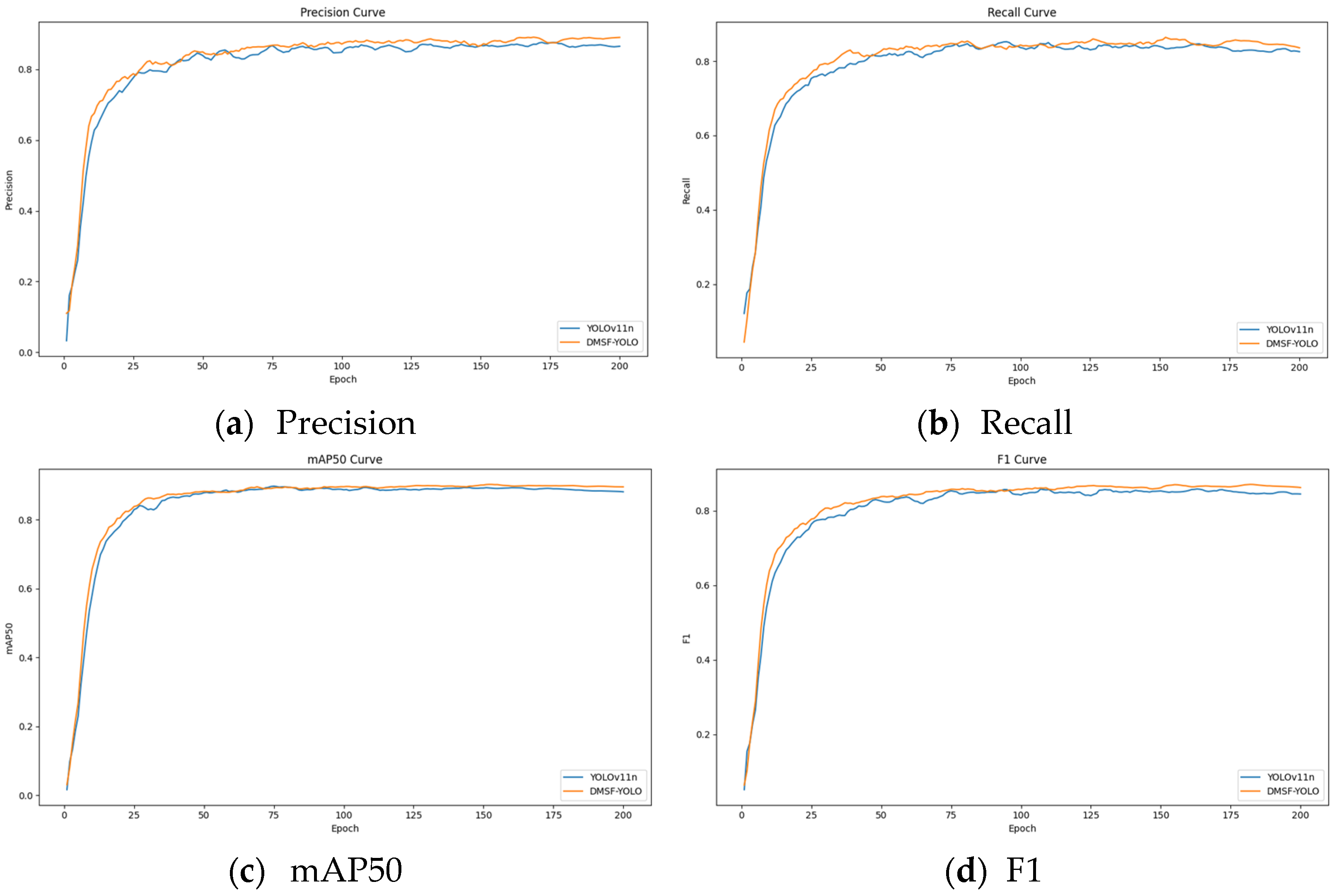
3.3.1. Ablation Experiments
To further explore the contribution of the improved module in the model to overall performance, an ablation experiment was conducted on the test set in the self-built dataset to verify the actual effect. The results are shown in
Table 5.
