1. Introduction
Surface water resources are crucial water resources on Earth, supporting indispensable functions related to human production, daily life, and the material and energy cycles [
1,
2,
3,
4,
5]. Satellite remote sensing technology has been widely applied in surface water detection because of its advantages of a fast monitoring speed, strong timeliness, and ability to obtain large-scale repetitive observations. Compared with optical remote sensing, synthetic aperture radar (SAR), as an active microwave system, can penetrate clouds, rain, and fog and is unaffected by lighting conditions, enabling all-weather, day–night target sensing. SAR systems can obtain information about objects by actively emitting radar wave signals and receiving backscattered echo signals from the Earth’s surface. When the radar signal emitted by a SAR system encounters a water surface, it typically exhibits specular reflection, with only a small portion of the signal returning to the receiving system. In contrast, rough surface objects return stronger backscattered signals via mechanisms such as diffuse reflection, secondary scattering, or volume scattering. Therefore, by utilizing the differences in backscatter values between water and non-water objects in SAR images, it is possible to distinguish water bodies effectively. This characteristic makes SAR an invaluable tool for water extraction, with enormous potential [
6].
There are two main types of methods for extracting water from SAR images: traditional methods and deep learning methods [
4]. Traditional methods primarily include thresholding [
7,
8,
9], clustering analysis [
10,
11,
12,
13,
14], Markov random field (MRF) [
15], and machine learning approaches [
16]. However, these methods are often influenced by the heterogeneity of the observation environment and the inherent speckle noise in SAR images [
17], making it difficult to meet the current demand for rapid, large-scale surface water extraction. Machine learning methods, represented by support vector machines (SVMs) and random forests (RFs) [
18,
19], can learn the differences in the patterns of water and non-water bodies across multiple feature dimensions through training datasets, thus improving the water extraction accuracy to some extent. However, most of the features in these methods rely on manual design, and their feature representation capabilities are limited, making it difficult to ensure that they can fully capture the distinctions between water bodies and other land features. In contrast, deep learning techniques possess powerful feature learning capabilities and do not require manual feature design [
20], providing a new approach for water extraction from SAR images.
Over the past few decades, deep learning has undergone rapid advancements and has been extensively applied in various SAR remote sensing tasks, such as image classification [
21,
22,
23,
24], change detection [
25,
26], and target recognition [
27,
28,
29,
30,
31]. In 2015, Jonathan Long proposed fully convolutional networks (FCNs) [
32], which replaced the fully connected layers of traditional CNNs with convolutional layers, marking the first application of deep learning in the field of semantic segmentation. Kang et al. used a FCN for flood monitoring and mapping with Gaofen-3 SAR imagery [
33], but the FCN model failed to adequately consider the global spatial relationships among pixels [
34], resulting in poor fine-scale segmentation. Ronneberger et al. enhanced the architecture of FCNs by increasing the number of decoders and incorporating skip connections to link decoder and encoder features, leading to the development of a U-Net network with an encoder–decoder structure [
35]. Wang et al. compared the water extraction accuracies of three methods—the Otsu method, the object-oriented method, and U-Net—using Sentinel-1 SAR imagery and demonstrated the advantages of the U-Net model for water extraction [
36]. However, owing to the similar backscattering characteristics of water bodies and land features, such as mountain shadows in SAR images [
25], there can be confusion between the two during water extraction, especially in mountainous regions. Although the U-Net approach has improved water extraction compared with traditional methods, it still struggles to effectively address issues such as confusion between water bodies and shadows, and the accurate extraction of complex boundary details for continuous water bodies may be limited.
