
Bearing Fault Diagnosis Based on Time–Frequency Dual Domains and Feature Fusion of ResNet-CACNN-BiGRU-SDPA


Abstract
1. Introduction
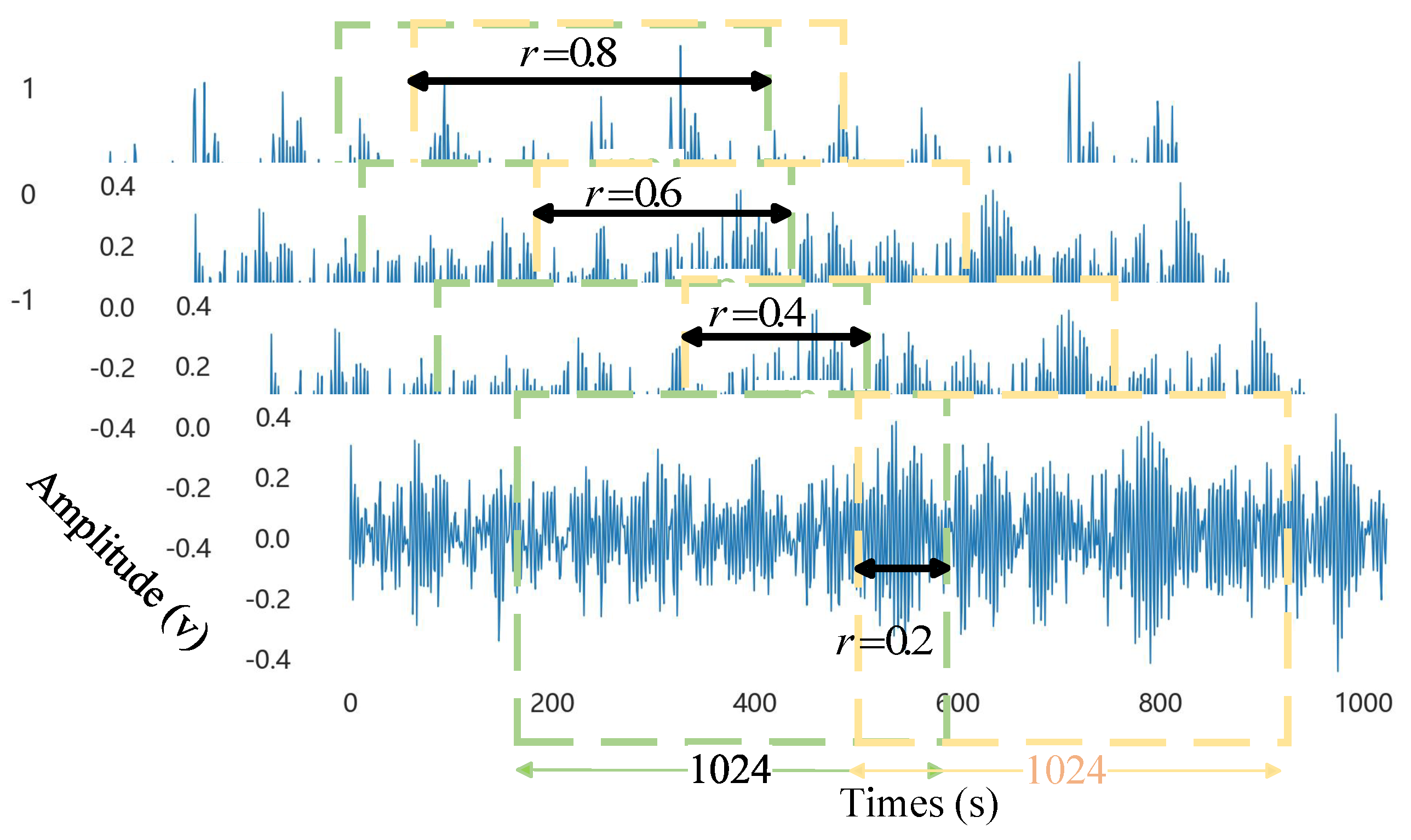
- A multi-window overlapping data enhancement and sampling technique is proposed to deal with sparse fault samples and provide rich fault sample support for subsequent diagnosis. Then, the Cooley–Tukey algorithm is introduced to convert the time-domain signals used in traditional fault diagnosis to the frequency domain, highlighting the periodic local features of the signals, which greatly expands the sensory field of the signals for multi-dimensional features, while simplifying signal representations, enabling the subsequent model to mine richer and more comprehensively detailed features.
- A CACNN structure is proposed to decompose the features and calculate the weight fusion of the input features in both the horizontal and vertical directions. This structure eliminates the problems of incomplete local feature extraction and overfitting when extracting long sequence features in the frequency domain with minimal computation, while preventing the model from falling into local optima and feature loss. In addition, while the CACNN extracts the local frequency-domain features, another channel uses the ResNet structure to process the long sequence time-domain features. This maximizes the extraction of the detailed features of the model in both the time and frequency domains for the dual channels, and improves the performance of the model’s feature extraction.
- The two-layer BiGRU structure helps explore and extract features by looking at both time and frequency, allowing it to understand long-distance relationships between local features and rebuild the overall signal, while gathering detailed bi-directional features. The SDPA structure dynamically captures complex feature information and adapts to changing noise conditions, which enhances the adaptability and robustness of the intelligent diagnostic model to noise, forms a complete and efficient diagnostic system, and expands the scope of the intelligent diagnostic model and its reliability in practical engineering applications.
