

An Intelligent Track Segment Association Method Based on Characteristic-Aware Attention LSTM Network

Abstract
1. Introduction
- This paper developed an association data preprocessing algorithm that can segment and time-series synchronize the data from different sensors within the same time window. At the same time, different tracks are combined to form inputs suitable for the model.
- The CA-LSTM model optimizes characteristic representation through three mechanisms: characteristic group embedding, encoding, and characteristic-aware attention. This method can assign characteristic weights based on model training results, effectively solving the waste of multi-dimensional data caused by using only position characteristic data in traditional methods.
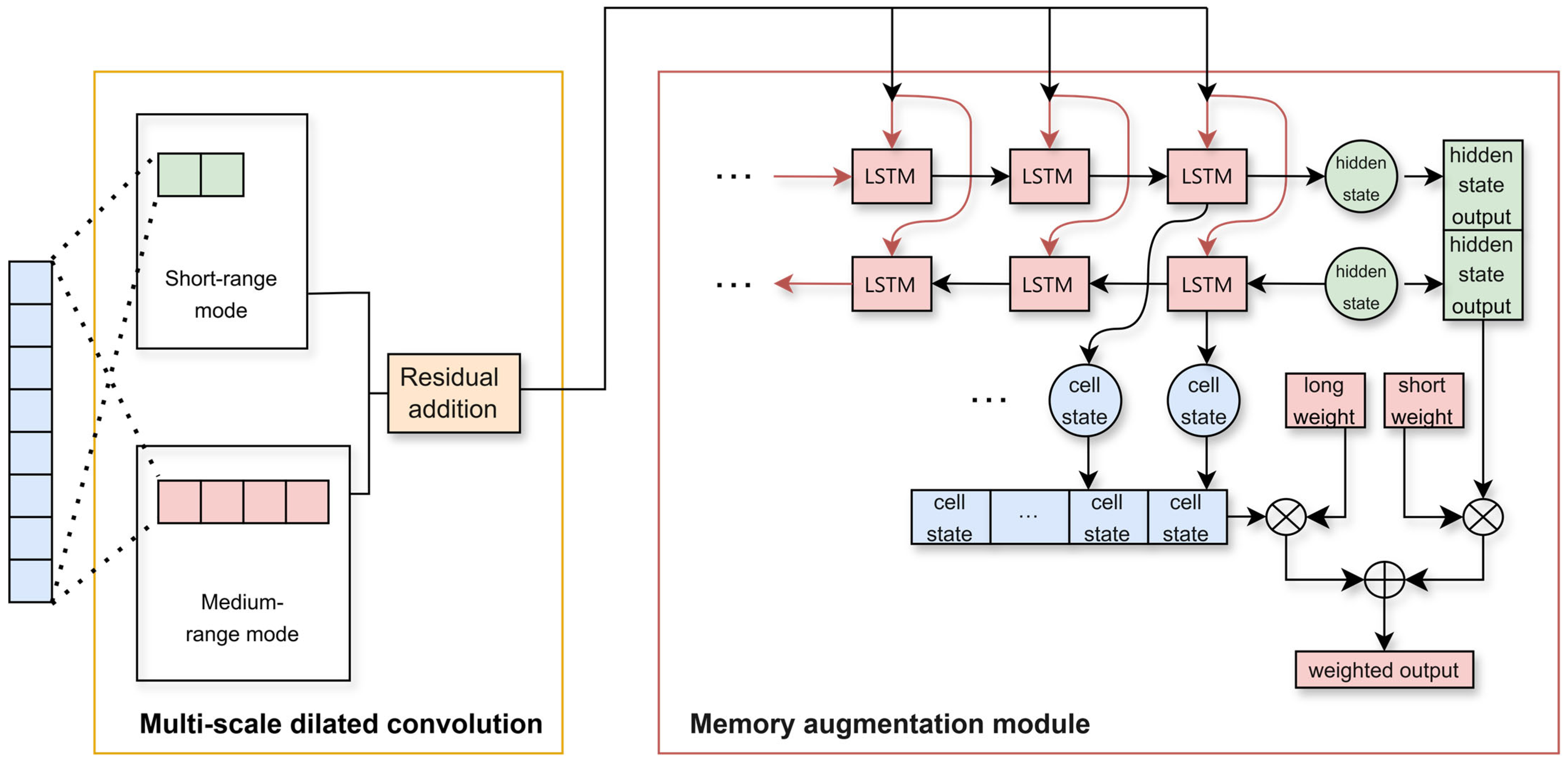
- The model combines a gated adaptive LSTM and a multi-scale dilated convolution to optimize the representation of the time dimension. The two modules can extract the characteristics of the input in the time dimension, and obtain the short-range and medium-range correlations of adjacent nodes and the long-range correlations of the entire track.
