

Adaptive Fusion of LiDAR Features for 3D Object Detection in Autonomous Driving




Abstract
1. Introduction
- We design a collaborative perception architecture based on a novel TS-IFF framework that hierarchically fuses intermediate features to balance perception accuracy and communication bandwidth.
- To enhance the detection of small and occluded objects, we propose a dual-branch fusion strategy that combines high-resolution pseudo-image features with contextual intermediate-level features for richer semantic representation.
- We introduce a Dynamic Weight Learning Mechanism (DWLM) to learn fusion weights for different feature types and develop an Adaptive Feature Selection Module(AFSM) to selectively aggregate the most informative components during the fusion process.
2. Related Work
2.1. 3D Object Detection
2.2. Cooperative Perception
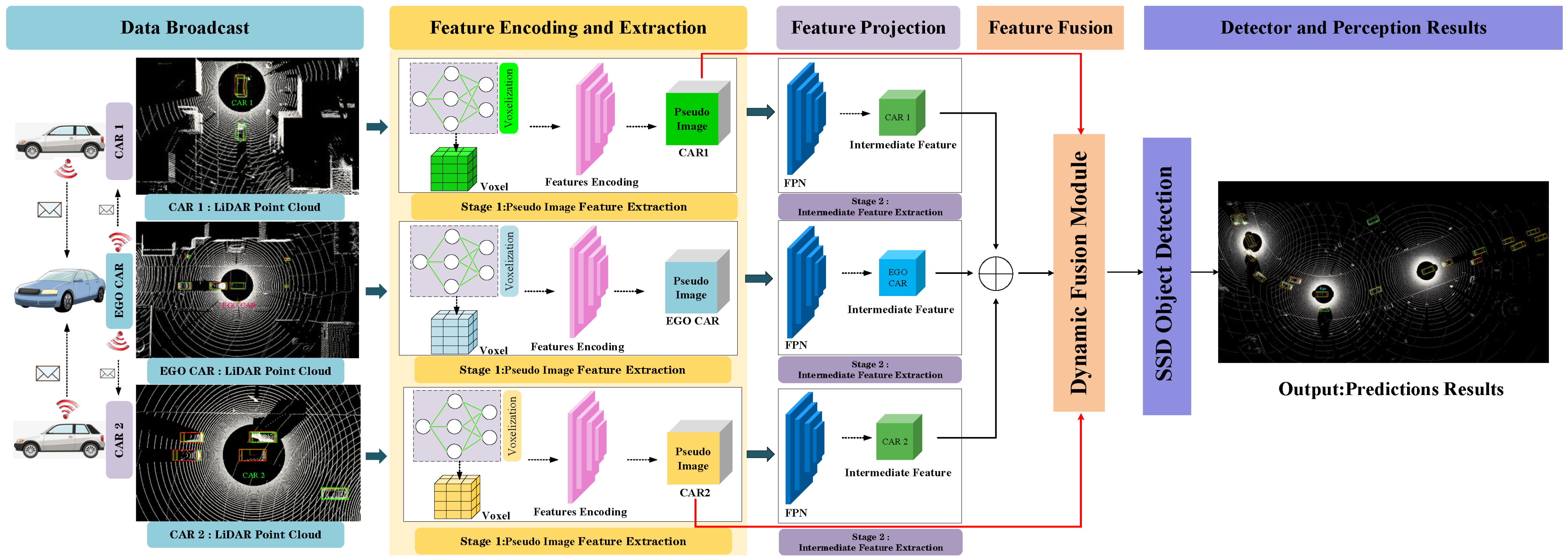
3. Overall Network Architecture
- Data Generation: Following the methodology of [38], a spatial graph is first constructed to effectively integrate the relative poses and geographic locations of each connected and autonomous vehicle (CAV), enabling reliable sharing of localization information across the network. Then, the LiDAR data from each CAV in the network is projected onto a unified reference self-coordinate plane for alignment. The aligned point cloud features are broadcast to all participating CAVs in the cooperative perception system, forming the initial stage of inter-vehicle feature interaction and preparing for the next phase of point-cloud encoding and extraction.
