
HDF-Net: Hierarchical Dual-Branch Feature Extraction Fusion Network for Infrared and Visible Image Fusion


Abstract
1. Introduction
- (1)
- We propose a hierarchical dual-branch fusion architecture that demonstrates exceptional performance in image fusion. This architecture effectively integrates infrared and visible images by separating them into low-frequency, shared features and high-frequency, modality-specific details, ensuring optimal fusion quality.
- (2)
- We design a novel PCT module to extract robust low-frequency features, strengthening the network’s capability to obtain background and large-scale structural data. Additionally, we employ an INN module to retain modality-specific high-frequency details with high fidelity.
- (3)
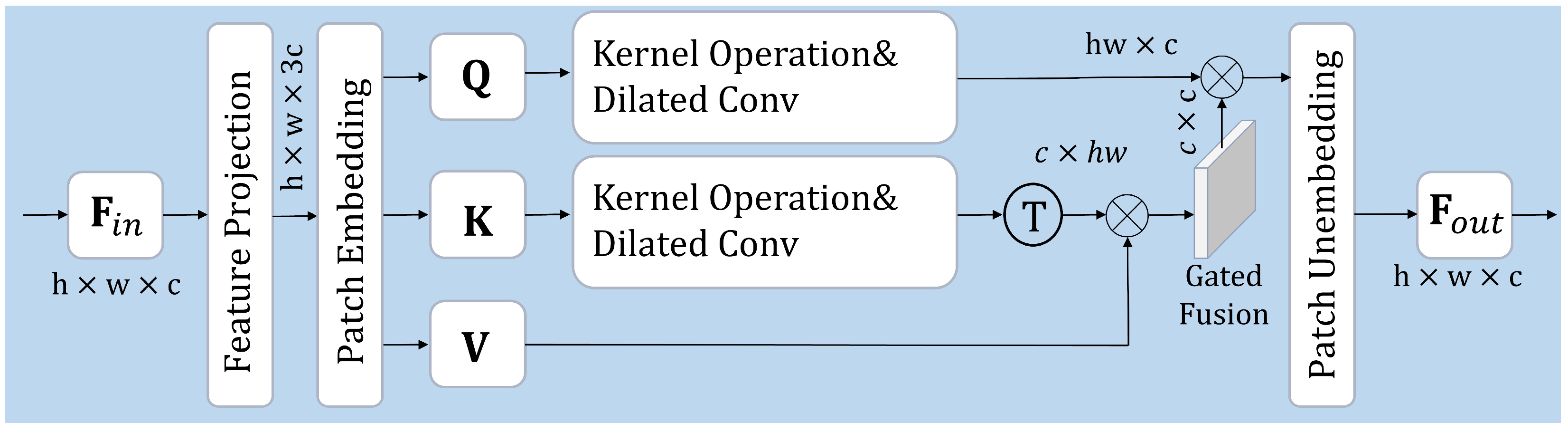
- We design a hierarchical feature refinement (HFR) module to refine fused features further. In contrast to conventional linear refinement, HFR incorporates kernel operations (KO) and dilated convolutions (DC) to enhance feature expression and facilitate robust multiscale fusion. By integrating KO and DC, representation learning becomes more flexible and effective across both frequency branches, thus improving the overall quality and stability of the fusion.
- (4)
2. Related Work
2.1. CNN- and GAN-Based Methods for IVIF
2.2. Transformer-Driven Approaches and Limitations
3. Methods
3.1. Overview
3.2. Encoder Architecture
3.2.1. Unified Feature Encoder
3.2.2. Core Feature Encoder
3.2.3. Refined Feature Encoder
3.2.4. Fusion Layer
3.2.5. HFR Module
3.3. Decoder
3.4. Loss Function
- (1)
- Refined high-level features (after HFR) remain consistent with their low-level counterparts (before HFR).
- (2)
- It prevents oversmoothing or semantic deviation during refinement.