2. Track Segment Association Problem Formulation
2.1. Problem Description
2.2. Association Characteristic Processing Algorithm
| Algorithm 1: Association characteristic processing algorithm |
| Input : Sensor matrices A(α), B(β), window size w, slide step δ = ∅ = max (min (, min ()) = min (max (), max ()) ] n = ⌈((length of ) − w)/δ⌉ + 1 for γ = 1: n do s = (γ − 1) * δ, ) [s:e] if ≠ ∅ then ) else = ∅ if ≠ ∅ then for f = x, y, v, θ do = (Δf − min(Δf))/(max(Δf) − min(Δf)) end end end |
2.3. Association Decision Output
3. The CA-LSTM Model
3.1. Overall Architecture
3.2. Core Module Design
3.2.1. Characteristic Grouping Embedding and Encoding
3.2.2. Time Dimension Processing Network
3.2.3. Characteristic-Aware Attention
4. Experimental Analysis on Real-World Data
4.1. Dataset and Experimental Setup
4.2. Experimental Metrics and Results Analysis
4.3. Model Performance Analysis and Parameter Optimization
4.3.1. Comparative Experiments
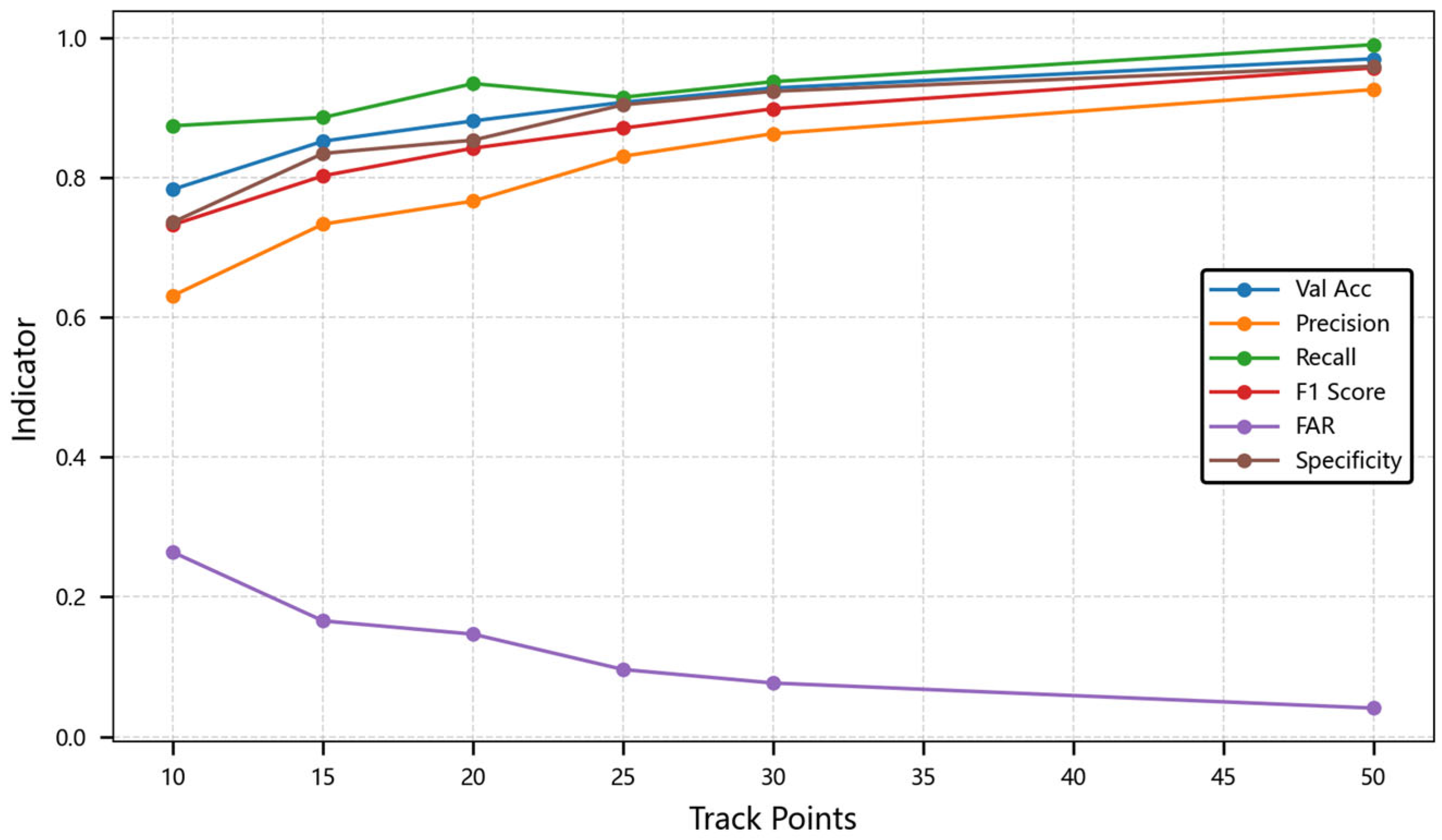
4.3.2. Influence of Time Series Length
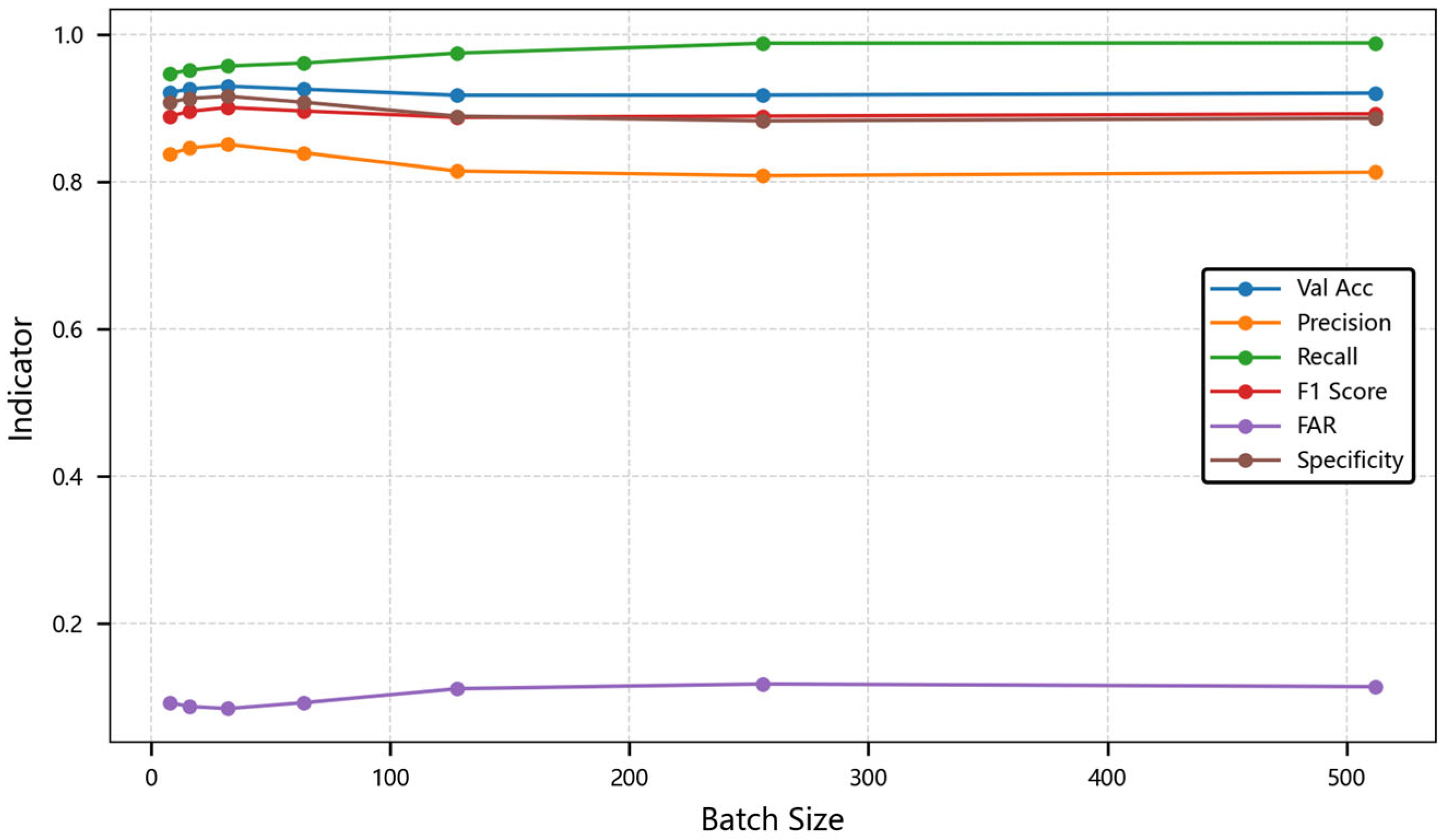
4.3.3. Parameter Sensitivity Analysis
4.3.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, S.-Y.; Xiao, H.; Liu, H. Expression of Track Correlation Uncertainty. Acta Electron. Sin. 2011, 39, 1589–1593. [Google Scholar]
- Liu, T.; Liu, K.; Zeng, X.; Zhang, S.; Zhou, Y. Efficient Marine Track-to-Track Association Method for Multi-Source Sensors. IEEE Signal Process. Lett. 2024, 31, 1364–1368. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, Y.; Wei, S.; Wei, Z.; Wu, Q.; Savaria, Y. Multi-Sensor Track-to-Track Association and Spatial Registration Algorithm Under Incomplete Measurements. IEEE Trans. Signal Process. 2021, 69, 3337–3350. [Google Scholar] [CrossRef]
- Bai, X.; Lan, H.; Wang, Z.; Pan, Q.; Hao, Y.; Li, C. Robust Multitarget Tracking in Interference Environments: A Message-Passing Approach. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 360–386. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, J. Track Fusion Based on the Mean OSPA Distance with an Adaptive Sliding Window. Acta Electron. Sin. 2016, 44, 353–357. [Google Scholar] [CrossRef]
