
Demonstration of 50 Gbps Long-Haul D-Band Radio-over-Fiber System with 2D-Convolutional Neural Network Equalizer for Joint Phase Noise and Nonlinearity Mitigation


Abstract
1. Introduction
2. Principle
2.1. Phase Recovery Theory
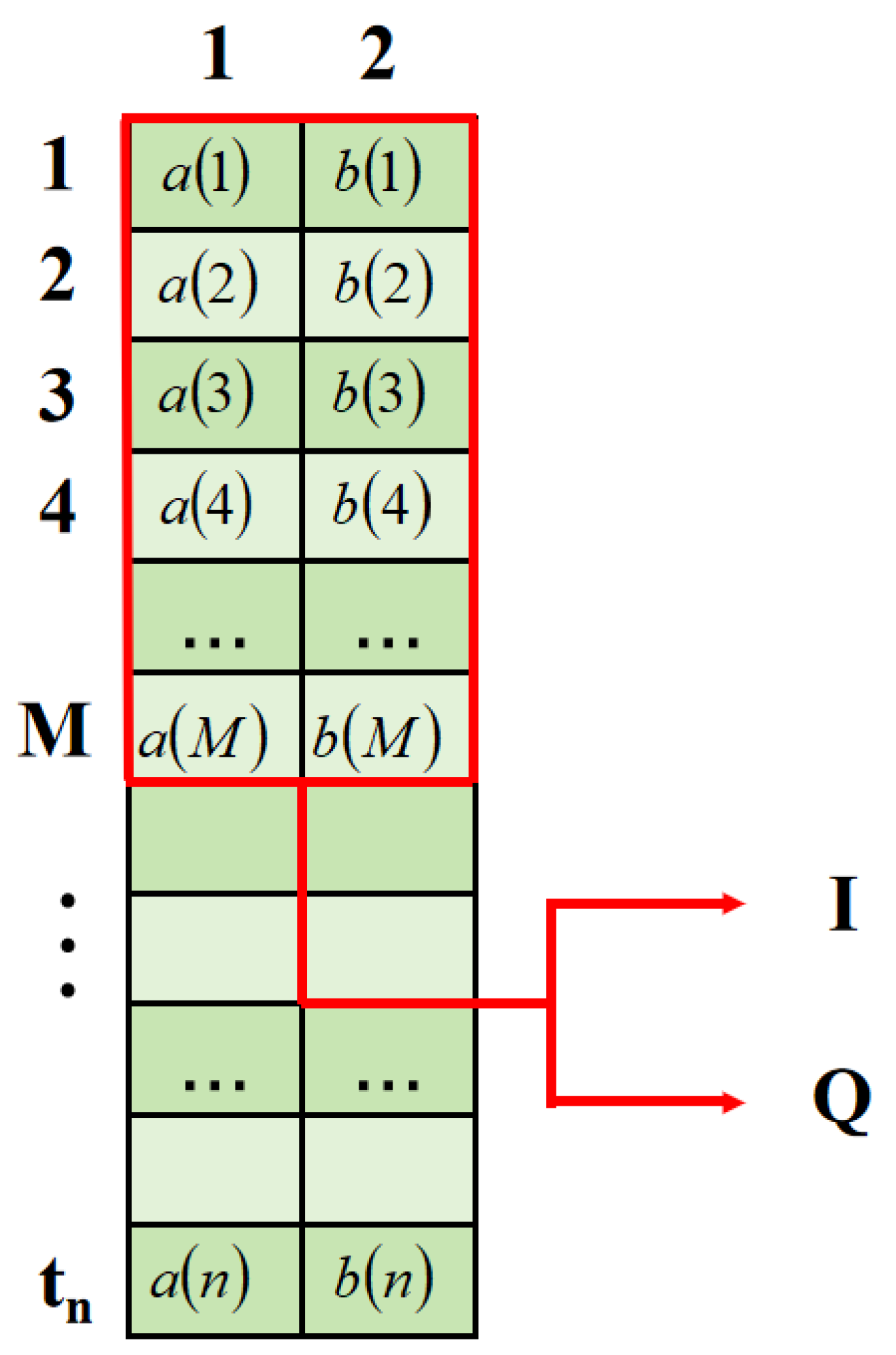
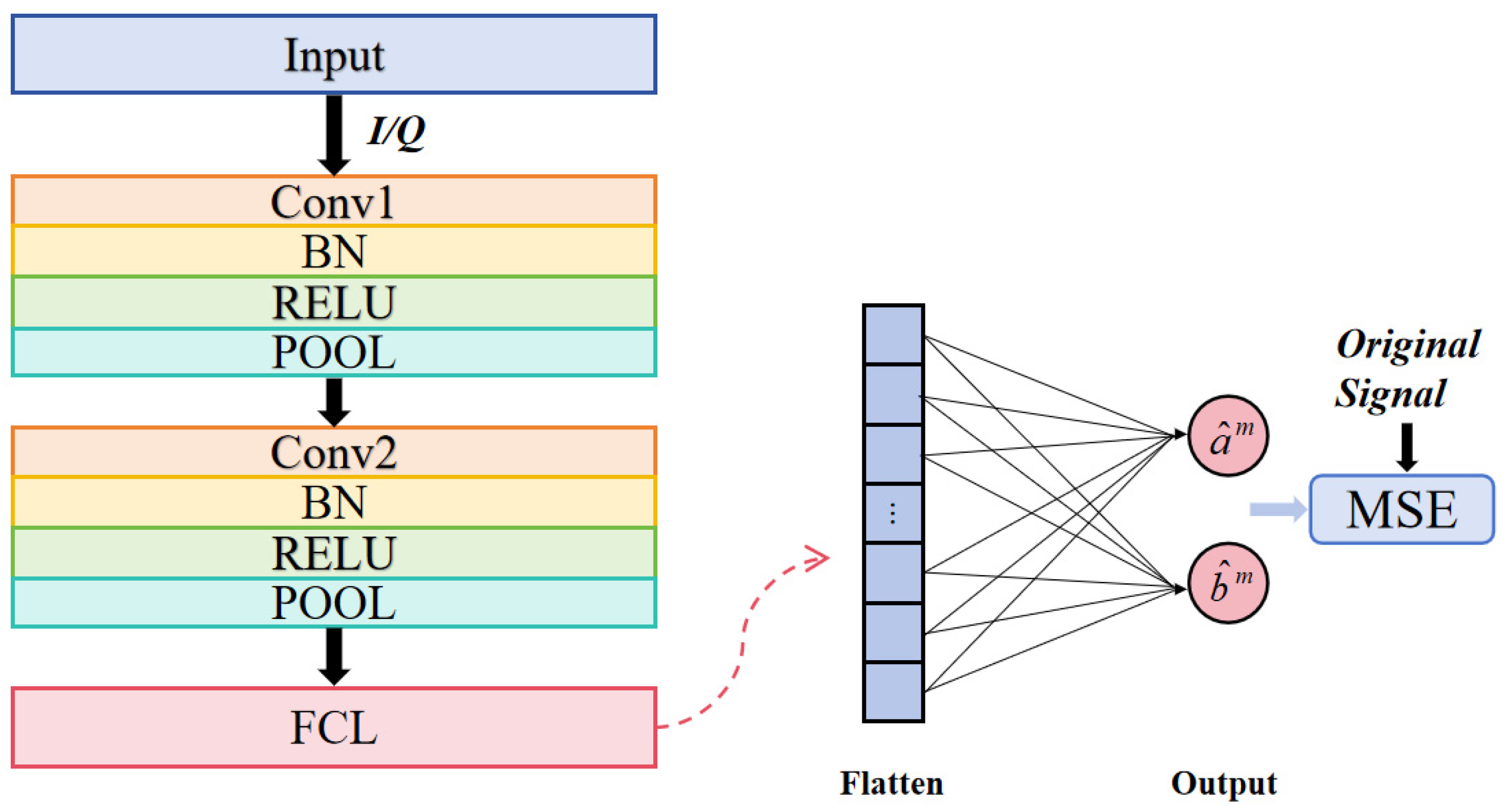
2.2. Principle of Two-Dimensional Convolutional Neural Networks
3. Experimental Setup
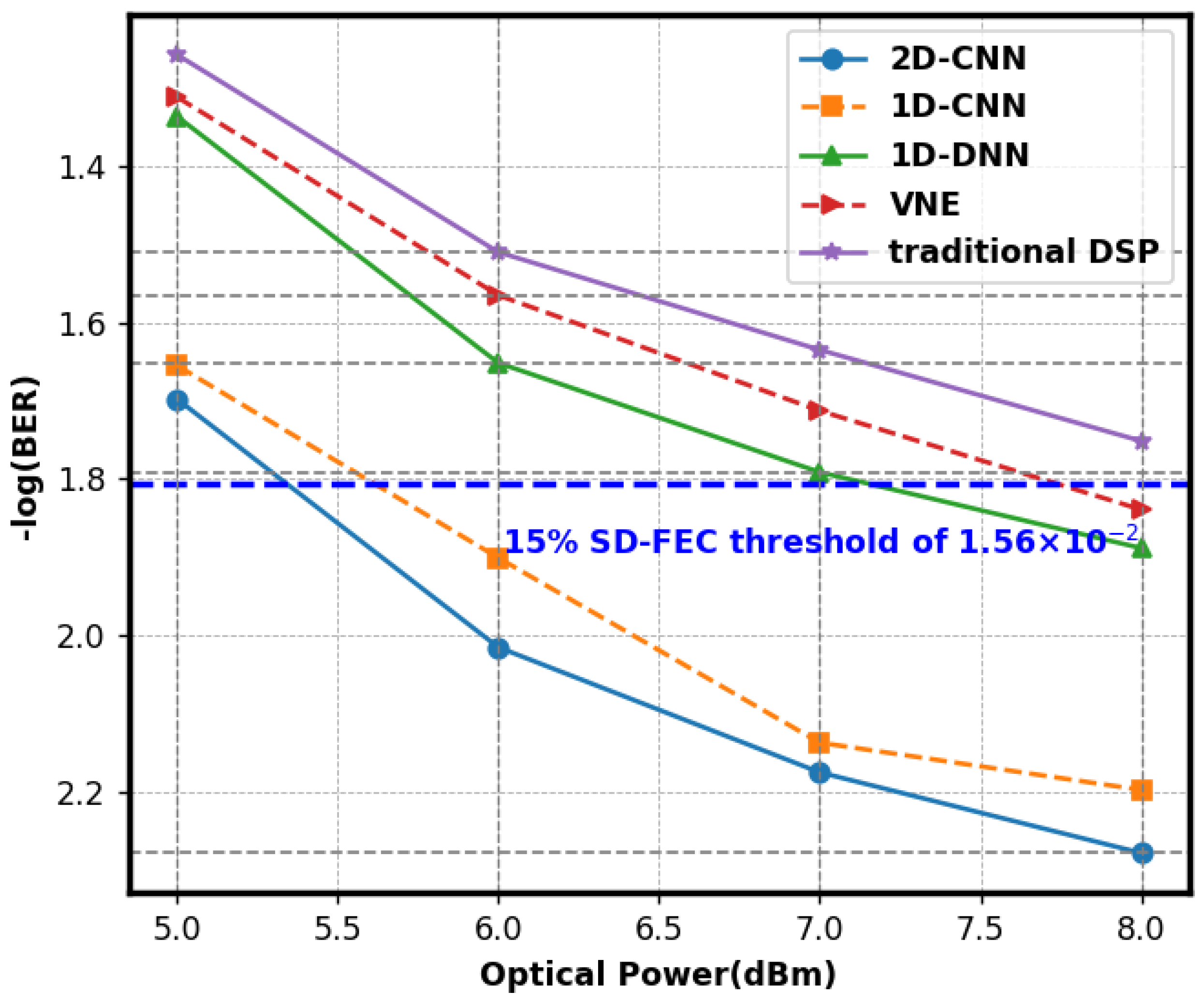
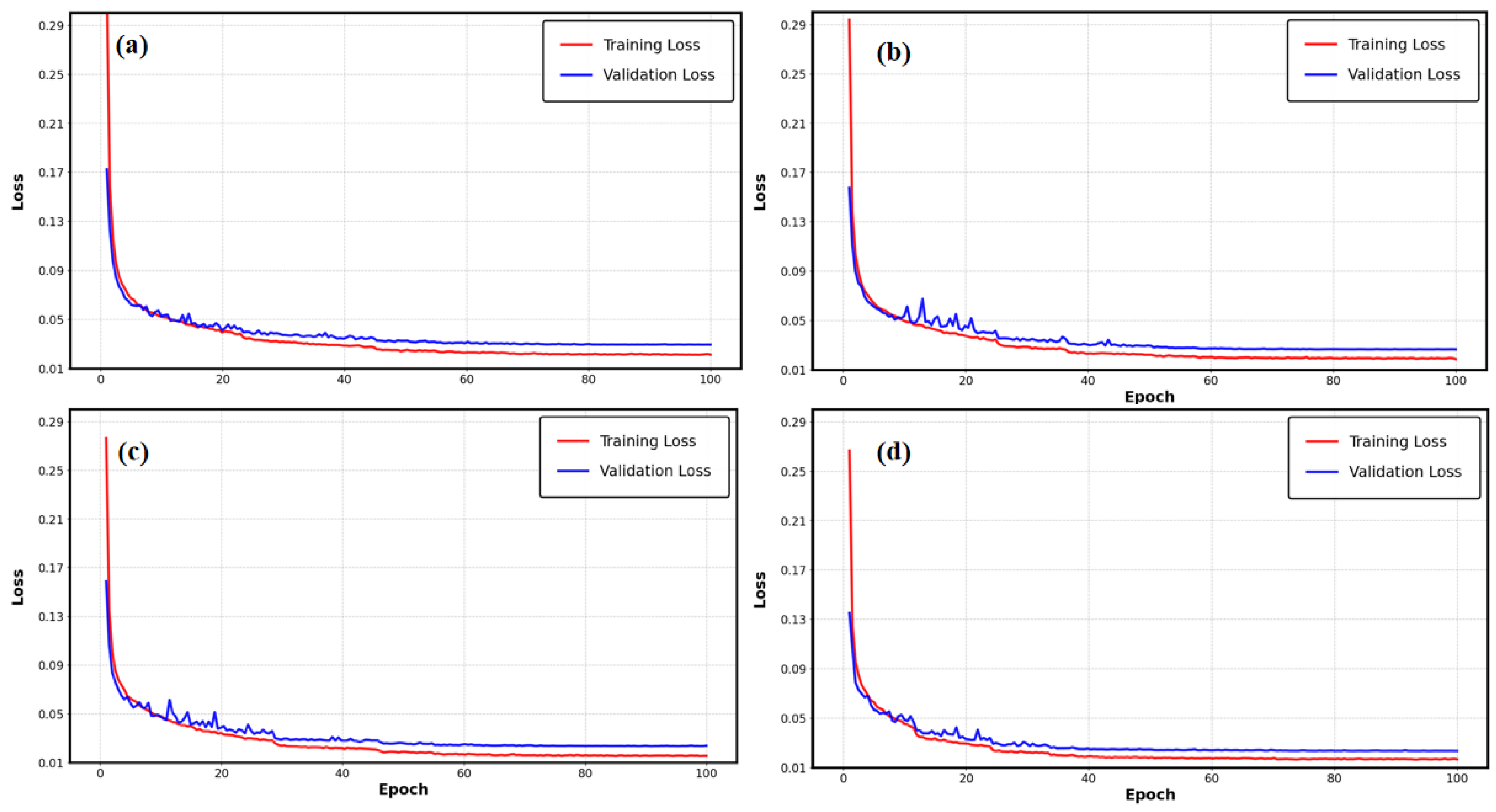
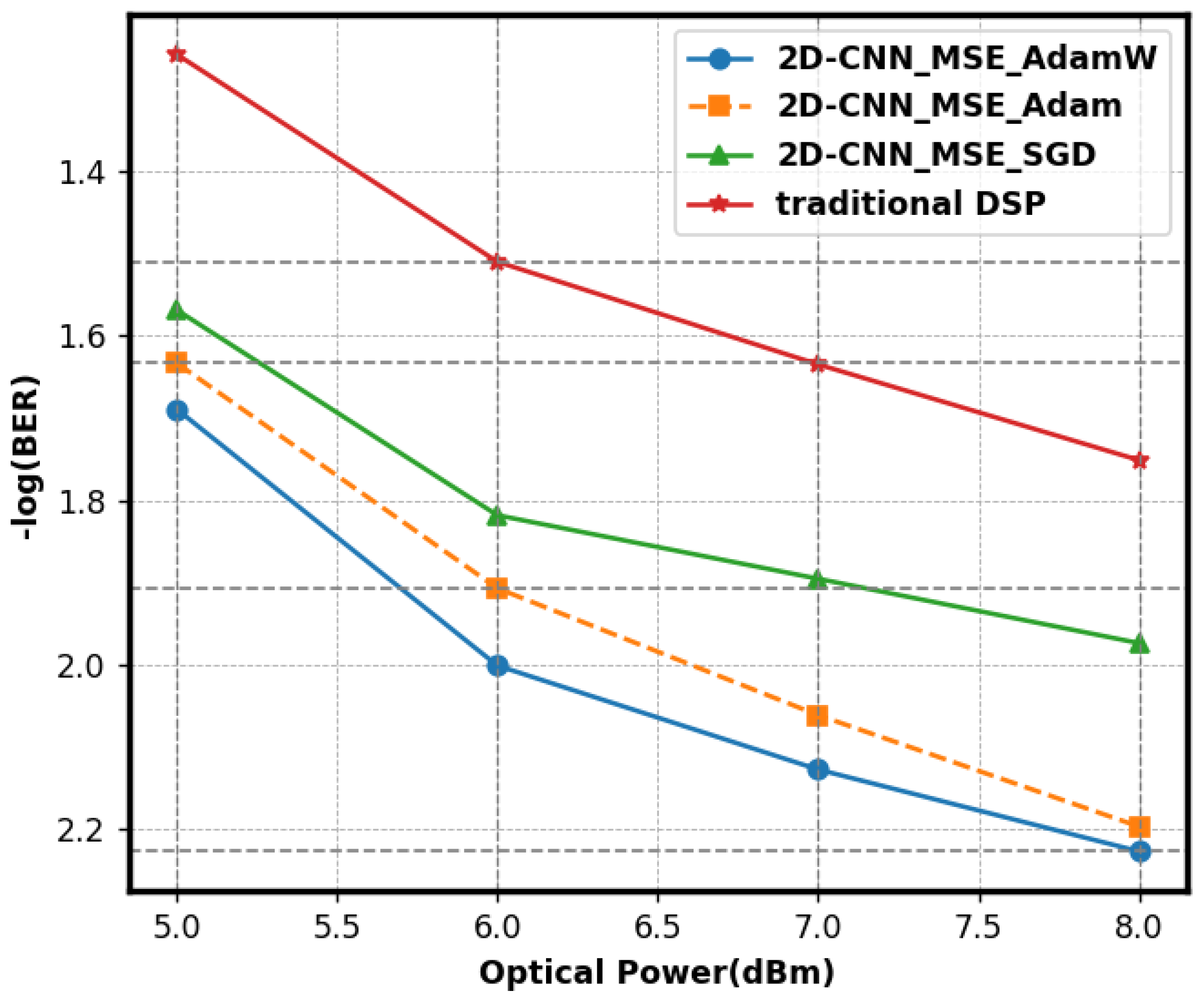
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hamada, H.; Nosaka, H.; Tsutsumi, T.; Sugiyama, H.; Matsuzaki, H.; Song, H.-J.; Itami, G.; Fujimura, T.; Abdo, I.; Okada, K. Millimeter-wave InP device technologies for ultra-high speed wireless communications toward beyond 5G. In Proceedings of the 2019 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Strinati, E.C.; Barbarossa, S.; Gonzalez-Jimenez, J.L.; Ktenas, D.; Cassiau, N.; Maret, L.; Dehos, C. 6G: The next frontier: From holographic messaging to artificial intelligence using subterahertz and visible light communication. IEEE Veh. Technol. Mag. 2019, 14, 42–50. [Google Scholar] [CrossRef]
