
A Survey of Deep Learning-Driven 3D Object Detection: Sensor Modalities, Technical Architectures, and Applications


Abstract
1. Introduction
2. Basic Knowledge
2.1. Sensors
2.1.1. Monocular Camera
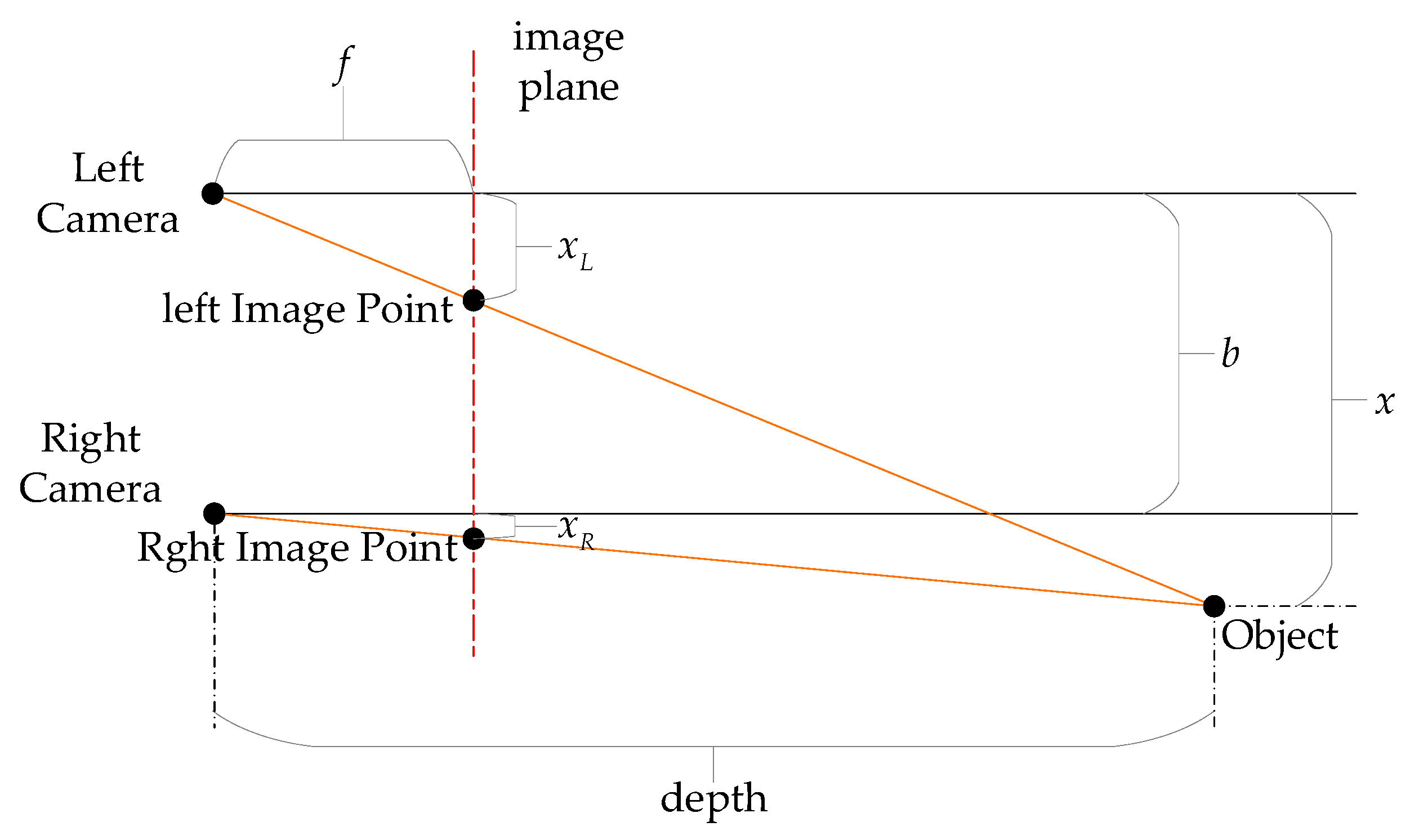
2.1.2. Stereo Camera (Binocular)
2.1.3. Mechanical LiDAR
2.1.4. Solid-State LiDAR
2.2. Datasets
2.2.1. KITTI
2.2.2. nuScenes
2.2.3. Waymo Open Dataset
2.2.4. ONCE (One Million Scenes)
2.2.5. Argoverse 2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Data Scale | Key Features | Train/Test Split | Latest SOTA Methods |
|---|---|---|---|---|---|
| KITTI [33] https://www.cvlibs.net/datasets/kitti/ (accessed on 15 May 2025) | 2012 | 7481 annotated frames (≈39.2 km driving mileage) Eight object classes (vehicles, pedestrians, etc.) | First multimodal benchmark dataset with rigorous sensor calibration. Limited dynamic objects (<15%), sparse long-range point clouds. | Train: 7481 samples Test: 7518 samples (no public labels, requires submission) | PV-RCNN++ [38] (point-voxel fusion) CenterPoint [39] (anchor-free detection) |
| nuScenes [34] https://www.nuscenes.org/ (accessed on 15 May 2025) | 2019 | 1000 scenarios (15 h driving duration) 1.4 M 3D annotations Temporal continuity (20 Hz sampling) | Multimodal fusion (LiDAR + radar + camera) for tracking/prediction. Includes Singapore’s right-hand traffic scenarios with dynamic attributes. | Train: 700 scenes Validation: 150 scenes Test: 150 scenes (no labels) | IS-Fusion [40] (Instance-Scene Collaborative BEV Enhancement) UniAD [41] (end-to-end multitask optimization) |
| Waymo Open Dataset [35] https://waymo.com/open/ (accessed on 15 May 2025) | 2020 | 1150 scenarios (≈6.4 h) 25 M 3D + 22 M 2D annotations 12% extreme weather coverage (rain/snow/fog) | Industry-scale dataset with L1/L2 difficulty grading. Features sub-8ms sensor synchronization and 1.4 TB storage requirements. | Train: 70% (≈70 k scenes) Validation: 15% Test: 15% (no public labels) | MPPNet [42] (temporal point cloud modeling) MotionCNN [43] (graph-based trajectory prediction) |
| ONCE [36] https://once-for-auto-driving.github.io/ (accessed on 15 May 2025) | 2021 | 1 M unlabeled LiDAR frames 150 k annotated frames (1 k scenarios) Covers Chinese urban roads | Focuses on long-tail scenarios (rare weather/occlusions). Contains fine-grained attributes (e.g., vehicle brands) for cross-modal learning. | Train: 70% (≈700 k scenes) Validation: 10% Test: 20% (requires submission) | Auto4D [44] (self-supervised pseudo-label generation) Pseudo-LiDAR++ [45] (monocular-to-point cloud conversion) |
| Argoverse 2 [37] https://www.argoverse.org/av2.html (accessed on 15 May 2025) | 2023 | 1 k multimodal sequences (3D annotations) 20 k unlabeled LiDAR sequences 250 k motion prediction cases | Largest LiDAR dataset supporting self-supervised learning. Contains complex interaction scenarios and 3D lane/pedestrian path geometry. | Sensor Dataset: 1000 scenes (official split) Motion Prediction: 70% train/15% val/15% test | Trajectron++ [46] (graph neural networks for multi-agent interaction) VectorNet [47] (HD map encoding + trajectory prediction) |
2.3. Evaluation Criteria
2.3.1. Problem Definition
2.3.2. Basic Principles
2.3.3. Special Criteria for Different Datasets
2.4. Literature Selection Methodology
3. Summary of 3D Object Detection Methods
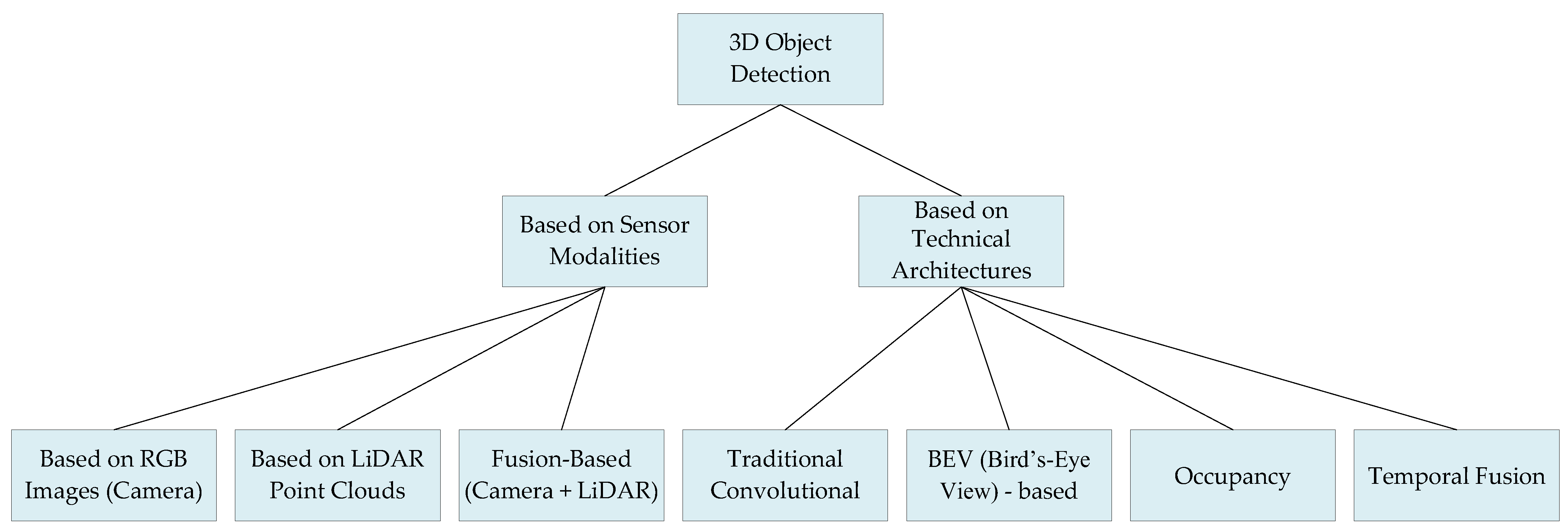
3.1. Taxonomy Based on Sensor Modalities
