


Cross-Modal Object Detection Based on Content-Guided Feature Fusion and Self-Calibration

Abstract
1. Introduction
- (1)
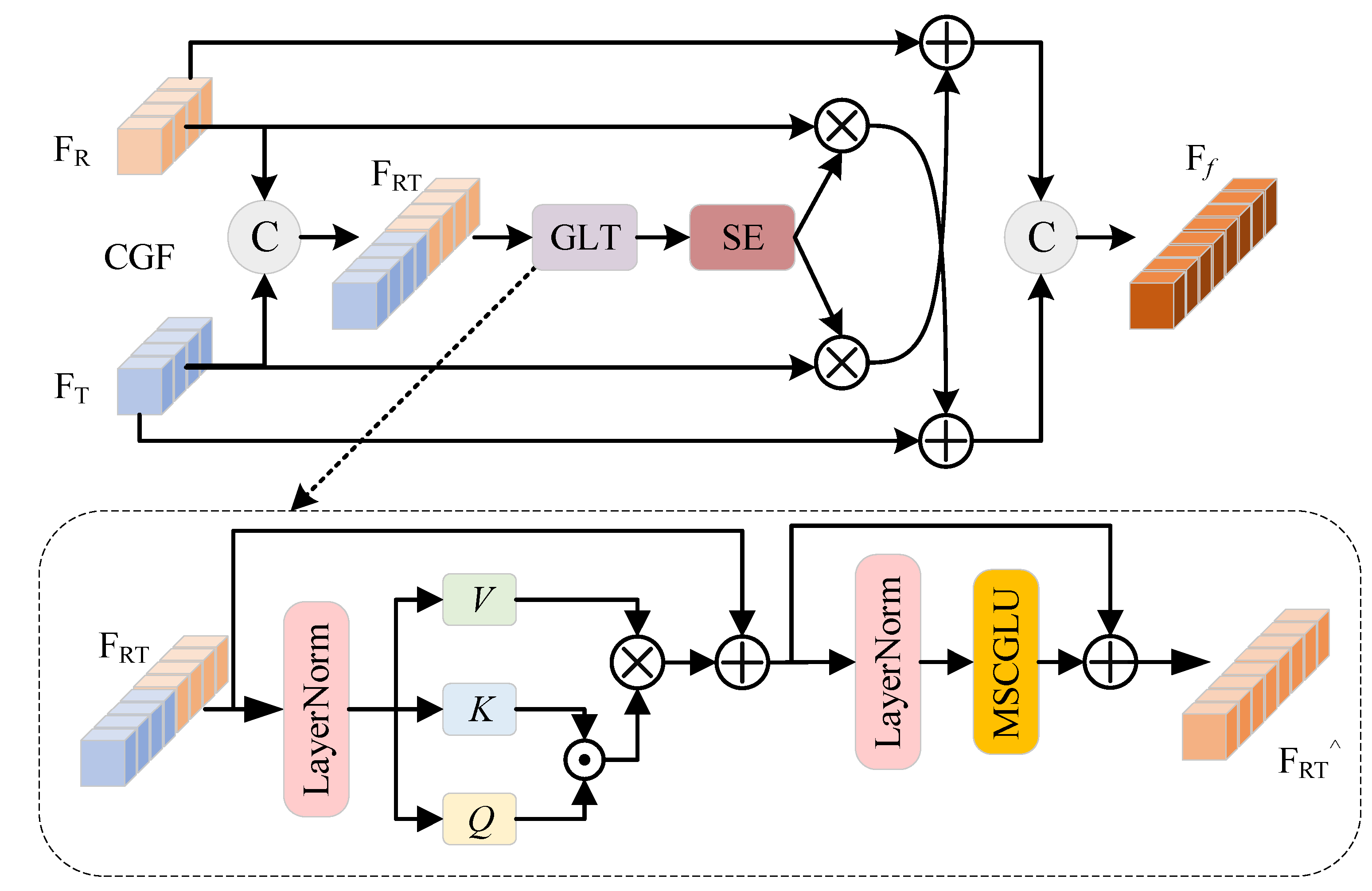
- Content-Guided Fusion Module (CGF): By embedding convolutional modules within the transformer architecture, CGF utilizes multi-head attention to capture global features while leveraging convolutional operations for feature processing. This enables joint modeling of global receptive fields and local detail features, effectively mitigating the traditional transformer’s shortcomings in local feature representation.
