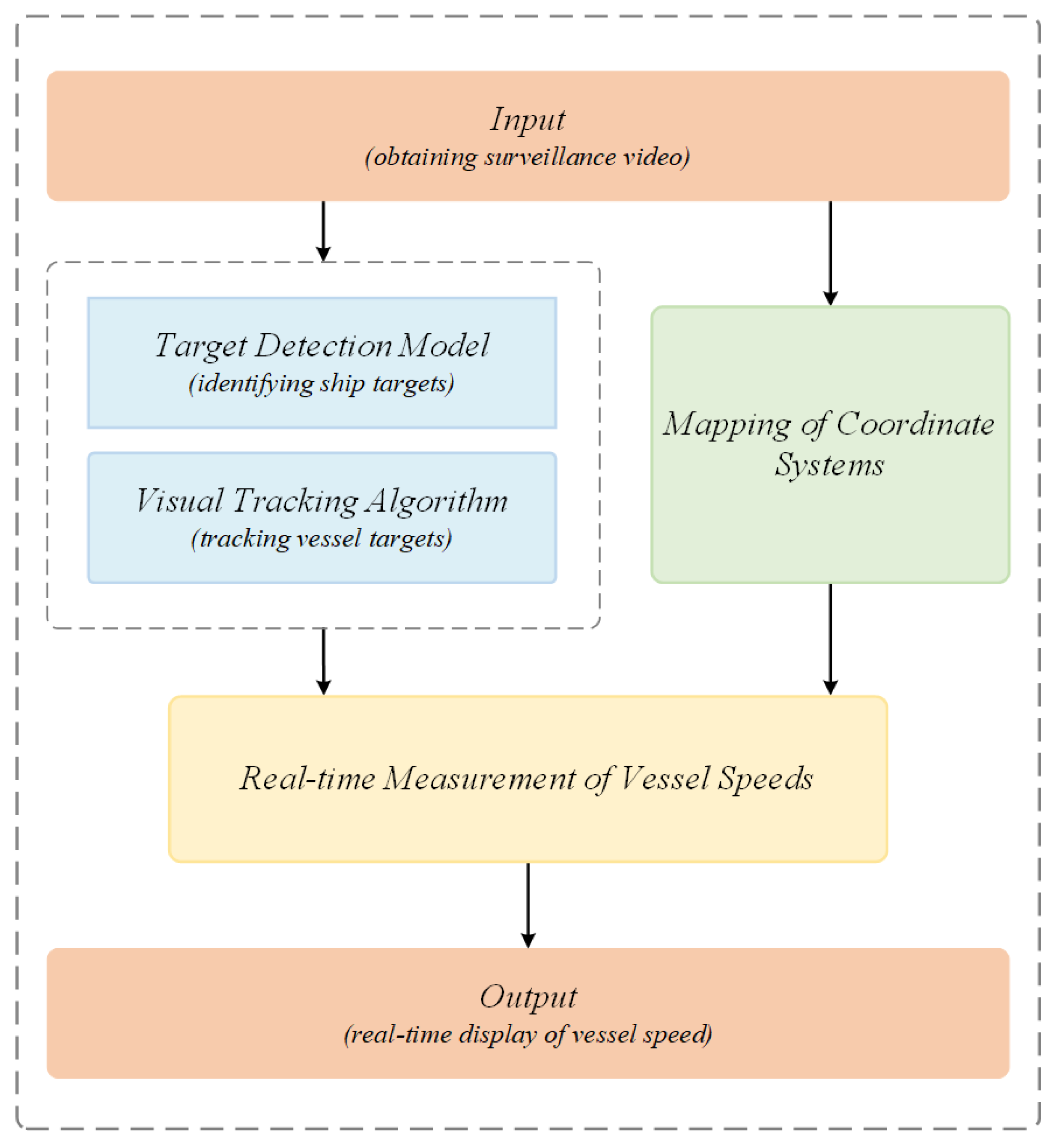
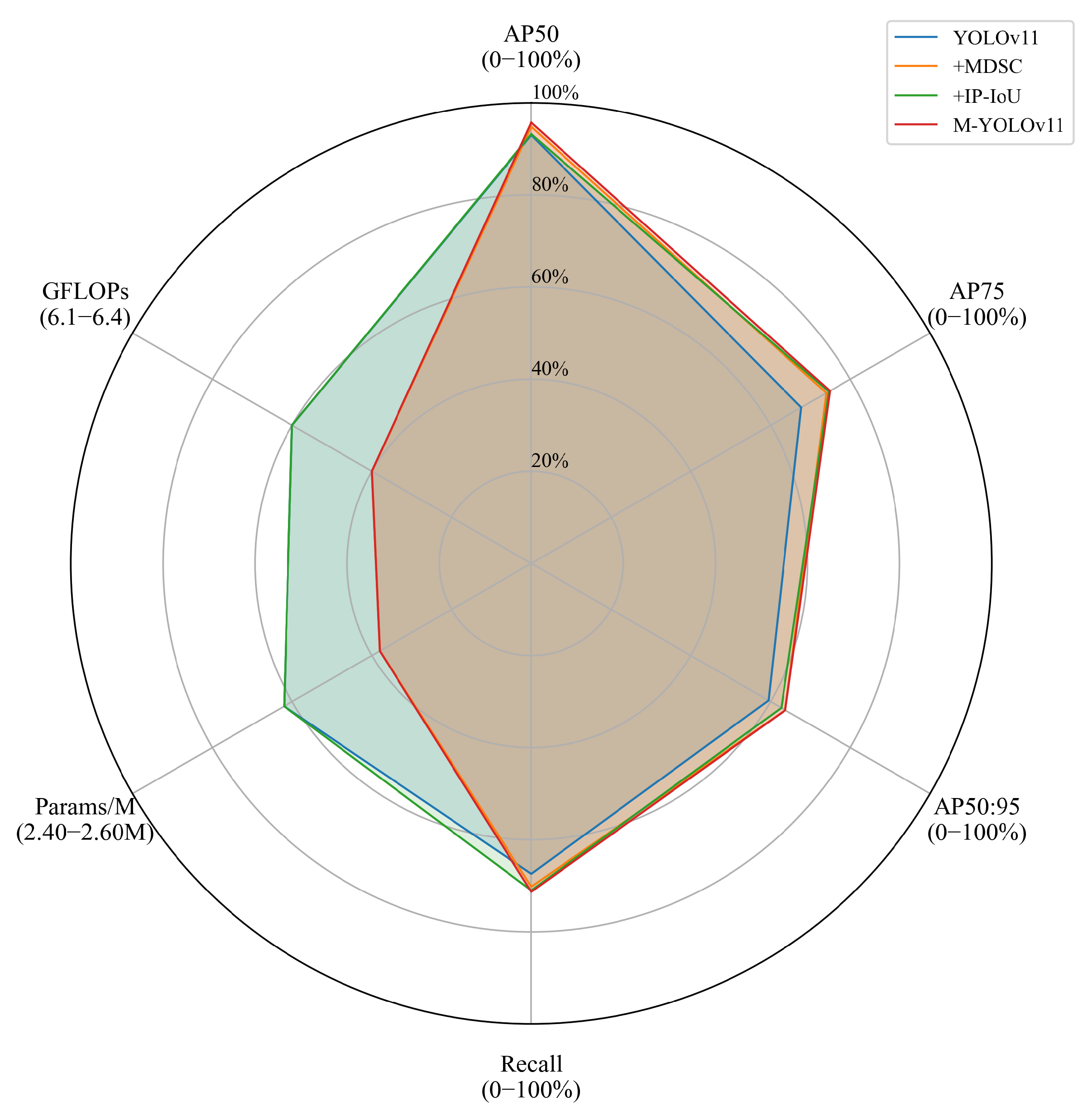
In the experimental process, this paper utilizes the surveillance camera provided by the maritime department for the target detection of vessels. The experimental findings demonstrate that the prevailing base model framework grapples with the challenges of suboptimal picture quality, target blurring due to fog interference, and missing feature information, thereby compromising the detection accuracy and robustness of the model. To address these challenges, this paper proposes an enhanced model based on YOLOv11 [
18]. This model enhances the ability of the model to recognize vessel targets, reduces the leakage detection rate, and improves its adaptability in complex environments. Specifically, we propose the Multi-scale Depthwise Separable Convolution (MDSC) module to enhance the ability of the model to capture features of vessels of different scales and shapes, especially in the case of low picture quality, which can improve the accuracy of target detection. Furthermore, the IP-IoU (Interior Perception Intersection over Union) loss function is introduced to ensure that the model focuses on the consistency of the internal structure of the target with the bounding box, thereby enhancing the stability of the detection frame. This enhancement is paramount for the precise measurement of vessel speed, as the stability of the detection frame directly impacts the accuracy of the speed calculation. The integration of these two enhancements within the YOLOv11 framework results in the development of the M-YOLOv11 model, as depicted in
Figure 2.
