
Power Line Segmentation Algorithm Based on Lightweight Network and Residue-like Cross-Layer Feature Fusion


Abstract
1. Introduction
2. Materials and Methods
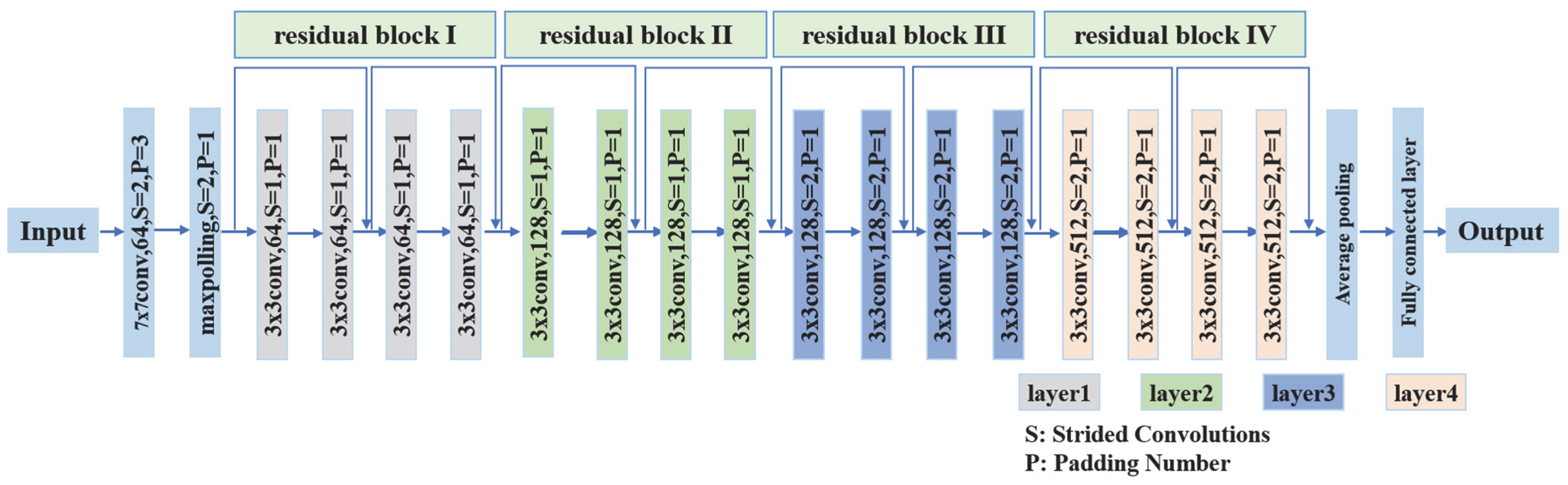
2.1. Enhanced Small Size Shallow Feature Extraction Based on Backbone ResNet18
2.2. Enhanced Network Lightweighting Based on the Ghost Module
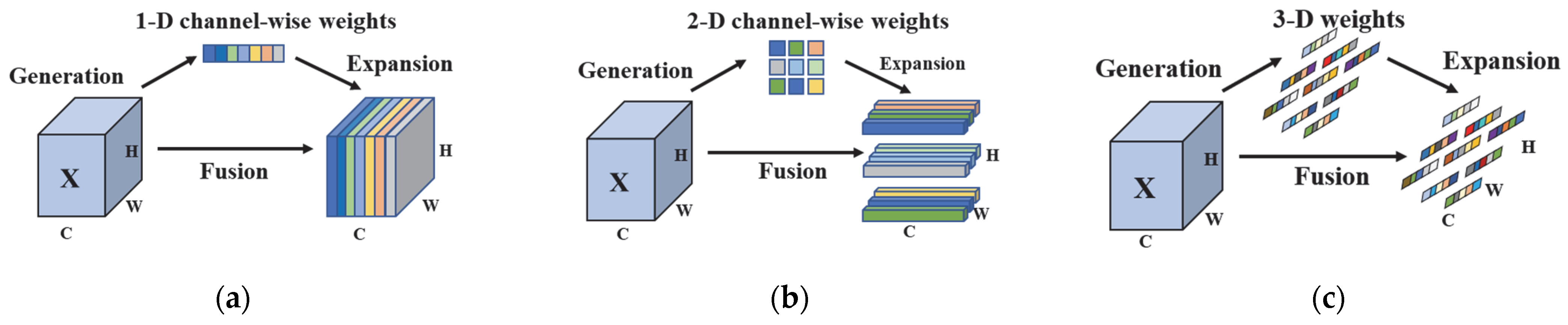
2.3. Class Residuals Embedding Attention Mechanisms Across Layers
2.4. Enhancing the Robustness of Networks Based on Activation Functions
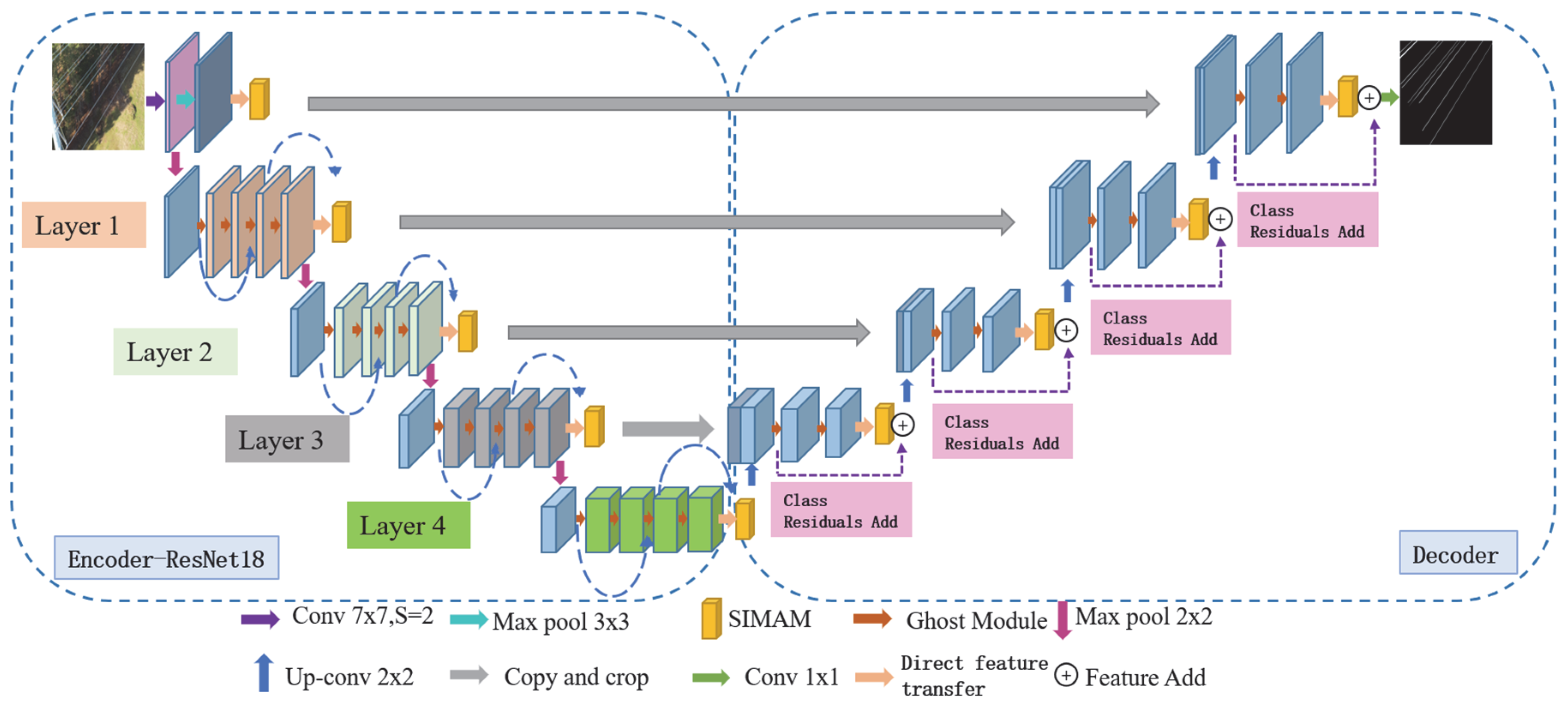
2.5. RGS-UNet Model
3. Experimental Results and Analysis
3.1. Dataset and Experimental Environment
3.2. Experimental Procedure
3.3. Experimental Evaluation and Analysis of Results
- (1)
- Comparison Based on Different Backbone Networks
- (2)
- Experimental Comparison of Introducing Different Attention Mechanisms and Different Embedding Methods
- (3)
- Ablation Experiment
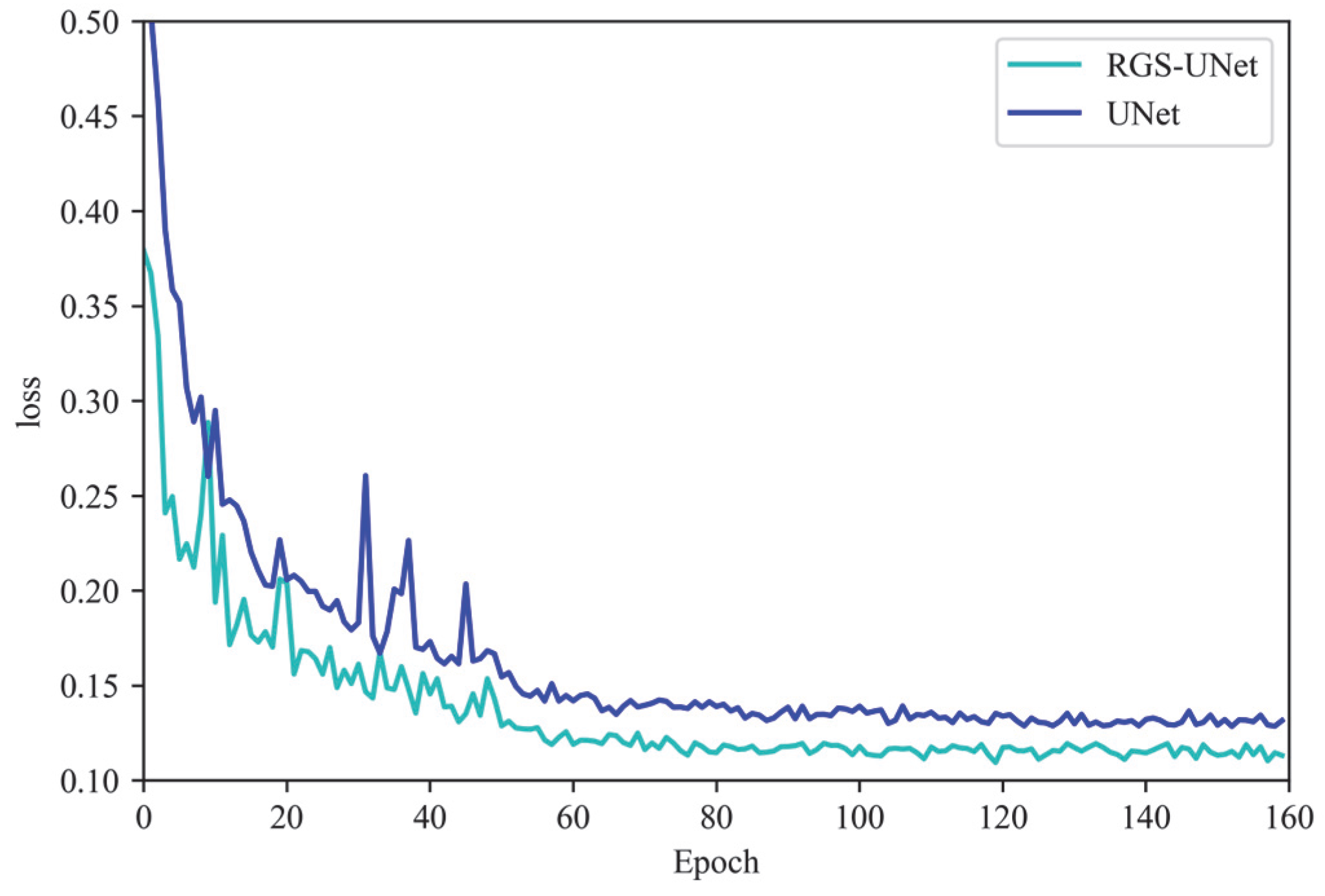
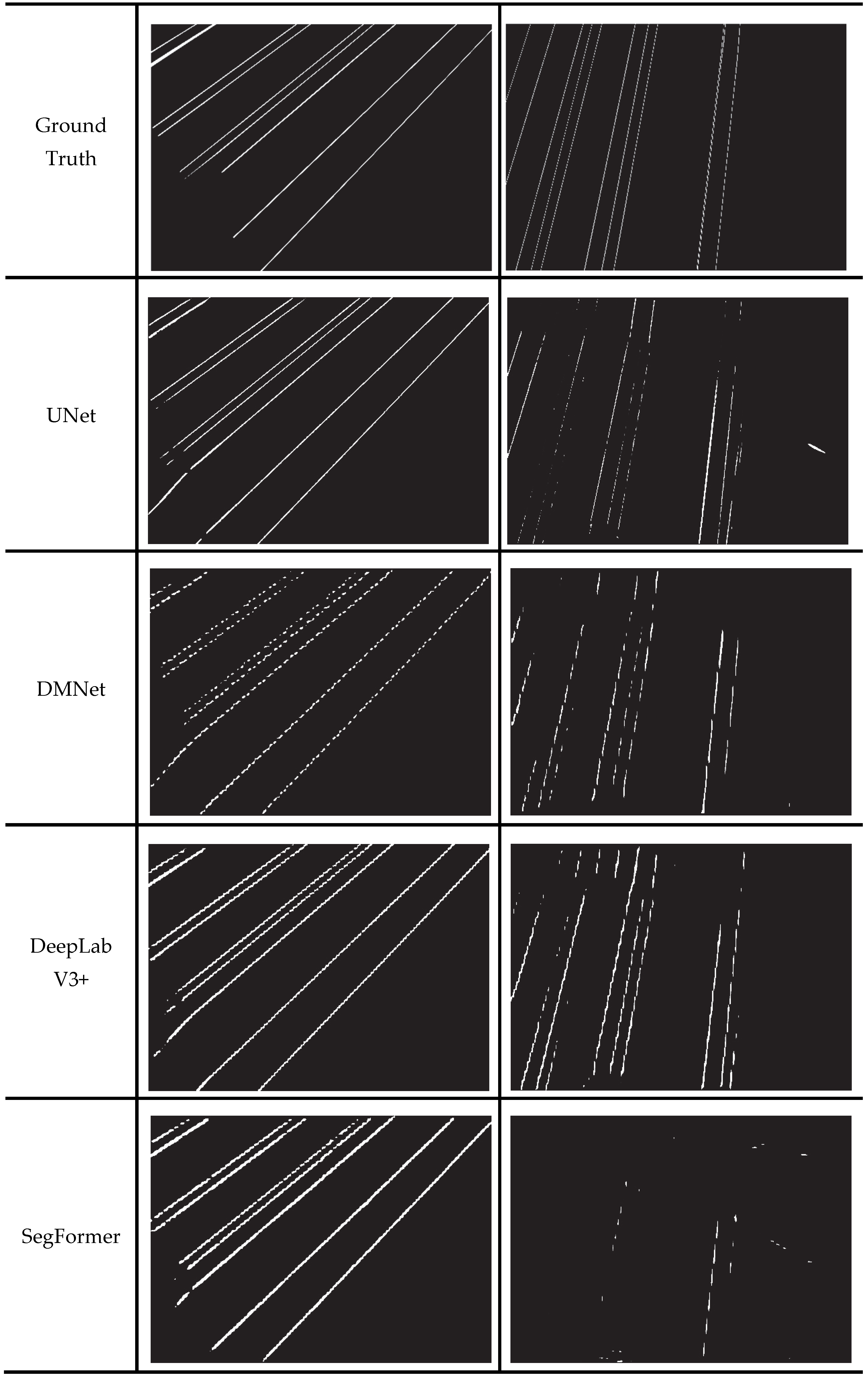
3.4. Comparison of Overall Detection Results of the Improved Model
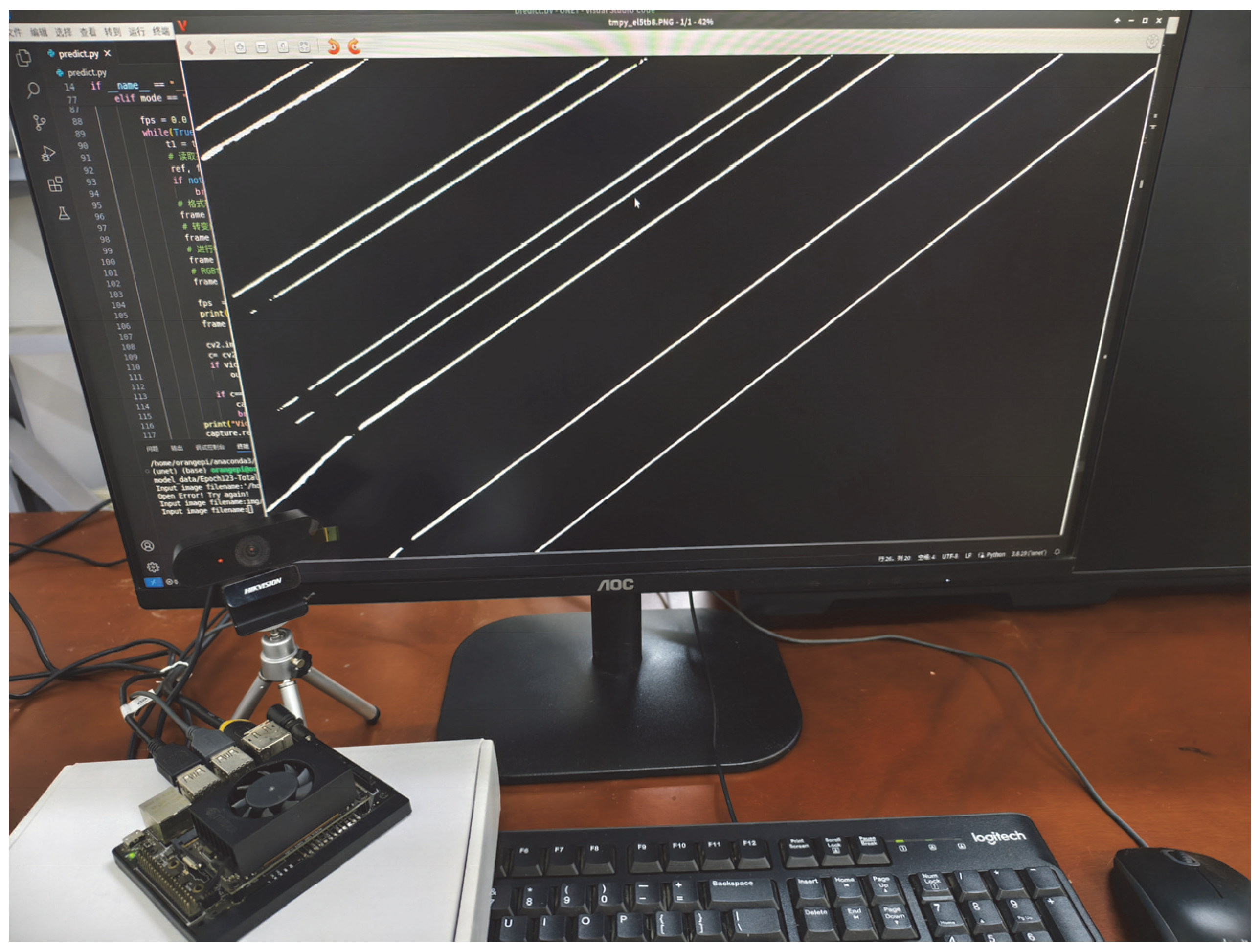
