1. Introduction
The giant panda (
Ailuropoda melanoleuca) is a unique and endangered species endemic to China. With the advancement of captive breeding techniques, the reintroduction of captive pandas into the wild has become a growing focus for biologists. To enhance the survival of giant pandas in the wild, a well-designed selection mechanism is essential [
1]. The various behaviors of pandas observed during a monitoring period serve as one of the key criteria for selection [
2].
Traditionally, the identification of panda behaviors primarily relies on experts manually analyzing and labeling video or audio data. However, this approach is very time-consuming and requires professional training to have the ability to judge behavioral types with high accuracy, and it is prone to subjective bias [
3]. Recently, advancements in deep learning have introduced new solutions that can effectively assist researchers. For example, Swarup et al. [
4] proposed a method to automatically identify the behavior of captive giant pandas using images, achieving 90% accuracy for behavior classification and 84% for facial motion recognition. Liu et al. [
5] proposed a model called PandaFormer to use identify the behavior of wild giant pandas based on videos and obtained 92.25% Top-1 accuracy.
Despite its impressive accuracy, video-based technique requires high quality images of pandas, which are difficult to collect in the wild. In addition, environmental factors such as season, weather, and lighting can seriously degrade image quality, making recognition more difficult [
5]. In contrast, using a collar to record audio signals whenever the panda exhibits a certain behavior proves to be a simpler alternative [
6]. However, the recorded audio data pose challenges in post-processing, as they often contain significant noise and are less intuitive for behavior labeling compared to video. Using audio-based methods to recognize giant panda behaviors also faces several challenges. (1) There are many environmental noises (such as collar friction, background sound, sounds made by other animals, etc.) that can seriously suppress the acoustic signals related to behavior, making it difficult to extract meaningful features. (2) The sounds produced by giant pandas’ behaviors are complex, containing many basic acoustic events, such as breathing sounds, footstep sounds, chewing sounds, etc. Moreover, the sounds produced by different giant panda individuals, even though these pandas are presenting the same behaviors, have a certain degree of difference. As a consequence, simply applying existing audio recognition methods directly to GPBR tasks probably results in low recognition accuracy and unstable performance when facing new individuals.
In this paper, we propose a novel audio-based GPBR method armed with competitive fusion learning that enables the model to extract richer advanced combinations of features in deep-integrated hidden space, so as to achieve higher accuracy in distinguishing different behaviors and minimize the impact of individual differences.
Overall, we make the following main contributions.
We construct a giant panda behavior audio dataset called abPanda-5, which includes recordings from five individual pandas and five main behaviors, totaling 18,930 audio samples.
We use a non-stationary noise reduction algorithm to preprocess the input audio to reduce the interference of noise and propose a novel audio-based GPBR method armed with competitive fusion learning, which uses a dual-branch structure to compete with each other to improve the model’s ability to extract more complex acoustic features without causing additional computational overhead in the inference stage.
We conduct comprehensive evaluation experiments and analyses on abPanda-5. The results show that our proposed method achieved an average accuracy of and an average F1-score of , better than that of counterpart methods. In particular, it is confirmed that our method is also effective on some lightweight models, making it possible to deploy IoT devices to monitor giant pandas in remote areas.
The rest of this paper is organized as follows.
Section 2 briefly reviews related work.
Section 3 describes the materials and methods used. Experiments and results are presented and discussed in
Section 4. Finally, conclusions are drawn in
Section 5.
2. Related Work
With the continuous advancement of artificial intelligence technologies in the field of computer science, many researchers have applied speech recognition algorithms to the field of animal acoustics [
7]. For example, Sun et al. [
8] applied convolutional neural networks (CNNs) with data augmentation and transfer learning to classify animal sounds in a tropical rainforest, demonstrating that these techniques can significantly improve accuracy even with small and imbalanced training datasets and are thus feasible for conservation projects. García-Ordás et al. [
9] proposed a method using fully convolutional neural networks (FCNs) for multispecies bird sound recognition. While most work has focused on species classification based on animal vocalizations, some researchers attempt to exploit single-species vocalizations. For example, Chen et al. [
10] proposed TransformerCNN for domestic pig sound classification and achieved recognition accuracy, AUC, and recall scores of 96.05%, 98.37%, and 90.52%, effectively outperforming traditional models.
Particularly in the study of giant pandas, Zhao et al. [
11] proposed a SENet-based model for the automatic recognition of giant panda age and sex from vocalizations, achieving F1-scores of 96.46% for age and 85.85% for sex recognition. Liao et al. [
12] proposed a novel deep neural network called 3Fbank-GRU to automatically recognize giant panda vocalizations based on wide spectrum features to accurately label large datasets of giant pandas, achieving over 95% recognition accuracy. Yan et al. [
13] proposed an automatic method for predicting giant panda mating success based on acoustic features, demonstrating that using audio-based emotion recognition technology in wildlife conservation is feasible.
However, there is no precedent for using deep learning to recognize giant panda behaviors from sounds. There are some successful experiences that can be learned from studies on other animals, though they are also very rare. For example, Nunes et al. [
14] developed a system using wearable sensing and BiLSTM to distinguish chew and bite events in horses. It achieved 94.13% accuracy for chew identification and 88.64% for bite identification. However, their approach demonstrates limitations when processing audio signals generated by complex behaviors and requires substantial computational resources and suffers from slow processing speeds.
