4.1. Digital Twin Categorization and Fidelity Measurement
Digital twins represent virtual replicas of physical objects, and their construction methodology significantly impacts their fidelity and utility. As illustrated in
Figure 1, we categorize digital twins (
) created from down-sampled point clouds (
) into three distinct types based on the original object’s geometry (
) and the reconstruction approach (
).
For objects with predominantly primitive or standard surface geometry, two reconstruction approaches are viable. Type A digital twins employ parametric representation, where the model is defined by fitted geometric primitives (planes, spheres, cylinders, etc.) or standard parametric surfaces. This approach involves segmenting the down-sampled point cloud and applying least-squares methods to estimate parameters (
) that define these geometric entities. As shown in
Figure 1, surfaces like planes and cylinders can be effectively represented by their mathematical equations, yielding compact yet precise digital representations.
Alternatively, Type B digital twins utilize mesh-based representation for parameterizable objects. Although the underlying geometry could be described parametrically, this approach directly applies surface reconstruction algorithms (such as Ball Pivoting, Poisson Surface Reconstruction, or Alpha Shapes) to the down-sampled point cloud. The resulting triangle mesh provides visual fidelity while maintaining a direct connection to the original geometric properties.
Figure 1 demonstrates how a standard object like a table can be disassembled into basic closed geometries (cylindrical top and rectangular legs), which can then be individually triangulated to form a complete mesh model.
For objects with free-form or organic geometry (such as the bunny model shown in
Figure 1), Type C digital twins are inherently represented as triangle meshes since their complexity makes parametric fitting impractical. This approach applies surface reconstruction algorithms directly to the down-sampled point cloud to generate a mesh that captures the intricate shapes and features of complex objects. The figure clearly illustrates how triangulation transforms the smooth, organic bunny shape into a detailed mesh representation capable of preserving its distinctive features.
The fidelity assessment for each digital twin type requires specialized metrics tailored to their representation. For Type A twins, we evaluate parameter accuracy, while Types B and C necessitate geometric comparison measures between reconstructed surfaces and ground truth data. This systematic categorization forms the foundation for our experimental evaluation of different down-sampling methods and their impact on digital twin fidelity.
The assessment of fidelity, denoted as , employs metrics specifically chosen based on the type of digital twin being evaluated.
For Type A digital twins, where the reconstructed model is represented by a fitted surface defined by a parameter vector , fidelity is measured by the discrepancy between the estimated parameters and the ground truth parameters . A robust method for quantifying this difference is the L1 norm, chosen for its resilience to outliers. This metric is calculated as , where k represents the number of parameters in the vector .
When the digital twin is represented as a mesh (applicable to both Type B and Type C), the fidelity assessment relies on metrics that quantify the geometric discrepancy between the reconstructed representation and the ground truth. This involves comparing either the down-sampled point cloud or the reconstructed mesh against the ground truth mesh or the ground truth point cloud . Several geometric metrics are utilized for this purpose.
One such metric is the Point-to-Mesh Distance (
). This asymmetric measure calculates the average distance from each point
in the down-sampled point cloud
to its nearest corresponding point
on the continuous surface
of the ground truth mesh. It effectively quantifies how closely the sampled points conform to the actual surface, providing insight into reconstruction accuracy from the sample’s perspective. The formulation is
, and it is often computed using tools like Metro [
54].
Another key metric is the Chamfer Distance (
), a symmetric measure evaluating the similarity between two point sets,
and
. It provides a global assessment of alignment by summing the average distance from each point in one set to its nearest neighbor in the other set, and vice versa. Using non-squared distances, the formulation is
. Although the original concept is older [
55], it has been widely adopted, particularly in deep learning contexts [
56], often using the sum of the average squared distances in implementations.
To address the sensitivity of the standard Hausdorff Distance [
57] to outliers, the Percentile Hausdorff Distance (
) is employed. This more robust metric calculates a specific percentile (e.g., 95th) of the nearest neighbor distances rather than the maximum. We consider its two directional components separately, as discussed in metric evaluation surveys [
58]. The sample-to-ground truth component (
) measures the 95th percentile of distances from points in
to their nearest neighbors in
, indicating how well
is covered by the true surface while tolerating some outliers in
. Conversely, the ground truth-to-sample component (
) measures the 95th percentile of distances from points in
to their nearest neighbors in
, indicating how well the sample
covers the true surface, tolerating some unrepresented points in
. Letting
and
, these are formulated as
and
.
