
RGB-FIR Multimodal Pedestrian Detection with Cross-Modality Context Attentional Model

 , , , ,
, , , ,
Abstract
1. Introduction
- (1)
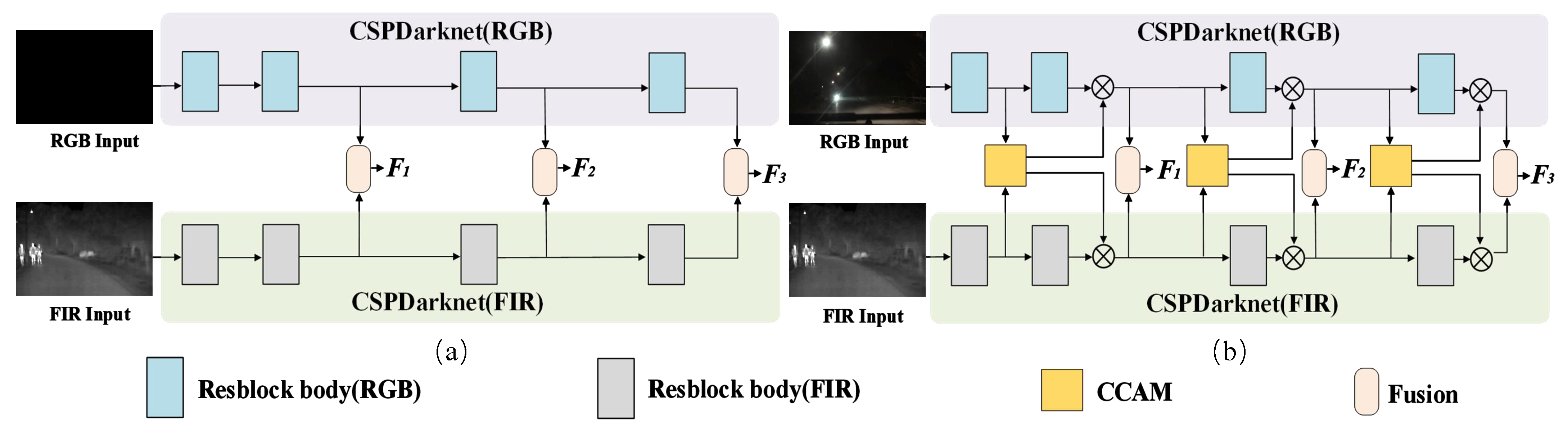
- We propose an RGB-FIR multimodal YOLO backbone network framework based on a multi-level fusion strategy, as shown in Figure 1d, consisting of an RGB-FIR parallel backbone network, a cross-modality contextual attention model, and a multimodal feature fusion module.
- (2)
- A CCAM model is designed for the front end of the RGB-FIR parallel backbone network to achieve cross-modality and cross-scale complementarity between adjacent scale features.
- (3)
- With comparative experimental results, we analyze the performance of feature fusion strategies at different positions of the RGB-FIR parallel backbone network for the multimodal pedestrian detection models.
2. Related Work
2.1. Pedestrian Detection Model Based on RGB Images
2.2. RGB-FIR Multimodal Pedestrian Detection Model
3. Proposed Method
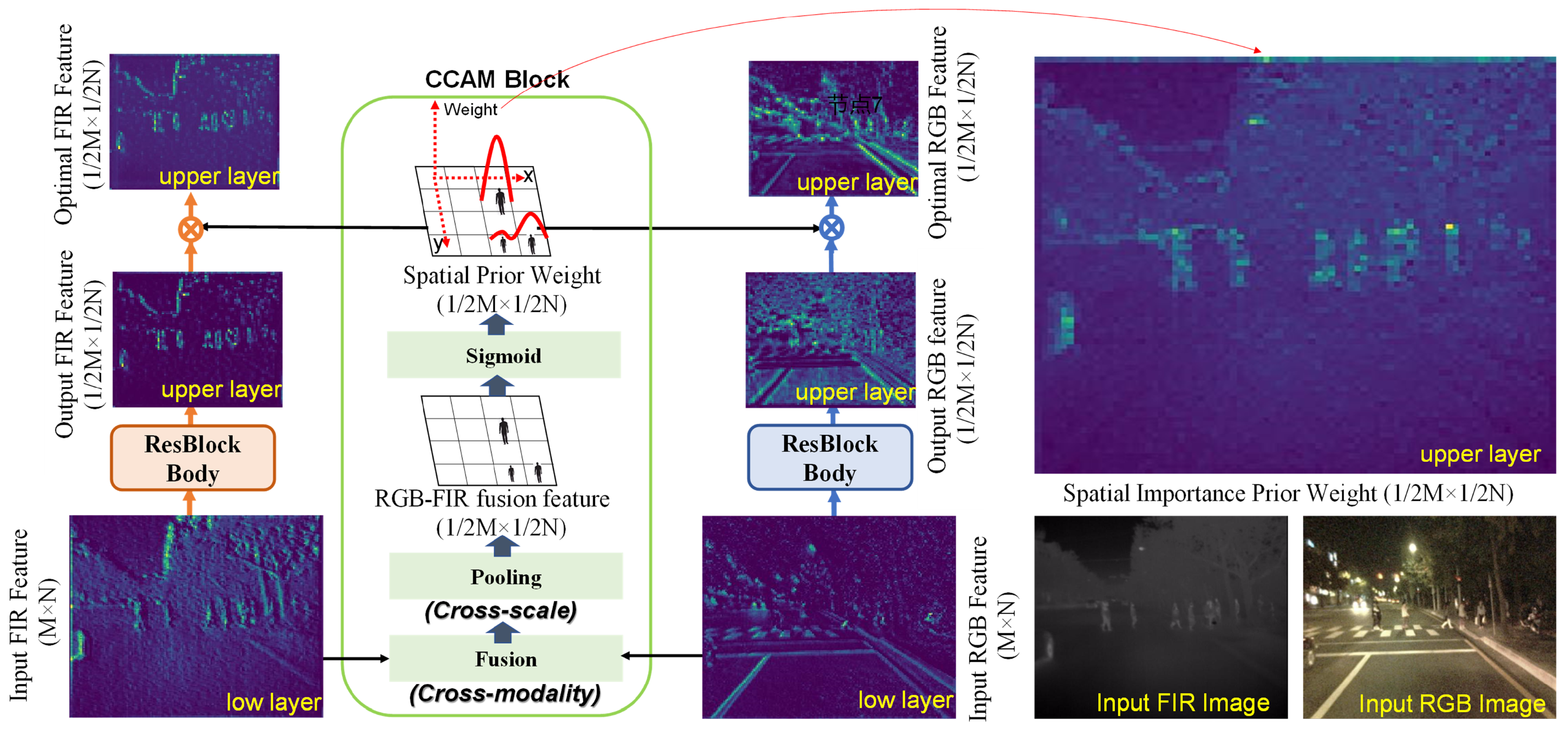
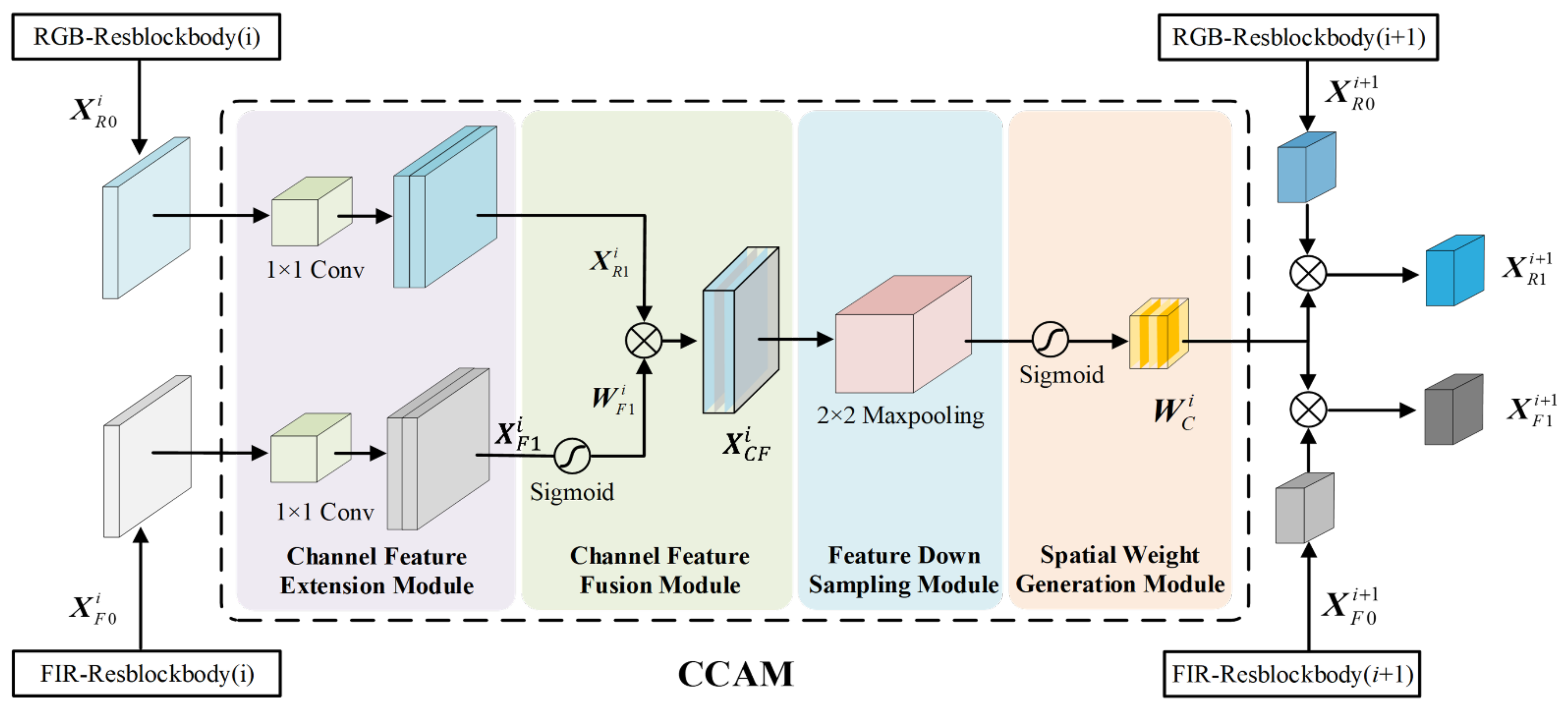
3.1. Cross-Modality Context Attentional Model (CCAM)
- (1)
- Channel feature extension module: The CFE module is shown in the purple section of Figure 3. The CFE module is used to expand the number of feature channels of the i-th Resblockbody to be the same as the number of feature channels of the i + 1th Resblockbody. Let the output features of the i-th Resblockbody in the RGB and FIR branch be and , respectively, where c, h, and w are the number of feature channels, height, and width of the feature, respectively. The 2D convolution operator doubles the number of channels for and , obtaining the expanded feature and ,
- (2)
- Channel feature fusion module: The CFF module is shown in the green section of Figure 3. The CFF module is used to generate channel fusion features. The specific process is as follows: we use the sigmoid function to generate weight values FIR features , and use these weight values to multiply with RGB features to generate channel fusion features ,where is the spatial importance weight matrix of channel j, is the fusion feature matrix of channel j, and ∘ denotes the Hadamard product.
