TFWFNet | Time–Frequency–Wavelet Fusion Network |
| TFWM | Time–Frequency–Wavelet Module |
| GTSAU | Gated Temporal–Spatial Attention Unit |
| VSS | Visual State Space |
| DWConv | Depthwise convolution |
| PWConv | Pointwise Convolution |
| ResNorm | Residual Normalization |
| Trans_conv | Transposed Convolution |
| Shuffle | Channel Shuffle |
| SS2D | 2D Selective Scan |
| DIR | Device Impulse Response |
| Coif3 Wavelet | Coiflet Wavelet Family, Order 3 |
| PACN | Parallel Attention–convolution Network |
| BC-ResBlocks | Broadcast residual blocks |
| ERANNs | Efficient Residual Audio Neural Networks |
| DCNN | Deep Convolutional Neural Networks |
Appendix A
References
- Venkatesh, S.; Mulimani, M.; Koolagudi, S.G. Acoustic scene classification using deep fisher network. Digit. Signal Process. 2023, 139, 104062. [Google Scholar] [CrossRef]
- Yang, C.; Gan, X.; Peng, A.; Yuan, X. ResNet based on multi-feature attention mechanism for sound classification in noisy environments. Sustainability 2023, 15, 10762. [Google Scholar] [CrossRef]
- Chandrakala, S.; Jayalakshmi, S. Environmental audio scene and sound event recognition for autonomous surveillance: A survey and comparative studies. ACM Comput. Surv. 2019, 52, 1–34. [Google Scholar] [CrossRef]
- Cai, Y.; Li, S.; Shao, X. Leveraging self-supervised audio representations for data-efficient acoustic scene classification. arXiv 2024, arXiv:2408.14862. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All you Need. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Castro-Ospina, A.E.; Solarte-Sanchez, M.A.; Vega-Escobar, L.S.; Isaza, C.; Martínez-Vargas, J.D. Graph-Based Audio Classification Using Pre-Trained Models and Graph Neural Networks. Sensors 2024, 24, 2106. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Smith, J.T.; Warrington, A.; Linderman, S.W. Simplified state space layers for sequence modeling. arXiv 2022, arXiv:2208.04933. [Google Scholar]
- Fu, D.Y.; Dao, T.; Saab, K.K.; Thomas, A.W.; Rudra, A.; Ré, C. Hungry hungry hippos: Towards language modeling with state space models. arXiv 2022, arXiv:2212.14052. [Google Scholar]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. Hippo: Recurrent memory with optimal polynomial projections. Adv. Neural Inform. Process. Syst. 2020, 33, 1474–1487. [Google Scholar]
- Shams, S.; Dindar, S.S.; Jiang, X.; Mesgarani, N. Ssamba: Self-supervised audio representation learning with mamba state space model. In Proceedings of the 2024 IEEE Spoken Language Technology Workshop (SLT), Macao, 2–5 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1053–1059. [Google Scholar]
- Erol, M.H.; Senocak, A.; Feng, J.; Chung, J.S. Audio mamba: Bidirectional state space model for audio representation learning. IEEE Sign. Process. Lett. 2024, 31, 2975–2979. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Yu, R.; Yu, W.; Wang, X. Kan or mlp: A fairer comparison. arXiv 2024, arXiv:2407.16674. [Google Scholar]
- Mu, W.; Yin, B.; Huang, X.; Xu, J.; Du, Z. Environmental sound classification using temporal-frequency attention based convolutional neural network. Sci. Rep. 2021, 11, 21552. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Zhang, P.; Li, S. TF-SepNet: An Efficient 1D Kernel Design in Cnns for Low-Complexity Acoustic Scene Classification. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 821–825. [Google Scholar]
- Kim, B.; Chang, S.; Lee, J.; Sung, D. Broadcasted residual learning for efficient keyword spotting. arXiv 2021, arXiv:2106.04140. [Google Scholar]
- Lee, J.-H.; Choi, J.-H.; Byun, P.M.; Chang, J.-H. Multi-Scale Architecture and Device-Aware Data-Random-Drop Based Fine-Tuning Method for Acoustic Scene Classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2022, Nancy, France, 3–4 November 2022. [Google Scholar]
- Tan, Y.; Ai, H.; Li, S.; Plumbley, M.D. Acoustic scene classification across cities and devices via feature disentanglement. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1286–1297. [Google Scholar] [CrossRef]
- McDonnell, M.D.; Gao, W. Acoustic scene classification using deep residual networks with late fusion of separated high and low frequency paths. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 141–145. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Schmid, F.; Masoudian, S.; Koutini, K.; Widmer, G. CP-JKU submission to dcase22: Distilling knowledge for low-complexity convolutional neural networks from a patchout audio transformer. Tech. Rep. Detect. Classif. Acoust. Scenes Events (DCASE) Chall. 2022. Available online: https://dcase.community/documents/challenge2022/technical_reports/DCASE2022_Schmid_77_t1.pdf (accessed on 17 June 2025).