2. Related Work
2.1. CNN
2.2. Bi-Directional Gated Circulation Unit
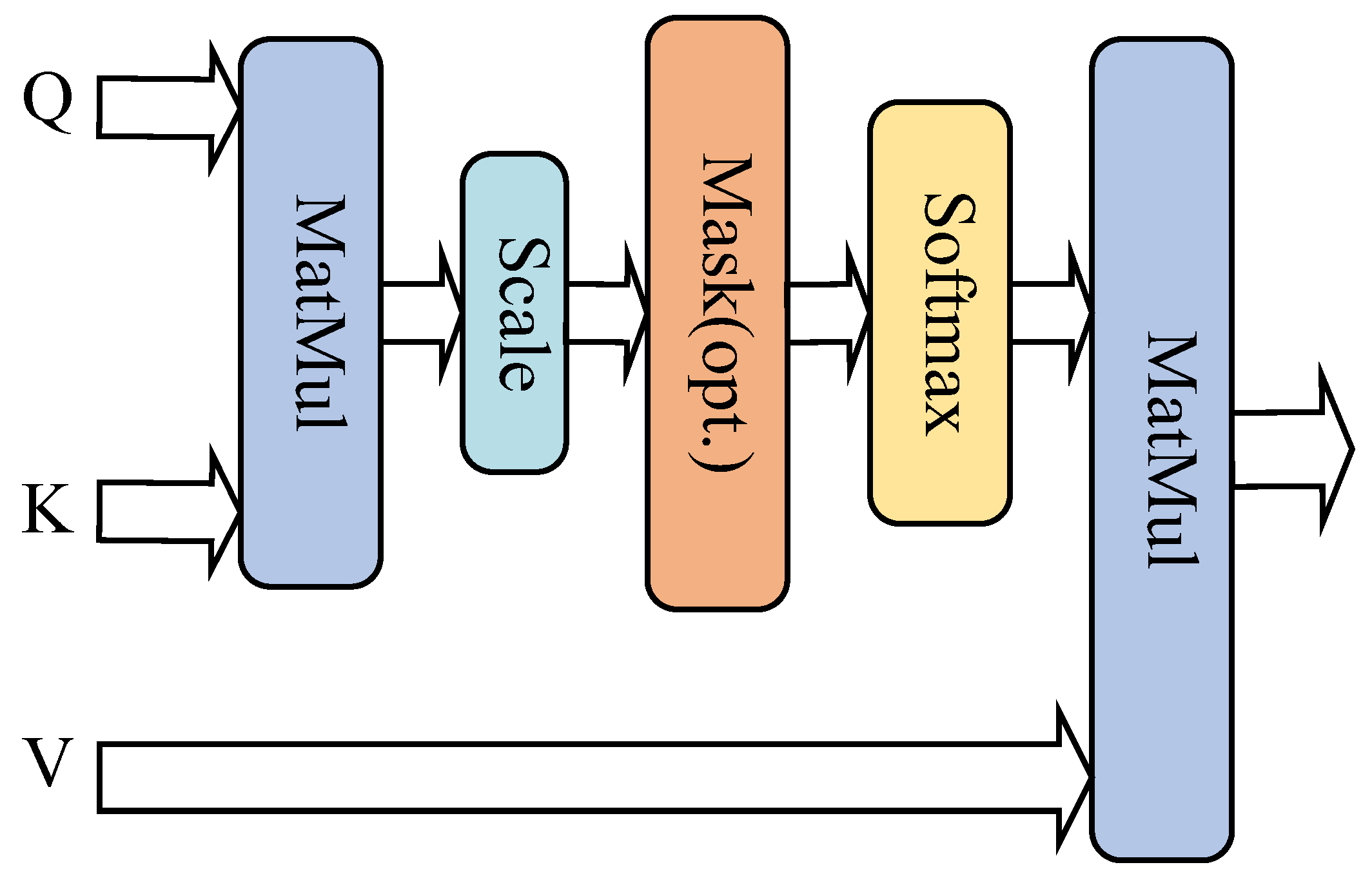
2.3. Scaling Dot Product Attention Mechanism
3. Proposed Method
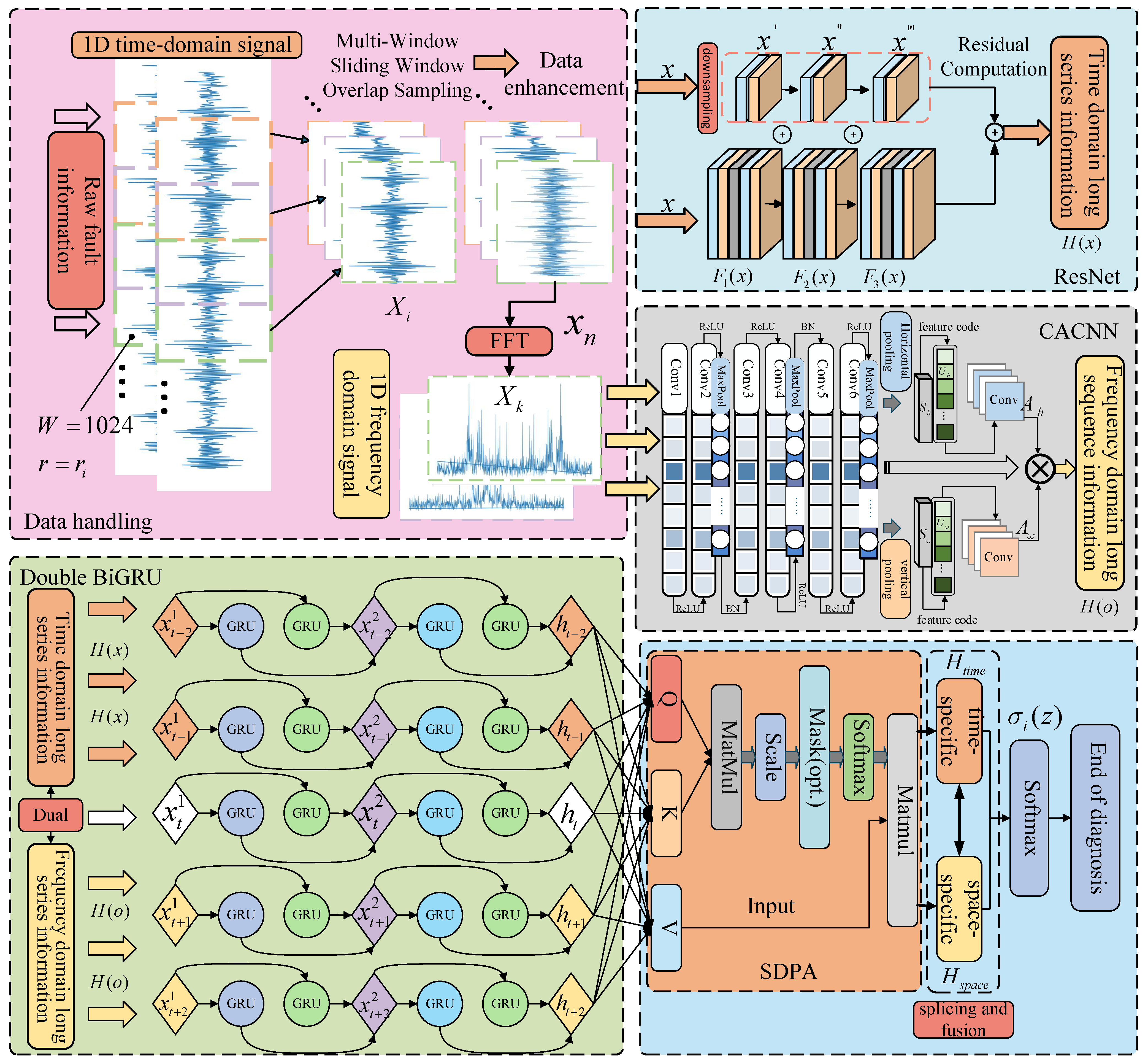
3.1. ResNet-CACNN-BiGRU-SDPA Modeling
- One-dimensional time-domain signals are converted into one-dimensional frequency-domain signals using the Cooley–Tukey technique, based on a multi-window sliding-window overlapping sampling technique to gather signals from the original data, which enriches the acquired data features, and then adding Gaussian white noise to improve the model’s adaptability to the noise;
- With the goal of conducting local feature exploration in the time-domain direction, the acquired one-dimensional time-domain signals are fed into the ResNet network. Meanwhile, the CACNN module is used to conduct local feature exploration in the frequency-domain direction, meaning that sensitive fault time–frequency-domain information, and , is mined by the two-way mining of ResNet and CACNN;
- The temporal and spatial BiGRU(T-S BiGRU) module receives the signal from feature mining, and the forward and reverse information is used to investigate the deeper global features in the time–frequency domain and to capture long dependencies in the sequence data;
- The time–frequency features extracted from the T-S BiGRU layer are used to measure the correlation with the dot product operation between the query vector (Query), the key vector (Key), and the value vector (Value) in the SDPA mechanism, and the outputs of the temporal and spatial features and after the dot product operation;
- Splicing and fusing the above spatio-temporal features and obtaining the model probability distribution with Softmax completes the fault classification task, and the following is the Softmax mathematical expression:
3.2. FFT Conversion of One-Dimensional Bearing Signals
3.3. ResNet Network and Residual Blocks
3.4. CACNN Model
3.5. Model Parameters
3.6. Troubleshooting Process
- Preparation of data. The original bearing fault signal is subjected to multi-window sliding window overlapping sampling and Gaussian noise data enhancement, and the training, validation, and test sets are separated in a 7:2:1 ratio;
- Feature extraction and model training. In this work, we used the Adam optimizer, with the learning rate at 0.0003, the number of training rounds at 50, and the model batch size at 32. The model is then given data from the processed training and validation sets, and the training and validation process loss is computed. After the model converges, the optimal model parameters are saved until the end of the iterative process with the designated number of rounds. The model parameters are then updated using backward gradient propagation. The cross-entropy function shown below is used to calculate the training loss:In Equation (22), n is the number of categories, is the one-hot encoding of the true label, and is the probability predicted by the model, which maximizes the probability of the correct category, while minimizing the predicted-true distribution difference.
