
Regression-Based Docking System for Autonomous Mobile Robots Using a Monocular Camera and ArUco Markers

Abstract
1. Introduction
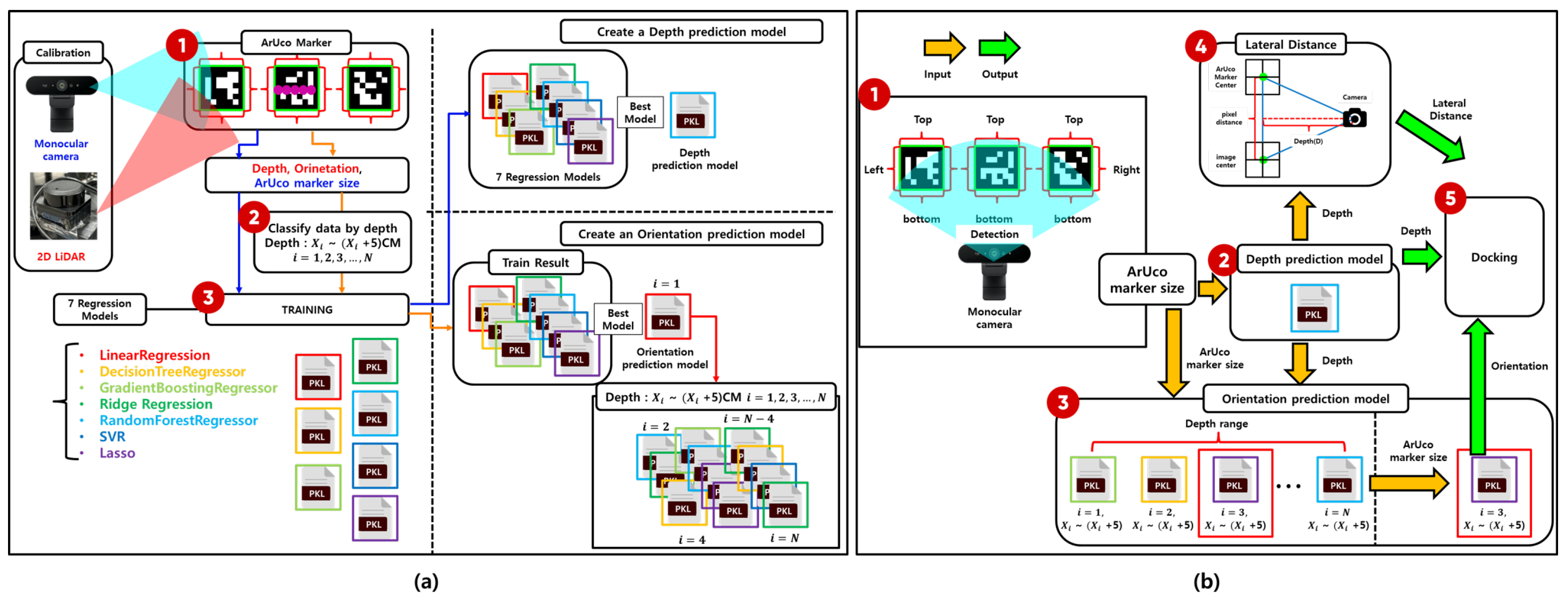
2. Overview of the Proposed Method
3. Proposed Depth and Orientation Estimation Concept
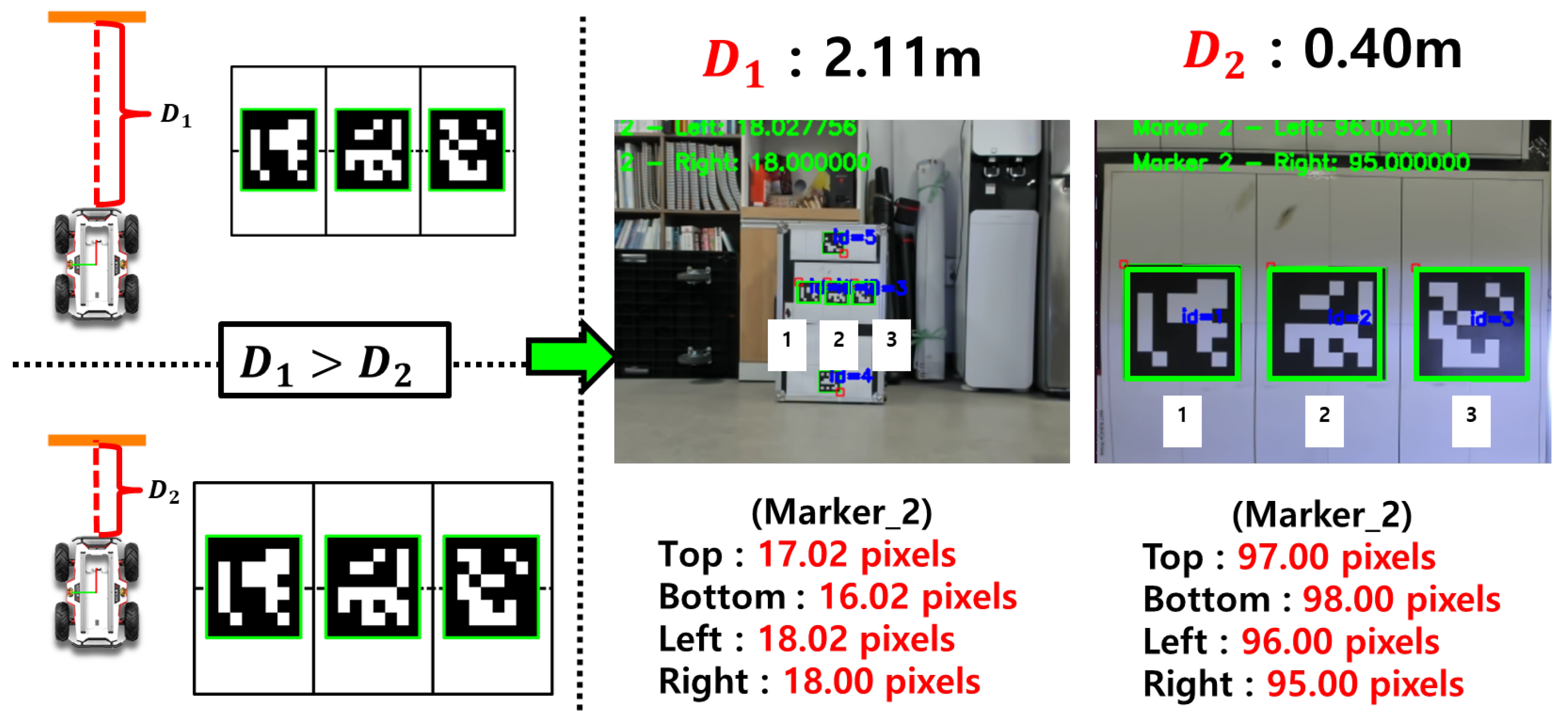
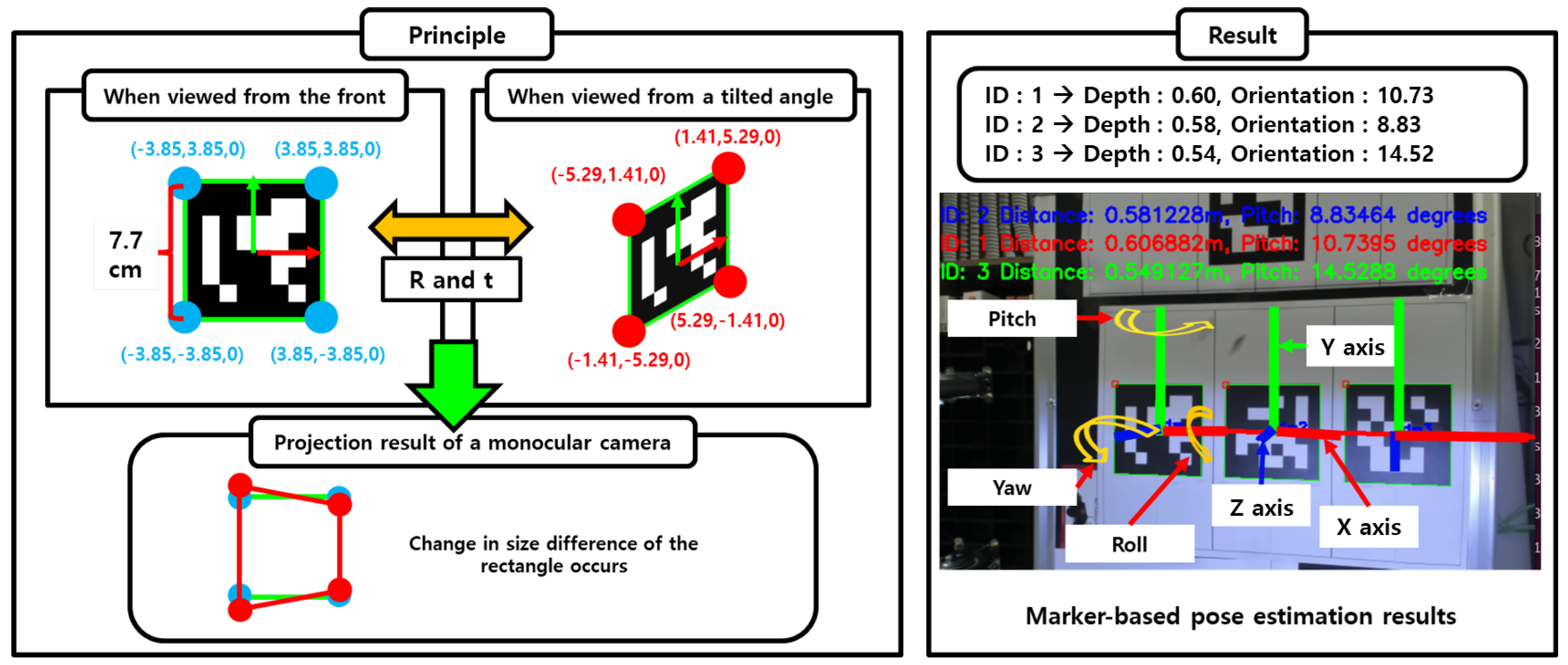
3.1. Depth Estimation from a Monocular Camera Using Marker Size and Regression
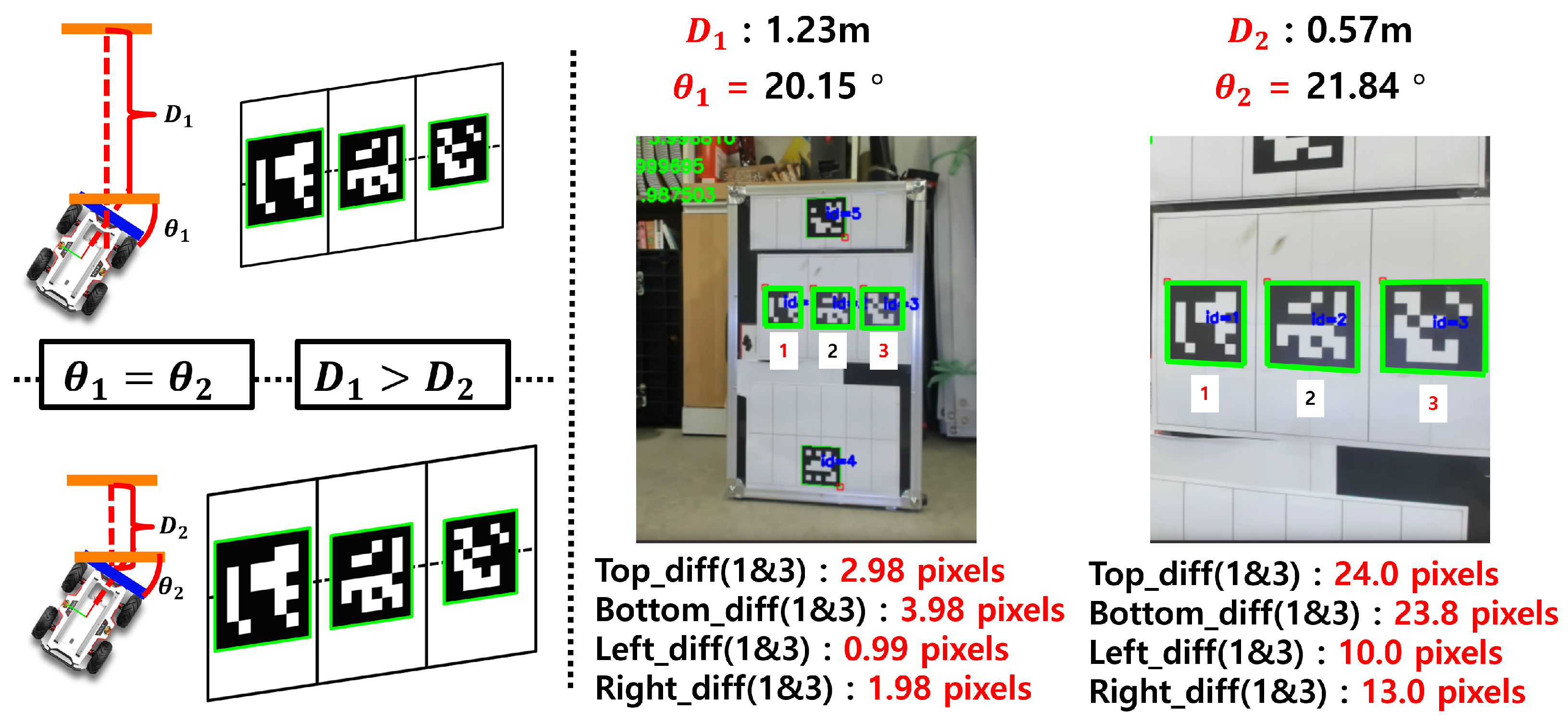
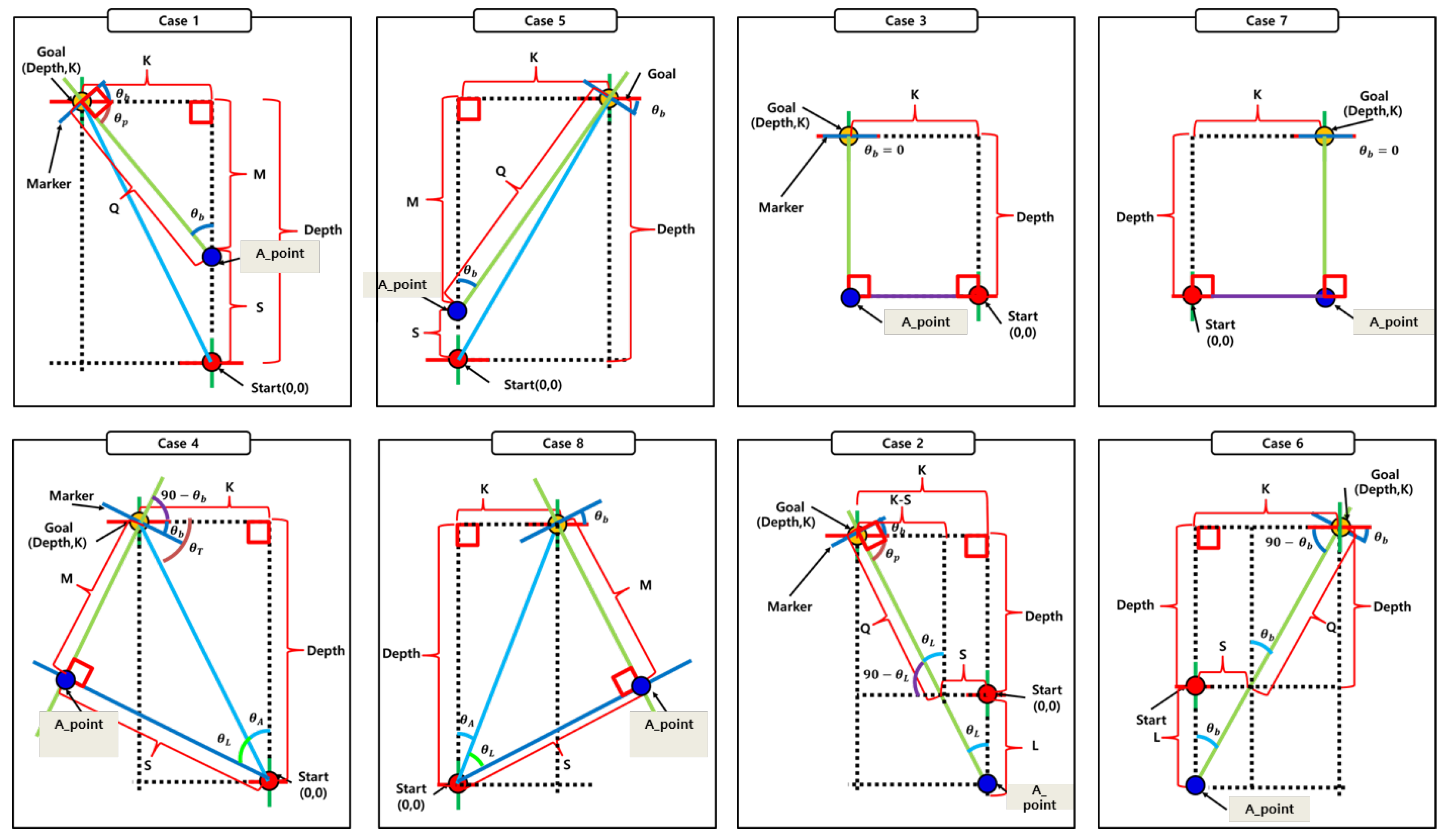
3.2. Orientation Estimation from a Monocular Camera Using Marker Shape and Regression
3.3. Segmented Regression Approach to Address Depth–Orientation Interference
4. Model Training for Depth and Orientation Prediction
4.1. Sensor Calibration and Ground-Truth Acquisition for Regression Model Training
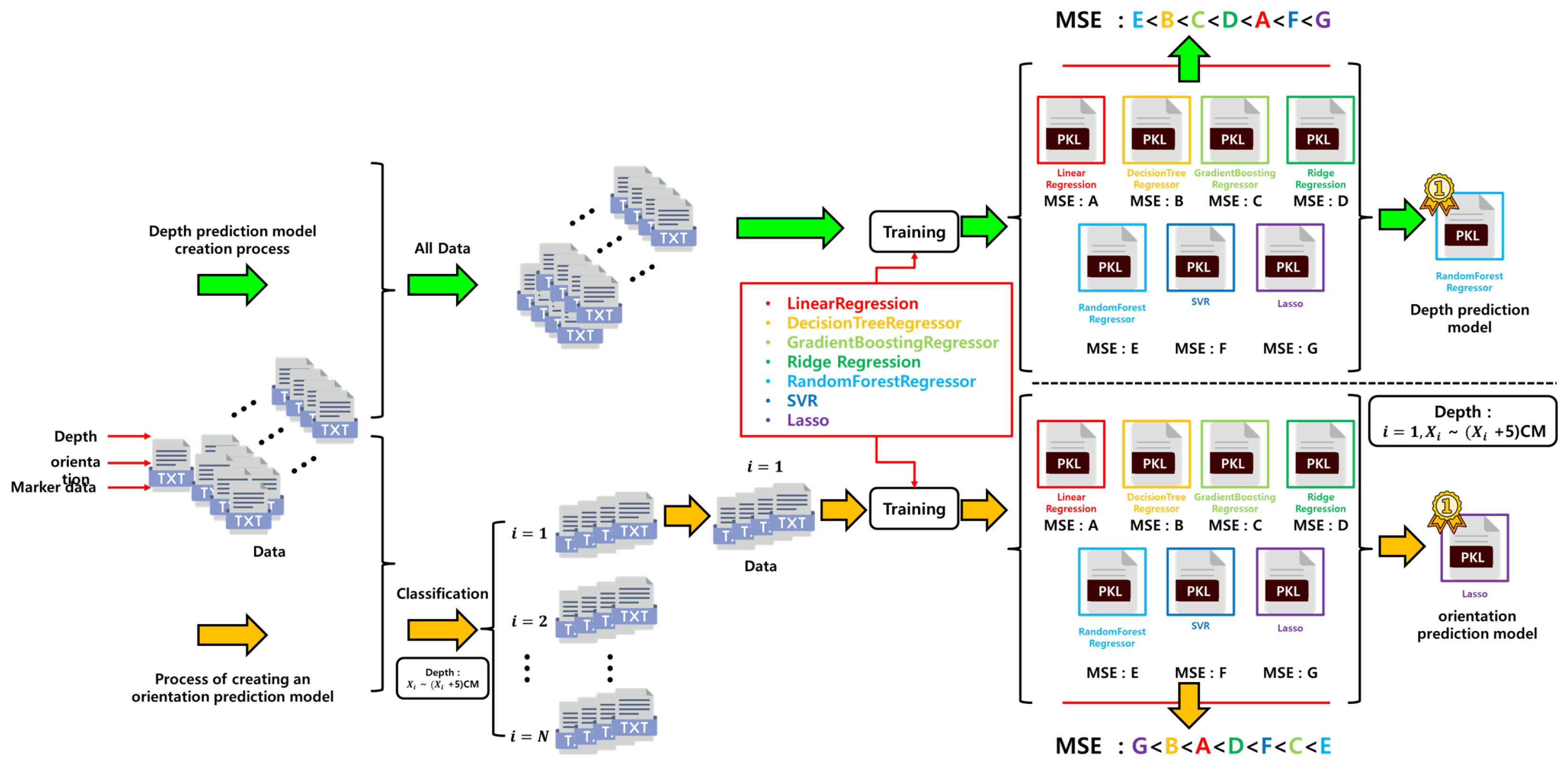
4.2. Development of Distance and Orientation Prediction Models Using Regression
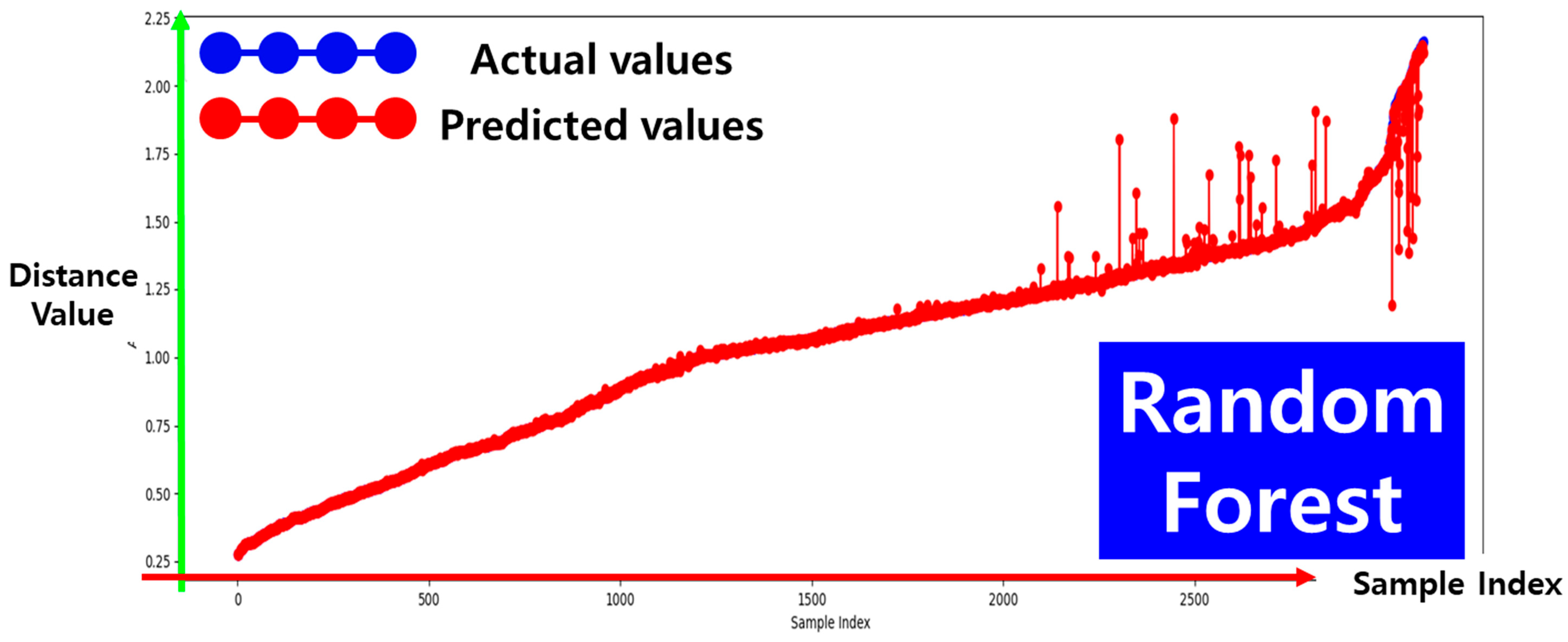
4.3. Performance Analysis of the Depth Prediction Model
4.4. Performance Analysis of the Orientation Prediction Model
4.5. Existing Monocular Depth and Orientation Estimation Method: SolvePnP
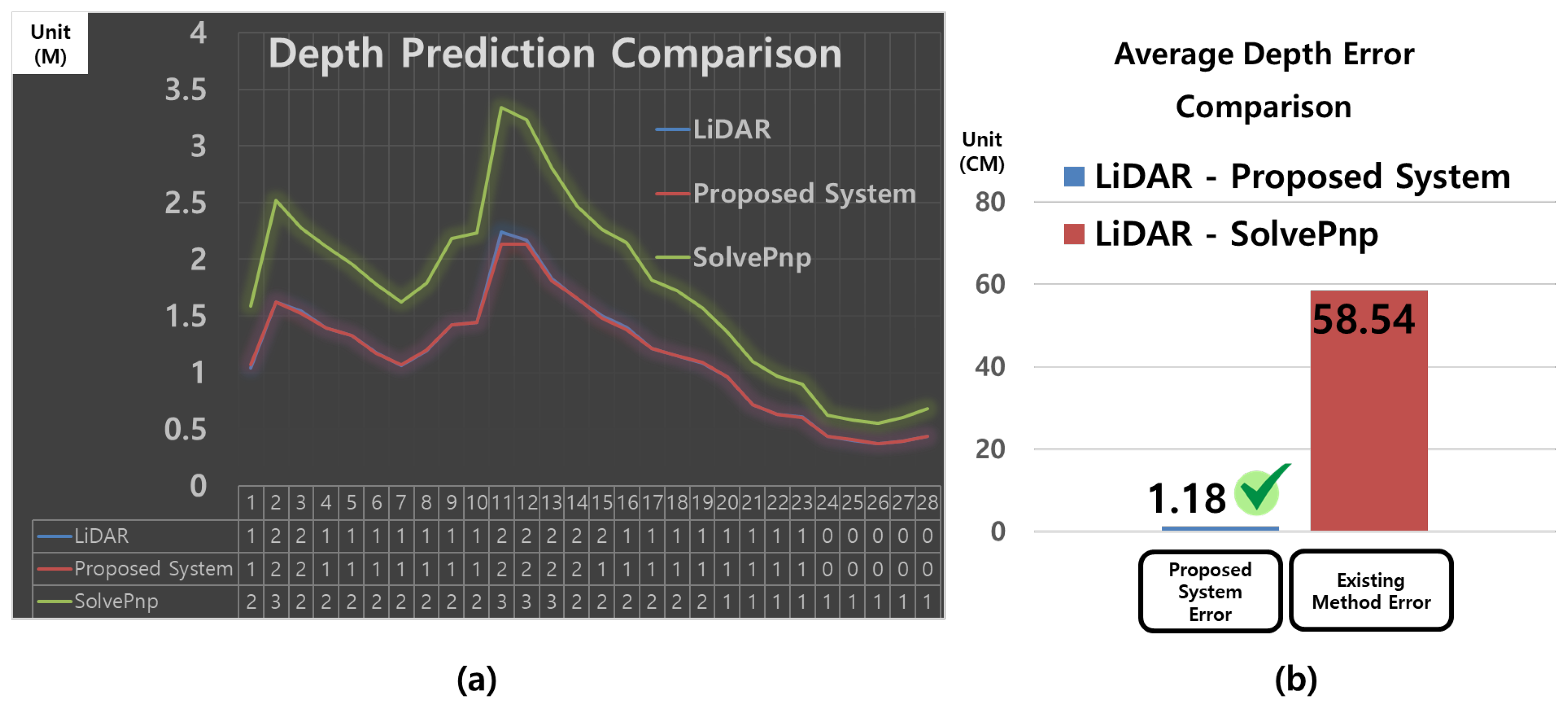
4.6. Comparison of Depth Estimation Performance Between the Proposed System and Existing Methods
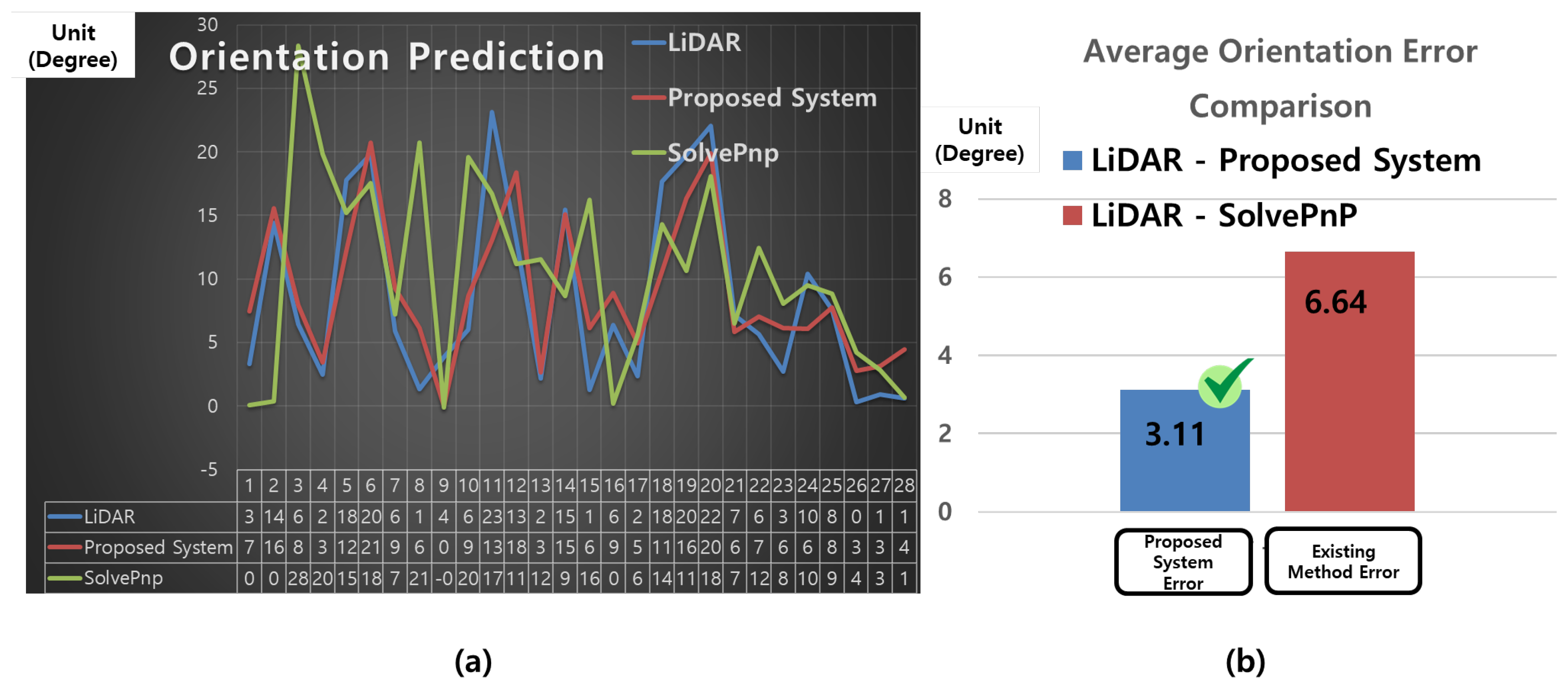
4.7. Comparison of Orientation Prediction Performance Between the Proposed System and Existing Methods