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Morocutti, T.; Schmid, F.; Koutini, K.; Widmer, G. Device-robust acoustic scene classification via impulse response augmentation. In Proceedings of the 2023 31st European Signal Processing Conference (EUSIPCO), Helsinki, Finland, 4–8 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 176–180. [Google Scholar]
- Yang, Y.; Yuan, G.; Li, J. Sffnet: A wavelet-based spatial and frequency domain fusion network for remote sensing segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3000617. [Google Scholar] [CrossRef]
- Huang, W.; Pan, J.; Tang, J.; Ding, Y.; Xing, Y.; Wang, Y.; Wang, Z.; Hu, J. Ml-mamba: Efficient multi-modal large language model utilizing mamba-2. arXiv 2024, arXiv:2407.19832. [Google Scholar]
- Liu, J.; Yang, H.; Zhou, H.-Y.; Xi, Y.; Yu, L.; Li, C.; Liang, Y.; Shi, G.; Yu, Y.; Zhang, S. Swin-Umamba: Mamba-Based Unet with Imagenet-Based Pretraining, International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2024; pp. 615–625. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. Adv. Neural Inform. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- Chen, C.-S.; Chen, G.-Y.; Zhou, D.; Jiang, D.; Chen, D.-S. Res-vmamba: Fine-grained food category visual classification using selective state space models with deep residual learning. arXiv 2024, arXiv:2402.15761. [Google Scholar]
- Tang, T.; Chen, Y.; Shu, H. 3D U-KAN implementation for multi-modal MRI brain tumor segmentation. arXiv 2024, arXiv:2408.00273. [Google Scholar]
- Heittola, T.; Mesaros, A.; Virtanen, T. Acoustic scene classification in dcase 2020 challenge: Generalization across devices and low complexity solutions. arXiv 2020, arXiv:2005.14623. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- Schmid, F.; Morocutti, T.; Masoudian, S.; Koutini, K.; Widmer, G. Distilling the knowledge of transformers and CNNs with CP-mobile. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2023 Workshop (DCASE2023), Tampere, Finland, 21–22 September 2023; pp. 161–165. [Google Scholar]
- Yifei, O.; Srikanth, N. Low Complexity Acoustic Scene Classification with Moflenet; Nanyang Technological University: Singapore, 2024. [Google Scholar]
- Koutini, K.; Eghbal-zadeh, H.; Widmer, G. Receptive field regularization techniques for audio classification and tagging with deep convolutional neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1987–2000. [Google Scholar] [CrossRef]
- Li, Y.; Tan, J.; Chen, G.; Li, J.; Si, Y.; He, Q. Low-complexity acoustic scene classification using parallel attention-convolution network. arXiv 2024, arXiv:2406.08119. [Google Scholar]
- Verbitskiy, S.; Berikov, V.; Vyshegorodtsev, V. Eranns: Efficient residual audio neural networks for audio pattern recognition. Pattern Recognit. Lett. 2022, 161, 38–44. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.-F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- Boddapati, V.; Petef, A.; Rasmusson, J.; Lundberg, L. Classifying environmental sounds using image recognition networks. Procedia Comput. Sci. 2017, 112, 2048–2056. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Comparison of Pre-Trained CNNs for Audio Classification Using Transfer Learning. J. Sens. Actuator Netw. 2021, 10, 72. [Google Scholar] [CrossRef]