- (2)
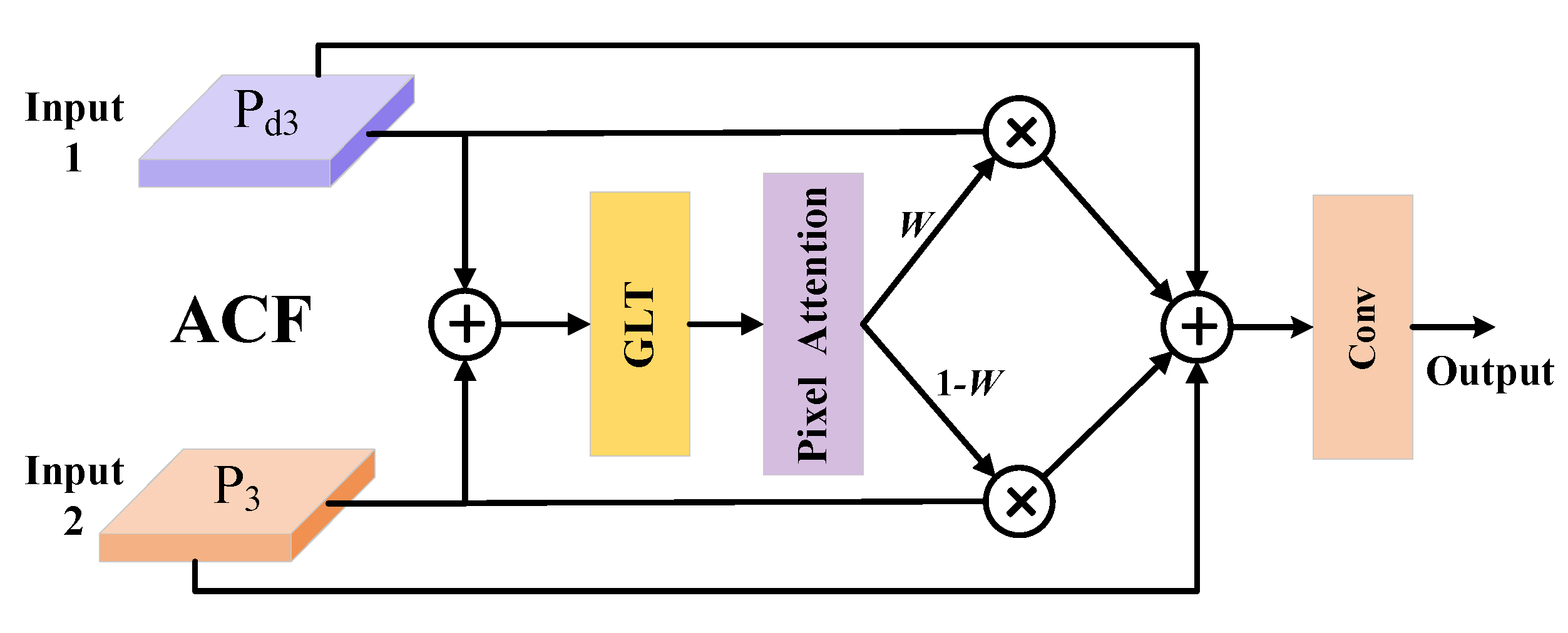
- Adaptive Calibration Fusion Module (ACF): By fusing shallow and deep features, ACF adaptively optimizes feature representation, significantly alleviating feature degradation caused by deep convolutional processes, particularly the loss of detailed information.
