
Research on Tunnel Crack Identification Localization and Segmentation Method Based on Improved YOLOX and UNETR++
Abstract
1. Introduction
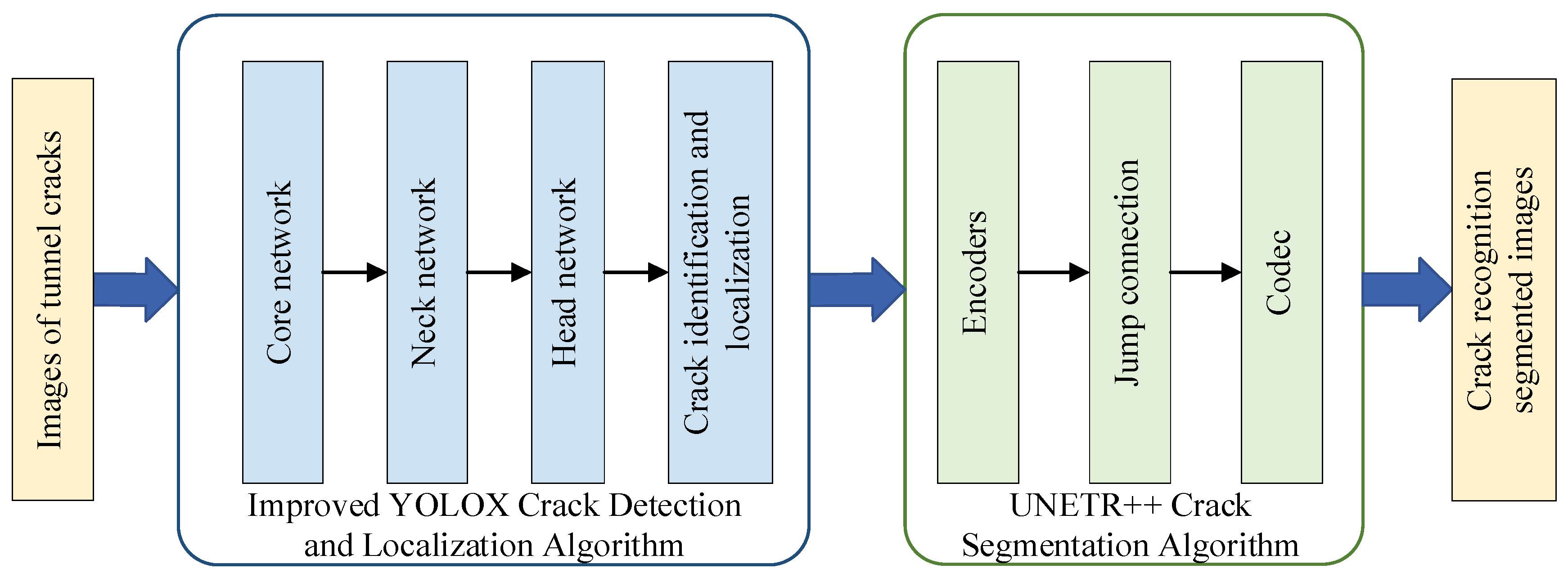
2. The Overall Design for Crack Detection–Localization and Segmentation
3. Tunnel Crack Identification Localization and Segmentation Based on Improved YOLOX and UNETR++
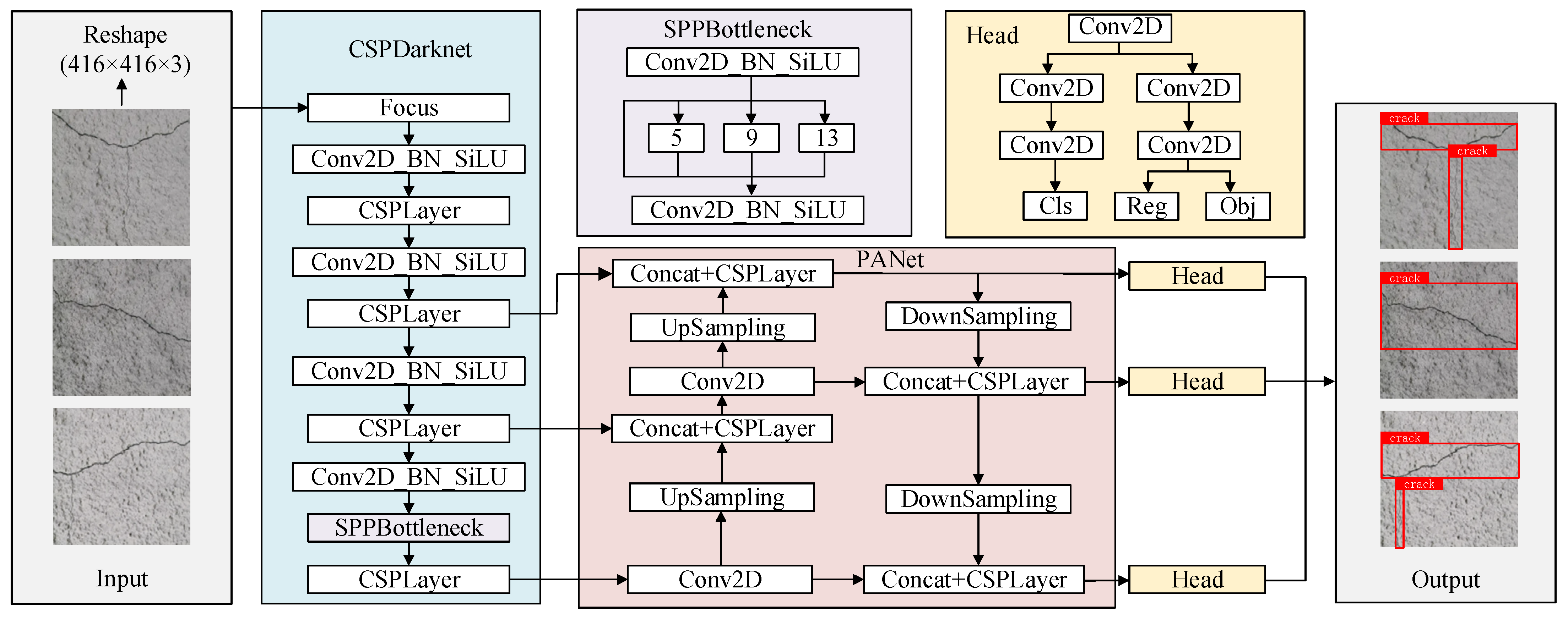
3.1. YOLOX Algorithm
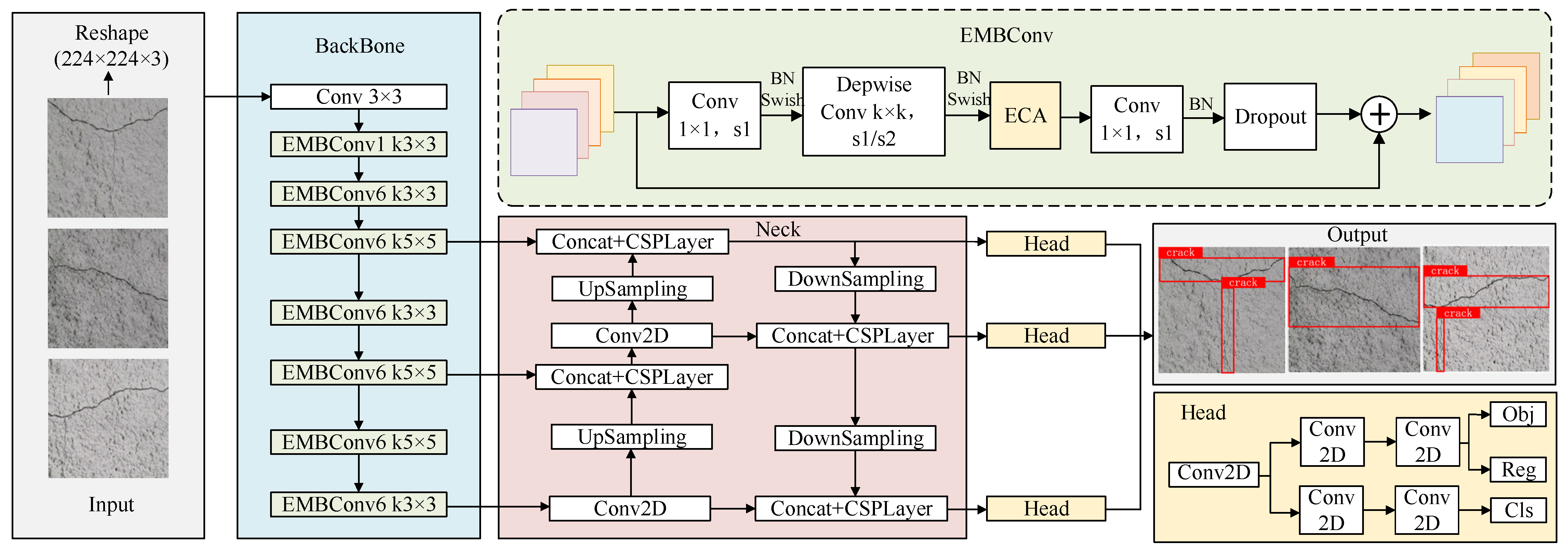
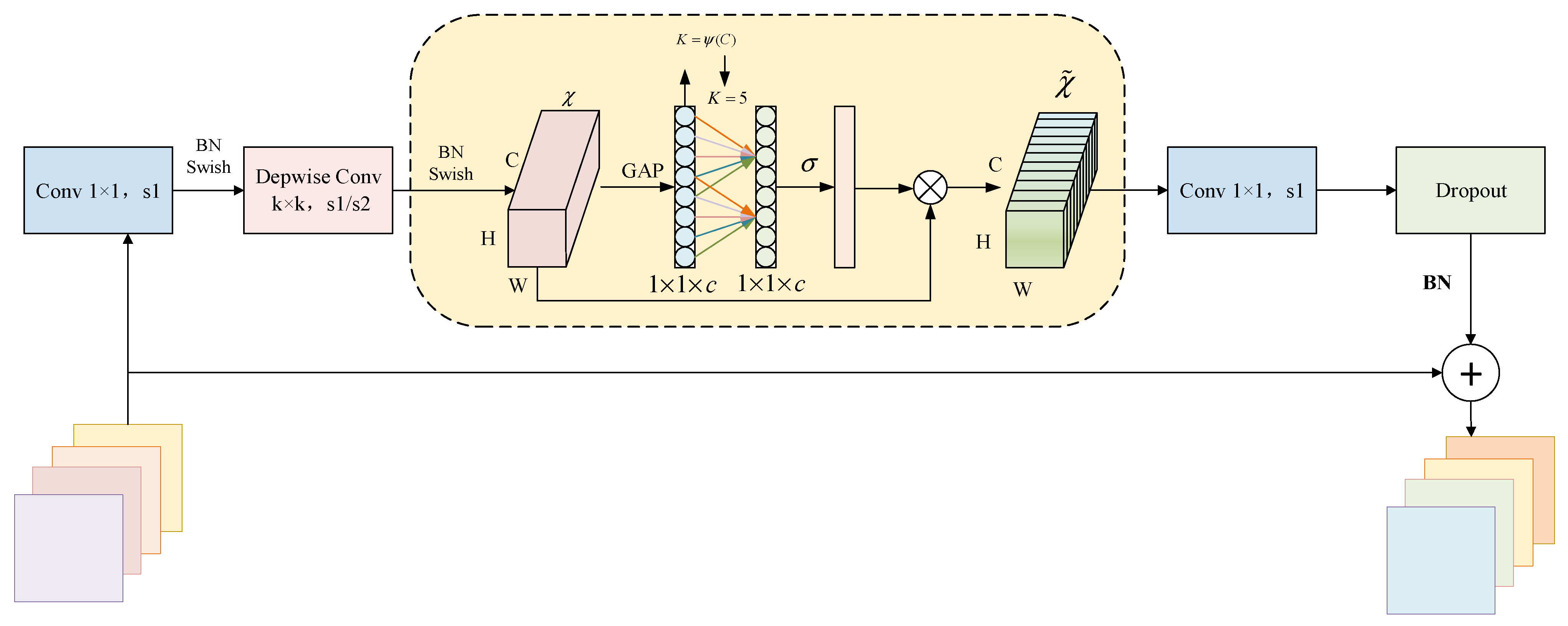
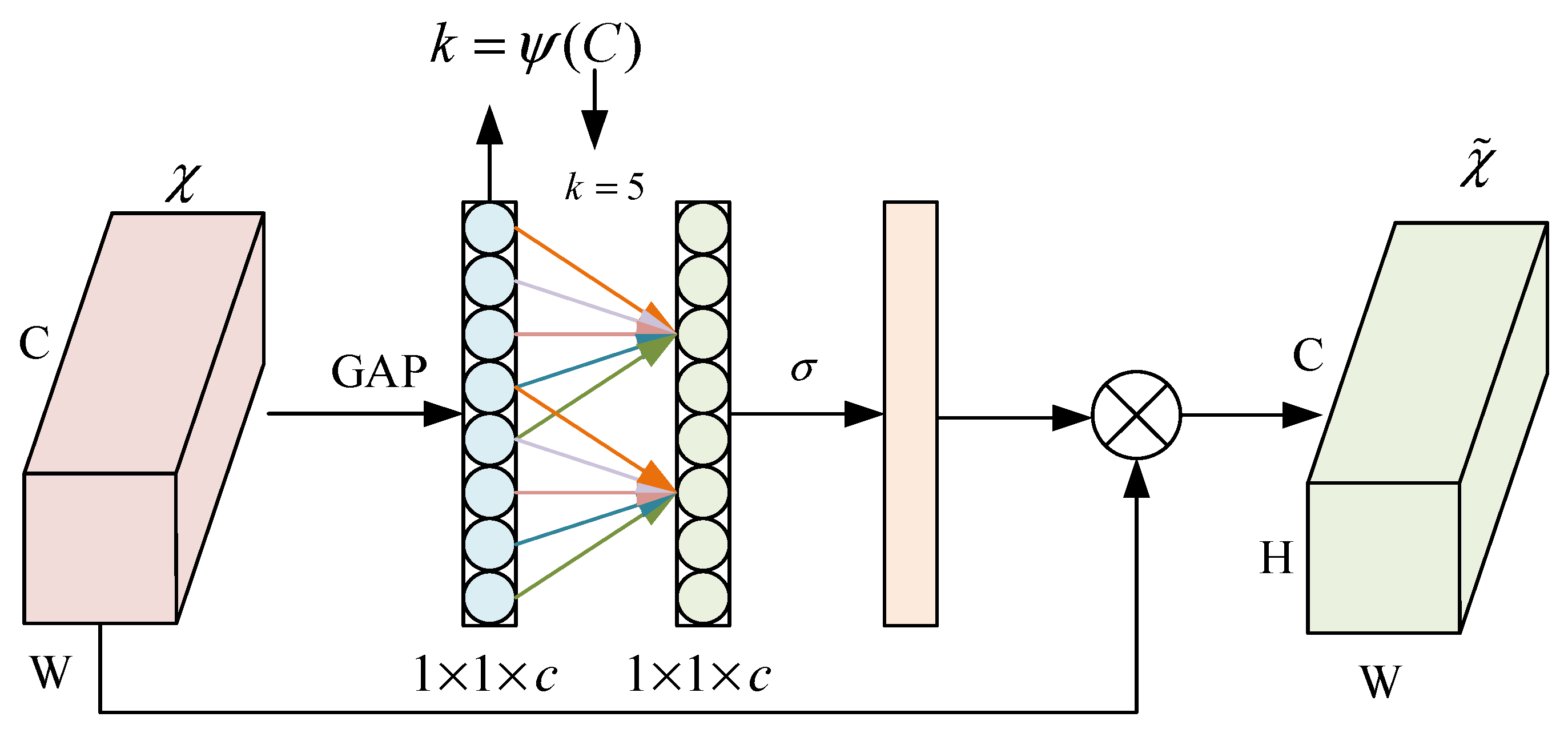