- Barrera, F.; Siligaris, A.; Blampey, B.; Gonzalez-Jimenez, J.L. A D-band 4-ways power splitter/combiner implemented on a 28nm bulk CMOS process. In Proceedings of the 2019 49th European Microwave Conference (EuMC), Paris, France, 1–3 October 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Song, H.J.; Lee, N. Terahertz communications: Challenges in the next decade. IEEE Trans. Terahertz Sci. Technol. 2021, 12, 105–117. [Google Scholar] [CrossRef]
- Alavi, S.E.; Soltanian, M.R.K.; Amiri, I.S.; Khalily, M.; Supa’at, A.S.M.; Ahmad, H. Towards 5G: A photonic based millimeter wave signal generation for applying in 5G access fronthaul. Sci. Rep. 2016, 6, 19891. [Google Scholar] [CrossRef]
- Yang, Y.; Lim, C.; Nirmalathas, A. Investigation on transport schemes for efficient high-frequency broadband OFDM transmission in fibre-wireless links. J. Light. Technol. 2013, 32, 267–274. [Google Scholar] [CrossRef]
- Zhou, W.; Qin, C. Simultaneous generation of 40, 80 and 120 GHz optical millimeter-wave from one Mach-Zehnder modulator and demonstration of millimeter-wave transmission and down-conversion. Opt. Commun. 2017, 398, 101–106. [Google Scholar] [CrossRef]