3.1.1. Three-Dimensional Object Detection Based on RGB Images
3.1.2. Three-Dimensional Object Detection Methods Based on LiDAR Point Clouds
3.1.3. Fusion-Based 3D Object Detection Methods
3.2. Taxonomy Based on Technical Architectures
3.2.1. Traditional Convolutional Architectures
3.2.2. BEV-Based Methods
3.2.3. Occupancy
3.2.4. Temporal Fusion Architectures
3.3. Applications of 3D Object Detection
4. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
References
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3D Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transport. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Hu, T.; Wang, W.; Gu, J.; Xia, Z.; Zhang, J.; Wang, B. Research on Apple Object Detection and Localization Method Based on Improved YOLOX and RGB-D Images. Agronomy 2023, 13, 1816. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Nunekpeku, X.; Zhang, W.; Gao, J.; Adade, S.Y.-S.S.; Li, H.; Chen, Q. Gel Strength Prediction in Ultrasonicated Chicken Mince: Fusing near-Infrared and Raman Spectroscopy Coupled with Deep Learning LSTM Algorithm. Food Control 2025, 168, 110916. [Google Scholar] [CrossRef]
- Li, H.; Sheng, W.; Adade, S.Y.-S.S.; Nunekpeku, X.; Chen, Q. Investigation of Heat-Induced Pork Batter Quality Detection and Change Mechanisms Using Raman Spectroscopy Coupled with Deep Learning Algorithms. Food Chem. 2024, 461, 140798. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Xie, S.; Ning, J.; Chen, Q.; Zhang, Z. Evaluating Green Tea Quality Based on Multisensor Data Fusion Combining Hyperspectral Imaging and Olfactory Visualization Systems. J. Sci. Food Agric. 2019, 99, 1787–1794. [Google Scholar] [CrossRef]
- Liang, Y.; Lin, H.; Kang, W.; Shao, X.; Cai, J.; Li, H.; Chen, Q. Application of Colorimetric Sensor Array Coupled with Machine-learning Approaches for the Discrimination of Grains Based on Freshness. J. Sci. Food Agric. 2023, 103, 6790–6799. [Google Scholar] [CrossRef]
- Xu, M.; Sun, J.; Cheng, J.; Yao, K.; Wu, X.; Zhou, X. Non-destructive Prediction of Total Soluble Solids and Titratable Acidity in Kyoho Grape Using Hyperspectral Imaging and Deep Learning Algorithm. Int. J. Food Sci. Tech. 2023, 58, 9–21. [Google Scholar] [CrossRef]
- Wang, H.; Gu, J.; Wang, M. A Review on the Application of Computer Vision and Machine Learning in the Tea Industry. Front. Sustain. Food Syst. 2023, 7, 1172543. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Gu, R. Research Status and Prospects on Plant Canopy Structure Measurement Using Visual Sensors Based on Three-Dimensional Reconstruction. Agriculture 2020, 10, 462. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, X.; Ma, G.; Du, X.; Shaheen, N.; Mao, H. Recognition of Weeds at Asparagus Fields Using Multi-Feature Fusion and Backpropagation Neural Network. Int. J. Agric. Biol. Eng. 2021, 14, 190–198. [Google Scholar] [CrossRef]
- Tian, Y.; Sun, J.; Zhou, X.; Yao, K.; Tang, N. Detection of Soluble Solid Content in Apples Based on Hyperspectral Technology Combined with Deep Learning Algorithm. Food Process. Preserv. 2022, 46, e16414. [Google Scholar] [CrossRef]
- Zhao, S.; Adade, S.Y.-S.S.; Wang, Z.; Jiao, T.; Ouyang, Q.; Li, H.; Chen, Q. Deep Learning and Feature Reconstruction Assisted Vis-NIR Calibration Method for on-Line Monitoring of Key Growth Indicators during Kombucha Production. Food Chem. 2025, 463, 141411. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral Technique Combined with Deep Learning Algorithm for Detection of Compound Heavy Metals in Lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef]
