
VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection

 , , ,
, , ,  and
and 
Abstract
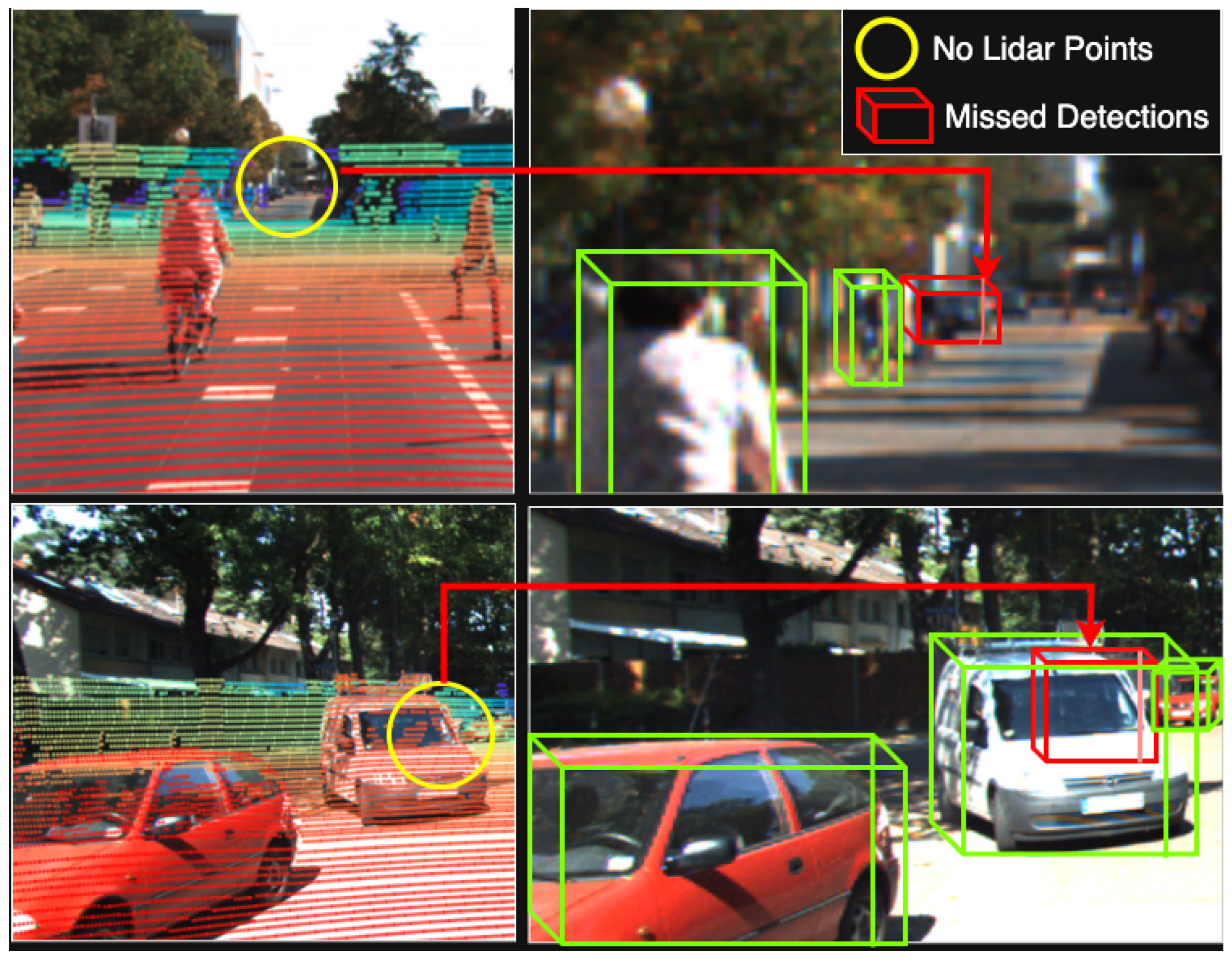
1. Introduction
- An innovative approach that augments virtual points obtained through the joint application of LiDAR and camera data with semantic labels derived from image-based semantic segmentation.
