1. Introduction
The quality of power grid image samples is crucial for the success of AI solutions within the power sector. In this field, images are widely used for the identification [
1], detection [
2], analysis, and monitoring of power grid equipment and systems [
3]. However, these images are often affected by quality issues such as noise, blurriness, and underexposure or overexposure. Image quality assessment (IQA) methods aim to assess the quality of images based on subjective human perception. According to whether an original reference image is required or not, IQA is usually categorized into full-reference IQA [
4], reduced-reference IQA [
5], and blind IQA [
6]. The scope of the FR-IQA and RR-IQA methods is limited because obtaining the original reference images is challenging in real-world applications. In contrast, BIQA methods do not require other images for reference and thus have greater application potential, but also face higher technical challenges.
Currently, BIQA methods are classified into convolutional neural network (CNN)-based methods [
7,
8] and Vision Transformer (ViT)-based methods [
9]. HyperIQA [
8] introduces a module that focuses on local distortions to capture local features, while a hyper-network is utilized to generate the parameters for the network. DEIQT [
10] uses the Transformer architecture in the encoder-decoder structure and feeds CLS tokens [
9] into the decoder, and finally outputs image quality scores. LoDa [
11] combines the advantages of CNN and Transformer by embedding local distortion features extracted by CNN into a pretrained ViT model and predicting image quality scores by CLS tokens.
As illustrated in
Figure 1, power grid images often experience significant distortions such as noise, overexposure, or underexposure. Previous methods [
8,
10,
11] have generally overlooked these specific characteristics, resulting in a decrease in quality prediction accuracy for these images. Noise typically corresponds to high-frequency features, while exposure levels are related to image brightness. We argue that integrating these features into image quality assessment models can enhance prediction accuracy. Meanwhile, low-frequency features, which contain semantic information and various local distortion characteristics, are also essential for predicting the image quality. In addition, CNNs are effective at extracting local texture features, while ViTs can integrate global features of the image. Combining the strengths of both is crucial for improving image quality predictions in power grid applications.
Finally, a multi-dimension distortion feature network (MDFN) is proposed based on CNN and Transformer, which leverages low-frequency features, high-frequency features, noise, and brightness information to assess the quality. Specifically, we design a dual-branch feature extractor, where CNN extracts multi-scale local distortion features, while ViT captures global image features, with extracted distortion features from CNN additionally introduced at each layer. As shown in
Figure 2, previous methods typically do not separate low-frequency and high-frequency features when extracting distortion features. We argue that more detailed distortion features can be obtained by processing low-frequency and high-frequency features separately, since high frequencies are typically associated with edges and details, while low frequencies are generally related to the semantic features. Therefore, we propose the frequency selection module (FSM) to extract low-frequency and high-frequency features, and update these representations in the spectral domain to achieve feature fusion in the spatial domain. Specifically, it first converts the features into the spectral domain using an FFT and passes them through a filter to get the frequency features, and then combines the real and imaginary components of the representations along the channel dimension to obtain the spectral domain representations. Then, the features are calculated with convolutional layers to realize the update of the frequency features. This can be regarded as a global fusion of the features because a change in the value within the spectral domain will influence all values in the spatial field. Finally, the real and imaginary parts are separated and the features are converted back to the spatial field to obtain multi-scale low-frequency and high-frequency distortion features. Then, inspired by LoDa [
11], we introduce a local distortion feature injection module that incorporates local distortion features into ViT. Finally, the noise and brightness features of the image are hand-designed and concatenated with the CLS token from ViT to perform the final quality prediction. As illustrated in
Figure 2, previous methods ignore the importance of the noise and brightness features and do not combine them into the prediction of image quality. Therefore, we design an effective method to obtain these features. Specifically, the brightness features can be viewed as an average of the gray values of the RGB channels of the image. For noise features, Gaussian blurring is first applied to the image, then the residuals of the image before and after blurring are calculated, and we finally obtain the standard deviation of the residuals. Considering the number of parameters, average pooling is finally performed on the hand-designed features.