- Zhu, J.; Jiang, X.; Rong, Y.; Wei, W.; Wu, S.; Jiao, T.; Chen, Q. Label-Free Detection of Trace Level Zearalenone in Corn Oil by Surface-Enhanced Raman Spectroscopy (SERS) Coupled with Deep Learning Models. Food Chem. 2023, 414, 135705. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Jiang, H. Monitoring of Chlorpyrifos Residues in Corn Oil Based on Raman Spectral Deep-Learning Model. Foods 2023, 12, 2402. [Google Scholar] [CrossRef] [PubMed]
- Yang, N.; Chang, K.; Dong, S.; Tang, J.; Wang, A.; Huang, R.; Jia, Y. Rapid Image Detection and Recognition of Rice False Smut Based on Mobile Smart Devices with Anti-Light Features from Cloud Database. Biosyst. Eng. 2022, 218, 229–244. [Google Scholar] [CrossRef]
- Luo, Y.; Wei, L.; Xu, L.; Zhang, Q.; Liu, J.; Cai, Q.; Zhang, W. Stereo-Vision-Based Multi-Crop Harvesting Edge Detection for Precise Automatic Steering of Combine Harvester. Biosyst. Eng. 2022, 215, 115–128. [Google Scholar] [CrossRef]
- Fahrenkrog, F.; Reithinger, S.; Gülsen, B.; Raisch, F. European Research Project’s Contributions to a Safer Automated Road Traffic. Automot. Innov. 2023, 6, 521–530. [Google Scholar] [CrossRef]
- Bella, G.; Biondi, P.; Tudisco, G. A Double Assessment of Privacy Risks Aboard Top-Selling Cars. Automot. Innov. 2023, 6, 146–163. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D Object Detection for Autonomous Driving: A Comprehensive Survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. 3D Object Detection for Autonomous Driving: A Survey. Pattern Recognit. 2022, 130, 108796. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, S.; Li, Y.; Liu, M. A Comprehensive Review of 3D Object Detection in Autonomous Driving: Technological Advances and Future Directions. arXiv 2024, arXiv:2408.16530. [Google Scholar] [CrossRef]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. BEVFormer: Learning Bird’s-Eye-View Representation From LiDAR-Camera via Spatiotemporal Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 2020–2036. [Google Scholar] [CrossRef] [PubMed]
- Asl Sabbaghian Hokmabadi, I.; Ai, M.; El-Sheimy, N. Shaped-Based Tightly Coupled IMU/Camera Object-Level SLAM. Sensors 2023, 23, 7958. [Google Scholar] [CrossRef] [PubMed]
- Hu, Q.; Liu, M.; Li, Q.; Wang, Z. First-Frame Supervised Video Polyp Segmentation via Propagative and Semantic Dual-Teacher Network. arXiv 2024, arXiv:2412.16503. [Google Scholar]
- Bochkovskii, A.; Delaunoy, A.; Germain, H.; Santos, M.; Zhou, Y.; Richter, S.R.; Koltun, V. Depth Pro: Sharp Monocular Metric Depth in Less Than a Second. arXiv 2024, arXiv:2410.02073. [Google Scholar]
- Cao, Z.; Li, N.; Zhu, L.; Wu, J.; Dai, Q.; Qiao, H. Aberration-Robust Monocular Passive Depth Sensing Using a Meta-Imaging Camera. Light Sci. Appl. 2024, 13, 236. [Google Scholar] [CrossRef] [PubMed]
- AI & Robotics|Tesla. 2025. Available online: https://www.tesla.com/AI (accessed on 3 March 2025).
- Li, G.; Chi, X.; Qu, X. Depth Estimation Based on Monocular Camera Sensors in Autonomous Vehicles: A Self-Supervised Learning Approach. Automot. Innov. 2023, 6, 268–280. [Google Scholar] [CrossRef]
- Velodynelidar: Detection-Measurement-DirectIndustry. Available online: https://www.directindustry.com/prod/velodynelidar-182407.html (accessed on 3 March 2025).
