
Confidence-Based, Collaborative, Distributed Continual Learning Framework for Non-Intrusive Load Monitoring in Smart Grids


Abstract
1. Introduction
2. Problem Statement
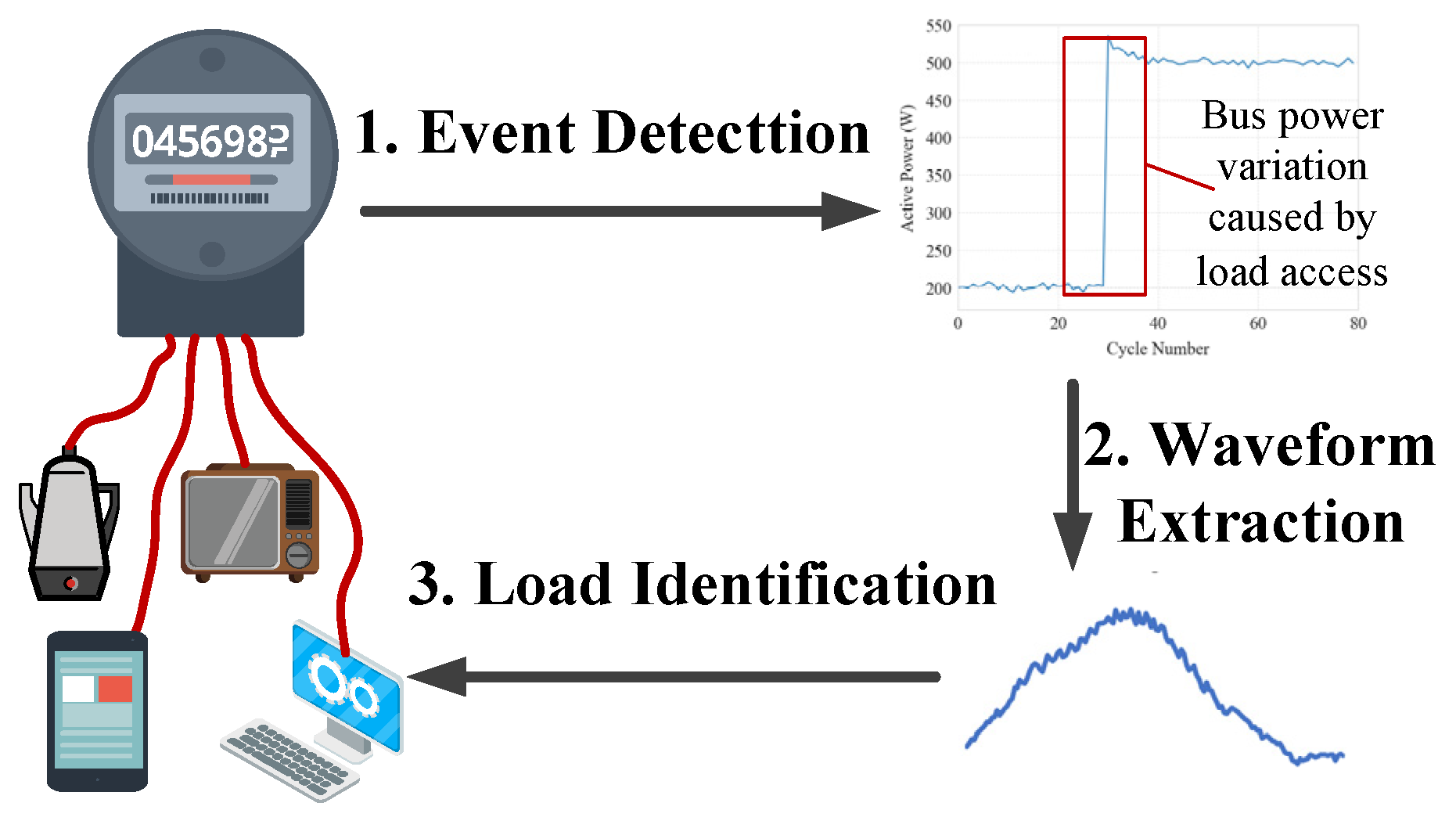
2.1. Event-Based NILM Methodology
2.2. The Distributed Continuous Learning Setting in Practical NILM Systems
3. Materials and Methods