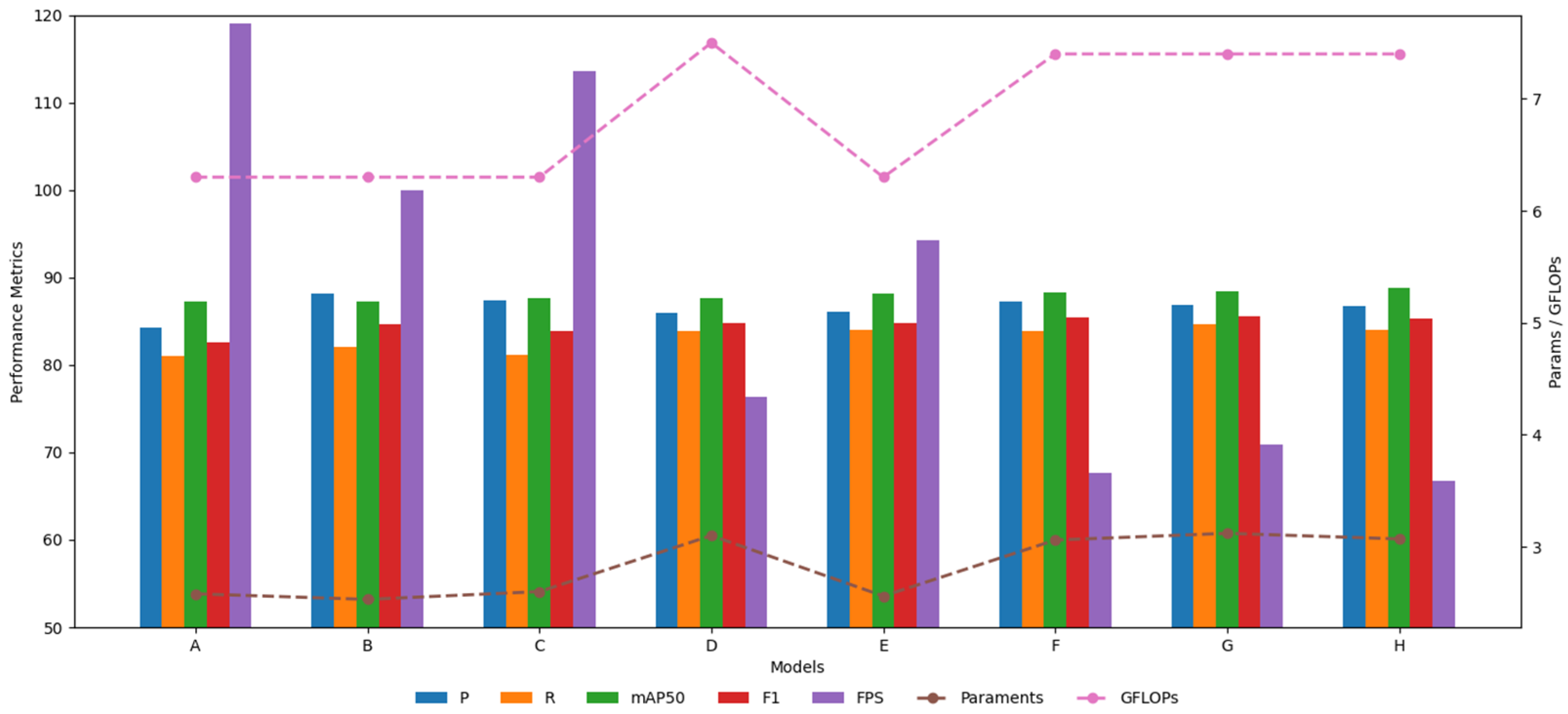
To more intuitively illustrate the effect of the improved model, the data from the ablation experiment are presented in the form of a bar–line graph. Bar graphs and lines of different colors represent different evaluation indicators. Precision (P), recall rate (R), mAP50, F1, and FPS value are represented by bar graphs, and parameters and GFLOPs are represented by line graphs. The horizontal axis represents different models, the vertical axis on the left represents the coordinate scale of the bar graph, and the vertical axis on the right represents the coordinate scale of the line graph. The data effect of the bar graph and line graph is shown in
Figure 13.
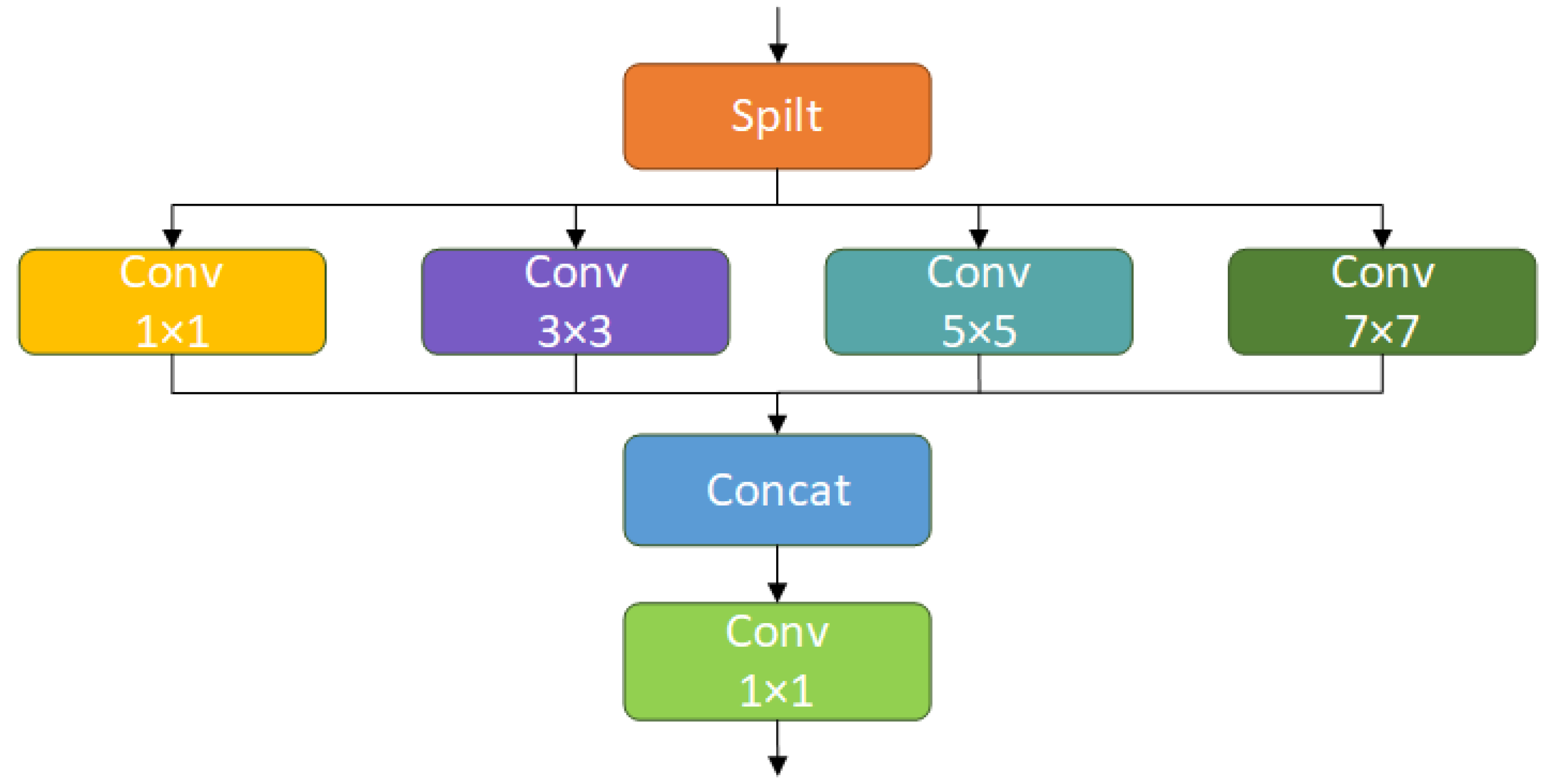
To more efficiently integrate cow behavior feature information at various scales, the MSFConv module is designed; after replacing this module, the overall precision (P), recall(R), mAP50, and F1 value of model B increased by 3.8%, 1%, 0.1%, and 2%, respectively, compared with the original model A. Considering the background interference of the dairy farm and the detailed information of small multi-scale cows, the C2PSA is innovatively replaced with the designed C2BRA module, and the overall precision (P), recall(R), mAP50, and F1 of model C increased by 3.1%, 0.1%, 0.4%, and 1.3%, respectively. To more effectively extract the multi-scale features of cow behavior and improve the accuracy of cow similar behavior detection, the detection head of the original model is replaced with DyHead. The overall precision (P), recall(R), mAP50 and F1 of the replaced model D increased by 1.7%, 2.8%, 0.4% and 2.2%, respectively. After combining MSFConv and C2BRA for improvement, the overall precision (P), recall (R), mAP50, and F1 of model E increased by 1.8%, 3%, 0.9%, and 2.2%, respectively. Compared with the improvement of a single module, although the precision (P) decreased, the recall (R), mAP50, and F1 values all increased to varying degrees, indicating that the model can reduce the risk of missed detection and has better overall detection performance. Combining MSFConv and Dyhead for improvement, the overall precision (P), recall (R), mAP50, and F1 of model F increased by 2.9%, 2.9%, 1.1%, and 2.8%, respectively. Compared with the improvement of a single module, its precision (P) is lower than that of model B, but significantly higher than that of model D. In addition, the