Finally, the Viewpoint Feature Histogram (VFH) Distance (
) assesses similarity based on global shape and viewpoint characteristics. VFH itself is a global descriptor for 3D point clouds, encoding geometric information derived from surface normals and viewpoint directions [
59,
60]. The
is not a direct spatial distance between points but rather a distance computed between the VFH descriptor histograms (
) of the reconstructed model/point cloud (
or
) and the ground truth model/point cloud (
or
). A smaller distance, typically calculated using the L2 norm
, indicates greater similarity in the overall shape and viewpoint properties captured by the histograms:
.
4.2. Experimental Design
To rigorously evaluate the efficacy of the proposed Low-Discrepancy Sequences-driven down-sampling method using Hilbert curve ordering (LDS-Hilbert), we designed a series of four comprehensive experiments. These experiments assess the method’s performance across a spectrum of object complexities and digital twin reconstruction tasks, comparing it against three widely recognized benchmark down-sampling techniques: Simple Random Sampling (SRS), Farthest Point Sampling (FPS), and Voxel Grid Filtering (Voxel). Furthermore, to isolate the contribution of the Hilbert curve ordering component within our proposed framework, we include an ablation study in each experiment by evaluating a variant of our method that replaces the Hilbert curve sorting step with sorting based on the first principal component obtained via Principal Component Analysis (PCA), referred to as LDS-PCA.
All experiments were implemented in Python 3.8 on a laptop with an Intel Core i7-11800H CPU (Intel, Santa Clara, CA, USA). Core point cloud and mesh operations utilized Open3D [
61] and NumPy [
62]. VFH computation leveraged the Python interface to the Point Cloud Library (PCL) [
14]. Farthest Point Sampling (FPS) was implemented via the fpsample library [
63], and Hilbert curve generation used the numpy-Hilbert-curve package [
64] which relies on Skilling’s work [
51]. Additional libraries, such as Scikit-learn [
65] and SciPy [
66], were employed for specific tasks like PCA and parametric fitting.
To provide a direct comparison of LDS-Hilbert against the other methods (SRS, FPS, Voxel, LDS-PCA), we introduce a
Performance Ratio for each fidelity metric and each object. Let
denote the calculated value of the
k-th fidelity metric (i.e.,
,
,
,
,
,
) for the
j-th object using a specific down-sampling method. For a given comparison method Comp (where Comp ∈ SRS, FPS, Voxel, LDS-PCA), the Performance Ratio relative to LDS-Hilbert is calculated as:
Since lower values indicate higher fidelity for all metrics used in these experiments, a ratio signifies that the LDS-Hilbert method achieved a better (lower) score and thus outperformed the comparison method ‘Comp’ for that specific metric k and object j.
To summarize the overall performance within each experiment, we calculate the percentage of objects for which LDS-Hilbert outperforms each comparison method on a given metric. Let
