1. Introduction
Outdoor depth estimation can be achieved in several ways, depending on the hardware and software adopted. For applications requiring accuracy and dense depth reconstruction, LiDAR devices are the best choice [
1]. However, the price of the hardware is high according to the depth accuracy provided, and oftentimes, such devices require the users to move slower than desired to ensure the correct acquisition of the point clouds (e.g., to deal with light interference in the best way possible). In addition, LiDAR systems require users to adopt dedicated hardware to keep up with the acquisition and storage needs of the device. Luckily, not every outdoor application requires the data density provided by LiDAR systems. In these cases, a viable and low-cost choice is the adoption of depth cameras leveraging stereo vision. However, the quality of the output (both the color and depth images) is often insufficient, especially when employed in applications where the camera moves fast, introducing defects due to the shutter and acquisition speed. In the case of high-speed movements, a good color camera paired with high-end optics is necessary to cope with the speed of the moving scenario to be acquired. Starting from good-quality images, the depth estimation problem could be addressed by computer vision (CV) techniques. One of the most popular methods is optical flow (OF), first developed in 1981 [
2,
3]. OF is defined as the apparent motion of objects in a sequence of images caused by the relative motion between the scene captured in them and the camera. Therefore, the problem encompasses several variables such as ambient illumination, object texture, and difficult geometrical shapes for which occlusions may happen, producing incorrect OF estimates [
4,
5,
6]. In general, OF is obtained as a map of vectors indicating, for each pixel in the image, the corresponding apparent motion and its intensity. OF is used to estimate the speed and depth of both slow and fast phenomena and is applied in several fields, such as healthcare [
7], robotics and moving vehicles in general [
8], industry [
9], and agriculture [
10,
11]. Modern approaches for solving OF issues exploit Deep Learning (DL) to improve the estimates, especially in the case of depth estimation [
12,
13]. Other recent advancements in the field of monocular depth estimation are presented in [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24]. These works extensively adopt DL models to estimate depth from monocular images without employing OF and are considered state-of-the-art by the CV community. However, their depth output is not stable and it is not based on a measurement, not to mention the computational requirements needed to run those models on mobile and embedded devices. Some of those models do not produce outputs in metric coordinates either, making it difficult for untrained personnel to use those models in real in-field applications for which near real-time computation is required. Focusing on the agricultural sector, however, the general problem of OF estimation can be simplified since the measurement environment is more constrained. Farming vehicles, such as tractors and fruit-picking robots, move linearly along the rows of the field at a constant speed, which is not higher than 5 km/h in the case of large and heavy tractors and close to 2 m/s for agricultural robots. In addition, modern tractors are being designed to be autonomously driven, requiring accurate tractor–row distance estimation to adapt to the specific field they work on [
25].
This article describes a simplified version of OF inspired by the Structure from Motion (SfM) CV problem, which allows the reconstruction of complex 3D structures from 2D multi-view images of the scene collected by a moving camera [
26]. Traditional SfM techniques are computationally intensive and hardware-demanding, typically adopted for applications such as land reconstruction, architecture, and construction. Therefore, in this paper, a custom model that is easier to understand for end-users was designed. The developed model was validated by means of a practical laboratory experiment mimicking the agricultural scenario, thus showing how the model performs at different camera speeds and relative camera–object depths. In particular, the focus of this article stands on the models’ validation and uncertainty analysis, which ultimately provides ready-to-use information for the end-user (e.g., the farmer) to both choose the right camera for the target application and design the measurement setup and constraints. In fact, it is generally challenging to couple depth estimates with measurement uncertainty, typically treated as a confidence measure [
27] that does not adhere to the “Guide to the Expression of Uncertainty” manual [
28,
29]. Moreover, monocular depth estimation research is mostly rooted in the CV community, which focuses more on the software and mathematical aspects of the problem and less on practical needs for the untrained end-user to obtain a reliable depth measure, such as which hardware to choose according to specific characteristics and what are the limitations of the measurement setup to keep in mind. The findings of this work could be beneficial for several research areas, including yield estimation [
30,
31] and the wood–fruits–leaf canopy volume estimation from 2D images [
32]. Finally, the code used for this work is made publicly available on GitHub at [
33].
2. Materials and Methods
2.1. Equipment and Experimental Setup
The experimental setup was designed considering the agricultural scenario, in which tractors and other vehicles move linearly at a constant speed. This is a constrained scenario that allows for some simplifications. The idea is that, by mounting a camera on the moving vehicle, it is possible to acquire a sequence of images for which the temporal and spatial relationships are known. This is possible because (i) the vehicle’s speed is known thanks to its encoder, and (ii) the acquired frames are coupled with acquisition timestamps. In addition, by mounting the camera orthogonal to the vehicle movement direction so that it looks at the canopy, its reference frame primarily moves along its Y axis. By focusing solely on the Y–Z plane with the motion vector confined within it, these assumptions allow for a simplified model implementation.
A scheme of the acquisition setup used for this work is shown in
Figure 1, depicting a robot, a color camera, and a custom-made target. The moving vehicle is simulated by a robot (Universal Robots UR10e) mounted upside-down in the workspace described in [
34]. On the robot’s end-effector a color camera (GoPro Hero 11 Black) was mounted, tasked with the acquisition of color images during movement. The robot was programmed to move horizontally at 5 constant speeds (
m/s,
m/s,
m/s,
m/s, and
m/s) with a horizontal travel distance of
m. The speeds tested were selected according to the common operating speed of farming vehicles. The camera has a
” CMOS sensor with a resolution of
px and F
lens aperture. To increase the camera frame rate, during acquisition the camera was set to a resolution of
px with an aspect ratio of 4:3, allowing it to acquire frames at 60 frames per second (fps). The lens distortion coefficients and the internal camera matrix (containing the position of the image center
and
[px] as well as the focal length dimension in both directions
and
[px]) were computed by performing a calibration procedure using a chessboard pattern [
35]. It is worth noting that the pixels of the chosen camera have a square shape; hence,
.
The custom-made target measurand is made of an aluminum bar (metallic support) placed at a height of m from the ground, on which 5 smaller bars of different sizes ( cm, cm, cm, cm, and cm) were fixed orthogonally. The target was crafted to simulate agricultural rows where plants grow at different depths than the guiding canopy. The metallic support was positioned at 4 different locations from the robot reference frame (RF), cm, cm, cm, and cm. These distances were chosen to simulate different working conditions (e.g., vehicles moving at different distances from the plants growing in the row, and different row distances).
On top of each bar, an ArUco marker [
36,
37,
38] of size
cm was positioned to be orthogonal to the camera during acquisition (
,
,
,
, and
). ArUco markers are square matrices of black and white cells that easily represent a location and an orientation at the same time according to the deformation of the matrix pattern. Each ArUco marker is unique and procedurally generated by the related library, which includes algorithms and functions to retrieve the information of a specific marker from an image. In this work, the ArUco markers serve as the depth ground truth. The ArUco OpenCV library was employed to extract the markers’ depth [
36,
37,
38]. Images taken from the acquisition setup (with the used ArUco marker shown) can be found in
Figure 2.
2.2. Data Acquisition
A total of 20 tests were conducted (4 target positions
D camera velocity
S). Each camera acquisition is composed of a positive and a negative camera movement along the
Y axis. Instead of saving each acquired frame independently, a more computationally efficient solution was defined. A single video in MP4 format was recorded, with each video including frames related to a specific combination of
D and
S, for both movements along the
axis and
axis. The customized algorithm detailed in
Section 2.4 extracts individual frames from the video, splits movements along
axis and
axis, and computes the distance from the camera (depth
Z m) of each ArUco marker. Subsequently, the displacement along the Y axis (
px) of the marker’s center is calculated between two consecutive frames to apply the OF algorithm and estimate the depth.
The number of frames in a single trial varies depending on the robot’s (and thus the camera’s) velocity, as the robot follows a fixed path, with an average of 300 frames. Overall, a total of 60,000 data points were collected (5 robot speeds × 2 robot movement directions × 4 relative distances of the metallic support from the camera × 5 ArUco markers at different depths × 300 frames).
