
HGCS-Det: A Deep Learning-Based Solution for Localizing and Recognizing Household Garbage in Complex Scenarios
 ,
, 
Abstract
1. Introduction
- Enhanced Attention Calibration: We introduce a normalization-based attention mechanism to guide the model toward critical target features while suppressing background noise. Furthermore, an Attention Feature Fusion (AFF) module is designed to adaptively integrate attention weights across channels using instance normalization and channel shuffling, ensuring more effective utilization of attention features.
- Instance Boundary Reinforcement: To improve the extraction of fine-grained features from irregularly shaped garbage objects, we propose an Instance Boundary Reinforcement (IBR) module. This module fuses gradient-based boundary cues with high-level semantic features to strengthen the representation of object contours.
- Hard-Sample Optimization with Slide Loss: We incorporate the Slide Loss function to dynamically reweight hard samples during training. This strategy improves the model’s sensitivity to ambiguous samples in transitional regions between the background and foreground, enhancing the overall detection accuracy.
2. Related Work
3. Materials and Methods
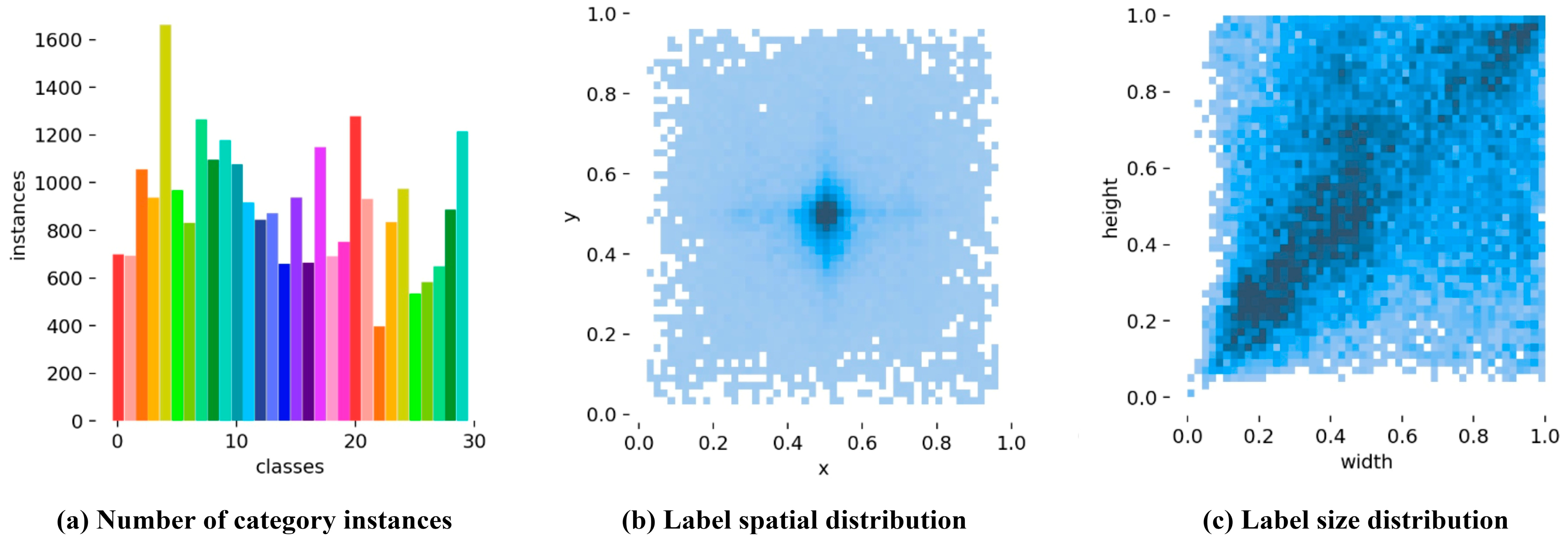
3.1. Dataset HGI30
3.2. Overview of YOLOv8
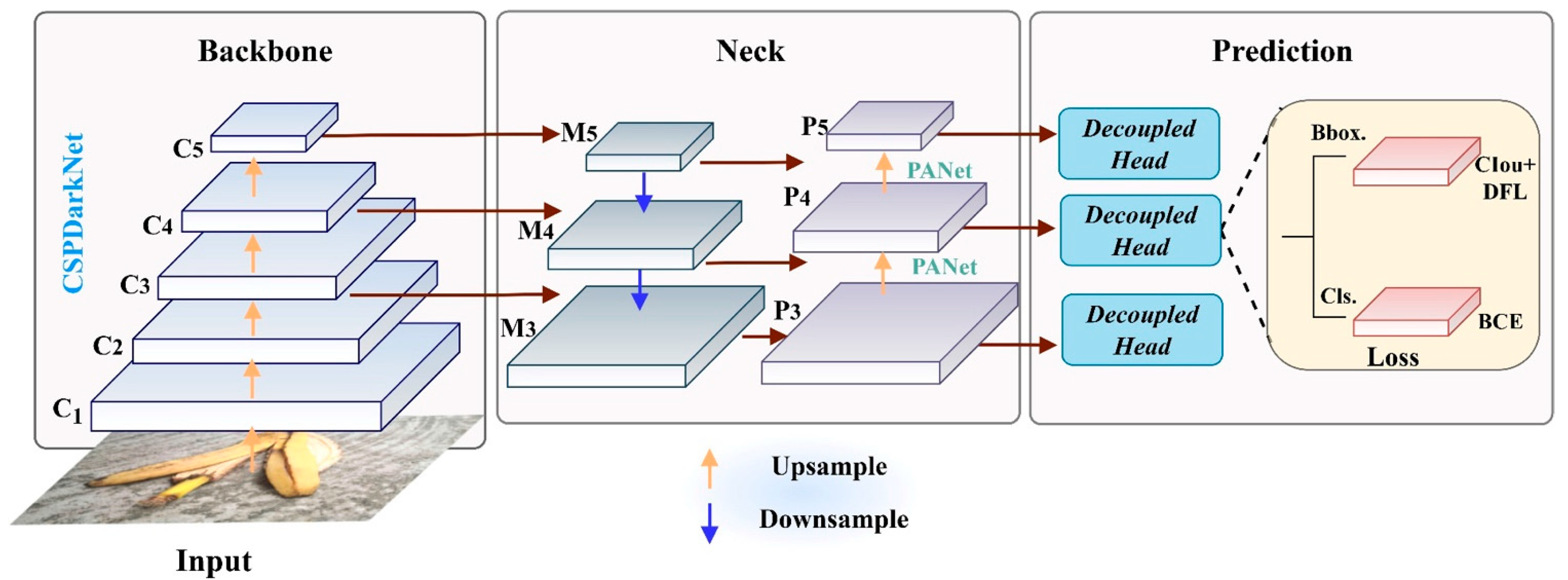
3.3. The Proposed Model
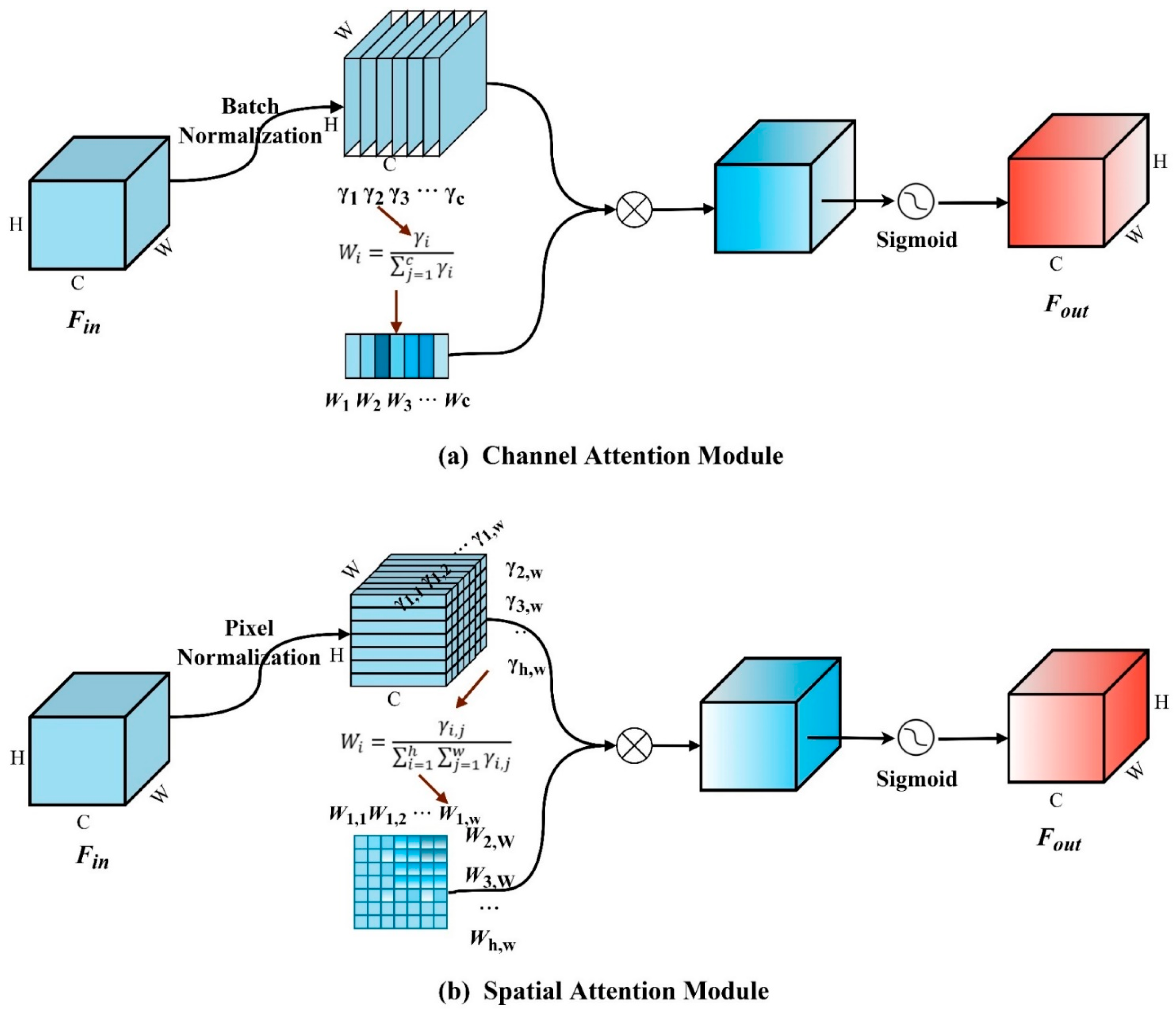
3.4. Normalization-Based Attention Module
3.5. Attention Feature Fusion Module
3.6. Instance Boundary Reinforcement Module
3.7. Slide Loss
4. Experiments and Results
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Evaluation of the Enhanced Attention Mechanism Module
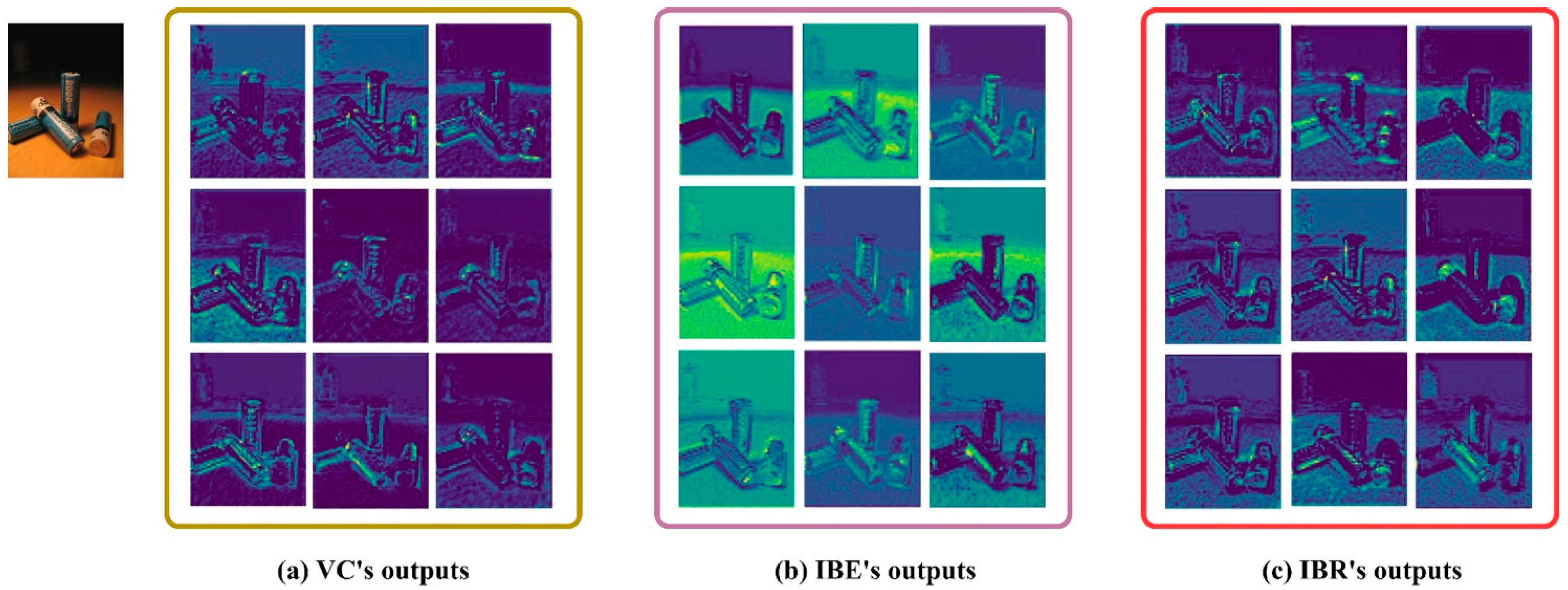
4.4. Evaluation of the Instance Boundary Reinforcement Module
4.5. Evaluation of Slide Loss
4.6. Evaluation of the Proposed Model
4.6.1. Ablation Experiments
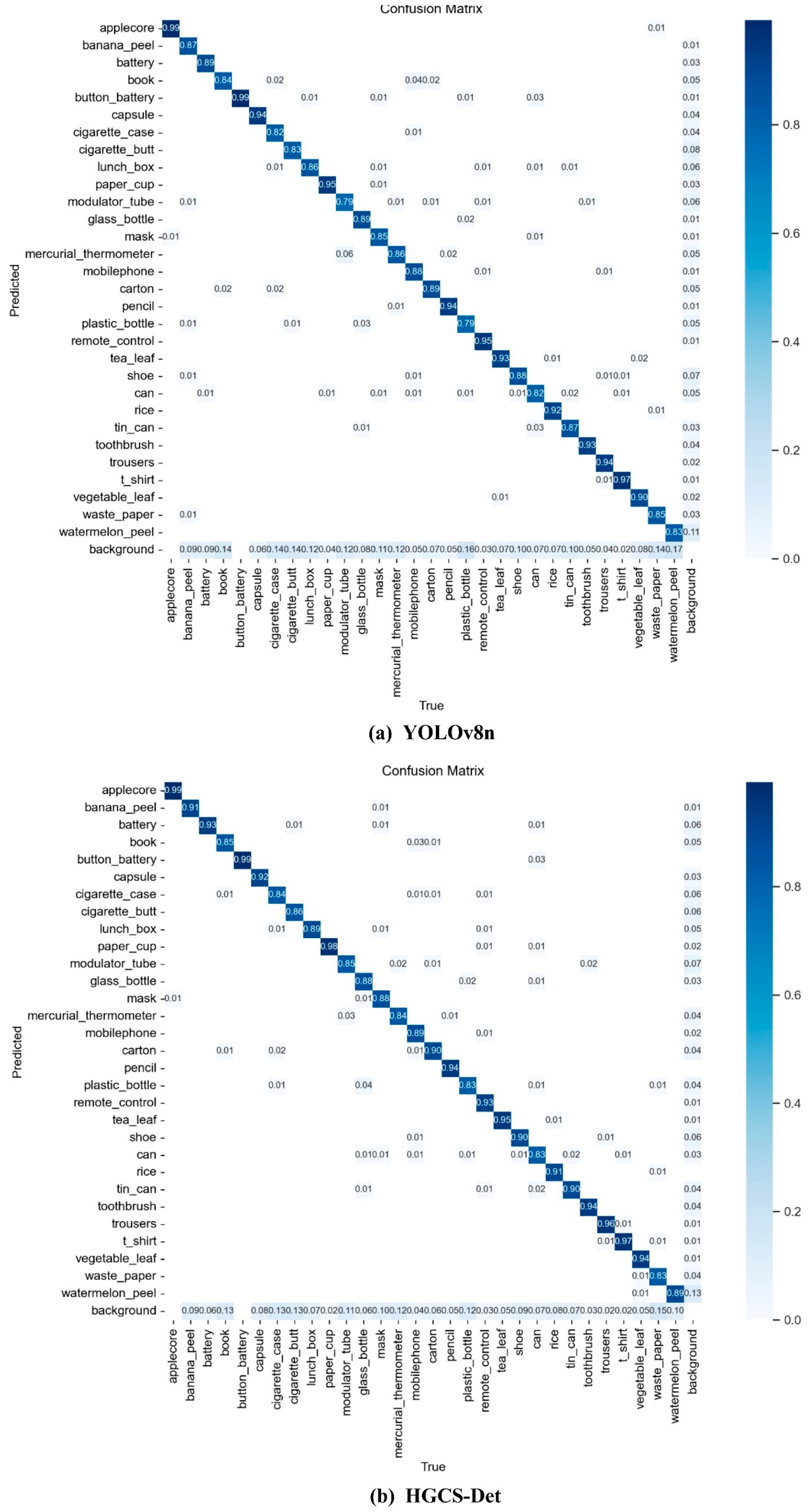
4.6.2. Qualitative Analysis
4.7. Model Performance Comparison
4.7.1. Comparison of Results with Previous Work