recall (R), mAP50, and F1 values all increased to varying degrees compared with models A and B, indicating that model F captures cow behavior information more comprehensively, effectively improves the comprehensive detection capability, and is more practical for cow multi-behavior category recognition tasks. By combining C2BRA and Dyhead for improvement, the overall precision (P), recall (R), mAP50, and F1 of model G are improved by 2.6%, 3.6%, 1.2%, and 3%, respectively. The precision (P) of model G is lower than that of model C but significantly higher than that of model D. In addition, the recall (R), mAP50, and F1 values are significantly improved, which indicates that model G has stronger behavior capture ability and higher recognition stability in the cow behavior recognition task.
The improved DMSF-YOLO model is 0.6% higher than model E in terms of accuracy, and slightly lower than models F and G. In terms of recall, it is on par with model E, 0.1% higher than model F, and 0.6% lower than model G. In terms of mAP50, it is significantly higher than models E, F, and G. In terms of F1, it is 0.5% higher than model E, and slightly lower than models F and G. Although some indicators of the model DMSF-YOLO after combining MSFConv, C2BRA and Dyhead are slightly lower than those of models E, F and G, they are all at a relatively high level, especially mAP50, which is one of the most core performance indicators and has a greater improvement, indicating that the average detection accuracy of this model is higher. The overall precision (P), recall(R), mAP50 and F1 of the improved DMSF-YOLO model increased by 2.4%, 3%, 1.6% and 2.7%, respectively. Compared with the original model YOLOv11n, although the parameters and GFLOPs of this model have increased slightly, and the FPS has decreased compared with other models, the frame rate still reaches 66.7. While ensuring the improvement of detection accuracy, it also takes into account the higher reasoning speed and has good real-time application potential. This shows that after improving the original model, it can more effectively capture the information of different receptive fields, dynamically focus on key regions and pixels in multiscale feature maps, and significantly enhance its capability in small object detection, enhance the ability of multi-scale feature extraction, and better fuse multi-scale features to improve the accuracy of cow behavior detection.