In summary, although many acoustic models have been applied in the field of animal acoustics to help researchers achieve good results in animal monitoring and protection, existing methods still cannot achieve excellent results when solving GPBR tasks because they cannot effectively capture more advanced expressions of basic acoustic events in audio signals in deep-integrated hidden space.
3. Materials and Methods
3.1. Data Collection
This study was conducted with full ethical approval from the committee member of the experimental animal ethics review committee of the China Conservation and Research Center for the Giant Panda (Approval No. CCRCGP2025003). The data used in this paper were acquired at the China Conservation and Research Center for the Giant Panda, State Forestry and Grassland Administration Key Laboratory of Conservation Biology for Rare Animals of the Giant Panda State Park, Sichuan, China.
Considering factors such as battery life, device weight, and storage, we chose Sony ICD-PX333M (Sony Corporation, Tokyo, Japan) devices to record and attach to the collar. The audio data collected was stored as MP3 files with a sampling rate of 44,100 Hz [
15] and a compression ratio of 192 kbps. The dataset includes continuous audio from five adult female giant pandas over a period of three days. According to the suggestion of giant panda researchers, we defined the behavior of this study as occurring for more than 30 s. In order to facilitate the follow-up experiments, we adopted mono-audio and cut the audio data into neat 1-min segments. After filtering out a few irrelevant or difficult-to-label segments, each clip was manually labeled as one of five behaviors: eating, resting, moving, nursing, or drinking, following the definitions of giant panda behaviors provided by Kleiman et al. [
16]. A total of 18,930 audio samples are obtained, forming the dataset abPanda-5. Detailed information is provided in
Table 1.
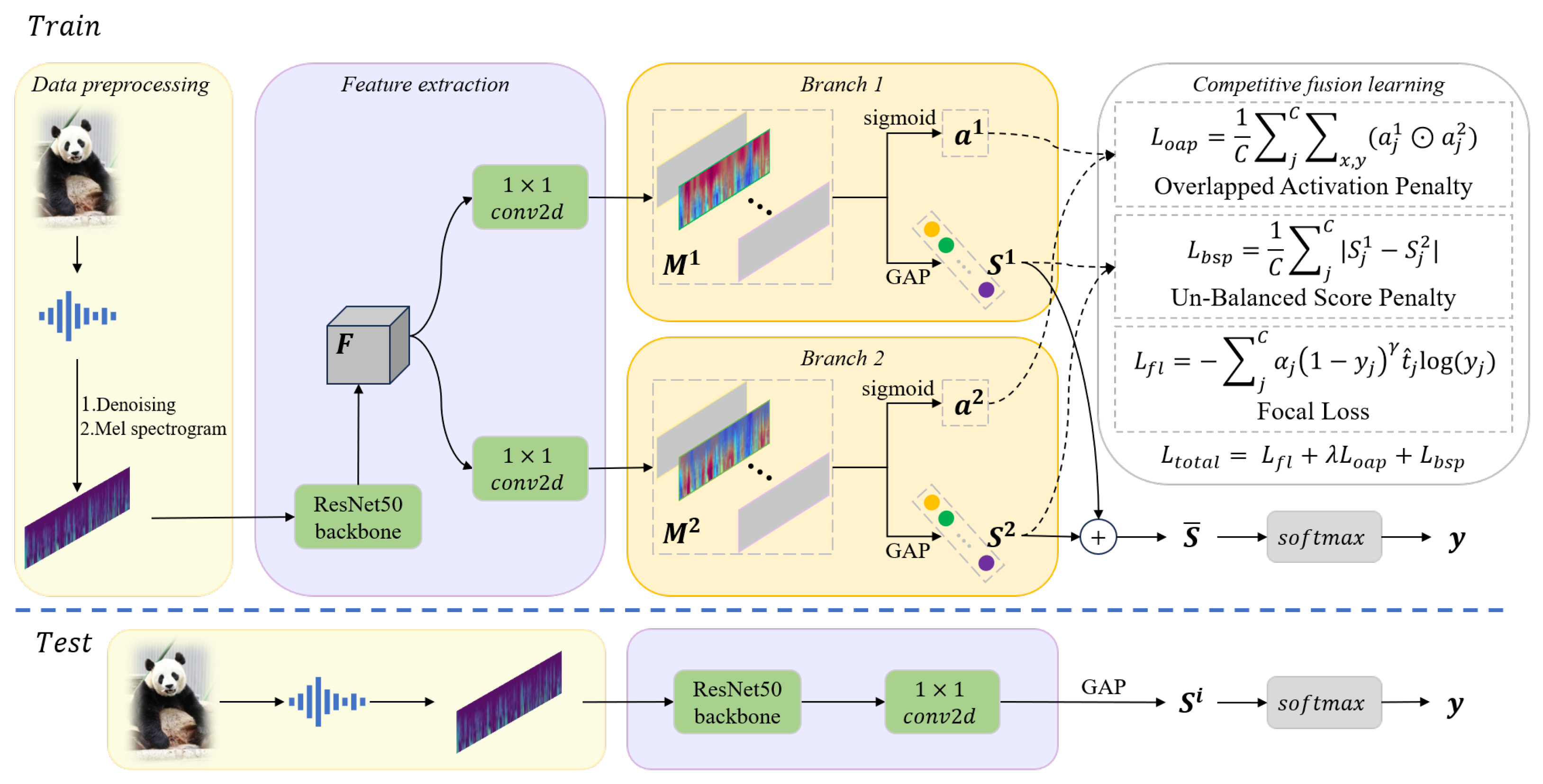
3.2. Overview of the Proposed Method
Figure 1 shows the flow chart of the proposed method, which begins with the preprocessing of the original audio data, including non-stationary noise reduction and Mel spectrogram conversion, and then extracts deep features through the ResNet50 backbone network. To enable the model to capture more basic acoustic events related to behavior, rather than focusing solely on the most salient acoustic events, we designed a dual-branch neural network with competitive fusion learning, which competed with each other in the training process to learn diverse fine-grained feature expression and advanced feature combinations in different feature sets. The features of shallow learning of neural network represent basic primitives (for example, time–frequency texture), and the shared backbone network reduces the model complexity while maintaining the feature representation ability.