3.5. Edge Device Deployment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, J.; Guo, Y.; Yue, F.; Yuan, H.; Yang, A.; Wang, X.; Rong, M. A Deep Learning Method to Detect Foreign Objects for Inspecting Power Transmission Lines. IEEE Access 2020, 8, 94065–94075. [Google Scholar] [CrossRef]
- Chen, M.L.; Wang, Y.Z.; Dai, Y.; Yan, Y.F.; Qi, D.L. SaSnet: A real-time power line segmentation network based on self-supervised learning. Proc. CSEE 2022, 42, 1365–1375. [Google Scholar]
- Wang, L.; Chen, Z.; Hua, D.; Zheng, Z. Semantic Segmentation of Transmission Lines and Their Accessories Based on UAV-Taken Images. IEEE Access 2019, 7, 80829–80839. [Google Scholar] [CrossRef]
- Wei, S.X.; Li, Y.; Shuang, F.; Zhou, Z.; Li, P.; Li, Z. Power Line Extraction Algorithm for UAV Inspection Scene Images. Comput. Integr. Manuf. Syst. 2024, 30, 3232–3243. [Google Scholar]
- Zhou, W.; Ji, C.; Fang, M. Effective Dual-Feature Fusion Network for Transmission Line Detection. IEEE Sens. J. 2024, 24, 101–109. [Google Scholar] [CrossRef]
- Zhang, C.X.; Zhao, L.; Wang, X.P. Fast Extraction Algorithm for Power Lines in Complex Feature Backgrounds. Eng. J. Wuhan Univ. 2018, 51, 732–739. [Google Scholar]