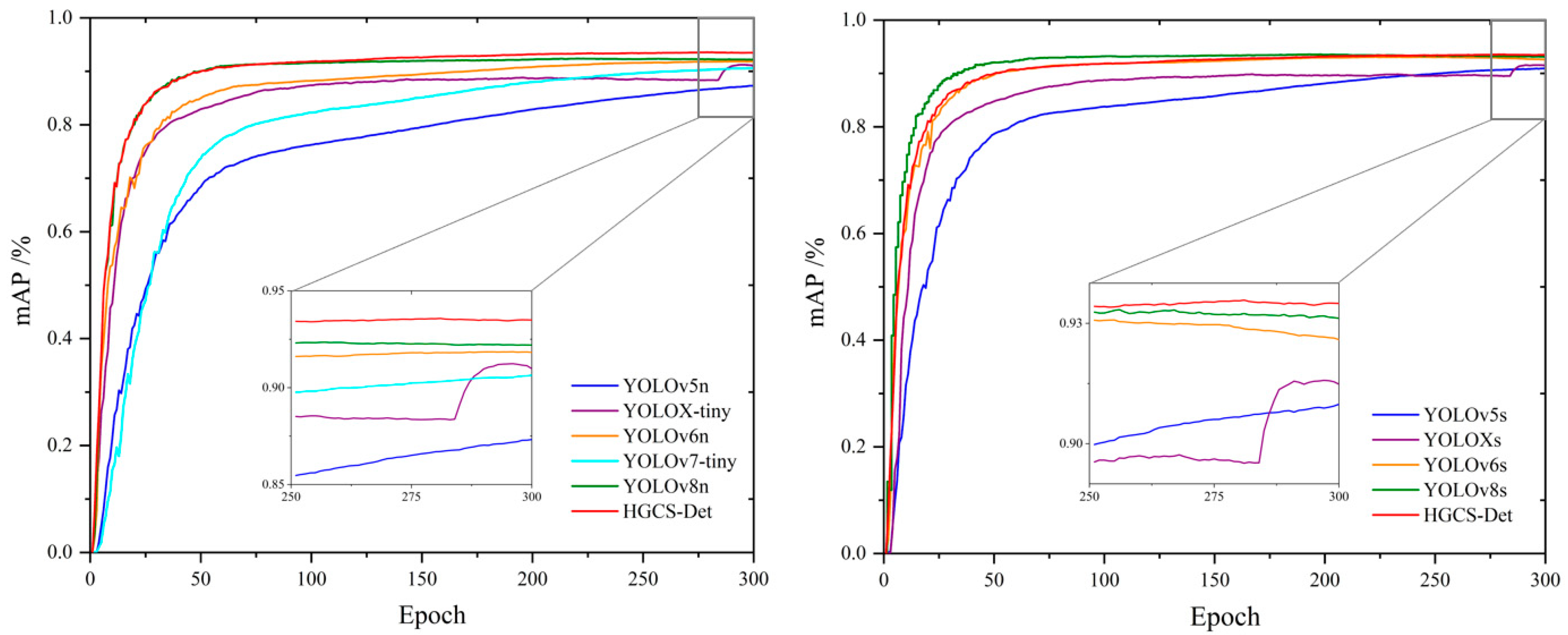
4.7.2. Comparison with Mainstream Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaza, S.; Yao, L.; Bhada-Tata, P.; Van Woerden, F. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050; World Bank Publications: Washington, DC, USA, 2018. [Google Scholar]
- Chu, X.; Chu, Z.; Huang, W.-C.; He, Y.; Chen, M.; Abula, M. Assessing the Implementation Effect of Shanghai’s Compulsory Municipal Solid Waste Classification Policy. J. Mater. Cycles Waste Manag. 2023, 25, 1333–1343. [Google Scholar] [CrossRef]
- Zhang, S.; Hu, D.; Lin, T.; Li, W.; Zhao, R.; Yang, H.; Pei, Y.; Jiang, L. Determinants Affecting Residents’ Waste Classification Intention and Behavior: A Study Based on TPB and A-B-C Methodology. J. Environ. Manag. 2021, 290, 112591. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A General Framework for Object Detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Salimi, I.; Dewantara, B.S.B.; Wibowo, I.K. Visual-Based Trash