- Model classification test. We tested the best model given above on the test set, evaluated the model’s performance, and tested the accuracy and fault classification effect of a model that was trained on new data.
4. Experimental Verification
4.1. Experiments with the CWRU Dataset
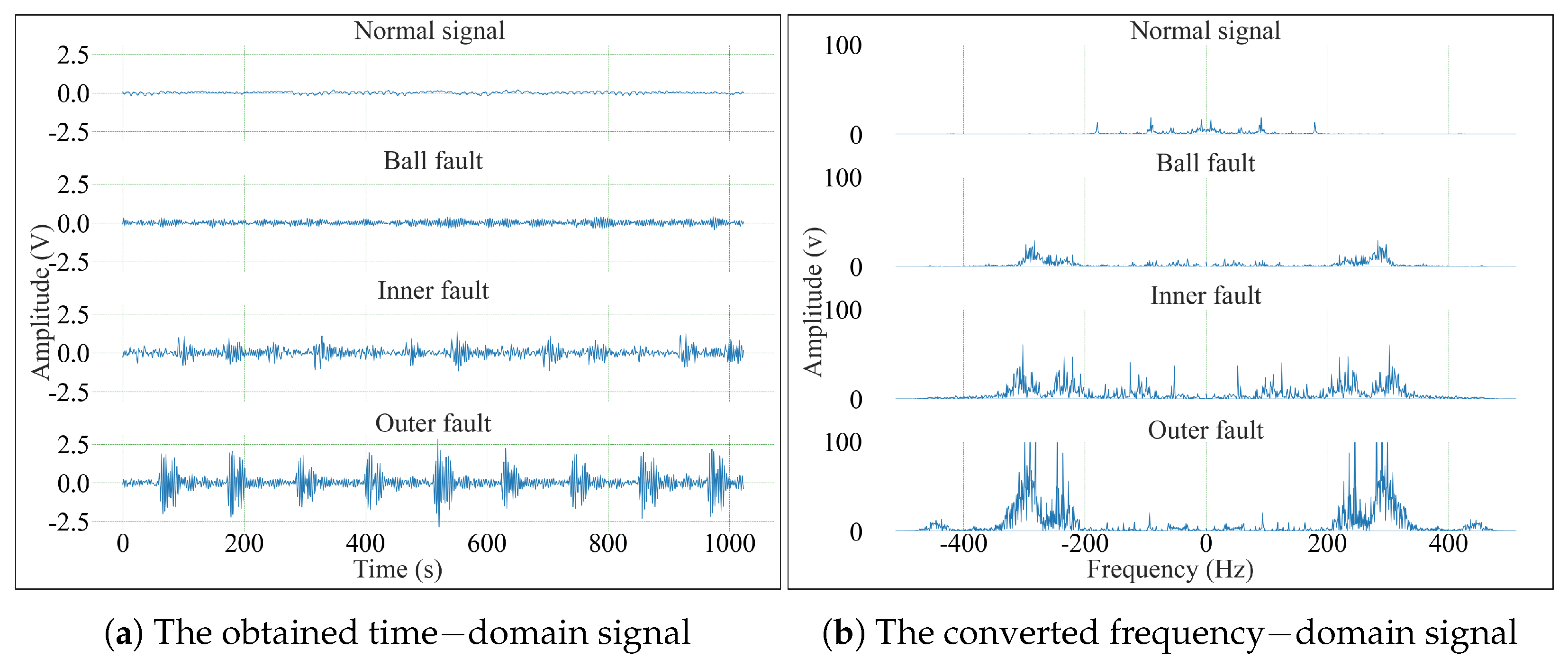
4.1.1. CWRU Bearing Dataset
4.1.2. Data Sampling and Enhancement
4.1.3. Small Sample Experiment
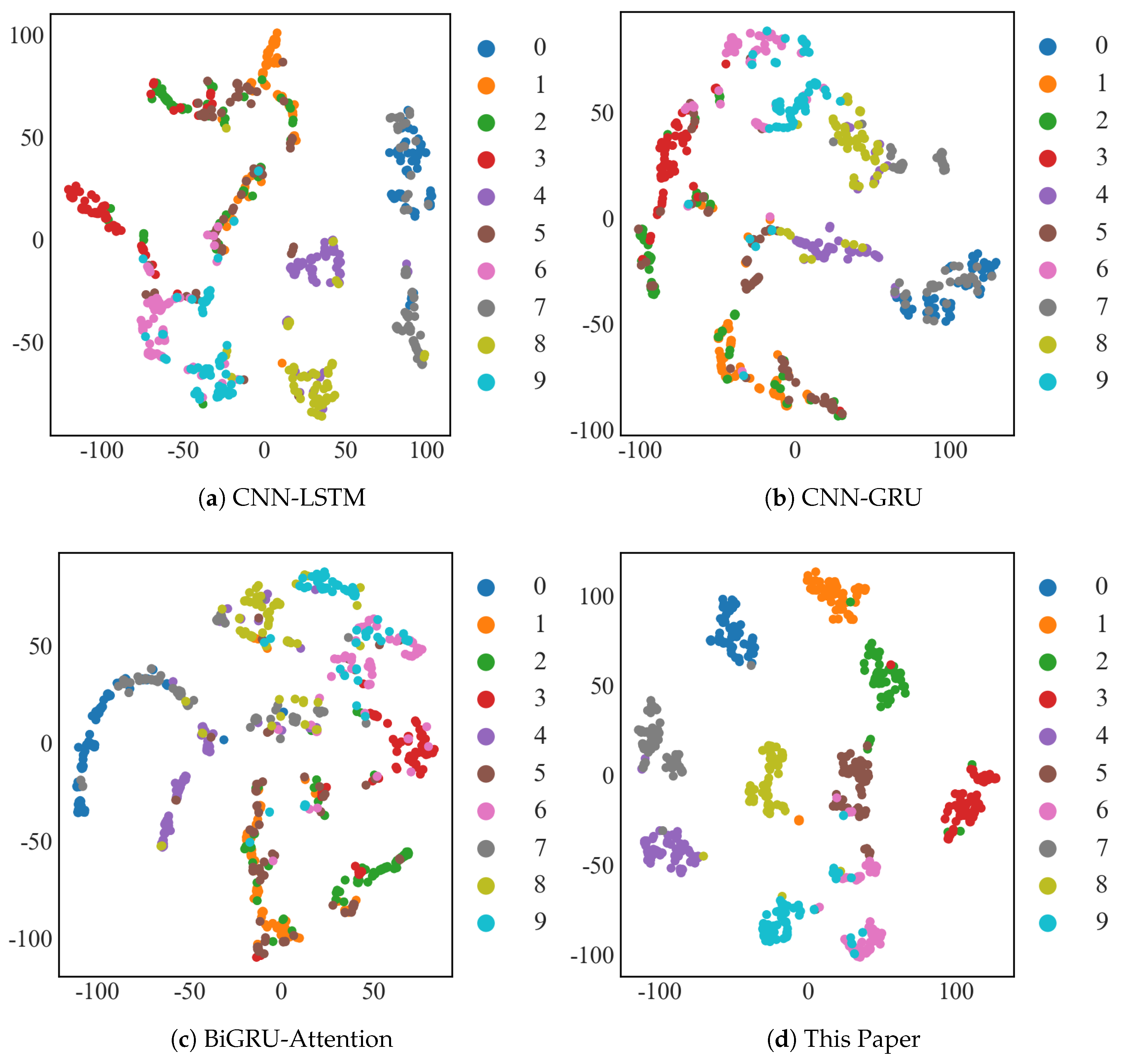
4.1.4. T-SNE Visualization
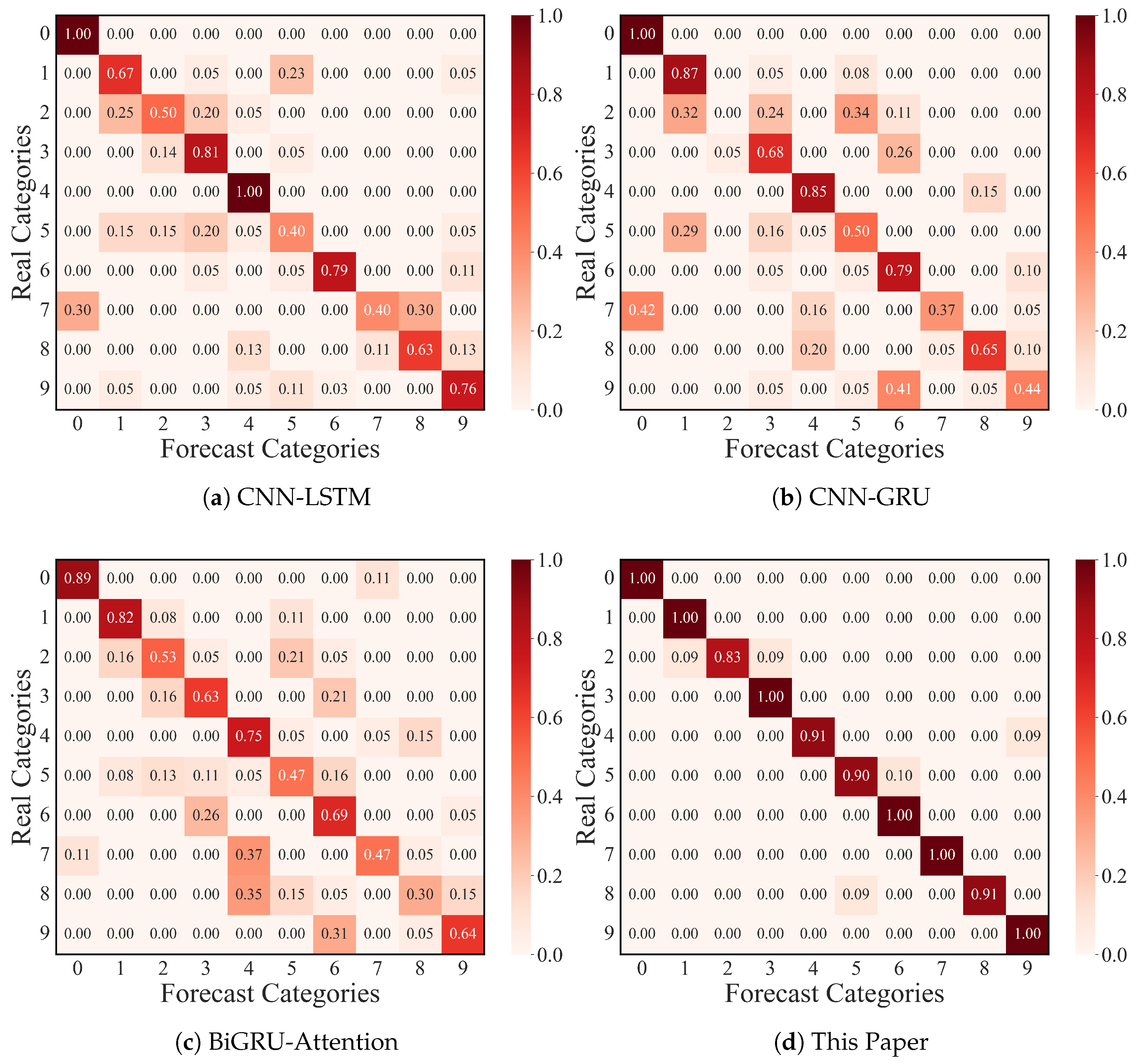
4.1.5. Confusion Matrix Visualization
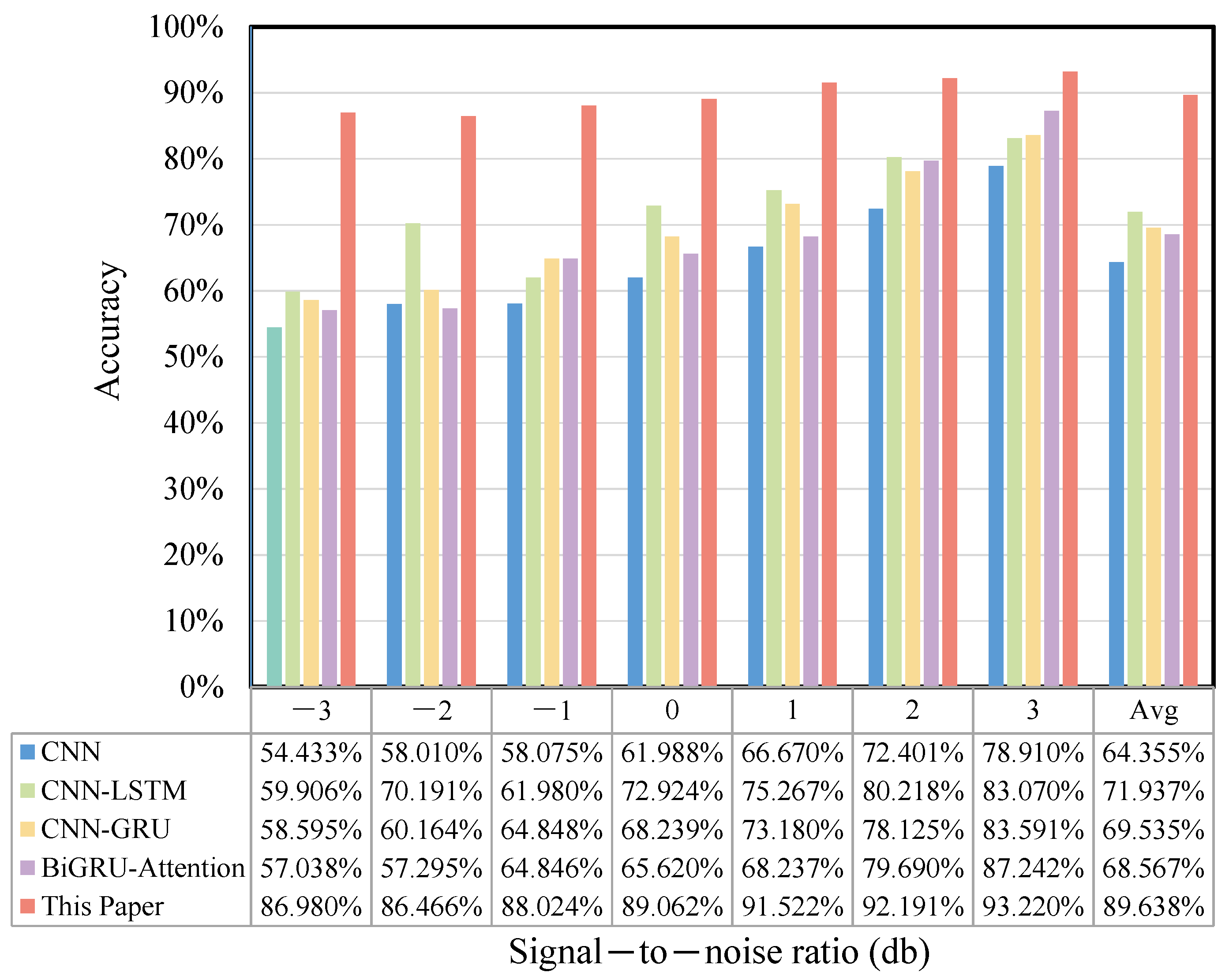
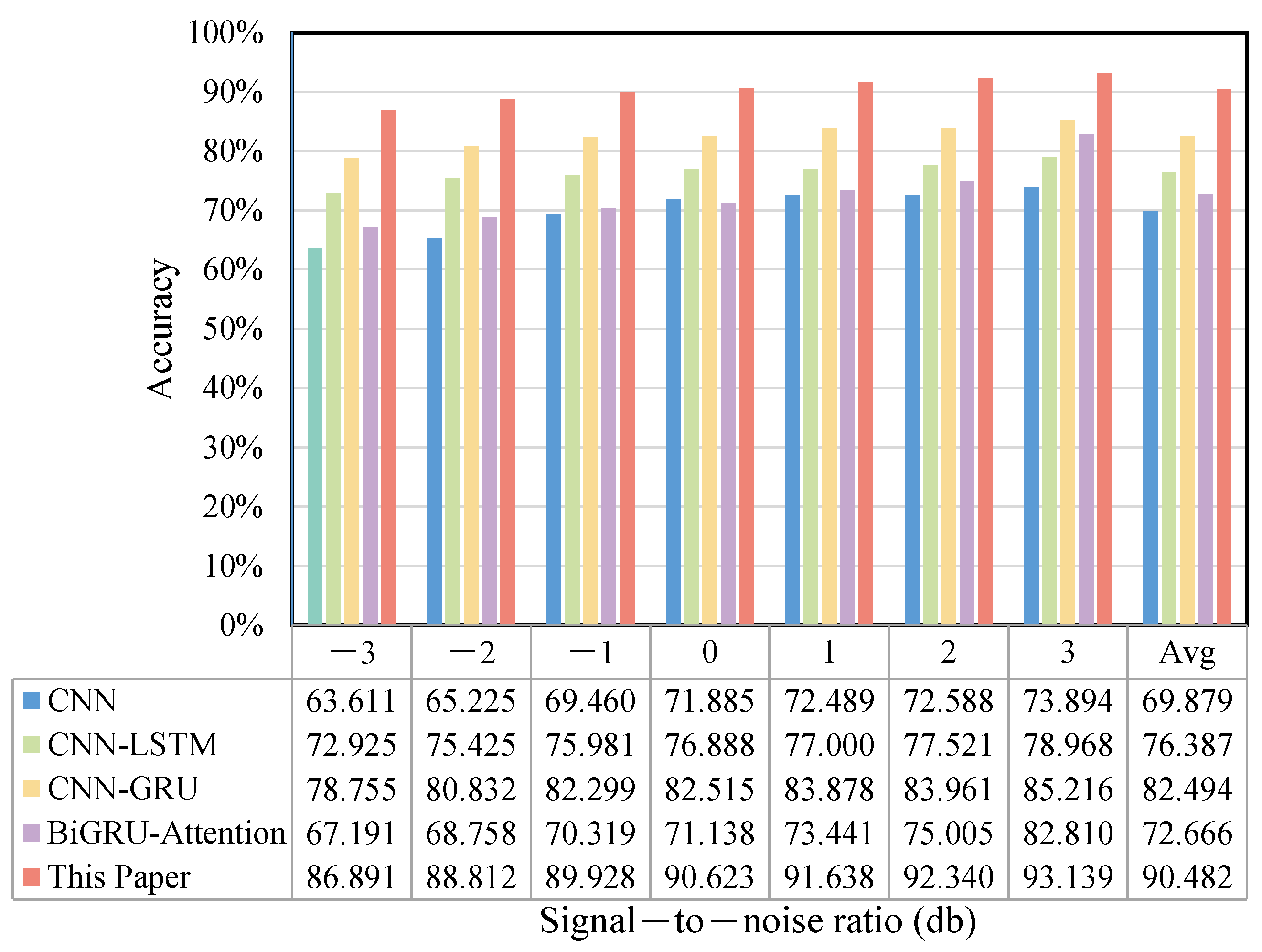
4.1.6. Noise Experiment
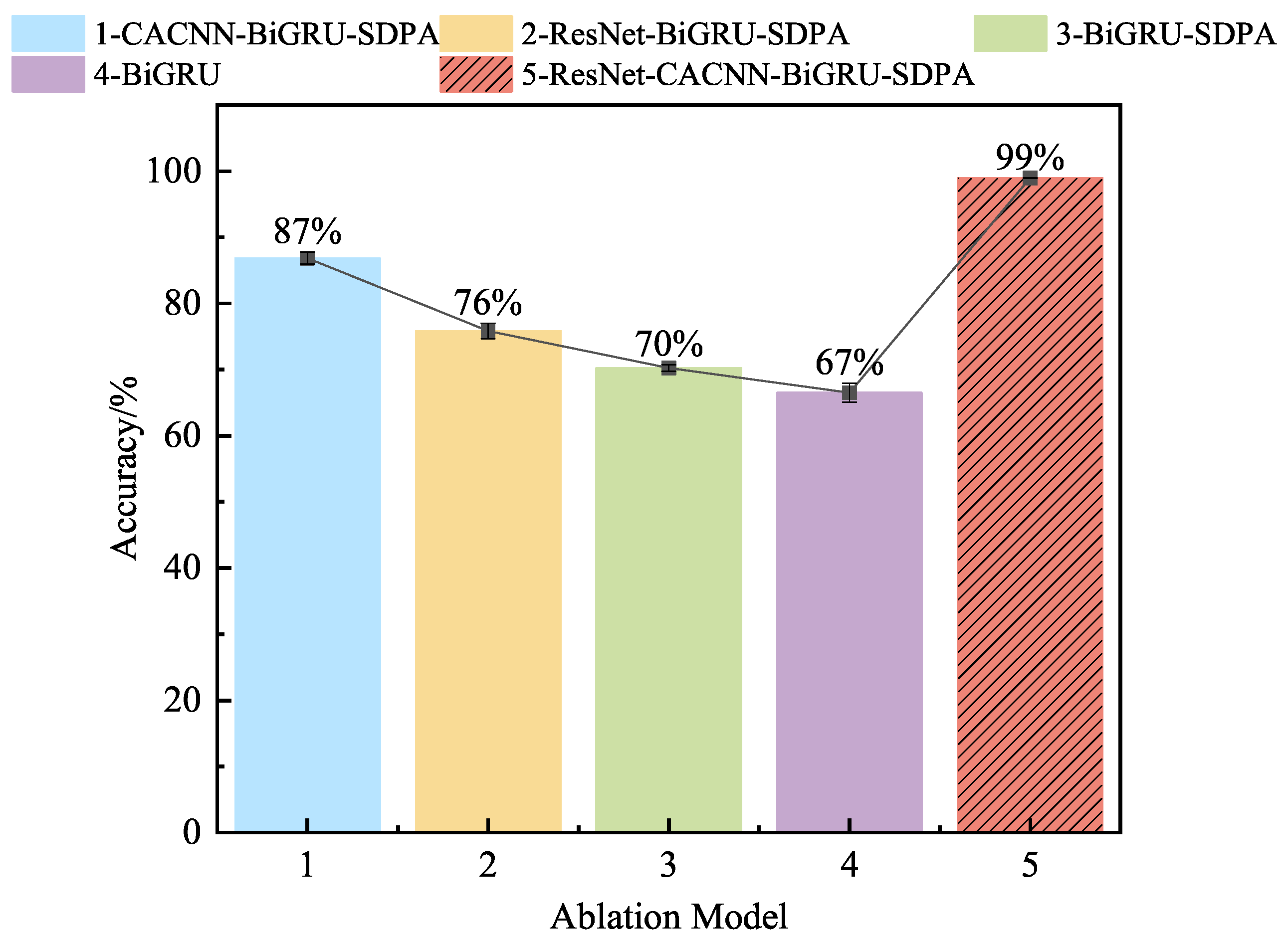
4.1.7. Ablation Experiments
4.2. Experiments with the JNU Dataset
4.2.1. JNU Bearing Dataset
4.2.2. Small Sample Experiment
4.2.3. T-SNE Visualization
4.2.4. Confusion Matrix Visualization
4.2.5. Noise Experiment
4.2.6. Ablation Experiments
5. Conclusions
- The multi-window sliding-window overlapping sampling method proposed in this paper enriched the original input features, and the experiments demonstrated that this method could mine more important information of the faults under the condition of a small number of samples. This paper extended the feature mining domain from the time domain to the frequency domain, giving the model a bidirectional sensing field in the time–frequency domain for signal feature extraction;
- With the goal of maximizing the depth of signal exploration in complex environments, we analyzed the signal features in time–frequency dual domains in this paper. Then, we designed ResNet and CACNN modules to extract the local fault features in the time–frequency domain and obtained the global feature dependence of the time–frequency long sequence through a two-layer BiGRU. It was experimentally demonstrated that the model could produce better diagnostic results with greater generality and robustness across a variety of datasets under various noise perturbation settings;
- In order to dynamically capture the spatio-temporal feature correlation weights in the dot-product state and further optimize the feature long-range dependence following BiGRU layer processing, we employed the SDPA in this paper. This helped to mitigate the perturbation of the data baseline features caused by fluctuating noise signals. The model’s strong diagnostic accuracy and noise immunity across several datasets were experimentally confirmed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Wu, Y. Fault diagnosis of photovoltaic modules: A review. Sol. Energy 2025, 293, 113489. [Google Scholar] [CrossRef]