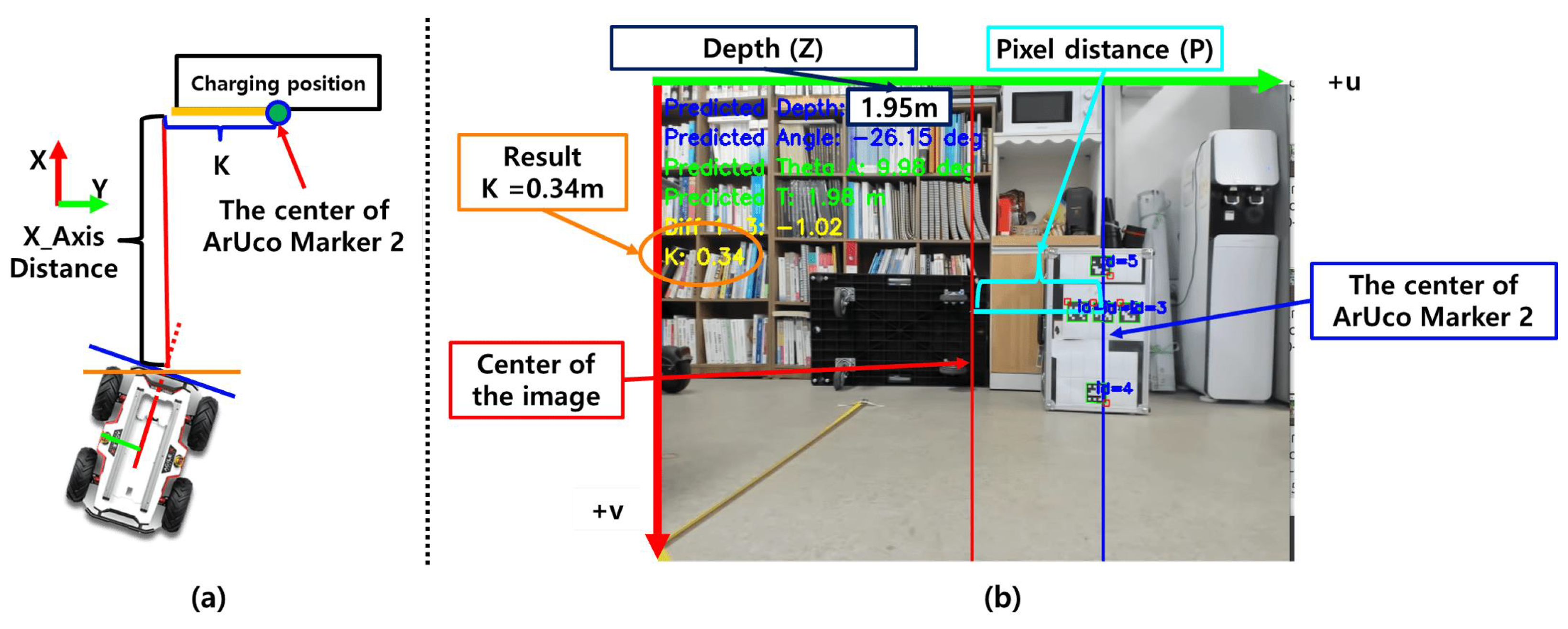
4.8. Estimation of the Relative Lateral Distance Between the Robot and Charger
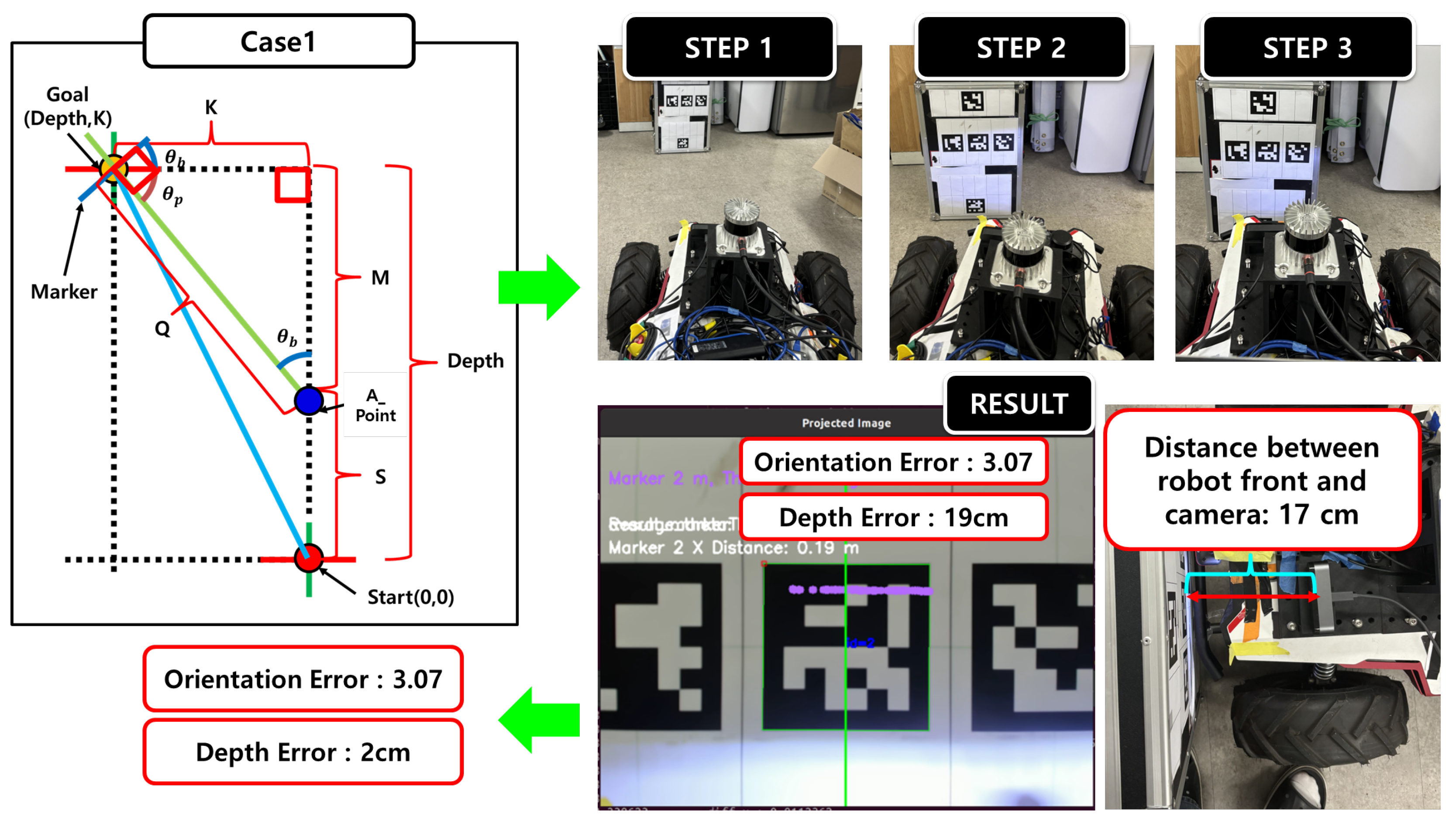
4.9. Docking Procedure
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khattak, M.A.; Al-Fuqaha, A.; Guizani, M.; Hassan, N.A. Review of autonomous mobile robots in intralogistics: State-of-the-art. Comput. Ind. 2024, 151, 103985. [Google Scholar]
- Braga, R.G.; Tahir, M.O.; Iordanova, I.; St-Onge, D. Robotic deployment on construction sites: Considerations for safety and productivity impact. Autom. Constr. 2024, 159, 105257. [Google Scholar]
- Sun, Y.; Wang, J.; Wang, L.; Wu, Y. A monocular vision-based autonomous navigation method for low-cost mobile robots. Robot. Auton. Syst. 2023, 161, 104368. [Google Scholar]
- Fu, C.; Hu, X.; Wu, H.; Deng, H. Multi-robot Cooperative Path Optimization Approach for Multi-objective Coverage in a Congestion Risk Environment. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5821–5832. [Google Scholar]
- Zhang, Q.; Yin, Y.; Wang, S. Path Planning for Monocular Vision-Based Indoor Robots Using Reinforcement Learning. Sensors 2023, 23, 6413. [Google Scholar]
- Li, R.; Wang, Y.; Chen, J.; Xue, W. Multi-Robot Path Planning Based on Adaptive Grid and Q-Learning in Dynamic Environments. Robotics 2024, 13, 50. [Google Scholar]
- Tourani, A.; Bavle, H.; Sanchez-Lopez, J.L.; Munoz-Salinas, R.; Voos, H. Marker-based visual SLAM leveraging hierarchical representations. Robot. Auton. Syst. 2024, 164, 104436. [Google Scholar]