Detection and Classification System for Smart Trash Bin Robot. In Proceedings of the 2018 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Bali, Indonesia, 29–30 October 2018. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Pan, H.; Guan, S.; Zhao, X. LVD-YOLO: An Efficient Lightweight Vehicle Detection Model for Intelligent Transportation Systems. Image Vis. Comput. 2024, 151, 105276. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Red Hook: Brooklyn, NY, USA, 2015. [Google Scholar]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep Absolute Pose Regression with Synthetic Views. arXiv 2017, arXiv:1712.03452. [Google Scholar]
- Wang, Y.; Wang, J.; Sun, A.; Zhang, Y. LWCNet: A Lightweight and Efficient Algorithm for Household Waste Detection and Classification Based on Deep Learning. Sensors 2024, 24, 1234. [Google Scholar]
- Zhang, Y.; Wang, L. Research on Lightweight Scenic Area Detection Algorithm Based on Small Targets. Electronics 2025, 14, 356. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, A.; Cheng, M.; Wu, Y.; Zhu, J.; Meng, Y.; Tan, W. Classification and Recycling of Recyclable Garbage Based on Deep Learning. J. Clean. Prod. 2023, 414, 137558. [Google Scholar] [CrossRef]
- Sun, X.; Liu, Y.; Yan, Z.; Wang, P.; Diao, W.; Fu, K. SRAF-Net: Shape Robust Anchor-Free Network for Garbage Dumps in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6154–6168. [Google Scholar] [CrossRef]
- Lee, S.-H.; Yeh, C.-H. A Highly Efficient Garbage Pick-Up Embedded System Based on Improved SSD Neural Network Using Robotic Arms. Appl. Intell. Syst. 2022, 14, 405–421. [Google Scholar] [CrossRef]
- Mao, W.-L.; Chen, W.-C.; Fathurrahman, H.I.K.; Lin, Y.-H. Deep Learning Networks for Real-Time Regional Domestic Waste Detection. J. Clean. Prod. 2022, 344, 131096. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Q.; Zhang, X.; Wei, W.; Bao, Q.; Su, J.; Liu, X. A Multi-Label Waste Detection Model Based on Transfer Learning. Resour. Conserv. Recycl. 2022, 181, 106235. [Google Scholar] [CrossRef]
- Majchrowska, S.; Mikołajczyk, A.; Ferlin, M.; Klawikowska, Z.; Plantykow, M.A.; Kwasigroch, A.; Majek, K. Deep Learning-Based Waste Detection in Natural and Urban Environments. Waste Manag. 2022, 138, 274–284. [Google Scholar] [CrossRef]
- Lun, Z.; Pan, Y.; Wang, S.; Abbas, Z.; Islam, S.; Yin, S. Skip-YOLO: Domestic Garbage Detection Using Deep Learning Method in Complex Multi-Scenes. Int. J. Comput. Intell. Syst. 2023, 16, 139. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Z.; Li, G.; Zhou, C.; Chen, P.; Yang, C. An Accurate and Adaptable Deep Learning-Based Solution to Floating Litter Cleaning up and Its Effectiveness on Environmental Recovery. J. Clean. Prod. 2023, 388, 135816. [Google Scholar] [CrossRef]
- Wu, Z.; Li, H.; Wang, X.; Wu, Z.; Zou, L.; Xu, L.; Tan, M. New Benchmark for Household Garbage Image Recognition. Tsinghua Sci. Technol. 2022, 27, 793–803. [Google Scholar] [CrossRef]
- Glenn, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 March 2025).