In the training stage, the deep features are sent to two branches to obtain class scores and class activation maps, and the competitive fusion learning method is used for back propagation training. In this process, is reduced from 1 thread to 0, which means that the competition gradually weakens, the two branches gradually penetrate and finally converge to the same, and the expression of the feature learned in the competition process will not be forgotten. After the training is completed, only one branch is needed for inference to obtain the recognition result.
3.3. Data Preprocessing
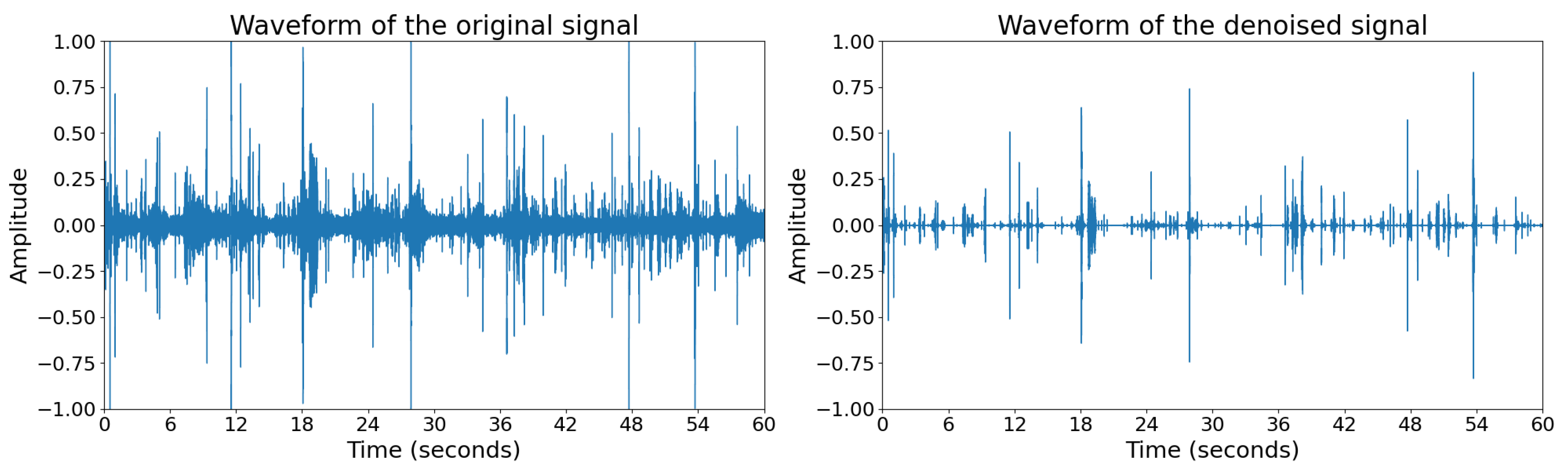
3.3.1. Non-Stationary Noise Reduction
Audio data often contain significant amounts of noise. Therefore, noise suppression was carried out to reduce the impact of background noise. We employ a non-stationary noise reduction algorithm for denoising, which has been shown to have better denoising performance in bioacoustics [
17].
This method operates on the spectrogram
of the input signal, where
f represents frequency and
t represents time. A time-smoothed version of the spectrogram
is computed using an Infinite Impulse Response (IIR) filter applied forward and backward on each frequency channel:
The noise spectrogram is estimated as
, representing the background noise in the signal. We enhance the signal as follows:
where the gain function
is defined as follows:
Finally, the denoised time-domain signal
is obtained by performing the inverse Short-Time Fourier Transform (STFT). This method effectively removes non-stationary noise while preserving the essential characteristics of the target signal.
Figure 2 shows the waveforms of the original signal and denoised signal.
3.3.2. Mel Spectrogram
To represent the time–frequency characteristics of the audio signal, we extract Mel spectrogram features for each audio sample. Mel spectrogram features are a more compact, robust, and suitable representation that can obtain a high-precision statistical model. First, we applied a pre-emphasis filter to the audio signal
to enhance high-frequency components, compensating for their attenuation, and divided the signal into frames. Subsequently, we applied the Fast Fourier Transform (FFT) to each frame to obtain a power spectrum
. Then, the power spectrum is passed through a set of triangular filters mapped to the Mel scale. The center frequency
of each filter is defined as follows:
For each filter, the energy is computed to obtain the Mel spectrogram
:
where
is the frequency response of the
m-th filter.