- (1)
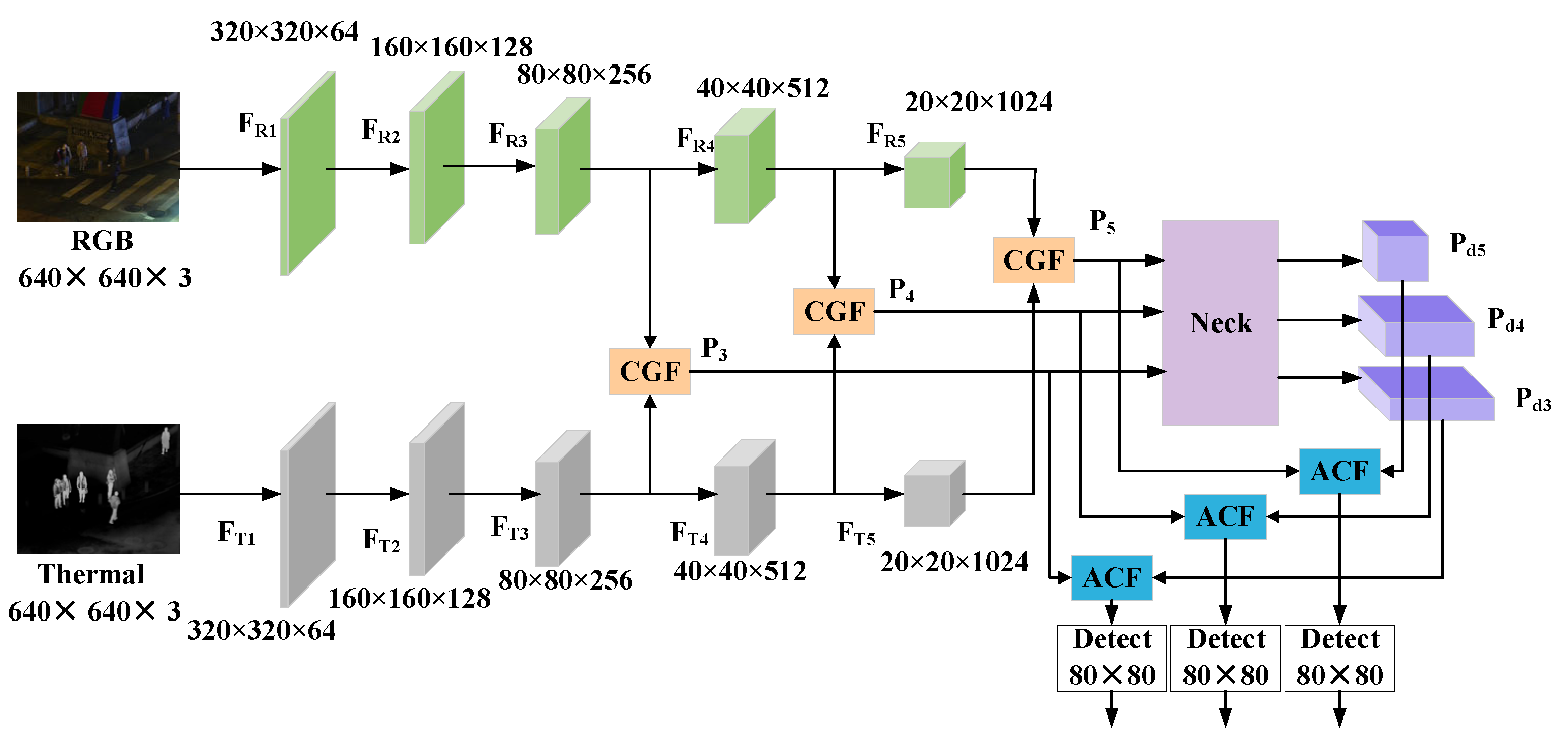
- The backbone was improved by adding a parallel network. The proposed CGF was embedded to enhance the model’s capability to represent both global and local features. Additionally, it facilitated the interaction between different modal features.