- (3)
- Feature down-sampling module: The FDS module is shown in the blue section of Figure 3. The FDS module is used to generate the same spatial resolution as the i+1th Resblockbody feature. The specific process is as follows: A maximum pooling operator for channel fused feature performs local maximum pooling to output feature map , reduced to half the resolution of the feature map to obtain features with the same resolution as the output feature of the i+1th Resblockbody,where is the down-sampled fusion feature map of channel j.
- (4)
- Spatial weight generation module: The SWG module is shown in the skin section of Figure 3. The SWG module generates spatial importance weight values for the RGB and FIR channel features of the i+1th Resblockbody. The specific process is as follows: A sigmoid function is applied to normalize down-sampled fusion feature map to generate a feature space importance weight matrix , where
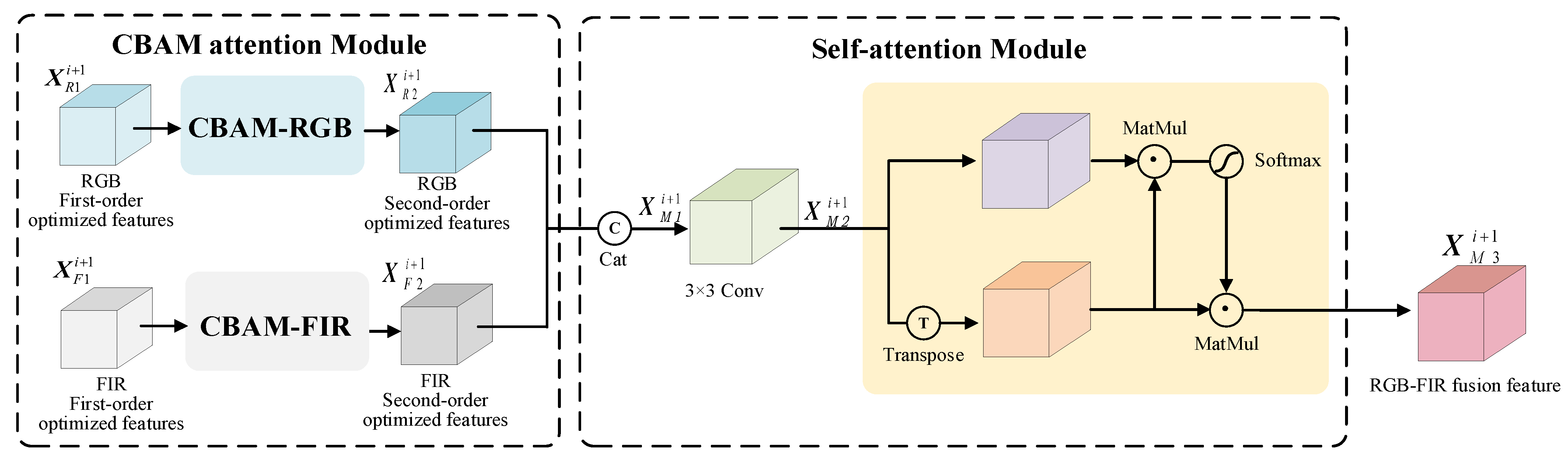
3.2. RGB-FIR Multimodal Feature Fusion Module
3.3. Multimodal Pedestrian Detection Model YOLO-CCAM
4. Experiment and Analysis
4.1. Experimental Setup
4.2. Baseline Model Comparison
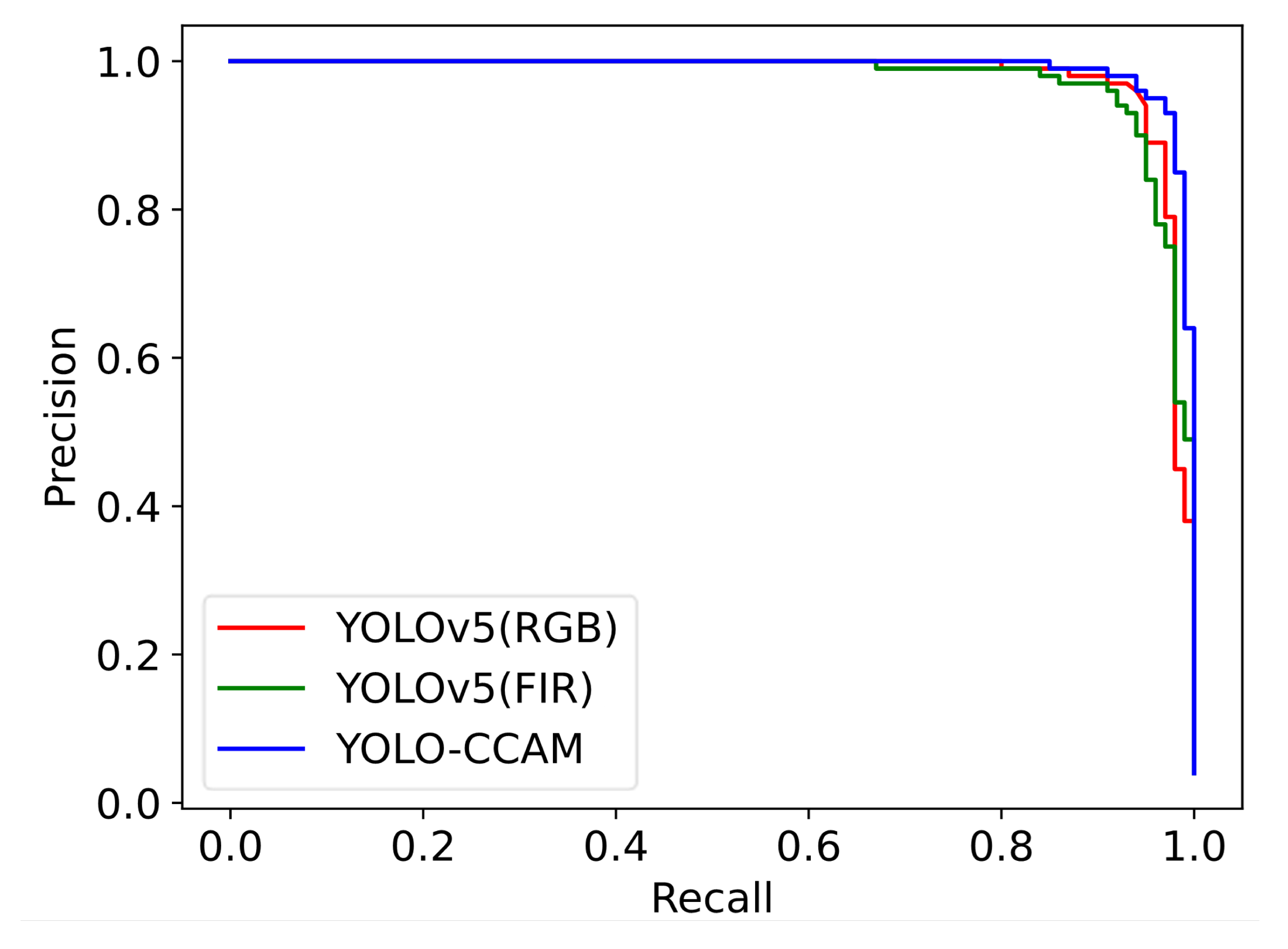
4.3. Effectiveness of the CCAM Module
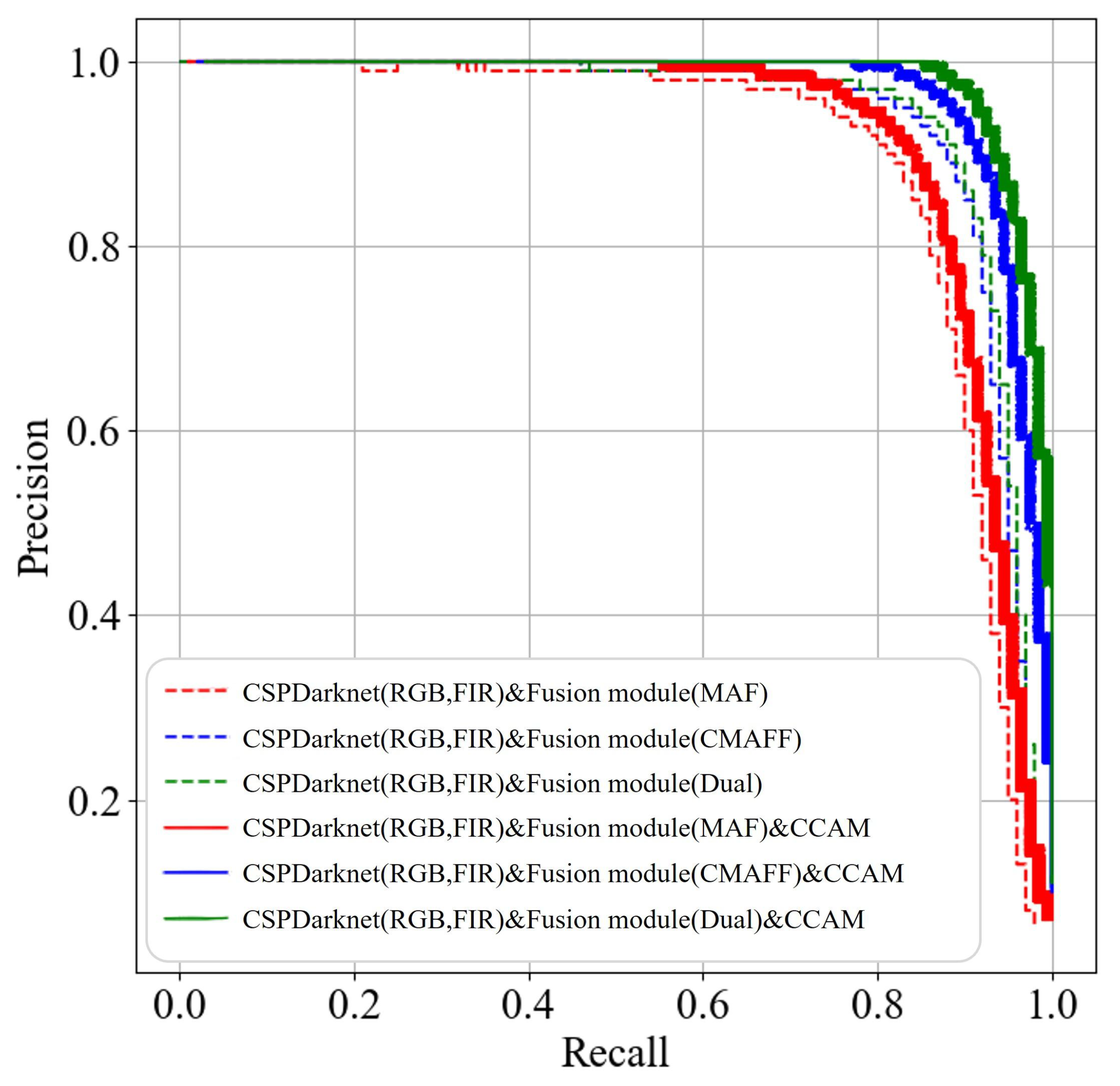
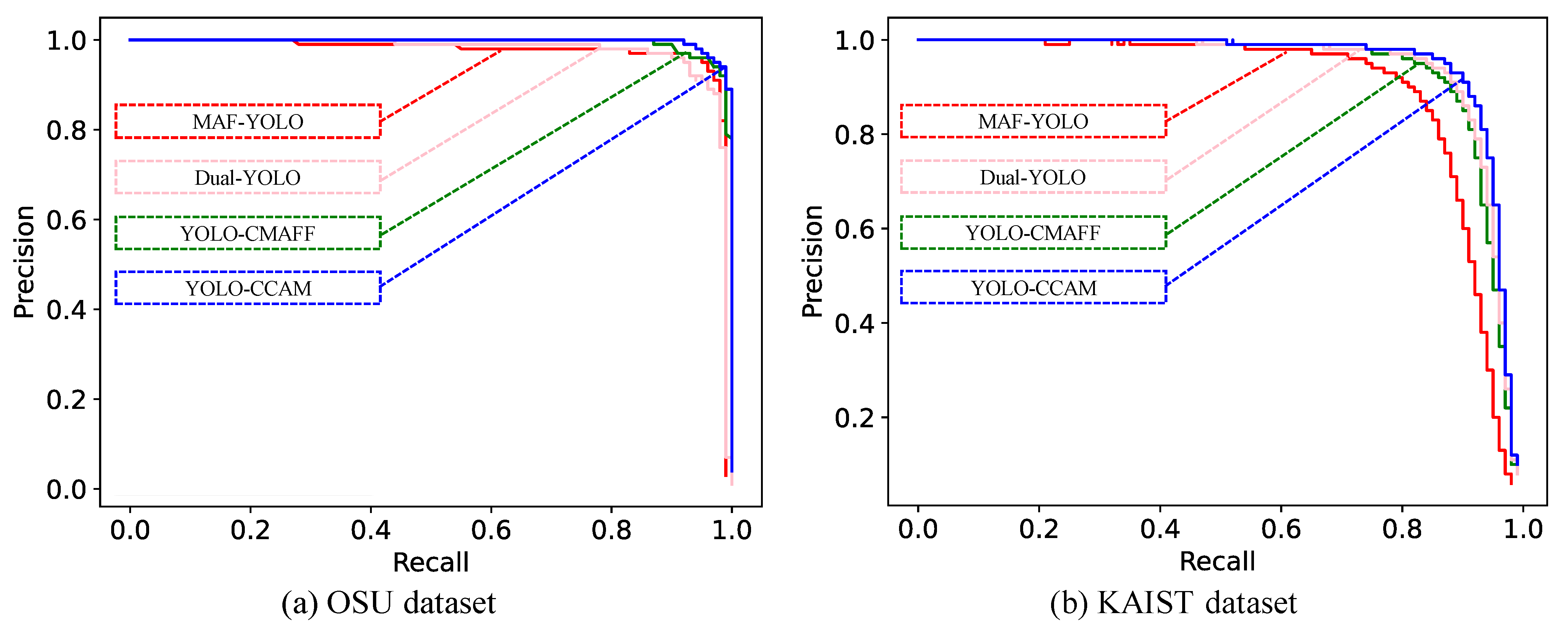
4.4. Comparison with Other Multimodal Models
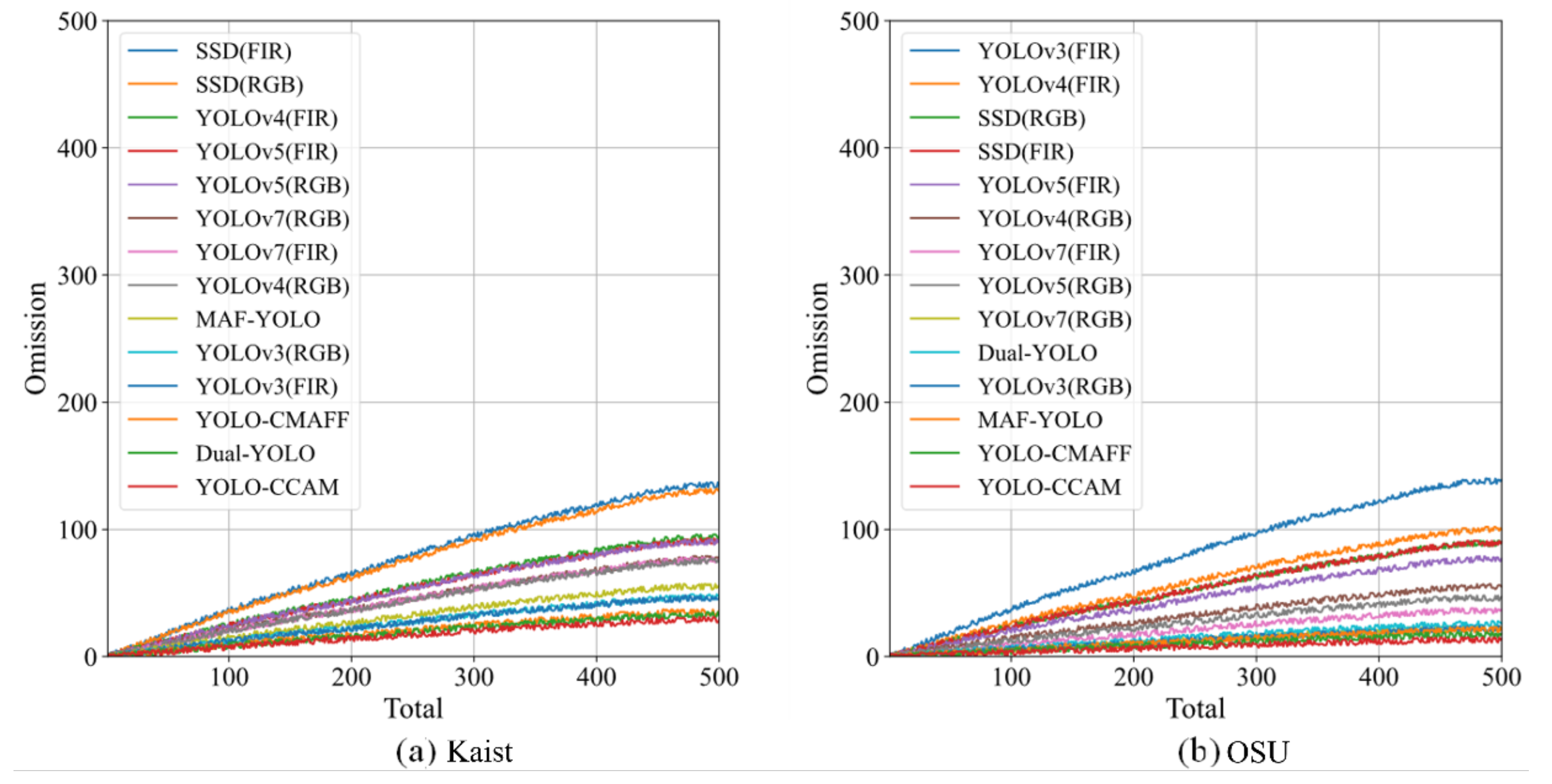
4.5. Real-World Pedestrian Detection Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Du, H.; Ren, L.; Wang, Y.; Cao, X.; Sun, C. Advancements in perception system with multi-sensor fusion for embodied agents. Inf. Fusion 2025, 117, 102859. [Google Scholar] [CrossRef]