- Wang, G.; Wang, Q.Y. Application research on multi-radar track association for formation targets using JPDA. Mod. Radar 2019, 41, 39–42. [Google Scholar] [CrossRef]
- Qiu, J.-J.; Cai, Y.-C.; Li, H.; Huang, Q.-Y. Grey Theory Track Association Algorithm Based on Dynamic Estimation Feedback. Syst. Eng. Electron. 2024, 46, 1401–1411. [Google Scholar]
- Xiong, W.; Zhang, J.-W.; He, Y. Track Correlation Algorithm Based on Multi-Dimension Assignment and Gray Theory. J. Electron. Inf. Technol. 2010, 32, 898–901. [Google Scholar] [CrossRef]
- Guo, J.-E.; Zhou, Z.; Zeng, R. Multi-Local Node Asynchronous Track Fast Correlation Algorithm. Syst. Eng. Electron. 2023, 45, 669–677. [Google Scholar] [CrossRef]
- Su, R.; Tang, J.; Yuan, J.; Bi, Y. Nearest Neighbor Data Association Algorithm Based on Robust Kalman Filtering. In Proceedings of the 2021 2nd International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 6–8 August 2021; pp. 177–181. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, H.; Ma, J.; Xie, H. Asynchronous Track-to-Track Association Based on Pseudo Nearest Neighbor Distance for Distributed Networked Radar System. Electronics 2023, 12, 1794. [Google Scholar] [CrossRef]
- Zhang, T.S.; Li, Y.L. Based on the Peer-to-peer System Error Correction Track Association Algorithm. Mod. Radar 2022, 44, 65–70. [Google Scholar] [CrossRef]
- Yang, X.; Ruan, K.-Z.; Liu, H.-M.; Wang, X.-K.; Liu, J.-Q.; Shi, Y.-S. Anti-Bias Track Association Algorithm Based on Target Measurement Error Distribution. Syst. Eng. Electron. 2024, 46, 2820–2828. [Google Scholar]
- Cui, Y.-Q.; Xiong, W.; Tang, T.-T. A Track Correlation Algorithm Based on New Space-Time Cross-Point Feature. J. Electron. Inf. Technol. 2020, 42, 2500–2507. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, Y.; Yang, Y.; Qu, C. Multi-Target Track-to-Track Association Based on Relative Coordinate Assignment Matrix. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Forestier, G.; Weber, J. Deep Learning for Time Series Classification: A Review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Gao, C.; Liu, H.; Varshney, P.K.; Yan, J.; Wang, P. Signal Structure Information-Based Data Association for Maneuvering Targets with a Convolutional Siamese Network. In Proceedings of the 2021 CIE International Conference on Radar (Radar), Haikou, China, 15–19 December 2021. [Google Scholar] [CrossRef]
- Huang, H.-W.; Liu, Y.-J.; Shen, Z.-K.; Zhang, S.-W.; Chen, Z.-M.; Gao, Y. End-to-End Track Association Based on Deep Learning Network Model. Comput. Sci. 2020, 47, 200–205. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Y.; Zhang, Q. Track Segment Association Based on LSTM Networks. In Proceedings of the 2023 5th International Conference on Frontiers Technology of Information and Computer (ICFTIC), Qiangdao, China, 17–19 November 2023. [Google Scholar] [CrossRef]
- Xiong, W.; Xu, P.; Cui, Y.; Xiong, Z.; Lv, Y.; Gu, X. Track Segment Association with Dual Contrast Neural Network. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 247–261. [Google Scholar] [CrossRef]
- Xu, P.-L.; Cui, Y.-Q.; Xiong, W.; Xiong, Z.-Y.; Gu, X.-Q. Generative Track Segment Consecutive Association Method. Syst. Eng. Electron. 2022, 44, 1543–1552. [Google Scholar] [CrossRef]
- Cui, Y.-Q.; He, Y.; Tang, T.-T.; Xiong, W. A Deep Learning Track Correlation Method. Acta Electron. Sin. 2022, 50, 759–763. [Google Scholar] [CrossRef]
- Guo, J.; Fang, Z.; Yu, Z.; Zhang, H.; Zheng, Y.; Zhang, H. Multi-Sensor Signal-Based Multi-Level Association Strategy for Real-Time Track Association and Fusion. In Proceedings of the 2023 9th International Conference on Big Data and Information Analytics (BigDIA), Haikou, China, 15–17 December 2023. [Google Scholar] [CrossRef]
- Wang, Z.-G.; Yan, W.-Z.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar] [CrossRef]