- Rong, S.; He, L.; Du, L.; Li, Z.; Yu, S. Intelligent Detection of Vegetation Encroachment of Power Lines with Advanced Stereovision. IEEE Trans. Power Deliv. 2021, 36, 3477–3485. [Google Scholar] [CrossRef]
- Shuang, F.; Chen, X.; Li, Y.; Wang, Y.; Miao, N.; Zhou, Z. PLE: Power Line Extraction Algorithm for UAV-Based Power Inspection. IEEE Sens. J. 2022, 22, 19941–19952. [Google Scholar] [CrossRef]
- Chen, X.Y.; Xia, J.; Du, K. Overhead transmission line detection based on multilinear feature enhancement network. J. Zhejiang Univ. (Eng. Sci.) 2021, 55, 2382–2389. [Google Scholar]
- Zhang, Y.P.; Wang, W.H.; Zhao, S.P.; Zhao, S.X. Research on automatic extraction of railroad contact network power lines in complex background based on RBCT algorithm. High Volt. Eng. 2022, 48, 2234–2243. [Google Scholar]
- Zhao, L.; Wang, X.P.; Yao, H.T.; Tian, M. A Review of Power Line Extraction Algorithms Based on Visible Light Aerial Images. High Volt. Eng. 2021, 45, 1536–1546. [Google Scholar]