- Feature Encoding and Extraction: Each CAV processes the received point-cloud features using a combination of a Voxel Feature Encoding (VFE) module and a PointPillar-based feature extraction network. The VFE module generates voxelized features with different resolutions, resulting in pseudo-images. These pseudo-images from different viewpoints are handled in two ways: (1) they are broadcast to a central dynamic fusion module to be integrated with the intermediate-level features from the ego CAV, and (2) they are retained locally to enable the extraction of intermediate features by the CAV itself. This stage enables distributed local encoding and centralized fusion interactions. (Section 3.1).
- Feature Projection: A Feature Pyramid Network (FPN) [40] is used to extract intermediate features from the pseudo-images. The network follows a top-down structure, first extracting semantic features through downsampling blocks with 2D convolution, batch normalization, and ReLU activation, then processing them through upsampling and lateral connections to generate multi-scale intermediate-level features. The projected features are unified in channel dimension, concatenated, and transmitted to the feature fusion module. Through the Dynamic Weight Learning Mechanism (DWLM), local pseudo-image features are adaptively fused, enabling fine-grained feature interaction across multiple CAVs. (Section 3.2).
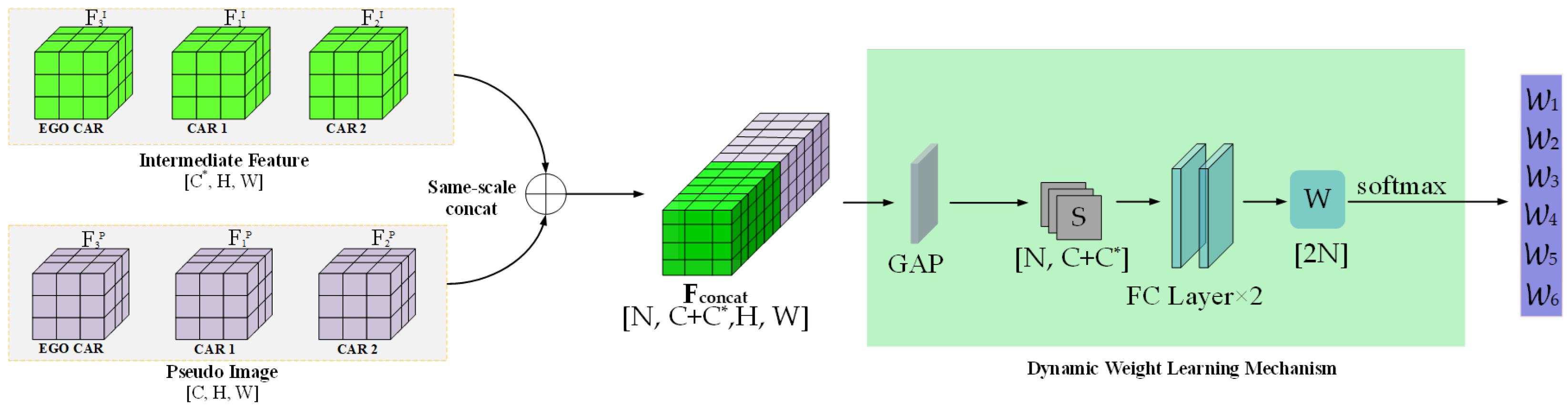
- Feature Fusion: All pseudo-images and intermediate-level features from participating CAVs are aggregated via the proposed dynamic fusion strategy. The system performs cross-agent feature integration by assigning adaptive weights to each feature channel based on its contribution. The Adaptive Feature Selection Module (AFSM) refines the joint features further to ensure that the final representation maintains discriminative cues from both local and shared contexts. (Section 3.3).
- Object Detector: Finally, a standard Single-Shot Detector (SSD) network [41] is applied to the fused intermediate features to classify 3D objects and regress their locations. The end-to-end detection result is enhanced by the preceding multi-agent collaborative encoding and fusion steps.