The results of the experiments indicate that our approach surpasses current models on three public datasets, with particularly significant improvements observed on the power grid image dataset, which demonstrates the success of our method. The main contributions of the paper are as follows:
The frequency selection module (FSM) is proposed to split the distortion features into the low-frequency and high-frequency representations and obtain the more detailed distortion tokens.
Considering the traits of the power grid image, we suggest extracting the brightness and noise features and combining them with the CLS token for better quality prediction.
We propose the multi-dimension distortion feature network (MDFN) based on CNN and Transformer. It leverages low-frequency features, high-frequency features, noise, and brightness features and can achieve more accurate predictions.
3. Methodology
3.1. Overall Architecture
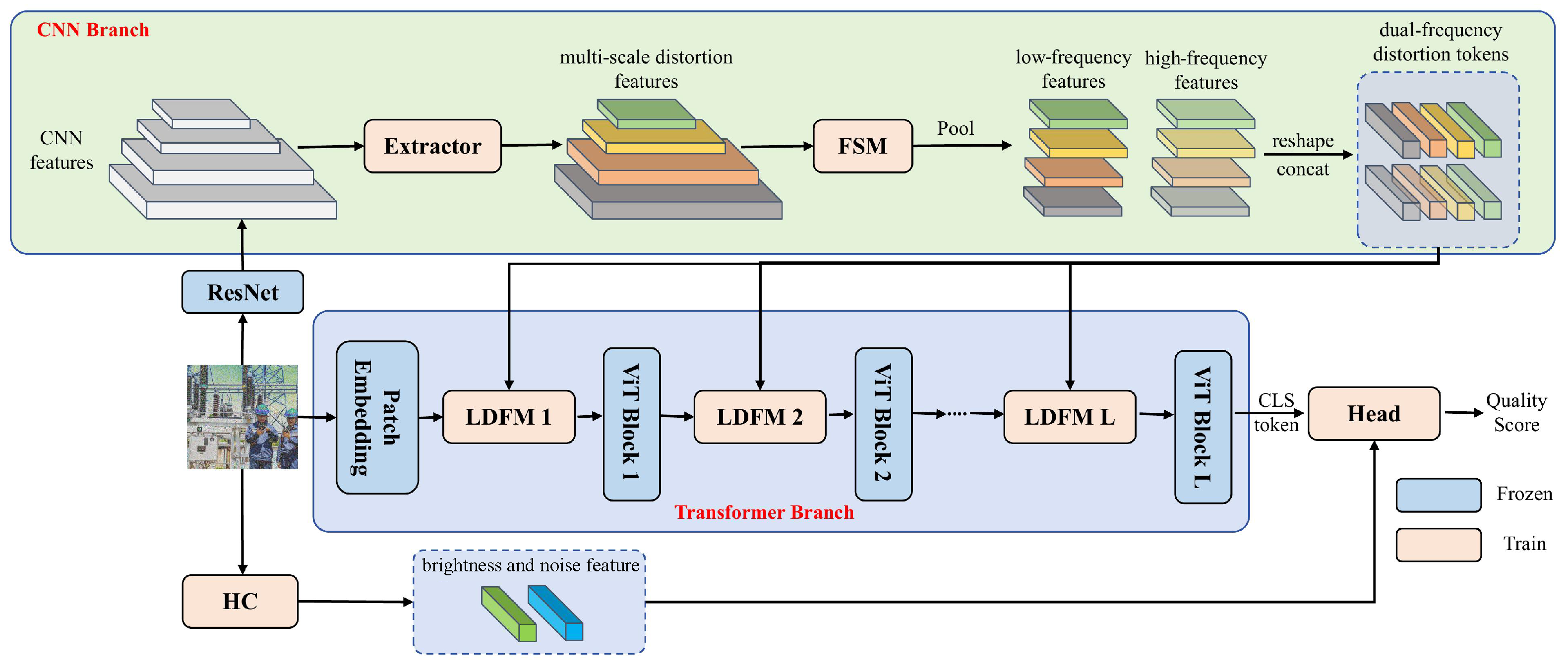
Our MDFN employs a dual-branch architecture, where the CNN branch is dedicated to capturing distortion features, while the Transformer branch utilizes a pretrained ViT to enhance the extraction of quality-related information. As shown in
Figure 3, for an image
, the CNN branch firstly applies ResNet50 to get image features of different sizes. These features are subsequently processed through an
to obtain multi-scale distortion features
, where
C represents the dimension of the channel, and
H and
W indicate the height and width. We believe that separating the low-frequency and high-frequency of these features can allow for better capture of detailed distortion information. Therefore, a feature selection module (FSM) is proposed to extract both components. Simultaneously, a pooling layer is employed for downsampling, resulting in low-frequency features
and high-frequency features
. We then apply a reshape operation
to process the features, and then concatenate them along the last dimension to form the final dual-domain distortion tokens
, where
.