- Yang, L.; Kong, S.; Deng, J.; Li, H.; Liu, Y. DRA-Net: A Dual-Branch Residual Attention Network for Pixelwise Power Line Detection. IEEE Trans. Instrum. Meas. 2023, 72, 5010813. [Google Scholar] [CrossRef]
- Yang, L.; Kong, S.; Cui, S.; Huang, H.; Liu, Y. An Efficient End-to-End CNN Network for High-voltage Transmission Line Segmentation. In Proceedings of the 2022 IEEE 8th International Conference on Cloud Computing and Intelligent Systems (CCIS), Chengdu, China, 26–28 November 2022; pp. 565–570. [Google Scholar] [CrossRef]
- Liu, J.W.; Li, Y.X.; Gong, Z.; Liu, X.G.; Zhou, Y.J. Full Convolutional Network Wire Recognition Method. J. Image Graph. 2020, 25, 956–966. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Xu, S.; Li, E.; Liu, Y. Vision-Based Power Line Segmentation with an Attention Fusion Network. IEEE Sens. J. 2022, 22, 8196–8205. [Google Scholar] [CrossRef]
- Han, G.; Zhang, M.; Li, Q.; Liu, X.; Li, T.; Zhao, L.; Liu, K.; Qin, L. A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism. Machines 2022, 10, 881. [Google Scholar] [CrossRef]