3.1. Feature Encoding and Extraction
3.2. Feature Fusion and Object Detection
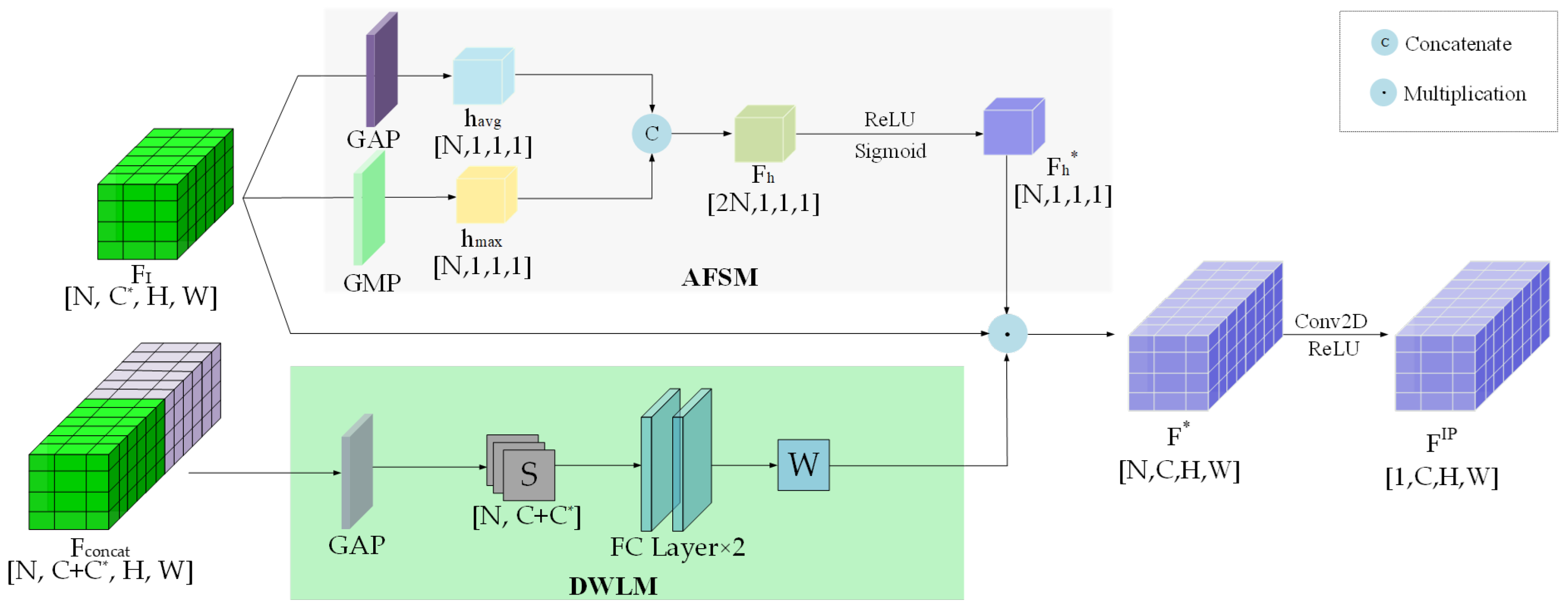
3.3. Dynamic Weight Learning Mechanism
3.4. Adaptive Feature Selection Module
| Algorithm 1: Adaptive Spatial and Channel Feature Fusion |
Input: Feature map , |
Output: Fused feature |
AFSM: Channel Attention Branch |
1. ; |
2. ; |
3. ; |
4. ; |
5. ; |
6. ; |
DWLM: Spatial Attention Branch |
7. ; |
8. ; |
9. ; |
10. ; |
11. ; |
Feature Fusion |
12. ; |
13. ; |
return ; |
3.5. Loss Function
4. Experimental Results
4.1. Datasets
4.2. Implementation Details
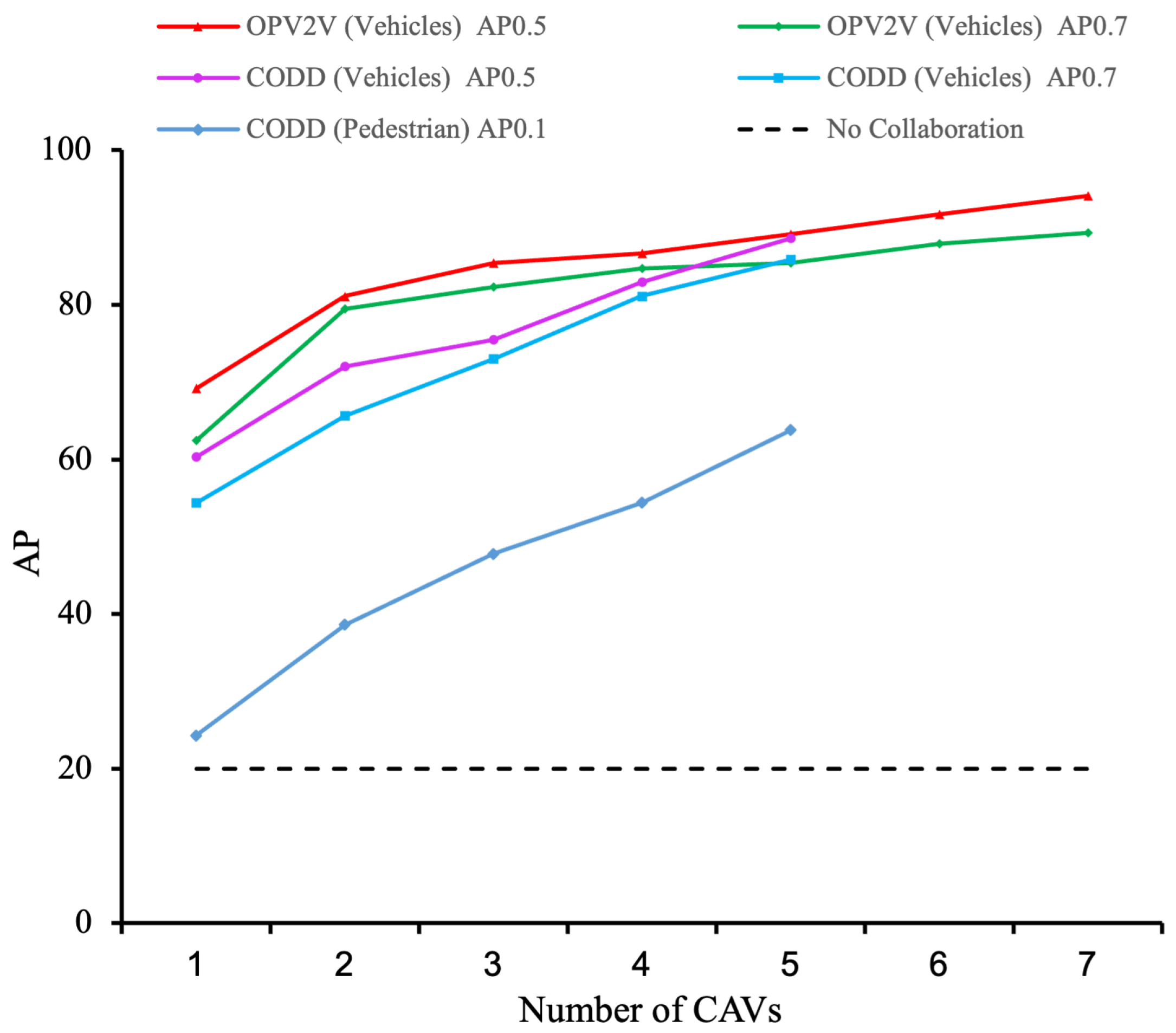
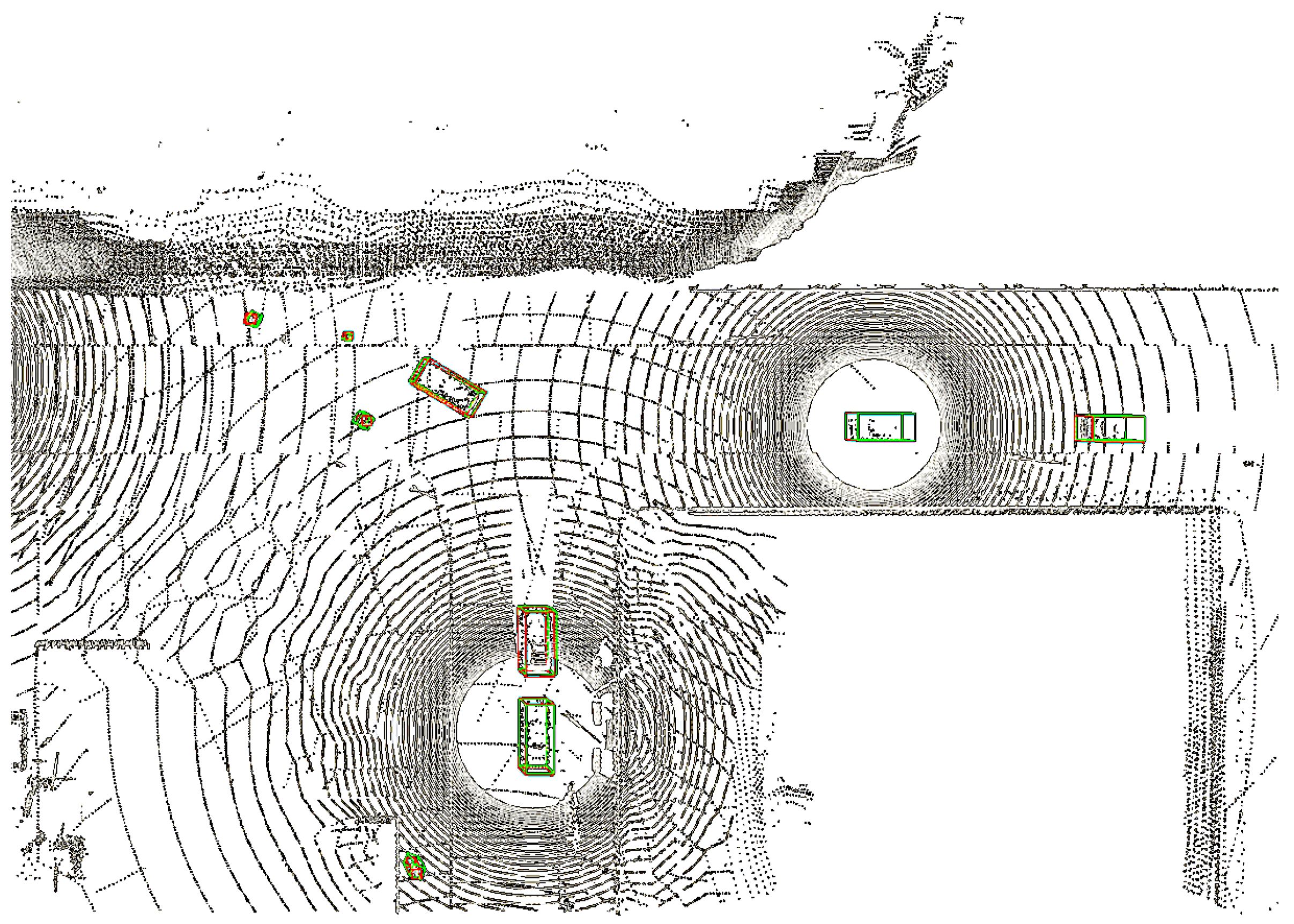
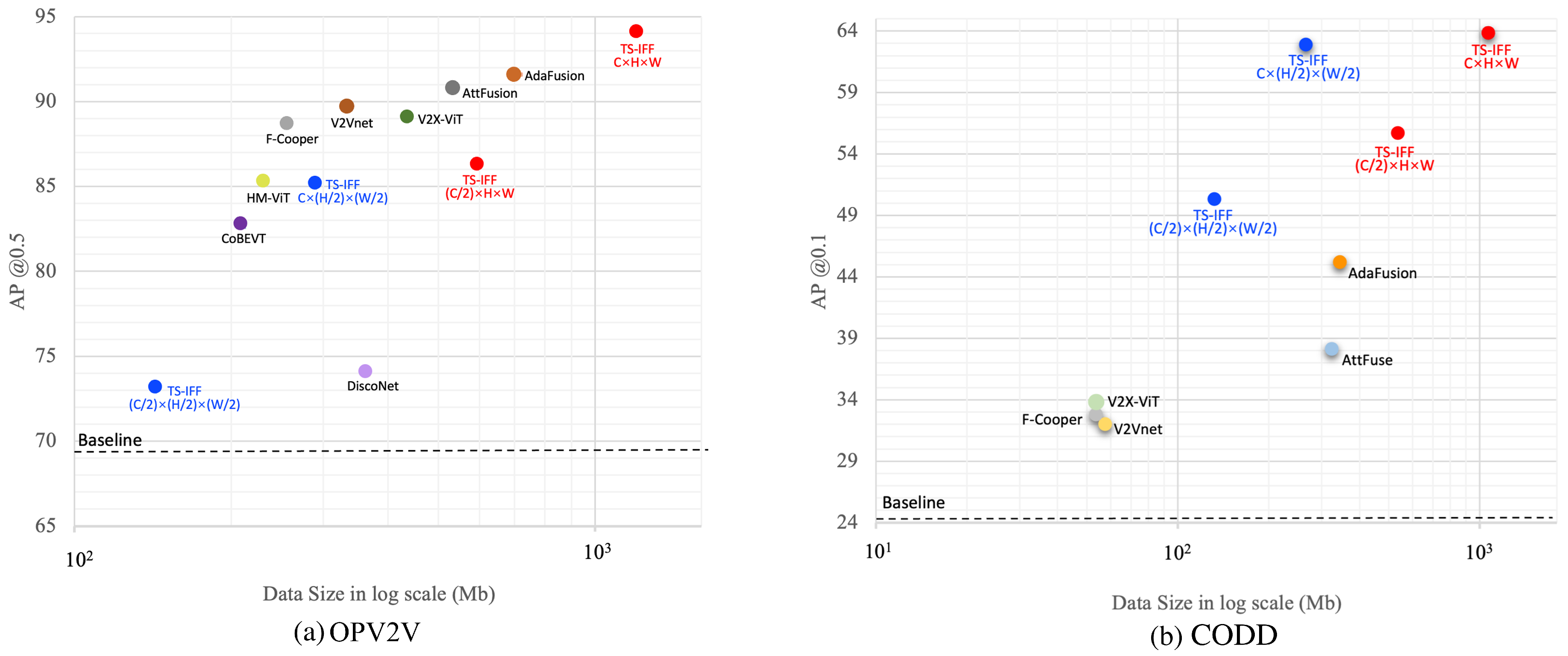
4.3. Experimental Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| V2V | Vehicle to vehicle |
| AVs | Autonomous vehicles |
| CAVs | Connected autonomous vehicles |
| TS-IFF | Two-stage intermediate-level feature fusion |
| DWLM | Dynamic weight learning mechanism |
| AFSM | Adaptive feature selection module |
| SSD | Single-shot detector |
| FPN | Feature pyramid network |
| VFE | Voxel feature encoding |
| BEV | Bird’s-eye view |
| 3D CNN | 3D convolutional neural network |
| 2D CNN | 2D convolutional neural network |
| DT | Default Towns |
| CC | Culver City |
| GT | Ground truth |
| PI | Pseudo-image |
References
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Fang, J.; Zhou, D.; Yan, F.; Zhao, T.; Zhang, F.; Ma, Y.; Wang, L.; Yang, R. Augmented LiDAR simulator for autonomous driving. IEEE Robot. Autom. Lett. 2020, 5, 1931–1938. [Google Scholar] [CrossRef]