- Zhong, Z.; Xie, H.; Wang, Z. Domain Adversarial Transfer Learning Bearing Fault Diagnosis Model Incorporating Structural Adjustment Modules. Sensors 2025, 25, 1851. [Google Scholar] [CrossRef] [PubMed]
- Mamun, A.; Zubiaga, G.D.; Peng, Y. Smart systems for real-time bearing faults diagnosis by using vibro-acoustics sensor fusion with Bayesian optimised 1-D CNNs. Nondestruct. Test. Eval. 2025, 40, 2113–2137. [Google Scholar] [CrossRef]
- Dai, Q.; Zheng, C.; Wang, S. Variable reluctance generator assisted intelligent monitoring and diagnosis of wind turbine spherical roller bearings. Measurement 2025, 251, 117264. [Google Scholar] [CrossRef]
- Wang, B.; Li, H.; Hu, X. Rolling bearing fault diagnosis based on multi-domain features and whale optimized support vector machine. J. Vib. Control 2025, 31, 708–720. [Google Scholar] [CrossRef]
- Guo, Y.; Zhou, J.; Dong, Z. Research on bearing fault diagnosis based on novel MRSVD-CWT and improved CNN-LSTM. Meas. Sci. Technol. 2024, 35, 095003. [Google Scholar] [CrossRef]
- Dai, J.; Tian, L.; Han, T. Digital Twin for wear degradation of sliding bearing based on PFENN. Adv. Eng. Inform. 2024, 61, 102512. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Wang, X. A comprehensive review on bearing failure analysis and condition monitoring techniques. Mech. Syst. Signal Process. 2023, 185, 109812. [Google Scholar]
- Li, H.; Wu, K.; Chen, T. Intelligent fault detection for motor bearings under varying operating conditions. IEEE/ASME Trans. Mechatronics 2023, 28, 287–299. [Google Scholar]
- Liu, J.; Zhang, R.; Yang, S. Physics-informed neural networks for bearing remaining useful life prediction. Nat. Commun. Eng. 2023, 2, 15. [Google Scholar] [CrossRef]
- Guo, H.; Ping, D.; Wang, L. Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment. Sensors 2025, 25, 2286. [Google Scholar] [CrossRef] [PubMed]
- Wei, K.; Zhao, R.; Kou, H. Dimensionality reduction of rolling bearing fault data based on graph-embedded semi-supervised deep auto-encoders. Eng. Appl. Artif. Intell. 2025, 152, 110689. [Google Scholar] [CrossRef]