be the total number of objects in an experiment. For a specific metric
k and comparison method Comp, we count the number of objects
, where
. The
Win Percentage is then:
A Win Percentage greater than 50% indicates that LDS-Hilbert outperformed the comparison method ‘Comp’ on that specific metric for the majority of objects within that experiment. This systematic evaluation across diverse datasets, reconstruction tasks, and metrics aims to provide robust evidence regarding the efficacy of the proposed LDS-Hilbert down-sampling method in enhancing digital twin fidelity.
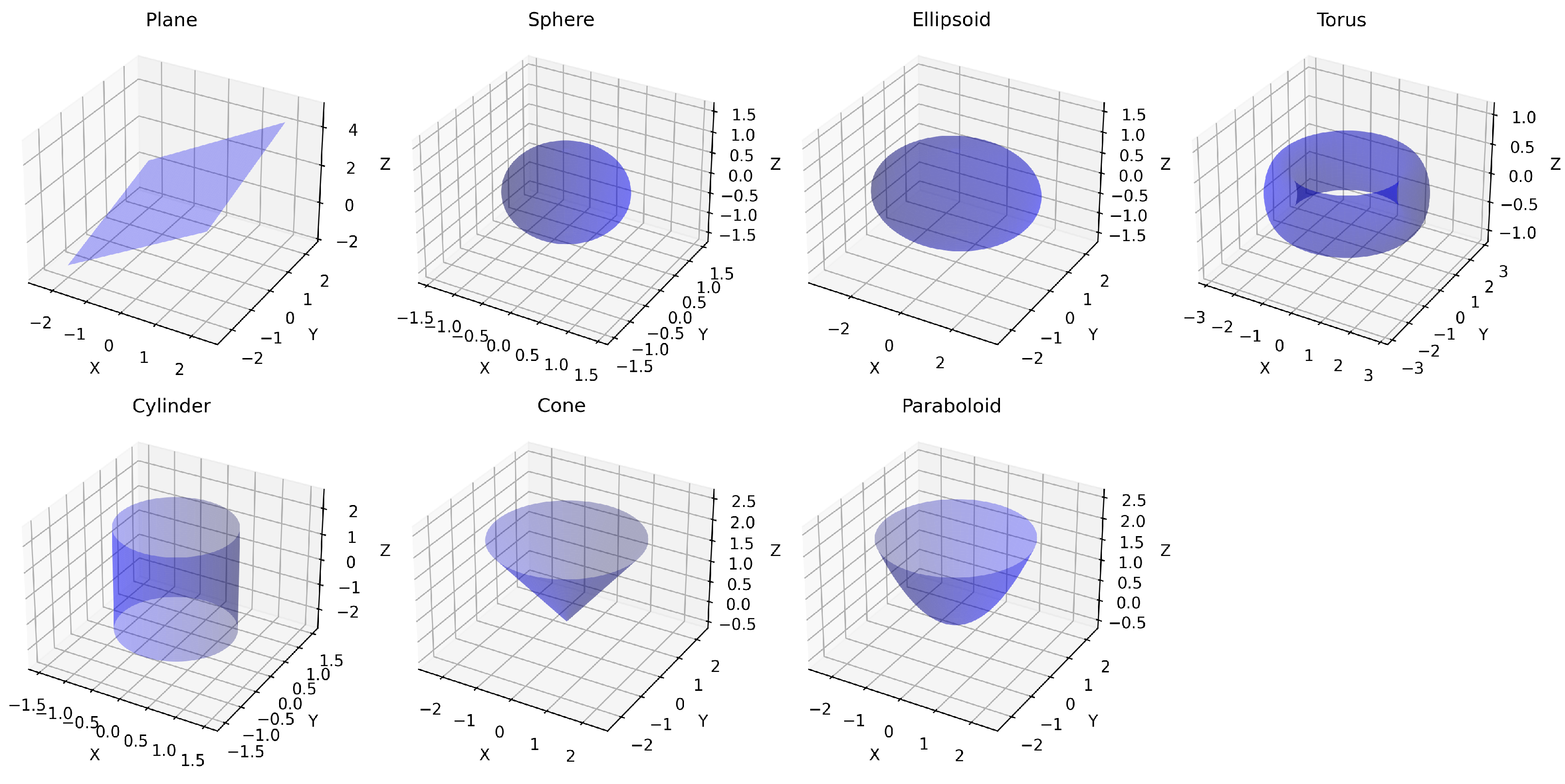
4.3. Experiment 1: Parametric Surface Fidelity
This experiment evaluated the capability of various down-sampling methods (LDS-Hilbert, LDS-PCA, SRS, FPS, Voxel) to retain geometric information essential for accurately recovering the parameters of simple, known shapes (Type A Digital Twin). The dataset consisted of synthetic point clouds generated by sampling points uniformly from seven distinct analytical surfaces: plane, sphere, ellipsoid, torus, cylinder, cone, and paraboloid, each defined by specific ground truth parameters (e.g., sphere radius = 1, ellipsoid semi-axes = 3,2,1; see
Appendix B for complete details). Points were sampled within defined parameter ranges for each surface type. To simulate measurement error, controlled Gaussian noise (
relative to object scale) was added independently to the coordinates of each point.
Point clouds were generated at three sizes (
N = 9180,
N = 37,240 and
N = 95,760), resulting in 21 unique synthetic objects. Each down-sampling method reduced the point clouds to 10% and 20% of their original size (ratio = 0.10 and ratio = 0.20). The resulting down-sampled point cloud
was then used to fit the corresponding known parametric surface equation using a least-squares optimization method (see
Appendix B for details). Performance was measured using the L1 norm of the parameter difference (
) between the estimated parameters
derived from
and the known ground truth parameters
.
Figure 2 illustrates the seven parametric surfaces used in our evaluation. These surfaces represent a diverse set of geometric primitives commonly encountered in CAD models and industrial environments, ranging from simple planar surfaces to more complex curved geometries like tori and paraboloids. This diversity enables comprehensive evaluation of each down-sampling method’s ability to preserve parametric characteristics across different surface types.
4.3.1. Quantitative Results
Table 1 and
Table 2, respectively, present the Performance Ratio and Win Percentage metrics for the L1 parameter distance. The Performance Ratio quantifies the relative error of each method compared to LDS-Hilbert, with values greater than 1.0 indicating LDS-Hilbert’s superior performance. The Win Percentage shows the proportion of test cases where LDS-Hilbert outperformed each comparison method. To analyze the effects of point cloud size (
N) and the down-sampling ratio on the results, the data are grouped by these factors, with each value representing the average across all surface types.