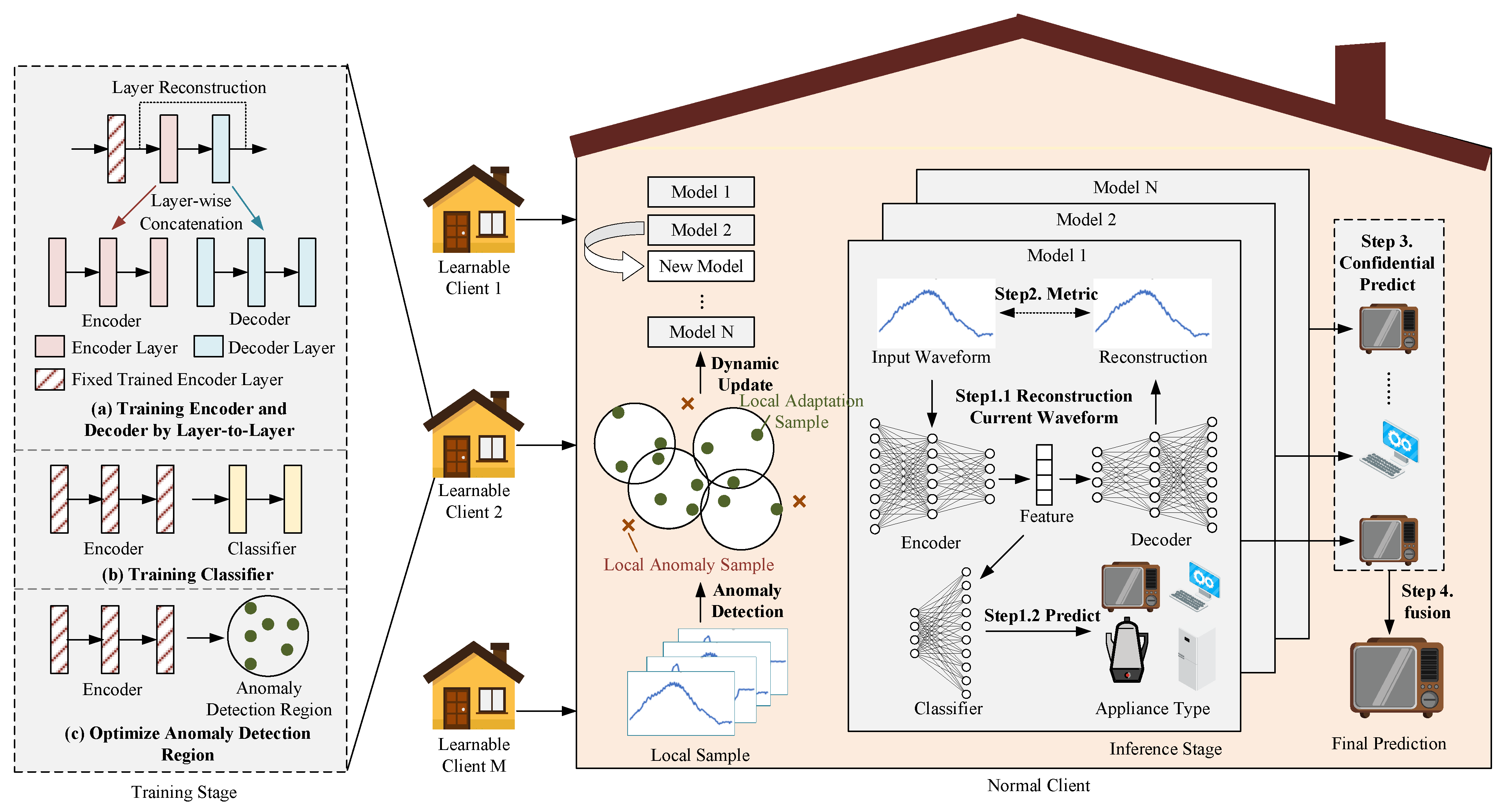
3.1. Confidence-Based Collaborative Distributed Continual Learning Framework
3.2. Construction of Layer-Wise Dual-Supervised Autoencoder Model
3.3. Dynamically Update the Local Model Portfolio
3.4. Multi-Model Confidence Identification Based on Reconstruction Deviation
3.5. Experimental Dataset and Evaluation Metrics