- Akhtar, A.; Siddiqui, F.; Malik, M.A. Evaluation of pose estimation using fiducial markers in industrial environments. In Proceedings of the IEEE CASE 2022, Mexico City, Mexico, 20–24 August 2022; pp. 456–461. [Google Scholar]
- Li, J.; Sun, X.; Wang, T. Wide-orientation, monocular head tracking using passive markers. PLoS ONE 2022, 17, e0262023. [Google Scholar]
- Seber, G.A.F.; Lee, A.J. Linear Regression Analysis, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2003. [Google Scholar]
- Zhou, Z.; Qiu, C.; Zhang, Y. A comparative analysis of linear regression, neural networks and random forest regression for predicting air ozone employing soft sensor models. Sci. Rep. 2023, 13, 22420. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Nakatsu, R.T. Validation of machine learning ridge regression models using Monte Carlo, bootstrap, and variations in cross-validation. J. Intell. Syst. 2023, 32, 20220224. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Levent, İ.; Şahin, G.; Işık, G.; van Sark, W.G.J.H.M. Comparative analysis of advanced machine learning regression models with advanced artificial intelligence techniques to predict rooftop PV solar power plant efficiency using indoor solar panel parameters. Appl. Sci. 2025, 15, 3320. [Google Scholar] [CrossRef]