- Caillot, A.; Ouerghi, S.; Vasseur, P.; Boutteau, R.; Dupuis, Y. Survey on cooperative perception in an automotive context. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14204–14223. [Google Scholar] [CrossRef]
- Hu, X.; Chen, T.; Zhang, W.; Ji, G.; Jia, H. MonoAMP: Adaptive multi-order perceptual aggregation for monocular 3D vehicle detection. Sensors 2025, 25, 787. [Google Scholar] [CrossRef] [PubMed]
- Coelho, D.; Oliveira, M.; Santos, V. RLAD: Reinforcement learning from pixels for autonomous driving in urban environments. IEEE Trans. Autom. Sci. Eng. 2023, 21, 7427–7435. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Cao, D.; Hang, P. Toward human-vehicle collaboration: Review and perspectives on human-centered collaborative automated driving. Transp. Res. C Emerg. Technol. 2021, 128, 103199. [Google Scholar] [CrossRef]
- Li, J.; Xu, R.; Liu, X.; Ma, J.; Chi, Z.; Ma, J.; Yu, H. Learning for vehicle-to-vehicle cooperative perception under lossy communication. IEEE Trans. Intell. Veh. 2023, 8, 2650–2660. [Google Scholar] [CrossRef]
- Du, X.; Ang, M.H.; Rus, D. Car detection for autonomous vehicle: LIDAR and vision fusion approach through deep learning framework. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 749–754. [Google Scholar]
- Wang, K.; Pu, L.; Zhang, J.; Lu, J. Gated adversarial network based environmental enhancement method for driving safety under adverse weather conditions. IEEE Trans. Intell. Veh. 2022, 8, 1934–1943. [Google Scholar] [CrossRef]
- Lahat, D.; Adali, T.; Jutten, C. Multimodal data fusion: An overview of methods, challenges, and prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef]
- Su, S.; Li, Y.; He, S.; Han, S.; Feng, C.; Ding, C.; Miao, F. Uncertainty quantification of collaborative detection for self-driving. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 5588–5594. [Google Scholar]