4. Results
4.1. The Result of Model Performance Comparison
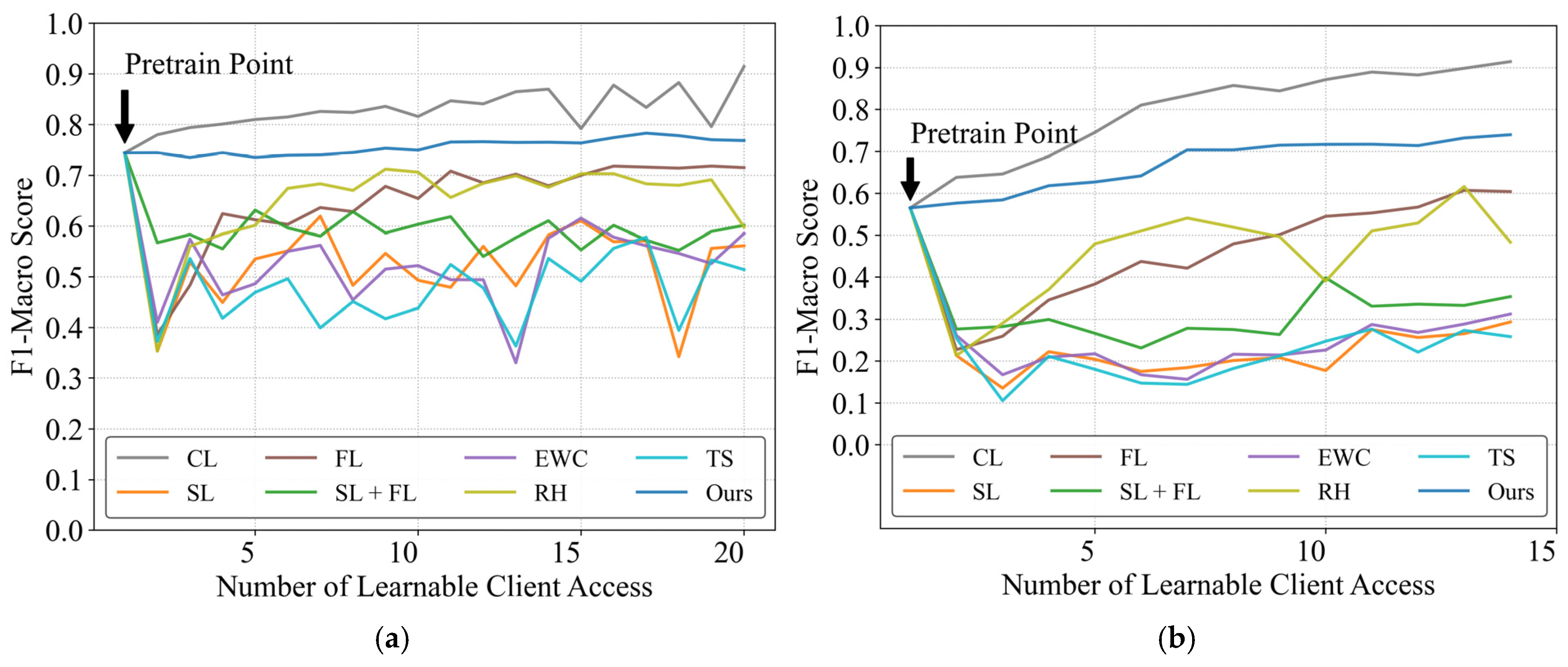
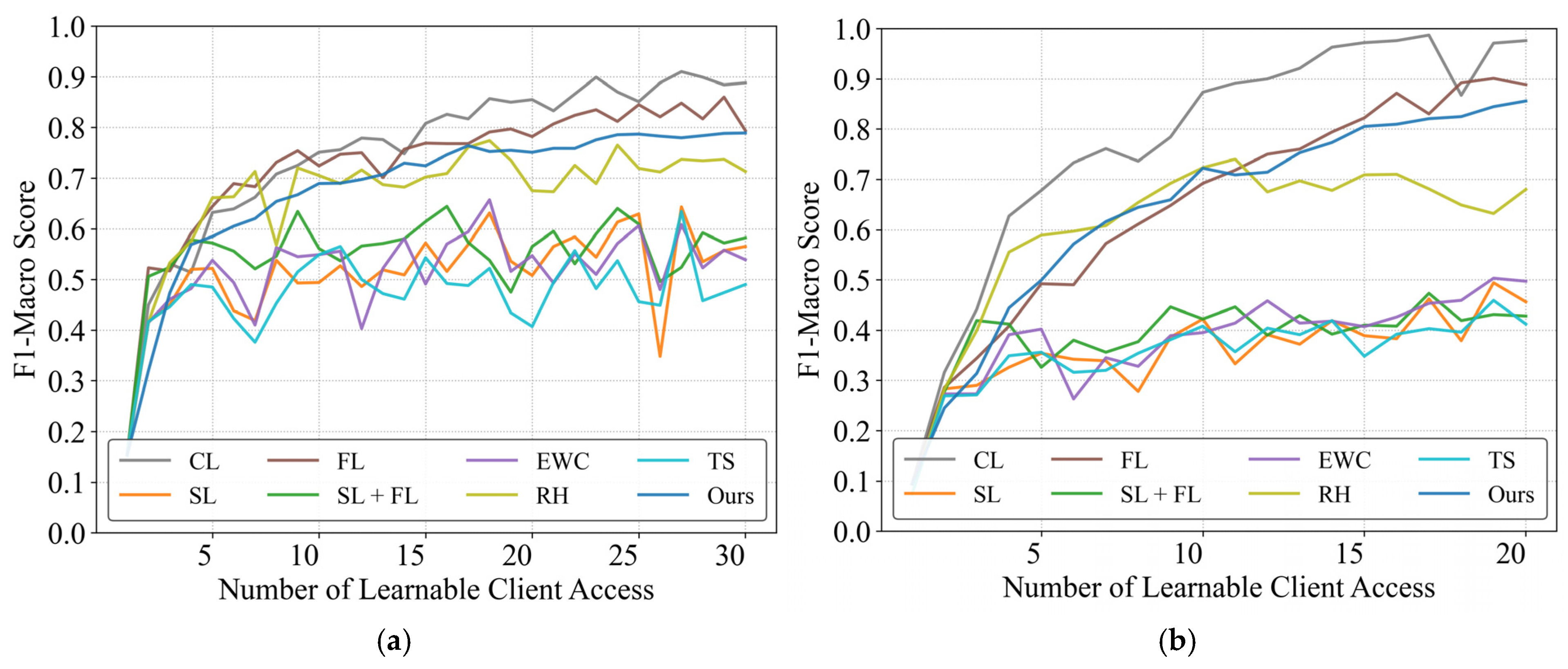
4.2. Distributed Continual Learning Performance Under Identical Data Distribution
4.3. Distributed Continual Learning Performance Across Scenarios
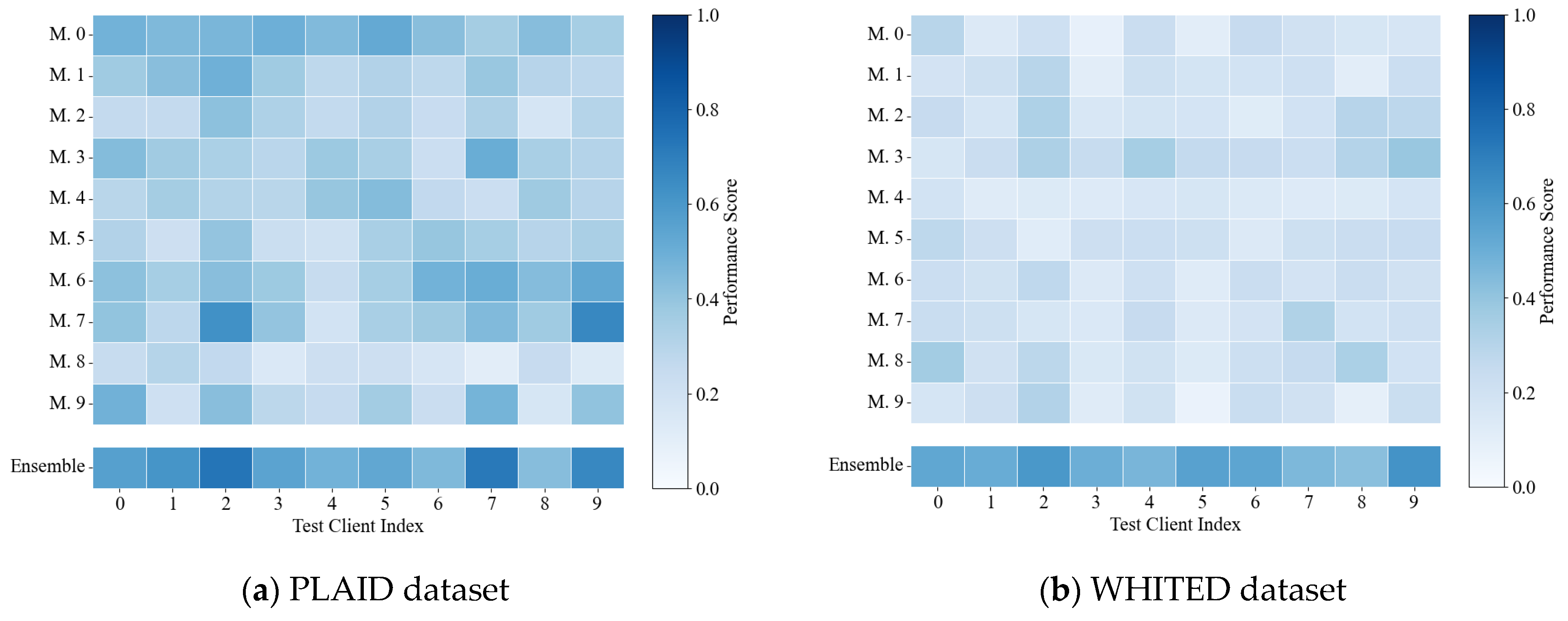
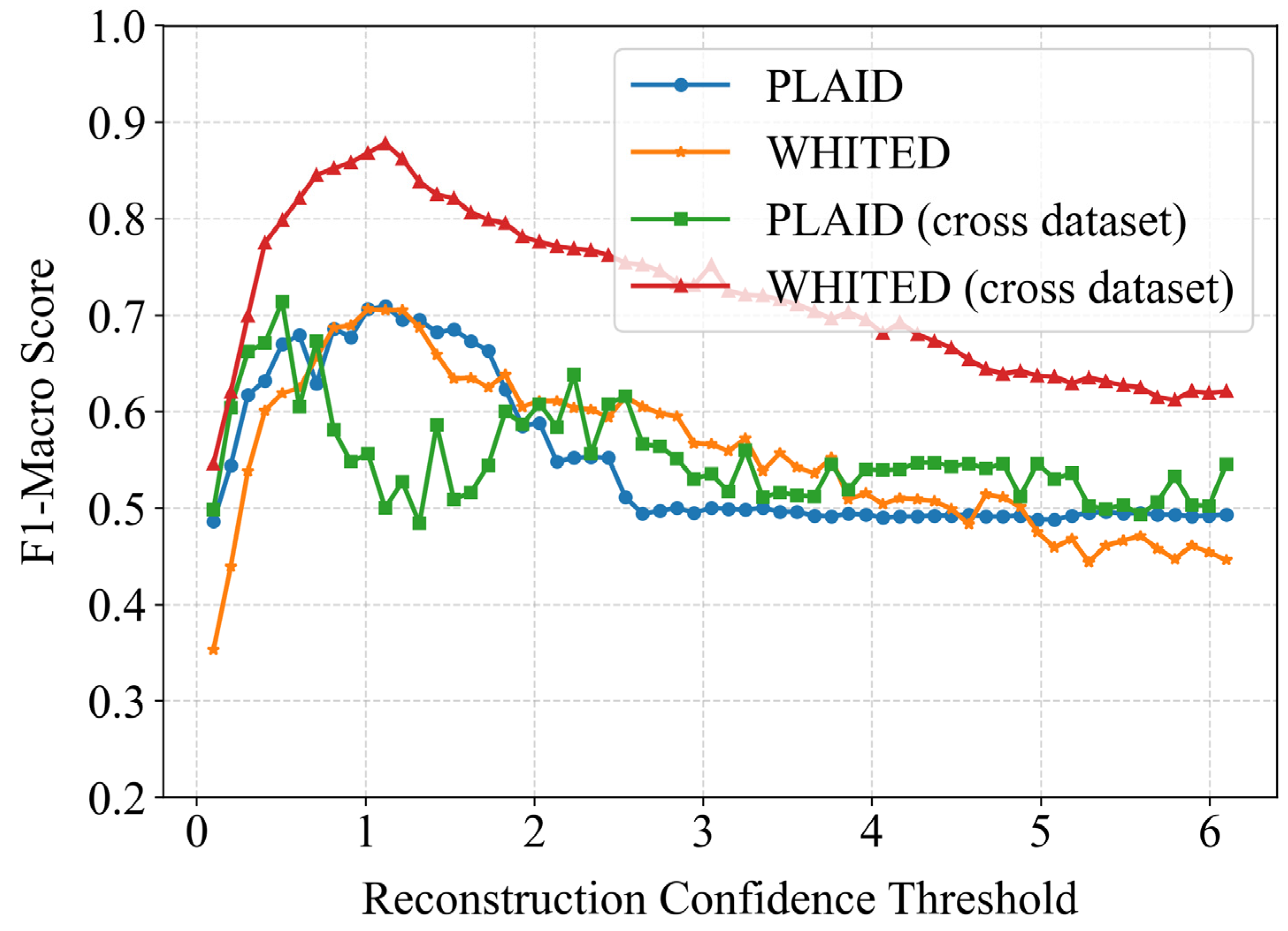