4.3.2. Key Findings
Three critical patterns emerge from this analysis:
Scale-dependent advantage of LDS-Hilbert: The performance benefit of LDS-Hilbert becomes more pronounced as point cloud size (N) increases. At , its advantage over methods like SRS or LDS-PCA is marginal (e.g., ratios of 0.97 vs. SRS and 0.84 vs. LDS-PCA at 20% sampling). However, at N = 95,760, LDS-Hilbert significantly outperforms them (e.g., ratios up to 1.29 vs. SRS and 1.18 vs. LDS-PCA, with 100% win rates against both in some cases). This scale dependency likely arises because larger N allows the Hilbert curve (with a correspondingly higher order s) to provide a more granular, locality-preserving 1D mapping, and the LDS reordering can more effectively distribute selection ranks across this longer, more detailed sequence.
Consistent superiority over structured methods: Regardless of point cloud size, LDS-Hilbert significantly outperforms both the FPS and Voxel methods across nearly all test conditions. Performance ratios consistently remain above 1.24 and reach as high as 3.07 for FPS at
N = 95,760 with 10% down-sampling.
Table 2 demonstrates that for the largest point clouds, LDS-Hilbert achieves a 100% win rate against these methods, indicating universal superiority for parameter recovery tasks at scale.
Evolving role of Hilbert vs. PCA ordering: The comparison with LDS-PCA (using Principal Component Analysis for initial ordering) shows that at smaller scales (), LDS-PCA can be competitive to LDS-Hilbert. This suggests PCA’s global variance capture might suffice for simpler distributions. However, at N = 95,760, LDS-Hilbert consistently surpasses LDS-PCA. This indicates that as point density increases, the Hilbert curve’s superior ability to preserve local neighborhood relationships across the entire manifold becomes more critical for accurate fitting than the global structure captured by PCA.
Notably, while the relative performance ranking of the methods remains largely consistent across different down-sampling ratios (10% vs. 20%), LDS-Hilbert demonstrates particular robustness and often a greater magnitude of performance advantage at the more aggressive 10% ratio. This highlights its effectiveness precisely when substantial data reduction is required, suggesting its advantages become more pronounced under stricter down-sampling constraints.
See
Section 4.7 for a paired
t-test of the significance level used to measure the superiority of LDS-Hilbert.
4.3.3. Implications
These results provide strong evidence that the LDS-Hilbert method significantly improves parametric surface reconstruction fidelity compared to traditional methods. Its advantages become most apparent when handling large point clouds requiring substantial down-sampling—precisely the scenario most relevant to practical digital twin applications where computational efficiency must be balanced with model accuracy.
4.4. Experiment 2: Mesh Reconstruction from Closed Prismatic Geometry
This experiment investigated the performance of down-sampling methods in reconstructing mesh-based digital twins (Type B) from point clouds representing regular, closed geometric shapes. These shapes featured both planar and curved faces, as well as sharp edges. The dataset was generated from 15 distinct mesh-based geometric models, including shapes like spheres, cylinders, various prisms (triangular, cube, rectangular, pentagonal, hexagonal), structural beams (L, T, U, H types), cones, tori, and basic polyhedra (tetrahedron, octahedron), with precisely defined dimensions based on a scale factor (see
Appendix C for more details). Before sampling, each mesh model underwent a random rotation. Points were then sampled relatively uniformly from the surface of each rotated mesh using the Poisson disk sampling method, generating clouds at three sizes (
N = 9180,
N = 37,240 and
N = 95,760) for a total of 45 objects. Gaussian noise with a standard deviation of 1 cm (assuming meter scale for the objects) was added to the coordinates of each sampled point to simulate LiDAR scanning errors. Each down-sampling method reduced the input cloud
to 10% (ratio = 0.10), as Experiment 1 demonstrated that the ratio had minimal impact on the relative performance of methods.
The resulting down-sampled cloud
was then used as input for surface reconstruction via the Ball Pivoting algorithm (
g) to create a mesh digital twin
(see
Appendix D for Ball Pivoting details).
Fidelity was evaluated by comparing against the ground truth mesh and the ground truth point cloud (vertices of the original mesh before noise) using a suite of geometric metrics: Point-to-Mesh Distance (), Chamfer Distance (), the 95th Percentile Hausdorff Distance components ( and ), and Viewpoint Feature Histogram Distance ().
4.4.1. Visual Assessment
Figure 3a,b provide visual comparisons of the reconstruction results across different down-sampling methods.
Figure 3a shows the results for simpler geometries (sphere, triangular prism, and cone), while
Figure 3b presents more complex structural shapes (L-beam, U-beam, and H-beam).
Visual inspection of
Figure 3a reveals that for the sphere (
), all methods produce reasonably complete reconstructions, but SRS, FPS, and to some extent LDS-PCA, create noticeable holes or irregularities on the surface. The LDS-Hilbert method produces a more complete and uniform sphere reconstruction with a high face count (1532), comparable to the Voxel method (1543).
