Abstract
This paper presents a novel method for centralized robotic swarm control that integrates path planning and task allocation subsystems. A swarm of agents is managed using various evaluation methods to assess performance. A feedforward neural network was developed to assign tasks to swarm agents in real time by predicting a suitability score. For centralized swarm planning, a hybrid algorithm combining Rapidly Exploring Random Tree (RRT) and Artificial Potential Field (APF) planners was implemented, incorporating a Multi-Agent Pathfinding (MAPF) solution to resolve simultaneous collisions at intersections. Additionally, experimental hardware using differential-drive, ArUco-tracked agents was developed to refine and demonstrate the proposed control solution. This paper specifically focuses on the swarm system design for applications in swarm reconfigurable manufacturing systems. Therefore, performance was evaluated on tasks that resemble such processes.
1. Introduction
A swarm of robots involves the coordination of multiple robots, or in swarm terminology, agents that can perform a collective task and solve a problem more efficiently than a single robot, defined in [1]. Real-world applications of swarm systems are rising, other than logistics where swarms are currently an industrial standard—e.g., Amazon uses more than 750,000 robots to handle logistics, as stated in [2]. Control of such robotic swarm systems mainly depends on the type of communication network utilized. Robot swarms that utilize centralized communication often rely on grid environmental models with modulations of known methods such as the Ant Colony Optimization (ACO) planning solution described in [3] or A* researched in [4]. The problem of swarms is the need for the adaptation of such planning methods for multi-agent planning without time–place collisions, known as the Multi-Agent Path Finding (MAPF) problem, researched in [5,6]. However, grid-based planning methods such as MAPF are limited in continuous and dynamic environments, where discrete grids impose unnecessary constraints on agent movement. For such free-space path planning scenarios, especially in highly reconfigurable layouts, hybrid methods like Rapidly Exploring Random Trees combined with Artificial Potential Fields (RRT-APF) offer a scalable and flexible alternative.
In contrast to the fundamental principles of Industry 4.0 described in [7], the current global focus has shifted towards the development of newer and more advanced principles, which are discussed in this article. Reconfigurable Manufacturing Systems (RMSs), originally proposed in [8], are labeled as the future of the manufacturing process. In RMSs, machines are required to change their position in real time to cover the production demand. This transportation, or reconfiguration of the entire line, can be handled by a centralized robotic swarm system as we propose and as also introduced in [9]. RMSs with swarms require positional freedom and flexibility, and they cannot be grid environments. Therefore, an effective control system for this purpose must be researched. Let us propose an example scenario for usage of an RMS with swarm—a company wants to automatize tailor-made products, but they vary in the manufacturing process due to the different varieties of the product wanted by the customers. A proper approach would be to build an RMS with swarms to handle any product variation within the factory. This type of factory would only be sustainable in the case of a high continuous demand for tailor-made products. In this research, we decided to explore the application of swarms into RMSs with the objective of developing an effective control system suitable to handle such use cases. A conceptual 3D render of a swarm applied to the reconfiguration of a manufacturing line is shown in Figure 1.
Figure 1.
Illustrative rendering of a Reconfigurable Manufacturing System (RMS) featuring a robotic swarm application. The system includes robotic arms and mobile platforms collaborating within a flexible work environment.
Several centralized swarm control strategies have been proposed in the literature, focusing primarily on efficient task assignment and motion coordination. Auction-based methods, such as Contract Net Protocols and First-Price Auctions, enable robots to bid for tasks based on estimated costs or utilities [10]. These strategies are often simple to implement but may result in suboptimal global allocations. More sophisticated approaches employ centralized scheduling algorithms inspired by operations research, where the allocation problem is solved as a constraint satisfaction or optimization problem [11]. Tools such as Google OR-Tools [12] provide scalable solvers for routing and scheduling problems in logistics, which can be adapted to swarm control. However, these approaches typically assume static environments or grid-based motion planning, making them less suited for dynamic or continuous-space scenarios like those found in RMSs. This research aims to overcome these limitations by combining learning-based allocation with sampling-based continuous-space planning.
2. Materials and Methods
2.1. Problem Statement
A robotic swarm is a coordinated group of n robots, mathematically represented as a set . In this research, the robots are modeled as systems with differentially driven chassis, which results in relatively straightforward kinematics. The swarm S collaborates to accomplish a defined mission where each task is assigned to an individual robot or a subset consisting of fewer than n robots. The primary objective of deploying a robotic swarm is to accomplish the mission M more efficiently than a single robot operating independently. Each robot is defined by a state matrix (1) that captures its state within the environment and its structural parameters, enabling it to be treated as an object in the system.
where:
- —Cartesian coordinates of the robot,
- —Rotation around the Y-axis,
- —Dimensions of the robot,
- —Instantaneous velocity,
- —Instantaneous angular velocity,
- E—Effector type, varying by application,
- —State of Charge, representing the battery percentage.
The E parameter in (1) specifies the effector technology used by the robot, which varies based on the task requirements. For instance, may be equipped with a 3-axis robotic arm (), whereas may use an electromagnetic gripper for transportation (). Consequently, a task that involves machine transportation would require a robot with an electromagnetic gripper (), making the suitable candidate among the available agents. Each robot is further characterized by mission-related parameters.
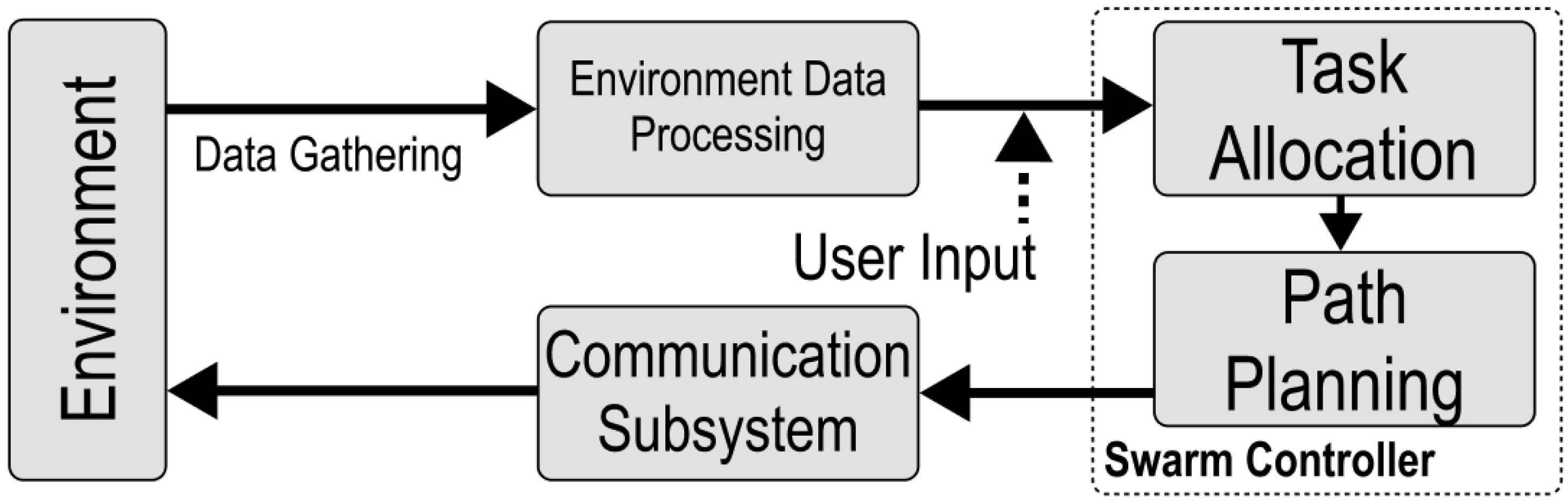
The swarm is considered centralized when all robots communicate with a central computer, which is responsible for generating their paths and assigning tasks. Efficient task allocation and path planning are critical for swarm performance. The system managing these functions on the central computer is referred to as the Robotic Swarm Controller, shown in Figure 2, which consists of two key subsystems: a task allocator and path planner.
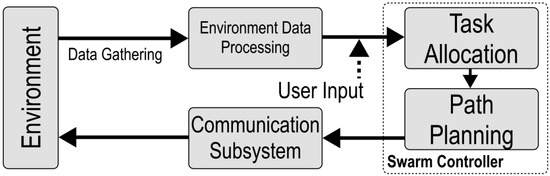
Figure 2.
Block diagram of the swarm controller comprising task allocation and path planning subsystems.
The task allocation problem involves assigning a set of tasks M to the agents in the swarm S with the objective of minimizing the assignment cost. The assignment of to should represent the minimum-cost option, as opposed to assigning .
The path planning problem can be defined as a search process for the minimum-cost path. Let denote the state space of the environment, where in this research, the swarm operational environment is modeled as a Cartesian XY system without prescribed node limitations. Using such notation is needed in order to utilize swarm within modular factories with possible human presence, and also to capture to the dynamic character. Planning a path involves searching for the minimum-cost, chassis-optimized route for between the coordinates and in space Q, where task is assigned to robot . To ensure that task is properly completed, must avoid collisions with any obstacle from the set of obstacles . as well as with any other robot .
An optimal path P is generated when it satisfies the collision-free criterion while minimizing cost, thereby increasing overall system performance. However, system effectiveness is also influenced by operational factors beyond movement, such as the effector action performed by during . Both the task allocation and path planning subsystems aim to minimize cost, where the cost is defined in terms of time and energy consumed by to complete task . The cost minimization objectives are mathematically defined in (2) and (3).
2.2. Performance Indicators
The performance of a robotic swarm S executing a mission M is expected to meet predefined efficiency and accuracy standards. Deviations from the expected performance, due to suboptimal path generation or task allocation, lead to a measurable decrease in the overall performance of the swarm. An ideal swarm operation would minimize such deviations, but errors are inevitable in practical scenarios. These performance losses are reflected in the increase of either the time-based cost function (2) or the energy-based cost function (3).
To quantitatively assess the performance of the swarm, appropriate Key Performance Indicators (KPIs) must be established to identify the sources of these errors. We researched our KPIs for the application of swarms specifically in modular manufacturing. Prior research [13] described most of the key metrics—scalability, robustness, fault tolerance. However, most of the KPIs are for decentralized robotic swarms. We adapted these metrics onto the centralized swarm.
2.2.1. Perfomance Indicator
The swarm’s performance P on a mission M depends on key mission parameters. For instance, if the mission objective is to transport packages from place A to place B, P can be evaluated based on:
- The number of packages transported within a given time span,
- The amount of time required to transport a certain number of packages.
In the context of a robotic swarm factory, performance can be defined primarily by the time required to perform a reconfiguration. Since time directly correlates with production costs, it serves as the most critical factor in evaluating swarm performance within modular manufacturing systems.
2.2.2. General Effectiveness Indicator
The overall effectiveness of a swarm S executing a mission M can be expressed as the geometric mean of individual task completion rates within a unit interval:
The task completion rate is primarily determined by the cost-time and cost-energy indicators defined in (2) and (3). The completion rate accounts for the extent to which a task is completed, such as the number of machines transported by the swarm within a mission interval compared to the expected one or any precision, e.g., placement precision parameters achieved during task execution. The geometrical mean in (4) is used to capture low completion rates and their impact on overall mission completion. The completion rate is defined as follows:
where:
- and —Scaling factors that weight time and energy, respectively,
- and —Time and energy consumed by robot to complete task ,
- and —Maximum expected time and energy, obtained through testing across n possible path generations.
The scaling factors and allow for adjustment of the evaluation priority between time and energy. If minimizing time is more critical than energy consumption, then , and vice versa. Equation (5) can be substituted into Equation (4), yielding a general time–energy efficiency formula for the swarm. This can be further generalized to include additional parameters that contribute to swarm effectiveness, as denoted in (6):
where are performance-related parameters (e.g., precision, task completion rate, or operational reliability) that contribute to the overall swarm effectiveness. This generalized form allows for evaluating swarm performance across multiple dimensions, including task accuracy, resource utilization, and operational efficiency.
Effectiveness determination can be evaluated within the time interval , where and represent the time constraints associated with the mission M or a specific task . All accountable variables influencing performance are assessed within this time interval, ensuring a consistent and comprehensive evaluation of swarm efficiency. Alternatively, effectiveness can also be evaluated at an instantaneous time by taking the instantaneous values of the relevant parameters.
2.2.3. Contribution Indicator
Imagine a scenario of swarm S, with, e.g., 10,000 robots working on operating an autonomous factory without breaks. The probability that , where has failed before and is now a static obstacle at due to an unexpected motor failure or a collision with an obstacle or agent due to sensory error, decreases the swarm performance.
An agent ’s contribution to the overall varies in ; therefore, the failure of a certain can cause a bigger drop in one of the KPIs compared to a failure of . Subsequently, can be replaced by a new from the docking station, but this process requires the transportation of to the operators to fix the issue as well as transportation of the mentioned replacement, both significantly contributing to KPI. A different case involves no agent malfunctions, where agent is assigned to —contributing to overall performance—while is without an assigned t or its t is less valuable in M, e.g., a side task of collecting data to use them in analysis. In this case, M—the line reconfiguration—will be completed even when fails its task or completes it with poor KPI. This leads to a need for a weight system to analyze the contribution of any R to KPI. Each performance must be weighted.
2.2.4. Scalability Limit Indicator
Scalability analysis examines the performance of a system as its size increases, specifically as additional units are added [14]. In the context of robotic swarms, scalability analysis evaluates the performance of a swarm S on a task M as the size of S increases. A swarm control system is considered scalable if its performance meets two key conditions, (7) and (8), as described in [13,15].
- The performance increases or remains stable with the addition of new agents:
- The performance gain from adding new agents exceeds the average performance per agent:
In centralized swarms, diminishing scalability can often be mitigated by increasing computational power and improving communication networks. Thus, scalability becomes a significant factor primarily when resources are limited. For centralized swarms, this suggests a refined definition of scalability: the performance of a robotic swarm increases only up to a certain limit, beyond which agents are no longer able to execute their paths effectively due to high robot density or high obstacle density within the operational space.
This threshold is known as the scalability limit, defined as the maximum swarm size that can operate effectively within a given area. It is estimated with Formula (9):
where:
- A is the total available operational area,
- is the fraction of area occupied by obstacles (obstacle area density),
- is the average area required per robot, including space needed for safe operation.
2.3. Task Allocation
The process of assigning a task to a robot or a group involves predicting suitability based on multiple parameters, including the state matrix, task specifications, and environmental data. Given the complexity of these non-linear relationships, a machine learning-based approach was adopted. The dynamic nature of the swarm, where may vary during the execution of M, introduces significant challenges in network design and training. To address this, a predictive model was developed to estimate a suitability score for each robot concerning a given task .
The suitability score is a normalized unit interval metric that quantifies the appropriateness of a specific robot for a particular task. The prediction process is executed for each agent, and the robot with the highest suitability score is selected for task execution. Computational efficiency is enhanced by filtering out agents that are ineligible due to insufficient battery charge, incompatible effector technology, or physical constraints that prevent successful task completion.