- Kabir, M.M.; Jim, J.R.; Istenes, Z. Terrain detection and segmentation for autonomous vehicle navigation: A state-of-the-art systematic review. Inf. Fusion 2025, 113, 102644. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.Y. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Jain, D.K.; Zhao, X.; González-Almagro, G.; Gan, C.; Kotecha, K. Multimodal pedestrian detection using metaheuristics with deep convolutional neural network in crowded scenes. Inf. Fusion 2023, 95, 401–414. [Google Scholar] [CrossRef]
- Li, J.; Bi, Y.; Wang, S.; Li, Q. CFRLA-Net: A Context-Aware Feature Representation Learning Anchor-Free Network for Pedestrian Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4948–4961. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, F.; Tang, S.; Zhao, R.; He, L.; Song, J. Feature Erasing and Diffusion Network for Occluded Person Re-Identification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 4744–4753. [Google Scholar] [CrossRef]
- Cao, Y.; Luo, X.; Yang, J.; Cao, Y.; Yang, M.Y. Locality guided cross-modal feature aggregation and pixel-level fusion for multispectral pedestrian detection. Inf. Fusion 2022, 88, 1–11. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Feng, T.T.; Ge, H.Y. Pedestrian detection based on attention mechanism and feature enhancement with SSD. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing (CCISP), Chongqing, China, 23–25 October 2020; pp. 145–148. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–24 June 2022; pp. 2636–2645. [Google Scholar]
- Hsu, W.Y.; Lin, W.Y. Ratio-and-Scale-Aware YOLO for Pedestrian Detection. IEEE Trans. Image Process. 2021, 30, 934–947. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-Time Intelligent Object Detection System Based on Edge-Cloud Cooperation in Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Goswami, S.; Singh, S.K. An image information fusion based simple diffusion network leveraging the segment anything model for guided attention on thermal images producing colorized pedestrian masks. Inf. Fusion 2025, 113, 102618. [Google Scholar] [CrossRef]