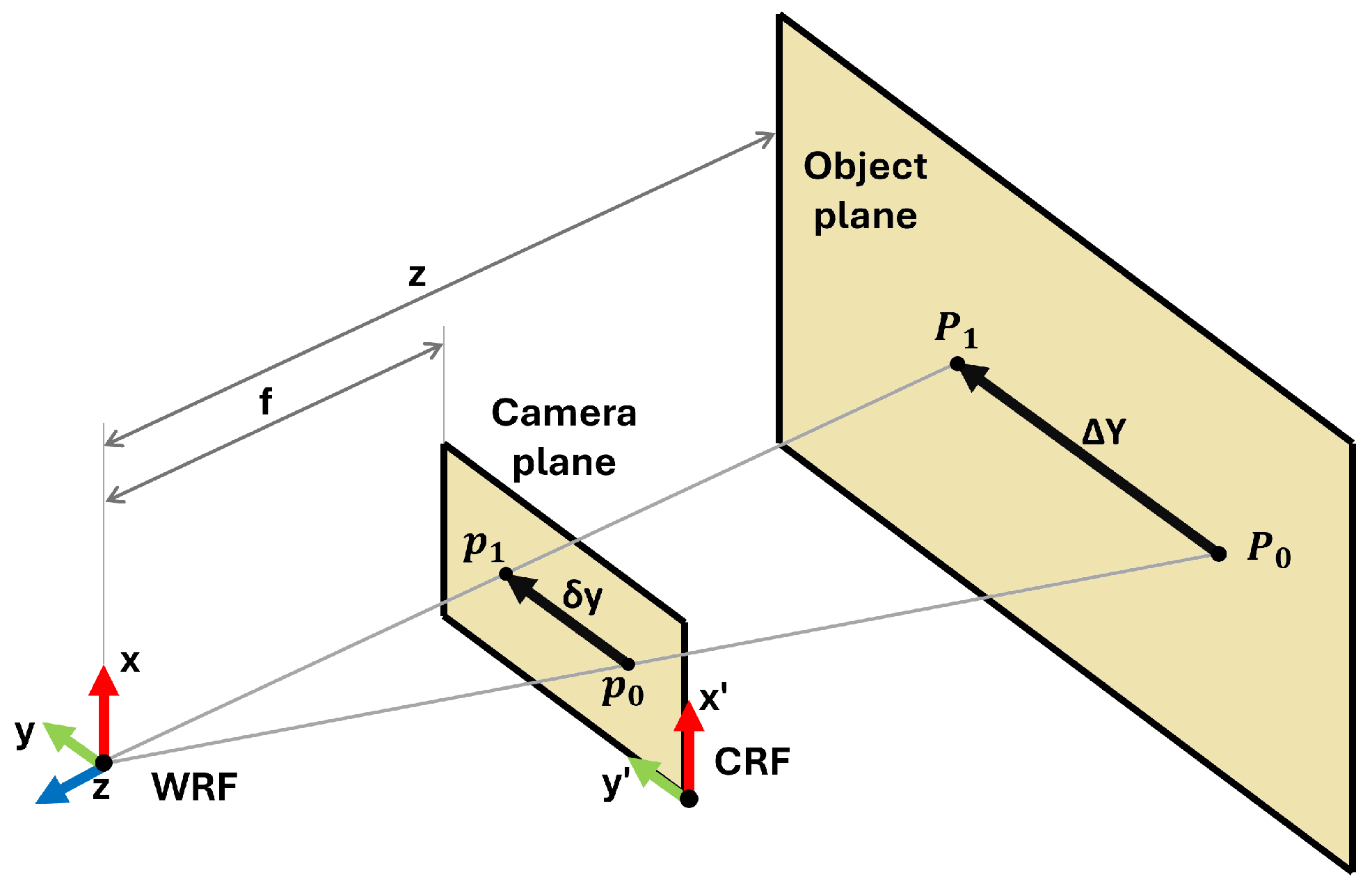
2.3. Model Definition
The model definition is based on the scheme of
Figure 3 where the projection of a moving point of interest onto the camera plane and the object plane is represented.
Imagine a point
P (with coordinates relative to the world’s reference frame, WRF) that moves in the object plane along the Y axis from position
to position
(displacement equal to
). In the camera’s reference frame (CRF), the projection
p of the point
P on the camera plane moves from position
to position
(displacement equal to
). This displacement is corrected for lens distortion through a camera calibration process (such as [
35] or similar approaches). Considering the object plane and the image plane placed at a distance from WRF equal to
z and
f, respectively, there are two similar triangles (
) and (
). Based on their similarity properties, the equation is obtained as follows:
where
is the displacement of the point in the WRF [m],
is the displacement of the point in the image plane [px],
Z is the depth corresponding to the point [m], and
f is the focal length of the camera [px].
By applying Equation (
1), knowing the camera focal length
f, it is possible to estimate the point’s
P depth (
Z) based on
p pixel displacement in the image plane
, given its relative displacement with respect to the WRF
.
To accurately calculate with respect to a specific point or object within an image, several challenges arise in detection and tracking. The detection challenges include reliably identifying specific points or objects despite varying lighting conditions and similar-looking objects. Ensuring consistency in detecting the same points across multiple frames is crucial for accurate displacement calculation.
In tracking, the main issue is maintaining the continuity of the detected object across successive frames, which requires robust algorithms capable of handling rapid movements, changes in scale, and rotation. Additionally, tracking algorithms may experience drift over time, leading to deviations from the actual position due to cumulative errors.
Advanced techniques are typically employed to address these challenges. Feature extraction methods provide robust features invariant to changes in scale, rotation, and illumination, aiding in detection and tracking. Optical flow (OF) algorithms calculate the apparent motion of objects between consecutive frames, directly providing by analyzing pixel displacement. Marker-based tracking, using fiducial markers, offers a reliable method as these markers are easily detectable and their positions can be accurately determined.
Integrating these methods improves the accuracy and reliability of
calculations. This displacement can be related to the original speed of the point
P tracked according to the formula
, where
S represents the space traversed by the tracked point,
V refers to the movement velocity, and
refers to the time between two consecutive frames. Two versions of this relationship can be defined accordingly:
where
is the point
P velocity in the object plane,
is the point
P velocity in the image frame, and
T is the time between two consecutive frames. Therefore, the speed of the object in the WRF (
) is related to the apparent speed of the object in the CRF (
).
By substituting these relations into Equation (
1) and simplifying for
T (purposely considered equal for the two terms),
Z can be obtained directly from point
P velocities (in the object plane and in the image plane):
This equation will be referred to as the “analytical model” definition.
In this work, the aim is to simplify the relationship for
Z estimation using only the OF output, treating
as a constant rather than an unknown variable. By assuming a constant
during movement, the idea is to obtain a general parameter
K that allows end users to estimate
Z with sufficient confidence for the target application using the data output of OF to obtain
. Following this, the “experimental model” definition is as follows:
where
[px/s] is obtained through the OF algorithm and parameter
K [
/s] is unknown.
2.4. Depth Computation
The
videos of the tests (see
Section 2.2) were processed leveraging a variety of open-source functions available on the OpenCV library. The processing code was developed in Python and is publicly available at the link provided in reference [
33]. Each video was analyzed independently, and the frames contained in it were not saved on disk; instead, to save space, a data extraction procedure was applied to analyze the contents of the frames and save the outputs in separate files in CSV format.