- Bhattacharyya, J. LASSO regression—A procedural improvement. Mathematics 2025, 13, 532. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Best Test MSE | Best Test |
|---|---|---|
| Linear Regression | 0.0233 | 0.8350 |
| Ridge Regression | 0.0255 | 0.8192 |
| Lasso Regression | 0.0352 | 0.7505 |
| Decision Tree | 0.0014 | 0.9901 |
| Random Forest | 0.0009 | 0.9937 |
| SVR | 0.0120 | 0.9148 |
| Gradient Boosting | 0.0017 | 0.9880 |
| Depth Range (25–140 cm) | Depth Range (145–250 cm) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Distance | N | Regression Model | MSE | Distance | N | Regression Model | MSE | ||
| 25–30 cm | 69 | Gradient Boosting | 0.0099 | 0.9847 | 135–140 cm | 705 | Random Forest | 3.5072 | 0.8887 |
| 30–35 cm | 276 | Gradient Boosting | 0.0814 | 0.9773 | 140–145 cm | 598 | Random Forest | 1.7674 | 0.9393 |
| 35–40 cm | 335 | Random Forest | 0.0932 | 0.9343 | 145–150 cm | 396 | Gradient Boosting | 1.3094 | 0.9430 |
| 40–45 cm | 431 | Decision Tree | 0.0814 | 0.9770 | 150–155 cm | 458 | Random Forest | 1.9674 | 0.9341 |
| 45–50 cm | 429 | Gradient Boosting | 0.3576 | 0.9854 | 155–160 cm | 193 | Gradient Boosting | 3.0796 | 0.9426 |
| 50–55 cm | 428 | Gradient Boosting | 0.4795 | 0.9785 | 160–165 cm | 138 | Decision Tree | 0.3289 | 0.9897 |
| 55–60 cm | 366 | Random Forest | 0.2585 | 0.9799 | 165–170 cm | 117 | Decision Tree | 1.0112 | 0.9505 |
| 60–65 cm | 460 | Random Forest | 1.6030 | 0.8857 | 170–175 cm | 101 | Decision Tree | 2.4376 | 0.5530 |