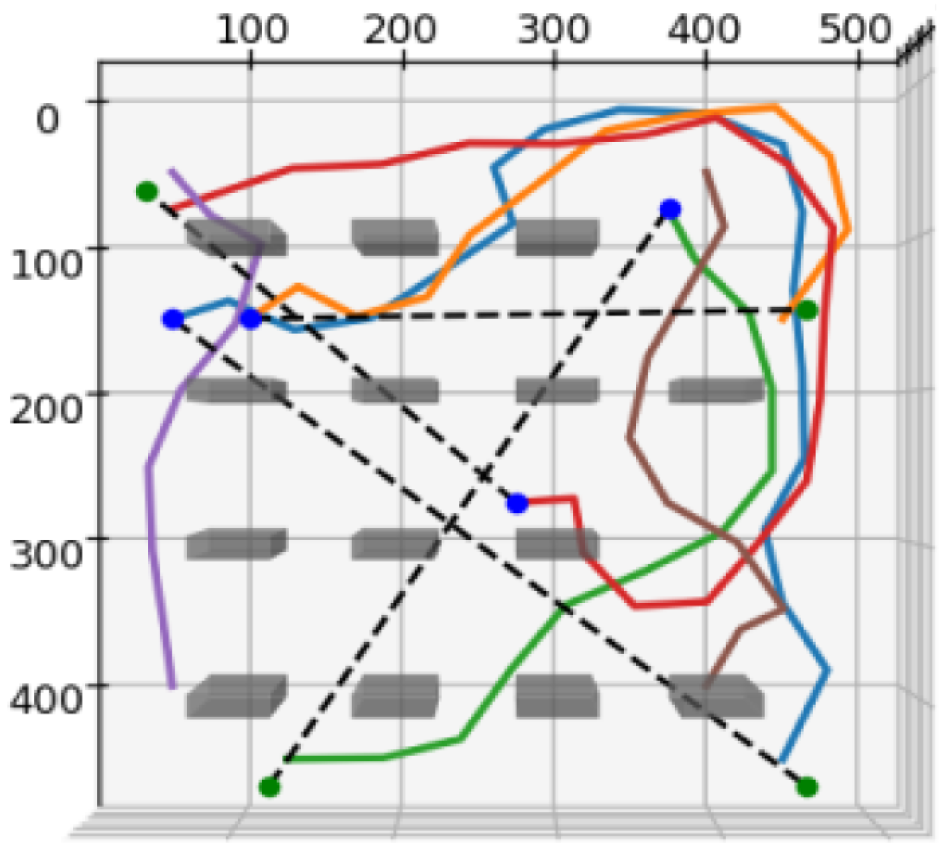
A Feedforward Neural Network (FNN) architecture was selected due to its demonstrated capability to model non-linear data relationships and its architectural simplicity, which facilitates efficient training and deployment. The training phase involved generating a dataset through simulation to capture the complex interactions among robot states, task requirements, and environmental variables. This simulation provided the necessary input–output pairs for training the FNN, enabling the model to generalize across diverse operational scenarios. Additionally, an alternative training approach using bootstrapped learning was explored. In this approach, a simulation is executed, and the model assigns a reward to each time step . The robot follows the path, executes the task, and the effectiveness is translated into a reward for the model. From this reward, the Mean Absolute Error (MAE) loss is computed. Therefore, using this techique, the FNN is able to generalize to heterogenous unseen scenarios as each simulation is generated. Figure 3 presents a representative plot illustrating an example of the synthetic data generation process.
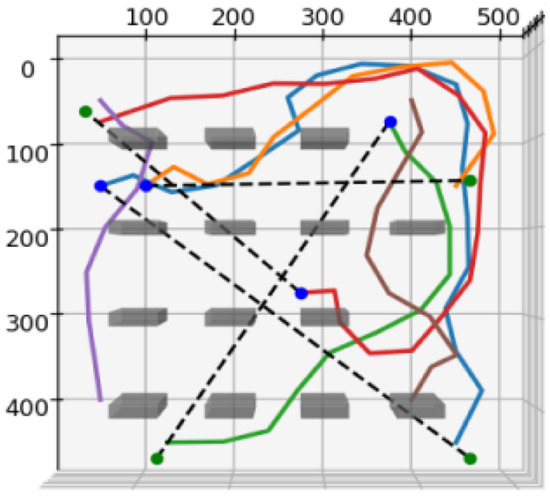
Figure 3.
Simulation plots illustrating data collection for task and agent analysis, generated using an unoptimized RRT algorithm. (Dashed lines indicate allocation, solid lines depict paths, and colored dots represent swarm agents).
The suitability score used as the output was obtained during training by evaluating the effectiveness of on task . This was achieved by simulating task execution and computing the efficiency metric using Equation (6), which is based on time and energy E. The suitability score directly reflects task execution efficiency. For example, if two robots and are both evaluated for a specific task , and the resulting simulation yields , then is deemed more suitable for executing . All data was generated using a custom-built 2D continuous-space simulator developed in Python (version 3.11). The environment integrates NumPy (version 1.26) for matrix operations, Matplotlib (version 3.8) for visualization, and a basic physics engine that models robot kinematics, energy consumption, and effector–task compatibility. The simulator includes obstacle placement, collision detection, and path generation using an unoptimized RRT module. Tasks and agents were initialized with randomized positions and parameters within a bounded 1000 × 1000 unit environment under varying obstacle densities.
A Feedforward Neural Network (FNN) was developed to predict the suitability score, shown in Figure 4. The architecture consists of an input layer, a Multi Layer Perceptron (MLP) with four hidden layers, and a single output neuron activated by a sigmoid function. The network layers are defined as follows:
where in (11):
- (Input Layer): The input vector , where corresponds to the number of input features. Specifically, corresponds to the dataset variables defined in Table 1. All input features are normalized to the range to ensure uniform scaling across the input space.
- (Hidden Layers): The architecture includes four fully connected hidden layers with neuron counts , respectively. The ReLU activation function was selected due to its efficiency and sparse activation properties.
- (Output Layer): The output layer produces a single scalar value representing the suitability score for robot on task . The output value is constrained to the unit interval using a sigmoid activation function.
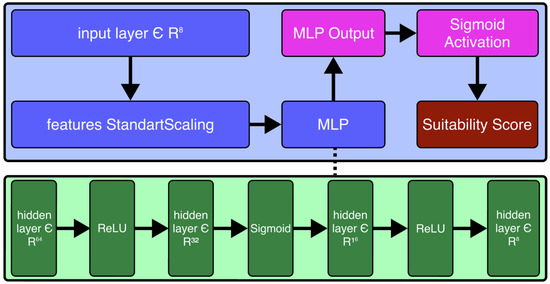
Figure 4.
Feedforward neural network architecture diagram. The blue boxes represent preprocessing and the main multilayer perceptron (MLP) structure. Green boxes illustrate hidden layers with various activation functions. The pink box denotes the MLP output, and the red box is the final suitability score after sigmoid activation. The dashed line indicates the internal structure of the MLP.
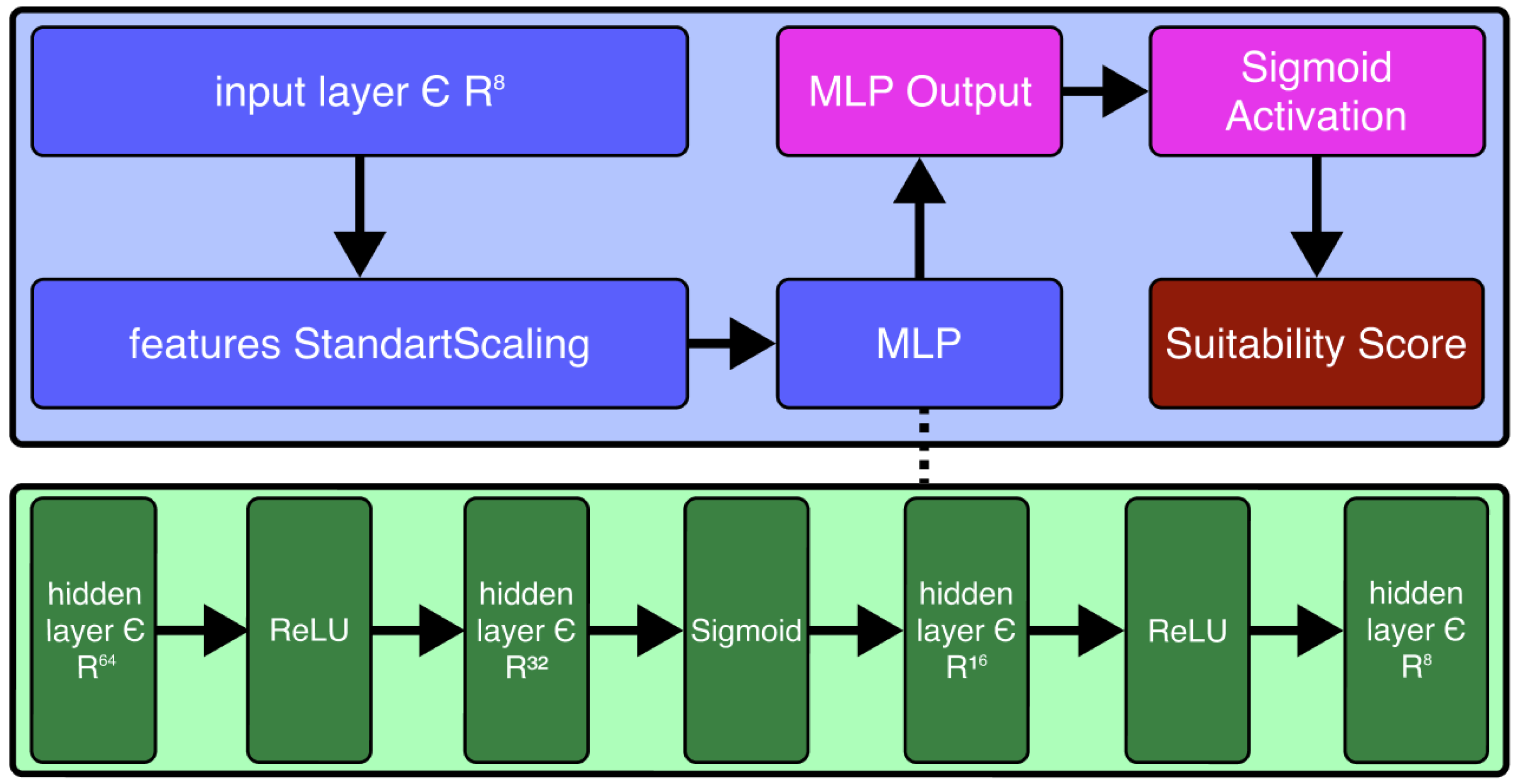

Table 1.
Example dataset.
The ReLU activation function was chosen for the hidden layers due to its ability to mitigate the vanishing gradient problem and promote sparsity, thereby improving training efficiency.
The network was trained using TensorFlow’s built-in Adam optimizer, which is based on a stochastic gradient descent method with adaptive moment estimation (ADAM), originally proposed in [16]. The loss function employed during training and validation was the mean absolute error (MAE). The Adam optimizer’s adaptive learning rate and moment estimation capabilities ensured fast convergence and stable learning dynamics.
2.4. Path Planning
Path planning algorithms are generally classified as either local or global, as described in [17]. Recent literature has explored path planning methods implemented on real-world platforms; for instance, ref. [18] proposed a cross-platform deep reinforcement learning (RL) model for autonomous local navigation, demonstrating its effectiveness across a variety of scenarios, which is highly relevant for RMS applications where flexibility and real-time adaptability are critical. Unlike grid-based methods such as ACO or A*, RL-based path planning offers robustness in continuous-space environments, which is suitable for swarm-based RMS. However, RL methods often require extensive training and may struggle with multi-agent coordination without centralized synchronization. For swarm-based operations in modular manufacturing environments, global path planning is essential. Our approach aims to develop a swarm-specific planning framework, leading to improved scalability and real-time coordination efficiency in MAPF scenarios.
2.4.1. Global Path Planning
The selection of global path planning algorithms was guided by a comparative analysis of existing planning approaches, as discussed in [17,19]. In this work, multiple global path planning methods were integrated and categorized under a centralized planning framework. This is necessary because the swarm operates in a modular factory, where even local adjustments (such as collision avoidance in response to unexpected obstacles, denoted as ) must be processed through a centralized mechanism to maintain consistency and coordination.
For path generation, we selected the Rapidly Exploring Random Tree (RRT) algorithm, originally introduced in [20]. RRT is a sampling-based method that constructs a tree of nodes in the configuration space Q, from which a feasible path is extracted. RRT is particularly effective for exploring non-convex and high-dimensional spaces due to its incremental nature and bias toward unexplored regions. Its capability to handle real-time scheduling requirements has been validated in [21], although the generation time is highly dependent on the complexity of Q, the resolution of the tree, and the swarm size . However, as highlighted in [21], RRT efficiency declines significantly in environments with narrow passages or dense obstacles because a large portion of computations is consumed by collision checking.
To address RRT’s limitations in complex environments, we incorporated the Artificial Potential Field (APF) algorithm for collision avoidance and local path optimization. The APF method, first proposed in [22], defines two forces acting on the robot:
- —Repulsive force generated by obstacles to prevent collisions,
- —Attractive force generated by the target position to guide the robot toward the goal.