For shapes with sharp features, such as the triangular prism () and cone (), the differences become more pronounced. SRS produces highly irregular reconstructions with significant gaps, while FPS creates smoother but sometimes incomplete reconstructions. The LDS-Hilbert method achieves the highest face counts (1192 for the triangular prism and 1289 for the cone), indicating more complete mesh reconstruction that better preserves the sharp geometric features.
Figure 3b demonstrates even more significant differences with complex structural shapes. The SRS method tends to produce irregular meshes with inconsistent densities. While FPS generates smoother surfaces, it often fails to maintain proper thickness in the thin sections of these complex shapes. The Voxel method struggles with the interior corners of the U-beam and H-beam. In contrast, the LDS-Hilbert method consistently achieves the highest face counts (8079 for L-beam, 10,142 for U-beam, and 9828 for H-beam) and visually preserves both the overall structure and fine details of these challenging geometries.
4.4.2. Quantitative Results
Table 3 and
Table 4 present the Performance Ratio and Win Percentage metrics for each evaluation criterion, grouped by point cloud size.
The Performance Ratio quantifies the relative error of each comparison method to LDS-Hilbert (values greater than 1.0 indicate LDS-Hilbert’s superior performance), while the Win Percentage shows the proportion of test cases where LDS-Hilbert outperformed each method.
The quantitative metrics align with the visual observations from
Figure 3a,b, demonstrating several clear patterns across different metrics and point cloud sizes.
In addition, we also provide computational time comparisons in
Appendix E to validate the efficiency of our proposed method.
4.4.3. Key Findings
Progressive advantage with scale: For nearly all metrics, LDS-Hilbert’s advantage increases with point cloud size. This is particularly evident in the Point-to-Mesh Distance () metric, where the Performance Ratio against FPS increases from 1.39 at to 1.64 at N = 95,760, and against Voxel from 0.89 at to 1.36 at N = 95,760. Similarly, the Win Percentage against Voxel for this metric rises dramatically from 6.67% at to 100% at N = 95,760.
Superior morphological fidelity: The Viewpoint Feature Histogram (VFH) Distance shows the most dramatic improvement, with Performance Ratios at N = 95,760 reaching 1.96, 1.96, 1.85, and 1.86 against SRS, FPS, Voxel, and LDS-PCA, respectively. This substantial difference (nearly twice as good) indicates that LDS-Hilbert preserves the overall geometric characteristics and surface morphology significantly better than all comparison methods, with 100% win rates against SRS, FPS, and LDS-PCA at the largest scale.
Trade-off in coverage metrics: For the Hausdorff Distance from ground truth to sample (), the FPS and Voxel methods achieved lower error rates than LDS-Hilbert at smaller scales, with Performance Ratios of 0.88 and 0.87, respectively, at . This reflects these methods’ design focus on ensuring uniform coverage. However, this advantage diminishes at larger scales, with ratios increasing to 1.04 for FPS at N = 95,760, suggesting that LDS-Hilbert’s balanced approach becomes increasingly effective as complexity grows.
Comprehensive distance metrics: The Chamfer Distance (), which considers both how well sampled points represent the surface and how well the surface is covered by sampled points, shows LDS-Hilbert outperforming the comparison methods across most conditions. At N = 95,760, LDS-Hilbert achieves a 100% win rate against all comparison methods, demonstrating its balanced approach to addressing both objectives.
Value of Hilbert ordering: The comparison with LDS-PCA isolates the contribution of the Hilbert curve ordering. While LDS-PCA performs relatively well compared to other methods, LDS-Hilbert consistently outperforms it at the largest scale (N = 95,760) across all metrics, with Performance Ratios of 1.00–1.86 and Win Percentages of 40–100%. This confirms that the Hilbert curve’s spatial coherence properties specifically enhance reconstruction quality.
The statistical significance of these results is analyzed in
Section 4.7.
4.4.4. Implications and Synthesis
Combining the visual assessment with the quantitative results yields several important insights about LDS-Hilbert’s performance in mesh reconstruction tasks:
LDS-Hilbert provides consistent, low-error results in surface reconstruction, particularly for large point clouds requiring significant down-sampling. The consistently higher face counts across diverse geometries indicate more complete reconstructions that better preserve the original shape characteristics.
While SRS produces down-sampled point clouds with moderate numerical differences from ground truth (Performance Ratios of 1.00–1.21 for most metrics), its high randomness and uneven distribution result in poor visual quality, evidenced by numerous holes and irregular surfaces in
Figure 3a,b.