Owing to its robust generalization capabilities supported by the U-shaped encoder–decoder architecture, U-Net has emerged as one of the predominant networks for semantic segmentation and water body extraction from SAR images [
5]. Researchers have proposed numerous enhanced network models that are based on the U-Net framework. For example, H. Song et al. proposed an improved U-Net network based on a hybrid attention mechanism (HA-UNet) for urban water extraction [
37]. By conducting experiments with Sentinel-1A SAR images, they demonstrated that the proposed method significantly improved the accuracy of water body extraction in urban areas. Chuan Xu et al. developed a flood detection method for SAR images by integrating attention U-Net with a multiscale level set method and applied it for the dynamic monitoring of flood disasters in Jiangxi, Anhui, and Chongqing in 2020 [
38]. However, this method still faces challenges in terms of water extraction in mountainous areas. Wang introduced dilated convolution and the spatial channel squeeze and excitation (SCSE) attention mechanism to U-Net [
39], proposing a floodwater extraction network (FWENet) based on SAR images [
40]. This model improved the extraction of small water bodies and water body boundaries, but the distinction between water bodies and shadows remained suboptimal. However, existing studies that utilize deep learning for SAR image-based water extraction rely primarily on convolutional kernels as the core for feature extraction. Convolution kernels are limited by their receptive fields [
4], hindering their ability to capture global information effectively from SAR images. Challenges such as confusion between shadows and water bodies, as well as difficulties in extracting the detailed boundaries of continuous water bodies, persist.
To address the aforementioned issues, a novel end–end network framework called the local and global feature fusion UNet (LGFUNet) model is developed in this study and applied for water extraction in the complex terrain of the Qinghai–Tibet Plateau to demonstrate the advantages of the proposed method. The main contributions of this paper are as follows:
- (1)
A multiscale feature learning module (DECASPP) is proposed. Without increasing the number of model layers, DECASPP enables the model to learn important multiscale water body features, thereby enhancing the model’s ability to distinguish between shadows and water bodies.
- (2)
To address the issue of the misdetection of small water bodies, the local and global feature fusion (LGFF) module is introduced; it integrates the global and local features of water bodies, improving the model’s ability to extract detailed information about small water bodies.
- (3)
To address the challenge of extracting complex boundary details for continuous water bodies, the LGFUNet water extraction network model is established by combining the Swin-Transformer [
41], DECASPP, and LGFF modules. This model comprehensively learns both the global and local features of water bodies at different scales, enhancing its ability to extract large-scale water bodies while effectively preserving the boundary details of spatially continuous and complex water bodies.
4. Discussion
The proposed LGFUNet model in this study employs the Swin-Transformer as a feature extractor, incorporating several key innovations. First, a DECASPP module is constructed, which combines atrous spatial pyramid pooling, ECA, and depthwise separable convolution to enhance multiscale feature extraction and obtain valuable multiscale information. Second, a series of LGFF modules are introduced between the encoder and decoder. These modules integrate global features from the encoder, multiscale features extracted by DECASPP, and local features extracted by the LGFF modules, which are then passed to the decoder. This integration reduces the semantic gap between the encoder and decoder feature maps and mitigates spatial information loss caused by patch merging and downsampling, thereby improving the model’s ability to learn detailed information. As demonstrated by the visualization results and quantitative evaluations in Chapter 3, the LGFUNet model exhibits superior performance in extracting water bodies in complex regions, including small water bodies, spatially continuous water bodies, and shadow areas. The number of parameters for each model and the training time per epoch are shown in
Table 7. The LGFUNet model has enhanced learning capabilities for water feature characteristics in SAR images, resulting in a slight increase in the number of parameters; however, it has a certain advantage in training time. Moreover, the LGFUNet model demonstrates the best performance across various metrics on the test dataset.