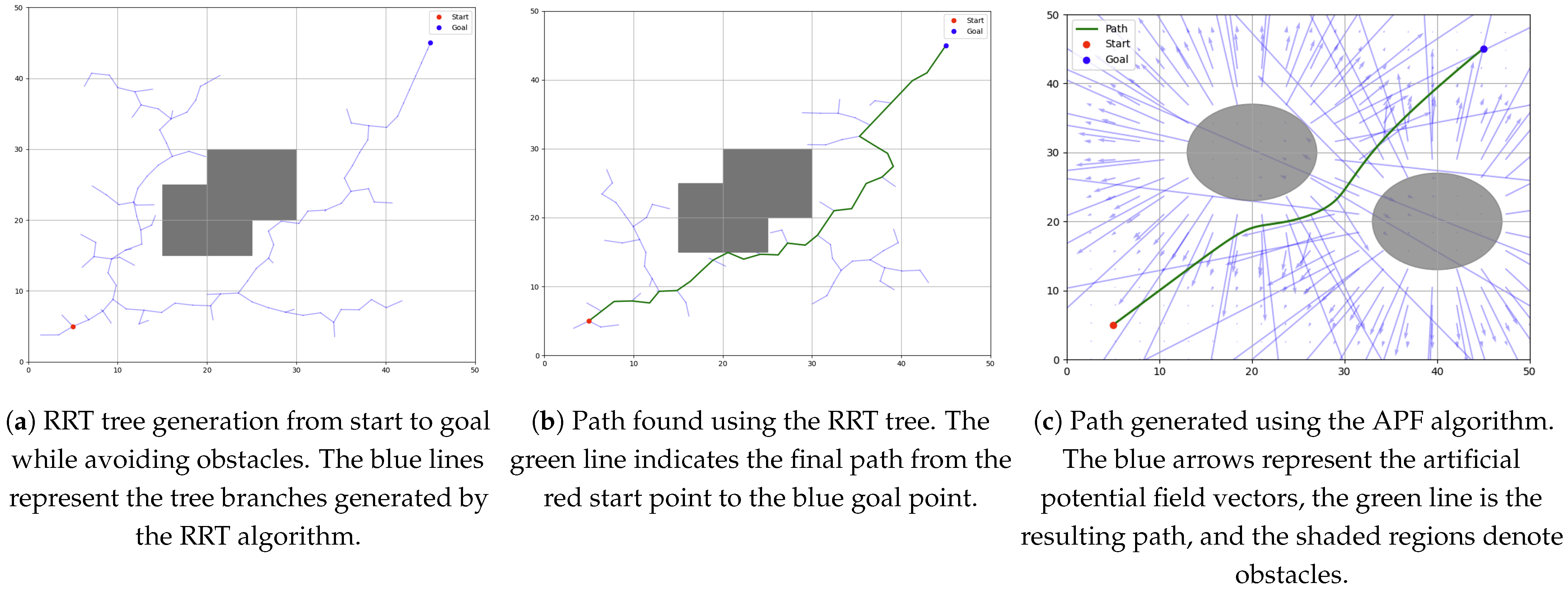
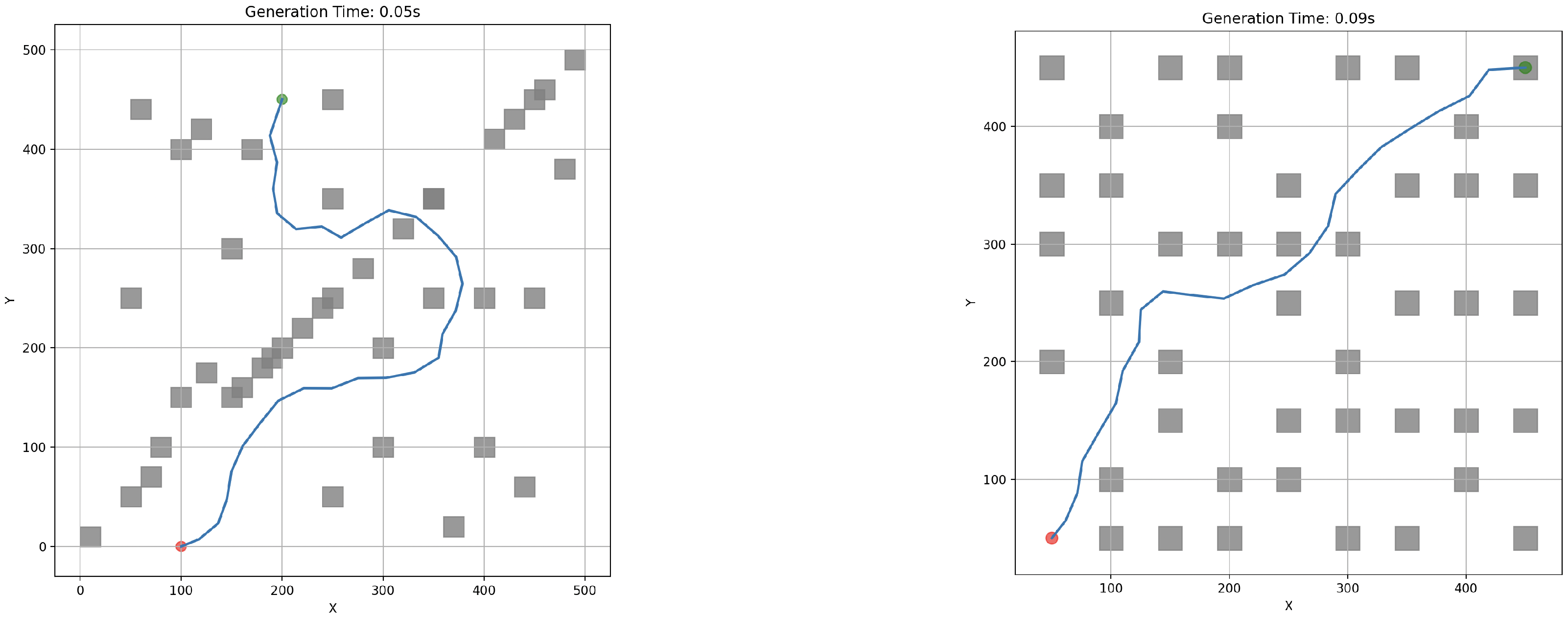
APF is well-suited for real-time dynamic adjustment because it generates smooth and continuous paths while enabling obstacle avoidance. However, it suffers from limitations such as local minima and oscillations near obstacles, which have been discussed in [23]. Despite this, APF remains valuable for improving the local efficiency of path generation, particularly when integrated with a global planning algorithm like RRT. Demonstrative plot examples of paths generated with RRT and APF are shown on Figure 5.
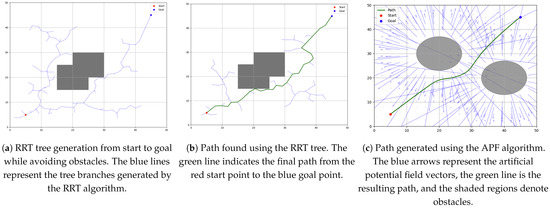
Figure 5.
Example usage of RRT and APF algorithms for single-agent path generation. (a) RRT tree example. (b) RRT path example. (c) APF path planning example.
2.4.2. Hybrid RRT-APF Approach
Hybridization of RRT and APF has been explored in recent research, where RRT generates an initial path and APF subsequently refines it for local adjustments and obstacle avoidance [24,25]. However, such hybrid approaches are often computationally expensive when scaled to multi-agent systems because they rely on post-processing of the RRT-generated path. In swarm-based settings, computational load scales with , creating a bottleneck for real-time execution.
To overcome this limitation, we propose a novel inline RRT-APF hybrid approach, where APF is directly embedded into the RRT process. Specifically, for each node r generated by RRT, if the node collides with an obstacle , the APF force vector is computed and applied to relocate the node in a collision-free direction. This adjustment is formulated in (12):
where:
- —nearest existing node in the RRT tree,
- —fixed step size for tree expansion,
- —resultant force computed from repulsive and attractive field contributions.
As RRT step size is directly related to the size of the environment as well as the obstacle density, we adopted a variable step size strategy, which is described in detail in [26]. The APF algorithm coefficients—attractive and repulsive coefficients—were tuned with an adaptive approach based on obstacles, as proposed in [27].
The inline correction using APF reduces the number of discarded nodes due to collision checking and increases the efficiency of tree expansion in complex environments. This approach ensures that RRT retains its exploratory strength while leveraging APF’s local adjustment capabilities, resulting in more direct and obstacle-aware path generation. The proposed inline hybrid approach has several advantages over conventional hybrid methods, such as the following:
- Reduced computational overhead—The direct correction of RRT nodes using APF reduces the need for post-processing and improves real-time performance.
- Improved path quality—The APF adjustment leads to smoother and more obstacle-aware paths, especially in confined environments.
- Reduced collision rate—Early rejection of infeasible nodes by the APF prevents excessive tree expansion in complex areas, improving the overall search efficiency.
This hybrid RRT-APF framework, described in Algorithm 1, addresses the limitations of both algorithms and enhances the swarm’s ability to execute complex pathfinding tasks in dynamic modular manufacturing settings.
| Algorithm 1 RRT-APF Path Generation |
|
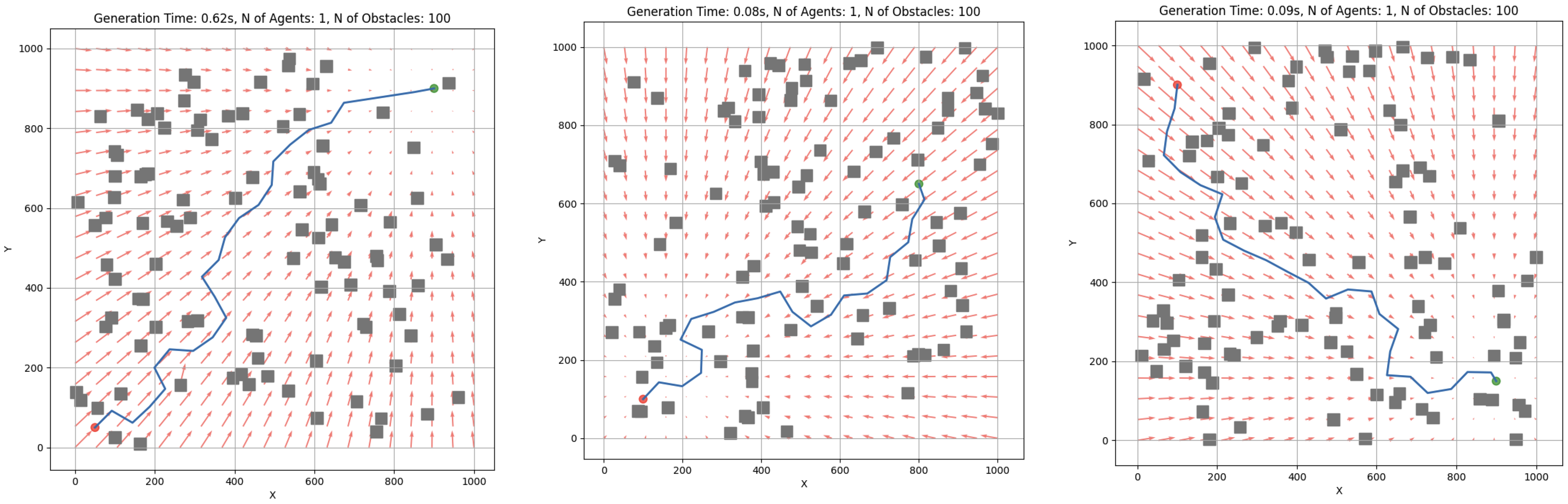
Figure 6 visually demonstrates how the RRT-APF algorithm performs path planning in environments, combining the strengths of sampling-based exploration and potential field guidance. The RRT-APF path planning algorithm features multiple tunable coefficients that can significantly affect the performance of the subsystem. The variable defines the attraction towards goals, while defines the repulsion from obstacles. When , the path may ignore obstacles, but when , the agent may get stuck, or the path will be planned inefficiently. These coefficients need to be optimized based on the environment.
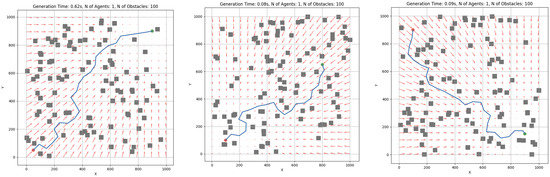
Figure 6.
Example usage of RRT and APF algorithms for single-agent path generation. The blue line represents the path from start (red point) to goal (green point), avoiding obstacles (grey squares). Red arrows represent artificial potential field vectors (used in APF).
2.4.3. MAPF Approach
The Multi-Agent Path Finding (MAPF) system transforms path planning from a single-agent paradigm to one involving a swarm of multiple moving agents. In traditional path planning algorithms, agents compute their paths independently, without accounting for the presence of other agents. However, in the MAPF context, paths must be planned while considering potential conflicts between agents along their trajectories.
To address this, a new concept and method called the swarm clock was developed. This algorithm is named swarm clock because it tracks each agent’s position over time, enabling real-time adjustments based on interactions between agents. Swarm therefore works under a certain synchronized time—swarm clock—to prevent inconvenient planning and asynchrony. The method is described in Algorithm 2.
| Algorithm 2 MAPF Collision Prediction |
|
The Path-Time-Intersection-Predictor function takes the entire swarm state matrix S as input. However, in large swarm systems, the function can be optimized by considering only agents within a predefined vicinity of path . The predictor calculates all possible collision points, mathematically defined in (13):
Here, denotes the set of collision points, determined by identifying intersections between path and every other path , for all . These intersections are obtained by solving a system of linear Equation (14) describing the respective paths:
Each path is represented as a linear equation. If this system yields a solution, it implies the paths intersect, signaling a potential collision. To assess whether agents are within collision range at the intersection point, a kinematic model is employed. This model defines the collision range as a circular area around the intersection with a radius equal to the agent’s physical size.
The swarm clock t functions as a synchronization mechanism, tracking the time elapsed since the start of the mission M. For instance, agent may be two-thirds through its path at time t, while agent may not have begun moving. Given the speed , Cartesian position , direction of movement , and trajectory , the arrival time of agent at a collision point can be estimated (15) (assuming the path comprises straight-line segments):
In this equation, s and e are the start and end indices of the path segment (from the current position to ). The terms and denote the left and right wheel velocities of agent , and the turning rate is given by (16):
where W is the distance between the agent’s wheels. If both and reach the collision point at the same time , a collision is predicted. In such cases, the algorithm regenerates the path for one or both agents to avoid the collision by introducing an imaginary obstacle at the collision point.
The swarm clock ensures synchronized movement among agents, while the collision prediction mechanism allows for dynamic, real-time path adjustments to avoid conflicts. This approach supports efficient coordination in large-scale multi-agent systems, allowing agents to operate autonomously while maintaining global harmony through continuous path updates and synchronization.
The proposed inline RRT-APF approach, combined with the swarm clock for multi-agent pathfinding, introduces several novel contributions compared to existing RRT-based path planning methods. Unlike traditional hybrid RRT-APF methods, such as those proposed by [24,25], our approach integrates APF directly into the RRT tree expansion process, enabling real-time collision avoidance during path generation rather than relying on post-processing. Ref. [24] presents APF-IRRT*, which combines an informed RRT* with APF to enhance path smoothness and convergence using a variable probability goal-bias strategy. However, their method applies APF as a post-processing step to refine RRT*-generated paths, which increases computational complexity, particularly for large swarms, due to RRT*’s iterative optimization. Similarly, ref. [25] introduce Potential Guided Directional-RRT* (PGD-RRT*), which uses potential fields to guide RRT* exploration, improving efficiency in single-agent scenarios but lacking specific mechanisms for multi-agent coordination. In contrast, our inline RRT-APF method embeds APF-based collision avoidance within the RRT tree expansion, reducing the number of discarded nodes and improving computational efficiency for both single-agent and multi-agent scenarios.
The integration of the inline RRT-APF with the swarm clock further distinguishes our approach by enabling dynamic, real-time path adjustments for multiple agents. While refs. [24,25] focus primarily on single-agent path planning or static multi-agent environments, our swarm clock synchronizes agent movements and predicts inter-agent collisions during path generation, treating collision points as imaginary obstacles within the RRT-APF framework. This ensures scalability and coordination in dynamic modular manufacturing settings, where agents must navigate complex environments with frequent interactions.
