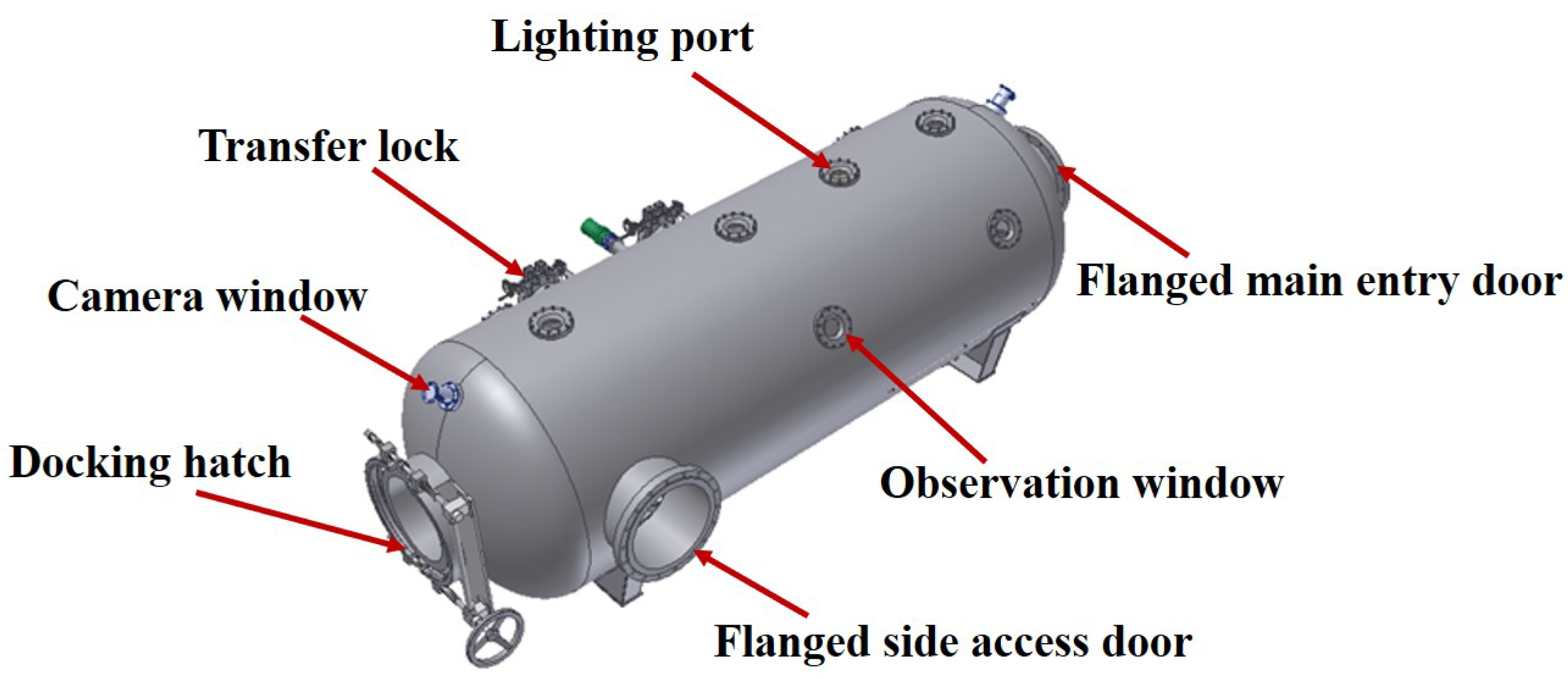
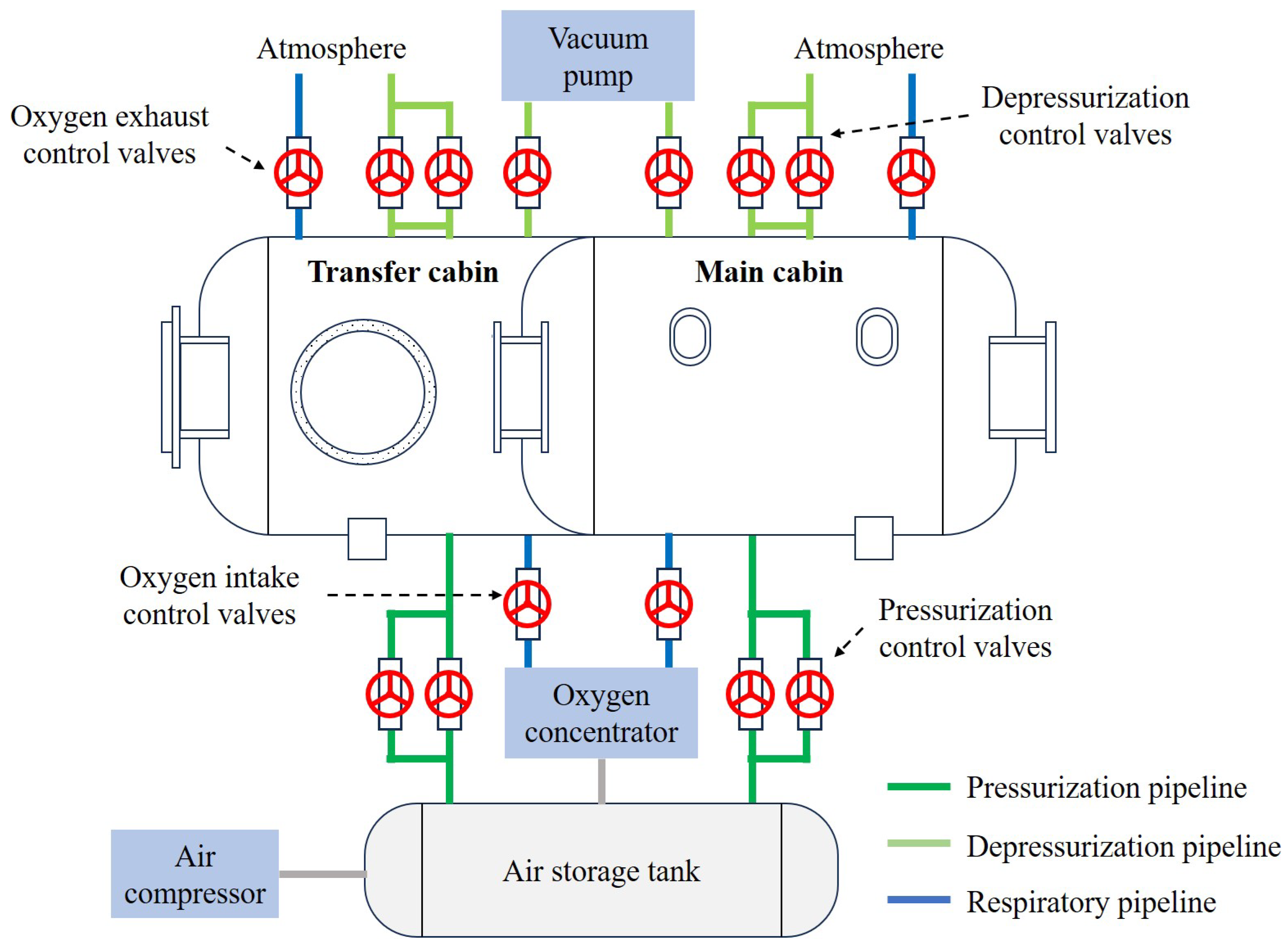
The control of the saturation diving decontamination decompression chamber falls under the category of stochastic optimal control problems. We address this by employing a model-based planning approach and optimizing the control process using reinforcement learning techniques.
3.1. Model-Based Planning as Control
Stochastic optimal control involves controlling dynamic systems subject to constraints under uncertainty, where such uncertainty affects various components of the system [
11]. We formulate the system as a discrete-time dynamic process, expressed as
where
represents the system state, and
denotes the input applied at time
t. A stochastic phenomenon refers to a process of state transitions, and, when the current state depends solely on the previous state, the process is said to have the Markov property [
12]. A stochastic process with the Markov property is referred to as a Markov process. The operation process of the decompression chamber can be regarded as a partially observable Markov decision process (POMDP), where the system state is inferred from observations at different time steps, and the system evolves continuously based on the state transitions and valve operations. The system dynamics are influenced by various uncertainties:
represents uncertain system parameters modeled as random variables, and
denotes time-varying disturbances or process noise, typically assumed to be independently and identically distributed. Considering the joint uncertainty of the system noise
and model parameters
, an optimal controller must be designed to handle these challenges. Denoting the observable state as
, the control objective is defined through the cumulative reward function:
where
denotes the expectation over all stochastic variables
and
. The primary challenge of stochastic optimal control lies in satisfying state and input constraints within the closed-loop control horizon. Input constraints typically represent physical limitations of actuators, such as the maximum rate of valve opening changes, while state constraints may take various forms. These can represent physical boundaries of system states, safety-related constraints, or performance requirements associated with desired objectives. Consequently, the resulting constrained stochastic optimal control problem can be formulated as
The optimal control policy requires access to all historical state measurements . Once the state transition model of the system environment is established, planning algorithms can be employed to search for the optimal policy. These algorithms operate by selecting actions in the state space, performing forward search, and propagating reward values. Such planning methods require a well-defined state transition model. In the deterministic case, the model specifies the next state for every possible action taken in each state. In stochastic settings, however, it provides a probability distribution over possible next states.