- Liu, J.-J.; Hou, Q.; Liu, Z.-A.; Cheng, M.-M. PoolNet+: Exploring the Potential of Pooling for Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 887–904. [Google Scholar] [CrossRef]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A Lightweight CPU Convolutional Neural Network. arXiv 2021, arXiv:2109.15099. [Google Scholar]
- Huang, L.; Xiang, Z.; Yun, J.; Sun, Y.; Liu, Y.; Jiang, D.; Ma, H.; Yu, H. Target Detection Based on Two-Stream Convolution Neural Network with Self-Powered Sensors Information. IEEE Sens. J. 2023, 23, 20681–20690. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- El Ariss, O.; Hu, K. ResNet-Based Parkinson’s Disease Classification. IEEE Trans. Artif. Intell. 2023, 4, 1258–1268. [Google Scholar] [CrossRef]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- He, Z.; He, D.; Li, X.; Qu, R. Blind Superresolution of Satellite Videos by Ghost Module-Based Convolutional Networks. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5400119. [Google Scholar] [CrossRef]
- Zhang, R.H.; Ou, J.S.; Li, X.M.; Ling, X.; Zhu, Z.; Hou, B.F. Lightweight pineapple seedling heart detection algorithm based on improved YOLOv4. Trans. Chin. Soc. Agric. Eng. 2023, 39, 135–143. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Lu, Y.-F.; Gao, J.