3.2. Improved YOLOX Crack Identification and Localization Algorithm
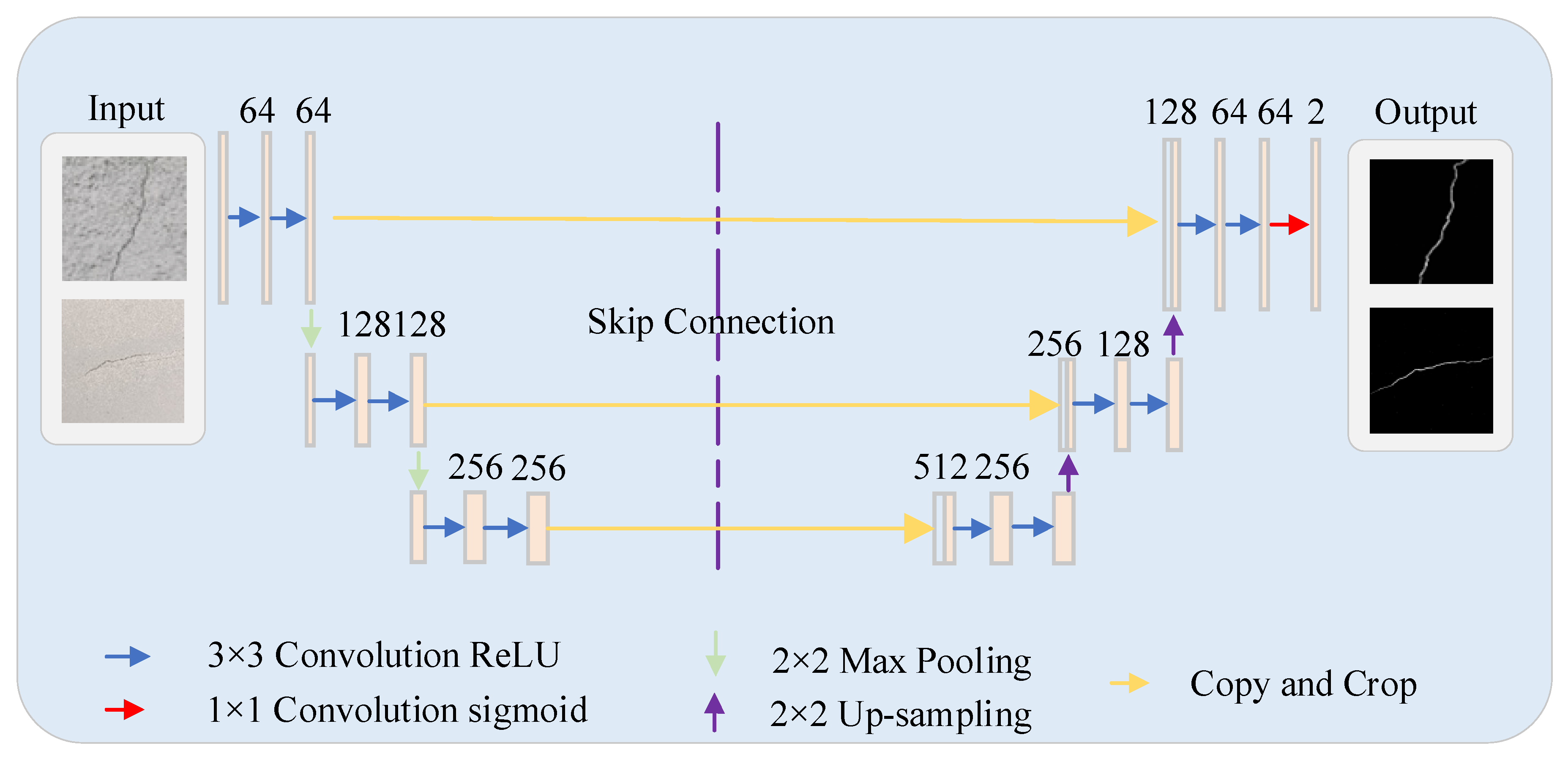
3.3. U-Net Segmentation Algorithm
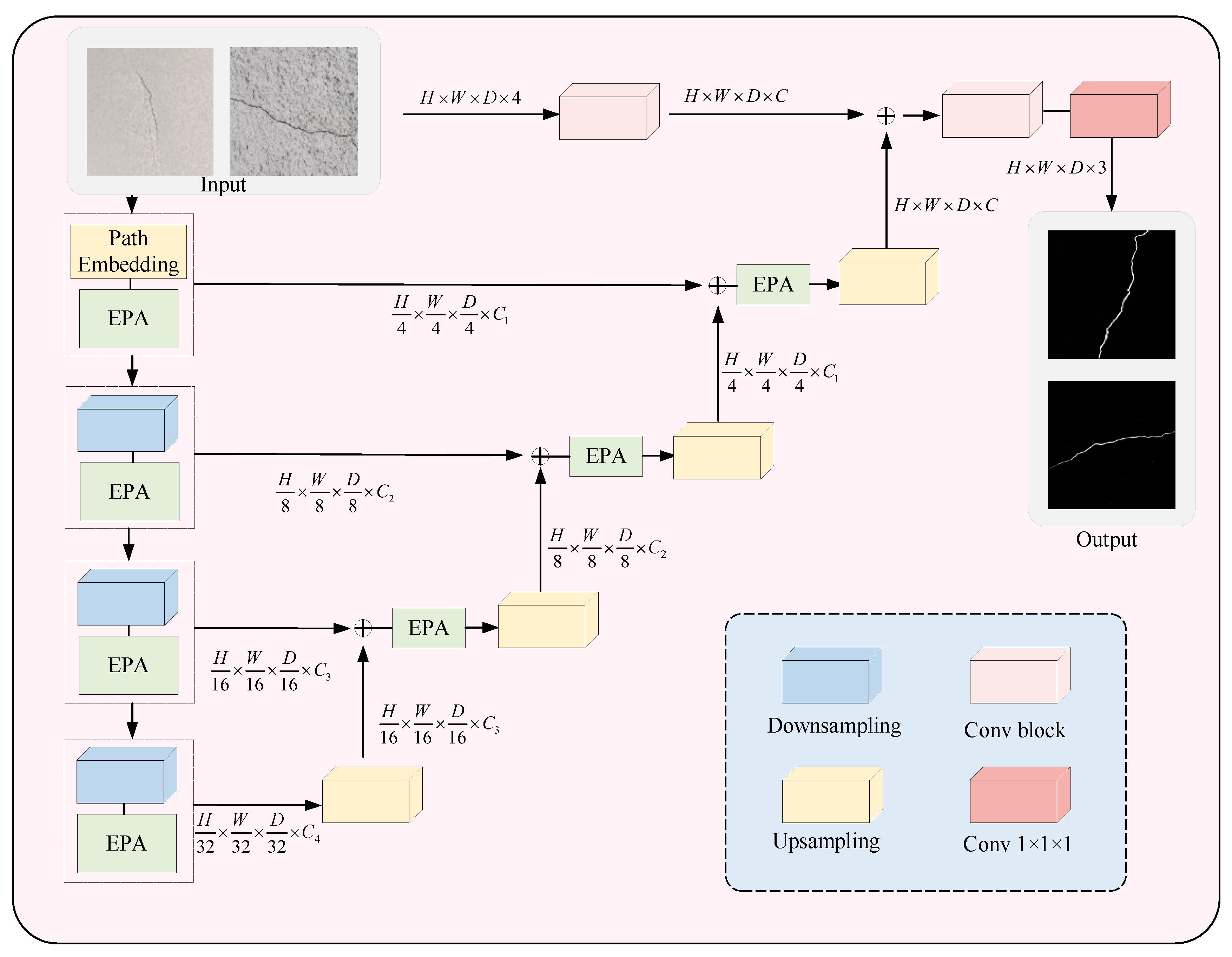
3.4. UNETR++ Crack Segmentation Algorithm
4. Crack Recognition Model Training
4.1. Tunnel Crack Dataset
4.2. Experimental Environment and Evaluation Indicators
5. Experiment and Analysis
5.1. Experimental Validation of Crack Localization Identification and Segmentation Algorithm Based on Improved YOLOX and UNETR++
5.2. Experimental Analysis of Improved YOLOX Crack Identification and Localization