4.4. Validation of Proposed Confidence Identification Strategy
4.5. Validation of Proposed Model Portfolio Management Method
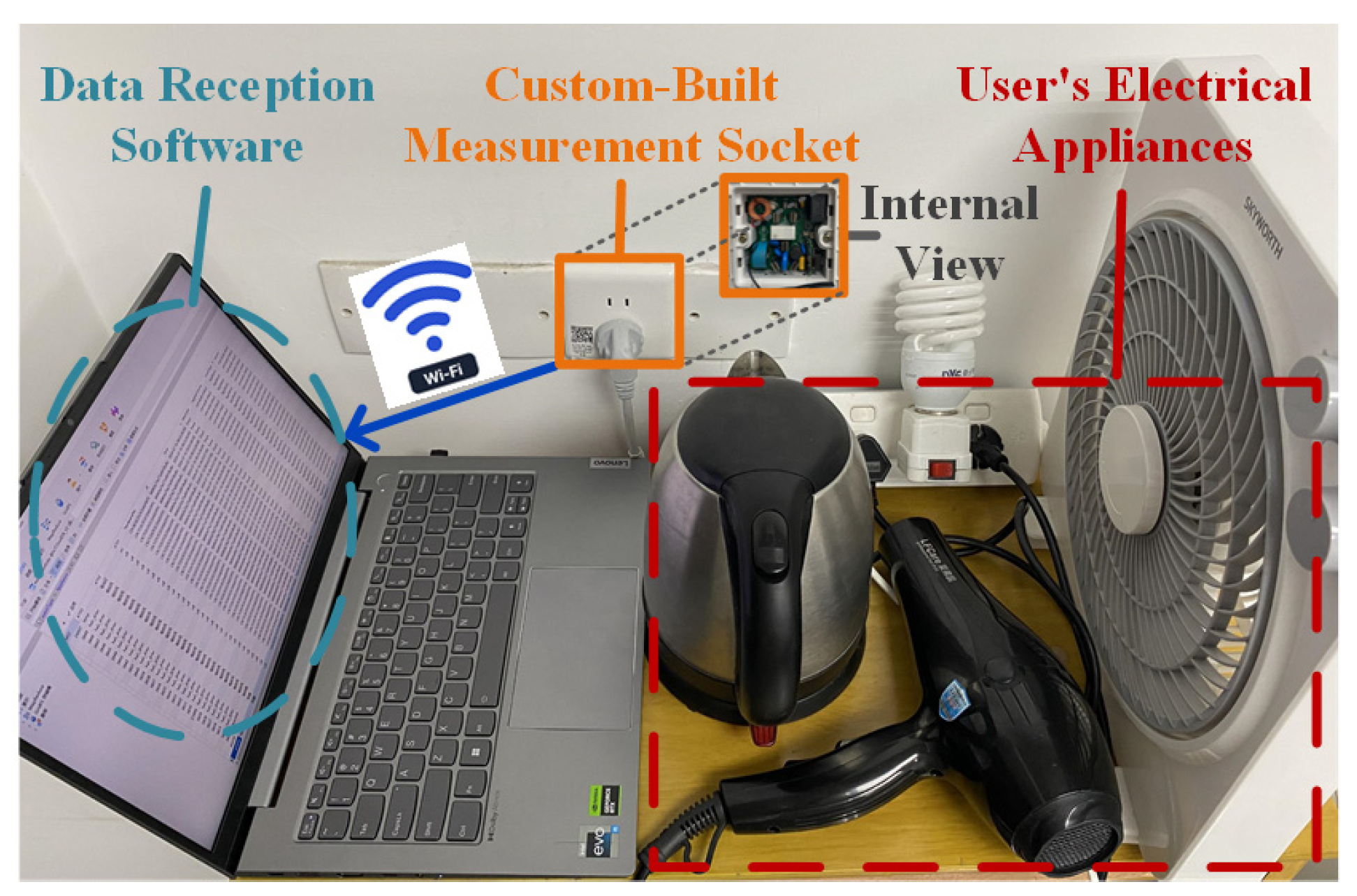
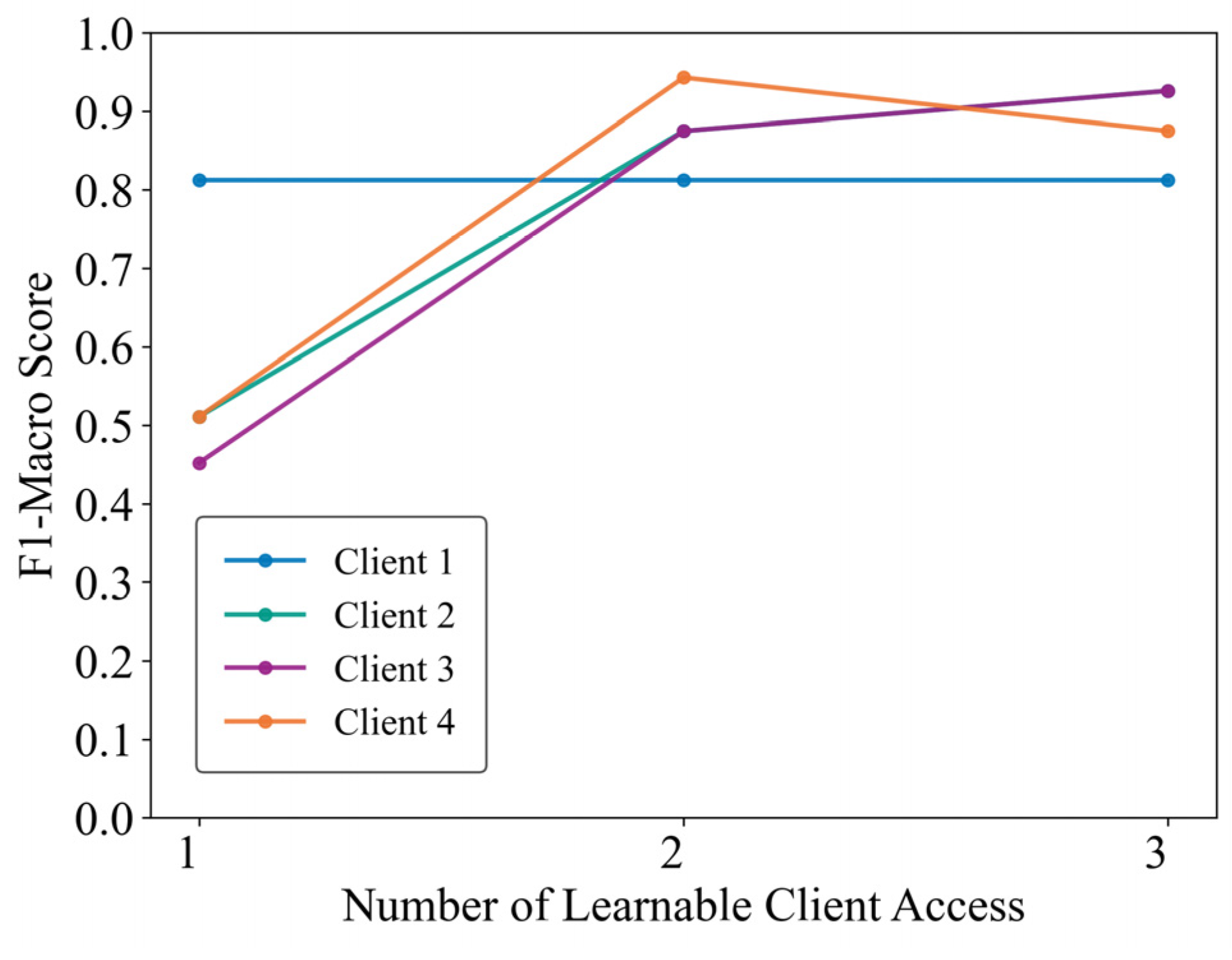
4.6. Practical Validation of the Proposed Framework
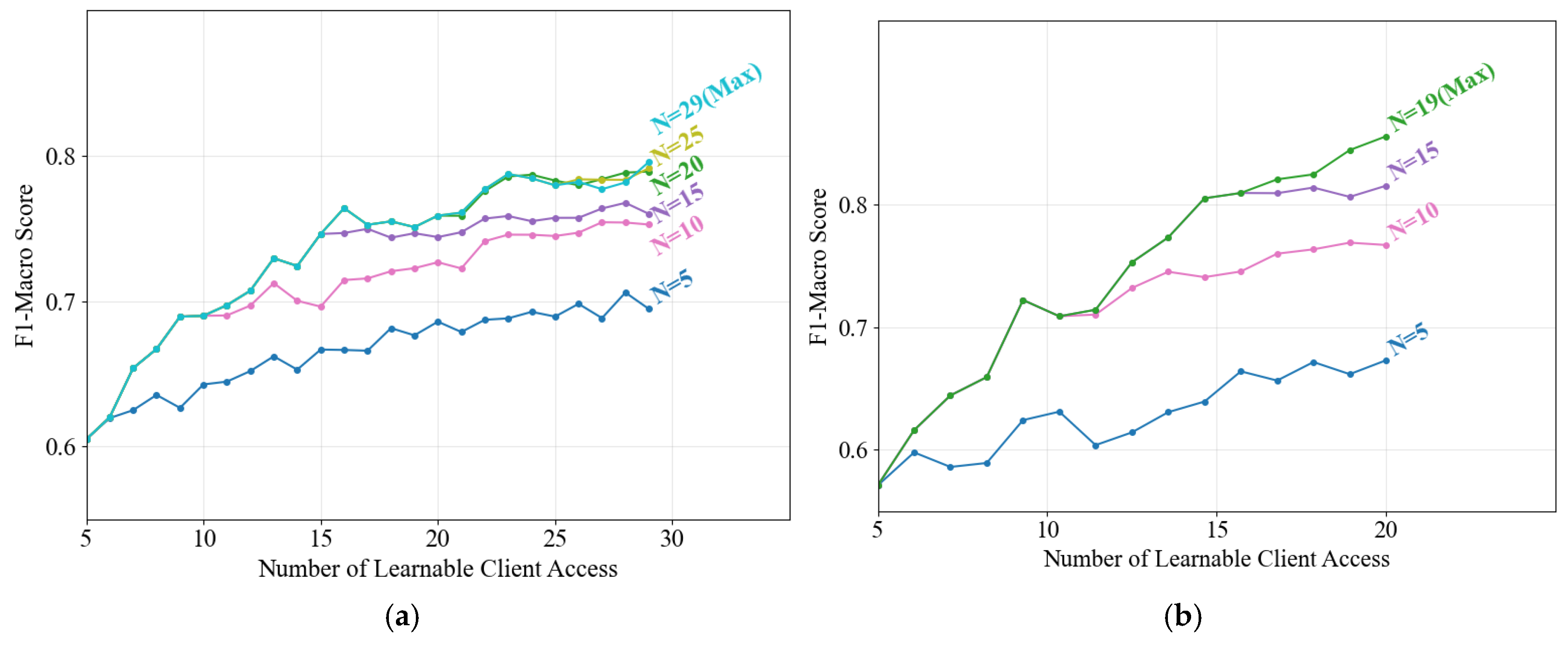
4.7. The Result of Hyperparameter Sensitivity Experiment
4.8. Targeted Ablation Experiments
- (1)
- Removal of the layer-wise dual-supervised auto-encoder (LWDSAE): Replaced with conventional end-to-end auto-encoder learning.
- (2)
- Removal of confidence-based fusion: substituted with a simple majority voting ensemble across all models.
- (3)
- Removal of model quantity limitation: allowed clients to retain all received models without restrictions (disabling the anomaly detection-based model replacement mechanism).
5. Discussion
6. Conclusions
- (1)
- A dual-layer, supervised, learning-based autoencoder model is developed for load identification, which achieves higher lightweight tatus, thereby advancing the practical deployment of NILM systems.