- Wang, R.; Yu, M.; Shan, T. Fast cyclostationary beamforming algorithm for localization of cyclostationary sound sources. Mech. Syst. Signal Process. 2025, 230, 112604. [Google Scholar] [CrossRef]
- Liang, C.; Mu, X.; Zhang, X. Enhanced fault diagnosis of rolling bearings using attention-augmented separable residual networks. Eng. Sci. Technol. Int. J. 2025, 61, 101930. [Google Scholar] [CrossRef]
- Zhu, H.; Sui, Z.; Xu, J. Fault Diagnosis of Mechanical Rolling Bearings Using a Convolutional Neural Network–Gated Recurrent Unit Method with Envelope Analysis and Adaptive Mean Filtering. Processes 2024, 12, 2845. [Google Scholar] [CrossRef]
- Han, K.; Wang, W.; Guo, J. Research on a Bearing Fault Diagnosis Method Based on a CNN-LSTM-GRU Model. Machines 2024, 12, 927. [Google Scholar] [CrossRef]
- Shan, S.; Zheng, J.; Wang, K. Weak Fault Diagnosis Method of Rolling Bearings Based on Variational Mode Decomposition and a Double-Coupled Duffing Oscillator. Appl. Sci. 2023, 13, 8505. [Google Scholar] [CrossRef]
- Li, X.; Chen, J.; Wang, J. Multi-Scale Channel Mixing Convolutional Network and Enhanced Residual Shrinkage Network for Rolling Bearing Fault Diagnosis. Electronics 2025, 14, 855. [Google Scholar] [CrossRef]
- Sulaiman, H.M.; Mustaffa, Z.; Mohamed, I.A. Battery state of charge estimation for electric vehicle using Kolmogorov-Arnold networks. Energy 2024, 311, 133417. [Google Scholar] [CrossRef]
- Liao, W.; Fu, W.; Yang, K. Multi-scale residual neural network with enhanced gated recurrent unit for fault diagnosis of rolling bearing. Meas. Sci. Technol. 2024, 35, 056114. [Google Scholar] [CrossRef]
- Qian, Q.; Wen, Q.; Tang, R. DG-Softmax: A new domain generalization intelligent fault diagnosis method for planetary gearboxes. Reliab. Eng. Syst. Saf. 2025, 260, 111057. [Google Scholar] [CrossRef]
- Xu, Z.; Jin, C.; Li, C. Creep behavior modeling of nickel-based superalloy foil structures in gas foil bearings. Thin-Walled Struct. 2025, 211, 113105. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, B.; Jin, H. Damage identification of wind turbine pitch bearings based on AFMD and SVDD. Acta Energiae Solaris Sin. 2025, 46, 514–523. [Google Scholar] [CrossRef]
- Cai, W.; Zhao, D.; Wang, T. Spatial-temporal graph attention contrastive learning for semi-supervised bearing fault diagnosis with limited labeled samples. Comput. Ind. Eng. 2025, 204, 111106. [Google Scholar] [CrossRef]