-W.; Yu, Q.; Li, Y.; Lv, Y.-S.; Qiao, H. A Cross-Scale and Illumination Invariance-Based Model for Robust Object Detection in Traffic Surveillance Scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6989–6999. [Google Scholar] [CrossRef]
- Wang, B.; Yang, K.; Zhao, Y.; Long, T.; Li, X. Prototype-Based Intent Perception. IEEE Trans. Multimed. 2023, 25, 8308–8319. [Google Scholar] [CrossRef]
- Chang, H.; Fu, X.; Guo, K.; Dong, J.; Guan, J.; Liu, C. SOLSTM: Multisource Information Fusion Semantic Segmentation Network Based on SAR-OPT Matching Attention and Long Short-Term Memory Network. IEEE Geosci. Remote Sens. Lett. 2025, 22, 4004705. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | F1-Score (%) | IoU (%) | Params/MB |
|---|---|---|---|
| UNet | 89.16 | 82.74 | 24.89 |
| PP-LCNet | 87.54 | 80.68 | 16.48 |
| MobileNetV3 | 86.34 | 79.10 | 8.48 |
| GhostNet v2 | 87.39 | 80.33 | 9.56 |
| FasternetT2 | 82.97 | 75.12 | 25.64 |
| RepVGG | 83.86 | 76.38 | 19.60 |
| EfficientNetV2 | 84.91 | 77.68 | 26.67 |
| ResNet18 | 90.36 | 84.21 | 19.80 |
| Model | F1-Score (%) | IoU (%) | Params/MB |
|---|---|---|---|