For system identification, we adopt the Context-Aware Dynamics Model (CADM) proposed by Lee et al. [
13]. This model enhances generalization across varying environmental dynamics by introducing a context encoder that extracts latent representations of local dynamics and conditions the model predictions accordingly. Furthermore, we apply the PETS (Probabilistic Ensembles with Trajectory Sampling) algorithm, as proposed by Chua et al. [
14], which leverages the cross-entropy method (CEM) to optimize the outputs of the learned dynamics model [
15]. As the primary focus of this paper is not on system modeling, we do not delve into the specifics of the modeling process. Readers are referred to the original works for a detailed methodology, model architecture, and training procedures.
Model-based planning does not explicitly construct the full policy; instead, it selects the current action based on predicted model outcomes. This approach solves a locally optimal subproblem within a receding horizon to realize control. At each time step, the problem is initialized from the current state
and solved over a short prediction horizon. Accordingly, the predictive model is defined as
where
and
denote the predicted state and action at step
i within the prediction horizon starting at time
t, respectively. The initial condition is set as
. The predictive dynamics function
f is typically designed to approximate the true system behavior; however, it may be affected by issues such as insufficient data or model inaccuracy. Despite this, one may proceed without explicitly accounting for model uncertainty and instead rely on the model to perform forward predictions and re-optimize the trajectory at each sampling instant. We define the action sequence as
, and the objective function is given by
In model-based planning, when an action is selected at each time step, a set of candidate action sequences is first generated. The expected outcomes of each candidate sequence are then evaluated based on the current state, and the first action of the sequence that yields the best result is selected for execution. Therefore, when applying model-based planning methods, two phases are involved: one is learning the environment model
from historical data, and the other is using the learned model to select actions during real-time interactions with the environment. At time step
k, our objective is to maximize the cumulative reward of the agent. The reward function
quantifies the reward received by taking action
in state
. Specifically, the optimization problem is formulated as
where
H denotes the length of the receding horizon, and
represents the operation of selecting, from all candidate sequences, the action sequence that maximizes the cumulative reward. At each step, we execute the first action
of the optimal sequence to interact with the environment. One key issue in model-based planning is how to generate candidate action sequences as the quality of these candidates directly affects the quality of the resulting actions. A commonly used method is the cross-entropy method, which we adopt as the baseline algorithm for model-based planning. The detailed steps are presented in Algorithm A1 in
Appendix A.1.
3.2. Policy-Network-Guided Trajectory Planning
Building upon model-based planning, we propose a policy-network-guided trajectory-planning (PN-TP) method. This approach leverages a policy network trained in conjunction with the environment model to guide trajectory selection during planning. In conventional model predictive control (MPC), the agent uses a system model during online planning but executes only the first action of the planned sequence [
16]. In contrast, under the policy-driven control of the PN-TP algorithm, the agent directly executes the action generated by the policy network based on the current observation, similar to standard reinforcement learning paradigms.
In the previous section, the CEM is applied independently at each state to solve the optimization problem. Typically, the sampling distribution is either initialized to a fixed distribution at the beginning of each episode or re-initialized at every time step. However, such initialization schemes suffer from low sampling efficiency due to the lack of a mechanism to generalize valuable information from high-value regions to nearby states. Moreover, information obtained during initialization is discarded afterward, making it difficult to scale the method to high-dimensional solution spaces, which are common in continuous-control environments. To address these limitations, Wang et al. proposed the use of a policy network in CEM-based planning to improve optimization efficiency [
17]. They developed two methods: POPLIN-A, which performs optimization in the action space, and POPLIN-P, which performs optimization in the parameter space. POPLIN represents one of the most advanced frameworks for planning from the perspective of policy networks. In our work, we adopt POPLIN as the foundational architecture for the PN-TP algorithm.