3.3.2. Comparative Experiments
To verify the effectiveness of the improved cow behavior recognition model in this study, the current mainstream target detection models are selected for comparative experiments under the same experimental conditions. As shown in
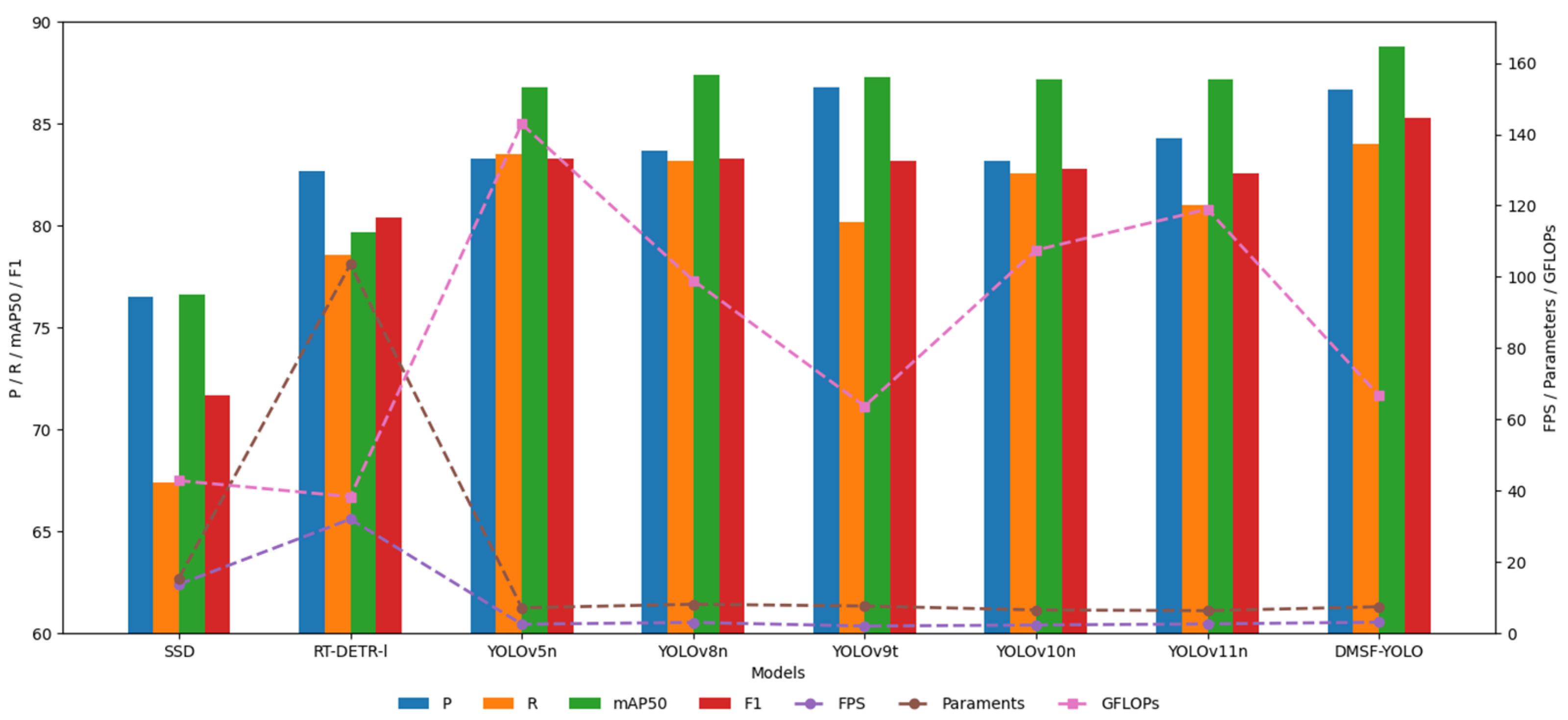
Figure 14, the benchmark model selected in this study is widely used in the field of target detection. With open-source code and better community support, it has good generality. It has been used as an evaluation standard in several cow behavior recognition studies, which can reflect the improvement effect of the model in this study more comprehensively. The results of the comparative experiments are shown in
Table 6.
The bar–line graph of the comparative experiment is similar to
Figure 13 of the ablation experiment. The horizontal axis of the bar graph of the comparative experiment represents YOLOv5n, YOLOv8n, YOLOv9t, YOLOv10n, YOLOv11n, and DMSF-YOLO models from left to right, and FPS is shown in the form of a line graph.
As shown in
Table 6, the precision (P) of the improved DMSF-YOLO model reaches 86.7%, which is 2.4% higher than the original model YOLOv11n and slightly lower than YOLOv9t, but significantly higher than other target detection models. In terms of recall(R), the R-value of the DMSF-YOLO model reaches 84%, which is 3% higher than the original model YOLOv11n and higher than other models, indicating that the model can capture more real positive examples and reduce missed detections. In terms of mAP50, the mAP50 value of the DMSF-YOLO model reaches 88.8%, which is 1.6% higher than the original model and better than other models, indicating that the model can accurately locate and classify different cow behavior categories and has better overall performance. In terms of F1, the F1 value of the DMSF-YOLO model reaches 85.3, which is 2.7% higher than the original model and higher than other target detection models, indicating that the model has better performance. In terms of FPS, the FPS value of the DMSF-YOLO model is lower than that of YOLOv5n, YOLOv8n, YOLOv10n, and YOLOv11n, but significantly lower than that of SSD, RT-DETR-l, and YOLOv9t. Its value reaches 66.7, which fully meets the real-time requirements of practical applications. The parameters and GFLOPs of the DMSF-YOLO model are at an optimal level. The parameters and GFLOPs of the model are slightly higher than those of YOLOv5n, YOLOv8n, YOLOv9t, YOLOv10n, and YOLOv11n but much lower than those of SSD and RT-DETR-l. This shows that the improved model can effectively control the computational and storage costs while maintaining high detection accuracy. In general, the overall performance of the improved cow behavior recognition model DMSF-YOLO is improved to varying degrees compared to the overall performance of the current mainstream target detection model. The model can focus on the key areas of the target cow, extract multi-scale features more effectively, and perform feature fusion. At the same time, it can effectively suppress background interference in the actual cow dairy farm environments and reduce the risk of false detection and missed detection.