The FPS and Voxel methods create visually smoother reconstructions for simpler convex geometries but struggle with shapes having sharp features (triangular prisms, cones) and complex structures with concave regions (U-beams, H-beams). These limitations are reflected in their higher error rates at larger scales.
The most significant advantage of LDS-Hilbert appears in preserving the overall shape characteristics and surface morphology, as demonstrated by the substantial improvements in the VFH Distance at N = 95,760. This suggests that the method is particularly valuable for applications where faithful reproduction of an object’s appearance and geometric features is critical.
These findings demonstrate that LDS-Hilbert offers substantial advantages for mesh reconstruction from closed prismatic geometries, with benefits that become increasingly pronounced as point cloud size and shape complexity increase—precisely the conditions encountered in practical digital twin applications.
4.5. Experiment 3: Mesh Reconstruction from Diverse CAD Models (ModelNet40)
This experiment focused on evaluating the generalization ability of the down-sampling methods across a broad spectrum of complex object shapes (Type C), often consisting of multiple components. The experiment utilized 40 CAD models selected from the ModelNet40 dataset, one from each class. A ground truth watertight mesh and corresponding point cloud were established for each model, and Gaussian noise was added to create the input point clouds. Following the standard procedure, each method down-sampled the input clouds to a 20% ratio. The resulting point clouds were then reconstructed into Type C Mesh digital twins using the Ball Pivoting algorithm. Performance was quantitatively evaluated using the same suite of geometric metrics as in Experiment 2, comparing the down-sampled cloud against the ground truth mesh and the ground truth point cloud.
4.5.1. Visual Assessment
Figure 4 provides a visual comparison of reconstruction results across different down-sampling methods for six representative objects: bottle, chair, cone, cup, flower pot, and piano. The ground truth is shown in the leftmost column, with reconstructed meshes from each method in subsequent columns. The numbers indicate the face count of each reconstructed mesh.
Visual examination reveals clear differences in reconstruction quality across the methods. Similar to our observations in Experiment 2, the FPS and Voxel methods tend to produce smoother surfaces but frequently fail at modeling concave regions and sharp features. This is particularly evident in the chair model, where the FPS method (1571 faces) struggles to properly reconstruct the seat and back connection, while the LDS-Hilbert method (1933 faces) preserves more structural details and achieves a higher face count.
The SRS and LDS-PCA methods consistently generate reconstructions with numerous surface irregularities. For example, in the bottle model, both methods show noticeable bumps and inconsistencies along what should be smooth surfaces. While SRS occasionally achieves high face counts (as seen in the piano model with 18,908 faces), the visual quality of these reconstructions remains problematic with multiple gaps and irregular surfaces.
The LDS-Hilbert method demonstrates superior performance in preserving both smooth regions and detailed structures. This is clearly visible in the cup model, where LDS-Hilbert (14,040 faces) captures the hollow interior and handle with greater fidelity than other methods. For objects with more complex geometry, such as the piano, LDS-Hilbert (19,909 faces) achieves the highest face count and visually appears to best preserve the original shape, including the keyboard area and supporting structure.
4.5.2. Quantitative Results
Due to the extreme complexity of one model (Keyboard_0001), all methods failed to produce acceptable reconstructions, so this model was excluded from the quantitative analysis. For the remaining 39 models,
Table 5 and
Table 6 present the Performance Ratio and Win Percentage metrics for each evaluation criterion.
The Performance Ratio (
Table 5) quantifies the relative error of each comparison method to LDS-Hilbert, with values greater than 1.0 indicating LDS-Hilbert’s superior performance. The Win Percentage (
Table 6) shows the proportion of test cases where LDS-Hilbert outperformed each comparison method. These metrics were calculated across all five geometric distance measures: Point-to-Mesh Distance (
), Chamfer Distance (
), both components of the 95th percentile Hausdorff Distance (
and
), and the VFH Distance (
).
4.5.3. Key Findings
Comprehensive superior performance:
Table 5 shows that LDS-Hilbert outperforms all comparison methods across nearly all metrics. Compared to SRS, the LDS-Hilbert method achieves approximately 1.03 times better performance on the Point-to-Mesh and Chamfer Distance metrics, indicating better overall geometric fidelity. Against the FPS and Voxel methods, the advantage is even more pronounced, with Performance Ratios reaching 1.46 and 1.22, respectively, for the Point-to-Mesh Distance, and 1.16 and 1.07 for the Chamfer Distance.
Trade-off in coverage vs. structure preservation: While the FPS and Voxel methods show lower Hausdorff Distance from ground truth to sample () compared to LDS-Hilbert (Performance Ratios of 0.93 and 0.89, respectively), this advantage comes at the cost of poorer performance in other metrics. This pattern, consistent with our findings in Experiment 2, confirms that these methods prioritize uniform coverage at the expense of preserving the original geometric structure.