4. Results and Analysis
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implement Details
4.1.3. Metrics
4.2. Comparison Results
4.2.1. Results of the MSRS Dataset
4.2.2. Results of the TNO Dataset
4.2.3. Results of the RoadScene Dataset
4.2.4. Results of the M3FD Dataset
4.3. Ablation Study
4.4. Medical Image Fusion
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B

References
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and Visible Image Fusion Technology and Application: A Review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef] [PubMed]
- Neama, R.M.; Al-asadi, T.A. The Deep Learning Methods for Fusion Infrared and Visible Images: A Survey. Rev. D’intelligence Artif. 2024, 38, 575–585. [Google Scholar] [CrossRef]
- Zhang, X.; Demiris, Y. Visible, and Infrared Image Fusion Using Deep Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10535–10554. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, W.; Wang, X. A Fusion Algorithm for Infrared and Visible Images Based on the Dual-Branch of CNN and Transformer. Proc. SPIE 2023, 12916, 129160S. [Google Scholar] [CrossRef]
- Yang, X.; Huo, H.; Wang, R.; Li, C.; Liu, X.; Li, J. DGLT-Fusion: A Decoupled Global–Local Infrared and Visible Image Fusion Transformer. Infrared Phys. Technol. 2022, 125, 104522. [Google Scholar] [CrossRef]
- Rao, D.; Wu, X.; Xu, T. TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network. arXiv 2022, arXiv:2201.10147. [Google Scholar] [CrossRef]
- Chen, J.; Ding, J.; Yu, Y.; Gong, W. THFuse: An Infrared and Visible Image Fusion Network Using Transformer and Hybrid Feature Extractor. Neurocomputing 2023, 527, 71–82. [Google Scholar] [CrossRef]
- Vinoth, K.; Sasikumar, P. Multi-Sensor Fusion and Segmentation for Autonomous Vehicle Multi-Object Tracking Using Deep Q Networks. Sci. Rep. 2024, 14, 31130. [Google Scholar] [CrossRef]
- Xu, D.; Wang, Y.; Xu, S.; Zhu, K.; Zhang, N.; Zhang, X. Infrared and Visible Image Fusion with a Generative Adversarial Network and a Residual Network. Appl. Sci. 2020, 10, 554. [Google Scholar] [CrossRef]
- Zhang, C.; Li, X.; Xu, Y.; Wang, J.; Chen, R. CTDPGAN: Infrared and Visible Image Fusion Using CNN-Transformer Dual-Process-Based Generative Adversarial Network. Proc. Chin. Control. Conf. 2023, 42, 8044–8051. [Google Scholar] [CrossRef]
- Li, L.; Shi, Y.; Lv, M.; Jia, Z.; Liu, M.; Zhao, X.; Zhang, X.; Ma, H. Infrared and Visible Image Fusion via Sparse Representation and Guided Filtering in Laplacian Pyramid Domain. Remote Sens. 2024, 16, 3804. [Google Scholar] [CrossRef]
- Du, K.; Fang, L.; Chen, J.; Chen, D.; Lai, H. CTFusion: CNN-Transformer-Based Self-Supervised Learning for Infrared and Visible Image Fusion. Math. Biosci. Eng. 2024, 21, 6710–6730. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, X.; Zan, G.; Yang, M. FCMDNet: A Feature Correlation-Based Multi-Scale Dual-Branch Network for Infrared and Visible Image Fusion. Proc. Int. Conf. Robot. Comput. Vis. 2024, 6, 139–143. [Google Scholar] [CrossRef]
- Yin, H.; Xiao, J.; Chen, H. CSPA-GAN: A Cross-Scale Pyramid Attention GAN for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2023, 72, 5027011. [Google Scholar] [CrossRef]