In the Transformer branch, we freeze the weights and insert a local distortion fusion module between each layer to integrate the distortion tokens extracted by the CNN branch, which helps the pretrained ViT network capture richer distortion features and obtain more accurate quality scores. To address the specific characteristics of the power grid images, we design brightness and noise features, which are concatenated with the CLS token output by the ViT and then passed into a regression layer to predict the quality score.
Note that only the extractor, local distortion fusion module, feature selection module, and regression head are trainable, while the parameters of the pretrained ViT and CNN remain frozen.
3.2. Frequency Selection Module
Previous studies [
26,
35] on the spectrum domain and deep learning have indicated that high-frequency components correspond to areas with rapid pixel changes, such as edges, textures, and noise, while low-frequency components capture broader semantic details. Traditional image quality assessment methods have rarely extracted distortion features from the perspective of frequency. In fact, processing low-frequency and high-frequency components separately can yield richer distortion features. Additionally, compared to high-quality images, low-quality images often exhibit different frequency distributions. For example, images with significant noise tend to have more high-frequency components. Extracting these frequency features for image quality assessment can improve prediction accuracy. However, it is insufficient to extract only low-frequency or high-frequency features. Integrating these features with the overall image features can achieve comprehensive feature fusion. According to Fourier theory, altering a single frequency value affects the entire data globally. This principle motivates the use of non-local receptive fields for design operations. Therefore, processing the features from the frequency domain can enable global feature fusion in the spatial domain.
Specifically, the frequency selection module (FSM) is proposed, which separates the features into low- and high-frequency components and updates them individually in the frequency domain, allowing for the extraction of finer distortion details. As shown in
Figure 4, the distortion features
F are first converted into the frequency domain through a 2D FFT. Then, a frequency filter (e.g., low-pass or high-pass) is applied to obtain the filtered features
, which emphasizes either low or high frequencies. The formula is as follows:
where
denotes the filter,
is the frequency domain feature.
Since frequency features typically consist of real and imaginary parts, both of which are crucial for feature learning, we separate these two components and concatenate them on the channel dimension to form the concatenated features
. Next, these concatenated features are passed through a convolutional layer, which includes a
convolution and an activation function, to update the frequency features. The updated features
are then split along the channel dimension and converted back to frequency components. Afterwards, we perform a 2D-IFFT to transform the features
to the spatial domain. Finally, the transformed features
are combined with the initial distortion representations to yield the updated distortion features
. The formula is as follows:
3.3. Distortion Extractor
The features extracted by CNNs may not necessarily align with the distortion features required for the quality assessment of images. To address this, we design a distortion extractor to further capture distortion-specific features and adjust their channel dimensions for consistent processing. Moreover, relying solely on the features from the last layer is insufficient, as they primarily represent the overall image content and lack detailed information. To obtain richer distortion features, we utilize multi-scale features for extraction.
Specifically, as illustrated in
Figure 5, we employ four different network branches to extract degradation features at each scale. Feature
is processed sequentially through a
convolution, a GELU activation function [
36], and a
convolution to produce the distortion features. The formula is as follows:
where
denotes the output feature. Next, the obtained distortion features are input into the frequency selection module.