3.3.3. Cow Behavior Experiment Analysis
To better validate the model’s effectiveness for cow behavior identification, the mAP50 value of each category is selected as the evaluation index for the experimental analysis, and the cow behavior category detection experimental analysis is carried out on each improved module. The specific results are shown in
Table 7.
The model contents indicated by the notes in
Table 7 A, B, C, D, E, F, and G are the same as those in the ablation experiment. After replacing C3k2 with the MSFConv module, the mAP50 values of the lying, eating, drinking, and mounting behaviors of model B are all improved compared with the original model. This is due to the excellent multi-scale feature extraction capability of the MSFConv module, which can obtain more feature information. After replacing C2PSA with the designed C2BRA module, the mAP50 values of the lying, standing, walking, and mounting behaviors of model C are all improved compared with the original model. This is due to the beneficial effect that the module automatically obtains information on different scales and performs feature alignment and fusion with the help of a dynamic routing strategy. With the introduction of the DyHead detection head, the mAP50 values of the walking, eating, and mounting behaviors of model D are all improved compared with the original model. This is because DyHead can effectively capture the dynamic behavioral changes of cows, thereby improving the detection ability of the model. After combining MSFConv and Dyhead for improvement, the mAP50 values of model E, except for the mounting behavior, are greatly improved compared with the original model. After combining C2BRA and Dyhead for improvement, the mAP50 values of model F for standing, walking, eating, and drinking behaviors are significantly improved compared with the original model. The mAP50 values of the improved model DMSF-YOLO in the test set for standing, walking, eating, drinking, and mounting behaviors increased by 2.5%, 3.4%, 1.3%, 2.2%, and 0.3%, respectively, with a significant improvement compared to the original model, which indicates that MSFConv, C2BRA and DyHead, can extract information under different receptive fields, extract multi-scale features and perform multi-scale feature fusion more efficiently, reduce the interference of