- Xiao, J.; Yu, J.; Li, X.; Xu, Y.; Zhang, Z.; Chen, L. 40-Gb/s PDM-QPSK signal transmission over 160-m wireless distance at W-band. Opt. Lett. 2015, 40, 998–1001. [Google Scholar] [CrossRef]
- Zhou, W.; Zhao, L.; Zhang, J.; Wang, K. Four sub-channel single sideband generation of vector mm-wave based on an I/Q modulator. IEEE Photonics J. 2019, 11, 1–9. [Google Scholar] [CrossRef]
- Dat, P.T.; Kanno, A.; Yamamoto, N.; Kawanishi, T. 190-Gb/s CPRI-equivalent rate fiber-wireless mobile fronthaul for simultaneous transmission of LTE-A and F-OFDM signals. In Proceedings of the ECOC 2016; 42nd European Conference on Optical Communication, Dusseldorf, Germany, 18–22 September 2016; VDE: Berlin, Germany, 2016. [Google Scholar]
- Kanno, A.; Dat, P.T.; Kuri, T.; Hosako, I.; Kawanishi, T.; Yoshida, Y.; Yasumura, Y.; Kitayama, K. Coherent radio-over-fiber and millimeter-wave radio seamless transmission system for resilient access networks. IEEE Photonics J. 2012, 4, 2196–2204. [Google Scholar] [CrossRef]
- Asif Khan, M.K.; Ali, F.; Irfan, M.; Muhammad, F.; Althobiani, F.; Ali, A.; Khan, S.; Rahman, S.; Perun, G.; Glowacz, A. Mitigation of phase noise and nonlinearities for high capacity radio-over-fiber links. Electronics 2021, 10, 345. [Google Scholar] [CrossRef]