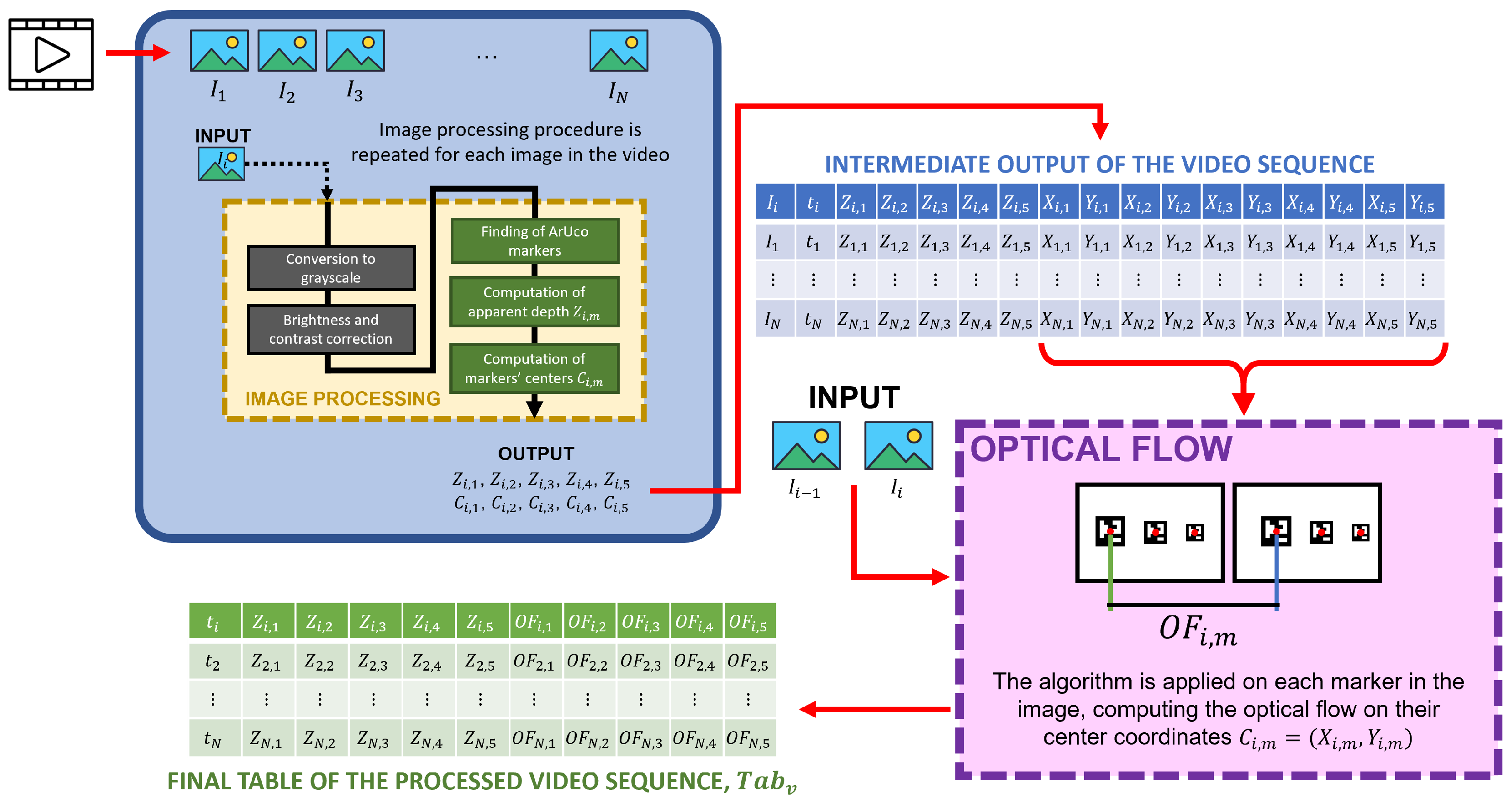
Each video sequence
v contains a set of frames
i acquired at time
. Each frame was processed individually following a two-block operational procedure illustrated in
Figure 4 (first block in blue, and second block in pink). The first block involves calculating the pose of the markers thanks to a set of image processing analyses (yellow block inside the blue block of
Figure 4), followed by the second block, which focuses on computing the optical flow for each marker. Examples of the frames registered by the camera during the experiments are shown in
Figure 5.
The image processing block (yellow) structure is the following:
Conversion to grayscale. The image of the current frame is converted from color to grayscale to facilitate the subsequent operations.
Brightness and contrast correction. The image’s contrast
and brightness
are optimized to improve the image’s quality. These parameters are defined to ensure that the markers can be detected with sufficient accuracy by the ArUco library functions. The best values were experimentally found and are equal to
and
according to the general illumination of the working conditions of the experimental setup. To read further about how these two parameters are defined and used in OpenCV, please refer to the official documentation in [
39].
ArUco markers finding. The five markers
m in the image
are identified using a specific set of functions in the OpenCV ArUco library [
36,
37,
38].
Computation of apparent depth. Using the ArUco library, the depth of each marker is calculated, providing an estimate of the marker’s Z coordinate relative to the camera’s reference system.
Computation of markers’ centers. For each detected marker m, its center coordinates on the image plane, , are calculated. Coordinates and are different from the 3D coordinates , which involve marker and camera calibration since they are solely related to the marker’s detection on the image plane.
Outputs of the first operational block are the ground truth coordinates of the ArUco markers acquired, for each acquired image .
The second operational block (pink) was defined to compute pixel displacements between consecutive frames through OF. To do so, starting from the intermediate output table, the OF algorithm was applied on pairs of images and (thus beginning the counter from image ), using as tracked markers the centers of the markers detected before. This produces another value called representing the pixel displacement between consecutive images in px/mm.
For each video the overall procedure produces a table of rows × 11 columns (time instant plus the 5 Z-coordinates of the markers’ centers and the 5 OFs of each marker’s center ). Each , containing the OF data stream over time, is saved in a CSV file.
2.5. Signal Synchronization and Filtering
Considering the analytical model definition described by Equation (
4), in the experiments
was equal to the robot’s speed. However, even if the robot is theoretically actuated at a constant speed, some portions of its movement include acceleration and deceleration (at the start, during changing direction, and at the end of the movement). Ideally, the robot’s movement during the experiment and the camera acquisition should be synchronized. However, the robot signal was obtained from its encoders, which produce denser data compared to the data obtained from the image-based analysis of
Section 2.4. Thus, the two data streams are not synchronized and contain a different number of points. To address this issue and obtain synchronized data streams, the following procedure was applied. Please note that in the following notation, we will refer to the data stream containing the robot speed over time using
and to the image speed over time (computed as the OF of the 5 ArUco markers’ centers’ positions in the image plane) using
, for a specific acquisition video
:
The robot’s signal obtained from the encoders represents its position in its coordinate reference system. The robot’s speed over time is obtained by computing the first derivative of the signal.