| 65–70 cm | 577 | Random Forest | 0.5087 | 0.9754 | 175–180 cm | 23 | Gradient Boosting | 12.7052 | 0.5293 |
| 70–75 cm | 494 | Decision Tree | 0.4155 | 0.9578 | 180–185 cm | 21 | Decision Tree | 0.0257 | 0.4752 |
| 75–80 cm | 442 | Random Forest | 0.5615 | 0.9880 | 185–190 cm | 18 | Random Forest | 0.2498 | 0.9982 |
| 80–85 cm | 338 | Gradient Boosting | 0.6338 | 0.9779 | 190–195 cm | 49 | Ridge Regression | 1.4240 | 0.8733 |
| 85–90 cm | 369 | Random Forest | 0.3977 | 0.9930 | 195–200 cm | 83 | Random Forest | 2.9834 | 0.7437 |
| 90–95 cm | 469 | Random Forest | 0.9296 | 0.9768 | 200–205 cm | 63 | Ridge Regression | 2.1568 | 0.8631 |
| 95–100 cm | 433 | Random Forest | 0.7588 | 0.9839 | 205–210 cm | 61 | Gradient Boosting | 0.5281 | 0.9918 |
| 100–105 cm | 957 | Random Forest | 1.4792 | 0.9793 | 210–215 cm | 93 | Gradient Boosting | 2.1457 | 0.9265 |
| 105–110 cm | 982 | Random Forest | 0.7898 | 0.9859 | 215–220 cm | 49 | Random Forest | 0.2762 | 0.9541 |
| 110–115 cm | 853 | Random Forest | 1.3915 | 0.9734 | 220–225 cm | 9 | Linear Regression | 0.0181 | 0.9988 |
| 115–120 cm | 977 | Random Forest | 1.2175 | 0.9818 | 225–230 cm | 7 | Linear Regression | 0.2861 | 0.0264 |
| 120–125 cm | 934 | Random Forest | 2.0215 | 0.9733 | 230–235 cm | 8 | Random Forest | 0.9308 | 0.1611 |
| 125–130 cm | 703 | Random Forest | 2.6560 | 0.9523 | 235–240 cm | 10 | Linear Regression | 1.3492 | 0.3258 |