5.2.1. Ablation Experiment
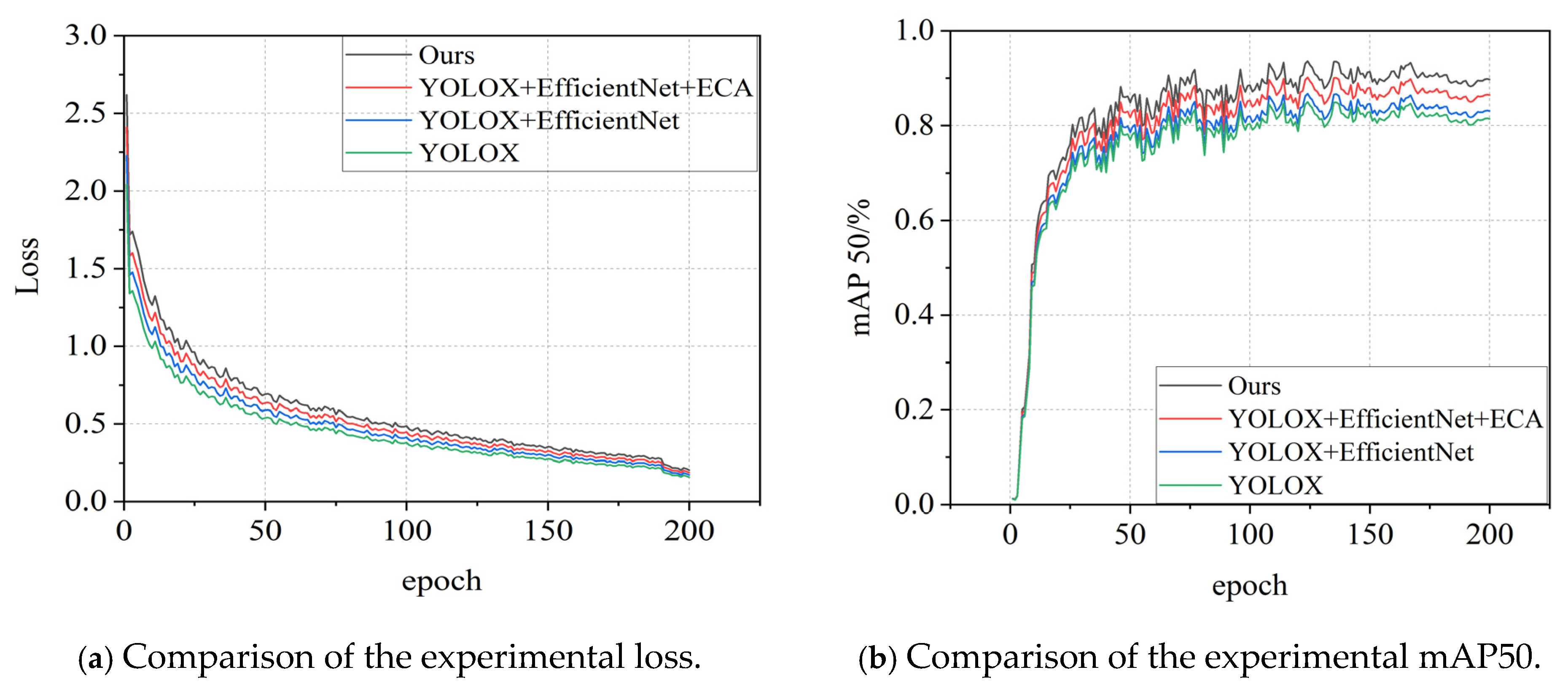
5.2.2. Comparison Experiment
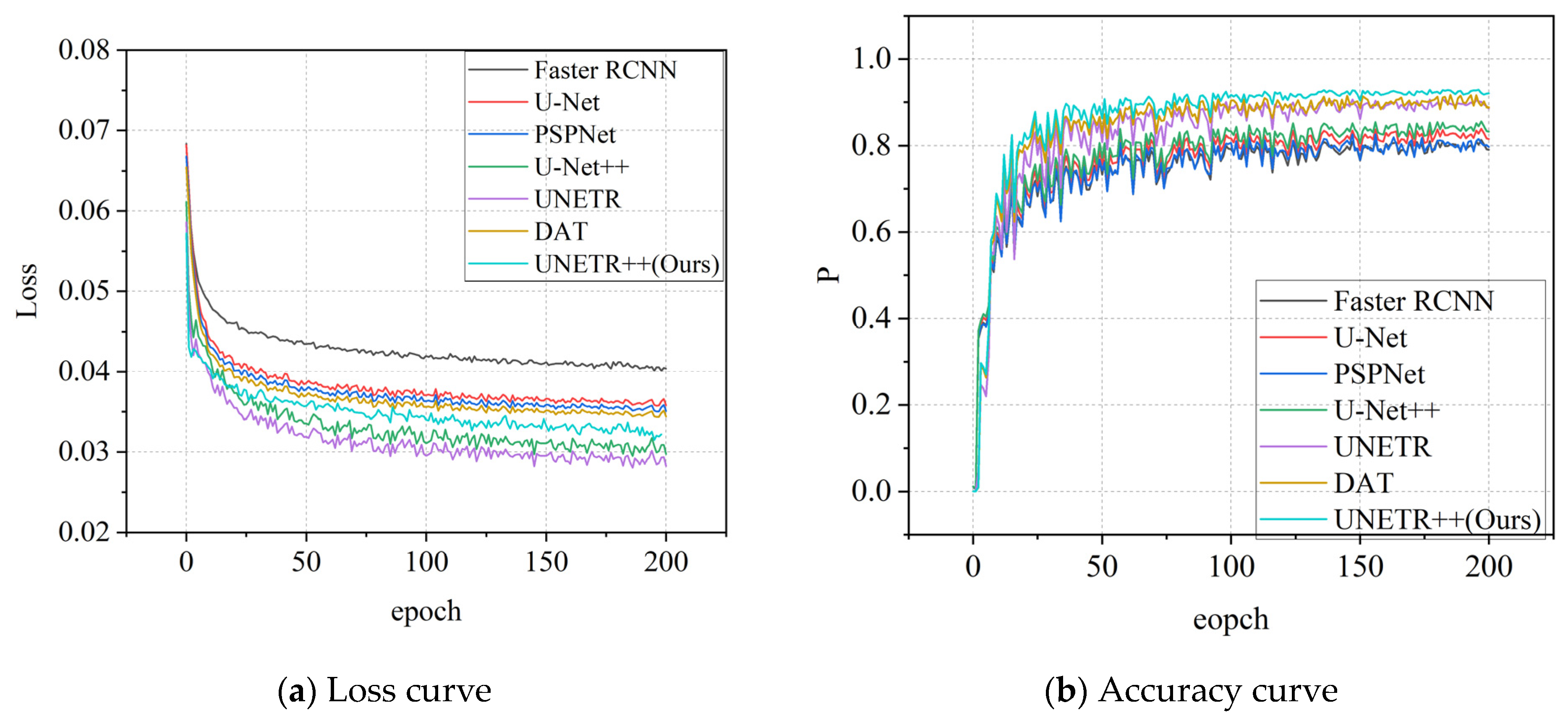
5.3. Experimental Analysis of UNETR++ Segmentation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bao, Y.; Mei, C.; Xu, P.; Sun, Z.; Wen, Y. Crack Identification in Metro Tunnels Based on Improved YOLOv8 Algorithm. Tunn. Constr. 2024, 44, 1961–1970. [Google Scholar]
- Huang, Y.; Peng, Q.; Xu, B. A Method of Identifying Surface Crack of Subway Tunnel in Consideration of Occlusions. J. Chang. River Sci. Res. Inst. 2023, 40, 145–152. [Google Scholar]