2.5. Experimental Hardware
The robot was created to further refine and demonstrate the researched control method. The objective was to design custom hardware without relying on existing kits, open-source projects, or commercially available robots. This approach allows the hardware to be specifically tailored to the requirements of the research, making it more adaptable to future applications in both research and educational environments. The agent was designed to meet several key objectives. First, the platform had to be low-cost, with a target production cost below EUR 60 per agent. Second, the design needed to be modular, featuring an option for swappable effectors to accommodate different experimental scenarios. Lastly, the agent was required to be max. mm across dimensions for experiments to be realisable in rooms or classrooms. The design parameters were a maximum velocity of at least and a numerically equal acceleration. The design had to ensure that manufacturing and assembly could be completed within an acceptable time frame, as multiple agents needed to be produced for swarm experiments, and the repairibility likely grows with assembly complexity, which is unwanted.
2.5.1. Kinematic Model
The development of the platform began with the definition of its kinematic model, which directly influenced the structural design and control approach. After reviewing relevant research, it was determined that most swarm robotic platforms rely on a differential drive chassis (2WD) due to its mechanical simplicity, low cost, and compatibility with the proposed control model based on (15) and (16). Examples include HeRo 2 [28], Amir [29], and Alice [30], which successfully implemented differential drive systems for swarm applications. A differential drive system consists of two independently driven wheels, where velocity and direction are controlled by adjusting the relative speed of each wheel. Stability in such systems is provided by an additional support ball wheel (or castor) in the back of the robot [31].
The kinematic model assumes that the robot’s velocity is determined by the combined rotational speed of the two drive wheels and that friction between the wheels and the ground is negligible. Under this assumption, the velocity of the robot is computed as (17):
where D is the wheel diameter, v is the desired velocity, and N is the wheel’s rotational speed (). Equation (17) provides a lower bound on the wheel diameter necessary to achieve the target velocity, considering the limitations of the motor’s rotational speed.
2.5.2. Structural Design
The choice of motor and wheel size was guided by the kinematic model and performance requirements. Geared DC motors were selected for actuation due to their high torque-to-size ratio and cost efficiency. After market analysis, the N20 motor series from TT Motor (Shenzhen) Industrial Co., Ltd. (Shenzhen, China) was identified as the most suitable option based on cost, performance, and availability. A motor with a nominal voltage of 12 V was selected, as higher voltage increases torque output according to the DC motor torque equation. For a differential drive system, the minimal wheel diameter D can be computed by incorporating Newton’s Second Law into the torque equation:
where M is the motor’s torque , m is the robot’s mass, and a and v are the design acceleration and velocity, respectively. Equation (18) consists of motor parameters (on the left-hand side) and design parameters (on the right-hand side, which are constant); therefore, the motor parameters can be directly substituted to determine the optimal configuration.
From the available options, a 75:1 geared DC motor with a rated speed of 400 RPM and a torque of satisfied this condition. The minimal viable wheel diameter was calculated as follows:
A wheel with a diameter of 32 mm was selected based on this calculation, as it was the best market option that fit all the requirements.
Once the motor and wheels were selected, the chassis structure was designed using computer-aided design (CAD) software—Autodesk Fusion 360 version 2.0.20981. The chassis was manufactured using fused deposition modeling (FDM) 3D printing with polylactic acid (PLA) material. PLA was selected due to its favorable strength-to-weight ratio, low cost, and ease of processing, as stated in [32]. The motors and wheels were positioned on opposite sides of the chassis, with stability provided by two support ball wheels. The design aimed to minimize weight while maintaining structural integrity.
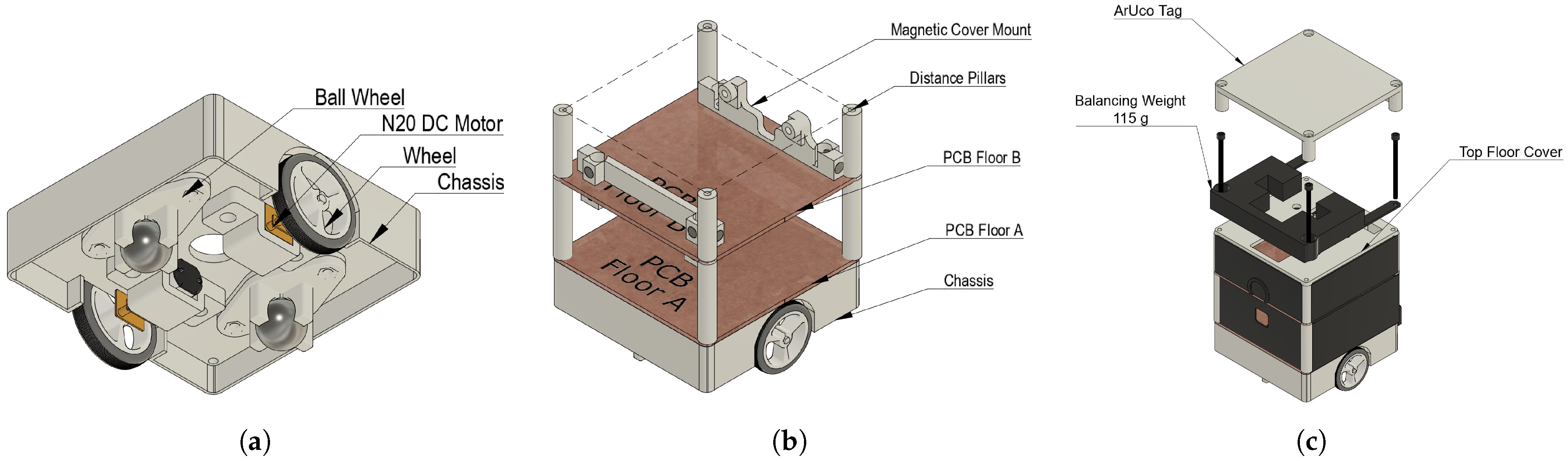
The structural design followed a layered assembly approach. The robot’s frame consisted of a floor structure where components were stacked vertically and interconnected using 3D-printed distance pillars. The modularity of the design was further enhanced by the use of a PCB-based floor structure, modeled at this stage as copper plain boards fastened together with the 3D-printed distance pillars. The magnetic cover system was added, as it ensures that the internal components are protected while allowing easy access for maintenance and modification.
The decision was made not to include the battery within the chassis itself as described Figure 7, despite the potential improvement in stability, because it would increase the height of the robot, thereby raising the center of mass and reducing maneuverability. Each motor was mounted into the main chassis body using a bracket, tightened by a nut from other the chassis side.
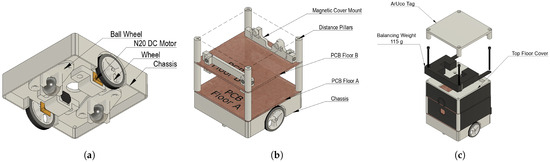
Figure 7.
Structural design using CAD for mechanical structure of agent, manufactured by FDM 3D printing. (a) Chassis design. (b) Floor structure. (c) Top floor design.
The top floor design, mounted atop a set of distance pillars from PCB Floor B, features a balancing weight to prevent the robot from turning over during a lift operation.
The final design met the target specifications for cost, velocity, and structural integrity. The selected motor and wheel combination provided sufficient torque and speed, while the modular chassis allowed for easy reconfiguration and component replacement. The use of 3D-printed materials reduced production costs and allowed for rapid iteration of the design, supporting the overall goal of developing a scalable, low-cost swarm robotic platform.
2.5.3. Electronic Design
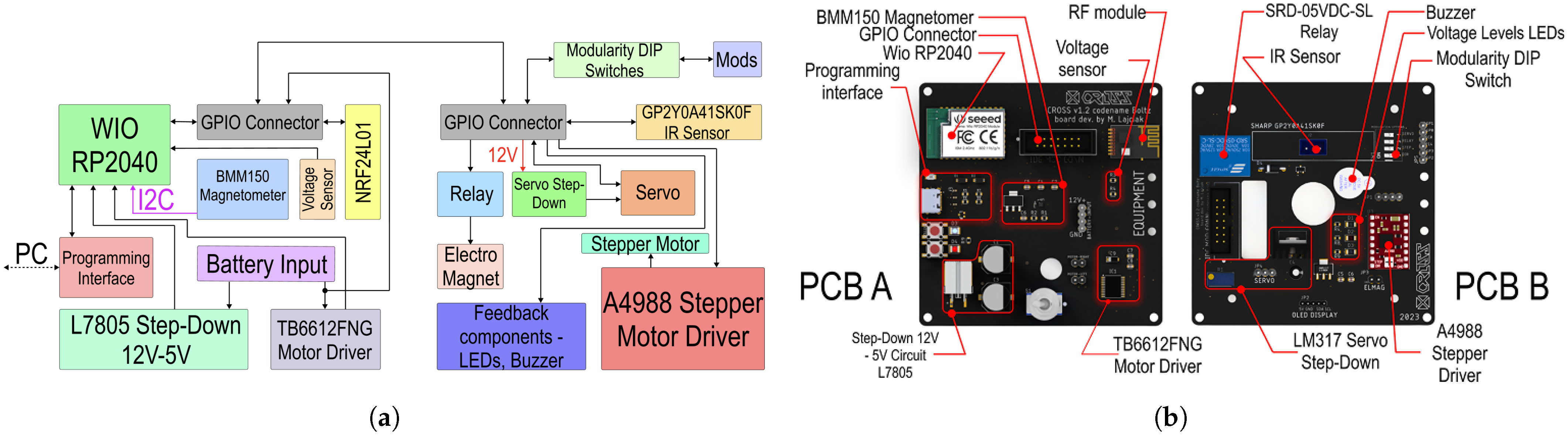
We then proceed to the electronics of the robot, which are divided into two printed circuit boards. PCB Floor A features all crucial components—MCU, power system etc. PCB Floor B mainly enables the modularity with interfaces for a variety of effectors.
The selected N20 motors have a nominal voltage of 12 V. The power system needed to be suited for this; therefore, an 60 g 3-series (11.1 V) 900 mAh battery was chosen. Each motor was rated for 1.6 A of stall current and needed to be controlled bidirectionally. A TB6612FNG motor driver (Toshiba Corporation, Tokyo, Japan) with in-built H-Bridge featuring two channels was utilized. Unfortunately, each channel was only rated for 1.2 A, so an overcurrent protection in the form of a PTC fuse was incorporated. The PTC switch current was 1.3 A, but the driver could handle up to 3 A momentarily, which might have even handled a stall if it occurred only for a brief moment. However, the PTC provides more reliable protection.
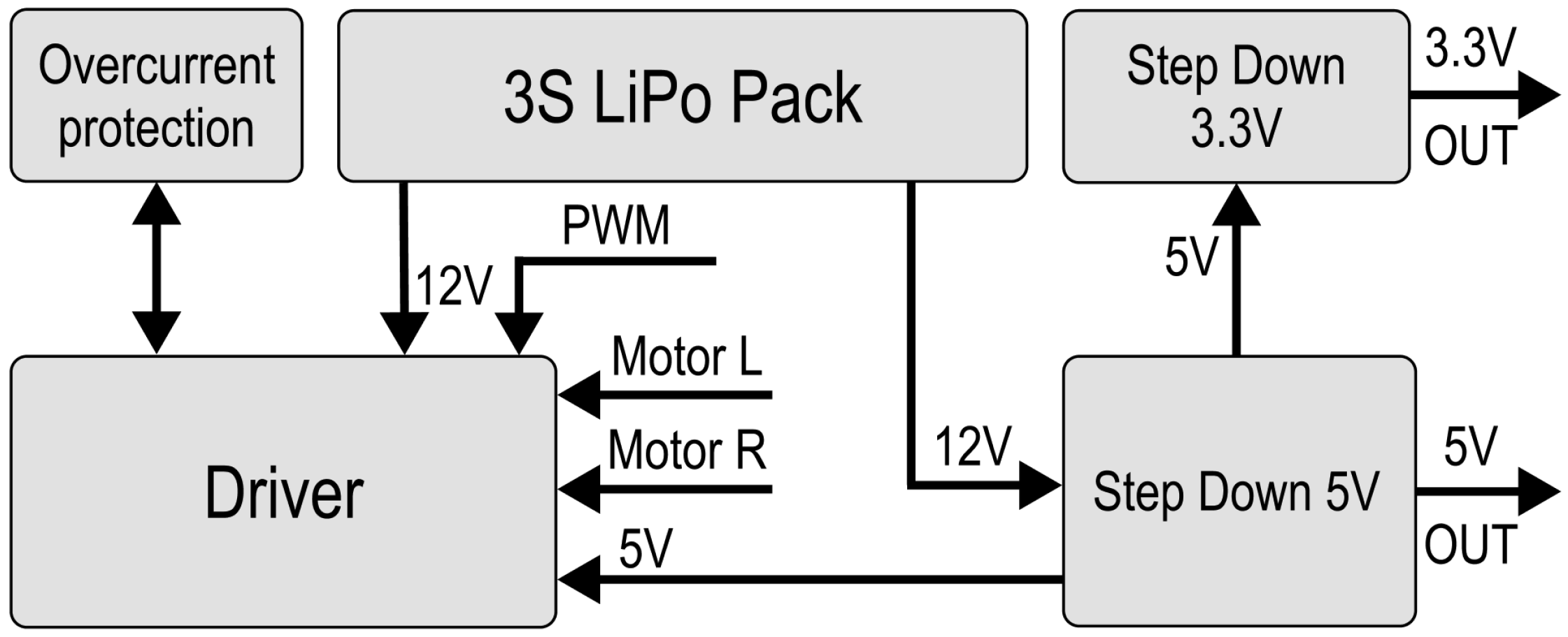
As depicted in Figure 8, the 12 V from the LiPo Pack are converted into 5 V and 3.3 V to supply the robot’s instruments. L7805 (STMicroelectronics, Geneva, Switzerland), outputting 5 V rated for 1.5 A, was used along with filtering eletrolyting capacitors. AMS1117 (Advanced Monolithic Systems, Santa Clara, CA, USA), outputting 3.3 V rated for 700 mA, was added to supply the systems in need of 3.3 V. The most important component selected was the Microcontroller Unit (MCU). We decided to implement a MCU and not a microchip because the application of a sole microchip would have brought a need for the installation of additional circuits, slowing down the assembly process. Since the experimental swarm is primarily designed for centralized missions, Wi-Fi was chosen as the communication tool between the central unit and the agents. We selected Wio RP2040 (Seeed Studio, Shenzhen, China) as the MCU due to its affordability and capabilities, including a dual-core 133 MHz Cortex M0+ processor (Arm Ltd., Cambridge, UK), 28 GPIO pins, an integrated ESP8285 (Espressif Systems, Shanghai, China) for Wi-Fi communication, 2 MB of Flash, and its compact surface-mount measuring 18.0 × 28.2 × 1 mm. The robot was equipped with a BGA-mounted BMM150 magnetometer (Bosch Sensortec, Reutlingen, Germany) for directional correction, a voltage sensor based on a resistor divider, and a GP2Y0A41SK0F infrared (IR) sensor (Sharp Corporation, Osaka, Japan) for collision detection, specifically measuring the distance to obstacles in the forward direction. The N20 motors in the chassis were controlled by a TB6612FNG H-bridge driver (Toshiba Corporation, Tokyo, Japan). Additionally, an additional 5V Step-Down circuit in the PCB Floor B was used to power a potential effector with a servo actuator and an A4988 stepper motor driver to control a stepper motor. A 12 V relay was also included to enable the control of additional equipment, such as an electromagnet.