| 130–135 cm | 909 | Random Forest | 1.9862 | 0.9543 | 240–245 cm | 47 | Decision Tree | 1.1248 | 0.9142 |
| Avg | – | – | 1.5185 | 0.915 | |||||
| Model | 140–145 cm | 145–150 cm | 150–155 cm | 155–160 cm | 160–165 cm |
|---|---|---|---|---|---|
| Decision Tree | 1.8441 | 1.5568 | 1.9931 | 5.8053 | 0.3289 |
| Gradient Boosting | 1.7674 | 1.3094 | 2.0993 | 3.0796 | 0.6183 |
| Lasso Regression | 27.3481 | 26.4010 | 26.9940 | 27.5812 | 19.4641 |
| Linear Regression | 27.5862 | 26.7054 | 27.2161 | 264.1204 | 19.8546 |
| Random Forest | 1.8173 | 1.4074 | 1.9674 | 3.2851 | 0.4118 |
| Ridge Regression | 20.9879 | 20.4370 | 21.0114 | 17.7053 | 15.0084 |
| SVR | 28.9687 | 28.7546 | 33.2085 | 55.4888 | 30.5262 |
| Index 1–14 | Index 15–28 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Idx | A | B | C | D | E | Idx | A | B | C | D | E |
| 1 | 1.04 | 1.07 | 1.59 | 0.03 | 0.55 | 15 | 1.50 | 1.48 | 2.26 | 0.02 | 0.76 |
| 2 | 1.62 | 1.62 | 2.52 | 0.00 | 0.90 | 16 | 1.40 | 1.38 | 2.15 | 0.02 | 0.75 |
| 3 | 1.54 | 1.52 | 2.28 | 0.02 | 0.74 | 17 | 1.21 | 1.21 | 1.82 | 0.00 | 0.61 |
| 4 | 1.39 | 1.39 | 2.11 | 0.00 | 0.72 | 18 | 1.15 | 1.15 | 1.72 | 0.00 | 0.57 |
| 5 | 1.33 | 1.33 | 1.96 | 0.00 | 0.63 | 19 | 1.08 | 1.09 | 1.57 | 0.01 | 0.49 |
| 6 | 1.18 | 1.17 | 1.78 | 0.01 | 0.60 | 20 | 0.96 | 0.96 | 1.36 | 0.00 | 0.40 |
| 7 | 1.06 | 1.07 | 1.62 | 0.01 | 0.56 | 21 | 0.72 | 0.72 | 1.10 | 0.00 | 0.38 |
| 8 | 1.19 | 1.20 | 1.79 | 0.01 | 0.60 | 22 | 0.63 | 0.63 | 0.97 | 0.00 | 0.34 |