- Fan, Q.; Lu, C.; Lau, A.P.T. Combined Neural Network and Adaptive DSP Training for Long-Haul Optical Communications. J. Light. Technol. 2021, 39, 7083–7091. [Google Scholar] [CrossRef]
- Zhang, S.; Yaman, F.; Nakamura, K.; Inoue, T.; Kamalov, V.; Jovanovski, L.; Vusirikala, V.; Mateo, E.; Inada, Y.; Wang, T. Field and lab experimental demonstration of nonlinear impairment compensation using neural networks. Nat. Commun. 2019, 10, 3033. [Google Scholar] [CrossRef]
- Ghose, S.; Singh, N.; Singh, P. Image denoising using deep learning: Convolutional neural network. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Shi, J.; Huang, A.P.; Tao, L.W. Deep Learning Aided Channel Estimation and Signal Detection for Underwater Optical Communication. Chin. J. Lasers 2022, 49, 1706004. [Google Scholar]
- Zhixuan, C.; Hongbo, Z.; Min, Z.; Ju, C.; Jiao, L.; Jie, D.; Qianwu, Z. Fiber Nonlinear Impairments Compensation Algorithm Based on CNN-BiLSTM-Attention Model. Electr. Power Inf. Commun. Technol. 2023, 21, 7–12. [Google Scholar]
- Wang, K.; Wang, C.; Li, W.; Wang, Y.; Ding, J.; Liu, C.; Kong, M.; Wang, F.; Zhou, W.; Zhao, F.; et al. Complex-valued 2D-CNN equalization for OFDM signals in a photonics-aided MMW communication system at the D-band. J. Light. Technol. 2022, 40, 2791–2798. [Google Scholar] [CrossRef]