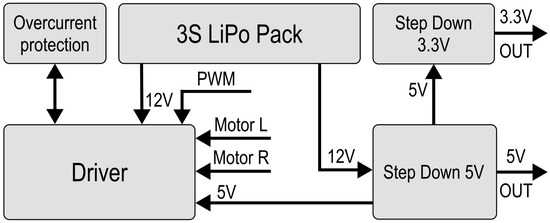
Figure 8.
Power system block diagram.
The distribution of components across the two PCBs is illustrated in Figure 9b. A GPIO connector links both boards. Based on this block diagram, we designed and developed the electronic schematics and PCB layouts. Each PCB has dimensions of 90 mm × 90 mm and is equipped with a four mounting hole pattern for distance pillar stacking.
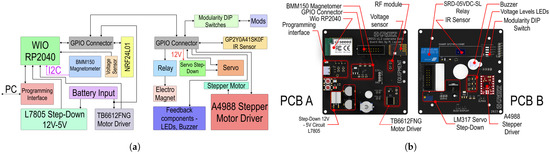
Figure 9.
AGV robotic agent electronics. (a) Electronics block diagram. (b) PCB notation.
2.5.4. Effector
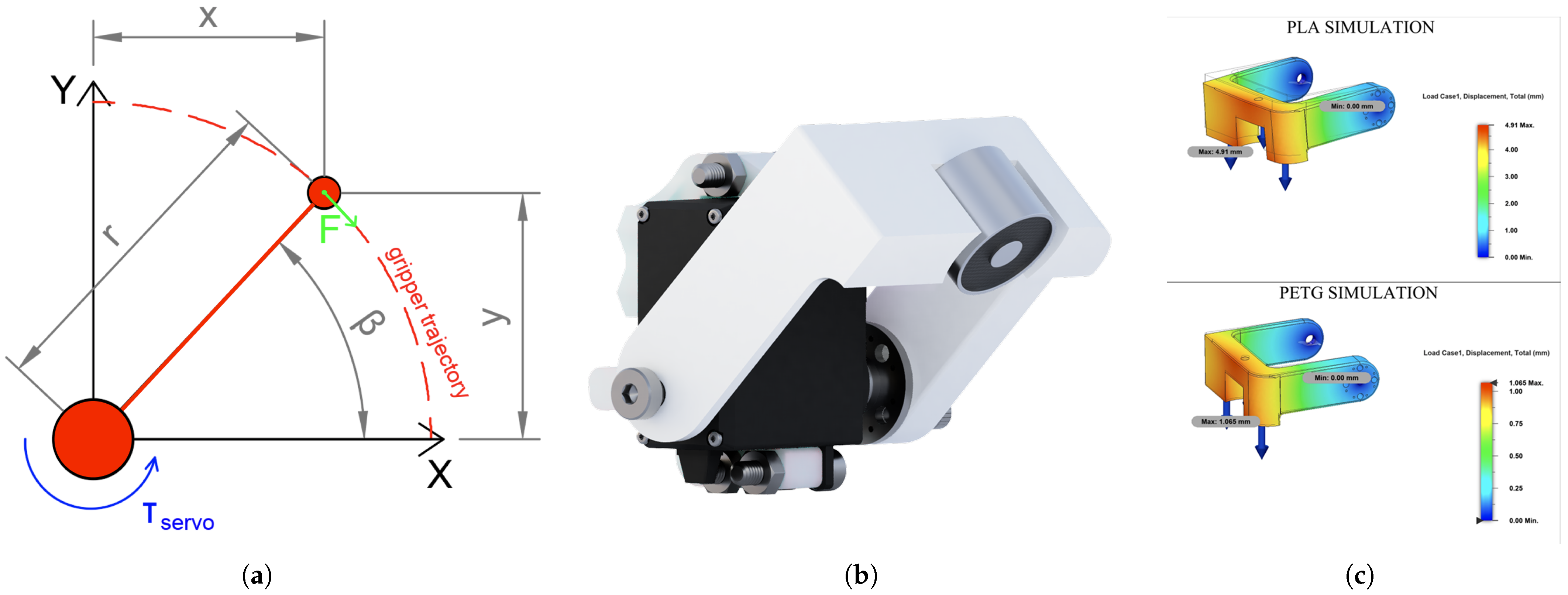
The application of swarm into modular manufacturing introduces the need for a lift or transporation effector directly on robot. Therefore, we decided to create a one-axis electromagnetic effector.
The rotary joint drawn in Figure 10a is actuated by a MG996R servo motor (TowerPro, Shenzhen, China) with , which can lift and transport a object with a mass of 500 g. The entire construction is designed to be mounted onto a magnetic cover and connected to nearby header. The design process involved a selection of materials. As mentioned, a plan was to utilize PLA for all the 3D-Printed parts. However, based on the simulation shown in Figure 10c, we see that with the usage of a PLA part, the displacement will be equal to 4.9 mm. Therefore, we decided to manufacture the effector from PETG material, which has more tensile strength than PLA, resulting in 1.1 mm displacement if loaded by 5 N of force. An electromagnet with parameters of 12 V, 1 W power, and 3 kgf was added to grip 3D-printed objects with a metal gripping zone. A rendering of the assembled effector is shown in Figure 10b.
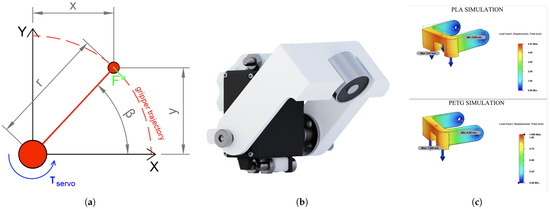
Figure 10.
Electromagnetic servo-actuated transportation effector. (a) Effector diagram. (b) Effector rendering. (c) Effector’s material simulation.
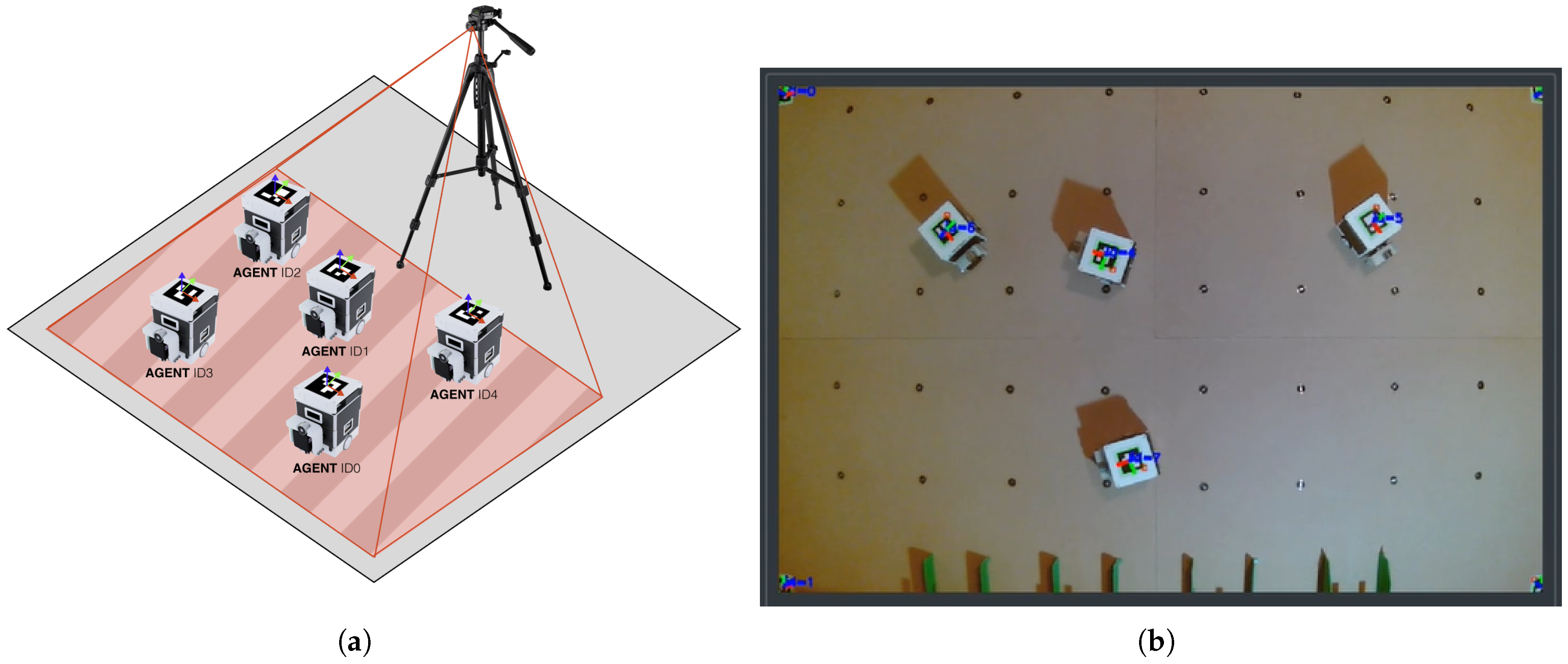
Agents are constructed for indoor experiments; therefore, ArUco fiducial markers [33] were selected as a low-cost precise positioning system. Each agent is featured as a 50 × 50 mm marker with a 4 × 4 inner matrix. The agents operate in an close 2D space, which is bordered by 4 markers at the corners, as depicted in Figure 11b. Corner markers utilization enables the correction of perspective, which is required for proper precise detection of agents on SMART Floor with offsetted camera system.

Figure 11.
Experimental swarm localization with ArUco fiducial markers. (a) Detection setup. (b) Real tracking example of 4 agents on SMART Floor with usage of wall-mounted web camera—corners of the camera feed are incomplete as the feed is perspectevily transformed.
The parameters of the assembled AGV are presented in Table 2. The final design in form of an exploded rendering is shown in Figure 12a, and the assembled system is shown in Figure 12b.
Table 2.
AGV key parameters.
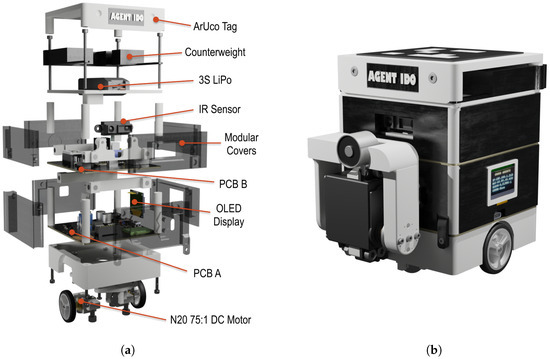
Figure 12.
Experimental robotic agent. (a) Exploded agent. (b) Agent’s rendering.
3. Results
To evaluate the effectiveness of the proposed model and swarm control strategy in dynamic and obstacle-rich environments, a series of simulations were conducted, aligning directly with the research objectives outlined in the previous sections.
3.1. Neural Network Performance
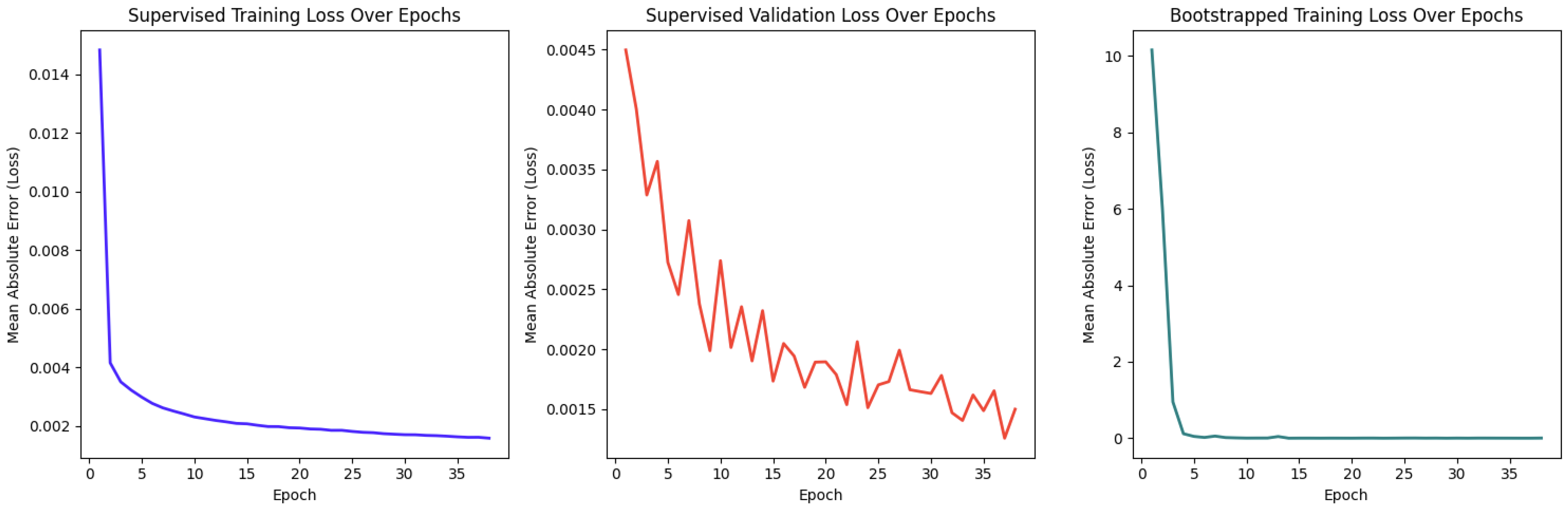
Firstly, the performance of the Feedforward Neural Network (FNN) model, trained with the Adam optimizer, was evaluated. The model utilized an 80/20 training/validation split and was assessed using Mean Absolute Error (MAE) as the loss metric. Trained over 50 epochs, the final training MAE converged to approximately 0.002, as shown in Figure 13. The validation MAE remained consistent at 0.002 (see Figure 13), indicating strong generalization and minimal overfitting. Additionally, the real-time deep-Q learning approach showed a similar convergence trend, stabilizing around a comparable MAE value.
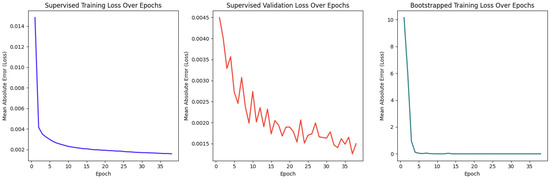
Figure 13.
Training and validation loss over 50 epochs for the FNN model using supervised and bootstrapped learning.