- Glenn, J. YOLOv5 Release v6.0. 2022. Available online: https://github.com/ultralytics/yolov5/tree/v6.0 (accessed on 12 October 2021).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-Based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tu, P.; Xie, X.; Ai, G.; Li, Y.; Huang, Y.; Zheng, Y. FemtoDet: An Object Detection Baseline for Energy Versus Performance Tradeoffs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. arXiv 2022, arXiv:2208.02019. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|
| YOLOv8n | 3.02 | 8.2 | 92.3 | 95 |
| +SE | 3.03 | 8.2 | 92.7 | 85 |
| +CBAM | 3.03 | 8.3 | 92.8 | 78 |
| +ECA | 3.02 | 8.2 | 92.7 | 87 |
| +CA | 3.03 | 8.3 | 93.2 | 81 |
| +NAM | 3.02 | 8.2 | 92.7 | 85 |
| +NAMS* | 3.02 | 8.2 | 92.6 | 86 |
| +NAMC* | 3.02 | 8.2 | 92.9 | 88 |
| +SE (+AFF) | 3.03 | 8.2 | 93.0 +0.3 | 83 |
| +CBAM (+AFF) | 3.03 | 8.3 | 93.2 +0.4 | 75 |
| +ECA (+AFF) | 3.02 | 8.2 | 93.1 +0.4 | 84 |
| +CA (+AFF) | 3.03 | 8.3 | 93.3 +0.1 | 80 |
| +NAMC* (+AFF) | 3.02 | 8.2 | 93.2 +0.3 | 86 |
| Model | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|
| YOLOv8n | 3.02 | 8.2 | 92.3 | 95 |
| +IBE | 2.60 | 7.2 | 92.0 | 101 |
| +IBE (replace DWC) | 3.07 | 8.3 | 92.8 | 87 |
| +IBE (replace DWC and remove PC) | 3.02 | 8.2 | 92.7 | 93 |
| Model | mAP/% |
|---|---|
| YOLOv8n | 92.3 |
| +Focal Loss | 87.2 |
| +QFocal Loss | 87.4 |
| +Varifocal Loss | 88.7 |
| +Slide Loss | 92.7 |
| Category | AP/% | |
|---|---|---|
| YOLOv8n | YOLOv8n + Slide | |
| battery | 86.6 | 92.8 |
| cigarette case | 88.3 | 87.8 |
| modulator tube | 84.3 | 84.7 |
| watermelon peel | 87.6 | 87.4 |
| mercury thermometer | 84.5 | 86.9 |
| plastic bottle | 84.7 | 86.2 |
| can | 85.9 | 88.7 |
| waste paper | 89.4 | 90.7 |
| YOLOv8 | NAM | AFF | IBR | SlideLoss | Params/M | FLOPs/G | P/% | R/% | mAP/% | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | 3.02 | 8.2 | 91.7 | 86.8 | 92.3 | 95 | ||||
| √ | √ | 3.02 | 8.2 | 92.5 | 86.4 | 92.9 | 88 | |||
| √ | √ | √ | 3.02 | 8.2 | 92.1 | 87.8 | 93.2 | 86 | ||
| √ | √ | 3.02 | 8.2 | 92.0 | 86.7 | 92.7 | 92 | |||
| √ | √ | 3.02 | 8.2 | 91.2 | 87.9 | 92.7 | 93 | |||
| √ | √ | √ | √ | 3.02 | 8.2 | 92.3 | 87.5 | 93.4 | 83 | |
| √ | √ | √ | 3.02 | 8.2 | 92.0 | 87.3 | 92.9 | 92 | ||