- Wei, Y.; Yu, J.; Zhao, X.; Yang, X.; Wang, M.; Li, W.; Tian, P.; Han, Y.; Zhang, Q.; Tan, J.; et al. Demonstration of a photonics-aided 4,600-m wireless transmission system in the sub-THz band. J. Light. Technol. 2024, 42, 8564–8576. [Google Scholar] [CrossRef]
- Lu, X.; Yu, J.; Li, W.; Zhao, X.; Zhu, M.; Zhang, J.; Yang, W.; Wang, M.; Wei, Y.; Zhang, Q.; et al. Realizing 10 Gbps Frequency Continuously Tunable D-Band Signal Transmission With 20 Kilometers Wireless Distance Based on Photon Assistance. J. Light. Technol. 2025, 43, 5709–5717. [Google Scholar] [CrossRef]
- Wang, C.; Wang, K.; Tan, Y.; Wang, F.; Sang, B.; Li, W.; Zhou, W.; Yu, J. High-speed terahertz band radio-over-fiber system using hybrid time-frequency domain equalization. IEEE Photonics Technol. Lett. 2022, 34, 559–562. [Google Scholar] [CrossRef]
- Torkaman, P.; Latifi, S.M.; Feng, K.-M.; Yang, S.-H. Nonlinearity-robust im/dd thz communication system via two-stage deep learning equalizer. IEEE Commun. Lett. 2024, 28, 1805–1809. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, L.; Yang, Z.; Yang, H.; Lü, Z.; Pang, X.; Ozolins, O.; Yu, X. Single-lane 200 Gbit/s photonic wireless transmission of multicarrier 64-QAM signals at 300 GHz over 30 m. Chin. Opt. Lett. 2023, 21, 023901. [Google Scholar] [CrossRef]