- Integration of distance-aware data augmentation method for improving models’ ability to identify sparse and occluded objects by creating training samples.
- A generic method that can incorporate any variation of 3D frameworks and 2D semantic segmentation for improving the overall detection accuracy.
- Evaluation on the KITTI and nuScenes datasets shows major improvement in both 3D and BEV detection benchmarks, especially for distant objects.
2. Related Work
2.1. Single Modality
2.2. Fusion-Based
2.3. Point Decoration Fusion
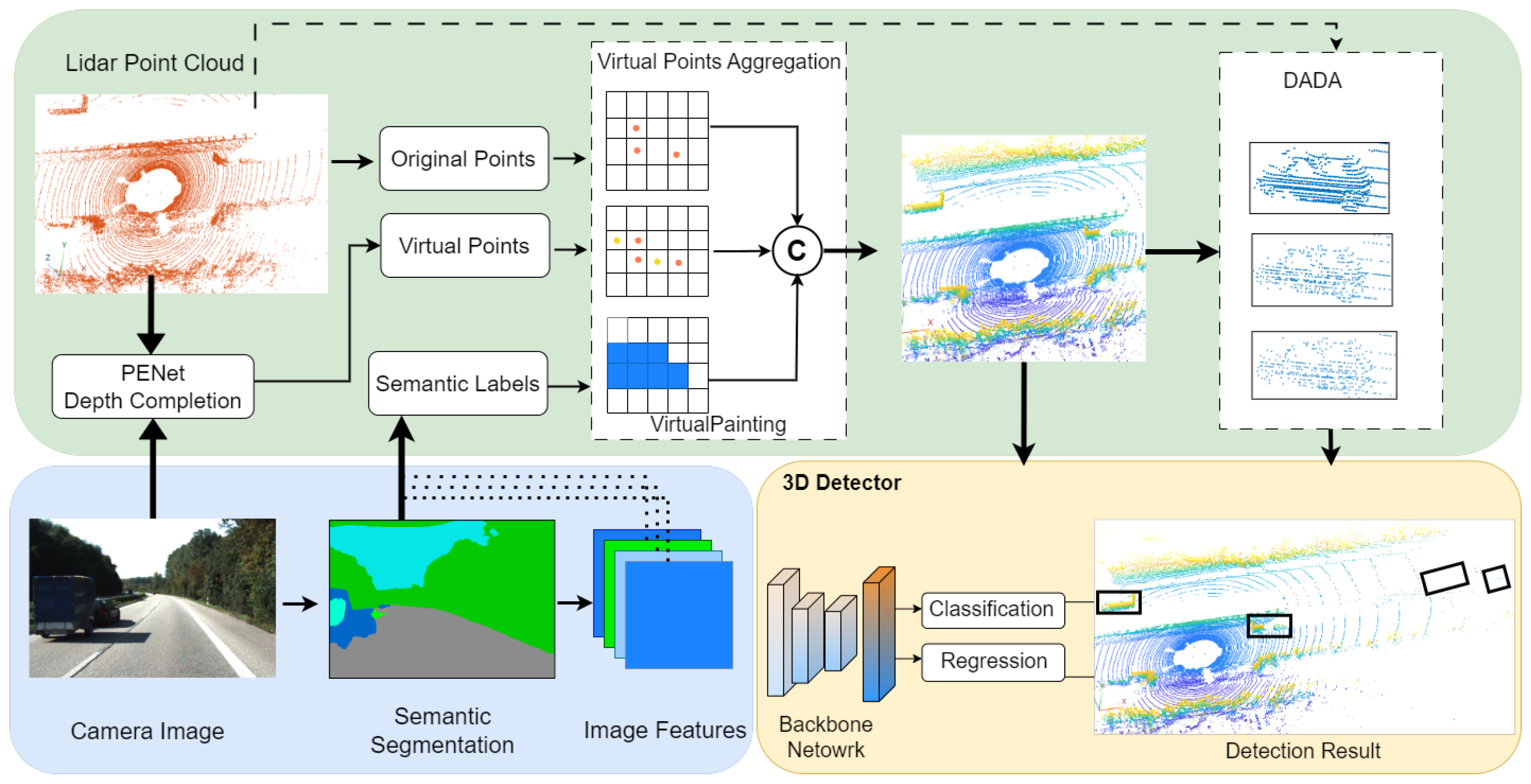
3. VirtualPainting
3.1. Image-Based Semantic Network
3.2. PENet for Virtual Point Generation
3.3. Painting Virtual Points
- denotes the original raw LiDAR point cloud, where N is the number of points and indicates spatial dimensions (e.g., ).