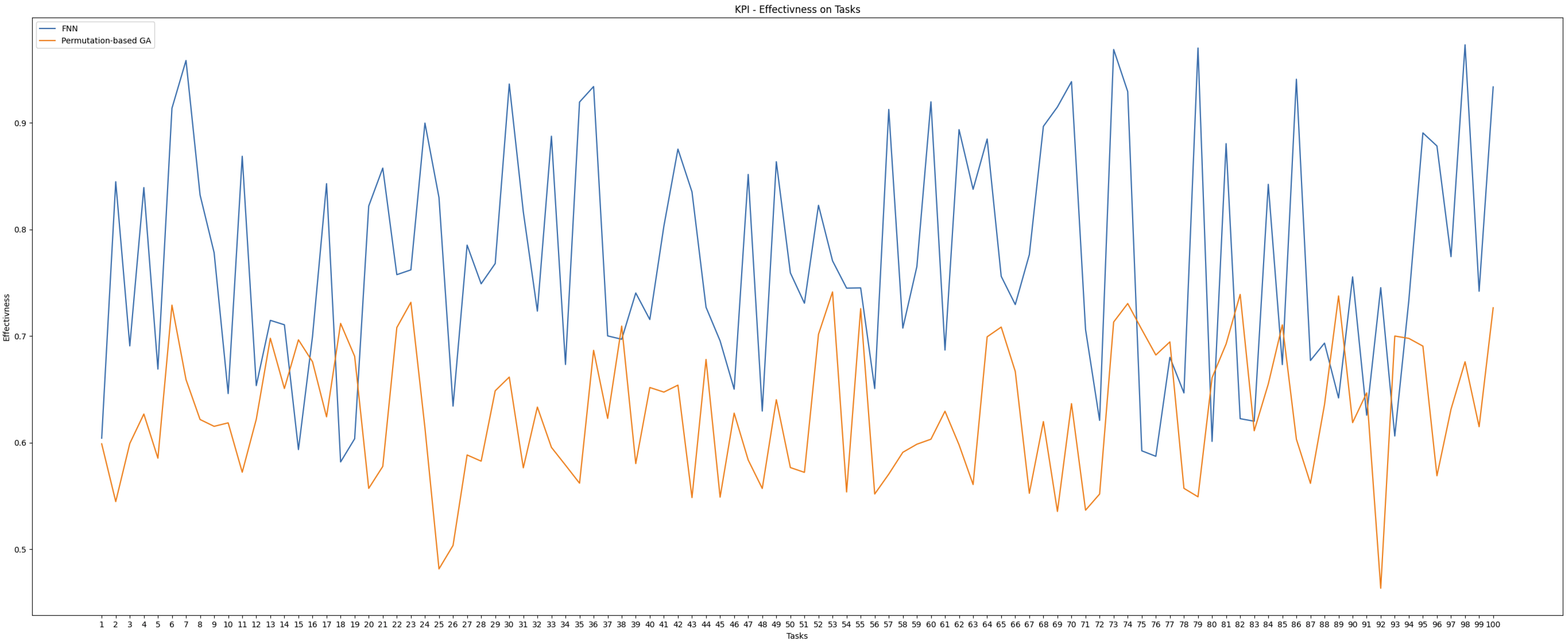
Interpreting the suitability score as a percentage, the MAE loss translates to a deviation of only 0.2%, affirming that the FNN produces highly accurate and reliable suitability predictions. These scores directly influenced task allocation decisions, which were further validated in controller-level evaluations. To demonstrate the applicability of this method, we conducted an experiment comparing two allocation approaches: our FNN and a permutation-based Genetic Algorithm (GA).
As shown in Figure 14, the FNN consistently outperformed the GA, achieving higher average effectiveness as a maximizer. This highlights the advantage of the FNN system over a standard GA. While the GA could potentially improve with longer optimization times due to its evolutionary nature, the FNN offers faster convergence, making it more suitable for real-time applications.
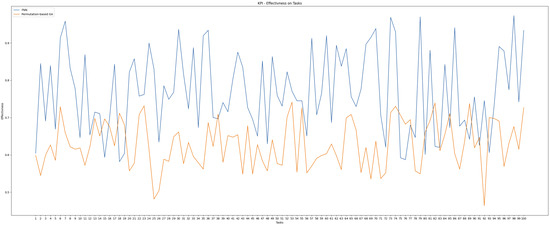
Figure 14.
Effectiveness comparison between FNN and permutation-based GA across 100 tasks.
3.2. Controller Evaluation Under Obstacle Density Variations
The swarm controller system was next evaluated through a series of simulation scenarios designed to analyze the effects of increasing obstacle density. Representative cases are depicted in Figure 15 and Figure 16. All experiments were executed locally on a MacBook Pro M3 without external computational acceleration.
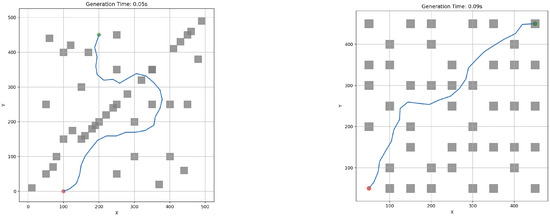
Figure 15.
RRT-APF individual robot experimental cases. Red dot represent the starting point, where as the green dot represent the end point. Obstacles are interpreted as grey squares and RRT-APF generated path is defined by blue line.
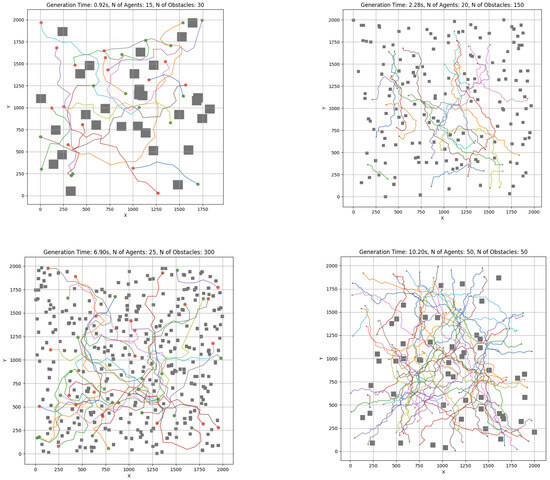
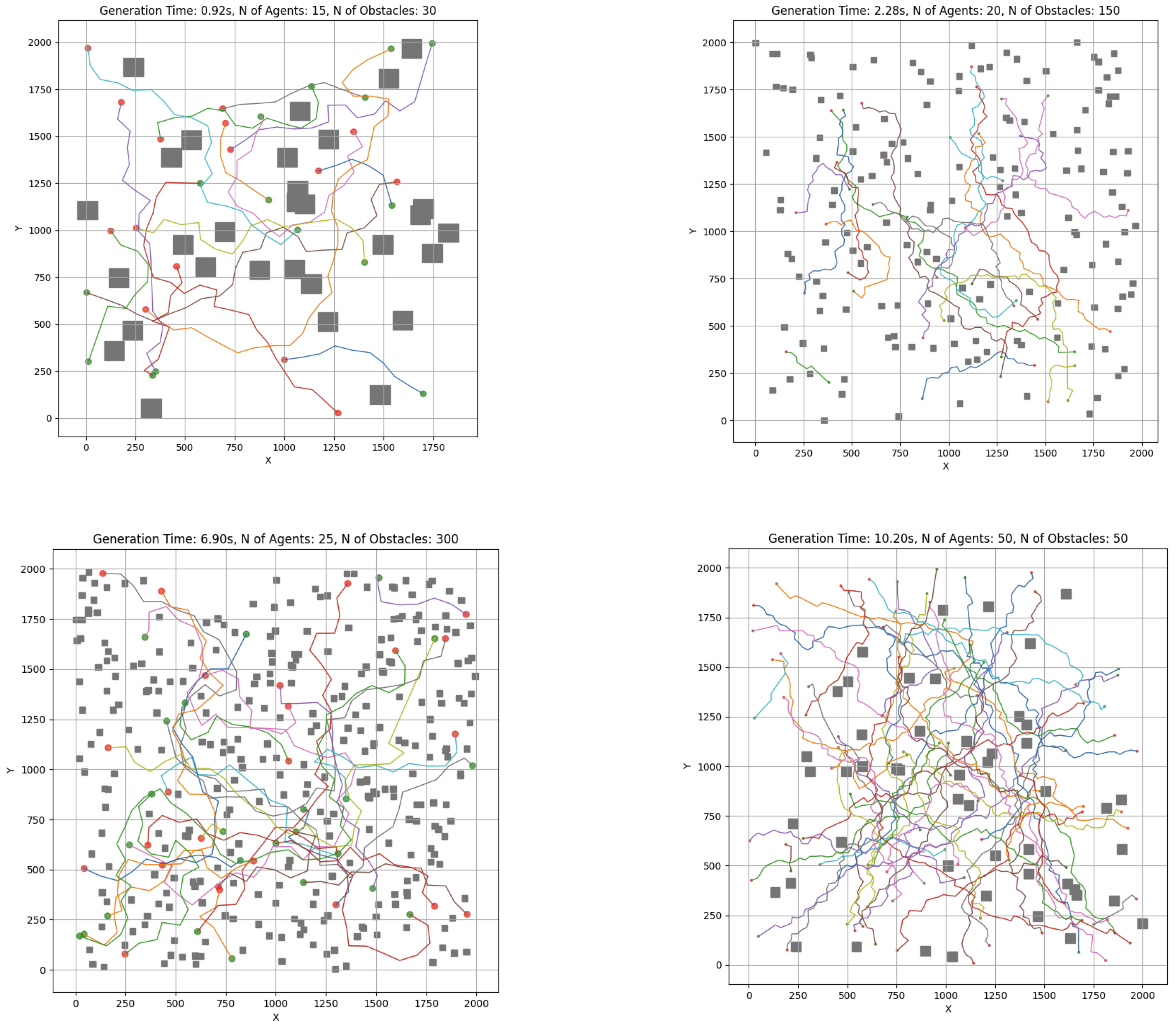
Figure 16.
RRT-APF simulation test cases. Red dots represent indvidual starting points and green dots represent end points for each agent. Unique color of path is assigned to each agent. Grey squares represent the obstacles in each case.
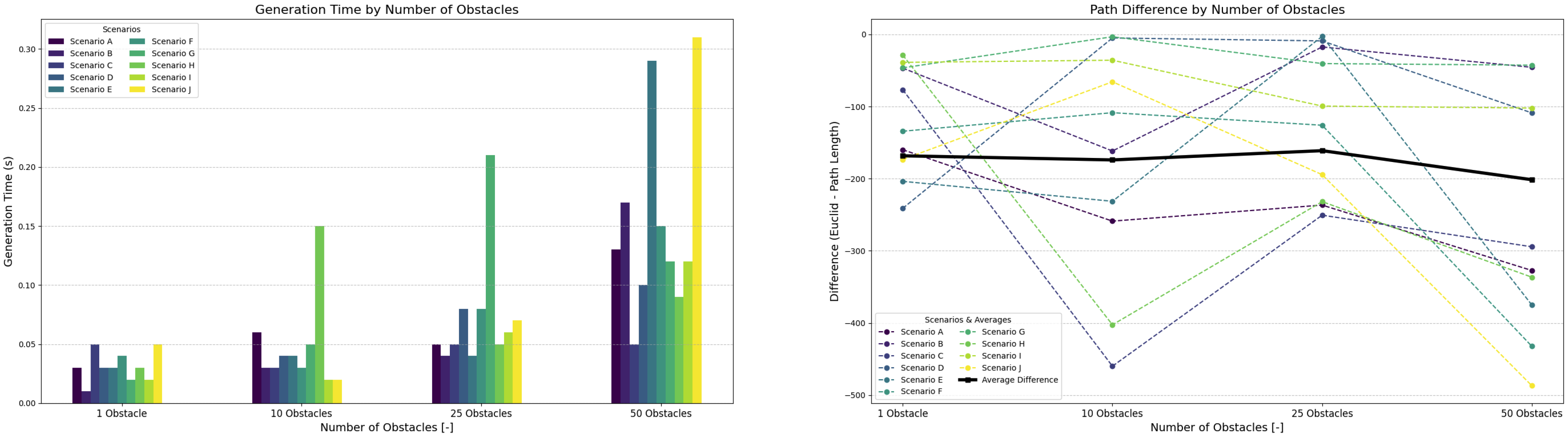
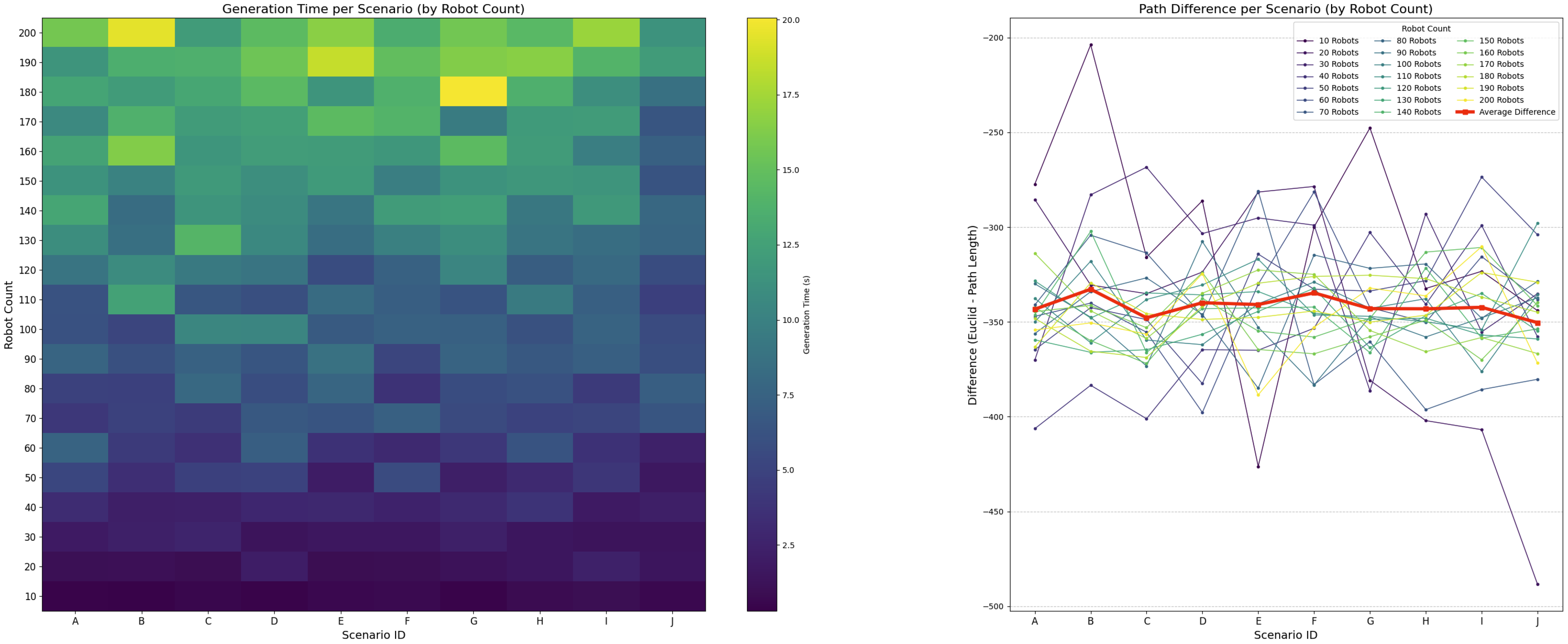
Figure 17 shows plotted data from 10 scenarios for each number of obstacles. Figure 17 shows that increasing the number of obstacles leads to a proportional increase in path generation time, consistent with rising environmental density as defined by Equations (9) and (10). Simulations were conducted within a fixed unit environment, using 5 robots of 20-unit size and obstacle sizes of 30 units.