- Leshem, A.; Yemini, M. Phase noise compensation for OFDM systems. IEEE Trans. Signal Process. 2017, 65, 5675–5686. [Google Scholar] [CrossRef]
- Chung, M.; Liu, L.; Edfors, O.; Sheikh, F. Phase-noise compensation for OFDM systems exploiting coherence bandwidth: Modeling, algorithms, and analysis. IEEE Trans. Wirel. Commun. 2021, 21, 3040–3056. [Google Scholar] [CrossRef]
- Mei, R.; Wang, Z.; Hu, W. Robust blind equalization algorithm using convolutional neural network. IEEE Signal Process. Lett. 2022, 29, 1569–1573. [Google Scholar] [CrossRef]
- Chang, Z.; Wang, Y.; Li, H.; Wang, Z. Complex CNN-based equalization for communication signal. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yongshi, W.; Jie, G.; Hao, L.; Li, L.; Zhigang, W.; Houjun, W. CNN-based modulation classification in the complicated communication channel. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, A.; Gupta, U.; Chinnakotla, M.K.; Srikanth, R.; Galley, M.; Agrawal, P. Understanding emotions in text using deep learning and big data. Comput. Hum. Behav. 2019, 93, 309–317. [Google Scholar] [CrossRef]
- Rusk, N. Deep learning. Nat. Methods 2016, 13, 35. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Frequency | Equalizer | Modulation Format | Distance | BER |
|---|---|---|---|---|---|
| [18] | 120 GHz | 2D-CNN | 16-QAM | 200 m | ≤3.8 × 10−3 |
| [19] | 125/135/145 GHz | Volterra equalizer | PDM-16-QAM | 4600 m | ≤2.4 × 10−2 |
| [20] | 110–170 GHz | LSTM + RF | QPSK | 20 km | <3.8 × 10−3 |
| [21] | 340 GHz | 2D-CNN | 16-QAM | 54.6 m | ≤10−2 |
| [22] | 125 GHz | LSTM + RF | 16-QAM | 4.5 m | 5.64 × 10−4 |
| [23] | 286/299/312 GHz | MMA + Viterbi | 64-QAM | 30 m | <4.5 × 10−3 |
| Term | 1D-DNN | 1D-CNN | 2D-CNN |
|---|---|---|---|
| Layers | 3 FCL | 2 Conv + 2 FCL | 2 Conv (3 × 2, 3 × 1) + 2 FCL |
| Kernel size | Not used | (3), (3) | (3, 2), (3, 1) |
| Activation | ReLU | ReLU | ReLU |
| Epoch | 100 | 100 | 100 |
| Batch Size | 512 | 512 | 512 |
| Loss function | MSELoss | MSELoss + L1 | MSELoss + L1 |
| Optimizer | AdamW | AdamW | AdamW |
| Pooling size | Not used | (2) | (2, 1) |
| Total Parameters | 239,042 | 139,802 | 139,702 |