- represents the virtual points generated using a depth completion network. These are spatially aligned with the original LiDAR points.
- The augmented point cloud A is obtained by combining the raw and virtual points, i.e., , where .
- is the semantic segmentation score map, where W and H are the width and height of the image, and C is the number of semantic classes.
- is the homogeneous transformation matrix used to project 3D points into the camera coordinate frame.
- is the camera projection matrix used to map 3D coordinates into 2D image coordinates.
- 1
- The 3D point is projected onto the image plane to obtain 2D coordinates using the ‘PROJECT’ function, which applies the transformation T followed by projection through M.
- 2
- The semantic class score vector is retrieved from S at the pixel coordinates .
- 3
- The final painted point is generated by concatenating the 3D point with its corresponding class score vector .
| Algorithm 1: VirtualPainting (L, V, A, S, T, M). |
 |
3.4. Distance-Aware Data Augmentation
3.5. LiDAR Network Details
4. Experimental Setup and Results
4.1. KITTI Results
4.2. nuScenes Results
5. Ablation Studies
5.1. VirtualPainting Is a Generic and Flexible Method
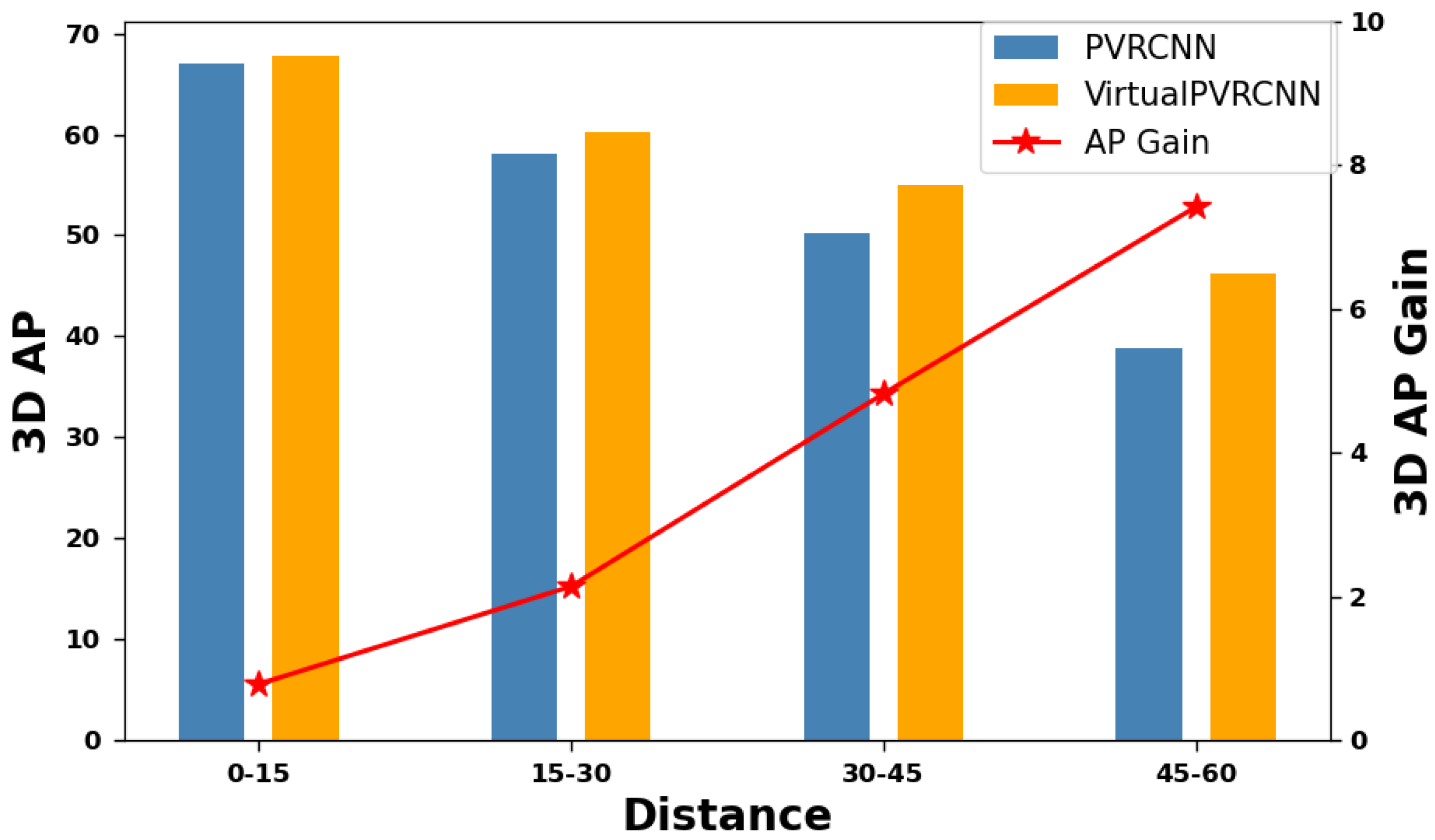
5.2. Where Does the Improvement Come from?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection. arXiv 2020, arXiv:2012.15712. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. arXiv 2017, arXiv:1611.07759. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.S.; Choi, J.W. 3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection. arXiv 2020, arXiv:2004.12636. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4603–4611. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. PointAugmenting: Cross-Modal Augmentation for 3D Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11789–11798. [Google Scholar]
- Dhakal, S.; Qu, D.; Carrillo, D.; Yang, Q.; Fu, S. OASD: An Open Approach to Self-Driving Vehicle. In Proceedings of the 2021 Fourth International Conference on Connected and Autonomous Driving (MetroCAD), Richardson, TX, USA, 27–28 May 2021; pp. 54–61. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal Virtual Point 3D Detection. arXiv 2021, arXiv:2111.06881. [Google Scholar]