and
are filtered to remove portions where the robot was not moving and, consequently, to separate between its positive (
) and negative (
) movements. To do so, the algorithm searched for OF and speed absolute values in
and
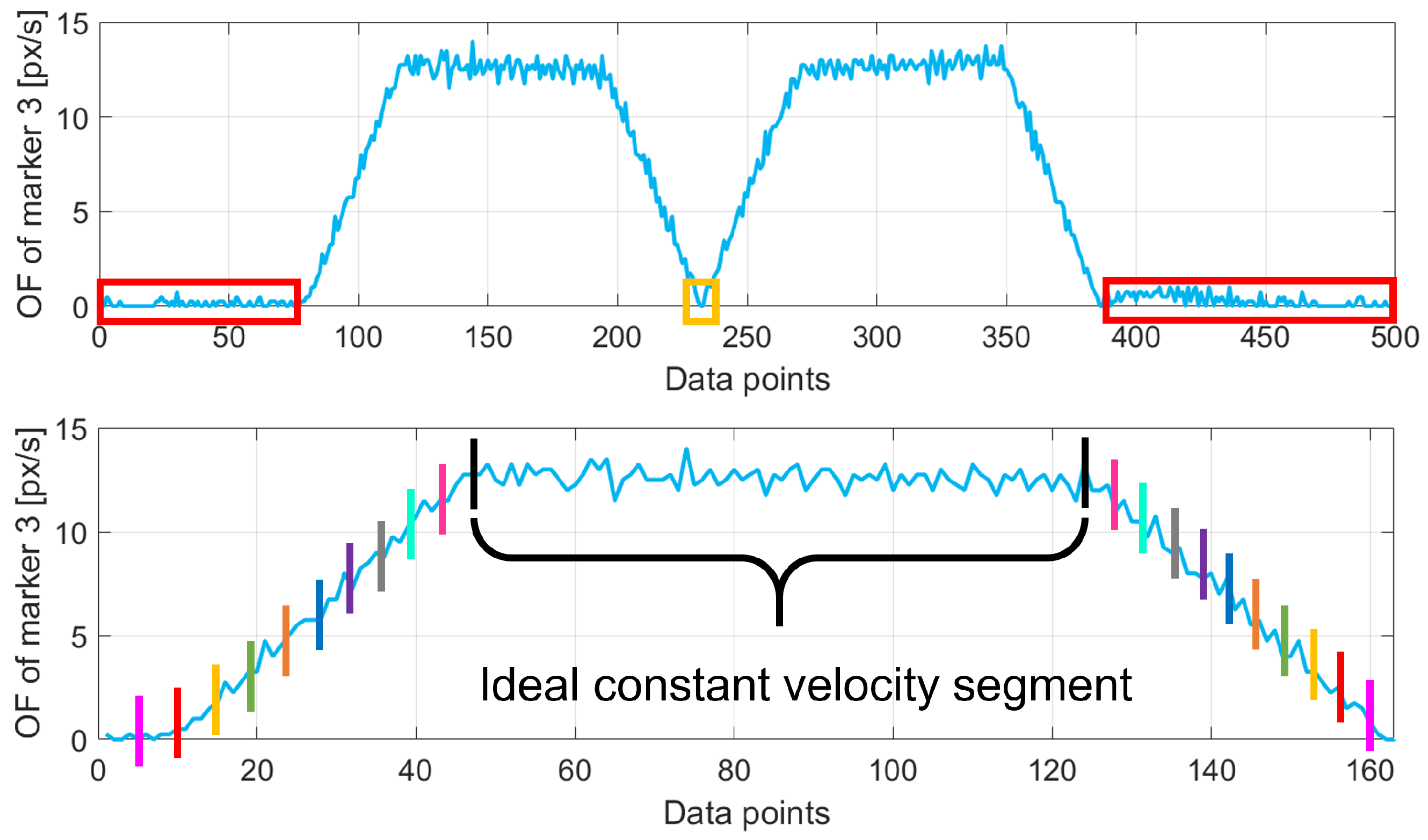
, respectively, below the 5th percentile of the overall values. This threshold, determined iteratively to minimize data loss while eliminating noise during stationary phases, ensures that even minimal detected movements are treated as stationary. These rows correspond to the initial and final moments of acquisition when the robot was not moving; hence, they are removed from both
and
(red portions in the top image of
Figure 6).
To find the instant when the robot changes its moving direction (from
to
), the software scans
and
to select the rows where OF and robot speed values change from positive to negative. The turning point (yellow portions in the top image of
Figure 6) is identified as the point where the corresponding signal goes under the 5th percentile of the values in
and
, respectively (without the elements already filtered out from the previous step). Then, the negative stream is rectified, obtaining a signal always in the positive quadrant for both OF and robot speed values.
The robot’s signal is sub-sampled to the same number of points as the corresponding OF signal of the experiment. Then, for each data point of the OF data stream , the algorithm searches the temporally nearest neighbor of the corresponding robot’s data stream . The iterative procedure outputs several values as many points in the data streams and then computes their average , representing the temporal shift between the two signals. The temporal correction is then applied to .
The two data streams include acceleration and deceleration components (i.e., not a constant speed) that must be removed to obtain only data corresponding to movements at a constant speed. This step is applied on both
and
at the same time. The points to be removed are selected iteratively by removing parts at the beginning and at the end of the original curve and computing the linear regression with the obtained curve. The procedure removes the initial and final
of the whole curve first and iteratively increases the removal percentage up to
(with steps of
). For each curve obtained, a linear fit is computed coupled with the corresponding
. The result is a function of the distribution of
values with respect to the percentage of removed data. The ideal constant velocity segment corresponds to the portion of the whole curve with the greatest
. It was experimentally found that the ideal value for sub-sampling is
for all acquisitions since
does not change notably afterward. An example of this procedure is graphically shown in the bottom image of
Figure 6, where the program iteratively selects portions of the data (depicted with colored bars to highlight the portion of data considered, in pairs) until the optimal portion is selected (in the figure, this is the black one).
At the end of this procedure, the data in each is merged according to the robot’s speed. The result is a total of 5 tables called , comprehending, for each ArUco marker, all the captured points obtained during the experiment for that specific robot’s speed (subscript s refers to the five robot speeds, ranging from 1 to 5 and equal to m/s, m/s, m/s, m/s, and m/s). Please note that the number of depends on the robot’s speed because the quantity of captured points varies according to it (more points for slower speeds).
2.6. Window-Based Filtering
The data in
resulting from the processing described in
Section 2.5 is significantly noisy, especially at higher speeds. This is primarily due to the vibrations of the camera and sudden environmental disturbances (e.g., light changes, electrical noise, and optical aberrations) that are inherent in real-world conditions, especially in agricultural scenarios where light scattering effects appear on the plants’ canopy. These factors introduce noise and uncertainty into the acquired images, which in turn affect the OF output, a well-known issue in the literature [
4,
5]. Moreover, in those scenarios, it is quite common to track specific objects during acquisition, for example, fruits [
40,
41], by using DL models such as object detectors, including in the uncertainty also the contribution of incorrect prediction or bounding box positioning. To mitigate this issue, the data in
are filtered again using a window-based moving average technique. In addition, this approach effectively reduces the impact of incorrect DL predictions in the case of fruit tracking.
The filter was applied on each , and considering the data of each ArUco marker individually, the best results were obtained by setting the window size equal to 3, resulting in a sub-sampling of the data corresponding to an “effective” camera acquisition speed of 20 fps (in contrast with the original 60 fps).
In the subsequent analysis, results will be shown for data with and without the application of the window-based moving average filter, for a total of
(5 robot speeds
, with and without filtering) experimental models represented by tables
. Accordingly, the quantity of captured points contained in each
will now be called
since their number is further reduced after filtering. An example of the windowing effect can be seen in
Figure 7.
2.7. Model Validation and Uncertainty Estimation
Each data set
contains a set of
points represented by a certain
obtained as the OF value of the ArUco marker
m (
),
, and a certain depth value
, computed for each acquired image
i in the data set
as described in
Section 2.4. For simplicity, the points of a data set are generally represented by the pair (
,
), a notation that takes into account all
m marker points contained in a specific
. Therefore, after conducting the pre-processing and filtering steps described in
Section 2, the resulting
data sets
are used to verify if the experimental model of Equation (
5) is in agreement with the analytical one in Equation (
4). To do so, it is first necessary to obtain an estimation of the parameter
K for each data set, namely
. For this purpose, the data set points are simply used as the input for a curve-fitting method implemented in Python 3.10 by the function “curve_fit” of the SciPy package [
42], producing a
for each data set. Using the known information about the robot speed (one of the 5 tested speeds in our experiment
, which can be considered equal to
since the camera is rigidly mounted on the robot’s end-effector), the focal length of the camera (
), and the acquired
of each point (
), it is straightforward to also apply the analytical model in Equation (
4) and compare the two.