extraneous background factors, improve the ability of small object detection, and effectively distinguish between similar behaviors, and the overall performance of the model is stronger.
3.3.4. Small Target Experiment Analysis
To verify the improvement of the model in small target detection, we set the target whose cow target box accounts for less than 5% of the entire image as a small target, and constructed a small target cow behavior dataset. In the process of constructing the small target dataset, we screen and retain the target boxes whose target box area in the test set is less than 5% of the entire image, and then remove other target boxes, and use the small target cow behavior dataset to verify the model’s detection performance for small targets.
The experimental results of the model before and after the improvement on small targets are shown in
Table 8. In terms of precision (P), the improved DMSF-YOLO model improves the accuracy of lying, standing, walking, eating, and drinking behaviors by 0.9%, 5%, 5.1%, 2.1%, and 8.5%, respectively, and the overall accuracy is improved by 3.5%. In terms of recall(R), the improved DMSF-YOLO model increased the recall of lying, standing, walking, eating, and drinking behaviors by 0.5%, 3.4%, 9.6%, 6.3%, and 0.8%, respectively, and the overall recall increased by 3.4%. In terms of mAP50, the improved DMSF-YOLO model improved the mAP50 of standing, walking, eating, drinking, and mounting behaviors by 3.8%, 2.1%, 4.4%, 2.1%, and 4.8%, respectively, and the overall mAP50 by 2.9%. In terms of F1, the improved DMSF-YOLO model improved the F1 values of lying, standing, walking, eating, and drinking behaviors by 0.6%, 4.3%, 7.7%, 4.3%, and 4.1%, respectively, and the overall F1 improvement by 3.2%.
The DMSF-YOLO model’s recognition of cow behaviors has overall different degrees of improvement in each index, and also has different degrees of improvement for different behaviors, which indicates that the improved model DMSF-YOLO has significant improvement in small target detection compared to the original model.





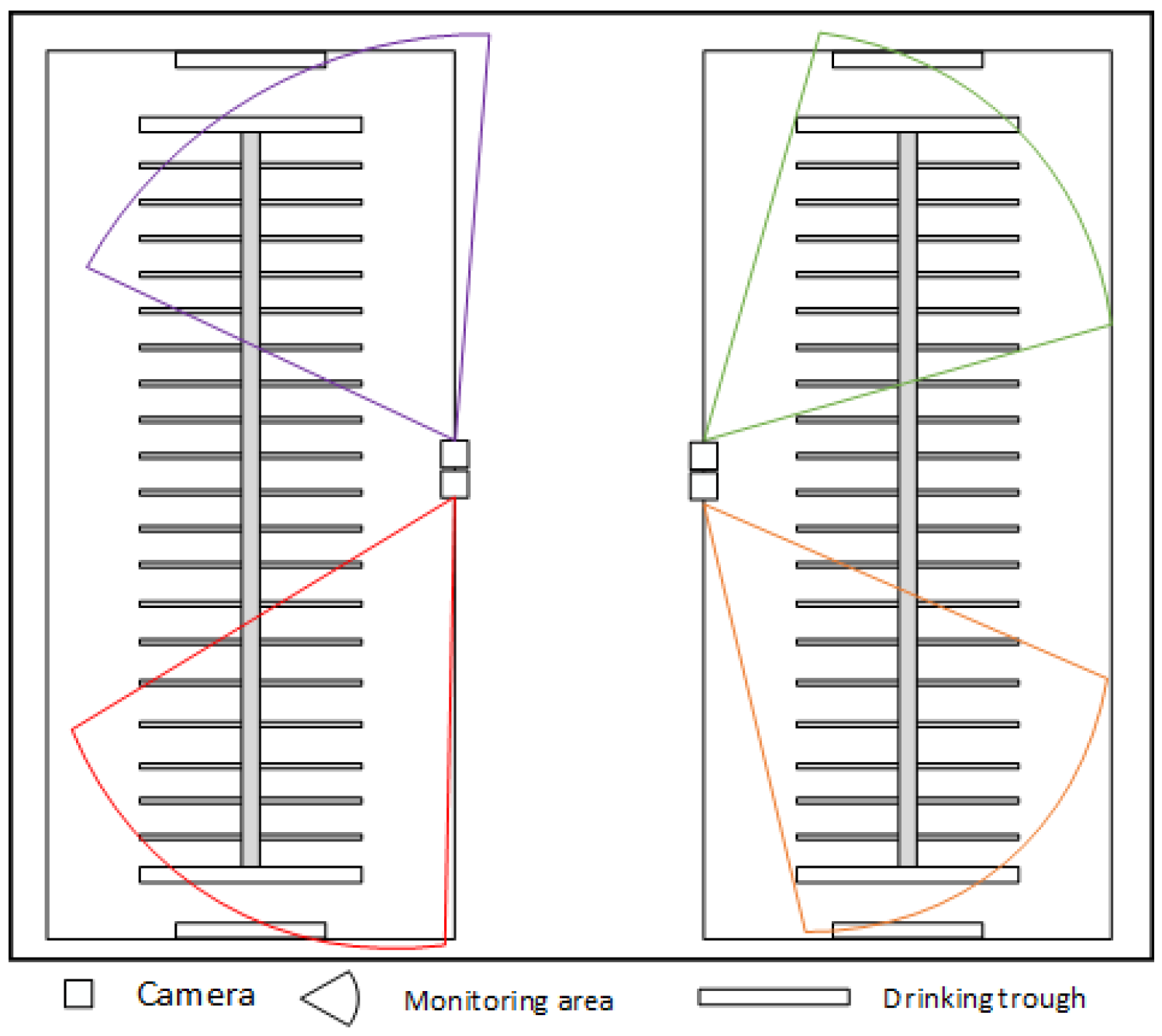


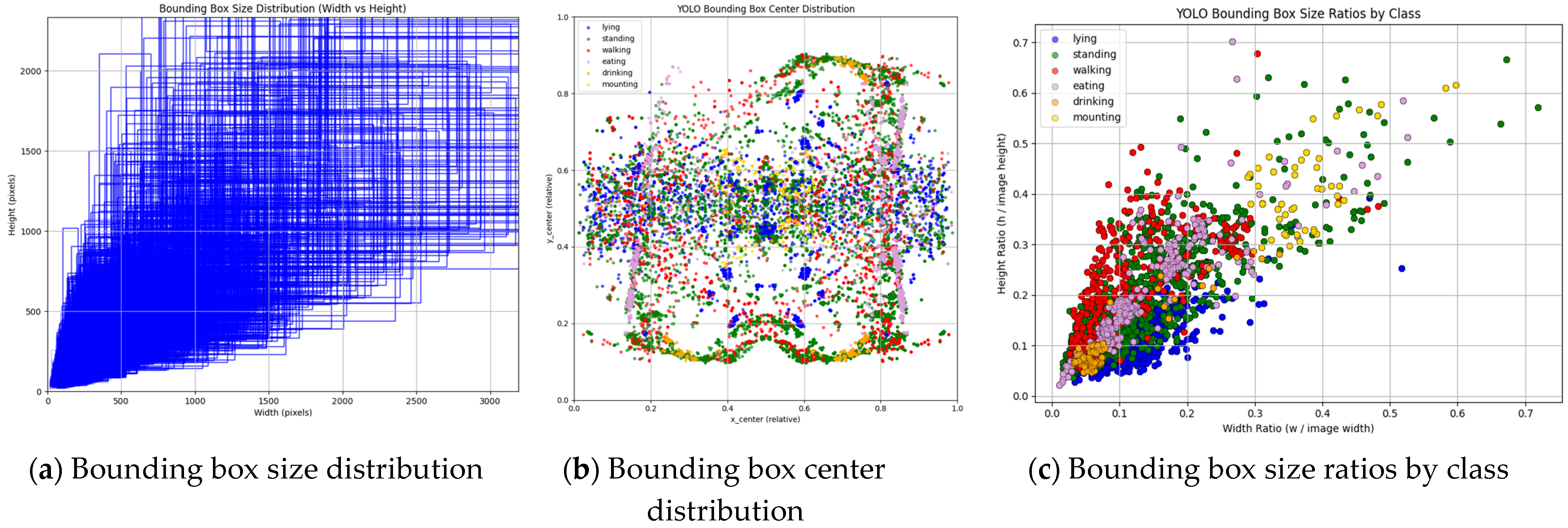

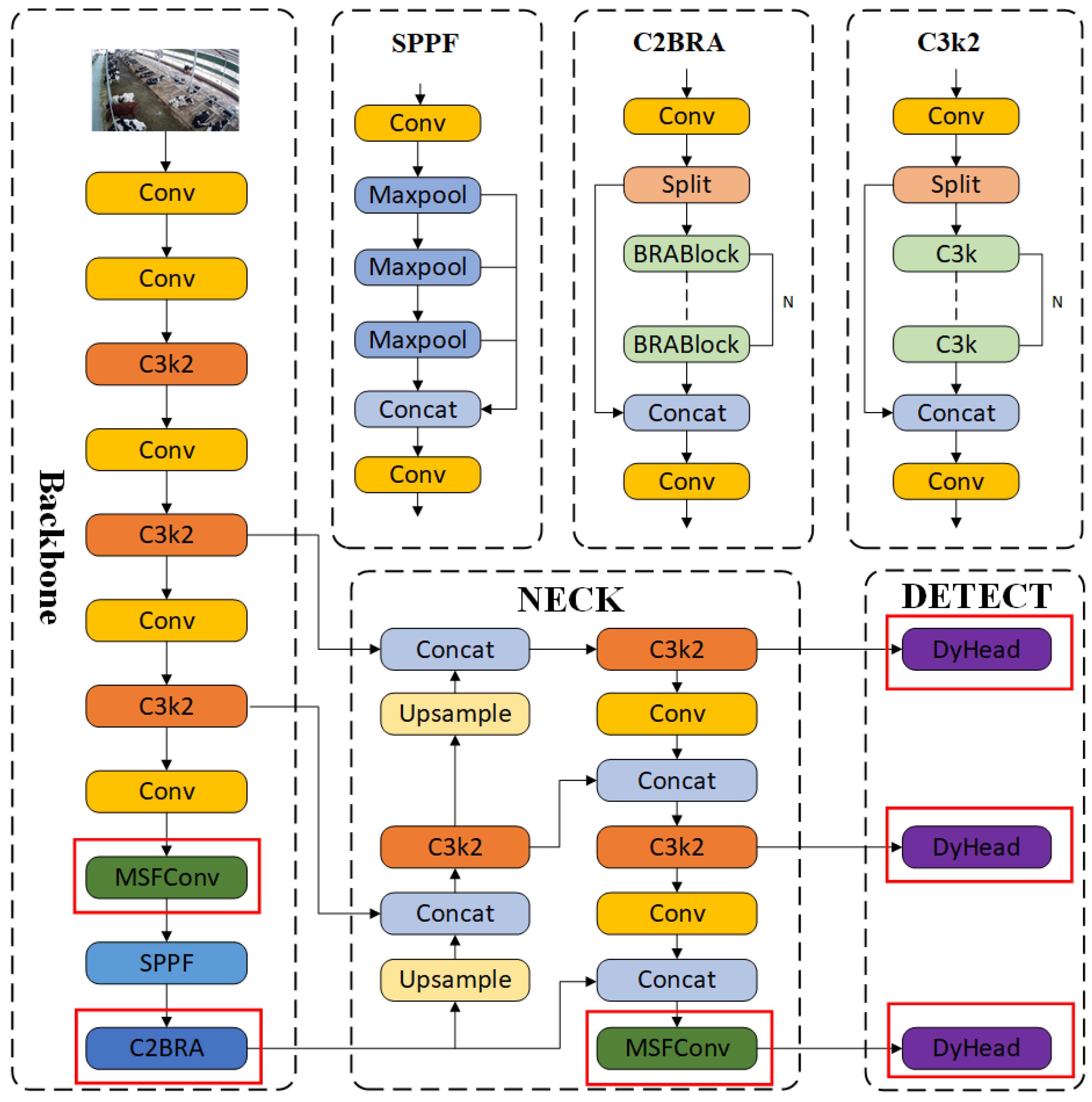
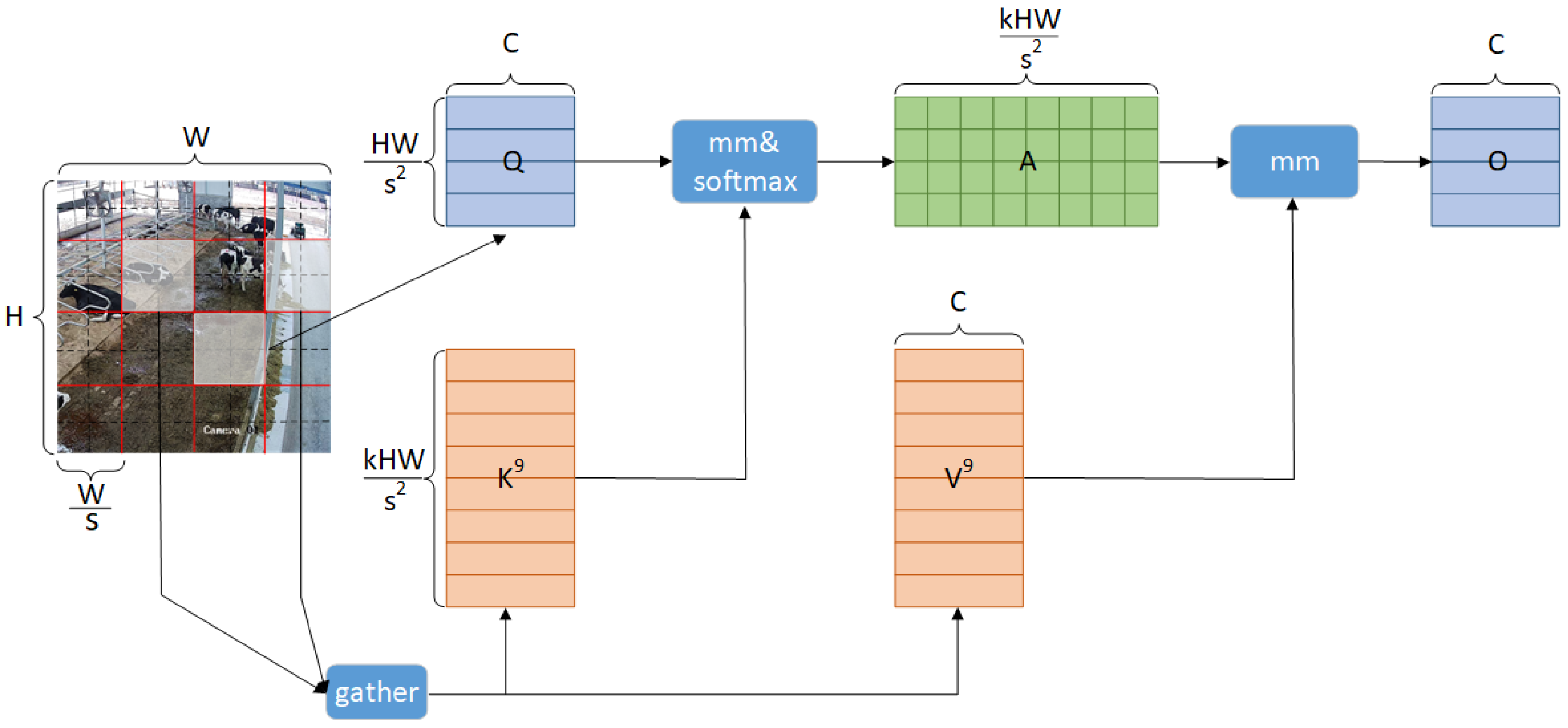


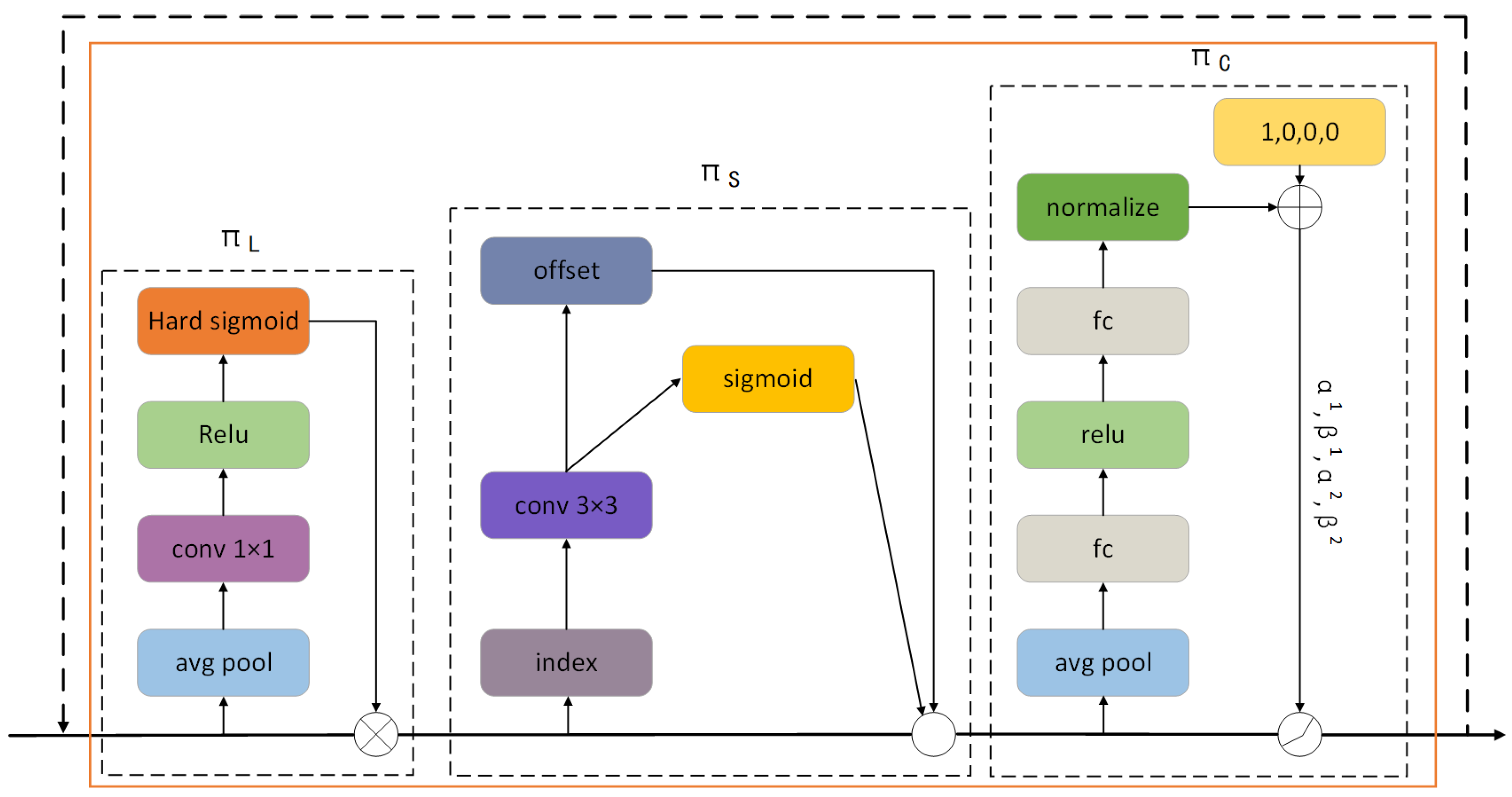



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}