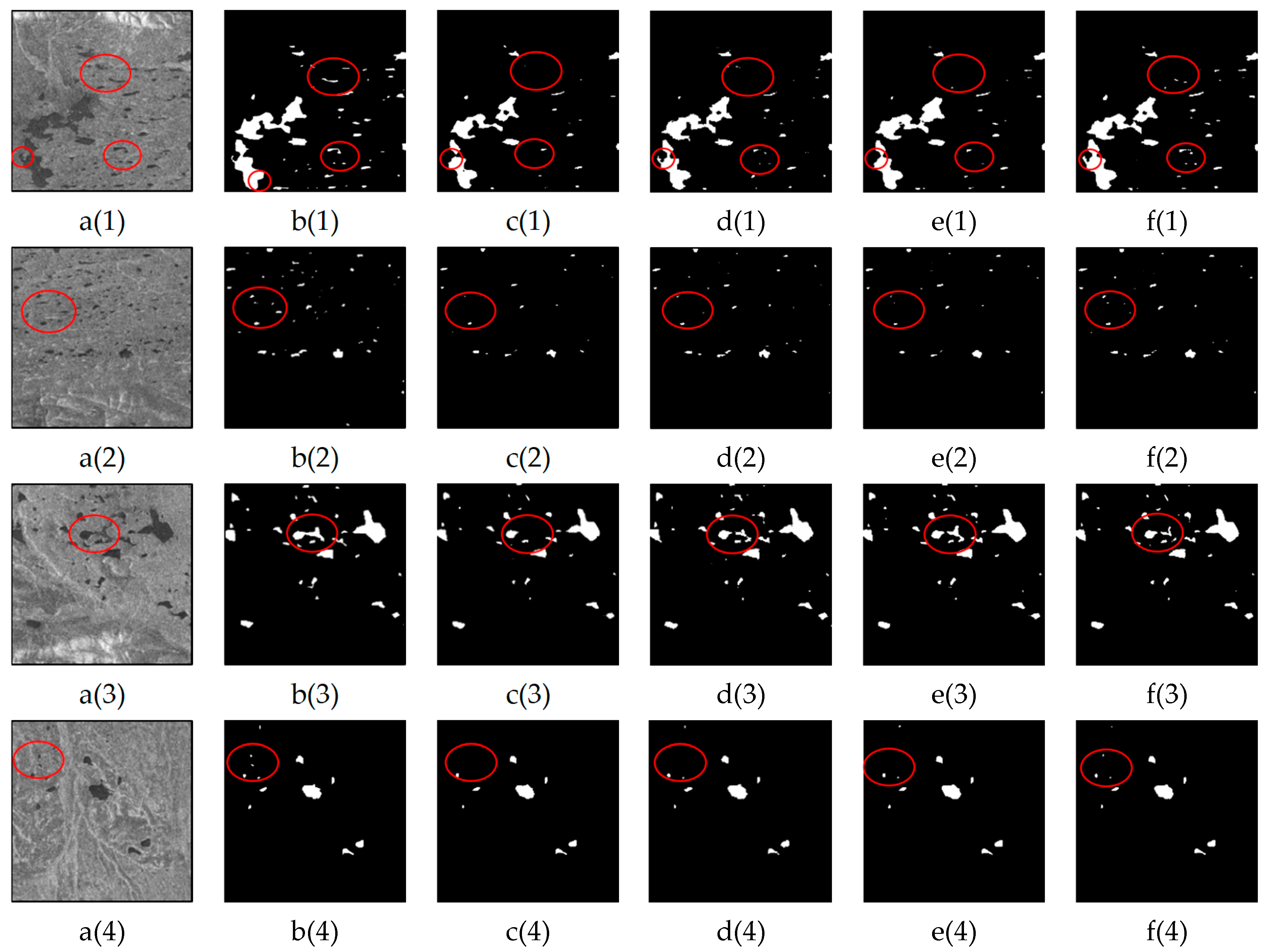
To further validate the effectiveness of the proposed improvements in the LGFUNet model, ablation experiments were conducted to assess the impact of the DECASPP and LGFF modules. The results of the ablation experiments are presented in
Table 8, and the visualization results are shown in
Figure 10. In Swin-UNet+DECASPP, the DECASPP module alone is employed to enhance multiscale feature extraction, effectively improving the accuracy of water body extraction. However, the improvements in the other metrics are relatively modest. In
Figure 10(d(1),d(2)), this module significantly enhances Swin-UNet’s ability to extract detailed water body boundaries. In Swin-UNet+LGFF, only the LGFF module is used to reduce the semantic gap between the encoder and decoder feature maps, improving Swin-UNet’s ability to extract local features. All the evaluation metrics for the prediction results show improvement. In
Figure 10(e(1),e(3)), the LGFF module enhances Swin-UNet’s ability to extract small water bodies, although the overall model performance remains inferior to that of the LGFUNet model. The experiments demonstrate that the LGFF module can effectively enhance the model’s water extraction performance. While the DECASPP module alone does not significantly improve model performance, it provides the LGFF module with valuable multiscale information. When the DECASPP module is combined with the LGFF module, the model achieves optimal performance.
Siling Co (located in Nagqu City, Tibet Autonomous Region) is one of China’s largest inland saltwater lakes. Research by Lei Yanbin et al. [
47]. has revealed that Siling Co has become one of the most rapidly expanding lakes on the Qinghai–Tibet Plateau over the past two decades. Its rapid expansion has led to the inundation of surrounding grasslands and road damage, significantly impacting the local environment, wildlife, and human livelihoods. Therefore, this study selected Siling Co to validate the model’s generalization capability and explored the correlation between lake area and meteorological data based on the monitoring results.