- Zhou, Z.; Yan, L.; Zhang, J. Intelligent Detection of Tunnel Lining Cracks Based on Self-attention Mechanism and Convolution Neural Network. J. China Railw. Soc. 2024, 46, 182–192. [Google Scholar]
- Song, Q.; Wu, Y.; Xin, X.; Yang, L.; Yang, M.; Chen, H.; Liu, C.; Hu, M.; Chai, X.; Li, J. Real-time tunnel crack analysis system via deep learning. IEEE Access 2019, 7, 64186–64197. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, X. Tunnel crack detection method and crack image processing algorithm based on improved Retinex and deep learning. Sensors 2023, 23, 9140. [Google Scholar] [CrossRef]
- Song, Y.; Zhao, N.; Yan, C.; Tan, H.; Deng, J. The Mobile-PSPNet method for real-time segmentation of tunnel lining cracks. J. Railw. Sci. Eng. 2022, 19, 3746–3757. [Google Scholar]
- Kuang, X.; Xu, Y.; Lei, H.; Cheng, F.; Huan, X. Tunnel crack segmentation based on lightweight Transformer. J. Railw. Sci. Eng. 2024, 21, 3421–3433. [Google Scholar]
- Chen, Y.; Yang, T.; Dong, S.; Wang, L.; Pei, B.; Wang, Y. Enhancing Crack Segmentation Network with Multiple Selective Fusion Mechanisms. Buildings 2025, 15, 1088. [Google Scholar] [CrossRef]
- Wu, Y.; Li, S.; Zhang, J.; Li, Y.; Li, Y.; Zhang, Y. Dual attention transformer network for pixel-level concrete crack segmentation considering camera placement. Autom. Constr. 2024, 157, 105166. [Google Scholar] [CrossRef]
- Yin, X.; Fu, L.; Zhou, S. Concrete pavement crack detection network with progressive context interaction and attention mechanism. J. Comput. Appl. 2025, 1–12. Available online: https://link.cnki.net/urlid/51.1307.TP.20250314.1257.002 (accessed on 27 May 2025).