| MACC | 236,160 | 229,440 | 229,440 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Xu, S.; Wang, Q.; Zhang, J.; Ge, J.; Lin, J.; Ma, Y.; Wang, S.; Ou, Z.; Zhou, W. Demonstration of 50 Gbps Long-Haul D-Band Radio-over-Fiber System with 2D-Convolutional Neural Network Equalizer for Joint Phase Noise and Nonlinearity Mitigation. Sensors 2025, 25, 3661. https://doi.org/10.3390/s25123661
Jiang Y, Xu S, Wang Q, Zhang J, Ge J, Lin J, Ma Y, Wang S, Ou Z, Zhou W. Demonstration of 50 Gbps Long-Haul D-Band Radio-over-Fiber System with 2D-Convolutional Neural Network Equalizer for Joint Phase Noise and Nonlinearity Mitigation. Sensors. 2025; 25(12):3661. https://doi.org/10.3390/s25123661
Chicago/Turabian StyleJiang, Yachen, Sicong Xu, Qihang Wang, Jie Zhang, Jingtao Ge, Jingwen Lin, Yuan Ma, Siqi Wang, Zhihang Ou, and Wen Zhou. 2025. "Demonstration of 50 Gbps Long-Haul D-Band Radio-over-Fiber System with 2D-Convolutional Neural Network Equalizer for Joint Phase Noise and Nonlinearity Mitigation" Sensors 25, no. 12: 3661. https://doi.org/10.3390/s25123661
APA StyleJiang, Y., Xu, S., Wang, Q., Zhang, J., Ge, J., Lin, J., Ma, Y., Wang, S., Ou, Z., & Zhou, W. (2025). Demonstration of 50 Gbps Long-Haul D-Band Radio-over-Fiber System with 2D-Convolutional Neural Network Equalizer for Joint Phase Noise and Nonlinearity Mitigation. Sensors, 25(12), 3661. https://doi.org/10.3390/s25123661