| UNet | 89.16 | 82.74 | 24.89 |
| ECA | 90.27 | 84.10 | 14.25 |
| ECA+ Class Residuals | 90.52 | 84.39 | 14.25 |
| CA | 90.33 | 84.17 | 14.31 |
| CA+ Class Residuals | 90.61 | 84.57 | 14.31 |
| SIMAM | 90.57 | 84.55 | 14.25 |
| SIMAM+ Class Residuals | 90.83 | 84.89 | 14.25 |
| Method | ResNet | Ghost Module | SIMAM | Mish | F1-Score (%) | IoU (%) | Params/MB | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| UNet | 89.16 | 82.74 | 24.89 | 451.67 | ||||
| Improvement 1 | √ | 90.36 | 84.21 | 19.80 | 334.64 | |||
| Improvement 2 | √ | √ | 90.25 | 84.14 | 14.25 | 299.67 | ||
| Improvement 3 | √ | √ | √ | 90.83 | 84.89 | 14.25 | 299.67 | |
| Improvement 4 | √ | √ | √ | 90.70 | 84.69 | 14.25 | 299.67 | |
| RGS-UNet | √ | √ | √ | √ | 91.21 | 85.32 | 14.25 | 299.67 |
| Y-UNet [15] | 87.05 | 80.13 | 3.97 | - | ||||
| G-UNet [16] | 89.24 | 82.98 | 2.99 | - |
| Name | Technical Parameters |
|---|---|
| CPU | 6-core NVIDIA Carmel ARM®v8.2 64-bit |
| GPU | 384-core NVIDIA Volta TM GPU 48 Tensor Cores (21TOPS) |
| RAM | 8 GB 128-bit LPDDR4x 51.2 GB/s |
| Memory | 16 GB eMMC5.1 |
| Network | 1000 BASE-T Ethernet |
| Power Wastage | 10 W/15 W |