- Yang, J.-B.; Nguyen, M.N.; San, P.P. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Wang, H.X.; Shu, T.; He, J.; Yu, W.X. Multi-function Radar Behavior Recognition Technology Based on Parallel Fusion Network. Mod. Radar 2024, 46, 50–55. [Google Scholar] [CrossRef]
- Zhai, X.L.; Wang, X.; Wang, Y.B.; Wang, F. Multi-station Fusion Recognition of Ballistic Targets Based on Two-stage Attention Layer Transformer. Mod. Radar 2024, 46, 37–44. [Google Scholar]
- Cao, Z.; Liu, B.; Yang, J.; Tan, K.; Dai, Z.; Lu, X.; Gu, H. Contrastive Transformer Network for Track Segment Association with Two-Stage Online Method. Remote Sens. 2024, 16, 3380. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, N.; Lu, X.; Hu, Z.; Huang, H. Mgformer: Multi-group transformer for multivariate time series classification. Eng. Appl. Artif. Intell. 2024, 133, 108633. [Google Scholar] [CrossRef]
- Cui, Y.-Q.; Xu, P.-L.; Gong, C.; Yu, Z.-C.; Zhang, J.-T.; Yu, H.-B.; Dong, K. Multisource Track Association Dataset Based on the Global AIS. J. Electron. Inf. Technol. 2023, 45, 746–756. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Metric | Track Points | CA-LSTM | CNN | ResNet | LSTM | Transformer |
|---|---|---|---|---|---|---|
| Val Acc | 10 | 0.7830 | 0.7563 | 0.7458 | 0.7043 | 0.7695 |
| 15 | 0.8519 | 0.8275 | 0.8108 | 0.7530 | 0.8319 | |
| 20 | 0.8809 | 0.8552 | 0.8440 | 0.8073 | 0.8797 | |
| Precision | 10 | 0.6301 | 0.6002 | 0.5889 | 0.5412 | 0.6118 |
| 15 | 0.7333 | 0.6884 | 0.6667 | 0.5873 | 0.6822 | |
| 20 | 0.7662 | 0.7171 | 0.7791 | 0.6553 | 0.7588 | |
| Recall | 10 | 0.8739 | 0.8462 | 0.8328 | 0.8494 | 0.8790 |
| 15 | 0.8858 | 0.8988 | 0.8858 | 0.9177 | 0.9454 | |
| 20 | 0.9343 | 0.9476 | 0.7547 | 0.9125 | 0.9469 | |
| F1 Score | 10 | 0.7323 | 0.7023 | 0.6900 | 0.6611 | 0.7214 |
| 15 | 0.8024 | 0.7796 | 0.7608 | 0.7162 | 0.7926 | |
| 20 | 0.8419 | 0.8164 | 0.7667 | 0.7628 | 0.8425 | |
| FAR | 10 | 0.2638 | 0.2898 | 0.2989 | 0.3703 | 0.2868 |
| 15 | 0.1656 | 0.2092 | 0.2277 | 0.3316 | 0.2264 | |
| 20 | 0.1466 | 0.1922 | 0.1100 | 0.2468 | 0.1548 | |
| Specificity | 10 | 0.7362 | 0.7102 | 0.7011 | 0.6297 | 0.7132 |
| 15 | 0.8344 | 0.7908 | 0.7723 | 0.6684 | 0.7736 | |