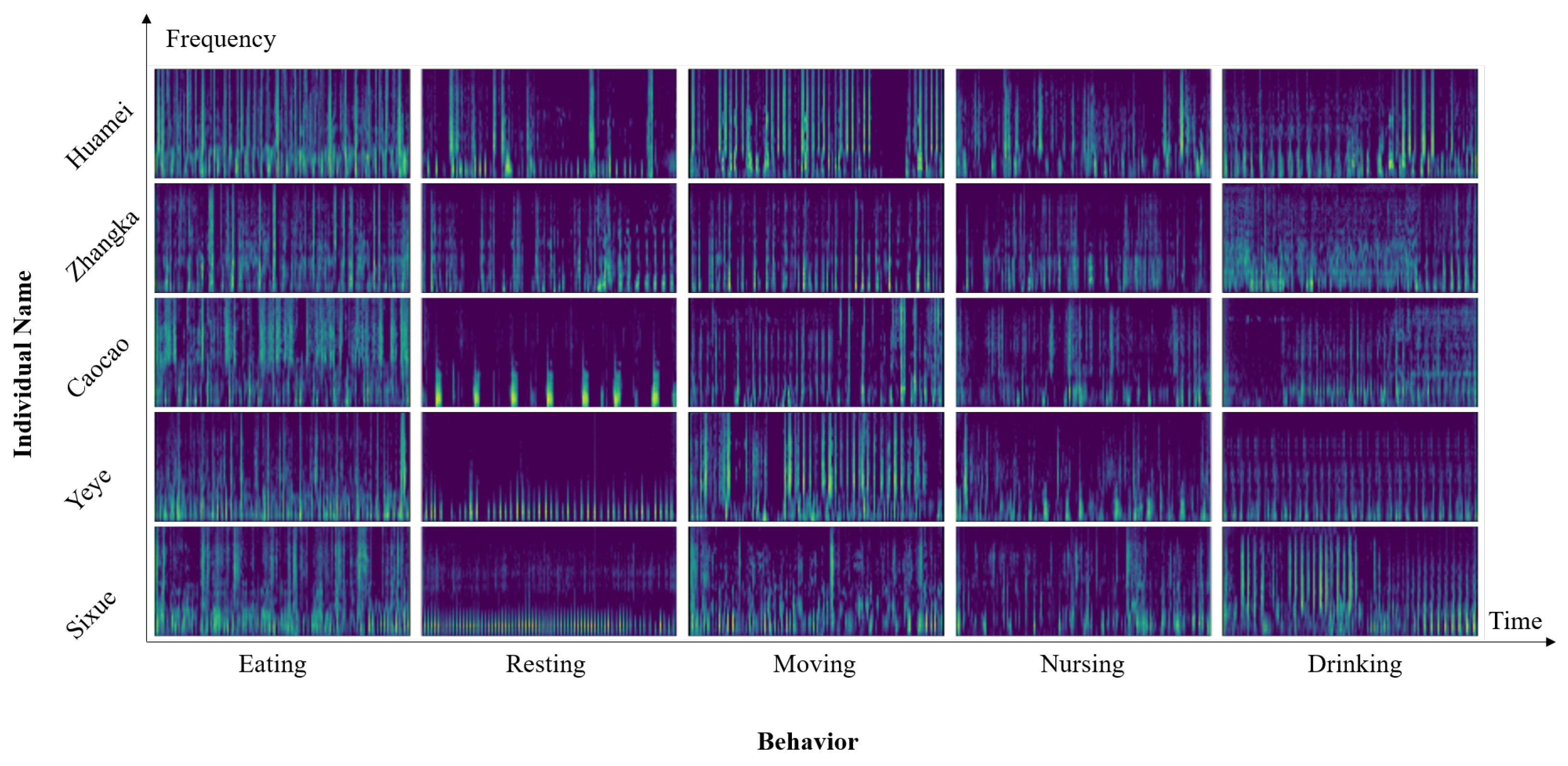
The resulting Mel spectrogram features are used for the subsequent classification task. The Mel spectrogram holds significant biological relevance and interpretability and possesses extensive applications in various fields such as sound recognition and audio classification [
18]. The Mel spectrograms of selected audio samples are shown in
Figure 3.
3.4. Competitive Fusion Learning
3.4.1. Baseline Model
In this study, the ResNet50 [
19] backbone is employed as the feature extractor. The input Mel spectrogram
L passes through the ResNet50 backbone network to obtain a tensor
, which can be interpreted as dense
grids of
d-dimensional local features
at the spatial location
. In the original ResNet50 baseline model, the feature map
F is first processed by global average pooling (GAP) and then passed through a fully connected (FC) layer to obtain the class scores
, where
C denotes the number of classes. The baseline process can be expressed as follows:
3.4.2. Class Activation Maps
Class activation maps (CAMs) [
20] are a widely used technique in visual models for visualizing the regions of an image that the neural network focuses on when making classification decisions. Here, we use a
2D convolution followed by GAP to obtain the class scores
S, replacing the original approach of applying GAP first and then passing the feature vector through a FC layer to obtain the class scores. The derivation of this process can be represented as follows:
where
represents the weight connecting the
k-th input channel to the
j-th output channel in the
2D convolution layer and is equivalent to the parameters of the FC layer.
The activation map for class
j, denoted as
, representing the contribution score of the local feature
to the class score
, is defined as follows:
3.4.3. Loss Function
For each input audio spectrogram
L, the two branches are used to obtain the CAMs,
and
. Then, the sigmoid function is applied to each spatial location
in
M to obtain the masks
and
. The values of these masks are normalized between zero and one, where values closer to one indicate a higher relevance of the corresponding region in L to the target behavior. This process can be described as follows:
To encourage the two branches to compete with each other and extract richer class-related features, we minimize the overlap between the high-response regions of
and
. This forces each branch to focus more on the low-response regions to learn more class-related basic acoustic events. To achieve this, we introduce the Overlapped Activation Penalty (OAP) [
21] to penalize the overlapping area of
and
, defined as follows:
where ⊙ denotes element-wise multiplication, and
C denotes the number of classes.
