
sEMG-Based Gesture Recognition Using Sigimg-GADF-MTF and Multi-Stream Convolutional Neural Network


Abstract
1. Introduction
- (1)
- In terms of feature extraction from sEMG signals, Sigimg images are employed to characterize sEMG signals, thereby maximizing the preservation of temporal information features inherent in multi-channel sEMG signals;
- (2)
- GADF and MTF images are designed to optimize the extraction of both static and dynamic information features from multi-channel sEMG signals;
- (3)
- In classifier design, the MSCNN, renowned for its exceptional image processing capabilities, is utilized to automatically extract and learn features from Sigimg, GADF, and MTF images. This method circumvents the complexities and limitations associated with manual feature extraction from signals;
- (4)
- The recognition performance is improved by learning and integrating various time-domain features of sEMG signals within the network.
2. Related Work
3. Methods
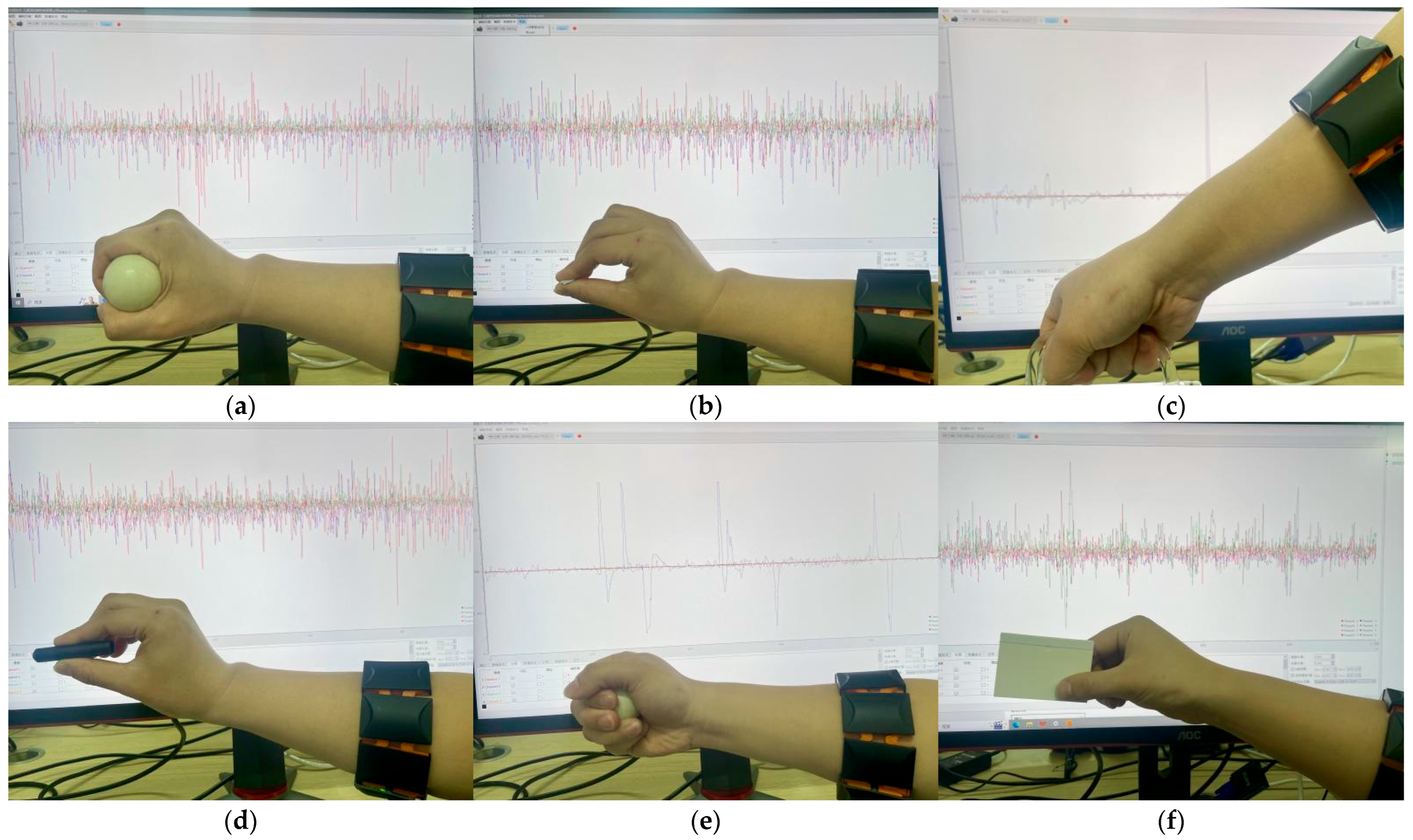
3.1. Experimental Data
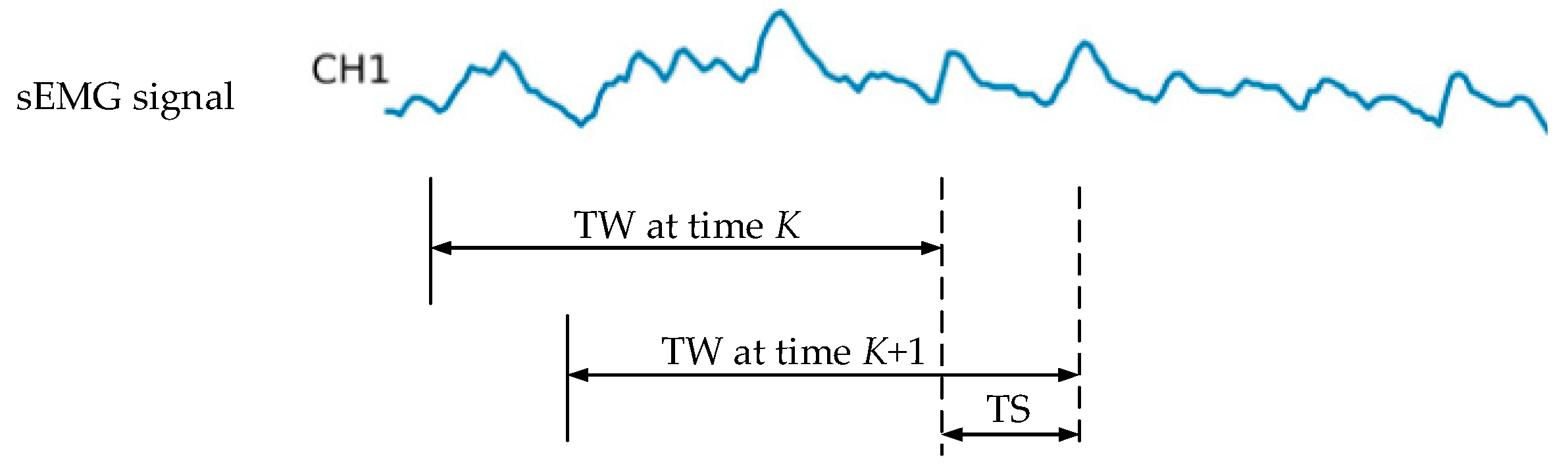
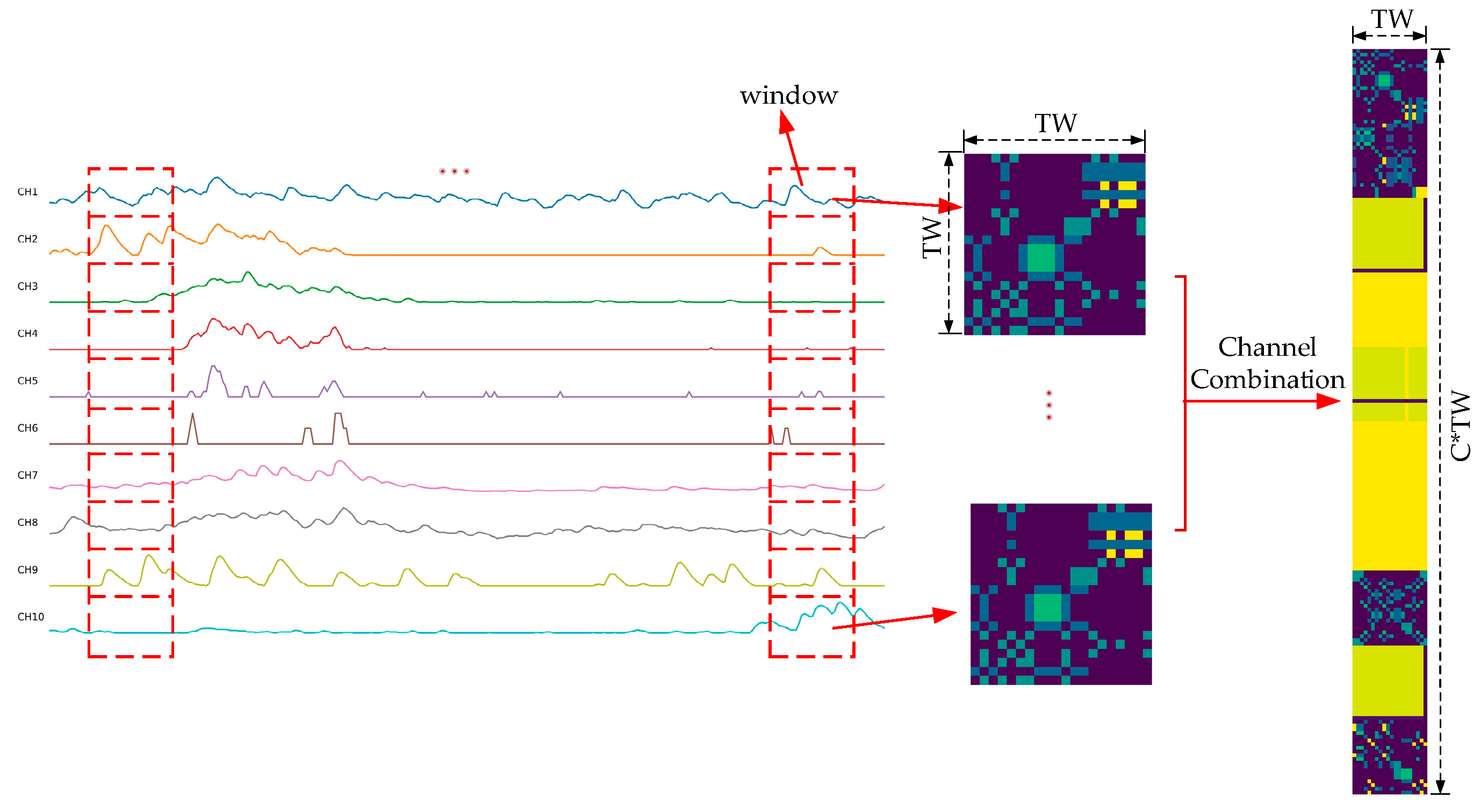
3.2. Multi-Channel Data Processing
3.2.1. Conversion of Multi-Channel Signals to Sigimg Images
3.2.2. Conversion of Multi-Channel Signals to GADF and MTF Images
3.2.3. Dataset Construction
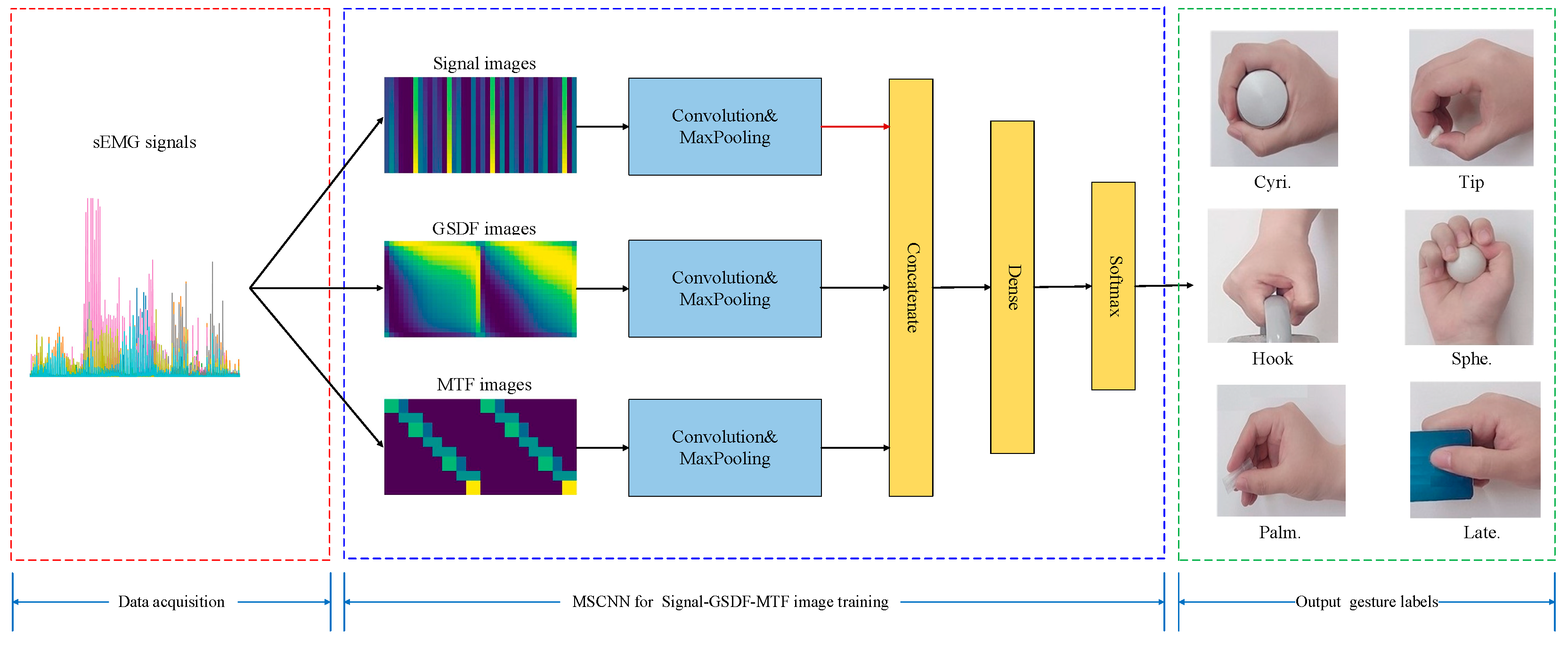
3.3. Structure Design of CNNs
3.3.1. Multi-Stream CNN