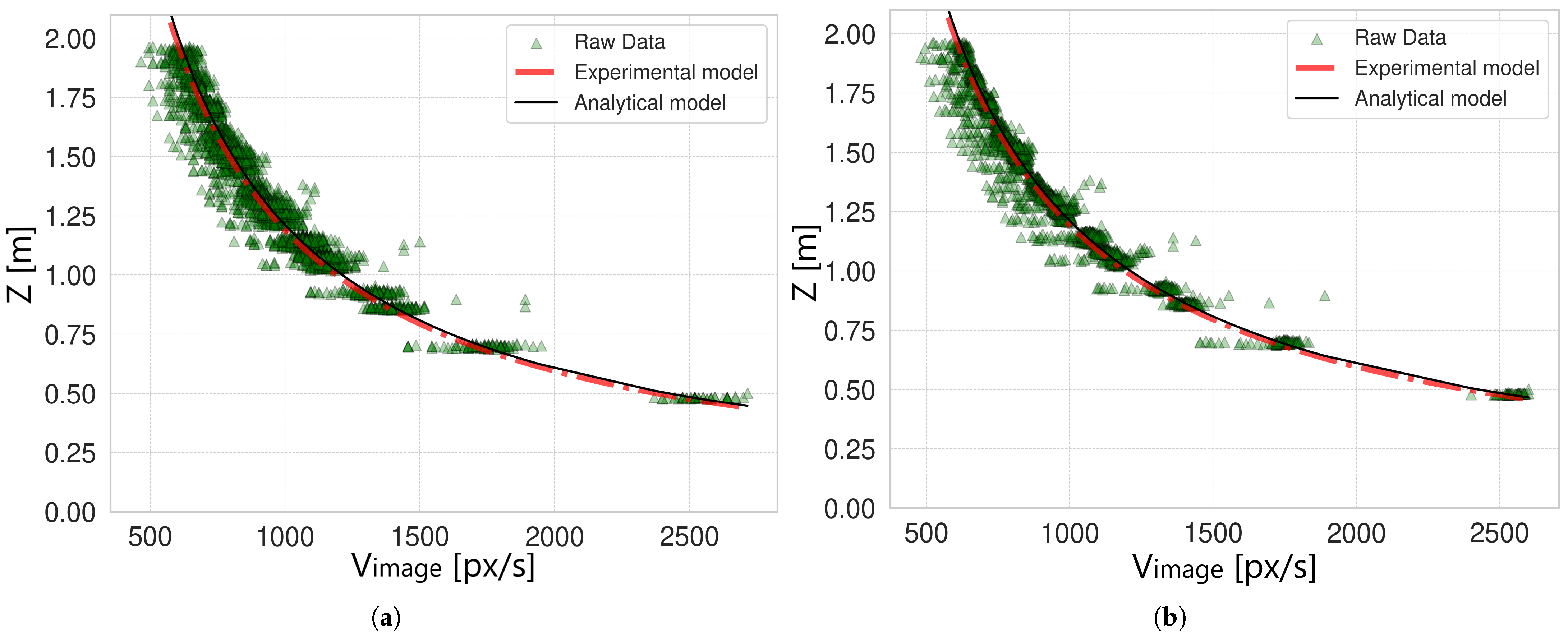
Figure 7 shows the resulting comparison of the two models for the original data and for the filtered data corresponding to the robot speed
m/s (the results for the other robot speeds are similar and are omitted for brevity). In both cases, the experimental and analytical models are overlapped (red dashed line versus black solid line), meaning that the experimental model was correctly defined and that the experimental procedure was properly conducted. However, by observing the curves, a major issue arises due to the exponential nature of the models. In fact, data points corresponding to
close to 0 px/s are distributed over a wider range of possible values, resulting in high variability. This effect is strongly reduced when
is higher than 500–800 px/s according to the camera’s speed, for which the model shows acceptable variability for the target application. Due to this issue, the problem of uncertainty estimation of the experimental model is challenging to tackle. In the following analysis, two approaches are proposed to obtain the model’s uncertainty: a “generalized approach” and a “complete approach”. A scheme of the analysis conducted to estimate the model’s uncertainty is shown in
Figure 8.
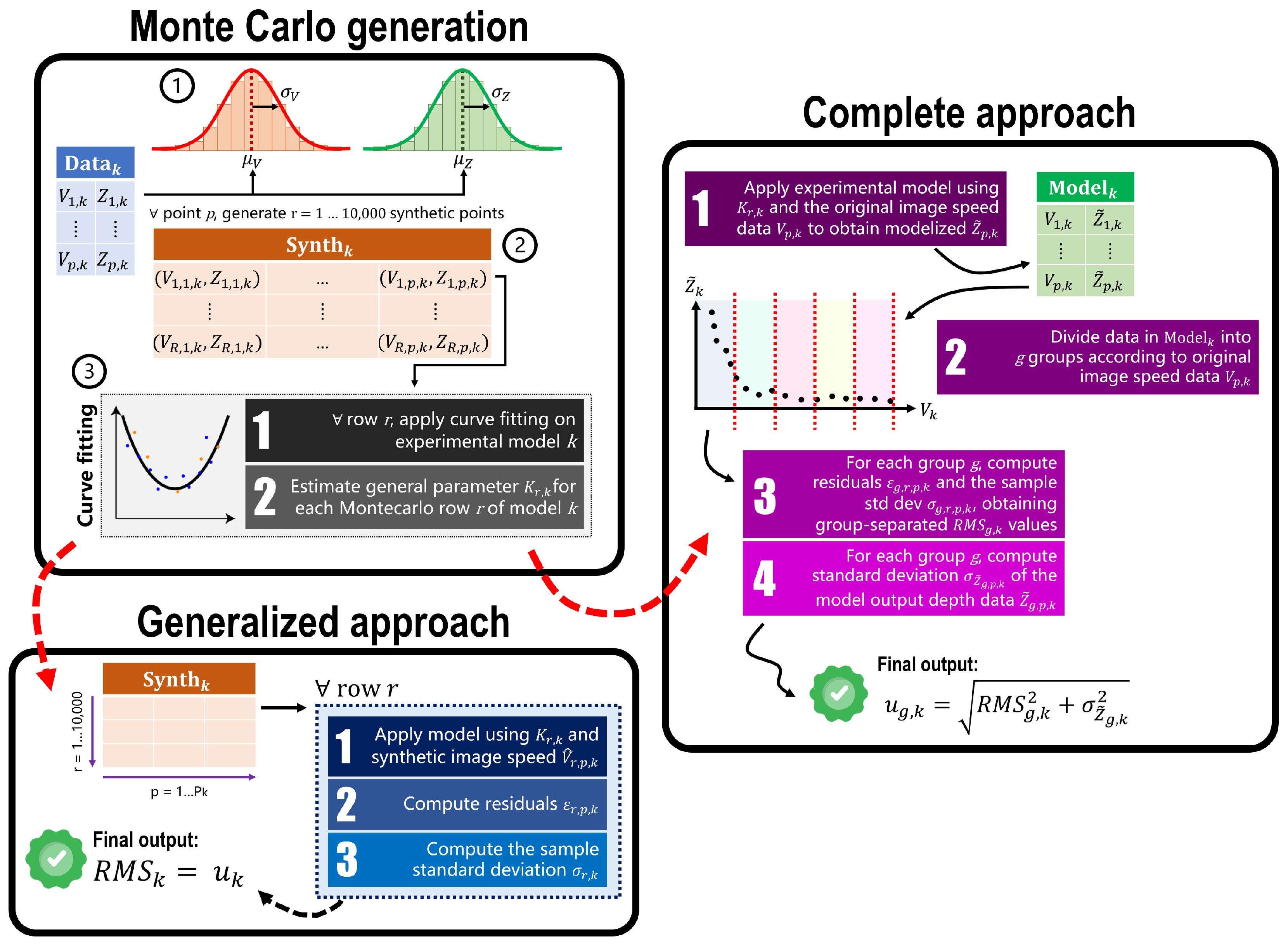
Both approaches are based on a common starting point based on a Monte Carlo generation of simulated data points. The procedure, called “Monte Carlo generation” in
Figure 8, is as follows:
Original data distributions definition. In real-world applications, the values of each point’s speed and depth are affected by uncertainty. To validate the proposed experimental model, their variability was empirically set to
px/s and
m, respectively. These two values were estimated considering the overall data acquired and the ArUco markers documentation [
36,
37,
38]. Now, considering a certain set of points
, for each point (
,
) contained in it, two Gaussian distributions were built using the data point’s actual values as the mean,
and
, and the variabilities defined before,
and
, as the distribution’s spread.