- Hu, W.; Liu, X.; Zhou, Z.; Wang, W.; Wu, Z.; Chen, Z. Robust crack detection in complex slab track scenarios using STC-YOLO and synthetic data with highly simulated modeling. Autom. Constr. 2025, 175, 106219. [Google Scholar] [CrossRef]
- Li, H.; Zhang, X. An equivalent target plate damage probability calculation mathematics model and damage evaluation method. Def. Technol. 2024, 41, 82–103. [Google Scholar] [CrossRef]
- Lu, L.; Zhang, X. Datafusion method of multi-sensor target recognition in complex environment. J. Xidian Univ. 2020, 47, 31–38. [Google Scholar]
- Li, H.; Zhang, X.; Gao, J. A cloud model target damage effectiveness assessment algorithm based on spatio-temporal sequence finite multilayer fragments dispersion. Def. Technol. 2024, 40, 48–64. [Google Scholar] [CrossRef]
- Liao, J.; Yue, Y.; Zhang, D.; Tu, W.; Cao, R.; Zou, Q.; Li, Q. Automatic tunnel crack inspection using an efficient mobile imaging module and a lightweight CNN. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15190–15203. [Google Scholar] [CrossRef]
- Li, P.; Zhang, B.; Wang, C.; Hu, G.; Yan, Y.; Guo, R.; Xia, H. CNN-based pavement defects detection using grey and depth images. Autom. Constr. 2024, 158, 105192. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; Luo, L.; Wang, L.; Zhi, Q. Tomato ripeness and stem recognition based on improved YOLOX. Sci. Rep. 2025, 15, 1924–1934. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, M.; Wan, Z.; Jiang, W.; He, W.; Wang, Y. A Dual Deep Network Based on the Improved YOLO for Fast Bridge Surface Defect Detection. Acta Autom. Sin. 2022, 48, 1018–1032. [Google Scholar]
- Duan, S.; Zhang, M.; Qiu, S.; Xiong, J.; Zhang, H.; Li, C.; Jiang, Q.; Kou, Y. Tunnel lining crack detection model based on improved YOLOv5. Tunn. Undergr. Space Technol. Sci. Technol. Eng. 2024, 147, 105713. [Google Scholar] [CrossRef]
- He, Y.; Chen, Q.; Cheng, J. Intelligent Identification of Tunnel Lining Cracks Based on Improved YOLOv7. J. Hunan Univ. Sci. Technol. 2024, 39, 35–43. [Google Scholar]
- Yu, S.; Jang, J.; Han, C. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Autom. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhan, Q.; Ma, Z. EfficientNet-ECA: A lightweight network based on efficient channel attention for class-imbalanced welding defects classification. Adv. Eng. Inform. 2024, 62, 102737. [Google Scholar] [CrossRef]
- Li, H.; Zhang, X.; Gao, J. A measurement method and calculation mathematical model of projectile fuze explosion position using binocular vision of AAVs. IEEE Trans. Instrum. Meas. 2025, 74, 1007711. [Google Scholar] [CrossRef]
- Laofor, C.; Peansupap, V. Defect detection and quantification system to support subjective visual quality inspection via a digital image processing: A tiling work case study. Autom. Constr. 2012, 24, 160–174. [Google Scholar] [CrossRef]
- Li, W.; Chao, T. Effective small crack detection based on tunnel crack characteristics and an anchor-free convolutional neural network. Sci. Rep. 2024, 14, 10355. [Google Scholar]
- Gao, J.; Han, B.; Yan, K. Static object imaging features recognition algorithm in dynamic scene mapping. Multimed. Tools Appl. 2019, 78, 33885–33898. [Google Scholar] [CrossRef]
- Liu, X.; Hong, Z.; Shi, W.; Guo, X. Image-processing-based subway tunnel crack detection system. Sensors 2023, 23, 6070. [Google Scholar] [CrossRef]
- Li, H. Recognition model and algorithm of projectiles by combining particle swarm optimization support vector and spatial-temporal constrain. Def. Technol. 2023, 23, 273–283. [Google Scholar] [CrossRef]
- Li, Y.; Hou, X.; Hao, X.; Shang, R.; Jiao, L. Bilateral-Aware and Multi-Scale Region Guided U-Net for precise breast lesion segmentation in ultrasound images. Neurocomputing 2025, 632, 129775. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Ye, H.; Shu, X. DA-Net: Deep attention network for biomedical image segmentation. Signal Process. Image Commun. 2025, 135, 117283. [Google Scholar] [CrossRef]