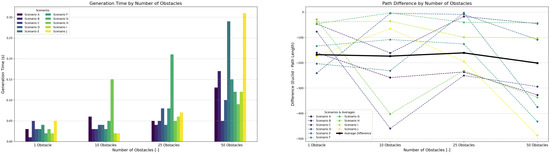
Figure 17.
Controller performance with varying numbers of obstacles while maintaining a constant number of 10 robots per scenario.
At the upper bound of 50 obstacles—each occupying approximately —the obstacle density was calculated as follows:
This value aligns with typical machine densities found in modular manufacturing cells. Even at the density from (20), the controller maintained real-time responsiveness, with generation time peaking at just 0.3 s. Path quality remained consistent across all obstacle configurations, with generated paths averaging 12.5% deviation from the environment’s diagonal (Euclidean distance).
3.3. Controller Evaluation Under Robot Density Variations
Figure 18 illustrates system behavior as the number of robots increases within a unit environment (total area units2) while keeping the number of obstacles fixed at 50. For each robot count, 10 scenarios were examined to capture the behavior of system. The robot footprint was estimated at roughly 600–1000 units2 per robot (including dynamic safety margin ).
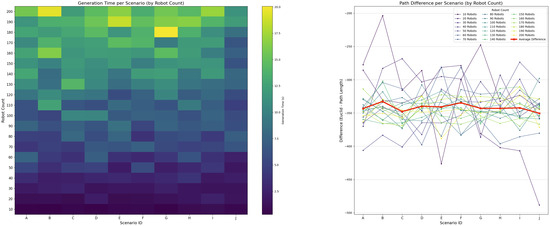
Figure 18.
Controller performance with varying numbers of robots while maintaining a constant number of 50 obstacles per scenario.
Using the dynamic scalability limit in Equation (10), the theoretical upper bound of the swarm size was calculated as follows:
In practice, however, congestion effects caused by local interactions emerged at much lower densities. Although the generation time increased gradually, the controller remained stable until a practical density threshold was exceeded; therefore, the robot count follows from (21). The deviation between the planned and Euclidean paths remained consistent at approximately 12.5% across all robot quantities.
All simulations were conducted within a static environment—all obstacles were fixed in a single location throughout the simulation. Simulations in dynamic environments were not performed, but we suggest that our system would remain feasible due to the low generation times shown in Figure 17 and Figure 18. The dynamic behavior of objects would require path regeneration if such objects remain on the planned path as the agent approaches the obstacle.
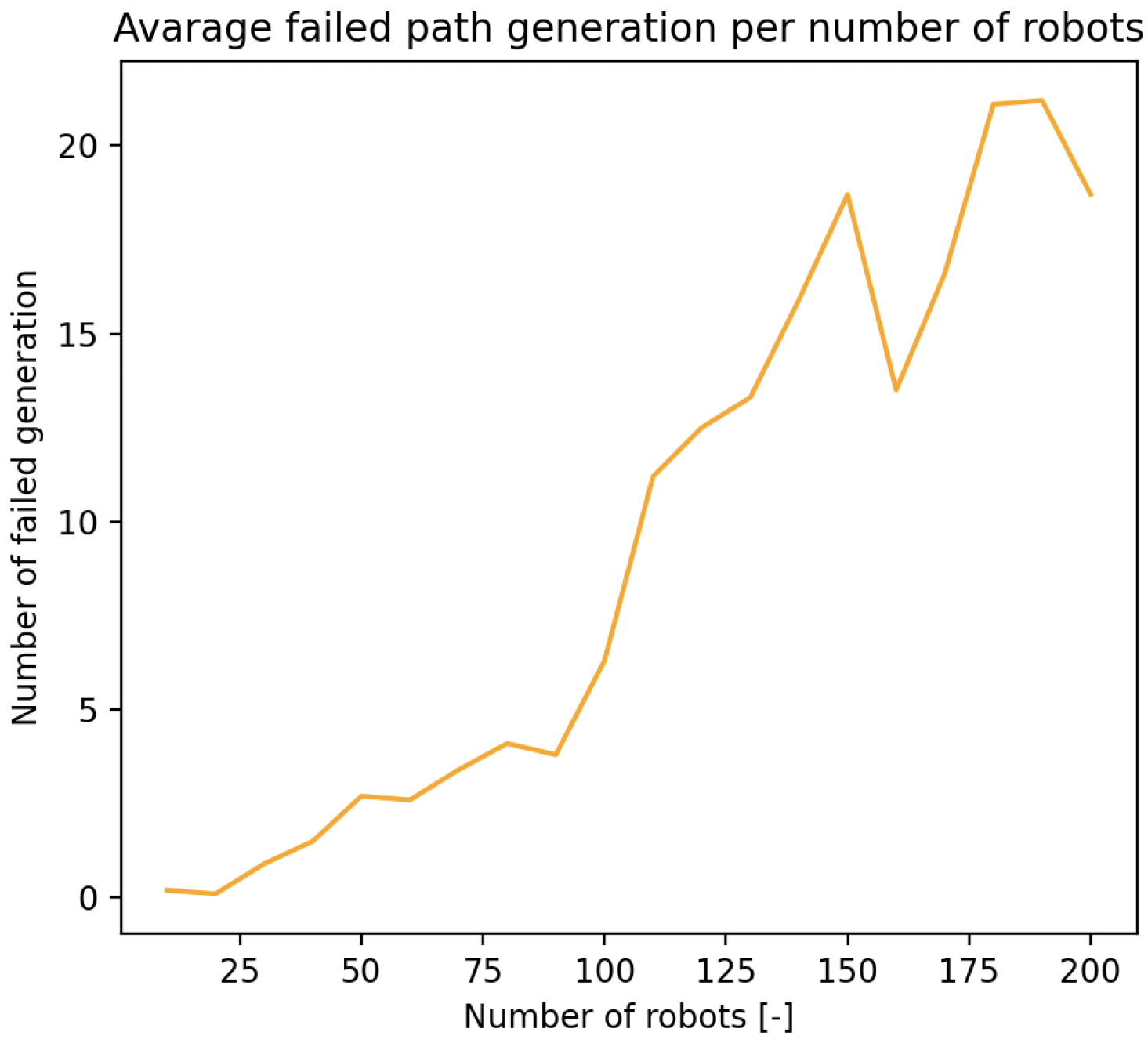
3.4. Path Generation Failures Due to Density
As shown in Figure 19, increasing environmental density—either via more agents or obstacles—eventually led to failed path generations. These failures emerged despite the theoretical limits suggesting sufficient spatial capacity, indicating that real-time constraints such as dynamic collision risk and path contention introduced bottlenecks earlier than static models predict. This confirms the relevance of the dynamic term in Equation (10), which accounts for temporary space requirements to prevent deadlocks and ensure feasible rerouting during high-density operation.
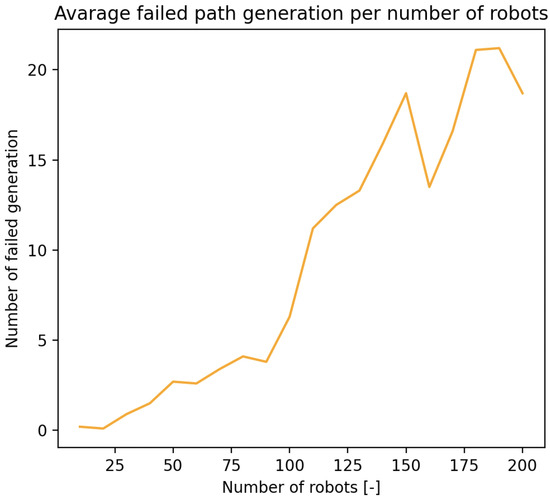
Figure 19.
Failed path generation trend due to increasing density of the environment.
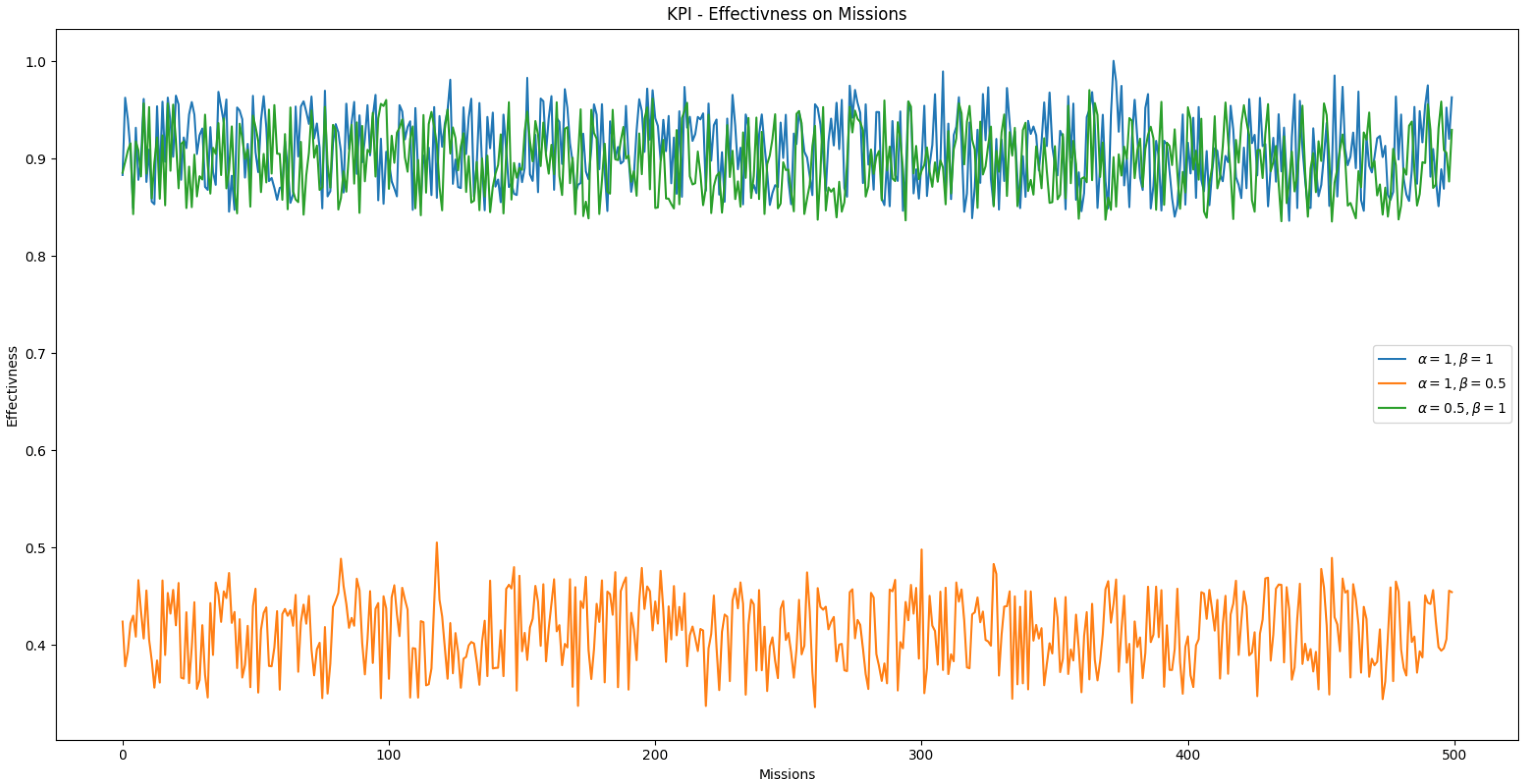
3.5. Analysis of KPI Effectiveness Metric
The defined effectiveness KPI in Equation (5) includes adjustable weights for each cost component. We analyzed how the performance of swarm S is evaluated across a set of tasks by varying , which weights task duration, and , which weights the energy required to complete a task. A bootstrapped-trained model was used for task allocation in this analysis, as it allows for retraining with label biases to prioritize specific cost factors.
The simulation results are shown in Figure 20. When time () or energy () is given higher relative importance, the swarm’s overall performance decreases. This occurs because the bootstrapped feedforward neural network (FNN) was not trained to generalize under asymmetric weight conditions. It was originally trained with , where it performed adequately. The degradation in performance at higher or values suggests that the model lacks the flexibility to adapt to cost priorities it was not explicitly trained on.
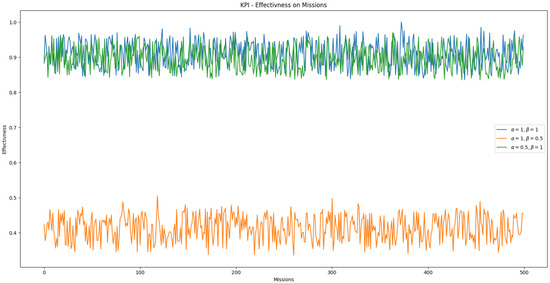
Figure 20.
Evaluation of swarm performance on a set of missions with varying weight factors of the effectiveness KPI.