- Yuan, M.; Shi, X.; Wang, N.; Wang, Y.; Wei, X. Improving RGB-infrared object detection with cascade alignment-guided transformer. Inf. Fusion 2024, 105, 102246. [Google Scholar] [CrossRef]
- Kim, J.U.; Park, S.; Ro, Y.M. Uncertainty-Guided Cross-Modal Learning for Robust Multispectral Pedestrian Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1510–1523. [Google Scholar] [CrossRef]
- Liu, T.; Lam, K.M.; Zhao, R.; Qiu, G. Deep Cross-Modal Representation Learning and Distillation for Illumination-Invariant Pedestrian Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 315–329. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wu, Y.; Xu, J.; Zhang, X. UNFusion: A Unified Multi-Scale Densely Connected Network for Infrared and Visible Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3360–3374. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, QC, Canada, 11 October 2021; pp. 2778–2788. [Google Scholar]
- Qingyun, F.; Zhaokui, W. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar] [CrossRef]
- Bao, C.; Cao, J.; Hao, Q.; Cheng, Y.; Ning, Y.; Zhao, T. Dual-YOLO Architecture from Infrared and Visible Images for Object Detection. Sensors 2023, 23, 2934. [Google Scholar] [CrossRef]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar] [CrossRef]
- Fu, L.; Gu, W.B.; Ai, Y.B.; Li, W.; Wang, D. Adaptive spatial pixel-level feature fusion network for multispectral pedestrian detection. Infrared Phys. Technol. 2021, 116, 103770. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, USA, 18–19 June 2023; pp. 7464–7475. [Google Scholar]
- Papageorgiou, C.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Mumbai, India, 4–7 January 1998; pp. 555–562. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Watanabe, T.; Ito, S.; Yokoi, K. Co-occurrence Histograms of Oriented Gradients for Pedestrian Detection. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology(PSIVT), Tokyo, Japan, 13–16 January 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 37–47. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Ten Years of Pedestrian Detection, What Have We Learned? In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–12 September 2015; pp. 613–627. [Google Scholar]
- Brazil, G.; Liu, X. Pedestrian Detection With Autoregressive Network Phases. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7224–7233. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2872–2893. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 27 June–2 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. DSOD: Learning Deeply Supervised Object Detectors from Scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Yuan, J.; Barmpoutis, P.; Stathaki, T. Effectiveness of vision transformer for fast and accurate single-stage pedestrian detection. Adv. Neural Inf. Process. Syst. 2022, 35, 27427–27440. [Google Scholar]
- Wu, T.; Li, X.; Dong, Q. An Improved Transformer-Based Model for Urban Pedestrian Detection. Int. J. Comput. Intell. Syst. 2025, 18, 68. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning Cross-Modal Deep Representations for Robust Pedestrian Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4236–4244. [Google Scholar]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-modality interactive attention network for multispectral pedestrian detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems. In Proceedings of the Computer Vision–ECCV 2020, Virtually, 23–28 August 2020; pp. 787–803. [Google Scholar]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unifying Convolution and Self-Attention for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.W.; Sharma, V. Background-subtraction using contour-based fusion of thermal and visible imagery. Comput. Vis. Image Underst. 2007, 106, 162–182. [Google Scholar] [CrossRef]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF international conference on computer vision, Virtually, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone Network Type | mAP0.5 | mAP0.75 | mAP |