- Shaker, M.A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.-H.; Khan, F.S. UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation. IEEE Trans. Med. Imaging 2024, 43, 3377–3390. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Li, H.; Ding, Z.; Guo, Q. An improved target detection method based on multiscale features fusion. Microw. Opt. Technol. Lett. 2020, 62, 3051–3059. [Google Scholar] [CrossRef]
- Zhao, N.; Song, Y.; Yang, A.; Lv, K.; Jiang, H.; Dong, C. Accurate Classification of Tunnel Lining Cracks Using Lightweight ShuffleNetV2-1.0-SE Model with DCGAN-Based Data Augmentation and Transfer Learning. Appl. Sci. 2024, 14, 4142. [Google Scholar] [CrossRef]
- Zheng, A.; Qi, S.; Cheng, Y.; Wu, D.; Zhu, J. Efficient Detection of Apparent Defects in Subway Tunnel Linings Based on Deep Learning Methods. Appl. Sci. 2024, 14, 7824. [Google Scholar] [CrossRef]
- Dang, L.M.; Wang, H.; Li, Y.; Park, Y.; Oh, C.; Nguyen, T.N.; Moon, H. Automatic tunnel lining crack evaluation and measurement using deep learning. Tunn. Undergr. Space Technol. 2022, 124, 104472. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, X.; Han, B. A fast and high accuracy localization estimation algorithm based on monocular vision. In Proceedings of the Big Data Analytics for Cyber-Physical System in Smart City, Shenyang, China, 28–29 December 2019; Volume 2019, pp. 238–245. [Google Scholar]
- Li, H.; Zhang, X. A measurement method of projectile explosion position and explosion image recognition algorithm Based on PSPNet and Swin Transformer Fusion. IEEE Sens. J. 2025, 25, 4715–4726. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Resolution | Channels | Layers |
|---|---|---|---|---|
| 1 | Conv 3 × 3 | 224 × 224 | 32 | 1 |
| 2 | MBConv 1, k3 × 3 | 112 × 112 | 16 | 1 |
| 3 | MBConv 6, k3 × 3 | 112 × 112 | 24 | 2 |
| 4 | MBConv 6, k5 × 5 | 56 × 56 | 40 | 2 |
| 5 | MBConv 6, k3 × 3 | 28 × 28 | 80 | 3 |
| 6 | MBConv 6, k5 × 5 | 14 × 14 | 112 | 3 |
| 7 | MBConv 6, k5 × 5 | 14 × 14 | 192 | 4 |
| 8 | MBConv 6, k3 × 3 | 7 × 7 | 320 | 1 |
| 9 | Conv 1 × 1&Pooling&FC | 7 × 7 | 1280 | 1 |
| Method | mAP 50/% | FPS |
|---|---|---|
| YOLOX | 81.28 | 47.65 |
| YOLOX + EfficientNet | 83.17 | 55.49 |
| YOLOX + EfficientNet + ECA | 86.38 | 58.87 |
| Improved YOLOX (Ours) | 89.14 | 62.28 |
| Algorithm | F1-Score/% | P/% | R/% | mAP50/% | FPS | FLOPs/G | Parameter/M |
|---|---|---|---|---|---|---|---|
| Faster RCNN | 80.21 | 82.49 | 78.27 | 79.52 | 18.62 | 138.73 | 41.52 |
| YOLOv3 | 78.2 | 80.83 | 74.56 | 78.17 | 40.38 | 65.21 | 61.23 |
| YOLOv5 | 79.34 | 81.31 | 75.39 | 80.38 | 42.65 | 98.73 | 7.29 |
| YOLOX | 82.31 | 84.28 | 78.31 | 81.28 | 47.65 | 25.69 | 9.03 |
| YOLOv8 | 85.18 | 86.53 | 83.72 | 85.92 | 58.24 | 26.85 | 10.52 |
| Mobile-Former | 83.53 | 84.68 | 82.19 | 83.71 | 61.53 | 24.16 | 6.82 |
| Improved YOLOX (ours) | 84.73 | 87.65 | 82.27 | 89.14 | 62.28 | 26.42 | 8.75 |
| Algorithm | P/% | R/% | IoU/% | F1-Score/% | FPS | FLOPs/G | Parameter/M |
|---|---|---|---|---|---|---|---|
| Faster RCNN | 58.0 | 87.0 | 52.7 | 70.1 | 12.3 | 200.3 | 41.2 |
| U-Net | 72.5 | 90.3 | 66.1 | 80.3 | 25.2 | 152.3 | 34.5 |
| PSPNet | 74.5 | 89.5 | 66.7 | 80.8 | 20.3 | 183.6 | 46.7 |
| UNet++ | 77.2 | 90.4 | 70.4 | 83.6 | 31.8 | 172.4 | 27.4 |
| DAT | 78.6 | 90.8 | 70.2 | 83.9 | 27.9 | 167.2 | 38.6 |
| UNETR | 80.7 | 93.2 | 74.3 | 86.1 | 36.3 | 62.3 | 18.9 |
| UNETR++(Ours) | 85.3 | 96.1 | 79.8 | 90.2 | 45.3 | 41.7 | 12.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Liu, X.; Lei, Z. Research on Tunnel Crack Identification Localization and Segmentation Method Based on Improved YOLOX and UNETR++. Sensors 2025, 25, 3417. https://doi.org/10.3390/s25113417
Sun W, Liu X, Lei Z. Research on Tunnel Crack Identification Localization and Segmentation Method Based on Improved YOLOX and UNETR++. Sensors. 2025; 25(11):3417. https://doi.org/10.3390/s25113417
Chicago/Turabian StyleSun, Wei, Xiaohu Liu, and Zhiyong Lei. 2025. "Research on Tunnel Crack Identification Localization and Segmentation Method Based on Improved YOLOX and UNETR++" Sensors 25, no. 11: 3417. https://doi.org/10.3390/s25113417
APA StyleSun, W., Liu, X., & Lei, Z. (2025). Research on Tunnel Crack Identification Localization and Segmentation Method Based on Improved YOLOX and UNETR++. Sensors, 25(11), 3417. https://doi.org/10.3390/s25113417