- (2)
- At the end of the neck, the ACF was incorporated. Shallow-layer information was utilized to calibrate deep feature representations, thereby improving the model’s detection performance in complex environments.
- (3)
- The proposed method was validated on multiple datasets. Experimental results demonstrated that it significantly outperformed existing state-of-the-art methods in terms of detection accuracy and robustness.
2. Related Work
3. Attention Mechanism
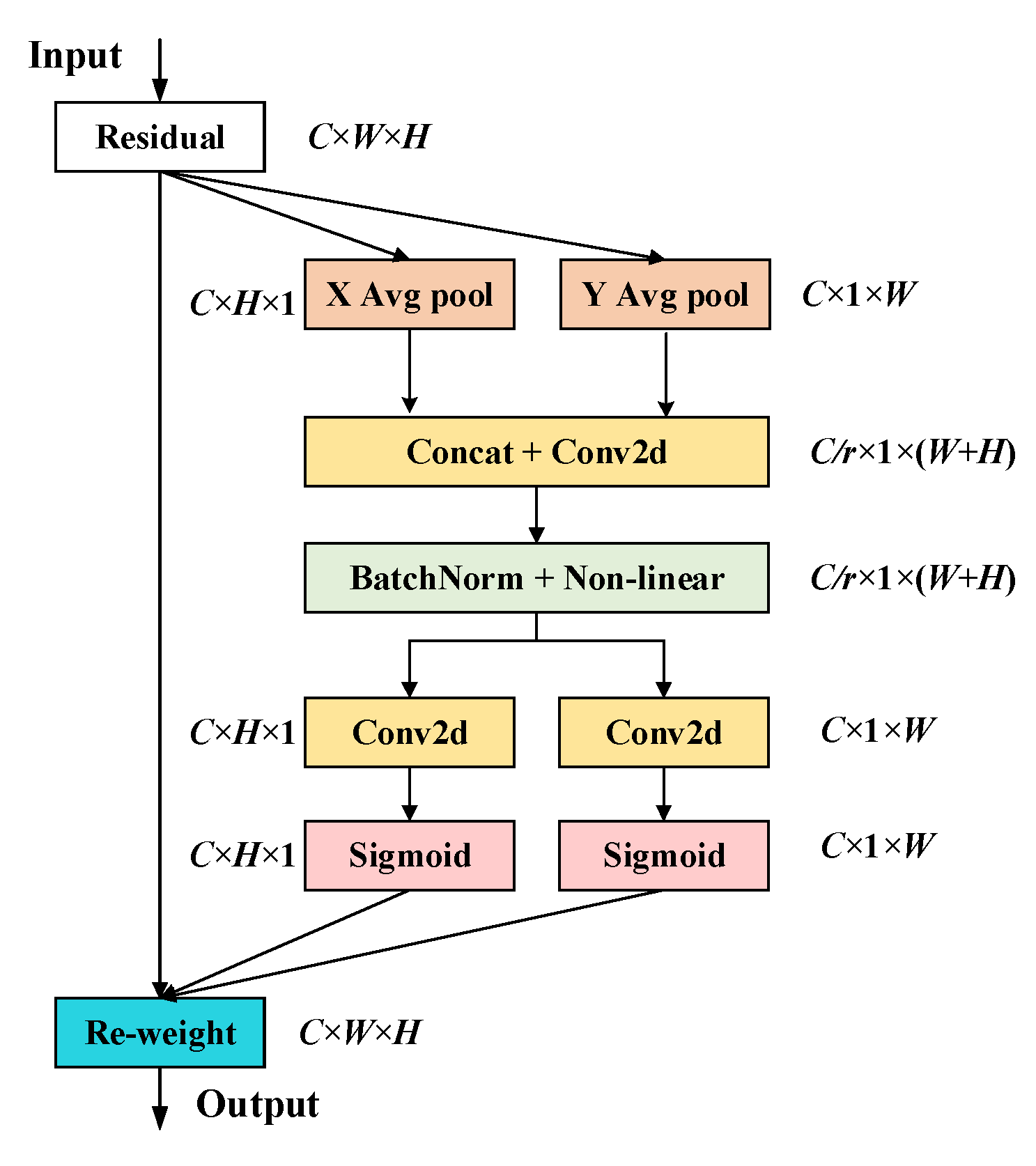
3.1. Coordinate Attention
3.2. Squeeze-And-Excitation Network
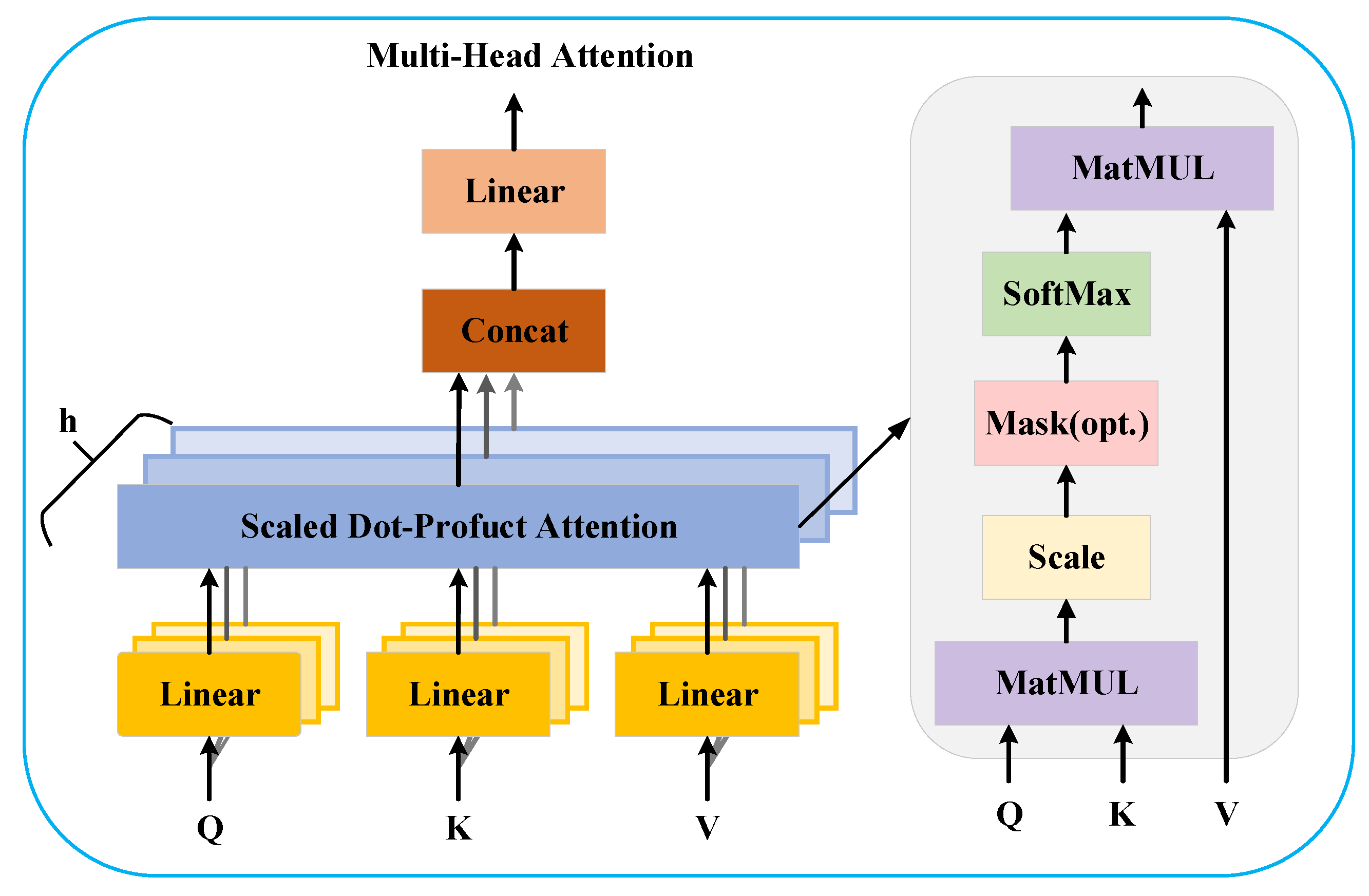
3.3. Multi-Head Self-Attention
4. Proposed Method
4.1. MFYOLO Structure Overview
4.2. Content-Guided Fusion Module
4.3. Adaptive Calibration Fusion Module
5. Experiments and Results
5.1. Experiments Setup
5.2. Dataset
5.3. Evaluation Indicators
5.4. Ablation Experiment
5.4.1. Cumulative Benefit Analysis of the CGF Module
5.4.2. Ablation Study on Algorithm
5.4.3. Efficiency Analysis
5.5. Comparison with Other Algorithms
5.5.1. Quantitative Analysis
5.5.2. Qualitative Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| MFYOLO | Multimodal Fusion YOLO |
| CNN | Convolutional neural networks |
| RCNN | Region-based convolutional neural network |
| SSD | Shot multi-box detector |
| CA | Coordinate attention |
| SE | Squeeze-and-excitation network |
| MSA | Multi-head self-attention |
| CGF | Content-guided fusion |
| GLT | Global–local transformer |
| GLU | Gated linear unit |