In the control process, we denote the action and state spaces by
A and
S, respectively. The reward function and state transition function are denoted as
and
, where
and
represent the state and action at time step
t. The agent’s objective is to optimize a policy
by maximizing the expected cumulative reward:
. At time step
i, the predicted reward for a trajectory
is defined as
Here, the state sequence is obtained by recursively applying the state transition model, such that , indicating that the next state is generated from the current state and action using the transition model . The action sequence is generated by the planning module as a candidate trajectory. The expected reward is computed by simulating trajectories from the current state using a set of P particles. At time step t, the k-th particle uses the transition model . This model can be constructed from deterministic ensemble models, such as a weighted combination of multiple deterministic models; or probabilistic ensemble models, such as bootstrapped or Bayesian-based transition estimators.
We utilize the policy network to generate a high-quality initial distribution over action sequences, denoted as
. Based on the predicted trajectories provided by the policy network, we inject Gaussian noise into the candidate action sequences and refine them using CEM by optimizing the mean and standard deviation of the noise distribution. This enhances the efficiency of the planning process. Specifically, we define an action sequence as
. Similarly, in CEM-based planning, we define a corresponding noise sequence as
. The initial noise distribution is assumed to have a mean
and a covariance matrix
, where
denotes the initial noise variance. During each CEM iteration, we first select the top
action sequences that yield the best performance. The corresponding elite noise sequences are
. We then update the parameters of the noise distribution based on these elite samples:
Subsequently, we apply a smoothing update scheme to refine the noise distribution. The update formulas are defined as
, where
is the smoothing parameter that controls the weighting between the old and new distributions. Specifically, at each time step, the CEM procedure is executed for multiple iterations. Candidate actions are resampled, and the noise distribution is updated to complete the trajectory planning. At time step
i, given an observed state
, a reference action sequence
is generated through forward propagation using the policy network. At each planning time step
, the executed action is jointly determined by the policy and the optimized noise, i.e.,
, where
and
. Given the search noise sequence
, the expected reward is re-estimated to efficiently guide the distribution toward optimal actions. The expected cumulative reward is expressed as
The state transitions are determined by .
In addition to injecting noise into the action space, we can also introduce noise into the parameter space of the policy network to further enhance the flexibility and efficiency of trajectory planning. Specifically, we denote the parameter vector of the policy network as
. Starting from time step
i, we define the parameter noise sequence for the policy as
. Under parameter space noise, the expected cumulative reward is defined as
where the state transition is determined by
. Similar to the method applied in the action space, we utilize CEM to optimize the distribution of parameter noise. Specifically, we select the top
parameter noise sequences with the highest performance in the current generation:
. The noise distribution is then updated based on these elite samples.
To simplify the optimization process, we constrain the parameter noise within a single trajectory to remain constant; i.e., . We further propose a method based on policy ensemble learning to efficiently estimate the sampling distribution used in CEM. This approach can be applied to both the action space and the parameter space of the policy network. We define two variants accordingly: PN-TP-A: planning is conducted in the action space; PN-TP-P: planning is conducted in the parameter space of the policy network. Specifically, the planning process involves M parallel CEM instances executed simultaneously. For each instance with index , we denote the sampling distribution parameter as . Then, we define for action-space optimization (PN-TP-A): and for parameter-space optimization (PN-TP-P): .
The algorithmic workflow of PN-TP-A can be further specified as follows: in each CEM instance, the policy network takes the current state
as input and outputs the sampling distribution parameters
for the action space used by that CEM instance. By leveraging the policy network to guide the CEM method in both action and parameter spaces, we can achieve more efficient trajectory planning and action optimization, especially in high-dimensional continuous control problems where this method demonstrates superior performance. The detailed procedure of the PN-TP-A algorithm is presented in Algorithm A2 in
Appendix A.2.
The PN-TP-P algorithm performs planning in the parameter space of the policy network. Each policy network outputs its parameter vector
. The initial sampling distribution for the
i-th CEM instance is a Gaussian distribution defined over the policy parameter space, with the mean initialized as
. In the argmax operation, the sample
denotes the
j-th sampled parameter vector from the distribution. Its corresponding value is approximated based on the predicted trajectory reward using the learned dynamics model. In contrast to optimization in the action space, which could suffer from non-convexity and local maxima, optimizing over the parameter space allows for structured exploration by injecting noise directly into policy parameters. By employing a stochastic policy network, it naturally encourages broader trajectory exploration and supports re-parameterization within the optimization process. The detailed procedure of the PN-TP-P algorithm is provided in Algorithm A3 in
Appendix A.3.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}