- Wang, B.; Zhang, L.; Wang, Z.; Zhao, Y.; Zhou, T. Core: Cooperative reconstruction for multi-agent perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 8–14 October 2023; pp. 8710–8720. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Lin, C.; Tian, D.; Duan, X.; Zhou, J.; Zhao, D.; Cao, D. V2VFormer: Vehicle-to-vehicle cooperative perception with spatial-channel transformer. IEEE Trans. Intell. Veh. 2024, 9, 3384–3395. [Google Scholar] [CrossRef]
- Fang, Q.; Wang, Z. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar]
- Yuan, Y.; Cheng, H.; Sester, M. Keypoints-based deep feature fusion for cooperative vehicle detection of autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 3054–3061. [Google Scholar] [CrossRef]
- Lei, Z.; Ren, S.; Hu, Y.; Zhang, W.; Chen, S. Latency-aware collaborative perception. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 316–332. [Google Scholar]
- Yang, Q.; Fu, S.; Wang, H.; Fang, H. Machine-learning-enabled cooperative perception for connected autonomous vehicles: Challenges and opportunities. IEEE Netw. 2021, 35, 96–101. [Google Scholar] [CrossRef]
- Chen, L.; Wang, H.; Kong, H.; Yang, W.; Ren, M. PTC-Net: Point-wise transformer with sparse convolution network for place recognition. IEEE Robot. Autom. Lett. 2023, 8, 3414–3421. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 146. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.S.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Zhou, Z.; Zhao, X.; Wang, Y.; Wang, P.; Foroosh, H. Centerformer: Center-based transformer for 3D object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 496–513. [Google Scholar]