- Wu, X.; Peng, L.; Yang, H.; Xie, L.; Huang, C.; Deng, C.; Liu, H.; Cai, D. Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5408–5417. [Google Scholar]
- Shi, Y.; Hu, J.; Li, L. PENet: Pre-Enhanced Network for Object Detection and Instance Segmentation. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Xi’an, China, 24–26 February 2023; pp. 184–189. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. arXiv 2018, arXiv:1812.05784. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413, 02413. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 770–779. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3D Object Detection and Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11779–11788. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189, 08189. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Penksy, M. Sparse Convolutional Neural Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10526–10535. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. arXiv 2017, arXiv:1712.02294. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-Task Multi-Sensor Fusion for 3D Object Detection. arXiv 2020, arXiv:2012.12397. [Google Scholar]
- Dhakal, S.; Chen, Q.; Qu, D.; Carillo, D.; Yang, Q.; Fu, S. Sniffer Faster R-CNN: A Joint Camera-LiDAR Object Detection Framework with Proposal Refinement. In Proceedings of the 2023 IEEE International Conference on Mobility, Operations, Services and Technologies (MOST), Dallas, TX, USA, 18–20 October 2023; pp. 1–10. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10386–10393. [Google Scholar]
- Dhakal, S.; Carrillo, D.; Qu, D.; Yang, Q.; Fu, S. Sniffer Faster R-CNN++: An Efficient Camera-LiDAR Object Detector with Proposal Refinement on Fused Candidates. ACM J. Auton. Transport. Syst. 2023, 36, 1138. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Zhou, B.; Zhang, L. FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11618–11628. [Google Scholar]
- Wu, H.; Wen, C.; Li, W.; Li, X.; Yang, R.; Wang, C. Transformation-Equivariant 3D Object Detection for Autonomous Driving. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence (AAAI’23/IAAI’23/EAAI’23), Washington, DC, USA, 7–14 February 2023; pp. 1–8. [Google Scholar] [CrossRef]