| MSCGLU | Multi-scale convolutional gated linear unit |
| ACF | Adaptive calibration fusion |
| SGD | Stochastic gradient descent |
| mAPx | mean average precision while confidence at 0.x |
| MR | Miss rate |
| IOU | Intersection of union |
References
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-modality interactive attention network for multispectral pedestrian detection. Inform. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Wolpert, A.; Teutsch, M.; Sarfraz, M.S.; Stiefelhagen, R. Anchor-free small-scale multispectral pedestrian detection. arXiv 2020, arXiv:2008.08418. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 3–8 January 2021; pp. 72–80. [Google Scholar]
- Cao, Z.; Yang, H.; Zhao, J.; Guo, S.; Li, L. Attention fusion for one-stage multispectral pedestrian detection. Sensors 2021, 21, 4184. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral pedestrian detection based on deep convolutional neural networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving multispectral pedestrian detection by addressing modality imbalance problems. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 787–803. [Google Scholar]
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: Gated fusion double SSD for multispectral pedestrian detection. arXiv 2019, arXiv:1903.06999. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. Unified multi-spectral pedestrian detection based on probabilistic fusion networks. Pattern Recogn. 2018, 80, 143–155. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral pedestrian detection via simultaneous detection and segmentation. arXiv 2018, arXiv:1808.04818. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster r-cnn for robust multispectral pedestrian detection. Pattern Recogn. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, W. Frequency Mining and Complementary Fusion Network for RGB-Infrared Object Detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5004605. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, X.; Wang, J.; Ying, J.; Sheng, Z.; Yu, H.; Li, C.; Shen, H.L. TFDet: Target-aware fusion for RGB-T pedestrian detection. IEEE Trans. Neural Networks Learn. Syst. 2024, 1–15, Early Access. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Zhu, Y.; Huang, H. Specificity-Guided Cross-Modal Feature Reconstruction for RGB-Infrared Object Detection. IEEE Trans. Intell. Transp. Syst. 2024, 26, 950–961. [Google Scholar] [CrossRef]
- Qingyun, F.; Dapeng, H.; Zhaokui, W. Cross-modality fusion transformer for multispectral object detection. arXiv 2021, arXiv:2111.00273. [Google Scholar]
- Shen, J.; Chen, Y.; Liu, Y.; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection. Pattern Recogn. 2024, 145, 109913. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 7132–7141. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 17773–17783. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3496–3504. [Google Scholar]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5906–5916. [Google Scholar]