- Barrera, A.; Beltrán, J.; Guindel, C.; Iglesias, J.A.; García, F. BirdNet+: Two-Stage 3D Object Detection in LiDAR Through a Sparsity-Invariant Bird’s Eye View. IEEE Access 2021, 9, 160299–160316. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Cai, K.; Qu, T.; Gao, B.; Chen, H. Consensus-based distributed cooperative perception for connected and automated vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8188–8208. [Google Scholar] [CrossRef]
- Chen, Q.; Ma, X.; Tang, S.; Guo, J.; Yang, Q.; Fu, S. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Bellevue, WA, USA, 28–30 October 2019; pp. 88–100. [Google Scholar]
- Guo, J.; Carrillo, D.; Tang, S.; Chen, Q.; Yang, Q.; Fu, S.; Wang, X.; Wang, N.; Palacharla, P. CoFF: Cooperative spatial feature fusion for 3-D object detection on autonomous vehicles. IEEE Internet Things J. 2021, 8, 11078–11087. [Google Scholar] [CrossRef]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.-H.; Ma, J. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 107–124. [Google Scholar]
- Xu, R.; Tu, Z.; Xiang, H.; Shao, W.; Zhou, B.; Ma, J. CoBEVT: Cooperative Bird’s Eye View Semantic Segmentation with Sparse Transformers. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 11–14 December 2023; pp. 989–1000. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2583–2589. [Google Scholar]
- Qiao, D.; Zulkernine, F. Adaptive feature fusion for cooperative perception using lidar point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2023; pp. 1186–1195. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xu, R.; Xia, X.; Li, J.; Li, H.; Zhang, S.; Tu, Z.; Meng, Z.; Xiang, H.; Dong, X.; Song, R.; et al. V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 20–25 October 2023; pp. 13712–13722. [Google Scholar]