- Han, B.; Huang, W.; Chen, Z.; Jiang, A.; Chen, X.; Fan, P.; Lu, C.; Lv, Z.; Liu, J.; Zhang, W.-Q. Data-Efficient Acoustic Scene Classification via Ensemble Teachers Distillation and Pruning. arXiv 2024, arXiv:2410.20775v1. [Google Scholar]
- Nadrchal, D.; Rostamza, A.; Schilcher, P. Data-efficient acoustic scene classification with pre-trained CP-Mobile; DCASE2024 Challenge. Tech. Rep. 2024. Available online: https://dcase.community/documents/challenge2024/technical_reports/DCASE2024_MALACH24_70_t1.pdf (accessed on 17 June 2025).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Devices Name | Type | 100% Subset | 50% Subset | 25% Subset | 10% Subset | 5% Subset |
|---|---|---|---|---|---|---|
| A | Real | 102,150 | 51,100 | 25,520 | 10,190 | 5080 |
| B | Real | 7490 | 3780 | 1900 | 730 | 380 |
| C | Real | 7480 | 3780 | 1920 | 790 | 380 |
| S1 | Simulated | 7500 | 3720 | 1840 | 740 | 380 |
| S2 | Simulated | 7500 | 3700 | 1850 | 750 | 380 |
| S3 | Simulated | 7500 | 3720 | 1870 | 760 | 380 |
| Total | 139,620 | 69,800 | 34,900 | 13,960 | 6980 |
| Model | 5% Subset | 10% Subset | 25% Subset | 50% Subset | 100% Subset | Avg |
|---|---|---|---|---|---|---|
| TFWConv + MLPs | 44.36 | 48.52 | 54.67 | 58.44 | 60.54 | 53.30 |
| TFWConv + KAN layers | 45.68 | 49.48 | 55.38 | 58.86 | 61.83 | 54.24 |
| Model | 5% Subset | 10% Subset | 25% Subset | 50% Subset | 100% Subset | Avg |
|---|---|---|---|---|---|---|
| TFWConv + GTSAU + KAN layers | 44.61 | 50.22 | 55.66 | 60.83 | 60.21 | 54.30 |
| TFWConv + VSS + KAN layers | 45.22 | 50.05 | 55.77 | 59.12 | 61.97 | 54.43 |
| ours | 47.84 | 51.88 | 57.89 | 60.06 | 63.14 | 56.16 |
| Model | 5% Subset | 10% Subset | 25% Subset | 50% Subset | 100% Subset | Avg |
|---|---|---|---|---|---|---|
| DECASE Baseline | 42.40 | 45.29 | 50.29 | 53.19 | 56.99 | 49.63 |
| MofleNet57 | 41.64 | 45.46 | 52.46 | 56.85 | 59.31 | 51.14 |
| CP-ResNet59 | 44.98 | 49.28 | 54.93 | 57.87 | 59.57 | 53.33 |
| BC-PACN-48 | 46.44 | 52.61 | 57.41 | 59.75 | 61.95 | 55.63 |
| TF-SepNet-64 | 45.70 | 51.10 | 55.60 | 59.60 | 62.50 | 54.90 |
| ours | 47.84 | 51.88 | 57.89 | 60.06 | 63.14 | 56.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, F.; Yang, L. Research on Acoustic Scene Classification Based on Time–Frequency–Wavelet Fusion Network. Sensors 2025, 25, 3930. https://doi.org/10.3390/s25133930
Bi F, Yang L. Research on Acoustic Scene Classification Based on Time–Frequency–Wavelet Fusion Network. Sensors. 2025; 25(13):3930. https://doi.org/10.3390/s25133930
Chicago/Turabian StyleBi, Fengzheng, and Lidong Yang. 2025. "Research on Acoustic Scene Classification Based on Time–Frequency–Wavelet Fusion Network" Sensors 25, no. 13: 3930. https://doi.org/10.3390/s25133930
APA StyleBi, F., & Yang, L. (2025). Research on Acoustic Scene Classification Based on Time–Frequency–Wavelet Fusion Network. Sensors, 25(13), 3930. https://doi.org/10.3390/s25133930