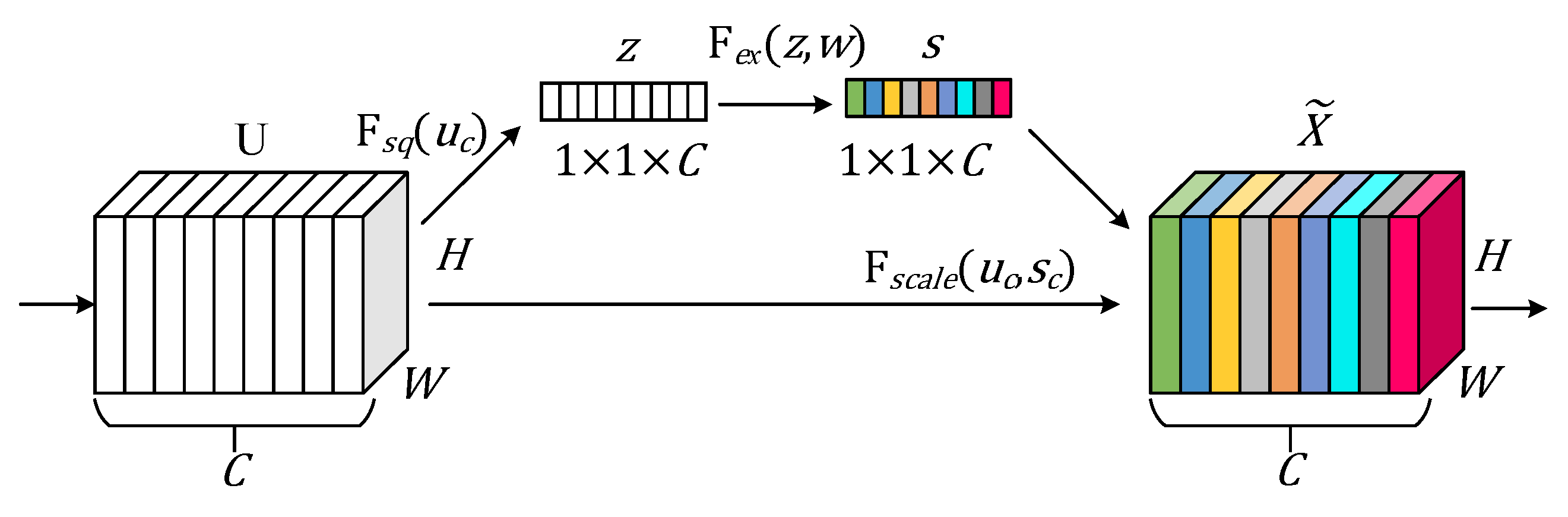




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Optimizer | SGD |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Input shape | 640 × 640 |
| Weight decay | 0.0005 |
| Training epochs | 200 |
| IoU threshold | 0.7 |
| Number (CGF) | mAP50 (%) | mAP95 (%) |
|---|---|---|
| 0 | 95.3 | 61.4 |
| 1 | 94.8 (−0.5) | 62.4 (+1.0) |
| 2 | 95.7 (+0.4) | 63.0 (+1.6) |
| 3 | 96.1 (+0.8) | 63.7 (+2.3) |
| Methods | Input | Params (M) | MR (%) | mAP50 (%) | mAP95 (%) | |||
|---|---|---|---|---|---|---|---|---|
| LLVIP | M3FD | LLVIP | M3FD | LLVIP | M3FD | |||
| YOLOv8 | RGB | 3.0 | 18.0 | 28.0 | 88.0 | 80.5 | 49.2 | 52.4 |
| YOLOv8 | T | 3.0 | 12.2 | 29.6 | 94.5 | 77.4 | 61.5 | 50.8 |
| Baseline | RGB + T | 4.4 | 10.7 | 26.7 | 95.3 | 79.7 | 61.4 | 52.7 |
| Baseline_Big | RGB + T | 6.7 | 11.5 | 25.5 | 95.6 | 80.6 | 62.6 | 53.4 |
| Baseline + CGF | RGB + T | 6.0 | 9.7 | 25.6 | 96.1 | 81.3 | 63.7 | 53.7 |
| Baseline + Swin | RGB + T | 11.1 | 10.2 | 25.1 | 96.2 | 81.6 | 61.2 | 49.3 |
| Baseline + CGF + Res | RGB + T | 7.4 | 12.7 | 25.3 | 95.3 | 82.7 | 61.4 | 55.9 |
| Baseline + CGF + ACF | RGB + T | 6.7 | 9.0 | 22.8 | 96.4 | 84.2 | 63.8 | 56.6 |
| Methods | Params (M) | Inference (ms) |
|---|---|---|
| YOLOv8 | 3.0 | 8.9 |
| Baseline | 4.4 | 9.2 |
| Baseline_Big | 6.7 | 10.1 |
| MFYOLO | 6.7 | 11.7 |
| Baseline + CGF + Res | 7.4 | 12.2 |
| Method | Input | mAP50 (%) | mAP95 (%) |
|---|---|---|---|
| YOLOv5 | RGB | 85.7 | 48.1 |
| YOLOv5 | T | 93.6 | 59.6 |