- (2)
- A reconstruction deviation-based model confidence identification strategy is introduced to enable multi-model collaboration across clients, achieving the best-known performance in cross-model aggregation.
- (3)
- A dynamic model composition update method is proposed to continually enhance local load monitoring performance under storage and computational constraints.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Structure |
|---|---|
| Encoder | FC: (150, 128) + ReLU |
| FC: (128, 64) + ReLU | |
| FC: (64, 64) + ReLU | |
| Decoder | FC: (64, 64) |
| FC: (64, 128) | |
| FC: (128, 150) | |
| Classifier | FC: (64, 32) + ReLU |
| FC: (32, NC) |
| Parameter Description | Value |
|---|---|
| Learning batch size | 128 |
| Learning rate | 0.001 |
| Pre-training epoch | 100 |
| Training epoch in learnable client | 100 |
| Optimizer | Adam |
| in (2) | [1, 1, 0.5] for each layer |
| in (2) | [0.5, 1, 1] for each layer |
| in (5) | 1 |
| in (8) | 3 |
| Confidential threshold τ | 1 |
References
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Ma, J. Non-Intrusive Load Monitoring in Smart Grids: A Comprehensive Review. arXiv 2024, arXiv:2403.06474. [Google Scholar]
- Schirmer, P.A.; Mporas, I. Non-Intrusive Load Monitoring: A Review. IEEE Trans. Smart Grid 2023, 14, 769–784. [Google Scholar] [CrossRef]
- Dash, S.; Sahoo, N.C. Electric Energy Disaggregation via Non-Intrusive Load Monitoring: A State-of-the-Art Systematic Review. Electr. Power Syst. Res. 2022, 213, 108673. [Google Scholar] [CrossRef]
- Yan, L.; Tian, W.; Han, J.; Li, Z. Event-Driven Two-Stage Solution to Non-Intrusive Load Monitoring. Appl. Energy 2022, 311, 118627. [Google Scholar] [CrossRef]
- Zheng, Z.; Chen, H.; Luo, X. A Supervised Event-Based Non-Intrusive Load Monitoring for Non-Linear Appliances. Sustainability 2018, 10, 1001. [Google Scholar] [CrossRef]
- Ji, T.; Chen, J.; Zhang, L.; Lai, H.; Wang, J.; Wu, Q. Low Frequency Residential Load Monitoring via Feature Fusion and Deep Learning. Electr. Power Syst. Res. 2025, 238, 111092. [Google Scholar] [CrossRef]
- Elahe, M.F.; Jin, M.; Zeng, P. Knowledge-Based Systematic Feature Extraction for Identifying Households with Plug-in Electric Vehicles. IEEE Trans. Smart Grid 2022, 13, 2259–2268. [Google Scholar] [CrossRef]
- Du, L.; He, D.; Harley, R.G.; Habetler, T.G. Electric Load Classification by Binary Voltage–Current Trajectory Mapping. IEEE Trans. Smart Grid 2016, 7, 358–365. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L.; Klemenjak, C. Adaptive Weighted Recurrence Graphs for Appliance Recognition in Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2021, 12, 398–406. [Google Scholar] [CrossRef]
- Mari, S.; Bucci, G.; Ciancetta, F.; Fiorucci, E.; Fioravanti, A. A Review of Non-Intrusive Load Monitoring Applications in Industrial and Residential Contexts. Energies 2022, 15, 9011. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; You, W. Non-Intrusive Load Monitoring by Voltage–Current Trajectory Enabled Transfer Learning. IEEE Trans. Smart Grid 2019, 10, 5609–5619. [Google Scholar] [CrossRef]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 1419–1429. [Google Scholar] [CrossRef]
- Luo, Q.; Yu, T.; Lan, C.; Huang, Y.; Wang, Z.; Pan, Z. A Generalizable Method for Practical Non-Intrusive Load Monitoring via Metric-Based Meta-Learning. IEEE Trans. Smart Grid 2023, 15, 1103–1115. [Google Scholar] [CrossRef]
- Wang, L.; Mao, S.; Wilamowski, B.M.; Nelms, R.M. Pre-Trained Models for Non-Intrusive Appliance Load Monitoring. IEEE Trans. Green Commun. Netw. 2022, 6, 56–68. [Google Scholar] [CrossRef]
- Zhou, Z.; Xiang, Y.; Xu, H.; Yi, Z.; Shi, D.; Wang, Z. A Novel Transfer Learning-Based Intelligent Nonintrusive Load-Monitoring With Limited Measurements. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J.; Liang, H. Deep Domain Adaptation for Non-Intrusive Load Monitoring Based on a Knowledge Transfer Learning Network. IEEE Trans. Smart Grid 2022, 13, 280–292. [Google Scholar] [CrossRef]
- Dai, S.; Meng, F.; Wang, Q.; Chen, X. DP2-NILM: A Distributed and Privacy-Preserving Framework for Non-Intrusive Load Monitoring. Renew. Sustain. Energy Rev. 2024, 191, 114091. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J. Privacy-Preserving Household Characteristic Identification With Federated Learning Method. IEEE Trans. Smart Grid 2022, 13, 1088–1099. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks 2017. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Psychology of Learning and Motivation; Bower, G.H., Ed.; Academic Press: Cambridge, MA, USA, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming Catastrophic Forgetting in Neural Networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory Aware Synapses: Learning What (Not) to Forget. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 139–154. [Google Scholar]