- Zhai, Z.; Luo, L.; Chen, Y. Rolling Bearing Fault Diagnosis Based on a Synchrosqueezing Wavelet Transform and a Transfer Residual Convolutional Neural Network. Sensors 2025, 25, 325. [Google Scholar] [CrossRef]
- Li, X.; Xing, Z.; Xiang, L. Memory-augmented prototypical meta-learning method for bearing fault identification under few-sample conditions. Neurocomputing 2025, 635, 129996. [Google Scholar] [CrossRef]
- Fan, C.; Zhang, Y.; Ma, H. A novel lightweight DDPM-based data augmentation method for rotating machinery fault diagnosis with small sample. Mech. Syst. Signal Process. 2025, 232, 112741. [Google Scholar] [CrossRef]
- Mao, M.; Jiang, Z.; Tan, Z. Tilting Pad Thrust Bearing Fault Diagnosis Based on Acoustic Emission Signal and Modified Multi-Feature Fusion Convolutional Neural Network. Sensors 2025, 25, 904. [Google Scholar] [CrossRef]
- Fang, Z.; Gao, S.; Dang, X. Transformer enhanced by local perception self-attention for dynamic soft sensor modeling of industrial processes. Meas. Sci. Technol. 2024, 35, 055123. [Google Scholar] [CrossRef]
- Ma, J.; Wei, J.; Li, Q. Variable-Speed Bearing Fault Diagnosis Based on BDVMD, FRTSMFrBSIE, and Parameter-Optimized GRU-MHSA. Processes 2025, 13, 498. [Google Scholar] [CrossRef]
- Lee, B.; Kim, Y.; Lee, H. Bidirectional Gated Recurrent Unit Neural Network for Fault Diagnosis and Rapid Maintenance in Medium-Voltage Direct Current Systems. Sensors 2025, 25, 693. [Google Scholar] [CrossRef]
- Bansal, K.; Tripathi, K.A. An explainable MHSA enabled deep architecture with dual-scale convolutions for methane source classification using remote sensing. Environ. Model. Softw. 2024, 181, 106178. [Google Scholar] [CrossRef]
- Zhang, B.; Wan, S.; Zhao, X. Instantaneous rotational frequency estimation and fault diagnosis for rotating machinery based on multi-component short-time Fourier transform. Measurement 2025, 253, 117565. [Google Scholar] [CrossRef]
- Sun, T.; Gao, J. New Fault Diagnosis Method for Rolling Bearings Based on Improved Residual Shrinkage Network Combined with Transfer Learning. Sensors 2024, 24, 5700. [Google Scholar] [CrossRef]
- Yu, P.; Song, Z.; Cao, J. Research on Bearing Fault Diagnosis of Wind Turbine Units Based on BNN-RA Model. Acta Energiae Solaris Sin. 2025, 46, 643–651. [Google Scholar] [CrossRef]