After applying GAP to the activation maps
and
, we obtain the class scores
and
for both branches. To prevent one branch from becoming too dominant over the other branch during the competition process, we introduce an Unbalanced Score Penalty (BSP) to constrain
and
, which is defined as follows:
This penalty
is essentially the Mean Absolute Error (MAE) loss, which encourages balance between the two branches.
By taking the mean scores of the two branches, we obtain the final class scores
. These scores are then normalized into a probability distribution
using the softmax function. The Focal Loss between the predicted probability
y and the true label
is computed as follows:
where
is a class-balancing factor and is calculated from the class distribution of the training set, and
is a focusing parameter that down-weights well-classified samples and is set to 2 in our implementation.
Integrating the above three losses, we obtain the total loss function for competitive fusion learning as follows:
where
guides the model to learn acoustic features related to the class and dynamically scales cross-entropy to focus on hard examples,
enforces competitive learning between the two branches, and
is a balancing weight. During training,
gradually decreases from one to zero over epochs, resulting in stronger competition in early stages of training and weaker competition in later stages.
guides the two branches to align and produce similar or identical class scores as the competition weakens.
4. Experiments and Results
4.1. Implementation Details
We implemented our method on an Ubuntu system equipped with a NVIDIA GTX 4090 (Santa Clara, CA, USA). During the data preprocessing stage, we used torchaudio [
22] for audio processing. When extracting Mel spectrograms, the length of FFT window, the time interval between successive frames, and the number of Mel filters were, respectively, set to
s,
s, and 64. As a result, a one-minute long audio sample was converted into a tensor with dimensions of
. In all experiments, we adopted a leave-one-out cross-validation strategy [
23]. Specifically, the data from one individual were selected as the test set while the data of the rest of the individuals were used for training, and the process was repeated for each individual. The batch size was set to 16. The learning rate was initialized as
and updated following a cosine annealing schedule [
24]. The model was trained for 40 epochs.
4.2. Evaluation Metrics
We selected accuracy and F1-score as the evaluation metrics [
25]. The F1-score balances both precision and recall. The definitions of these metrics are as follows:
Accuracy: Accuracy is the proportion of correctly classified instances among all the test instances:
where
is the number of true positives,
is the number of true negatives,
is the number of false positives, and
is the number of false negatives.
F1-score: The F1-score is the harmonic mean of precision and recall, providing a balanced measure of both:
where
is defined as the proportion of correctly predicted positive instances among all of the predicted positive instances:
and
is defined as the proportion of correctly predicted positive instances among all of the positive test instances:
4.3. Results and Discussion
4.3.1. Comparison with State-of-the-Art Methods
Table 2 provides a comparison of the proposed method with other state-of-the-art models, including BiLSTM [
14], MobileNetV3 [
26], ShuffleNetV2 [
27], VGG16 [
28], EfficientNetV2 [
29], ResNet50 [
19], ResNext50 [
30], and HTS-AT [
31], in terms of accuracy and F1-score. The results show that our method achieved an average accuracy (± standard deviation) of
and an average F1-score (± standard deviation) of
, outperforming other models in both classification accuracy and robustness.
Figure 4 shows the accuracy and F1-score of the methods under comparison across different panda individuals. From the results, we can see that our method is more stable than other methods in classifying new individual data and achieves the highest accuracy/F1-score for most individuals.
The t-distributed Stochastic Neighbor Embedding (t-SNE) plot provides a visual representation of the classification performance of some test data in a simplified two-dimensional feature space. For quantitative evaluation, the confusion matrix provides a detailed breakdown of the accuracy of the prediction between classes. As shown in
Figure 5, most classes are correctly classified, such as eating and resting. However, there were some exceptions with a slightly lower proportion of correct classifications, such as nursing, which is often misclassified as resting. We infer that this misclassification occurs because giant panda mothers are usually in a relatively restful state while nursing their cubs, causing the model to misidentify them as resting. Additionally, the use of an acquisition device that stores data in MP3 compressed format may blur the cub’s vocalizations, making it difficult for the model to learn effective information. An important premise of using audio to identify the behavior of giant pandas is that giant pandas are solitary animals, and among the five behaviors, only nursing is a process of mother and baby together, which increases the difficulty of identification.