- Li, S.; Su, T.; Zhang, X.-Y.; Wang, Z. Continual Learning with Knowledge Distillation: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Qiu, L.; Yu, T.; Lan, C. A Semi-Supervised Load Identification Method with Class Incremental Learning. Eng. Appl. Artif. Intell. 2024, 131, 107768. [Google Scholar] [CrossRef]
- Shoham, N.; Avidor, T.; Keren, A.; Israel, N.; Benditkis, D.; Mor-Yosef, L.; Zeitak, I. Overcoming Forgetting in Federated Learning on Non-IID Data. arXiv 2019, arXiv:1910.07796. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A Survey on Federated Learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Anderson, K.D.; Bergés, M.E.; Ocneanu, A.; Benitez, D.; Moura, J.M.F. Event Detection for Non Intrusive Load Monitoring. In Proceedings of the IECON 2012—38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 3312–3317. [Google Scholar]
- Fang, K.; Huang, Y.; Huang, Q.; Yang, S.; Li, Z.; Cheng, H. An Event Detection Approach Based on Improved CUSUM Algorithm and Kalman Filter. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October 2020; pp. 3400–3403. [Google Scholar]
- Tax, D.M.J.; Duin, R.P.W. Support Vector Domain Description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Torres-Barrán, A.; Alaíz, C.M.; Dorronsoro, J.R. Faster SVM Training via Conjugate SMO. Pattern Recognit. 2021, 111, 107644. [Google Scholar] [CrossRef]
- Medico, R.; De Baets, L.; Gao, J.; Giri, S.; Kara, E.; Dhaene, T.; Develder, C.; Berges, M.; Deschrijver, D. A Voltage and Current Measurement Dataset for Plug Load Appliance Identification in Households. Sci. Data 2020, 7, 49. [Google Scholar] [CrossRef]
- Kahl, M.; Haq, A.; Kriechbaumer, T.; Jacobsen, H.-A. WHITED—A Worldwide Household and Industry Transient Energy Data Set. In Proceedings of the 3rd International Workshop on Non-Intrusive Load Monitoring, Vancouver, Canada, 14–15 May 2016. [Google Scholar]
- Moon, J.; Kim, J.; Shin, Y.; Hwang, S. Confidence-Aware Learning for Deep Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7034–7044. [Google Scholar]
| Model | Performance | Complexity | ||||
|---|---|---|---|---|---|---|
| PLAID | WHITED | Params (Mb) | FLOPs | |||
| ACC | F1-Macro | ACC | F1-Macro | |||
| 1DCNN [14] | 0.936 | 0.913 | 0.898 | 0.911 | 0.85 | 77,248 |
| AWRG [10] | 0.974 | 0.937 | 0.969 | 0.946 | 21.22 | 2,582,160 |
| FCNN | 0.916 | 0.868 | 0.850 | 0.856 | 1.05 | 34,048 |
| DS-AE | 0.917 | 0.838 | 0.859 | 0.869 | 1.05 | 34,048 |
| LSDS-AE | 0.974 | 0.966 | 0.976 | 0.965 | ||
| Training Phase | Inference Phase in Each Client | |||
|---|---|---|---|---|
| Calculations | Transmissions | Storages | Calculations | |
| CL | 1 | 1 | ||
| FL | 1 | 1 | ||
| SL | 1 | 1 | ||
| Ours | M | M | ||
| Model Capacity | Memory Usage (Mb) | Inference Time (s) |
|---|---|---|
| 5 | 5.25 | 0.004 |
| 10 | 10.50 | 0.008 |
| 15 | 15.75 | 0.011 |
| 20 | 21.00 | 0.014 |
| Aggregation Strategy | Single Dataset | Cross Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| PLAID | WHITED | PLAID | WHITED | |||||
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Output confidence | 0.700 | 0.605 | 0.520 | 0.453 | 0.715 | 0.619 | 0.696 | 0.617 |
| Majority voting | 0.691 | 0.593 | 0.505 | 0.418 | 0.721 | 0.631 | 0.622 | 0.528 |
| Parameter averaging | 0.566 | 0.446 | 0.292 | 0.181 | 0.344 | 0.281 | 0.166 | 0.063 |
| The proposed | 0.812 | 0.767 | 0.773 | 0.751 | 0.833 | 0.794 | 0.876 | 0.854 |
| Comparison | PLAID | WHITED | PLAID (c.d.) | WHITED (c.d.) |
|---|---|---|---|---|
| Proposed | 0.812/0.767 | 0.773/0.750 | 0.833/0.794 | 0.876/0.854 |
| Proposed w/o LWDS | 0.724/0.660 | 0.551/0.488 | 0.725/0.679 | 0.678/0.607 |
| Proposed w/o confidence fusion | 0.691/0.593 | 0.506/0.418 | 0.720/0.631 | 0.622/0.528 |
| Proposed w/o model portfolio limit | 0.807/0.763 | 0.773/0.750 | 0.821/0.800 | 0.876/0.854 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, C.; Luo, Q.; Yu, T.; Liang, M.; Pan, Z. Confidence-Based, Collaborative, Distributed Continual Learning Framework for Non-Intrusive Load Monitoring in Smart Grids. Sensors 2025, 25, 3667. https://doi.org/10.3390/s25123667
Lan C, Luo Q, Yu T, Liang M, Pan Z. Confidence-Based, Collaborative, Distributed Continual Learning Framework for Non-Intrusive Load Monitoring in Smart Grids. Sensors. 2025; 25(12):3667. https://doi.org/10.3390/s25123667
Chicago/Turabian StyleLan, Chaofan, Qingquan Luo, Tao Yu, Minhang Liang, and Zhenning Pan. 2025. "Confidence-Based, Collaborative, Distributed Continual Learning Framework for Non-Intrusive Load Monitoring in Smart Grids" Sensors 25, no. 12: 3667. https://doi.org/10.3390/s25123667
APA StyleLan, C., Luo, Q., Yu, T., Liang, M., & Pan, Z. (2025). Confidence-Based, Collaborative, Distributed Continual Learning Framework for Non-Intrusive Load Monitoring in Smart Grids. Sensors, 25(12), 3667. https://doi.org/10.3390/s25123667