- Li, Z.; Han, Y.; Wu, L.; Zang, Z.; Dai, M.; Set, S.Y.; Yamashita, S.; Li, Q.; Fu, H.Y. Towards an Ultrafast 3D Imaging Scanning LiDAR System: A Review. Photon. Res. 2024, 12, 1709. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Providence, RI, USA, 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 11618–11628. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 2443–2451. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One Million Scenes for Autonomous Driving: ONCE Dataset. arXiv 2021, arXiv:2106.11037. [Google Scholar]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. arXiv 2023, arXiv:2301.00493. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-Based 3D Object Detection and Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 11779–11788. [Google Scholar]
- Yin, J.; Shen, J.; Chen, R.; Li, W.; Yang, R.; Frossard, P.; Wang, W. IS-Fusion: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Seattle, WA, USA, 2024; pp. 14905–14915. [Google Scholar]
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W.; et al. Planning-Oriented Autonomous Driving. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 17853–17862. [Google Scholar]
- Chen, X.; Shi, S.; Zhu, B.; Cheung, K.C.; Xu, H.; Li, H. MPPNet: Multi-Frame Feature Intertwining with Proxy Points for 3D Temporal Object Detection. arXiv 2022, arXiv:2205.05979. [Google Scholar] [CrossRef]
- Konev, S.; Brodt, K.; Sanakoyeu, A. MotionCNN: A Strong Baseline for Motion Prediction in Autonomous Driving. arXiv 2022, arXiv:2206.02163. [Google Scholar] [CrossRef]
- Yang, B.; Bai, M.; Liang, M.; Zeng, W.; Urtasun, R. Auto4D: Learning to Label 4D Objects from Sequential Point Clouds. arXiv 2021, arXiv:2101.06586. [Google Scholar] [CrossRef]
- You, Y.; Wang, Y.; Chao, W.-L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving. arXiv 2019, arXiv:1906.06310. [Google Scholar] [CrossRef]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-Feasible Trajectory Forecasting With Heterogeneous Data. arXiv 2021, arXiv:2001.03093. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Zhao, H.; Shen, Y.; Anguelov, D.; Li, C.; Schmid, C. VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation. arXiv 2020, arXiv:2005.04259. [Google Scholar] [CrossRef]
- Li, W.; Li, G.; Tan, R.; Wang, C.; Sun, Z.; Li, Y.; Guo, G.; Cao, D.; Li, K. Review and Perspectives on Human Emotion for Connected Automated Vehicles. Automot. Innov. 2024, 7, 4–44. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar] [CrossRef]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Seoul, Republic of Korea, 2019; pp. 9286–9295. [Google Scholar]
- Manhardt, F.; Kehl, W.; Gaidon, A. ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 2064–2073. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 2147–2156. [Google Scholar]
- Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 8437–8445. [Google Scholar]
- Xu, B.; Chen, Z. Multi-Level Fusion Based 3D Object Detection from Monocular Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 2345–2353. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 5632–5640. [Google Scholar]
- Chabot, F.; Chaouch, M.; Rabarisoa, J.; Teuliere, C.; Chateau, T. Deep MANTA: A Coarse-to-Fine Many-Task Network for Joint 2D and 3D Vehicle Analysis from Monocular Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 1827–1836. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3D Object Proposals Using Stereo Imagery for Accurate Object Class Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Ku, J.; Waslander, S.L. Confidence Guided Stereo 3D Object Detection with Split Depth Estimation. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Las Vegas, NV, USA, 2020; pp. 5776–5783. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo R-CNN Based 3D Object Detection for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 7636–7644. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Chen, Y.-N.; Dai, H.; Ding, Y. Pseudo-Stereo for Monocular 3D Object Detection in Autonomous Driving. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 877–887. [Google Scholar]
- Liu, Y.; Wang, L.; Liu, M. YOLOStereo3D: A Step Back to 2D for Efficient Stereo 3D Detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Xi’an, China, 2021; pp. 13018–13024. [Google Scholar]