- Lu, G.; Fang, Z.; Tian, J.; Huang, H.; Xu, Y.; Han, Z.; Kang, Y.; Feng, C.; Zhao, Z. GAN-HA: A Generative Adversarial Network with a Novel Heterogeneous Dual-Discriminator Network and a New Attention-Based Fusion Strategy for Infrared and Visible Image Fusion. Infrared Phys. Technol. 2024, 132, 105548. [Google Scholar] [CrossRef]
- Yang, X.; Huo, H.; Li, C.; Liu, X.; Wang, W.; Wang, C. Semantic Perceptive Infrared and Visible Image Fusion Transformer. Pattern Recognit. 2024, 149, 110223. [Google Scholar] [CrossRef]
- Gao, X.; Liu, S. BCMFIFuse: A Bilateral Cross-Modal Feature Interaction-Based Network for Infrared and Visible Image Fusion. Remote Sens. 2024, 16, 3136. [Google Scholar] [CrossRef]
- Li, X.; He, H.; Shi, J. HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion. Electronics 2024, 13, 3470. [Google Scholar] [CrossRef]
- Luo, Y.; Luo, Z. Infrared and Visible Image Fusion: Methods, Datasets, Applications, and Prospects. Appl. Sci. 2023, 13, 10891. [Google Scholar] [CrossRef]
- Xing, M.; Liu, G.; Tang, H.; Qian, Y.; Zhang, J. CFNet: An Infrared and Visible Image Compression Fusion Network. Pattern Recognit. 2024, 156, 110774. [Google Scholar] [CrossRef]
- Park, S.; Vien, A.G.; Lee, C. Cross-Modal Transformers for Infrared and Visible Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 770–785. [Google Scholar] [CrossRef]
- Li, J.; Liu, L.; Song, H.; Huang, Y.; Jiang, J.; Yang, J. DCTNet: A Heterogeneous Dual-Branch Multi-Cascade Network for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2023, 72, 5030914. [Google Scholar] [CrossRef]
- Xu, X.; Shen, Y.; Han, S. Dense-FG: A Fusion GAN Model by Using Densely Connected Blocks to Fuse Infrared and Visible Images. Appl. Sci. 2023, 13, 4684. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.J. A Dual-Branch Network for Infrared and Visible Image Fusion. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2021; pp. 10675–10680. [Google Scholar] [CrossRef]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection. arXiv 2024, arXiv:2412.16986. [Google Scholar] [CrossRef]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density Estimation Using Real NVP. arXiv 2016, arXiv:1605.08803. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A Progressive Infrared and Visible Image Fusion Network Based on Illumination Aware. Inf. Fusion 2022, 83–84, 79–92. [Google Scholar] [CrossRef]
- Toet, A. The TNO Multiband Image Data Collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A Unified Densely Connected Network for Image Fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12484–12491. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware Dual Adversarial Learning and a Multi-Scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Sun, C.; Zhang, C.; Xiong, N. Infrared and Visible Image Fusion Techniques Based on Deep Learning: A Review. Electronics 2020, 9, 2162. [Google Scholar] [CrossRef]
- Patel, A.; Chaudhary, J. A Review on Infrared and Visible Image Fusion Techniques. In Intelligent Communication Technologies and Virtual Mobile Networks: ICICV 2019; Springer: Cham, Switzerland, 2020; pp. 127–144. [Google Scholar] [CrossRef]