| 20 | 0.8534 | 0.8078 | 0.8900 | 0.7532 | 0.8452 | |
| Params (M) | 10 | 1.7286 | 0.3553 | 3.9102 | 0.8606 | 0.9855 |
| 15 | 2.2202 | 0.3553 | 3.9102 | 1.0243 | 1.4771 | |
| 20 | 2.7117 | 0.3553 | 3.9102 | 1.1882 | 1.9686 | |
| GPU Mem (GB) | 10 | 0.08 | 0.02 | 0.09 | 0.07 | 0.04 |
| 15 | 0.10 | 0.02 | 0.09 | 0.08 | 0.06 | |
| 20 | 0.11 | 0.02 | 0.09 | 0.09 | 0.06 | |
| Epoch Time (s) | 10 | 28.53 | 16.12 | 24.55 | 15.77 | 18.95 |
| 15 | 23.43 | 14.42 | 19.30 | 15.73 | 20.49 | |
| 20 | 20.44 | 13.30 | 17.44 | 13.06 | 14.91 |
| Model Metric | 10 | 15 | 20 | 25 | 30 | 50 |
|---|---|---|---|---|---|---|
| Val Acc | 0.7830 | 0.8519 | 0.8809 | 0.9076 | 0.9280 | 0.9697 |
| Precision | 0.6310 | 0.7333 | 0.7662 | 0.8304 | 0.8627 | 0.9258 |
| Recall | 0.8739 | 0.8858 | 0.9343 | 0.9148 | 0.9371 | 0.9900 |
| F1 Score | 0.7323 | 0.8024 | 0.8419 | 0.8706 | 0.8983 | 0.9568 |
| FAR | 0.2638 | 0.1656 | 0.1466 | 0.0960 | 0.0767 | 0.0408 |
| Specificity | 0.7362 | 0.8344 | 0.8534 | 0.9040 | 0.9233 | 0.9592 |
| Model Metric | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|---|---|
| Val Acc | 0.9211 | 0.9260 | 0.9298 | 0.9256 | 0.9175 | 0.9178 | 0.9204 |
| Precision | 0.8374 | 0.8457 | 0.8508 | 0.8392 | 0.8145 | 0.8081 | 0.8129 |
| Recall | 0.9473 | 0.9515 | 0.9571 | 0.9612 | 0.9746 | 0.9881 | 0.9885 |
| F1 Score | 0.8889 | 0.8955 | 0.9009 | 0.8960 | 0.8874 | 0.8891 | 0.8922 |
| FAR | 0.0920 | 0.0868 | 0.0839 | 0.0921 | 0.1110 | 0.1173 | 0.1137 |
| Specificity | 0.9080 | 0.9132 | 0.9161 | 0.9079 | 0.8890 | 0.8827 | 0.8863 |
| Model Metric | 1/50 | 2/50 | 3/50 | 4/50 | 5/50 | 6/50 | 7/50 |
|---|---|---|---|---|---|---|---|
| Val Acc | 0.8074 | 0.8600 | 0.8745 | 0.8757 | 0.8820 | 0.8801 | 0.8846 |
| Precision | 0.6540 | 0.7599 | 0.7801 | 0.7604 | 0.7827 | 0.7647 | 0.7895 |
| Recall | 0.9190 | 0.8592 | 0.8781 | 0.9254 | 0.9034 | 0.9343 | 0.9001 |
| F1 Score | 0.7641 | 0.8065 | 0.8262 | 0.8349 | 0.8387 | 0.8410 | 0.8412 |
| FAR | 0.2500 | 0.1396 | 0.1273 | 0.1499 | 0.1290 | 0.1478 | 0.1234 |