4.3.2. Ablation Study
To evaluate the effectiveness of denoising, as well as the impact of
and
, we conducted ablation experiments in this section. The results of the ablation study are shown in
Table 3. A comparison of the first two rows indicates that denoising influences the recognition performance, highlighting the considerable impact of noise on behavior classification. As the recorder is tied to the collar, denoising mainly reduces the friction sound, wind, and other noises of the collar, which can avoid the noise masking the behavior features we need. Furthermore, a comparison of the last four rows demonstrates that the combination of
and
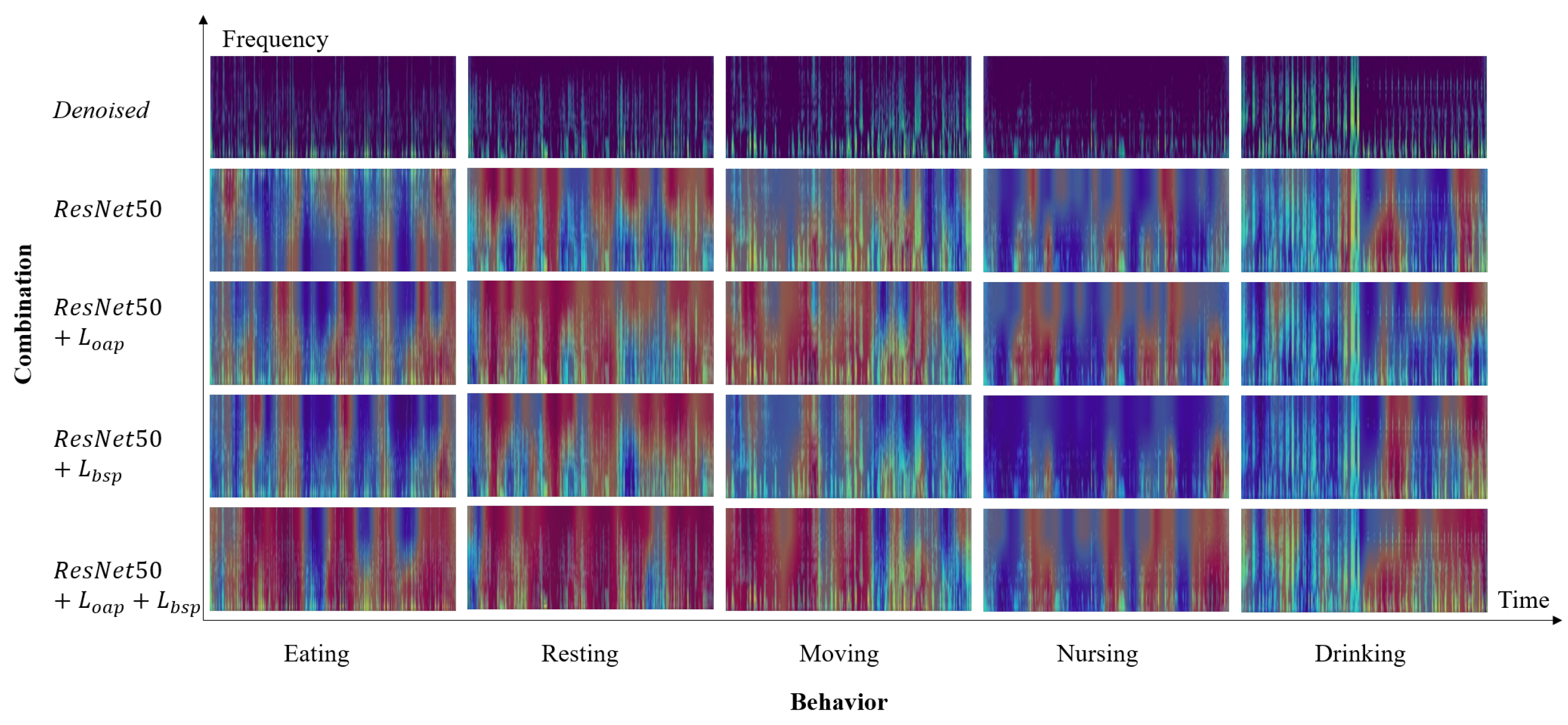
enables the two branches of the model to learn more basic features or combinations of features (see
Figure 6) in competition and balance and improves the feature representation ability of the model, and they are all indispensable.
Additionally,
Figure 6 presents the denoised Mel spectrograms and CAMs for some samples. It is evident that by employing competitive fusion learning, the model is able to capture more diverse audio features such as chewing, rhythmic swallowing sounds, and vocalization bursts. For example, in the sample of drinking in
Figure 6, the beginning of the entire audio clip is a giant panda doing other activities, and the latter part is drinking water. There is an obvious rhythmic gurgling sound in the Mel spectrogram. After using the competitive fusion learning method that includes
and
, the model is able to learn to express behavior features more accurately, which correspond to the time and frequency ranges of more basic acoustic events on the Mel spectrogram.