|---|---|---|---|
| CSPDarknet (RGB, FIR) and Fusion [19] | 91.30% | 55.10% | 51.90% |
| CSPDarknet (RGB, FIR) and Fusion [19] and CCAM | 93.80% | 58.30% | 55.40% |
| CSPDarknet (RGB, FIR) and Fusion [20] | 92.70% | 57.10% | 54.20% |
| CSPDarknet (RGB, FIR) and Fusion [20] and CCAM | 94.90% | 59.80% | 57.20% |
| CSPDarknet (RGB, FIR) and Fusion [21] | 88.30% | 46.00% | 46.00% |
| CSPDarknet (RGB, FIR) and Fusion [21] and CCAM | 92.40% | 56.60% | 53.30% |
| Model | mAP0.5 | mAP0.75 | mAP |
|---|---|---|---|
| 96.40% | 58.40% | 52.40% | |
| 97.10% | 59.20% | 55.80% | |
| 97.20% | 61.00% | 56.90% |
| Mono-modality pedestrian detection models | |||||||||
| Model | OSU | KAIST | ALL | ||||||
| mAP0.5 | mAP0.75 | mAP | mAP0.5 | mAP0.75 | mAP | Time | FPS | Para | |
| SSD (RGB) [39] | 82.00% | 60.50% | 51.90% | 73.90% | 55.60% | 48.60% | 67.3 | 14.9 | 23.8 |
| SSD (FIR) [39] | 82.00% | 63.90% | 52.80% | 72.90% | 54.30% | 48.00% | |||
| YOLOv3 (RGB) [23] | 95.50% | 63.00% | 55.60% | 90.50% | 55.90% | 52.60% | 18.6 | 55.5 | 61.5 |
| YOLOv3 (FIR) [23] | 72.20% | 23.80% | 33.20% | 90.70% | 54.10% | 52.50% | |||
| YOLOv4 (RGB) [24] | 88.90% | 42.80% | 46.70% | 84.90% | 57.90% | 52.40% | 22.7 | 46.1 | 63.9 |
| YOLOv4 (FIR) [24] | 79.90% | 38.20% | 41.20% | 81.10% | 38.70% | 42.50% | |||
| YOLOv5 (RGB) [18] | 90.60% | 63.80% | 56% | 81.80% | 59.50% | 52.30% | 11.5 | 90.4 | 7.1 |
| YOLOv5 (FIR) [18] | 84.50% | 56.90% | 50.30% | 81.70% | 58.60% | 52.30% | |||
| YOLOv7 (RGB) [25] | 95.40% | 65.80% | 55.90% | 84.50% | 58.80% | 53.10% | 17.3 | 57.8 | 37.2 |
| YOLOv7 (FIR) [25] | 92.60% | 63.10% | 55.20% | 84.60% | 59.00% | 53.40% | |||