Synthetic data generation. From the distributions of V and Z, a total of 10,000 simulated data points (, ) were generated for each original point. This process produces a table composed of 10,000 rows and columns. The synthetic data generation procedure was repeated for each tested robot’s velocity , for both original and filtered data, obtaining a total of tables .
Estimation of parameter K. Each row of now contains synthetic points. Therefore, it is possible to estimate parameter K for that specific row, , by fitting the experimental model to the data in the row. Repeating this process for all rows produces 10,000 estimated values of .
2.8. Uncertainty Estimation Using the Generalized Approach
The following steps are conducted after the “Monte Carlo generation” procedure described in
Section 2.7 and are graphically shown in
Figure 8 in the block called “Generalized approach”.
Given the 10 tables
and the corresponding
for each row
, for each point
in the row, it is possible to compute
, which is the depth value output produced by applying the experimental model in Equation (
5). Then, residuals
of each point are calculated as the absolute difference between the synthetic depth
and the depth obtained from the experimental model,
:
where
and
are the depth and the image speed of a synthetic data point
p in row
r, respectively, and
is the experimental model parameter
K estimated for each row
of the data set
at the end of the “Monte Carlo generation” procedure.
Then, for each row
r, it is possible to compute the sample standard deviation
as
where
P corresponds to the original number of data points
in the columns of table
.
Finally, we compute the root mean square (RMS) of all the
values, which is the final uncertainty for each model,
:
2.9. Uncertainty Estimation Using the Complete Approach
The following steps are conducted after the “Monte Carlo generation” procedure described at the start of
Section 2.7 and are graphically shown in
Figure 8 in the block called “Complete approach”.
After generating the 10 tables
and obtaining the
model parameters
, the experimental model in Equation (
5) is now estimated for each robot speed, for a total of
models,
. Using as the input the estimated
and the original image velocity data of each point
(given from the OF), the model outputs a depth value
. Repeating this step for all the points in all
tables produces new data tables
, in which each point is described as the pair (
,
).
As already discussed at the start of
Section 2.7, given the exponential nature of the model, the data points for which
V was close to 0 px/s demonstrated a behavior very different from those belonging to the latter part of the graph where
V was close to 3000 px/s. To analyze this issue, the data points have been split into groups according to their
value. For all
tables, the data points were divided into groups according to the value of
. By considering the range of possible values of
for that specific
, groups were created with a step of 30 px/s (e.g., group 1 contained points with
in the range [10, 40) px/s, group 2 with
in the range [40, 70), etc.). This resulted in a certain number of groups
according to the specific table
considered. The
values described by Equation (
9) are now calculated on the data belonging to each group
g for each model
k; namely,
is obtained by using Equation (
8) and
, as in Equation (
6). This produces group-separated RMS values for the specific experimental model
k considered,
. The final uncertainty in this approach is composed of two contributions for each model
k and it is separated by velocity group
g: one is given by the
, and the other is given by the standard deviation
of the depth values obtained by applying the experimental model and is divided by group, namely
. The computation of the group-separated uncertainty for each model
k is given by the following:
3. Results and Discussion
The resulting uncertainties for the generalized approach are shown in
Table 1 for both original and filtered data. The effect of the window-based filter is evident for
and
, for which the overall uncertainty is reduced by
, while for
the effective uncertainty reduction is only
. In the case of
and
, the effect is even less evident, reducing the uncertainty of just
m in both cases (
). This effect is related to the number of frames acquired according to the robot’s speed; in fact, since the camera’s acquisition rate is the same in all tests (60 fps), at lower speeds, more images are acquired representing the same scene; thus, there is not sufficient displacement in between two consecutive pictures for OF to work well. By sub-sampling the data, the effect is to virtually reduce the camera’s acquisition rate to 20 fps, incrementing the spatial difference between two consecutive frames and thus improving OF estimation. In addition, after applying the filtering, the overall uncertainty for
m/s is the same as the one obtained for
m/s. Generally, best-case scenarios are obtained for
m/s and for
m/s. These speeds are acceptable for the agricultural scenario considered.
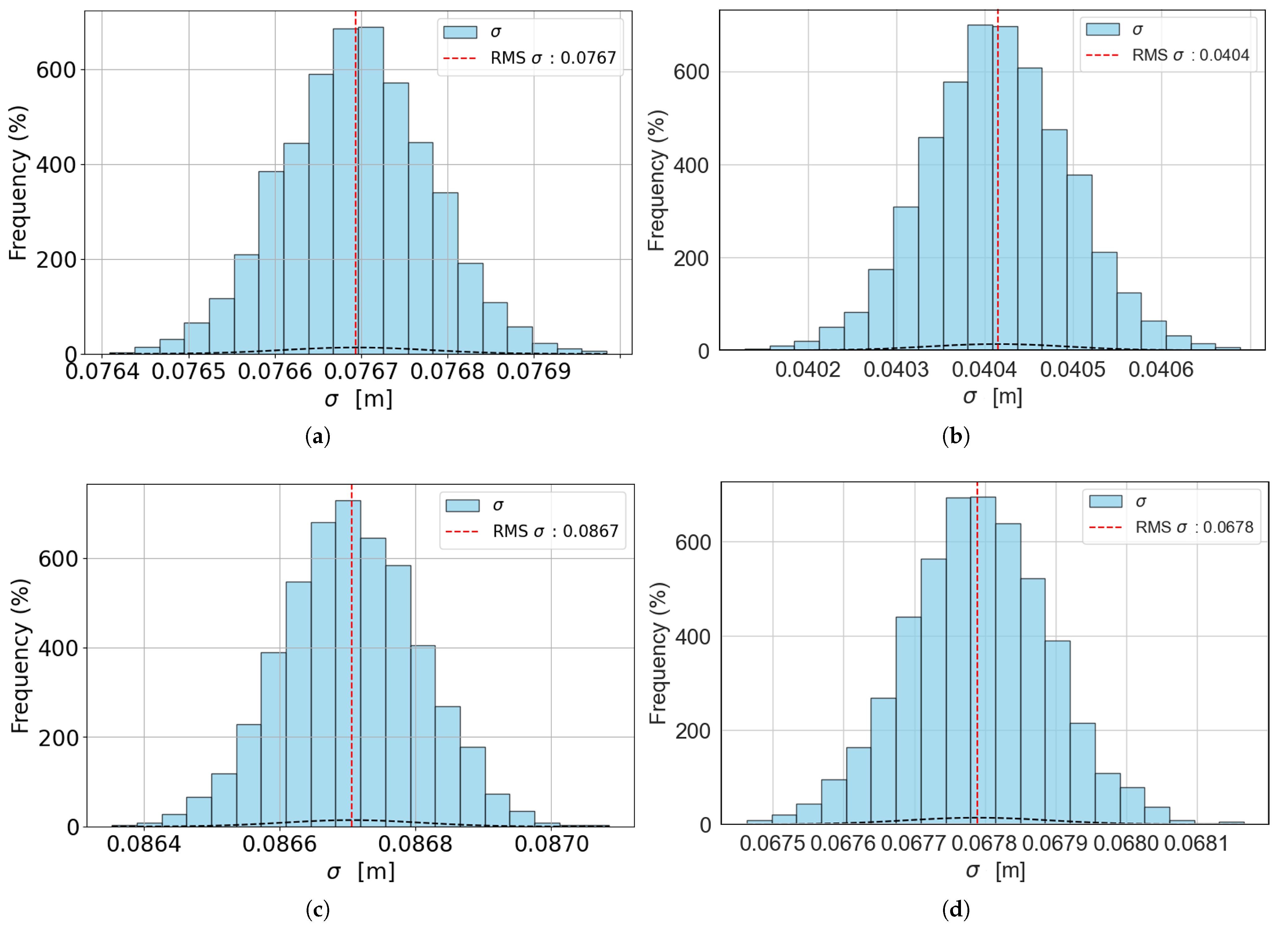
Figure 9 shows the histograms of the distribution of values
from which the final uncertainty
is computed, for the best-case scenarios (models with
and
), both with no filter and with a filter applied. All the other models were omitted for brevity since the resulting histograms are the same.