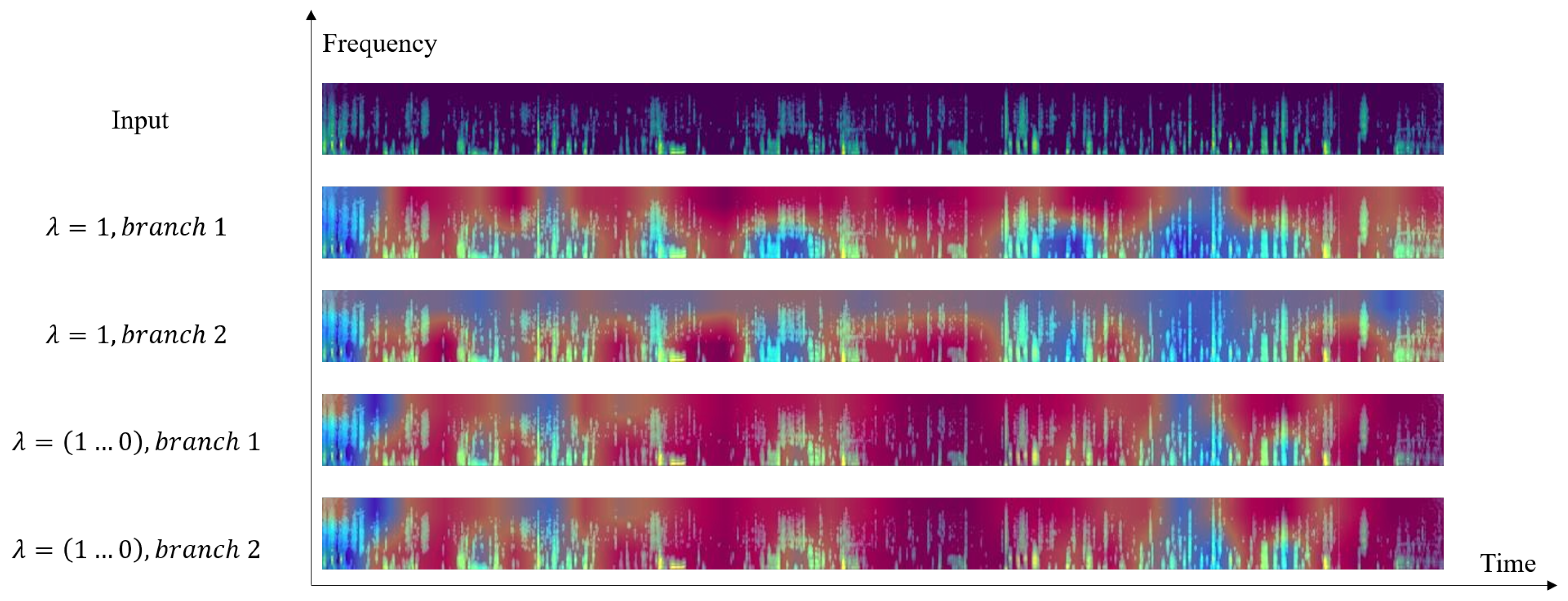
To evaluate the effectiveness of setting the dynamic parameter
, we compare the CAMs generated by the dual-branch under two configurations: (1) a fixed
and (2) a linearly decaying
, as shown in
Figure 7. When
, the two branches produce different outputs, necessitating collaborative inference from both branches. In contrast, when
decays dynamically, the branches converge to identical outputs. Therefore, we can obtain the same result using only a single branch while reducing computational costs.
4.3.3. Different Backbones
In order to test the universality and effectiveness of our proposed framework, we conducted experiments on different CNN-based backbones.
Table 4 presents the experimental results of competitive fusion learning on different backbones, including ResNet50 [
19], VGG16 [
28], MobileNetV1 [
32], MobileNetV2 [
33], MobileNetV3 [
26], ShuffleNetV2 [
27], and EfficientNetB0 [
34]. The results show that the proposed method achieves a significant improvement in accuracy and F1-score by 1–2% on average and a reduction in the standard deviation by 1–2% on these backbones, further validating the effectiveness and broad applicability of our method. Notably, the last five models are lightweight architectures, which have significantly fewer parameters and lower computational costs compared to the others. This suggests that our method offers a promising solution for enhancing algorithm performance and enabling deployment on mobile terminals or edge devices.
5. Conclusions
In order to explore the potential of audio-based automatic recognition of panda behaviors, we have collected an audio dataset containing 18,930 samples of five behaviors from five individual pandas. In this study, we propose a novel audio-based GPBR method armed with competitive fusion learning. Our method is capable of extracting complex acoustic features, which significantly improves recognition performance and robustness without extra computational burden during the inference stage.
We conducted extensive experiments, and the results demonstrate that our method outperforms other deep learning approaches. These results also validate the feasibility of audio-based GPBR. Furthermore, we applied competitive fusion learning to various CNN backbones, achieving significant performance improvements, particularly with lightweight models. This opens up new possibilities for enhancing algorithm performance and deploying the system on mobile devices. Ultimately, this approach not only facilitates panda monitoring but can also be extended to studies of other species, providing a powerful tool for global wildlife conservation efforts.
Despite these significant advances, audio-based GPBR still faces substantial challenges, such as the scarcity of labeled data, noise interference, and behavioral differences between adult and juvenile individuals. In future work, we plan to further expand the dataset and refine the method to address these challenges for better performance of audio-based GPBR.
Author Contributions
Conceptualization, Y.L. (Yuancheng Li), Y.L. (Yong Luo), Q.Z. and Y.Y.; methodology, Y.L. (Yuancheng Li) and Y.L. (Yong Luo); software, Y.L. (Yuancheng Li) and Q.Z.; validation, Y.L. (Yuancheng Li); formal analysis, Y.L. (Yong Luo), M.Z. and D.L.; investigation, M.Z. and D.L.; resources, Y.L. (Yong Luo) and M.Z.; data curation, Y.L. (Yong Luo) and D.L.; writing—original draft preparation, Y.L. (Yuancheng Li); writing—review and editing, Y.L. (Yong Luo), Q.Z. and Y.Y.; visualization, Y.L. (Yuancheng Li); supervision, Q.Z., M.Z., Y.Y. and D.L.; project administration, Q.Z., Y.Y. and Y.L. (Yong Luo); funding acquisition, Q.Z. and Y.L. (Yong Luo). All authors have read and agreed to the published version of this manuscript.