Superior morphological fidelity: For the VFH Distance, which captures overall shape similarities, LDS-Hilbert demonstrates substantial advantages over all comparison methods, with Performance Ratios of 1.18, 1.21, 1.44, and 1.17 against SRS, FPS, Voxel, and LDS-PCA, respectively. This indicates that LDS-Hilbert preserves the essential morphological characteristics of these complex models significantly better than other methods.
Consistent Win Percentages:
Table 6 further supports LDS-Hilbert’s superior performance, showing that it outperforms SRS in approximately 61.54% of cases for the Point-to-Mesh Distance and 100% for the Chamfer Distance. Against FPS and Voxel, LDS-Hilbert wins in 100% and 79.49% of cases, respectively, for the Point-to-Mesh Distance. For the comprehensive VFH metric, LDS-Hilbert achieves impressive win rates of 89.74%, 66.67%, 66.67%, and 87.18% against SRS, FPS, Voxel, and LDS-PCA, respectively.
Value of Hilbert ordering: The comparison with LDS-PCA isolates the contribution of the Hilbert curve ordering. While LDS-PCA performs relatively well compared to other methods, LDS-Hilbert consistently outperforms it across most metrics, with particularly notable advantages in the Point-to-Mesh Distance (58.97% win rate) and VFH Distance (87.18% win rate). This confirms that the Hilbert curve’s spatial coherence properties specifically enhance the reconstruction quality for complex models.
For the corresponding significance test, please refer to
Section 4.7.
4.5.4. Implications and Synthesis
Given the diversity of the ModelNet40 dataset, which includes objects ranging from simple geometric forms to complex multi-component assemblies, these results demonstrate that LDS-Hilbert’s advantages extend beyond the basic parametric forms and closed prismatic geometries tested in previous experiments. The method appears particularly effective at handling the varied density distributions and complex feature arrangements found in real-world CAD models.
The primary advantage of LDS-Hilbert in this experiment appears to be its ability to maintain a balance between preserving local features (such as sharp edges and corners) while also ensuring sufficient point density in smooth regions. This balanced approach results in reconstructions that better capture both the overall structure and the fine details of the original models, making it particularly suitable for complex digital twin applications where fidelity across multiple scales is essential.
These findings align with the theoretical foundation of our method: the Hilbert curve’s locality preservation combined with the Low-Discrepancy Sequence’s uniform coverage creates a synergistic approach that offers particular advantages for complex, multi-feature objects. The strong performance across the diverse ModelNet40 dataset suggests that LDS-Hilbert provides a robust, generally applicable solution for high-fidelity down-sampling of 3D point clouds representing real-world objects.
4.6. Experiment 4: Mesh Reconstruction from Real-World Laser Scans (Stanford Dataset)
This experiment tested the down-sampling methods on challenging real-world data obtained from laser scans. These data featured complex organic shapes, intricate surface details, non-uniform point distributions, and potential scanning imperfections. The dataset consisted of 254 individual scans from four well-known models in the Stanford 3D Scanning Repository (Happy Buddha, Bunny, Dragon, Armadillo). The provided high-resolution meshes served as the ground truth, with their vertices forming the ground truth point clouds. Input point clouds were generated by adding Gaussian noise to these ground truth points. Each method down-sampled these clouds to appropriate ratios—20% for Armadillo and Dragon, and 10% for Happy Buddha and Bunny—to account for differences in model complexity. The resulting down-sampled point clouds were used to reconstruct Type C Mesh digital twins via the Ball Pivoting algorithm. Fidelity was assessed using the identical set of geometric metrics employed in previous experiments.
4.6.1. Visual Assessment
Figure 5 provides a detailed visual comparison of reconstruction quality using the Stanford Bunny as an example. Rather than showing the reconstructions separately, this visualization overlays the ground truth mesh (in green) with the reconstructed meshes (in gray) from each method. This approach clearly reveals where reconstructions deviate from the original model.
Several important observations can be made from this visualization:
The SRS, LDS-PCA, and LDS-Hilbert methods produce meshes that interlock with the ground truth mesh, indicating their overall dimensions closely match the original. In contrast, the FPS and Voxel methods generate meshes that completely envelop the ground truth, suggesting systematic overestimation of the model dimensions.
The yellow circles highlight two important detail regions: the ear and knee indentations of the bunny model. The LDS-Hilbert method successfully preserves these concave details, while the SRS, FPS, and Voxel methods tend to “smooth over” these features, losing important geometric characteristics. This observation confirms LDS-Hilbert’s superior ability to maintain fine details in organic, complex models.