- Duan, J.; Xiong, J.; Li, Y.; Ding, W. Deep Learning Based Multimodal Biomedical Data Fusion: An Overview and Comparative Review. Inf. Fusion 2024, 112, 102536. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 4796–4810. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A General Image Fusion Framework Based on Convolutional Neural Networks. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network Based on Proportional Maintenance of Gradient and Intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar] [CrossRef]
- Tang, L.; Deng, Y.; Ma, Y.; Huang, J.; Ma, J. SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness. IEEE/CAA J. Autom. Sin. 2022, 9, 2121–2137. [Google Scholar] [CrossRef]
- Xu, J.; He, X. DAF-Net: A Dual-Branch Feature Decomposition Fusion Network with Domain Adaptive for Infrared and Visible Image Fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39. [Google Scholar] [CrossRef]
- Zhang, X. Deep Learning-Based Multi-Focus Image Fusion: A Survey and a Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4819–4838. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A Generative Adversarial Network for Infrared and Visible Image Fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A Generative Adversarial Network with Multiclassification Constraints for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5005014. [Google Scholar] [CrossRef]
- Rao, Y.; Liu, J.; Zhang, L. AttentionFGAN: Multi-Scale Attention Mechanism for Infrared and Visible Image Fusion. IEEE Trans. Multimed. 2024, 23, 1383–1396. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, H.; Zhang, Z. TarDAL: Target-Aware Dual Adversarial Learning Network for Image Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and Visible Image Fusion Methods and Applications: A Survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Ali, A.M.; Benjdira, B.; Koubaa, A.; El-Shafai, W.; Khan, Z.; Boulila, W. Vision Transformers in Image Restoration: A Survey. Sensors 2023, 23, 2385. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images. IEEE Trans. Instrum. Meas. 2022, 71, 5016412. [Google Scholar] [CrossRef]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; luo, Z.; Fan, X.; Luo, Z; Fan, X. CoCoNet: Coupled Contrastive Learning Network with Multi-Level Feature Ensemble for Multi-Modality Image Fusion. Int. J. Comput. Vis. 2024, 132, 1748–1775. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion. arXiv 2022, arXiv:2211.14461. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, C.; Xiao, J.; Tao, W.; Dai, T. PDFusion: A Dual-Branch Infrared and Visible Image Fusion Network Using Progressive Feature Transfer. J. Vis. Commun. Image Represent. 2024, 92, 104190. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Xu, H.; Ma, Y.; Guo, X.; Huang, J.; Fan, F.; Zhang, J.; Xu, Y. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image Fusion in the Loop of High-Level Vision Tasks: A Semantic-Aware Real-Time Infrared and Visible Image Fusion Network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and Visible Image Fusion via Dual Attention Transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Zhao, W.; Xie, S.; Zhao, F.; He, Y.; Lu, H. Metafusion: Infrared and Visible Image Fusion via Meta-Feature Embedding from Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13955–13965. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhu, Y.; Zhang, J.; Xu, S.; Zhang, Y.; Zhang, K.; Meng, D.; Timofte, R.; Van Gool, L. DDFM: Denoising Diffusion Model for Multi-Modality Image Fusion. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; IEEE: New York, NY, USA, 2023; pp. 8048–8059. [Google Scholar] [CrossRef]