- Wang, J.; Gao, Z.; Zhang, Y.; Zhou, J.; Wu, J.; Li, P. Real-Time Detection and Location of Potted Flowers Based on a ZED Camera and a YOLO V4-Tiny Deep Learning Algorithm. Horticulturae 2021, 8, 21. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space; Curran Associates Inc.: Long Beach, CA, USA, 2017; pp. 5105–5114. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 770–779. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 11037–11045. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection. AAAI 2021, 35, 1201–1209. [Google Scholar] [CrossRef]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel Transformer for 3D Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 3144–3153. [Google Scholar]
- Chen, Y.; Liu, J.; Zhang, X.; Qi, X.; Jia, J. VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 21674–21683. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 12689–12697. [Google Scholar]
- Shi, G.; Li, R.; Ma, C. PillarNet: Real-Time and High-Performance Pillar-Based 3D Object Detection. In Computer Vision–ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; Volume 13670, pp. 35–52. [Google Scholar]
- Li, J.; Luo, C.; Yang, X. PillarNeXt: Rethinking Network Designs for 3D Object Detection in LiDAR Point Clouds. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 17567–17576. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 10526–10535. [Google Scholar]
- Qian, R.; Lai, X.; Li, X. BADet: Boundary-Aware 3D Object Detection from Point Clouds. Pattern Recognit. 2022, 125, 108524. [Google Scholar] [CrossRef]
- He, C.; Li, R.; Li, S.; Zhang, L. Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 8407–8417. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection From RGB-D Data. arXiv 2017, arXiv:1711.08488. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. IPOD: Intensive Point-Based Object Detector for Point Cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar] [CrossRef]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 4603–4611. [Google Scholar]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. RoarNet: A Robust 3D Object Detection Based on RegiOn Approximation Refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Paris, France, 2019; pp. 2510–2515. [Google Scholar]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual Sparse Convolution for Multimodal 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 21653–21662. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 6526–6534. [Google Scholar]
- Li, X.; Ma, T.; Hou, Y.; Shi, B.; Yang, Y.; Liu, Y.; Wu, X.; Chen, Q.; Li, Y.; Qiao, Y.; et al. LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 17524–17534. [Google Scholar]
- Wang, Y.; Deng, J.; Li, Y.; Hu, J.; Liu, C.; Zhang, Y.; Ji, J.; Ouyang, W.; Zhang, Y. Bi-LRFusion: Bi-Directional LiDAR-Radar Fusion for 3D Dynamic Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 13394–13403. [Google Scholar]
- Xie, Y.; Xu, C.; Rakotosaona, M.-J.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 17545–17556. [Google Scholar]
- Yan, J.; Liu, Y.; Sun, J.; Jia, F.; Li, S.; Wang, T.; Zhang, X. Cross Modal Transformer: Towards Fast and Robust 3D Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 18222–18232. [Google Scholar]
- Ge, C.; Chen, J.; Xie, E.; Wang, Z.; Hong, L.; Lu, H.; Li, Z.; Luo, P. MetaBEV: Solving Sensor Failures for 3D Detection and Map Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 8687–8697. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Las Vegas, NV, USA, 2020; pp. 10386–10393. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Fast-CLOCs: Fast Camera-LiDAR Object Candidates Fusion for 3D Object Detection. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; IEEE: Waikoloa, HI, USA, 2022; pp. 3747–3756. [Google Scholar]
- Wang, W.; Guo, K.; Cao, W.; Zhu, H.; Nan, J.; Yu, L. Review of Electrical and Electronic Architectures for Autonomous Vehicles: Topologies, Networking and Simulators. Automot. Innov. 2024, 7, 82–101. [Google Scholar] [CrossRef]
- Markó, N.; Kőrös, P.; Unger, M. Inverse Perspective Mapping Correction for Aiding Camera-Based Autonomous Driving Tasks. In SMTS 2024; MDPI: Basel, Switzerland, 2024; p. 67. [Google Scholar]
- Philion, J.; Fidler, S. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12359, pp. 194–210. ISBN 978-3-030-58567-9. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection. arXiv 2022, arXiv:2206.10092. [Google Scholar] [CrossRef]