Red circles on the SRS and LDS-PCA reconstructions indicate significant surface defects and irregularities not present in the ground truth. These artifacts are largely absent in the LDS-Hilbert reconstruction, which achieves a better balance between detail preservation and surface smoothness.
The visual differences in detail preservation highlighted in
Figure 5 are further substantiated by the quantitative metrics presented in
Table 7 and
Table 8, which we will now discuss.
4.6.2. Quantitative Results
Table 7 and
Table 8 present the Performance Ratio and Win Percentage metrics for each evaluation criterion. The Performance Ratio (
Table 7) quantifies the relative error of each comparison method to LDS-Hilbert, with values greater than 1.0 indicating LDS-Hilbert’s superior performance. The Win Percentage (
Table 8) shows the proportion of test cases where LDS-Hilbert outperformed each comparison method.
4.6.3. Key Findings
Superior shape preservation: The most striking result appears in the VFH Distance () metric, where LDS-Hilbert dramatically outperforms all comparison methods with Performance Ratios of 2.60, 3.19, 3.25, and 2.41 against SRS, FPS, Voxel, and LDS-PCA, respectively. These substantial differences indicate that LDS-Hilbert preserves the essential morphological characteristics and overall shape of these complex organic models 2–3 times better than other methods. The Win Percentages for this metric range from 91.67% to 97.92%, demonstrating consistent superiority across nearly all test cases.
Balanced geometric fidelity: The Point-to-Mesh Distance () shows LDS-Hilbert achieving Performance Ratios of 1.00, 1.47, 1.16, and 1.00 against SRS, FPS, Voxel, and LDS-PCA, respectively. While the advantages over SRS and LDS-PCA appear modest when averaged, the Win Percentages of 41.67% and 60.42% reveal that LDS-Hilbert outperforms these methods on many individual scans. Against FPS and Voxel, the advantages are more pronounced, with Win Percentages of 97.92% and 85.42%.
Comprehensive distance metrics: For the Chamfer Distance (), which considers both how well sampled points represent the surface and how well the surface is covered by sampled points, LDS-Hilbert demonstrates Performance Ratios of 1.02, 1.17, 1.02, and 1.02 against SRS, FPS, Voxel, and LDS-PCA, respectively. The Win Percentages for this metric are 89.58%, 100%, 43.75%, and 85.42%, indicating particularly consistent advantages over FPS and strong performance against SRS and LDS-PCA.
Trade-off in coverage metrics: For the Hausdorff Distance from ground truth to sample (), the FPS and Voxel methods achieve lower error rates than LDS-Hilbert, with Performance Ratios of 0.87 and 0.83, respectively. This reflects these methods’ design focus on ensuring uniform coverage at the expense of other quality aspects. The 0% Win Percentage against these methods confirms this is a systematic pattern. However, LDS-Hilbert performs significantly better on the Hausdorff Distance from sample to ground truth (), with Performance Ratios of 1.00, 1.28, 1.13, and 1.00 against SRS, FPS, Voxel, and LDS-PCA, respectively.
Value of Hilbert ordering: The comparison with LDS-PCA isolates the contribution of the Hilbert curve ordering. While LDS-PCA performs reasonably well across most metrics, LDS-Hilbert maintains an advantage in several key areas, particularly in the VFH Distance (Performance Ratio of 2.41) and Win Percentage (91.67%). This confirms that the Hilbert curve’s spatial coherence properties specifically enhance shape preservation for complex organic models.
4.6.4. Implications and Synthesis
These results on the Stanford dataset—widely recognized as a benchmark for 3D reconstruction algorithms—provide compelling evidence that the LDS-Hilbert method’s advantages extend to real-world scanned data. The method’s ability to maintain fine details while preserving overall shape integrity makes it particularly valuable for digital twin applications involving complex, organic geometries with varying feature scales and density distributions.
The Stanford dataset results are especially meaningful because these models represent genuine scanned data with all the complexities and imperfections inherent in real-world acquisition processes. LDS-Hilbert’s robust performance on this data suggests it would be well suited for practical applications in cultural heritage preservation, medical modeling, and other fields where high-fidelity digital reproduction of complex organic forms is essential.
The most significant advantage of LDS-Hilbert appears to be in preserving the overall morphological characteristics of the models, as evidenced by the dramatic improvements in the VFH Distance. This suggests that the method is particularly valuable for applications where the visual appearance and geometric features of the digital twin must closely match the physical original.
Combined with our findings from previous experiments, these results establish LDS-Hilbert as a consistently superior approach for point cloud down-sampling across a wide range of geometry types, from simple parametric surfaces to complex real-world scans. The method’s advantages become increasingly pronounced as object complexity increases, making it especially relevant for challenging digital twin applications where both computational efficiency and geometric fidelity are critical requirements.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}