3.3.2. Hyperparameter Setting of the Network
4. Experiments and Analysis
4.1. Evaluation Indicators
4.2. Network Model Training and Testing
4.3. Experimental Results
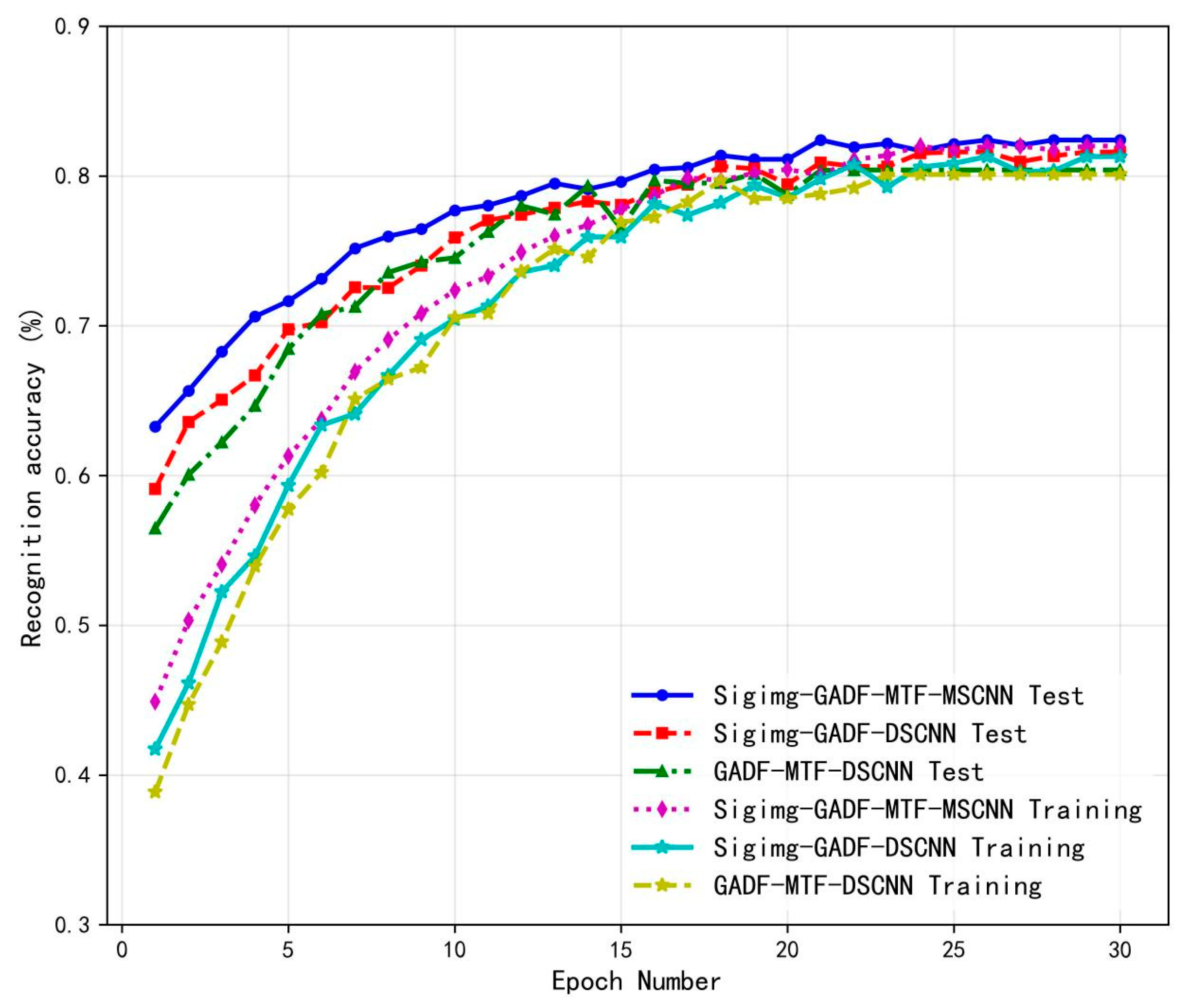
4.3.1. Comparative Experiment Between MSCNN, SSCNN, and DSCNN
- (1)
- SSCNN model: Based on the SSCNN model, three gesture recognition algorithms were developed: Sigimg-SSCNN, GADF-SSCNN, and MTF-SSCNN. For the Sigimg-SSCNN algorithm, the input is Sigimg images, and its network architecture consists of two alternating convolutional and pooling layers, followed by one flattening layer and three fully connected layers. The number of neurons in each connected layer is 1024, 256, and 52, respectively. The