- Li, Y.; Bao, H.; Ge, Z.; Yang, J.; Sun, J.; Li, Z. BEVStereo: Enhancing Depth Estimation in Multi-View 3D Object Detection with Temporal Stereo. AAAI 2023, 37, 1486–1494. [Google Scholar] [CrossRef]
- Park, J.; Xu, C.; Yang, S.; Keutzer, K.; Kitani, K.; Tomizuka, M.; Zhan, W. Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection. arXiv 2022, arXiv:2210.02443. [Google Scholar] [CrossRef]
- Han, C.; Yang, J.; Sun, J.; Ge, Z.; Dong, R.; Zhou, H.; Mao, W.; Peng, Y.; Zhang, X. Exploring Re-current Long-Term Temporal Fusion for Multi-View 3D Perception. IEEE Robot. Autom. Lett. 2024, 9, 6544–6551. [Google Scholar] [CrossRef]
- Wang, W.; Lu, Y.; Zheng, G.; Zhan, S.; Ye, X.; Tan, Z.; Wang, J.; Wang, G.; Li, X. BEVSpread: Spread Voxel Pooling for Bird’s-Eye-View Representation in Vision-Based Roadside 3D Object De-tection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recogni-tion (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Seattle, WA, USA, 2024; pp. 14718–14727. [Google Scholar]
- Chi, X.; Liu, J.; Lu, M.; Zhang, R.; Wang, Z.; Guo, Y.; Zhang, S. BEV-SAN: Accurate BEV 3D Object Detection via Slice Attention Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 17461–17470. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework. arXiv 2022, arXiv:2205.13790. [Google Scholar] [CrossRef]
- Hu, H.; Wang, F.; Su, J.; Wang, Y.; Hu, L.; Fang, W.; Xu, J.; Zhang, Z. EA-LSS: Edge-Aware Lift-Splat-Shot Framework for 3D BEV Object Detection. arXiv 2023, arXiv:2303.17895. [Google Scholar] [CrossRef]
- Cai, H.; Zhang, Z.; Zhou, Z.; Li, Z.; Ding, W.; Zhao, J. BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird’s-Eye-View via Cross-Modality Guidance and Temporal Aggregation. arXiv 2023, arXiv:2303.17099. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Liu, Q.; Wang, Y. SA-BEV: Generating Semantic-Aware Bird’s-Eye-View Feature for Multi-View 3D Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 3325–3334. [Google Scholar]
- Schramm, J.; Vödisch, N.; Petek, K.; Kiran, B.R.; Yogamani, S.; Burgard, W.; Valada, A. BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Abu Dhabi, United Arab Emirates, 2024; pp. 1435–1442. [Google Scholar]
- Liu, H.; Teng, Y.; Lu, T.; Wang, H.; Wang, L. SparseBEV: High-Performance Sparse 3D Object Detec-tion from Multi-Camera Videos. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 18534–18544. [Google Scholar]
- Kim, Y.; Shin, J.; Kim, S.; Lee, I.-J.; Choi, J.W.; Kum, D. CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 17569–17580. [Google Scholar]
- Huang, J.; Huang, G. BEVDet4D: Exploit Temporal Cues in Multi-Camera 3D Object Detection. arXiv 2022, arXiv:2203.17054. [Google Scholar] [CrossRef]
- Cao, A.-Q.; De Charette, R. MonoScene: Monocular 3D Semantic Scene Completion. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 3981–3991. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View. arXiv 2022, arXiv:2112.11790. [Google Scholar] [CrossRef]
- Huang, Y.; Zheng, W.; Zhang, Y.; Zhou, J.; Lu, J. Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 9223–9232. [Google Scholar]
- Wei, Y.; Zhao, L.; Zheng, W.; Zhu, Z.; Zhou, J.; Lu, J. SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 21672–21683. [Google Scholar]
- Yu, Z.; Shu, C.; Deng, J.; Lu, K.; Liu, Z.; Yu, J.; Yang, D.; Li, H.; Chen, Y. FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin. arXiv 2023, arXiv:2311.12058. [Google Scholar] [CrossRef]
- Li, Y.; Yu, Z.; Choy, C.; Xiao, C.; Alvarez, J.M.; Fidler, S.; Feng, C.; Anandkumar, A. VoxFormer: Sparse Voxel Transformer for Camera-Based 3D Semantic Scene Completion. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 9087–9098. [Google Scholar]
- Shamsafar, F.; Woerz, S.; Rahim, R.; Zell, A. MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; IEEE: Waikoloa, HI, USA, 2022; pp. 677–686. [Google Scholar]
- Jia, Y.; He, J.; Chen, R.; Zhao, F.; Luo, H. OccupancyDETR: Using DETR for Mixed Dense-Sparse 3D Occupancy Prediction. arXiv 2024, arXiv:2309.08504. [Google Scholar] [CrossRef]
- Li, Z.; Yu, Z.; Austin, D.; Fang, M.; Lan, S.; Kautz, J.; Alvarez, J.M. FB-OCC: 3D Occupancy Prediction Based on Forward-Backward View Transformation. arXiv 2023, arXiv:2307.01492. [Google Scholar] [CrossRef]