- Li, Q.; Zuo, D.; Feng, Y. Research on High-Performance Fourier Transform Algorithms Based on the NPU. Appl. Sci. 2024, 14, 405. [Google Scholar] [CrossRef]
- Dai, Z.; Jiang, L.; Li, F. A Multi-Scale Self-Supervision Approach for Bearing Anomaly Detection Using Sensor Data Under Multiple Operating Conditions. Sensors 2025, 25, 1185. [Google Scholar] [CrossRef]
- Kato, Y.; Otaka, M. Compressed Sensing of Vibration Signal for Fault Diagnosis of Bearings, Gears, and Propellers Under Speed Variation Conditions. Sensors 2025, 25, 3167. [Google Scholar] [CrossRef]
- Wang, J.; Dong, Z.; Zhang, S. KAN-HyperMP: An Enhanced Fault Diagnosis Model for Rolling Bearings in Noisy Environments. Sensors 2024, 24, 6448. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Name | Number of Network | Nuclear Size | Number of Nuclear | Output Size |
|---|---|---|---|---|---|
| Input Layer | Original Input Signal | input | - | - | 1024 × 10 |
| CACNN Layer | CNN1/CNN2 | 2 × Conv1d | 3 × 3 | 16 | 512 × 16 |
| MaxPool1 | MaxPool1d | 2 × 2 | 16 | 256 × 16 | |
| CNN3/CNN4 | 2 × Conv1d | 3 × 3 | 32 | 256 × 32 | |
| MaxPool2 | MaxPool1d | 2 × 2 | 32 | 128 × 32 | |
| CNN5/CNN6 | 2 × Conv1d | 3 × 3 | 64 | 128 × 64 | |
| MaxPool3 | MaxPool1d | 2 × 2 | 64 | 64 × 64 | |
| CoordAttention | Conv1d | 1 × 1 | 64 | 64 × 64 | |
| ResNet Layer | ResidualBlock1 | 2 × Conv1d | 3 × 3 | 32 | 1024 × 32 |
| ResidualBlock2 | 2 × Conv1d | 3 × 3 | 64 | 1024 × 64 | |
| ResidualBlock3 | 2 × Conv1d | 3 × 3 | 128 | 1024 × 128 | |
| T-S BiGRU layer | Time-BiGRU1 | BiGRU | - | 128 | 1024 × 256 |
| Time-BiGRU2 | BiGRU | - | 64 | 1024 × 64 | |
| Space-BiGRU1 | BiGRU | - | 128 | 64 × 256 | |
| Space-BiGRU2 | BiGRU | - | 64 | 64 × 128 | |
| SDPA layer | SDPA-Time | SDPA | - | 128 | 1024 × 128 |
| SDPA-Space | SDPA | - | 128 | 64 × 128 | |
| Output layer | Fully Connected Layer | Linear | 10 | - | 1 × 10 |
| Fault Type | Category | Fault Size (mm) | Labeling |
|---|---|---|---|
| Normal | Normal | - | 0 |
| Rolling body failure | B007 | 0.1778 | 1 |
| Rolling body failure | B014 | 0.3556 | 2 |
| Rolling body failure | B007 | 0.5334 | 3 |
| Inner ring failure | IR007 | 0.1778 | 4 |
| Inner ring failure | IR007 | 0.3556 | 5 |
| Inner ring failure | IR007 | 0.5334 | 6 |
| Outer ring failure | OR007@6 | 0.1778 | 7 |