- Li, J.; Yu, H.; Chen, J.; Ding, X.; Wang, J.; Liu, J.; Ma, H. A2RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion. arXiv 2024, arXiv:2412.09954. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Zhang, K.; Xu, S.; Chen, D.; Timofte, R.; Van Gool, L. Equivariant Multi-Modality Image Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2024; pp. 25912–25921. [Google Scholar] [CrossRef]
- Qian, Y.; Liu, G.; Tang, H.; Xing, M.; Chang, R. BTSFusion: Fusion of Infrared and Visible Image via a Mechanism of Balancing Texture and Salience. Opt. Lasers Eng. 2024, 173, 107925. [Google Scholar] [CrossRef]
- Liu, X.; Huo, H.; Li, J.; Pang, S.; Zheng, B. A Semantic-driven Coupled Network for Infrared and Visible Image Fusion. Inf. Fusion 2024, 108, 102352. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset: MSRS Fusion Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | EN | SD | AG | SF | SCD | MI | SSIM | |
| TarDAL | 6.35 | 35.48 | 3.13 | 9.91 | 1.49 | 1.82 | 0.42 | 0.71 |
| SwinFusion | 6.62 | 43.00 | 3.57 | 11.09 | 1.69 | 3.14 | 0.65 | 0.96 |
| U2Fusion | 6.04 | 29.28 | 2.56 | 9.19 | 1.01 | 2.04 | 0.47 | 0.77 |
| SeAFusion | 6.65 | 41.84 | 3.70 | 11.11 | 1.69 | 2.79 | 0.68 | 0.99 |
| DATFuse | 6.48 | 36.48 | 3.57 | 10.93 | 1.41 | 2.70 | 0.64 | 0.90 |
| MetaFusion | 6.37 | 39.43 | 3.56 | 12.17 | 1.49 | 1.16 | 0.48 | 0.80 |
| DDFM | 6.17 | 28.91 | 2.50 | 7.37 | 1.45 | 1.88 | 0.46 | 0.89 |
| CDDFuse | 6.70 | 43.37 | 3.75 | 11.56 | 1.62 | 3.47 | 0.69 | 1.00 |
| A2RNet | 6.39 | 37.78 | 2.75 | 8.67 | 1.45 | 2.21 | 0.43 | 0.67 |
| EMMA | 6.62 | 44.59 | 3.79 | 11.56 | 1.63 | 2.94 | 0.64 | 0.96 |
| BTSFusion | 6.29 | 33.85 | 4.49 | 11.82 | 1.37 | 1.58 | 0.49 | 0.79 |
| SDCFusion | 6.71 | 42.66 | 3.96 | 11.83 | 1.73 | 2.67 | 0.71 | 0.96 |
| Ours | 6.75 | 46.01 | 4.30 | 12.67 | 1.74 | 3.24 | 0.67 | 1.03 |
| Dataset: TNO Fusion Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | EN | SD | AG | SF | SCD | MI | SSIM | |
| TarDAL | 6.83 | 41.17 | 4.38 | 12.40 | 1.51 | 1.90 | 0.41 | 0.95 |
| SwinFusion | 6.92 | 41.53 | 4.29 | 10.88 | 1.72 | 1.86 | 0.52 | 0.97 |
| U2Fusion | 7.03 | 38.09 | 4.13 | 8.79 | 0.98 | 1.45 | 0.44 | 0.94 |
| SeAFusion | 7.13 | 44.95 | 4.91 | 12.06 | 1.72 | 2.02 | 0.50 | 0.99 |
| DATFuse | 6.58 | 29.87 | 3.62 | 9.56 | 1.45 | 2.36 | 0.51 | 0.94 |
| MetaFusion | 7.11 | 48.36 | 4.86 | 12.10 | 1.73 | 1.16 | 0.31 | 0.77 |
| DDFM | 6.81 | 33.34 | 3.13 | 7.82 | 1.72 | 1.56 | 0.40 | 0.97 |
| CDDFuse | 7.14 | 46.00 | 4.80 | 13.19 | 1.76 | 2.21 | 0.54 | 1.03 |
| A2RNet | 7.12 | 46.09 | 3.48 | 8.93 | 1.68 | 1.78 | 0.33 | 0.75 |
| EMMA | 7.18 | 46.75 | 4.67 | 11.17 | 1.66 | 2.14 | 0.48 | 0.97 |
| BTSFusion | 6.82 | 34.67 | 5.78 | 14.01 | 1.62 | 1.26 | 0.42 | 0.94 |
| SDCFusion | 7.09 | 41.58 | 5.16 | 13.09 | 1.72 | 1.79 | 0.53 | 0.97 |
| Ours | 7.21 | 47.48 | 5.58 | 14.70 | 1.81 | 2.43 | 0.47 | 1.01 |
| Dataset: RoadScene Fusion Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | EN | SD | AG | SF | SCD | MI | SSIM | |