parameters of each convolution layer and pooling layer in the model are the same as those of Branch1 in Table 1. For the GADF-SSCNN and MTF-SSCNN algorithms, the inputs are GADF and MTF images, respectively. Their network architectures are identical, comprising two alternating convolutional and pooling layers, one flattening layer, and three fully connected layers. The number of neurons in each connected layer layer is 2048, 512, and 52, respectively. The parameters of each convolution layer and pooling layer in the model are the same as those of Branch2 or Branch3 in Table 1;
- (2)
- DSCNN model: Based on the DSCNN model, two gesture recognition algorithms were constructed: Sigimg-GADF-DSCNN and GADF-MTF-DSCNN. For the Sigimg-GADF-DSCNN algorithm, the inputs include Sigimg and GADF images, and its network architecture consists of two branches. The parameters of its convolutional, pooling, and flattening layers are identical to those of Branch1 and Branch2 in Table 1. The number of neurons in the three fully connected layers is 4096, 1024, and 52, respectively. Similarly, the GADF-MTF-DSCNN algorithm uses GADF and MTF images as inputs and has a two-branch architecture. Its convolutional, pooling, and flattening layer parameters are consistent with those of Branch2 and Branch3 in Table 1. The number of neurons in the three fully connected layers is also 4096, 1024, and 52, respectively.