| 9 | 1.42 | 1.42 | 2.18 | 0.00 | 0.76 | 23 | 0.61 | 0.60 | 0.90 | 0.01 | 0.29 |
| 10 | 1.44 | 1.44 | 2.23 | 0.00 | 0.79 | 24 | 0.44 | 0.44 | 0.62 | 0.00 | 0.18 |
| 11 | 2.24 | 2.13 | 3.34 | 0.11 | 1.10 | 25 | 0.40 | 0.41 | 0.58 | 0.01 | 0.18 |
| 12 | 2.17 | 2.13 | 3.23 | 0.04 | 1.06 | 26 | 0.37 | 0.37 | 0.55 | 0.00 | 0.18 |
| 13 | 1.83 | 1.81 | 2.81 | 0.02 | 0.98 | 27 | 0.39 | 0.39 | 0.60 | 0.00 | 0.21 |
| 14 | 1.65 | 1.66 | 2.47 | 0.01 | 0.82 | 28 | 0.44 | 0.44 | 0.68 | 0.00 | 0.24 |
| Avg | – | – | – | 0.01 | 0.59 | ||||||
| Index 1–14 | Index 15–28 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Idx | A | B | C | D | E | Idx | A | B | C | D | E |
| 1 | 3.32° | 7.45° | 0.08° | 4.13° | 3.24° | 15 | 1.29° | 6.12° | 16.22° | 4.83° | 14.93° |
| 2 | 14.44° | 15.59° | 0.36° | 1.15° | 14.08° | 16 | 6.40° | 8.91° | 0.172° | 2.51° | 6.23° |
| 3 | 6.44° | 7.91° | 28.37° | 1.47° | 21.93° | 17 | 2.38° | 4.91° | 5.62° | 2.53° | 3.24° |
| 4 | 2.47° | 3.46° | 19.84° | 0.99° | 17.37° | 18 | 17.64° | 10.57° | 14.29° | 7.07° | 3.35° |
| 5 | 17.81° | 12.19° | 15.21° | 5.62° | 2.60° | 19 | 19.78° | 16.32° | 10.65° | 3.46° | 9.13° |
| 6 | 19.83° | 20.74° | 17.53° | 0.91° | 2.30° | 20 | 22.03° | 19.87° | 18.09° | 2.16° | 3.94° |
| 7 | 5.92° | 9.26° | 7.20° | 3.34° | 1.28° | 21 | 7.17° | 5.85° | 6.52° | 1.32° | 0.65° |
| 8 | 1.32° | 6.14° | 20.75° | 4.82° | 19.43° | 22 | 5.63° | 7.02° | 12.42° | 1.39° | 6.79° |