The M-YOLOv11 model comprises three distinct components as follows: Backbone, Neck, and Head [
19]. The function of the Backbone component is principally to extract the fundamental feature information of the vessel from the image, thereby providing high-quality feature representations for the subsequent target detection [
20,
21]. The Neck component’s primary responsibility is to fuse the feature information extracted by the Backbone component, with the objective of enhancing the capacity of the model to detect targets at diverse scales [
22]. This, in turn, leads to an augmentation of the model’s generalization performance in complex backgrounds. Finally, Head is responsible for the final classification and bounding box regression of the targets and outputs the detection results [
23]. The following discussion will address both the MDSC module and the IP-IoU loss function.
2.1.1. MDSC
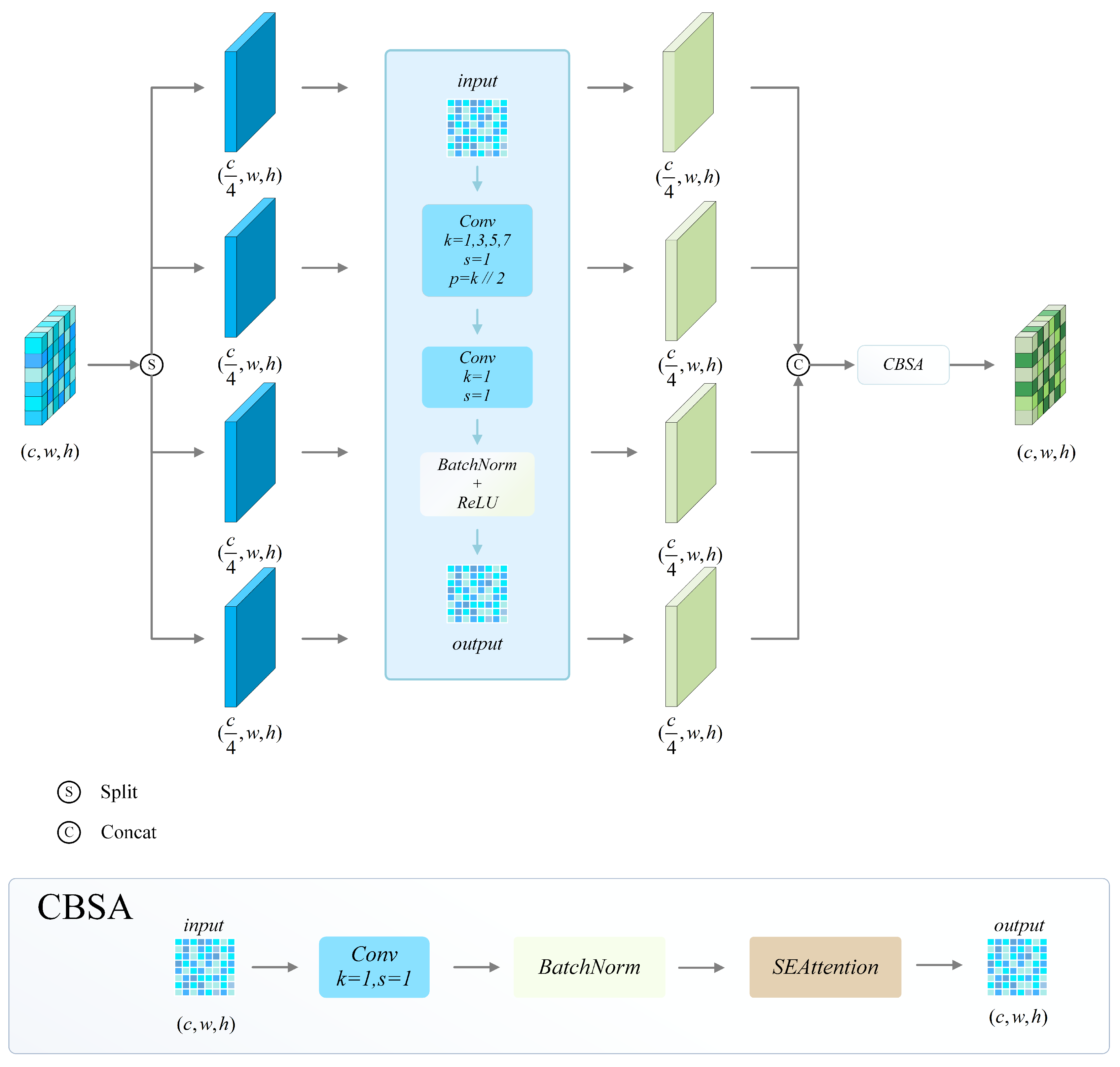
The MDSC module is composed of Multi-Scale Convolution, Depthwise Separable Convolution, and an SE (Squeeze-and-Excitation) attention mechanism. The module’s structure is shown in
Figure 3. Multi-scale convolution extracts features at multiple scales by using convolution kernels with varying receptive fields. This enhances the ability of the model to adapt to different sizes of vessel targets and improves the generalization of detection [
24,
25]. The deep separable convolution enhances the model’s computational efficiency while reducing its computational complexity compared to standard convolution. This results in faster inference speeds while maintaining high detection accuracy [
26]. The SE attention mechanism enhances the ability of the model to detect targets in complex environments by adaptively adjusting the weights of feature channels [
27]. This highlights key features and suppresses redundant information, thereby improving the model’s performance.