4.3.2. Ablation Study
- Experiment I: Sigimg-SSCNN.
- Experiment II: GADF-SSCNN.
- Experiment III: MTF-SSCNN.
- Experiment IV: Sigimg-GADF-DSCNN.
- Experiment V: GADF-MTF-DSCNN.
- Experiment VI: Sigimg-GADF-MTF-MSCNN.
4.3.3. Comparative Experiment Between MSCNN and Other Network Models
4.4. Practical Application Testing
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Latreche, A.; Kelaiaia, R.; Chemori, A.; Kerboua, A. Reliability and validity analysis of MediaPipe-based measurement system for some human rehabilitation motions. Measurement 2023, 214, 112826. [Google Scholar] [CrossRef]
- Guo, W.; Craig, O.; Difato, T.; Oliverio, J.; Santoso, M.; Sonke, J.; Barmpoutis, A. AI-driven human motion classification and analysis using laban movement system. Lec. Notes Comp. Sci. 2022, 13319, 201–210. [Google Scholar]
- Ni, S.; Al-qaness, M.A.A.; Hawbani, A.; Al-Alimi, D.; Elaziz, M.A.; Ewees, A.A. A survey on hand gesture recognition based on surface electromyography: Fundamentals, methods, applications, challenges and future trends. Appl. Soft Comput. 2024, 166, 112235. [Google Scholar] [CrossRef]
- Rahman, M.M.; Uzzaman, A.; Khatun, F.; Aktaruzzaman, M.; Siddique, N. A comparative study of advanced technologies and methods in hand gesture analysis and recognition systems. Expert Syst. Appl. 2025, 266, 125929. [Google Scholar] [CrossRef]
- Atzori, M.; Cognolato, M.; Muller, H. Deep learning with convolutional neural networks applied to electromyography data: A resource for the classification of movements for prosthetic hands. Front. Neurorobot. 2016, 10, 9. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.; Hu, R.; Zhang, X.; Chen, X. Hand gesture recognition based on surface electromyography using convolutional neural network with transfer learning method. IEEE J. Biomed. Health Inform. 2020, 25, 1292–1304. [Google Scholar] [CrossRef]
- Hudgins, B.; Parker, P.; Scott, R.N. A new strategy for multifunction myoelectriccontrol. IEEE Trans. Biomed. Eng. 1993, 40, 82–94. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Liang, H.; Wang, S.; Wang, Y.; Li, Z. Gesture recognition of sEMG signal based on GASF-LDA feature enhancement and adaptive ABC optimized SVM. Biomed. Signal Process. Control 2023, 85, 105104. [Google Scholar]
- Fan, J.; Wen, J.; Lai, Z. Myoelectric pattern recognition using Gramian angular field and convolutional neural networks for muscle–computer interface. Sensors 2023, 23, 2715. [Google Scholar] [CrossRef]
- Wang, N.F.; Chen, Y.L.; Zhang, X.M. The recognition of multi-finger prehensile postures using LDA. Biomed. Signal Process. Control 2013, 8, 706–712. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, P. A novel myoelectric pattern recognition strategy for hand function restoration after incomplete cervical spinal cord injury. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 96–103. [Google Scholar] [CrossRef] [PubMed]
- Oskoei, M.A.; Hu, H. Support vector machine-based classification scheme for myoelectric control applied to upper limb. IEEE Trans. Biomed. Eng. 2008, 55, 1956–1965. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, S.; Li, X.; Qu, L.; Zhuang, B.; Han, G. Improving sEMG-based hand gesture recognition through optimizing parameters and sliding voting classifiers. Eletronics 2024, 13, 1322. [Google Scholar] [CrossRef]