| 9 | 3.88° | 0.00° | −0.12° | 3.88° | 4.00° | 23 | 2.74° | 6.13° | 8.03° | 3.39° | 5.29° |
| 10 | 6.01° | 8.68° | 19.59° | 2.67° | 13.58° | 24 | 10.40° | 6.05° | 9.50° | 4.35° | 0.90° |
| 11 | 23.11° | 13.03° | 16.70° | 10.08° | 6.41° | 25 | 7.55° | 7.73° | 8.83° | 0.18° | 1.28° |
| 12 | 13.05° | 18.41° | 11.18° | 5.36° | 1.87° | 26 | 0.29° | 2.79° | 4.23° | 2.50° | 3.94° |
| 13 | 2.20° | 2.67° | 11.57° | 0.47° | 9.37° | 27 | 0.90° | 3.13° | 2.84° | 2.23° | 1.94° |
| 14 | 15.43° | 15.09° | 8.65° | 0.34° | 6.78° | 28 | 0.64° | 4.43° | 0.68° | 3.79° | 0.04° |
| Avg | – | – | – | 3.11° | 6.64° | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, J.S.; Kim, M.Y. Regression-Based Docking System for Autonomous Mobile Robots Using a Monocular Camera and ArUco Markers. Sensors 2025, 25, 3742. https://doi.org/10.3390/s25123742
Oh JS, Kim MY. Regression-Based Docking System for Autonomous Mobile Robots Using a Monocular Camera and ArUco Markers. Sensors. 2025; 25(12):3742. https://doi.org/10.3390/s25123742
Chicago/Turabian StyleOh, Jun Seok, and Min Young Kim. 2025. "Regression-Based Docking System for Autonomous Mobile Robots Using a Monocular Camera and ArUco Markers" Sensors 25, no. 12: 3742. https://doi.org/10.3390/s25123742
APA StyleOh, J. S., & Kim, M. Y. (2025). Regression-Based Docking System for Autonomous Mobile Robots Using a Monocular Camera and ArUco Markers. Sensors, 25(12), 3742. https://doi.org/10.3390/s25123742