In order to maximize the benefits of the MDSC module, this paper proposes a refined embedding method during experimentation. The experimental findings demonstrate that the extraction and integration of advanced semantic features can be efficiently enhanced by substituting the final C3k2 module in the Backbone and Neck structures with the MDSC module. This approach results in an enhanced model that significantly improves the capability to distinguish deep features and detect low-resolution vessel targets in challenging environments, such as water fog conditions. The optimization of information exchange [
28] among multi-scale features establishes a balance between efficiency and performance, ensuring that the model remains both robust and suitable for deployment.
2.1.2. IP-IoU
Due to the significant variations in vessel shape and size, as well as the complexity of inland waterway environments, traditional IoU can only reflect the overall overlap between the predicted and ground truth bounding boxes. However, it struggles to capture the fine-grained features and local structural information of vessel targets, which affects detection accuracy. To address this issue, this study introduces the Inner Powerful IoU (IP-IoU) loss function, enabling the predicted bounding box to not only outline the overall contour of the target but also assign higher importance to its internal key features. This enhancement effectively reduces localization errors caused by shape variations and environmental disturbances, thereby improving the model’s detection performance in complex scenarios. IP-IoU integrates and combines the strategies of Inner IoU [
29] and Powerful IoU [
30] to enhance the accuracy and robustness of object detection. Specifically, Inner IoU focuses on capturing fine-grained internal features of the target, ensuring that the detection model maintains high performance and stability even when the vessel undergoes shape distortion due to viewpoint variations or partial occlusion.
To effectively capture internal features, this study extracts the internal regions of the predicted bounding box
and the ground truth bounding box
. Furthermore, the original bounding box is defined with its center point and dimensions as
, where
x and
y represent the center coordinates, while
w and
h denote the width and height of the box, respectively. First, we introduce the scaling factor ratio, and we then calculate the boundary coordinates of the internal area as follows:
At the same time, the IoU of the internal area is calculated, that is, the overlap between the predicted box and the internal area of the real box, as follows:
where
and
are the inner areas of the predicted box and the real box after scaling as above.
is a very small constant.
The individual boundary coordinates of the predicted and real frames on the internal region are calculated according to Equation (
1), respectively, as follows:
(a) : left, right, top, and bottom boundaries of the inner region of the prediction box.
(b) : left, right, top, and bottom boundaries of the inner region of the real box.
Subsequently, based on the calculated boundary coordinates, the deviations between the predicted box and the ground truth box in both the horizontal and vertical directions are computed to quantify their positional discrepancies as follows:
The deviation is then normalized to obtain the position deviation value
P as follows:
The deviation value P measures the distance between the predicted box and the true box in position. When the two are very close, the
P value is small; otherwise, the
P value increases. After obtaining
P, the deviation of internal IoU and position can be calculated as follows:
At the same time, we define
q and ensure that the smaller
P is, the larger
q is, and vice versa, as follows:
From Equation (
6), we can further get the factor
x that controls the gradient correction as follows:
where
is used as an adjustment parameter to control the intensity of gradient correction.
In summary, combining the formulas, we can get the calculation method of IP-IoU as follows:
IP-IoU integrates internal feature matching and position correction strategies, enabling the predicted bounding box to more accurately align with the actual vessel target, thereby reducing prediction errors and improving detection accuracy. Moreover, it effectively handles vessel targets at varying distances and with diverse shapes, providing a solid foundation for accurate vessel speed detection in this study.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}