- Wei, W.; Wong, Y.; Dua, Y.; Hua, Y.; Kankanhalli, M.; Geng, W. A multi-stream convolutional neural network for sEMG-based gesture recognition in muscle-computer interface. Pattern Recognit. Lett. 2019, 119, 131–138. [Google Scholar] [CrossRef]
- Wei, W.; Dai, Q.; Wong, Y.; Hu, Y.; Kankanhalli, M.; Geng, W. Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng. 2019, 66, 2964–2973. [Google Scholar] [CrossRef]
- Wei, W.; Hong, H.; Wu, X. A hierarchical view pooling network for multichannel surface electromyography-based gesture recognition. Comput. Intell. Neurosci. 2021, 2021, 6591035. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Jiang, D.; Sun, Y.; Tao, B.; Tong, X.; Jiang, G.; Xu, M.; Yun, J.; Liu, Y.; Chen, B. Dynamic gesture recognition using surface EMG signals based on multi-stream residual network. Front. Bioeng. Biotechnol. 2021, 9, 779353. [Google Scholar] [CrossRef]
- Wang, S.; Huang, L.; Jiang, D.; Sun, Y.; Jiang, G.; Li, J.; Zou, C.; Fan, H.; Xie, Y.; Xiong, H.; et al. Improved multi-stream convolutional block attention module for sEMG-based gesture recognition. Front. Bioeng. Biotechnol. 2022, 10, 909023. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, H.; Xia, Q.; Xiao, H.; Peng, B.; Wang, L.; Zhao, Y. An efficient surface electromyography-based gesture recognition algorithm based on multiscale fusion convolution and channel attention. Sci. Rep. 2024, 14, 30867. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, H.; Xia, Q.; Li, G.; Xiao, H.; Zhao, Y. NKDFF-CNN: A convolutional neural network with narrow kernel and dual-view feature fusion for multitype gesture recognition based on sEMG. Digital Signal Process. 2025, 156, 104772. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Xie, H. Surface-electromyography-based gesture recognition using a multistream fusion strategy. IEEE Access 2021, 9, 50583–50592. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, K.; Yang, G.; Chu, J. Gesture recognition using dual-stream CNN based on fusion of sEMG energy kernel phase portrait and IMU amplitude image. Biomed. Signal Process. Control 2022, 73, 103364. [Google Scholar] [CrossRef]
- Shin, J.; Miah, A.S.M.; Konnai, S.; Takahashi, I.; Hirooka, K. Hand gesture recognition using sEMG signals with a multi-stream time-varying feature enhancement approach. Sci. Rep. 2024, 14, 22061. [Google Scholar] [CrossRef] [PubMed]
- Gan, Z.; Bai, Y.; Wu, P.; Xiong, B.; Zeng, N.; Zou, F.; Li, J.; Guo, F.; He, D. SGRN: SEMG-based gesture recognition network with multi-dimensional feature extraction and multi-branch information fusion. Expert Syst. Appl. 2025, 259, 125302. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1, 140053. [Google Scholar] [CrossRef] [PubMed]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Zhao, X.; Sun, H.; Lin, B.; Zhao, H.; Niu, Y.; Zhong, X. Markov transition fields and deep learning-based event-classification and vibration-frequency measurement for φ-OTDR. IEEE Sens. J. 2022, 22, 3348–3357. [Google Scholar] [CrossRef]