- OpenPCDet Development Team. OpenPCDet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 2 April 2025).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | mAP | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mod. | Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| AVOD | L&I | 64.07 | 90.99 | 84.82 | 79.62 | 58.49 | 50.32 | 46.98 | 69.39 | 57.12 | 51.09 |
| MV3D | L&I | N/A | 86.62 | 78.93 | 69.80 | N/A | N/A | N/A | N/A | N/A | N/A |
| PointRCNN | L | 66.92 | 92.13 | 87.39 | 82.72 | 54.77 | 46.13 | 42.84 | 82.56 | 67.24 | 60.28 |
| VirtualPointRCNN | L&I | 70.56 | 92.67 | 88.35 | 83.67 | 58.99 | 50.22 | 46.63 | 84.07 | 71.76 | 63.17 |
| Improvement ↑ | +3.64 | +0.54 | +0.96 | +0.95 | +4.22 | +4.09 | +3.79 | +1.51 | +4.52 | +2.89 | |
| PointPillars | L | 65.98 | 90.07 | 86.56 | 82.81 | 57.60 | 48.64 | 45.78 | 79.90 | 62.73 | 55.58 |
| VirtualPointPillars | L&I | 69.07 | 90.39 | 86.98 | 83.59 | 58.86 | 50.03 | 46.71 | 80.15 | 65.89 | 59.44 |
| Improvement ↑ | +3.09 | +0.32 | +0.42 | +0.78 | +1.26 | +1.39 | +0.93 | +0.25 | +3.16 | +3.86 | |
| PVRCNN | L | 68.54 | 91.91 | 88.13 | 85.40 | 52.41 | 44.83 | 42.57 | 79.60 | 64.46 | 57.94 |
| VirtualPVRCNN | L&I | 70.05 | 92.33 | 88.64 | 86.08 | 53.57 | 48.97 | 46.76 | 80.26 | 68.39 | 61.91 |
| Improvement ↑ | +1.51 | +0.42 | +0.51 | +0.68 | +1.16 | +4.14 | +4.19 | +0.66 | +3.93 | +3.97 | |
| Model | Modality | mAP | Total mAP | Improvement | ||
|---|---|---|---|---|---|---|
| Car | Pedestrian | Cyclist | ||||
| PaintedPointRCNN | L&I | 87.97 | 51.97 | 72.80 | 70.91 | |
| VirtualPointRCNN | L&I | 88.23 | 52.61 | 72.66 | 71.16 | +0.25 |
| PaintedPointPillars | L&I | 87.18 | 51.44 | 68.18 | 69.02 | |
| VirtualPointPillars | L&I | 87.32 | 51.87 | 68.49 | 69.23 | +0.21 |
| PaintedPVRCNN | L&I | 88.91 | 48.78 | 69.97 | 69.22 | |
| VirtualPVRCNN | L&I | 89.35 | 49.43 | 70.08 | 69.98 | +0.76 |
| Method | Modality | NDS | mAP | Car | Truck | Bus | Trailer | Cons | Ped | Moto | Bicycle | TC | Barrier |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3DCVF | L & C | 62.3 | 52.7 | 83.0 | 45.0 | 48.8 | 49.6 | 15.9 | 74.2 | 51.2 | 30.4 | 62.9 | 65.9 |
| PointPillars | L | 55.0 | 40.1 | 76.0 | 31.0 | 32.1 | 36.6 | 11.3 | 64.0 | 34.2 | 14.0 | 45.6 | 56.4 |