| Specificity | 0.7500 | 0.8604 | 0.8727 | 0.8501 | 0.8710 | 0.8522 | 0.8766 |
| Model Metric | CA-LSTM | w/o Characteristic Grouping Embedding | w/o Multi-Scale Dilated Convolution | w/o Gated Adaptive LSTM | w/o Characteristic-Aware Attention |
|---|---|---|---|---|---|
| Val Acc | 0.8519 | 0.8377 | 0.8414 | 0.8360 | 0.8407 |
| Precision | 0.7333 | 0.6946 | 0.7165 | 0.7028 | 0.7152 |
| Recall | 0.8858 | 0.9315 | 0.8820 | 0.8957 | 0.8821 |
| F1 Score | 0.8024 | 0.7958 | 0.7907 | 0.7876 | 0.7899 |
| FAR | 0.1656 | 0.2106 | 0.1794 | 0.1947 | 0.1807 |
| Specificity | 0.8344 | 0.7894 | 0.8206 | 0.8053 | 0.8193 |
| Params (M) | 2.2202 | 2.2207 | 1.9986 | 1.9233 | 2.2181 |
| GPU Mem (GB) | 0.1033 | 0.1350 | 0.1486 | 0.1486 | 0.1432 |
| Epoch Time | 23.43 | 39.83 | 32.77 | 29.32 | 22.54 |
| Model Metric | CA-LSTM | w/o Multi-Dimensional Characteristic Fusion | w/o Multi-Dimensional Characteristic Fusion and Multi-Dimensional Data |
|---|---|---|---|
| Val Acc | 0.8519 | 0.8485 | 0.8233 |
| Precision | 0.7333 | 0.7227 | 0.6854 |
| Recall | 0.8858 | 0.8988 | 0.8866 |
| F1 Score | 0.8024 | 0.8012 | 0.7731 |
| FAR | 0.1656 | 0.1773 | 0.2093 |
| Specificity | 0.8344 | 0.8227 | 0.7907 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, J.; Lu, X.; Sun, J. An Intelligent Track Segment Association Method Based on Characteristic-Aware Attention LSTM Network. Sensors 2025, 25, 3465. https://doi.org/10.3390/s25113465
Qi J, Lu X, Sun J. An Intelligent Track Segment Association Method Based on Characteristic-Aware Attention LSTM Network. Sensors. 2025; 25(11):3465. https://doi.org/10.3390/s25113465
Chicago/Turabian StyleQi, Jiadi, Xiaoke Lu, and Jinping Sun. 2025. "An Intelligent Track Segment Association Method Based on Characteristic-Aware Attention LSTM Network" Sensors 25, no. 11: 3465. https://doi.org/10.3390/s25113465
APA StyleQi, J., Lu, X., & Sun, J. (2025). An Intelligent Track Segment Association Method Based on Characteristic-Aware Attention LSTM Network. Sensors, 25(11), 3465. https://doi.org/10.3390/s25113465