This research utilizes Sentinel-1A images acquired at the beginning of each month from July to November 2018 for the Siling Co region. Combined with LGFUnet extraction, we investigated the short-term fluctuations in the lake’s monthly water extent. The monthly variations in the water surface area of Siling Co Lake and the corresponding average precipitation from July to November 2018 are presented in
Figure 11.
The Siling Co region experiences its rainy season from July to September, characterized by substantial monthly precipitation. During this period, the surface area of Siling Co Lake exhibits a steady expansion, reaching its maximum extent at the end of the rainy season (early October). Following the conclusion of the rainy season, the lake gradually enters its freezing period. During freezing, precipitation and evaporation on the Qinghai–Tibet Plateau are both minimal, resulting in relatively stable Siling Co lake areas. Consequently, this study employs July Sentinel-1A data from 2017 to 2024 to monitor Siling Co’s interannual variations.
The interannual variations in the Siling Co Lake area and annual precipitation from 2017 to 2024 are presented in
Figure 12. The lake area exhibited a minimum value of 2347.7 km
2 in 2017 and reached its maximum of 2441.82 km
2 in 2024, demonstrating a consistent expansion trend. Over the eight-year period, the lake area increased by 94.12 km
2 in total, with an average annual growth rate of 0.5%. Precipitation showed an overall increasing trend with considerable interannual variability (coefficient of variation, CV = 29.92%), indicating significant year-to-year differences in rainfall.
To quantitatively assess the relationship between lake area and climatic factors, we performed Pearson correlation analysis. The results revealed a statistically significant positive correlation (r = 0.76, p = 0.029) between lake area and precipitation, suggesting a strong association (p < 0.05). For instance, the annual precipitation in 2021 (from July 2020 to July 2021) reached 1135 mm, corresponding to an area increase of 17.63 km2, while the lower precipitation in 2018 (490 mm) resulted in a smaller expansion of 6.93 km2. Precipitation during the previous year’s rainy season (July–September) is stored through surface runoff and winter ice formation, then gradually released during spring snowmelt, ultimately influencing the lake area measured in July.
5. Conclusions
In this study, a water extraction method based on SAR imagery, the LGFUNet model, is proposed. Sentinel-1A SAR images are used as the basis for extraction, and the model achieves promising extraction results in the study area on the Qinghai–Tibet Plateau. In the LGFUNet model, the Swin-Transformer module is employed to replace convolutional kernels for feature extraction, enhancing the learning of global features and improving the model’s ability to capture the spatial relationships associated with large, continuous water bodies. Within the DECASPP module, ECA and atrous spatial pyramid pooling are utilized to filter and refine multiscale features, thereby improving multiscale extraction performance. Additionally, a series of LGFF modules are introduced between the encoder and decoder. These modules integrate global information from the encoder, multiscale feature information from the DECASPP module, and local information extracted by the LGFF modules, which are then passed to the decoder. This integration reduces the semantic gap between the encoder and decoder feature maps, compensates for Swin-Transformer’s limitations in local feature extraction, mitigates spatial information loss during downsampling, and enhances the model’s ability to extract small water bodies. Both quantitative evaluation results and visualization results comparing the LGFUNet model with other models demonstrate that the LGFUNet model can accurately and effectively extract surface water resources on the Qinghai–Tibet Plateau, showing significant potential for water body extraction applications in this region.
In comparative experiments involving three challenging tasks—water extraction in shadowed areas, small lake extraction, and complex boundary extraction for continuous water bodies—the proposed LGFUNet model outperforms other end-to-end models, demonstrating superior performance. However, some limitations remain, such as occasional omissions of small water bodies with blurred boundaries and fine river branches with spatially continuous and complex boundaries. In future work, we aim to further refine the LGFUNet model, including but not limited to the following aspects: exploring more combinations of the Swin-Transformer and CNNs based on the LGFUNet architecture to optimize the model structure and enhance performance; expanding the dataset to improve the model’s generalization capabilities; and addressing the current limitations to achieve more robust and accurate water body extraction.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}