Funding
This research was supported by the Self-funded Foundation of China Conservation and Research Center for the Giant Panda (CCRCGP222336).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data generated or presented in this study are available upon request from the corresponding author. Furthermore, the models and code used during this study cannot be shared at this time as the data also form part of an ongoing study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yang, Z.; Gu, X.; Nie, Y.; Huang, F.; Huang, Y.; Dai, Q.; Hu, Y.; Yang, Y.; Zhou, X.; Zhang, H.; et al. Reintroduction of the giant panda into the wild: A good start suggests a bright future. Biol. Conserv. 2018, 217, 181–186. [Google Scholar] [CrossRef]
- He, K.; Dai, Q.; Foss-Grant, A.; Gurarie, E.; Fagan, W.F.; Lewis, M.A.; Qing, J.; Huang, F.; Yang, X.; Gu, X.; et al. Movement and activity of reintroduced giant pandas. Ursus 2019, 29, 163–174. [Google Scholar] [CrossRef]
- Kardish, M.R.; Mueller, U.G.; Amador-Vargas, S.; Dietrich, E.I.; Ma, R.; Barrett, B.; Fang, C.C. Blind trust in unblinded observation in ecology, evolution, and behavior. Front. Ecol. Evol. 2015, 3, 51. [Google Scholar] [CrossRef]
- Swarup, P.; Chen, P.; Hou, R.; Que, P.; Liu, P.; Kong, A.W.K. Giant panda behaviour recognition using images. Glob. Ecol. Conserv. 2021, 26, e01510. [Google Scholar] [CrossRef]
- Liu, J.; Hou, J.; Liu, D.; Zhao, Q.; Chen, R.; Chen, X.; Hull, V.; Zhang, J.; Ning, J. A joint time and spatial attention-based transformer approach for recognizing the behaviors of wild giant pandas. Ecol. Inform. 2024, 83, 102797. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, H.; Li, D.; Wu, D.; Zhou, S.; Sun, M.; Hu, H.; Liu, X.; Mou, S.; He, S.; et al. Acoustic recordings provide detailed information regarding the behavior of cryptic wildlife to support conservation translocations. Sci. Rep. 2019, 9, 5172. [Google Scholar] [CrossRef]
- Oikarinen, T.; Srinivasan, K.; Meisner, O.; Hyman, J.B.; Parmar, S.; Fanucci-Kiss, A.; Desimone, R.; Landman, R.; Feng, G. Deep convolutional network for animal sound classification and source attribution using dual audio recordings. J. Acoust. Soc. Am. 2019, 145, 654–662. [Google Scholar] [CrossRef]
- Sun, Y.; Maeda, T.M.; Solís-Lemus, C.; Pimentel-Alarcón, D.; Buřivalová, Z. Classification of animal sounds in a hyperdiverse rainforest using convolutional neural networks with data augmentation. Ecol. Indic. 2022, 145, 109621. [Google Scholar] [CrossRef]
- García-Ordás, M.T.; Rubio-Martín, S.; Benítez-Andrades, J.A.; Alaiz-Moretón, H.; García-Rodríguez, I. Multispecies bird sound recognition using a fully convolutional neural network. Appl. Intell. 2023, 53, 23287–23300. [Google Scholar] [CrossRef]
- Liao, J.; Li, H.; Feng, A.; Wu, X.; Luo, Y.; Duan, X.; Ni, M.; Li, J. Domestic pig sound classification based on TransformerCNN. Appl. Intell. 2023, 53, 4907–4923. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, Y.; Hou, R.; He, M.; Liu, P.; Xu, P.; Zhang, Z.; Chen, P. Automatic recognition of giant panda attributes from their vocalizations based on Squeeze-and-Excitation Network. Sensors 2022, 22, 8015. [Google Scholar] [CrossRef] [PubMed]
- Liao, Z.; Hu, S.; Hou, R.; Liu, M.; Xu, P.; Zhang, Z.; Chen, P. Automatic recognition of giant panda vocalizations using wide spectrum features and deep neural network. Math. Biosci. Eng. 2023, 20, 15456–15475. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.; Tang, M.; Chen, Z.; Chen, P.; Zhao, Q.; Que, P.; Wu, K.; Hou, R.; Zhang, Z. Automatically predicting giant panda mating success based on acoustic features. Glob. Ecol. Conserv. 2020, 24, e01301. [Google Scholar] [CrossRef]
- Nunes, L.; Ampatzidis, Y.; Costa, L.; Wallau, M. Horse foraging behavior detection using sound recognition techniques and artificial intelligence. Comput. Electron. Agric. 2021, 183, 106080. [Google Scholar] [CrossRef]
- Watkinson, J. Art of Digital Audio; Routledge: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Kleiman, D.G. Ethology and reproduction of captive giant pandas (Ailuropoda melanoleuca). Z. Tierpsychol. 1983, 62, 1–46. [Google Scholar] [CrossRef]
- Sainburg, T.; Gentner, T.Q. Toward a computational neuroethology of vocal communication: From bioacoustics to neurophysiology, emerging tools and future directions. Front. Behav. Neurosci. 2021, 15, 811737. [Google Scholar] [CrossRef]
- Seo, S.; Kim, C.; Kim, J.H. Convolutional neural networks using log mel-spectrogram separation for audio event classification with unknown devices. J. Web Eng. 2022, 21, 497–522. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Yang, W.; Huang, H.; Zhang, Z.; Chen, X.; Huang, K.; Zhang, S. Towards rich feature discovery with class activation maps augmentation for person re-identification. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1389–1398. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Hira, M.; Ni, Z.; Astafurov, A.; Chen, C.; Puhrsch, C.; Pollack, D.; Genzel, D.; Greenberg, D.; Yang, E.Z.; et al. Torchaudio: Building blocks for audio and speech processing. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 23–27 May 2022; pp. 6982–6986. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobileNetV3. In Proceedings of the 2019 IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Chen, K.; Du, X.; Zhu, B.; Ma, Z.; Berg-Kirkpatrick, T.; Dubnov, S. Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 23–27 May 2022; pp. 646–650. [Google Scholar] [CrossRef]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}