| Model | F1-Score (%) | Speed (s) | Params/MB |
|---|---|---|---|
| UNet | 89.16 | 0.58 | 24.89 |
| RGS-UNet | 91.21 | 0.39 | 14.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Ding, H.; Han, G.; Wang, W.; Li, M.; Qin, L. Power Line Segmentation Algorithm Based on Lightweight Network and Residue-like Cross-Layer Feature Fusion. Sensors 2025, 25, 3551. https://doi.org/10.3390/s25113551
Zhu W, Ding H, Han G, Wang W, Li M, Qin L. Power Line Segmentation Algorithm Based on Lightweight Network and Residue-like Cross-Layer Feature Fusion. Sensors. 2025; 25(11):3551. https://doi.org/10.3390/s25113551
Chicago/Turabian StyleZhu, Wenqiang, Huarong Ding, Gujing Han, Wei Wang, Minlong Li, and Liang Qin. 2025. "Power Line Segmentation Algorithm Based on Lightweight Network and Residue-like Cross-Layer Feature Fusion" Sensors 25, no. 11: 3551. https://doi.org/10.3390/s25113551
APA StyleZhu, W., Ding, H., Han, G., Wang, W., Li, M., & Qin, L. (2025). Power Line Segmentation Algorithm Based on Lightweight Network and Residue-like Cross-Layer Feature Fusion. Sensors, 25(11), 3551. https://doi.org/10.3390/s25113551