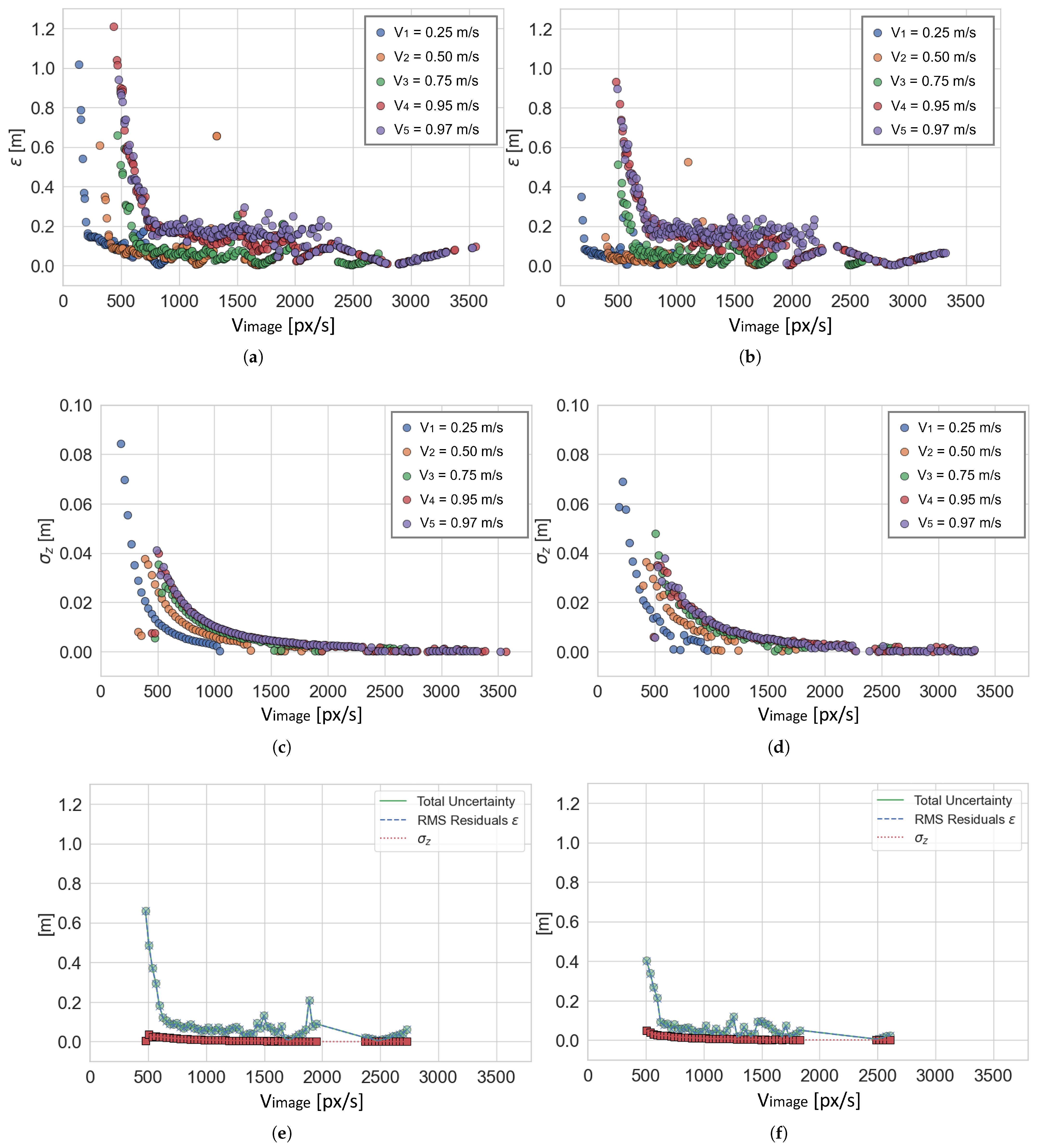
As for the complete approach, the results of
and
are shown in
Figure 10a and
Figure 10c, respectively, for models with
(no filtering), and in
Figure 10b and
Figure 10d, respectively, for models with
(filtering applied). Obviously, the groups of each model are not comparable since they depend on the numerosity of points belonging to the group, which in turn depends on the total number of points
in the original data set
. In
Figure 10e,f the contribution of
and
towards the computation of the total uncertainty
, for
m/s in both the unfiltered and filtered cases (models with
and
, respectively), is displayed. The results for the other robot speeds
,
,
, and
are similar, so they were omitted for brevity. It is evident that almost all the contribution is due to
, and its trend indicates that estimating the depth of a given point from OF is not robust in the first area of the graph where the speed of the point (OF) is lower than 500–800 px/s according to the camera’s speed. However, for point speed higher than this value, the overall uncertainty is reduced to less than 20 cm.
Measurement uncertainty on the computation of depth is even less than 100 mm for robot speeds equal to
m/s and
m/s, while it increases for the other three (see
Figure 10a,c). This is interesting because it highlights that moving at a very low speed (
m/s
km/h) gives similar uncertainty values to those obtained when moving at higher speeds (
m/s
km/h and
m/s
km/h). This effect can be explained by how depth is estimated from OF. When the robot moves too slowly (
is too low), there is not sufficient pixel difference between consecutive pairs of images for OF to produce an accurate estimation of
, while the accuracy of the ArUco markers’ apparent depth
is higher with lower uncertainty due to a more stable image frame. On the other hand, when the robot moves faster, the estimation of
improves until the amount of pixel difference between consecutive images is too high for OF to produce a valid estimation since the two images could be so different from each other that the point matching fails. Consequently, the accuracy in the estimation of apparent depth becomes less accurate when
increases. Evidently, by applying the window-based filtering, the variability of OF estimation is reduced, and the overall depth estimation is improved despite losing data points (see
Figure 10b,d). This drawback is acceptable for the target application (agriculture) and other applications for which sampling one data point in every three is not an issue.
To conclude, the sub-sampling of data points is closely related to the camera acquisition speed (fps): given the issue of OF not being able to produce reliable outputs when the image pairs’ difference is too low, adopting cameras with high fps is not the best choice. On the other hand, considering the possibility of sub-sampling the acquired frames, choosing a camera with less than 30 fps could lead to similar issues. In both cases, the outcome may be similar to the model produced for
. It is worth noting that a few points are missing in the region of 2000–2300 px/s in
Figure 10e,f. This is due to poor detection of some markers happening for
and the lack of detected points for that
speed range in the case of
and
, as can be noted in
Figure 10a,b. Poor detections may occur if the acquired image is too blurred (as is the case for
) or if illumination conditions create aberrations on the ArUco markers, resulting in incorrect or missing detections. However, considering the points present for the speed range higher than 2300 px/s, it is safe to say that the overall trend of the two curves in
Figure 10e,f is unaltered.
3.1. Limitations of the Method
It is worth stressing that the present article describes the theory of the measurement principle validated through a laboratory experiment. Therefore, the choices made to design the setup and its constraints (
Section 2.1) refer to agricultural scenarios in general but can be easily generalized to other environments as well (e.g., industry and autonomous driving). An important limitation of this approach is that the validation was only conducted indoors; hence, other impacting parameters typical of the outdoor environment were not studied in detail. These are as follows: (1) The illumination of the scene, which must be sufficient to see the points of interest in the image but, at the same time, not too bright to avoid aberrations or light spots that may interfere with the recognition of the targets. This is especially important since bright spots and blurred areas of the targets produce incorrect or missing detections. To this aim, an interesting design choice is the addition of an illumination system, for example, in the case of industrial or dark scenarios, to improve the clarity and contrast of image details. (2) The eventual vibrations of the moving vehicle, which may produce incorrect estimations of the OF values and should therefore be compensated either during acquisition or afterwards. (3) Adverse meteorological conditions that may interfere with data acquisition, including dirt. However, assessing the impact of these factors on the method and eventually proposing algorithmic solutions to overcome them requires a more in-depth outdoor study, which will be conducted in the future as a further advancement of the proposed method.