- Arnold, E.; Mozaffari, S.; Dianati, M. Fast and robust registration of partially overlapping point clouds. IEEE Robot. Autom. Lett. 2021, 7, 1502–1509. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Wang, T.-H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 605–621. [Google Scholar]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. Adv. Neural Inf. Process. Syst. 2021, 34, 29541–29552. [Google Scholar]
- Xiang, H.; Xu, R.; Ma, J. HM-ViT: Hetero-modal vehicle-to-vehicle cooperative perception with vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 20–25 October 2023; pp. 284–295. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OPV2V | CODD | Para (M) Total (↓) | |||||
|---|---|---|---|---|---|---|---|---|
| DT | CC | Vehicle | Pedestrian | |||||
| AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 (↑) | AP@0.5 | AP@0.7 | AP@0.1 (↑) | ||
| Baseline | 69.2 | 62.4 | 55.3 | 47.6 | 60.3 | 54.4 | 24.3 | 6.58 |
| F-Cooper [33] | 88.7 | 79.0 | 84.6 | 72.8 | 77.6 | 74.3 | 32.8 | 7.27 |
| V2VNet [47] | 89.7 | 82.2 | 86.0 | 73.4 | 80.3 | 75.8 | 32.0 | 14.61 |
| AttFuse [38] | 90.8 | 81.5 | 85.4 | 73.5 | 81.4 | 77.7 | 38.1 | 6.58 |
| DiscoNet [48] | 74.1 | 59.0 | – | – | – | – | – | 9.66 |
| CoBEVT [36] | 82.8 | 63.7 | – | – | – | – | – | 8.35 |
| V2X-ViT [35] | 89.1 | 82.6 | 87.3 | 73.7 | 82.3 | 78.9 | 33.8 | 13.45 |
| HM-ViT [49] | 85.3 | 76.3 | – | – | – | – | – | 17.64 |
| AdaFusion [39] | 91.6 | 85.6 | 88.1 | 79.0 | 86.2 | 83.9 | 45.2 | 7.27 |
| Ours | 94.1 (+2.7%) | 89.3 (+4.1%) | 90.3 (+2.4%) | 82.1 (+3.8%) | 88.6 (+2.7%) | 85.8 (+2.2%) | 63.8 (+29.2%) | 8.16 (+10.9%) |