- Zhang, H.; Yan, X.; Bai, D.; Gao, J.; Wang, P.; Liu, B.; Cui, S.; Li, Z. RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation. AAAI 2024, 38, 7060–7068. [Google Scholar] [CrossRef]
- Huang, Y.; Zheng, W.; Zhang, B.; Zhou, J.; Lu, J. SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Seattle, WA, USA, 2024; pp. 19946–19956. [Google Scholar]
- Zhang, C.; Yan, J.; Wei, Y.; Li, J.; Liu, L.; Tang, Y.; Duan, Y.; Lu, J. OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments. arXiv 2024, arXiv:2312.09243. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Yang, B.; Urtasun, R. Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 3569–3577. [Google Scholar]
- Liu, Y.; Yan, J.; Jia, F.; Li, S.; Gao, A.; Wang, T.; Zhang, X. PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; IEEE: Paris, France, 2023; pp. 3239–3249. [Google Scholar]
- Hu, A.; Murez, Z.; Mohan, N.; Dudas, S.; Hawke, J.; Badrinarayanan, V.; Cipolla, R.; Kendall, A. FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 15253–15262. [Google Scholar]
- Kobayashi, S.; Sasaki, Y.; Yorozu, A.; Ohya, A. Probabilistic Semantic Occupancy Grid Mapping Considering the Uncertainty of Semantic Segmentation with IPM. In Proceedings of the 2022 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Sapporo, Japan, 11–15 July 2022; IEEE: Sapporo, Japan, 2022; pp. 250–255. [Google Scholar]
- Gu, W.; Wen, W.; Wu, S.; Zheng, C.; Lu, X.; Chang, W.; Xiao, P.; Guo, X. 3D Reconstruction of Wheat Plants by Integrating Point Cloud Data and Virtual Design Optimization. Agriculture 2024, 14, 391. [Google Scholar] [CrossRef]
- Xu, J.; Liu, H.; Shen, Y.; Zeng, X.; Zheng, X. Individual Nursery Trees Classification and Segmentation Using a Point Cloud-Based Neural Network with Dense Connection Pattern. Sci. Hortic. 2024, 328, 112945. [Google Scholar] [CrossRef]
- Sun, Y.; Luo, Y.; Zhang, Q.; Xu, L.; Wang, L.; Zhang, P. Estimation of Crop Height Distribution for Mature Rice Based on a Moving Surface and 3D Point Cloud Elevation. Agronomy 2022, 12, 836. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, Y.; Wu, C.; Wu, H. Fruit Distribution Density Estimation in YOLO-Detected Strawberry Images: A Kernel Density and Nearest Neighbor Analysis Approach. Agriculture 2024, 14, 1848. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, H. Evaluation of a Laser Scanning Sensor in Detection of Complex-Shaped Targets for Variable-Rate Sprayer Development. Trans. ASABE 2016, 59, 1181–1192. [Google Scholar] [CrossRef]
- Xu, S.; Xu, X.; Zhu, Q.; Meng, Y.; Yang, G.; Feng, H.; Yang, M.; Zhu, Q.; Xue, H.; Wang, B. Monitoring Leaf Nitrogen Content in Rice Based on Information Fusion of Multi-Sensor Imagery from UAV. Precis. Agric. 2023, 24, 2327–2349. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, Y.; Fan, W.; Liu, J. An Improved YOLOv8 Model for Lotus Seedpod Instance Segmentation in the Lotus Pond Environment. Agronomy 2024, 14, 1325. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Zhao, Y.; Pan, Q.; Jin, K.; Xu, G.; Hu, Y. TS-YOLO: An All-Day and Lightweight Tea Canopy Shoots Detection Model. Agronomy 2023, 13, 1411. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Z.; Ali, S.; Yang, N.; Fu, S.; Zhang, Y. Multi-Class Detection of Cherry Tomatoes Using Improved YOLOv4-Tiny. Int. J. Agric. Biol. Eng. 2023, 16, 225–231. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A Real-Time Apple Targets Detection Method for Picking Robot Based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Tao, K.; Wang, A.; Shen, Y.; Lu, Z.; Peng, F.; Wei, X. Peach Flower Density Detection Based on an Improved CNN Incorporating Attention Mechanism and Multi-Scale Feature Fusion. Horticulturae 2022, 8, 904. [Google Scholar] [CrossRef]
- Yu, S.; Huang, X.; Wang, L.; Chang, X.; Ren, Y.; Zhang, X.; Wang, Y. Qualitative and Quantitative Assessment of Flavor Quality of Chinese Soybean Paste Using Multiple Sensor Technologies Combined with Chemometrics and a Data Fusion Strategy. Food Chem. 2023, 405, 134859. [Google Scholar] [CrossRef]
- Huang, X.; Pan, S.; Sun, Z.; Ye, W.; Aheto, J.H. Evaluating Quality of Tomato during Storage Using Fusion Information of Computer Vision and Electronic Nose. J. Food Process Eng. 2018, 41, e12832. [Google Scholar] [CrossRef]

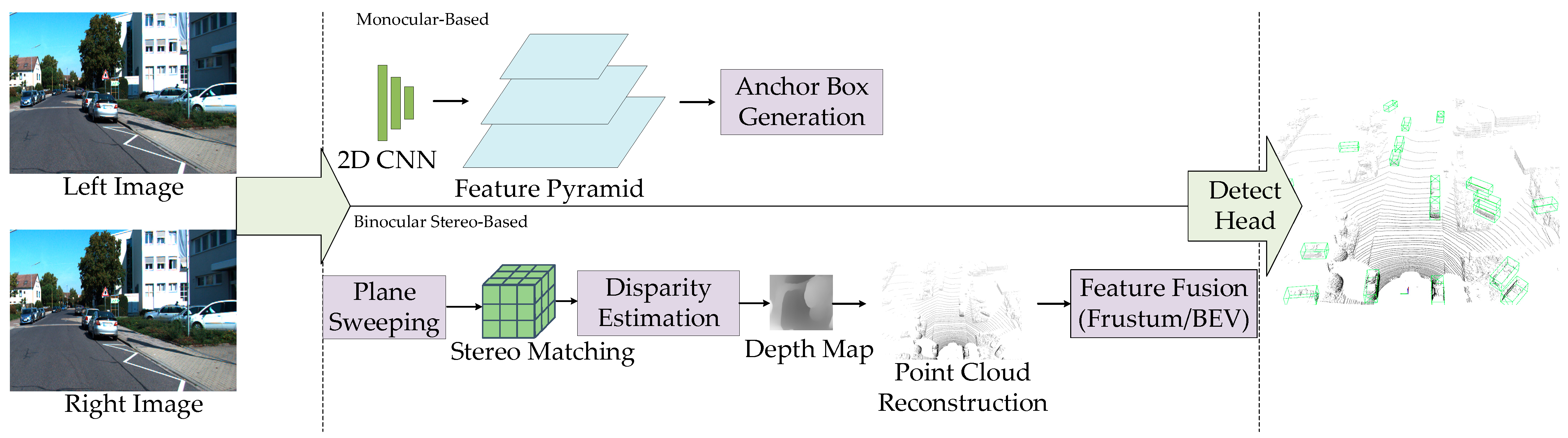