Concerning the inference time, e.g., the time required for a new pair of consecutive frames to be processed by the proposed model and pipeline to produce a final depth estimation, some considerations should be made. (1) The inference can be applied only to pairs of frames because OF is calculated on their differences; thus, we should consider the time required by the camera to acquire and save two frames (either on disk or in volatile memory). This may be a crucial bottleneck, especially if the acquisition hardware is an embedded platform, slowing down acquisition to even 10 fps instead of the typical 30 fps of most common devices. (2) At least one point of interest should be detected in both images of the pair. In the case of our experiment, the points of interest were the ArUco markers, but for other applications, it can be something else. This detection requires dedicated software, which may be AI-based instead of classical computer vision techniques (as is the case for the ArUco markers library adopted in this work). The ArUco markers were detected at a speed of approximately 100 ms per image. Keep in mind that AI-based software is often slower, requiring even 500 ms per image. (3) OF should be computed on the points of interest detected in the pair of images, which is a fast and well-known algorithm that benefits from GPU acceleration if available, requiring only a few ms per pair of images. (4) The final step is the application of the proposed model to obtain the depth estimation in meters according to the estimated speed obtained, which is a simple formula requiring a few ns to be computed. All things considered, we experimentally found that for our setup the average inference time is approximately 300 ms.
3.2. Practical Examples
In the next sections, two examples provide some practical conclusions for agronomists and researchers aiming at conducting on-the-go depth measurements using the proposed method, taking into consideration the uncertainty behavior explained above. In particular, the examples explain (1) how to choose the correct vehicle speed given a specific camera, and (2) how to choose the correct camera for the target application given the vehicle speed ().
3.2.1. Choose the Correct Vehicle Speed Given a Specific Camera
Let us consider a camera with a sensor size of mm, pixel resolution of px, and 60 fps acquisition speed. The camera is fixed on a rigid case mounted on the side of a vehicle, so the pixels vary along the X axis of the camera (assuming negligible vibrations, so no movement along Y). From the results obtained and discussed in the previous section, it is assumed the minimum and maximum acceptable image velocity are px/s and to keep measurement uncertainty on estimated depth values acceptable for the target application.
Consider adopting a maximum vehicle speed equal to . In these conditions, the camera obtains a pair of frames after a time s, so the amount of pixels that change in two consecutive images according to the chosen speed is calculated as . Using the minimum and maximum image speeds, it results that px and px.
Considering the target application of an agriculture scenario where a tractor moves in between two rows, it is known that the inter-row distance is typically set to 2 m, so it can be reasonably assumed that the working distance
, which is the camera–object distance, is
mm. By using the following formula, we can calculate the camera’s field of view (FoV) along the
X axis:
where
f is the focal length of the chosen optics. Several options exist on the market, and the choice depends on the magnification effect desired according to the operating
, recalling from the basics of digital photography [
43] that higher values of
f correspond to a higher magnification and a narrow FoV, while lower values correspond to the opposite case. In this example, let us assume
mm, corresponding to
mm. Now it is possible to calculate the millimeters-to-pixels resolution ratio
as follows:
A low value of
corresponds to a higher number of pixels needed to represent a millimeter, thus producing image details with a higher number of pixels. Having a sufficient number of pixels to represent the smallest target object in the image is key to successful computer vision applications. For this example, it results in
mm/px. Then, the minimum and maximum vehicle speeds can be obtained using the following formulas:
This results in mm/s m/s km/h and m/s km/h. Given the described camera, the tractor must maintain its velocity between and to obtain the most reliable depth measurements.
3.2.2. Choose the Correct Camera for the Target Application Given the Vehicle Speed
In the second scenario, the vehicle speed and the working distance are already defined and the question is about the choice of the right camera for the application. For the sake of the example, let us consider
km/h
m/s
mm/s and
mm. Hence, by inverting Equation (
13) and considering
px/s (which is the optimal image velocity resulting from our experiments), the result is
mm/px. Let us assume that, for the target application, at least
mm must be viewed by the camera. Inverting Equation (
12) results in
px. The end-user is now encouraged to search among the plethora of available cameras on the market with a pixel resolution along
X at least equal to 360 px, a requirement easily fulfilled nowadays. After selecting the best product for its needs, it is straightforward to also select the optics by using Equation (
11) to find the value of
f. Once again, the resulting value is the optimal one obtained from mathematical formulations; thus, it may differ from what is available on the market. The process of finding the right camera and optics may be a long one since it requires adjustments and comparisons with several products.
Finally, two considerations should be made about possible aberrations appearing in the acquired frames when using cameras for on-the-go acquisitions. The first issue is motion blur, an effect appearing when the vehicle moves too fast and the camera acquires too slowly. In this case, it is recommended to use cameras with high fps. The second issue is about the camera’s shutter. Low-cost cameras are typically equipped with a rolling shutter; however, this results in the upper and bottom portions of the image corresponding to two different scenes, an issue especially for fast movements (a typical example is the picture of a fan). To avoid this issue, it is recommended to choose cameras equipped with a global shutter.
4. Conclusions
The presented work deals with the topic of depth estimation from a moving monocular 2D camera, leveraging optical flow. Starting from the classic analytical model used to estimate depth from moving images, an experimental model that is easier to apply for end-users is proposed and validated. The experimental setup comprises a robot that simulates the moving vehicle, on which the camera is mounted. The target measurand is a rigid frame with five bars of different lengths mounted on it to simulate objects positioned at different depths. On top of each bar, an ArUco marker was fixed. A total of five experiments were conducted by actuating the robot at five speeds, each time recording a video that contains both positive and negative robot motions. The developed software analyzes the videos to extract the ArUco markers’ apparent depth (Z) and compute the optical flow () from pairs of images. A window-based moving average filter was developed and applied to the acquired data to reduce noise and improve the final uncertainty.
The core of this work lies in the metrological validation of the system and the computation of measurement uncertainty, for which two approaches are proposed as follows: the generalized approach and the complete approach. In the case of the generalized approach, the best-case scenario is obtained for robot speeds equal to m/s and m/s, for which the corresponding uncertainty on depth estimation is m (no filter) and m (filter applied) for , and m (no filter) and m (filter applied) for . The complete approach separates the depth data according to their speed to deal with the exponential nature of the models, producing group-separated results for each model with and without filtering. Again, the best case scenario is obtained for robot speed equal to or .
Another interesting conclusion useful for end-users is that the experiments highlighted that low image speeds increase the total uncertainty when the pixel displacement between two consecutive images is insufficient, thus reducing the robustness of the optical flow algorithm. This effect directly impacts both the vehicle speed and the camera’s acquisition rate. Generally, it is shown that for image speeds higher than 500–800 px/s, uncertainty on depth estimation drops below 200 mm. This outcome is especially useful for applications such as on-the-go depth measurements in scenarios where 100 to 200 mm uncertainty is acceptable, such as agriculture. In fact, in this specific context, it is common to have low-cost cameras mounted on moving vehicles and the main questions are as follows: “Given a certain camera, at which speed should the vehicle move to get stable depth readings?” and “Which camera should be bought if the vehicle moves at a certain speed?” To answer these questions, two practical examples are presented and discussed, showing how the proposed work can be effectively employed by end-users in the two most common scenarios.
To conclude, the presented work is a stepping stone towards the development of reliable, easy-to-use, and low-cost embedded measuring systems suitable for in-field measurements for a plethora of applications, especially in agriculture. Future work will be devoted to the optimization of the presented methodology by combining it with modern Deep Learning models; for example, for fruit counting and measurements.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}