- Krizhevsky, A.A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kang, J.; Zhu, X.; Shen, L.; Li, M. Fault diagnosis of a wave energy converter gearbox based on an Adam optimized CNN-LSTM algorithm. Renew. Energy 2024, 231, 121022. [Google Scholar] [CrossRef]
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 36571. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, G.; Yu, M.; Du, J.; Yun, J.; Liu, Y.; Liu, Y.; Chen, D. Gesture recognition based on surface electromyography- feature image. Concurr. Comput. Pract. Exp. 2020, 33, e6051. [Google Scholar] [CrossRef]
- Castellini, C.; Fiorilla, A.E.; Sandini, G. Multi-subject/daily-life activity EMG-based control of mechanical hands. J. NeuroEng. Rehabil. 2009, 6, 41. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch | Layer Type | Key Parameters | Output Dimension |
|---|---|---|---|
| Branch 1 | Conv1-1 | Conv 16@3 × 3, s = 1, p = 1,c = 16, ReLU | 20 × 100 × 16 |
| Pool1-1 | 2 × 2 MaxPooling, s = 2 | 10 × 50 × 16 | |
| Conv1-2 | Conv 32@3 × 3, s = 1, p = 1,c = 32, ReLU | 10 × 50 × 32 | |
| Pool1-2 | 2 × 2 MaxPooling, s = 2 | 5 × 25 × 32 | |
| Flatten1 | - | 4000 | |
| Branch 2 | Conv2-1 | Conv 16@3 × 3, s = 1, p = 1,c = 16, ReLU | 20 × 200 × 16 |
| Pool2-1 | 2 × 2 MaxPooling, s = 2 | 10 × 100 × 16 | |
| Conv2-2 | Conv 32@5 × 5, s = 1, p = 2,c = 32, ReLU | 10 × 100 × 32 | |
| Pool2-2 | 2 × 2 MaxPooling, s = 2 | 5 × 50 × 32 | |
| Flatten2 | - | 8000 | |
| Branch 3 | Conv3-1 | Conv 16@3 × 3, s = 1, p = 1, c = 16, ReLU | 20 × 200 × 16 |
| Pool3-1 | 2 × 2 MaxPooling, s = 2 | 10 × 100 × 16 | |
| Conv3-2 | Conv 32@5 × 5, s = 1, p = 2,c = 32, ReLU | 10 × 100 × 32 | |
| Pool3-2 | 2 × 2 MaxPooling, s = 2 | 5 × 50 × 32 | |
| Flatten3 | - | 8000 | |
| Concatenate | - | - | 20,000 |
| Dense 1 | FC1 | ReLU | 4096 |
| Dense 2 | FC2 | ReLU | 2048 |
| Dense | FC3 | Softmax | 52 |
| Algorithms | MACs (M) | Training Time (s) | Testing Time (s) | Inference Time (ms) | ||
|---|---|---|---|---|---|---|
| Sigimg-SSCNN | 77.9% | 67.4% | 25.0 | 6853 | 1713 | 19 |
| GADF-SSCNN | 75.3% | 66.4% | 58.2 | 10,414 | 2603 | 28 |
| MTF-SSCNN | 63.0% | 59.9% | 58.2 | 10,664 | 2666 | 29 |
| Sigimg-GADF-DSCNN | 85.9% | 74.7% | 83.2 | 13,234 | 3308 | 36 |
| GADF-MTF-DSCNN | 80.1% | 71.5% | 116.4 | 15,098 | 3774 | 41 |
| Sigimg-GADF-MTF-MSCNN | 88.6% | 78.5% | 141.4 | 22,943 | 5736 | 62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Qu, L.; Wu, W.; Han, G.; Zhu, W. sEMG-Based Gesture Recognition Using Sigimg-GADF-MTF and Multi-Stream Convolutional Neural Network. Sensors 2025, 25, 3506. https://doi.org/10.3390/s25113506
Zhang M, Qu L, Wu W, Han G, Zhu W. sEMG-Based Gesture Recognition Using Sigimg-GADF-MTF and Multi-Stream Convolutional Neural Network. Sensors. 2025; 25(11):3506. https://doi.org/10.3390/s25113506
Chicago/Turabian StyleZhang, Ming, Leyi Qu, Weibiao Wu, Gujing Han, and Wenqiang Zhu. 2025. "sEMG-Based Gesture Recognition Using Sigimg-GADF-MTF and Multi-Stream Convolutional Neural Network" Sensors 25, no. 11: 3506. https://doi.org/10.3390/s25113506
APA StyleZhang, M., Qu, L., Wu, W., Han, G., & Zhu, W. (2025). sEMG-Based Gesture Recognition Using Sigimg-GADF-MTF and Multi-Stream Convolutional Neural Network. Sensors, 25(11), 3506. https://doi.org/10.3390/s25113506