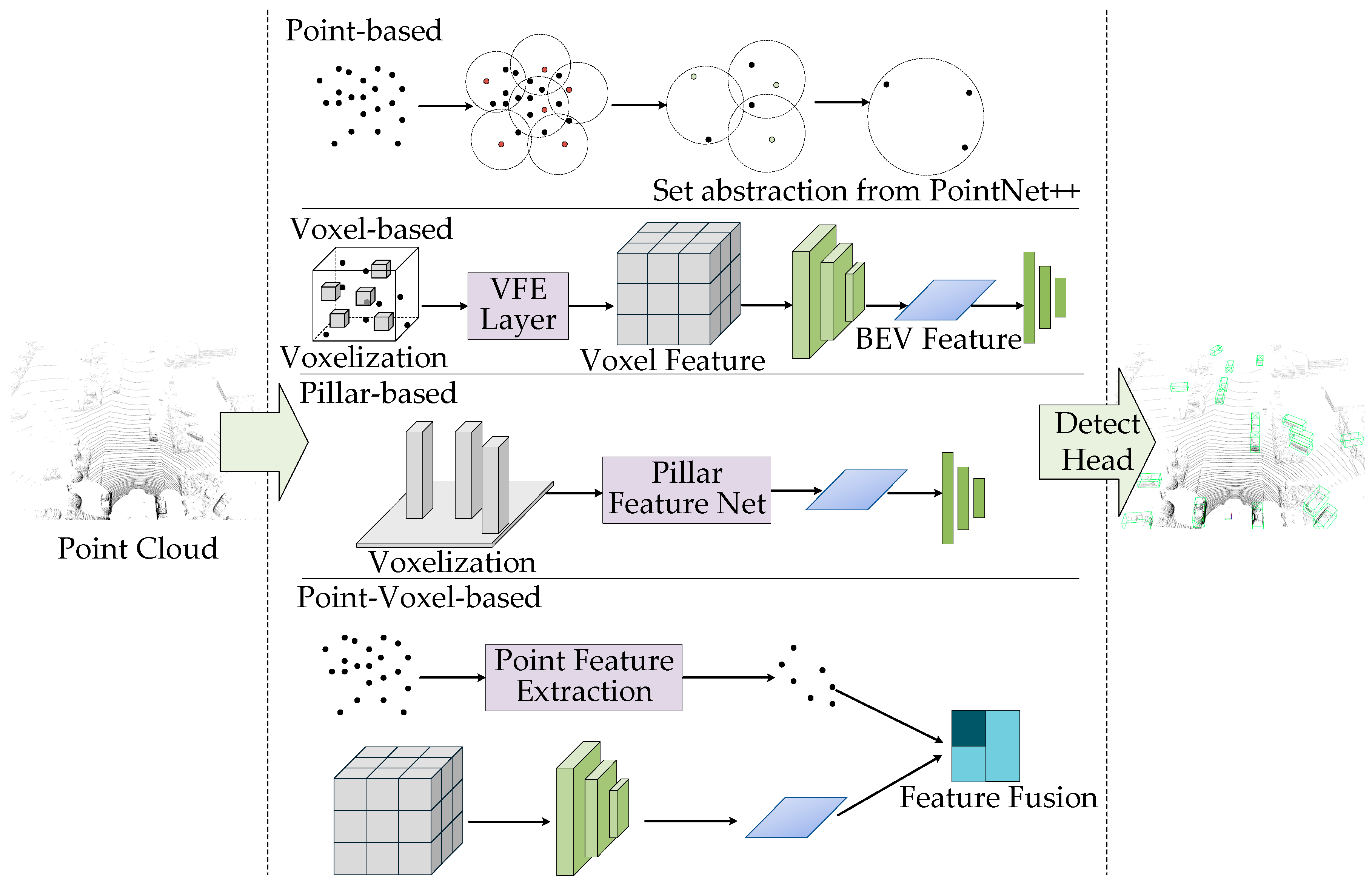
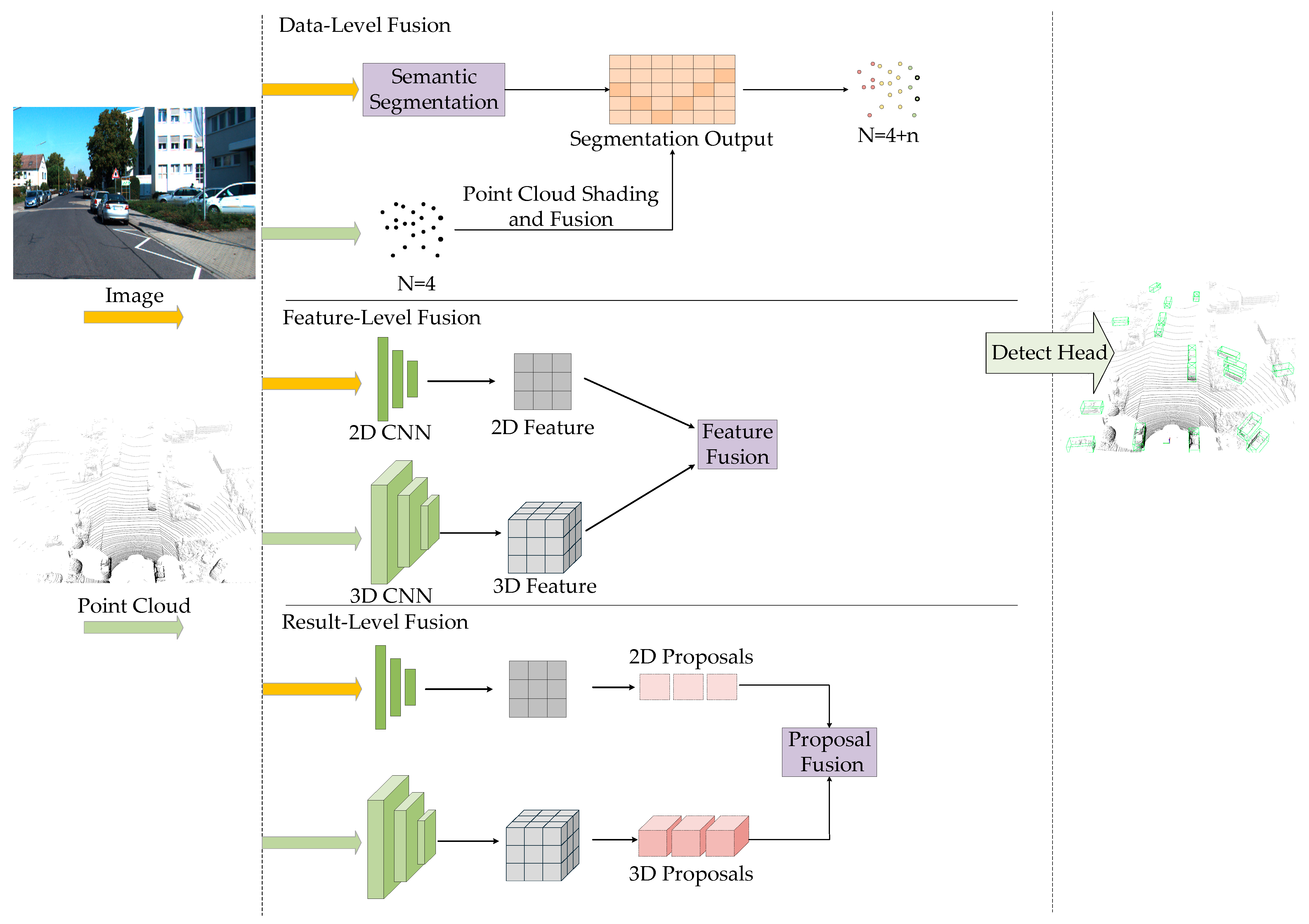
| Device Type | Advantages | Disadvantages |
|---|---|---|
| Monocular Camera | Structurally simple and cost-effective, suitable for robotics and UAV applications, but requires algorithmic depth estimation [21]. | Lacks direct depth measurement capability, sensitive to lighting/texture variations, and degrades in low-light conditions. |
| Stereo Camera | Calculates depth directly via binocular disparity, offers high resolution, and adapts to indoor/outdoor environments (active variants enhance performance with infrared illumination). | High computational complexity, texture-dependent matching, baseline-limited range, and reduced efficacy in low-texture or high-glare scenarios. |
| Mechanical LiDAR | Provides millimeter-level accuracy and 360° scanning, with mature technology and stable point clouds for early autonomous systems. | Bulky size, high cost/power consumption, short lifespan due to mechanical wear, and challenges in mass production. |
| Solid-State LiDAR | Compact and vibration-resistant, purely solid-state designs eliminate moving parts, ideal for vehicular and robotic navigation. | Pure solid-state variants have limited detection range (e.g., 20–50 m), while hybrid versions retain micro-mechanical components, compromising long-range accuracy. |
| Sensor Type | Subcategory | Data Format | Advantages | Limitations |
|---|---|---|---|---|
| RGB Images | Monocular Vision | Two-dimensional pixel matrix | Low cost, rich texture semantics | Depth ambiguity, scale uncertainty |
| Stereo Vision | Stereo image pairs | True depth perception | High computation, texture reliance | |
| LiDAR | Point-based | Raw point clouds (N × 3) | Preserves geometric details | High computational complexity |
| Voxel-based | Three-dimensional voxel grids | Structured representation | Quantization errors | |
| Pillar-based | Two-dimensional pseudo-images | Balances efficiency and structure | Compressed height information | |
| Multimodal | Data-Level Fusion | Raw sensor alignment | Preserves raw information | Requires precise calibration |
| Feature-Level Fusion | Cross-modal features | Complementary strengths | Feature alignment challenges | |
| Result-Level Fusion | Independent outputs | Flexibility | Redundant computation |
| Architecture Type | Key Technical Features | Core Innovations | Strengths | Key Challenges |
|---|---|---|---|---|
| Traditional Conv. | Voxelization + 3D conv. | Structured data representation | Hardware-friendly, real-time | Quantization errors |
| Sparse convolution | Non-empty voxel processing | A total of 50%+ efficiency gain | Long-range feature decay | |
| BEV Methods | Perspective transformation | LSS 3D feature lifting | Unified multi-view perception | Projection distortion |
| Spatiotemporal attention | Cross-frame alignment | Dynamic tracking | Historical frame storage | |
| Occupancy | Dense voxel modeling | Three-dimensional spatial probability prediction | Irregular object detection | O(n3) complexity |
| NeRF fusion | Joint NeRF + occupancy training | High-fidelity reconstruction | Data-hungry | |
| Temporal Fusion | RNN/LSTM | Sequential modeling | Motion trajectory prediction | Long-term dependency issues |
| Four-dimensional feature tensor | BEV + temporal dimension | Velocity estimation (<0.3 m/s) | High memory usage |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wang, H.; Dong, H. A Survey of Deep Learning-Driven 3D Object Detection: Sensor Modalities, Technical Architectures, and Applications. Sensors 2025, 25, 3668. https://doi.org/10.3390/s25123668
Zhang X, Wang H, Dong H. A Survey of Deep Learning-Driven 3D Object Detection: Sensor Modalities, Technical Architectures, and Applications. Sensors. 2025; 25(12):3668. https://doi.org/10.3390/s25123668
Chicago/Turabian StyleZhang, Xiang, Hai Wang, and Haoran Dong. 2025. "A Survey of Deep Learning-Driven 3D Object Detection: Sensor Modalities, Technical Architectures, and Applications" Sensors 25, no. 12: 3668. https://doi.org/10.3390/s25123668
APA StyleZhang, X., Wang, H., & Dong, H. (2025). A Survey of Deep Learning-Driven 3D Object Detection: Sensor Modalities, Technical Architectures, and Applications. Sensors, 25(12), 3668. https://doi.org/10.3390/s25123668