3.4. Hand-Crafted Features and IQA Regression
In image processing and computer vision, brightness and noise are two key low-level features that directly affect image visibility and stability. As power grid images are often noisy and exhibit significant brightness features, we design a method for extracting brightness and noise features, which are combined with the CLS token output from the ViT model, allowing for the effective utilization of fundamental image information in image quality assessment.
Brightness features reflect the overall illumination intensity of an image and can effectively describe both local and global light distribution. For each image
, the brightness features are computed by taking the average of the RGB channels to minimize the impact of color bias on brightness estimation. The calculation process for the brightness features is as follows:
where
is the brightness representation of the single channel and
denotes the
c-th channel of the image.
Noise features reflect the distribution of random interference information in the image and are important indicators of image quality. Gaussian blur is a low-pass filter that removes high-frequency representations while preserving the low-frequency representations of an image. Therefore, an image after Gaussian blur can be considered the low-frequency part of the original image. Since the original image contains all frequencies, a residual image with the high-frequency components can be obtained by subtracting the Gaussian blurred image from the original image. Specifically, a Gaussian blur operation is employed on the original image to obtain a blurred image
, with a
blur kernel to smooth the details of the image. The equation is as follows:
We then calculate the residual between the blurred image and the original image and compute the root mean square value of the residual in local regions to estimate the noise intensity. The formula is as follows:
where
is the noise representation of the single channel.
To reduce computational complexity, the brightness and noise features are downsampled to a resolution of
with adaptive average pooling, and are concatenated across the channel dimension to yield the hand-crafted features
. The formula is as follows:
With the output CLS token
and the hand-crafted features
, we first flatten the features into a one-dimensional vector and concatenate them to obtain the features
for quality prediction, where
. Finally, the features are fed into a single-layer regressor head to obtain the quality score. We use the PLCC-induced loss for training. Given
m images on the training batch and the predicted quality scores
and corresponding label
, the loss is calculated as:
3.5. Local Distortion Fusion Module
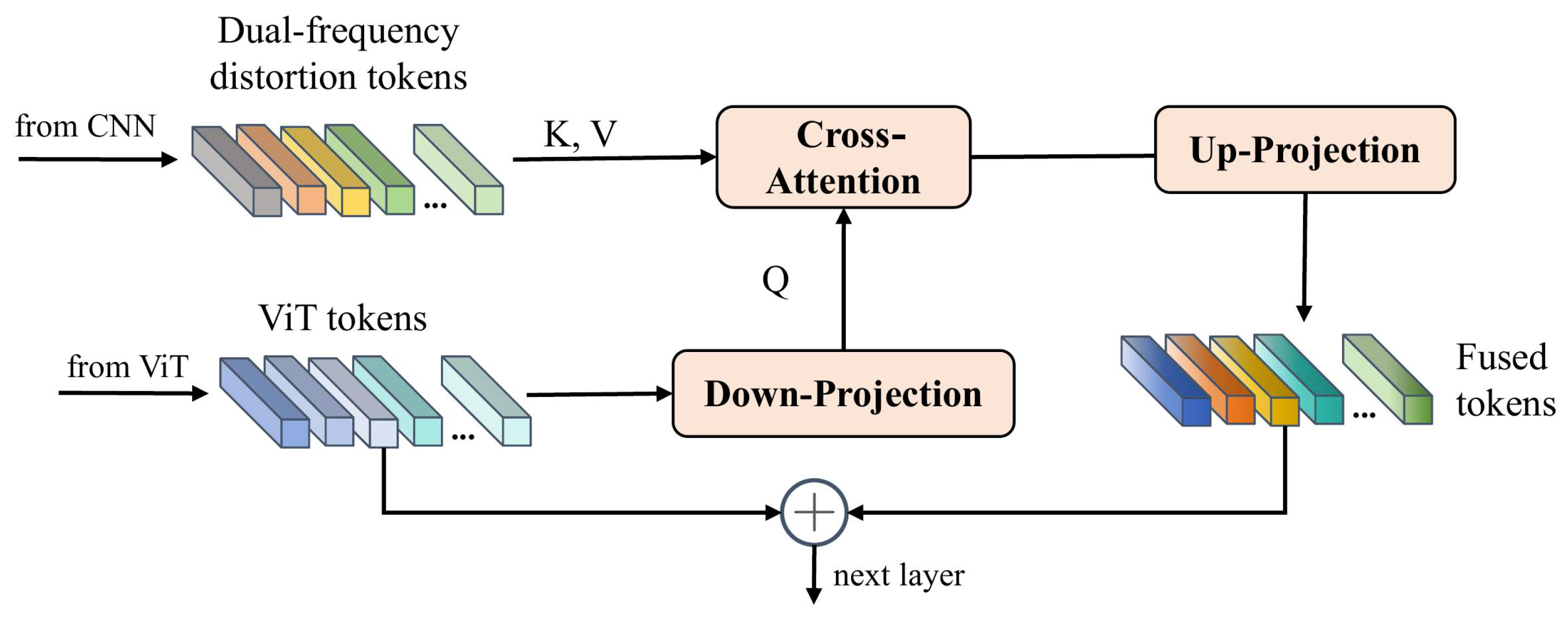
A straightforward approach to fusing dual-frequency distortion tokens into a pretrained ViT model involves simply adding the features to the tokens. However, image tokens of ViT correspond to
patches of the original image, which may not align with the scale of the dual-frequency distortion features. To address this misalignment, inspired by LoDa [