| PaintedPointPillars | L & C | 58.1 | 46.4 | 77.9 | 35.8 | 36.2 | 37.3 | 15.8 | 73.3 | 41.5 | 24.1 | 62.4 | 60.2 |
| VirtualPointPillars | L & C | 60.21 | 48.59 | 79.20 | 36.11 | 39.47 | 40.53 | 16.27 | 76.25 | 47.45 | 28.79 | 65.71 | 63.77 |
| Improvement ↑ | – | +2.11 | +2.19 | +1.30 | +0.29 | +3.07 | +3.23 | +0.47 | +2.95 | +5.95 | +4.69 | +3.31 | +3.57 |
| Model | VPC | Sem.Seg | DA-Aug. | 3D AP | |
|---|---|---|---|---|---|
| Pedestrian | Cyclist | ||||
| PointRCNN | 47.85 | 68.93 | |||
| VirtualPointRCNN | √ | √ | 48.43 | 69.39 | |
| √ | √ | 51.75 | 72.04 | ||
| √ | √ | √ | 52.61 | 72.66 | |
| PointPillar | 50.13 | 66.16 | |||
| VirtualPointPillar | √ | √ | 50.59 | 66.62 | |
| √ | √ | 51.45 | 68.06 | ||
| √ | √ | √ | 51.87 | 68.49 | |
| PVRCNN | 46.41 | 67.26 | |||
| VirtualPVRRCNN | √ | √ | 46.83 | 67.73 | |
| √ | √ | 48.94 | 69.48 | ||
| √ | √ | √ | 49.43 | 70.08 | |
| VPC | Sem.Seg | DADA | mAP | NDS | |
|---|---|---|---|---|---|
| (a) | 40.12 | 55.02 | |||
| (b) | √ | √ | 41.03 + 0.93 | 55.75 + 0.75 | |
| (c) | √ | √ | 47.05 + 6.75 | 58.73 + 2.98 | |
| (d) | √ | √ | 47.78 + 0.73 | 59.59 + 0.86 | |
| (e) | √ | √ | √ | 48.59 + 0.81 | 60.21 + 0.62 |
| VirtualPainting | PointPainting | F-PointNet | EPNet | 3D-CVF |
|---|---|---|---|---|
| 5.37FPS | 2.38FPS | 5.52FPS | 8.15FPS | 13.83FPS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhakal, S.; Qu, D.; Carrillo, D.; Dehghani Tezerjani, M.; Yang, Q. VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection. Sensors 2025, 25, 3367. https://doi.org/10.3390/s25113367
Dhakal S, Qu D, Carrillo D, Dehghani Tezerjani M, Yang Q. VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection. Sensors. 2025; 25(11):3367. https://doi.org/10.3390/s25113367
Chicago/Turabian StyleDhakal, Sudip, Deyuan Qu, Dominic Carrillo, Mohammad Dehghani Tezerjani, and Qing Yang. 2025. "VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection" Sensors 25, no. 11: 3367. https://doi.org/10.3390/s25113367
APA StyleDhakal, S., Qu, D., Carrillo, D., Dehghani Tezerjani, M., & Yang, Q. (2025). VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection. Sensors, 25(11), 3367. https://doi.org/10.3390/s25113367