| √ | √ | √ | √ | √ | 3.02 | 8.2 | 92.6 | 87.8 | 93.6 | 86 |
| Model | Data Division | Input Size | mAP/% |
|---|---|---|---|
| Faster-RCNN | 8:2 | 1000 × 800 | 74.8 |
| SSD | 8:2 | 512 × 512 | 73.5 |
| YOLOv3 | 8:2 | 608 × 608 | 74.3 |
| M2Det | 8:2 | 512 × 512 | 76.2 |
| EfficientDet | 8.2 | 512 × 512 | 77.6 |
| YOLOv4 | 8:2 | 608 × 608 | 79.1 |
| LWCNet | 8:2 | 640 × 640 | 91.5 |
| MS-YOLO | 8:2 | 640 × 640 | 93.2 |
| HGCS-Det | 8:2 | 640 × 640 | 93.6 |
| Model | Params/M | FLOPs/G | mAP/% | FPS |
|---|---|---|---|---|
| YOLOv5n | 1.80 | 4.3 | 87.3 | 102 |
| YOLOX-tiny | 5.04 | 15.3 | 91.2 | 82 |
| YOLOv6n | 4.31 | 11.1 | 91.8 | 85 |
| YOLOv7-tiny | 6.09 | 13.4 | 90.6 | 98 |
| YOLOv8n | 3.02 | 8.2 | 92.3 | 95 |
| YOLOv12n | 2.6 | 6.5 | 90.3 | 94 |
| LWCNet | 1.7 | 4.3 | 91.5 | - |
| MS-YOLO | 2.1 | 6.3 | 93.2 | - |
| YOLOv5s | 7.10 | 16.2 | 90.9 | 84 |
| YOLOXs | 8.95 | 26.8 | 91.6 | 68 |
| YOLOv6s | 17.20 | 44.1 | 93.0 | 74 |
| YOLOv8s | 11.15 | 28.7 | 93.6 | 77 |
| YOLOv12s | 9.3 | 21.4 | 91.04 | 82 |
| HGCS-Det | 3.02 | 8.2 | 93.6 | 86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Chen, C.; Xia, Z.; Ding, Q.; Liao, Q.; Wang, Q.; Yu, H.; Hu, H.; Zhang, G.; Hu, J.; et al. HGCS-Det: A Deep Learning-Based Solution for Localizing and Recognizing Household Garbage in Complex Scenarios. Sensors 2025, 25, 3726. https://doi.org/10.3390/s25123726
Zhou H, Chen C, Xia Z, Ding Q, Liao Q, Wang Q, Yu H, Hu H, Zhang G, Hu J, et al. HGCS-Det: A Deep Learning-Based Solution for Localizing and Recognizing Household Garbage in Complex Scenarios. Sensors. 2025; 25(12):3726. https://doi.org/10.3390/s25123726
Chicago/Turabian StyleZhou, Houkui, Chang Chen, Zhongyi Xia, Qifeng Ding, Qinqin Liao, Qun Wang, Huimin Yu, Haoji Hu, Guangqun Zhang, Junguo Hu, and et al. 2025. "HGCS-Det: A Deep Learning-Based Solution for Localizing and Recognizing Household Garbage in Complex Scenarios" Sensors 25, no. 12: 3726. https://doi.org/10.3390/s25123726
APA StyleZhou, H., Chen, C., Xia, Z., Ding, Q., Liao, Q., Wang, Q., Yu, H., Hu, H., Zhang, G., Hu, J., & He, T. (2025). HGCS-Det: A Deep Learning-Based Solution for Localizing and Recognizing Household Garbage in Complex Scenarios. Sensors, 25(12), 3726. https://doi.org/10.3390/s25123726