| Outer ring failure | OR014@6 | 0.3556 | 8 |
| Outer ring failure | OR021@6 | 0.5334 | 9 |
| Model | 200 Sample | 100 Sample | 50 Sample | 10 Sample | Average |
|---|---|---|---|---|---|
| CNN | 97.927% | 93.233% | 92.010% | 84.385% | 91.889% |
| CNN-LSTM | 96.966% | 94.792% | 92.212% | 84.685% | 92.164% |
| CNN-GRU | 98.701% | 96.282% | 93.255% | 78.120% | 91.590% |
| BiGRU-Attention | 98.244% | 95.832% | 86.469% | 85.428% | 91.493% |
| Model of this paper | 100.000% | 100.000% | 100.000% | 98.966% | 99.742% |
| Rotation Speed | Category | Fault Size (mm) | Labeling |
|---|---|---|---|
| 1000 | n10002 | - | 0 |
| 600 | ib6002 | 0.25 | 1 |
| 600 | tb6002 | 0.15 | 2 |
| 600 | ob6002 | 0.25 | 3 |
| 800 | ib8002 | 0.25 | 4 |
| 800 | tb8002 | 0.15 | 5 |
| 800 | ob8002 | 0.25 | 6 |
| 1000 | ib10002 | 0.25 | 7 |
| 1000 | tb10002 | 0.15 | 8 |
| 1000 | ob10002 | 0.25 | 9 |
| Model | 200 Sample | 100 Sample | 50 Sample | 10 Sample | Average |
|---|---|---|---|---|---|
| CNN | 82.186% | 77.706% | 69.376% | 58.970% | 72.060% |
| CNN-LSTM | 84.062% | 81.874% | 62.500% | 61.390% | 72.457% |
| CNN-GRU | 89.060% | 76.664% | 63.124% | 66.410% | 73.815% |
| BiGRU-Attention | 86.252% | 84.900% | 79.372% | 64.520% | 78.761% |
| Model of this paper | 97.866% | 96.040% | 94.990% | 94.350% | 95.812% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasenjiang, J.; Zhao, Y.; Xiao, Y.; Hao, H.; Gong, Z.; Han, S. Bearing Fault Diagnosis Based on Time–Frequency Dual Domains and Feature Fusion of ResNet-CACNN-BiGRU-SDPA. Sensors 2025, 25, 3871. https://doi.org/10.3390/s25133871
Yasenjiang J, Zhao Y, Xiao Y, Hao H, Gong Z, Han S. Bearing Fault Diagnosis Based on Time–Frequency Dual Domains and Feature Fusion of ResNet-CACNN-BiGRU-SDPA. Sensors. 2025; 25(13):3871. https://doi.org/10.3390/s25133871
Chicago/Turabian StyleYasenjiang, Jarula, Yingjun Zhao, Yang Xiao, Hebo Hao, Zhichao Gong, and Shuaihua Han. 2025. "Bearing Fault Diagnosis Based on Time–Frequency Dual Domains and Feature Fusion of ResNet-CACNN-BiGRU-SDPA" Sensors 25, no. 13: 3871. https://doi.org/10.3390/s25133871
APA StyleYasenjiang, J., Zhao, Y., Xiao, Y., Hao, H., Gong, Z., & Han, S. (2025). Bearing Fault Diagnosis Based on Time–Frequency Dual Domains and Feature Fusion of ResNet-CACNN-BiGRU-SDPA. Sensors, 25(13), 3871. https://doi.org/10.3390/s25133871