3.6. Experimental Agent Precision Analysis
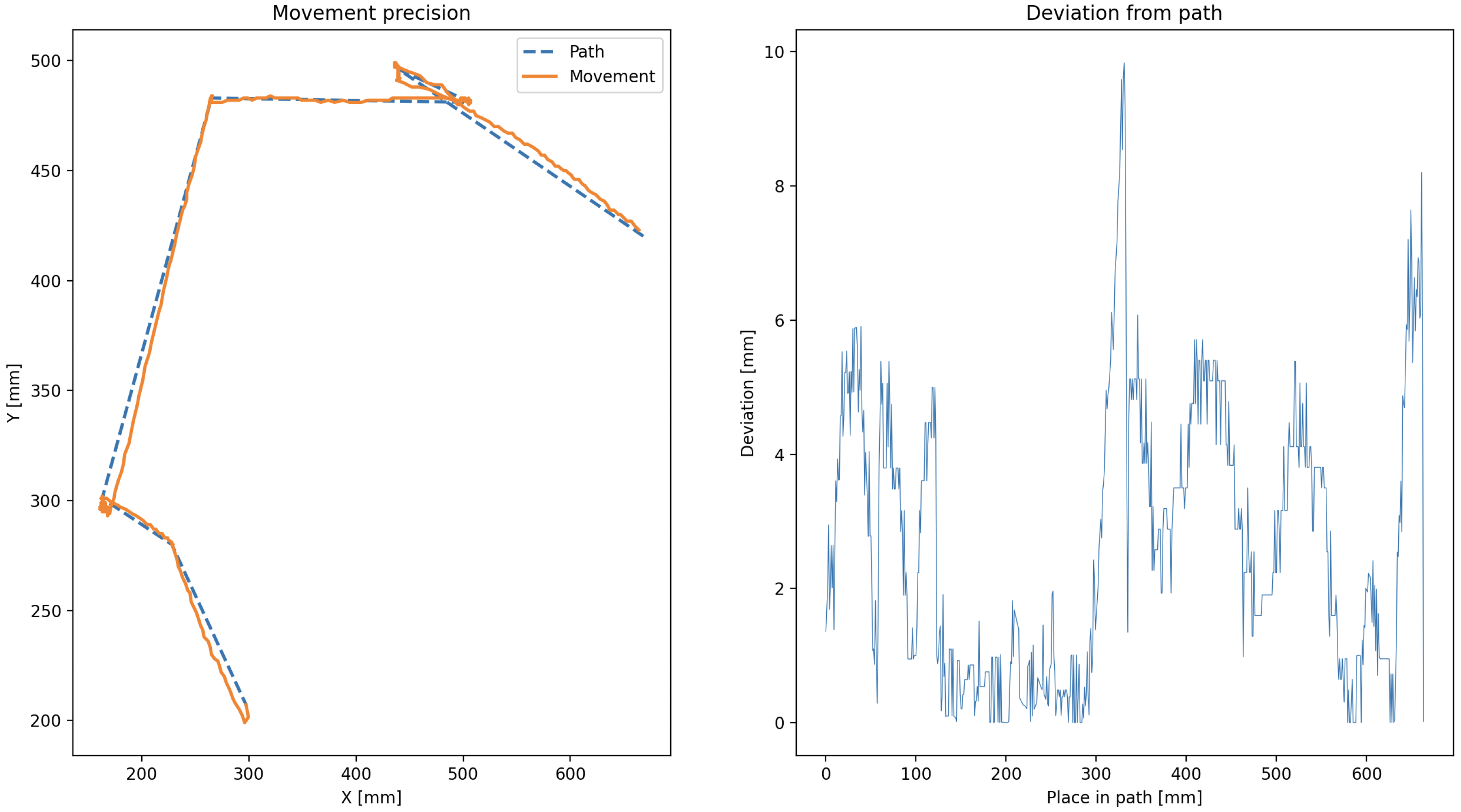
To validate the physical performance of the robotic agent, we conducted an analysis of its kinematic precision during navigation and task execution. The experiments were conducted in a controlled indoor environment using the ArUco-based positioning system described earlier. Positional accuracy was quantified by comparing the agent’s reported pose to its true location obtained via camera-based tracking.
The robot’s trajectory was planned through predefined waypoints, and deviations from the expected paths were recorded over multiple trials. Each trial consisted of the robot navigating a path and returning to its origin, repeated ten times for statistical relevance. The average deviation from the ideal path was computed using the root mean square error (RMSE) of positional data, mathematically described in (22):
where are ground truth positions and are reported positions.
The mean RMSE across all tests was found to be approximately 4.2 mm, which is within acceptable limits for swarm-scale coordination tasks and shown for a test case in Figure 21.
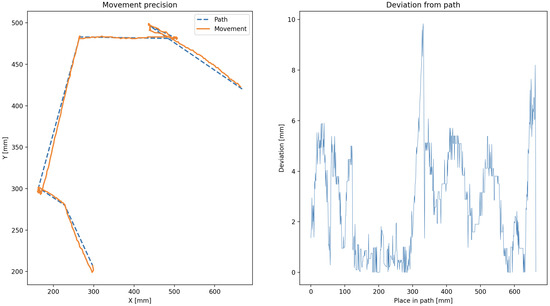
Figure 21.
Example of planned vs. actual path with measured deviation.
Overall, the agent demonstrated consistent sub-centimeter positional precision. These results affirm that the system is sufficiently precise for modular task execution in structured swarm environments, where small individual deviations are tolerable due to swarm-level redundancy and error correction.
4. Discussion
The primary objective of this research was to develop an effective control system for a centralized robotic swarm tailored for deployment in Reconfigurable Manufacturing Systems (RMSs). The usage of robotic swarms in RMS environments has been proposed in recent literature, such as in [9]. The proposed swarm controller consists of two subsystems: a path planner and a task allocator. Hybrid RRT-APF planning is shown to be suitable for dynamic obstacle-rich RMS environments. Embedding APF-based local correction into the node expansion of the RRT algorithm led to computationally efficient and low-noise path generation. The multi-agent pathfinding (MAPF) problem was addressed through a time-collision following method, enabling dynamic collision avoidance between agents without relying on a fully decentralized negotiation mechanism. This simplification is beneficial for RMS applications, where latency and system predictability are of high importance. For the task allocation component, the Feedforward Neural Network (FNN) trained using the Adam optimizer achieved a MAE of 0.002. This suits the allocator system for usage in swarm applications, where predicting an agent for certain task should lead to cost minimization. Simulations confirmed that the planner and allocator modules maintained real-time performance in dynamic RMS-like environments. For example, for an obstacle density of approximately 4.5%, representative of a typical modular manufacturing cell, tasks were allocated and paths generated in under 0.3 s with a swarm of size of 10 robotic agents. Scalability tests revealed the system’s ability to maintain path quality, stability, and computational efficiency under increasing numbers of robots and obstacles, up to the threshold defined in (10). The theoretical limits of robot density were rarely achieved in practical scenarios because of crowding and interference between robots. These included increased local interference between agents and a higher risk of temporary deadlocks. This case directly shows the need for adding dynamic environmental factors, such as the time-dependent spatial requirement term , into the maximum number of robots. The system was further validated through physical experimentation using custom-built experimental AGV robotic agents. Each AGV agent comprises an differential chassis, modular interface, wireless connectivity, and ArUco localization. Figure 22a shows photo of an AGV unit. The agents were built to be easily reprogrammable and to support future hardware integration (e.g., different sensor arrays or manipulators), making them suitable platforms for continued research and testing. The AGVs’ movement accuracy had a mean RMSE of ∼4.2 mm when tested on various tasks, e.g., a swarm applied to transportation, as shown in Figure 22b. Transitioning the experiments from the static condition-specific simulations and indoor small-scale tests to a real factory introduces new factors. Our current tests, performed in ideal setups, did not deal with real-world factory problems. For example, communication delays may lead to collisions, which would require the usage of a different positioning system, as ArUco markers are not suitable for centralized-only positioning, where communication delays cause major real trajectory offsets compared with the planned path. Electromagnetic interference from machines is common in factories. This could lead to problems with wireless signals or sensor accuracy, affecting how our robots find their way and move precisely. To fix these, we would need to utilize better communication methods that can handle errors. We also need to test our system in simulated interference.

Figure 22.
Developed AGV robotic swarm. (a) Photo of AGV unit. (b) Swarm application on SMART floor.
In summary, this research presents a comprehensive methodology for centralized swarm control within RMS contexts, validated through both simulation and hardware implementation. The hybrid RRT-APF planner and neural task allocator together demonstrate that such systems can achieve real-time responsiveness, adaptability, and high precision. Future work will explore robustness under partial failure conditions, dynamic task reassignment, and integration with higher-level production planning tools.
Author Contributions
Conceptualization, M.L. and J.V.; methodology, M.L. and J.V.; software, M.L.; validation, J.V. and M.L.; formal analysis, J.V.; investigation, M.L. and J.V.; resources, M.L. and J.V.; data curation, M.L.; writing—original draft preparation, M.L. and J.V.; writing—review and editing, M.L. and J.V.; visualization, M.L.; supervision, J.V.; project administration, J.V.; funding acquisition, J.V. All authors have read and agreed to the published version of the manuscript.
Funding
This article was written thanks to the generous support of the Scientific Grant Agency KEGA, grant numbers 008STU-4/2024 and 024STU-4/2023.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shahzad, M.M.; Saeed, Z.; Akhtar, A.; Munawar, H.; Yousaf, M.H.; Baloach, N.K.; Hussain, F. A Review of Swarm Robotics in a NutShell. Drones 2023, 7, 269. [Google Scholar] [CrossRef]
- Naysmith, C. Amazon Grows to over 750,000 Robots as World’s Second-Largest Private Employer Replaces over 100,000 Humans. 2024. Available online: https://finance.yahoo.com/news/amazon-grows-over-750-000-153000967.html (accessed on 13 April 2025).
- Ajeil, F.H.; Ibraheem, I.K.; Azar, A.T.; Humaidi, A.J. Grid-Based Mobile Robot Path Planning Using Aging-Based Ant Colony Optimization Algorithm in Static and Dynamic Environments. Sensors 2020, 20, 1880. [Google Scholar] [CrossRef] [PubMed]
- Ou, Y.; Fan, Y.; Zhang, X.; Lin, Y.; Yang, W. Improved A* Path Planning Method Based on the Grid Map. Sensors 2022, 22, 6198. [Google Scholar] [CrossRef] [PubMed]
- Bogatarkan, A. Flexible and Explainable Solutions for Multi-Agent Path Finding Problems. Electron. Proc. Theor. Comput. Sci. 2021, 345, 240–247. [Google Scholar] [CrossRef]
- Stern, R. Multi-Agent Path Finding—An Overview. In Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2022; pp. 96–115. [Google Scholar]
- Vachálek, J.; Bartalský, L.; Rovný, O.; Šišmišová, D.; Morháč, M.; Lokšík, M. The digital twin of an industrial production line within the industry 4.0 concept. In Proceedings of the 2017 21st International Conference on Process Control (PC), Strbske Pleso, Slovakia, 6–9 June 2017; pp. 258–262. [Google Scholar] [CrossRef]
- Koren, Y.; Heisel, U.; Jovane, F.; Moriwaki, T.; Pritschow, G.; Ulsoy, G.; Van Brussel, H. Reconfigurable Manufacturing Systems. CIRP Ann. 1999, 48, 527–540. [Google Scholar] [CrossRef]
- Avhad, A.; Schou, C.; Arnarson, H.; Madsen, O. Demonstrating a Swarm Production lifecycle: A comprehensive multi-robot simulation approach. J. Manuf. Syst. 2025, 79, 484–503. [Google Scholar] [CrossRef]
- Dias, M.; Simmons, R. A market-based approach to multirobot coordination. Int. J. Robot. Res. 2005, 25, 277–292. [Google Scholar]
- Gerkey, B.P.; Mataric, M.J. Sold!: Auction methods for multirobot coordination. IEEE Trans. Robot. Autom. 2002, 18, 758–768. [Google Scholar] [CrossRef]
- Google OR-Tools. Operations Research Tools: Routing Library. 2025. Available online: https://developers.google.com/optimization (accessed on 30 May 2025).
- Milner, E.; Sooriyabandara, M.; Hauert, S. Swarm Performance Indicators: Metrics for Robustness, Fault Tolerance, Scalability and Adaptability. arXiv 2023, arXiv:2311.01944. [Google Scholar]
- Hamann, H.; Reina, A. Scalability in Computing and Robotics. arXiv 2020, arXiv:2006.04969. [Google Scholar] [CrossRef]
- Harwell, J.; Gini, M. Improved Swarm Engineering: Aligning Intuition and Analysis. arXiv 2021, arXiv:2012.04144. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Sánchez-Ibáñez, J.R.; Pérez-del Pulgar, C.J.; García-Cerezo, A. Path Planning for Autonomous Mobile Robots: A Review. Sensors 2021, 21, 7898. [Google Scholar] [CrossRef]
- Cheng, C.; Zhang, H.; Sun, Y.; Tao, H.; Chen, Y. A cross-platform deep reinforcement learning model for autonomous navigation without global information in different scenes. Control Eng. Pract. 2024, 150, 105991. [Google Scholar] [CrossRef]
- Qin, H.; Shao, S.; Wang, T.; Yu, X.; Jiang, Y.; Cao, Z. Review of Autonomous Path Planning Algorithms for Mobile Robots. Drones 2023, 7, 211. [Google Scholar] [CrossRef]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Leuven, Belgium, 16–21 May 1998; pp. 1–6. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-Based Algorithms for Optimal Motion Planning. arXiv 2011, arXiv:1105.1186. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Robot. Res. 1986, 5, 90–98. [Google Scholar] [CrossRef]
- Borenstein, J.; Heragu, S.; Koren, Y. The vector field histogram for real-time obstacle avoidance. IEEE Trans. Robot. Autom. 1991, 7, 487–495. [Google Scholar] [CrossRef]
- Tahir, Z.; Qureshi, A.; Ayaz, Y.; Nawaz, R. Potentially Guided Bidirectionalized RRT* for Fast Optimal Path Planning in Cluttered Environments. Robot. Auton. Syst. 2018, 108, 13–27. [Google Scholar] [CrossRef]
- Wu, D.; Wei, L.; Wang, G.; Tian, L.; Dai, G. APF-IRRT*: An Improved Informed Rapidly-Exploring Random Trees-Star Algorithm by Introducing Artificial Potential Field Method for Mobile Robot Path Planning. Appl. Sci. 2022, 12, 10905. [Google Scholar] [CrossRef]
- Wang, L.; Yang, X.; Chen, Z.; Wang, B. Application of the Improved Rapidly Exploring Random Tree Algorithm to an Insect-like Mobile Robot in a Narrow Environment. Biomimetics 2023, 8, 374. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Ji, Y.; Fang, L. A Multi-UAV Formation Obstacle Avoidance Method Combined Improved Simulated Annealing and Adaptive Artificial Potential Field. arXiv 2025, arXiv:2504.11064. [Google Scholar] [CrossRef]
- Rezeck, P.; Azpurua, H.; Correa, M.F.; Chaimowicz, L. HeRo 2.0: A Low-Cost Robot for Swarm Robotics Research. arXiv 2022, arXiv:2202.12391. [Google Scholar] [CrossRef]
- Arvin, F.; Samsudin, K.; Ramli, A. Development of IR-Based Short-Range Communication Techniques for Swarm Robot Applications. Adv. Electr. Comput. Eng. 2010, 10, 61–68. [Google Scholar] [CrossRef]
- Correll, N.; Cianci, C.; Raemy, X.; Martinoli, A. Self-Organized Embedded Sensor/Actuator Networks for “Smart” Turbines. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems Workshop on Network Robot System: Toward Intelligent Robotic Systems Integrated with Environments, Beijing, China, 10 October 2006. [Google Scholar]
- Shih, C.L.; Lin, L.C. Trajectory Planning and Tracking Control of a Differential-Drive Mobile Robot in a Picture Drawing Application. Robotics 2017, 6, 17. [Google Scholar] [CrossRef]
- Rubies, E.; Palacín, J. Design and FDM/FFF Implementation of a Compact Omnidirectional Wheel for a Mobile Robot and Assessment of ABS and PLA Printing Materials. Robotics 2020, 9, 43. [Google Scholar] [CrossRef]
- Neto, B.S.R.; Araújo, T.D.O.; Meiguins, B.S.; Santos, C.G.R. Tape-Shaped, Multiscale, and Continuous-Readable Fiducial Marker for Indoor Navigation and Localization Systems. Sensors 2024, 24, 4605. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).