| YOLOv6 | RGB | 85.6 | 49.3 |
| YOLOv6 | T | 94.4 | 62.4 |
| YOLOv8 | RGB | 88.0 | 49.2 |
| YOLOv8 | T | 94.5 | 61.5 |
| ICAFusion | RGB + T | 95.8 | 59.0 |
| CFT | RGB + T | 95.8 | 62.3 |
| Baseline | RGB + T | 95.3 | 61.4 |
| MFYOLO (Ours) | RGB + T | 96.4 | 63.8 |
| Method | Input | mAP50 (%) | mAP95 (%) |
|---|---|---|---|
| YOLOv5 | RGB | 65.6 | 42.2 |
| YOLOv5 | T | 64.7 | 41.8 |
| YOLOv6 | RGB | 75.6 | 49.0 |
| YOLOv6 | T | 73.8 | 47.8 |
| YOLOv8 | RGB | 80.5 | 52.4 |
| YOLOv8 | T | 77.4 | 50.8 |
| TarDAL | RGB + T | 81.9 | - |
| CDDFuse | RGB + T | 82.0 | - |
| Baseline | RGB + T | 79.7 | 52.7 |
| MFYOLO (Ours) | RGB + T | 84.2 | 56.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, L.; Liu, X.; Zhou, L.; Zou, X. Cross-Modal Object Detection Based on Content-Guided Feature Fusion and Self-Calibration. Sensors 2025, 25, 3392. https://doi.org/10.3390/s25113392
Ning L, Liu X, Zhou L, Zou X. Cross-Modal Object Detection Based on Content-Guided Feature Fusion and Self-Calibration. Sensors. 2025; 25(11):3392. https://doi.org/10.3390/s25113392
Chicago/Turabian StyleNing, Liyang, Xuxun Liu, Luoyu Zhou, and Xueyu Zou. 2025. "Cross-Modal Object Detection Based on Content-Guided Feature Fusion and Self-Calibration" Sensors 25, no. 11: 3392. https://doi.org/10.3390/s25113392
APA StyleNing, L., Liu, X., Zhou, L., & Zou, X. (2025). Cross-Modal Object Detection Based on Content-Guided Feature Fusion and Self-Calibration. Sensors, 25(11), 3392. https://doi.org/10.3390/s25113392