| Method | V2V4Real | |
|---|---|---|
| AP@0.5 | AP@0.7 | |
| Baseline | 39.8 | 22.0 |
| F-Cooper | 60.7 | 31.8 |
| V2Vnet | 64.5 | 34.3 |
| AttFuse | 64.7 | 33.6 |
| V2X-ViT | 64.9 | 36.9 |
| CoBEVT | 66.5 | 36.0 |
| Ours | 68.2 (+2.5%) | 40.1 (+8.0%) |
| Model | AFSM | DWLM | OPV2V (AP@0.5↑) | CODD (AP@0.1↑) | Para. (M) | Ave Infer. Time (ms/Frame) |
|---|---|---|---|---|---|---|
| Baseline | × | × | 69.8 | 24.7 | 6.58 | 15.63 |
| × | ✓ | 70.2 | 26.6 | 7.03 | 26.18 | |
| TS-IFF | ✓ | × | 72.1 | 27.8 | 7.27 | 27.33 |
| ✓ | ✓ | 76.7 | 30.3 | 8.16 | 29.60 |
| Model | PI (C × H × W) | OPV2V (AP@0.5↑) | CODD (AP@0.1↑) |
|---|---|---|---|
| Baseline | – | 76.7 | 30.3 |
| TS-IFF | 85.2 | 62.9 | |
| 73.2 | 50.3 | ||
| 94.1 | 65.9 | ||
| 86.3 | 55.7 | ||
| 90.7 | 69.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Li, D.; Casas, J.R.; Ruiz-Hidalgo, J. Adaptive Fusion of LiDAR Features for 3D Object Detection in Autonomous Driving. Sensors 2025, 25, 3865. https://doi.org/10.3390/s25133865
Wang M, Li D, Casas JR, Ruiz-Hidalgo J. Adaptive Fusion of LiDAR Features for 3D Object Detection in Autonomous Driving. Sensors. 2025; 25(13):3865. https://doi.org/10.3390/s25133865
Chicago/Turabian StyleWang, Mingrui, Dongjie Li, Josep R. Casas, and Javier Ruiz-Hidalgo. 2025. "Adaptive Fusion of LiDAR Features for 3D Object Detection in Autonomous Driving" Sensors 25, no. 13: 3865. https://doi.org/10.3390/s25133865
APA StyleWang, M., Li, D., Casas, J. R., & Ruiz-Hidalgo, J. (2025). Adaptive Fusion of LiDAR Features for 3D Object Detection in Autonomous Driving. Sensors, 25(13), 3865. https://doi.org/10.3390/s25133865