| TarDAL | 7.07 | 42.97 | 3.87 | 14.16 | 1.38 | 1.80 | 0.45 | 0.90 |
| SwinFusion | 7.01 | 45.10 | 3.54 | 11.65 | 1.73 | 1.86 | 0.50 | 0.99 |
| U2Fusion | 7.16 | 38.16 | 5.34 | 11.05 | 1.53 | 1.57 | 0.27 | 0.64 |
| SeAFusion | 7.31 | 50.99 | 4.91 | 15.49 | 1.72 | 2.31 | 0.50 | 0.94 |
| DATFuse | 6.67 | 32.16 | 3.24 | 10.95 | 1.28 | 2.63 | 0.52 | 0.92 |
| MetaFusion | 7.07 | 48.83 | 5.71 | 16.45 | 1.63 | 1.56 | 0.40 | 0.82 |
| DDFM | 6.98 | 36.67 | 3.05 | 9.59 | 1.72 | 2.01 | 0.44 | 0.88 |
| CDDFuse | 7.41 | 54.55 | 5.80 | 16.14 | 1.80 | 2.34 | 0.52 | 0.96 |
| A2RNet | 7.22 | 51.77 | 3.74 | 12.56 | 1.65 | 2.23 | 0.37 | 0.79 |
| EMMA | 7.36 | 54.17 | 5.83 | 14.68 | 1.72 | 2.32 | 0.47 | 0.89 |
| BTSFusion | 6.96 | 35.92 | 5.52 | 16.72 | 1.50 | 1.53 | 0.45 | 0.88 |
| SDCFusion | 7.25 | 45.18 | 5.14 | 16.62 | 1.72 | 1.92 | 0.54 | 0.90 |
| Ours | 7.46 | 55.56 | 6.86 | 17.60 | 1.86 | 2.07 | 0.46 | 1.00 |
| Dataset: M3FD Fusion Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | EN | SD | AG | SF | SCD | MI | SSIM | |
| TarDAL | 6.78 | 40.11 | 4.34 | 12.86 | 1.55 | 2.20 | 0.41 | 0.88 |
| SwinFusion | 6.81 | 36.01 | 4.74 | 14.24 | 1.57 | 2.15 | 0.60 | 0.99 |
| U2Fusion | 6.78 | 34.17 | 4.13 | 10.58 | 1.53 | 1.88 | 0.57 | 0.81 |
| SeAFusion | 6.86 | 35.19 | 4.90 | 14.46 | 1.58 | 2.53 | 0.59 | 0.95 |
| DATFuse | 6.41 | 26.08 | 3.48 | 10.67 | 1.30 | 2.88 | 0.48 | 0.92 |
| MetaFusion | 6.83 | 37.13 | 6.08 | 16.33 | 1.71 | 1.66 | 0.41 | 0.76 |
| DDFM | 6.69 | 30.11 | 3.20 | 9.37 | 1.69 | 2.00 | 0.45 | 0.85 |
| CDDFuse | 6.91 | 36.94 | 4.98 | 15.36 | 1.65 | 2.79 | 0.61 | 1.01 |
| A2RNet | 6.85 | 34.54 | 3.21 | 9.39 | 1.51 | 2.30 | 0.33 | 0.65 |
| EMMA | 6.95 | 38.38 | 5.43 | 15.69 | 1.51 | 2.41 | 0.59 | 0.90 |
| BTSFusion | 6.75 | 33.03 | 6.63 | 17.84 | 1.56 | 1.74 | 0.49 | 0.84 |
| SDCFusion | 6.94 | 36.10 | 5.45 | 16.21 | 1.66 | 2.23 | 0.67 | 0.89 |
| Ours | 7.09 | 43.09 | 6.32 | 16.93 | 1.84 | 2.62 | 0.70 | 1.03 |
| Model | EN | SD | AG | SF | SCD | MI | SSIM | |
|---|---|---|---|---|---|---|---|---|
| w/o PCT | 6.68 | 43.32 | 3.78 | 11.63 | 1.59 | 2.67 | 0.67 | 1.01 |
| w/o HRM | 6.71 | 45.18 | 3.53 | 11.87 | 1.57 | 2.86 | 0.57 | 0.81 |
| w/o PCT and HRM | 6.44 | 42.83 | 3.21 | 10.67 | 1.64 | 2.76 | 0.58 | 0.98 |
| Ours | 6.75 | 46.01 | 4.30 | 12.67 | 1.74 | 3.24 | 0.67 | 1.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Huang, M.; Zhu, Y.; Jiang, J.; Zhang, Y. HDF-Net: Hierarchical Dual-Branch Feature Extraction Fusion Network for Infrared and Visible Image Fusion. Sensors 2025, 25, 3411. https://doi.org/10.3390/s25113411
Zhu Y, Huang M, Zhu Y, Jiang J, Zhang Y. HDF-Net: Hierarchical Dual-Branch Feature Extraction Fusion Network for Infrared and Visible Image Fusion. Sensors. 2025; 25(11):3411. https://doi.org/10.3390/s25113411
Chicago/Turabian StyleZhu, Yanghang, Mingsheng Huang, Yaohua Zhu, Jingyu Jiang, and Yong Zhang. 2025. "HDF-Net: Hierarchical Dual-Branch Feature Extraction Fusion Network for Infrared and Visible Image Fusion" Sensors 25, no. 11: 3411. https://doi.org/10.3390/s25113411
APA StyleZhu, Y., Huang, M., Zhu, Y., Jiang, J., & Zhang, Y. (2025). HDF-Net: Hierarchical Dual-Branch Feature Extraction Fusion Network for Infrared and Visible Image Fusion. Sensors, 25(11), 3411. https://doi.org/10.3390/s25113411