| Multi-modality pedestrian detection models | |||||||||
| Model | OSU | KAIST | ALL | ||||||
| mAP0.5 | mAP0.75 | mAP | mAP0.5 | mAP0.75 | mAP | Time | FPS | Para | |
| MAF-YOLO [21] | 95.70% | 48.20% | 51.10% | 88.80% | 46.40% | 47.80% | 48.4 | 20.9 | 32.6 |
| YOLO-CMAFF [19] | 96.40% | 56.10% | 54.80% | 92.80% | 55.90% | 53.90% | 21.7 | 48.1 | 13 |
| Dual-YOLO [20] | 94.70% | 53.70% | 53.70% | 93.30% | 57.80% | 54.80% | 25.1 | 40.4 | 19.6 |
| YOLO-CCAM | 97.20% | 61.00% | 56.90% | 94.10% | 60.80% | 56.50% | 23.8 | 42.7 | 21.2 |
| Model | mAP0.5 | mAP0.75 | mAP |
| YOLOv9 (RGB) | 90.60% | 56.20% | 52.40% |
| YOLOv9 (FIR) | 96.40% | 74.70% | 65.60% |
| YOLOv11 (RGB) | 88.40% | 50.00% | 49.20% |
| YOLOv11 (FIR) | 96.30% | 73.60% | 64.60% |
| YOLOv12 (RGB) | 89.00% | 50.30% | 49.50% |
| YOLOv12 (FIR) | 96.00% | 73.90% | 64.50% |
| YOLO-CCAM | 96.70% | 73.20% | 64.90% |
| YOLOv9-CCAM | 97.10% | 75.10% | 65.80% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Jin, L.; Wang, G.; Liu, W.; Shi, Q.; Hou, Y.; Liu, J. RGB-FIR Multimodal Pedestrian Detection with Cross-Modality Context Attentional Model. Sensors 2025, 25, 3854. https://doi.org/10.3390/s25133854
Wang H, Jin L, Wang G, Liu W, Shi Q, Hou Y, Liu J. RGB-FIR Multimodal Pedestrian Detection with Cross-Modality Context Attentional Model. Sensors. 2025; 25(13):3854. https://doi.org/10.3390/s25133854
Chicago/Turabian StyleWang, Han, Lei Jin, Guangcheng Wang, Wenjie Liu, Quan Shi, Yingyan Hou, and Jiali Liu. 2025. "RGB-FIR Multimodal Pedestrian Detection with Cross-Modality Context Attentional Model" Sensors 25, no. 13: 3854. https://doi.org/10.3390/s25133854
APA StyleWang, H., Jin, L., Wang, G., Liu, W., Shi, Q., Hou, Y., & Liu, J. (2025). RGB-FIR Multimodal Pedestrian Detection with Cross-Modality Context Attentional Model. Sensors, 25(13), 3854. https://doi.org/10.3390/s25133854