11], we introduce the cross-attention mechanism, which enables the ViT image tokens to query similar features from the dual-frequency distortion features. The queried features are then effectively integrated with the image tokens, which ensures the coherent and effective incorporation of distortion information.
Considering that the channel dimension of ViT features is 768, while the channel dimension of the dual-domain token is 256, we need to ensure channel consistency. To achieve this, we first process the channel dimensions. As shown in
Figure 6, the input tokens from the ViT are passed through a down-projection layer to map channel dimensions to match that of the dual-domain distortion tokens. The formula is as follows:
where
is the down-projection layer, which is a trainable MLP layer and performs the projection of ViT token
into
.
Then, the cross-attention network is applied for the fusion between the ViT tokens and the dual-frequency distortion tokens. Specifically, the processed ViT tokens
are considered as query
Q, and the dual-frequency distortion tokens are viewed as key
K and value
V in the multi-head cross-attention (MHCA). The equation is as follows:
where the softmax function transforms a vector
into a probability distribution, and is given by the following formula:
where
is the
i-th value of the vector
,
n is the dimension of
, and
is the exponential of the input value. After that, the fused tokens
are added with the initial ViT tokens
to keep the initial features, which are expressed as follows:
Finally, an up-projection layer is used to transform the dimension of the fused features back to a format compatible with the ViT model. Note that the up-projection layer is essentially also an MLP.
5. Conclusions
We propose a multi-dimension distortion feature network (MDFN) combining CNN and Transformer architectures to enhance image quality prediction by leveraging low- and high-frequency, noise, and brightness features. Two branches for feature extraction are used to obtain the local distortion representations and global image representations, respectively. The CNN branch is responsible for extracting the multi-scale distortion representation and the Transformer branch combines the features from CNN to achieve the fusion of the local and global features. In the CNN branch, the frequency selection module is proposed for obtaining more detailed distortion tokens, which helps the network obtain more accurate predictions. In addition, whereas previous methods solely use the CLS token for the prediction, we design an effective method to extract the noise and brightness features and combine them with the CLS token to obtain the prediction score. According to the results of our experiments, the performance of MDFN in image quality assessment is effectively improved, surpassing previous methods and the baseline method. Our novel and effective ideas, namely, that splitting the features into low- and high-frequency representations is more beneficial for predicting the quality score and that combining the noise and brightness representations can improve performance, are validated by these results.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}