
A Novel Approach to Speed Up Hampel Filter for Outlier Detection

 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methods
2.1. Standard Hampel Filter
2.2. Proposed Hampel Filter with Modified MAD (mMAD)
2.3. Analysis of the Robustness of the Proposed Estimator
2.3.1. Robustness of the Proposed Estimator
2.3.2. Breakdown Point Analysis
- -
- Classical MAD: Since the median has a BP of 50%, the MAD inherits this property [14]. Contamination of up to 50% of the data cannot arbitrarily perturb the median of absolute deviations.
- -
- Modified MAD (mMAD): For the mMAD, let be a sliding window of size centered at . The local median has a BP of 50% within . Even if of the entire dataset is contaminated, each window contains at most outliers. Since , we haveensuring the local median remains bounded. The absolute deviations are then filtered by another median (mMAD), which also has a BP of 50%.
2.3.3. Influence Function Analysis
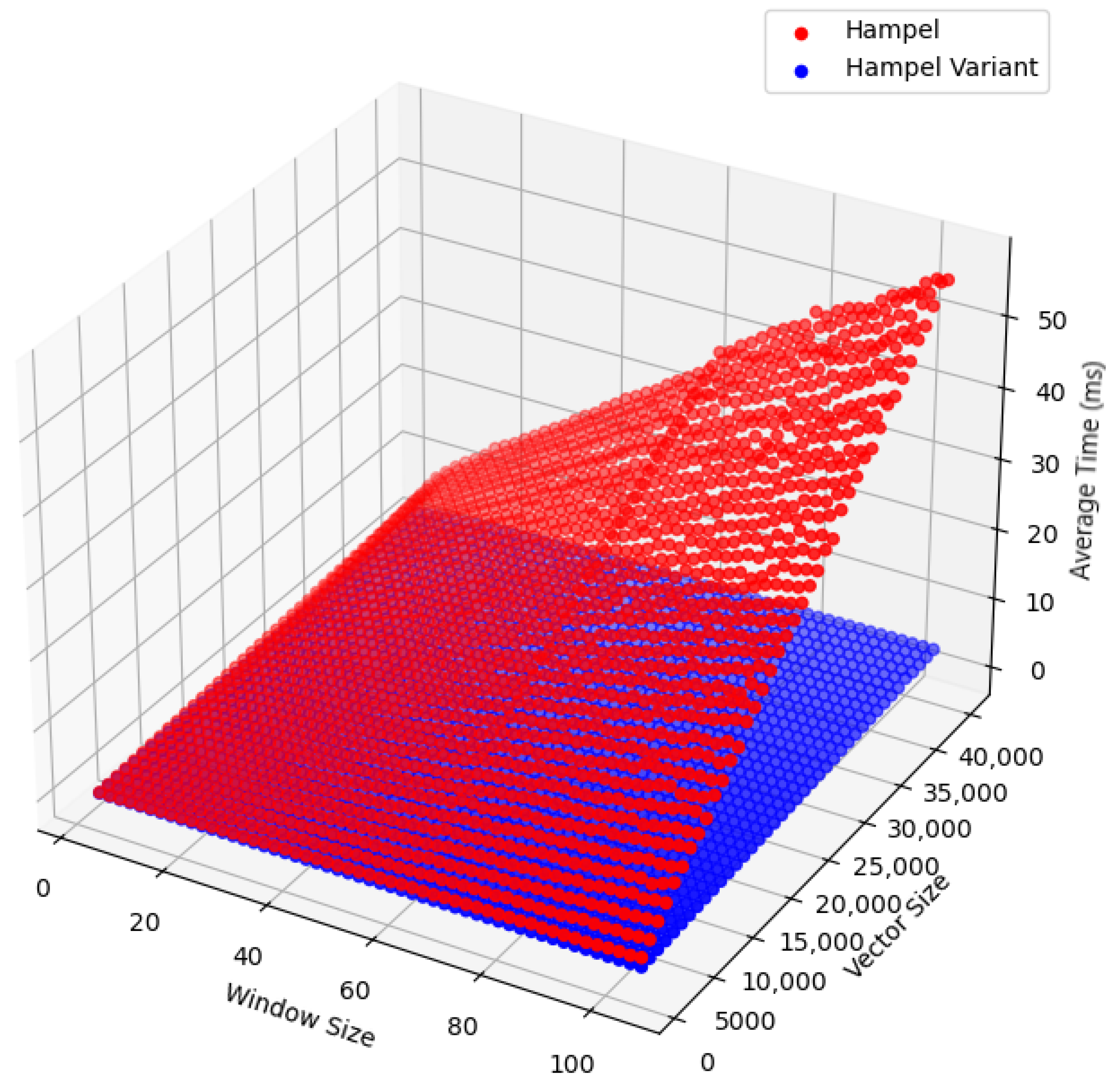
2.4. Computational Complexity Comparison
2.4.1. Original Hampel Filter
- Median filter calculation:
- A median filter is applied to the original data series to obtain .
- Complexity: , since the median filter operates over a sliding window [17].
- Calculation of absolute deviations from the median:
- For each point, the absolute deviation from the median within the window is calculated as
- Complexity: , as it involves an elementary operation on each data point.
- Calculation of the Median Absolute Deviation (MAD):
- The median of the absolute deviations within each window is computed as
- Complexity: , since each window needs to be sorted to find the median.
- Determination of the outlier threshold:
- A threshold is computed by multiplying the MAD by a scaling factor , typically defined as
- Complexity: , as it involves a simple multiplication for each point.
- Replacement of outliers:
- If the absolute deviation of a point exceeds the threshold, i.e., , the point is considered an outlier and is replaced with the median of its window.
- Complexity: , involving a comparison and possible substitution for each data point.
2.4.2. Proposed Hampel Filter Variant
- Median filter calculation:
- A median filter is applied to the original data series to obtain .
- Complexity: , since the median filter operates over a sliding window.
- Calculation of absolute deviations from the initial median:
- For each point, the absolute deviation from the median is calculated:
- Complexity: , involving an element-wise operation.
- Application of median filter to absolute deviations (MAD):
- A median filter is applied to the absolute deviations to obtain .
- Complexity: , as it involves another median filter over a sliding window.
- Calculation of the outlier threshold:
- The threshold for each point is computed as
- Complexity: .
- Application of the Hampel filter:
- For each point, if , the point is considered an outlier and is replaced with the median .
- Complexity: .
2.4.3. Comparison
- Original Hampel filter: .
- Hampel filter variant: .
3. Experiments and Result
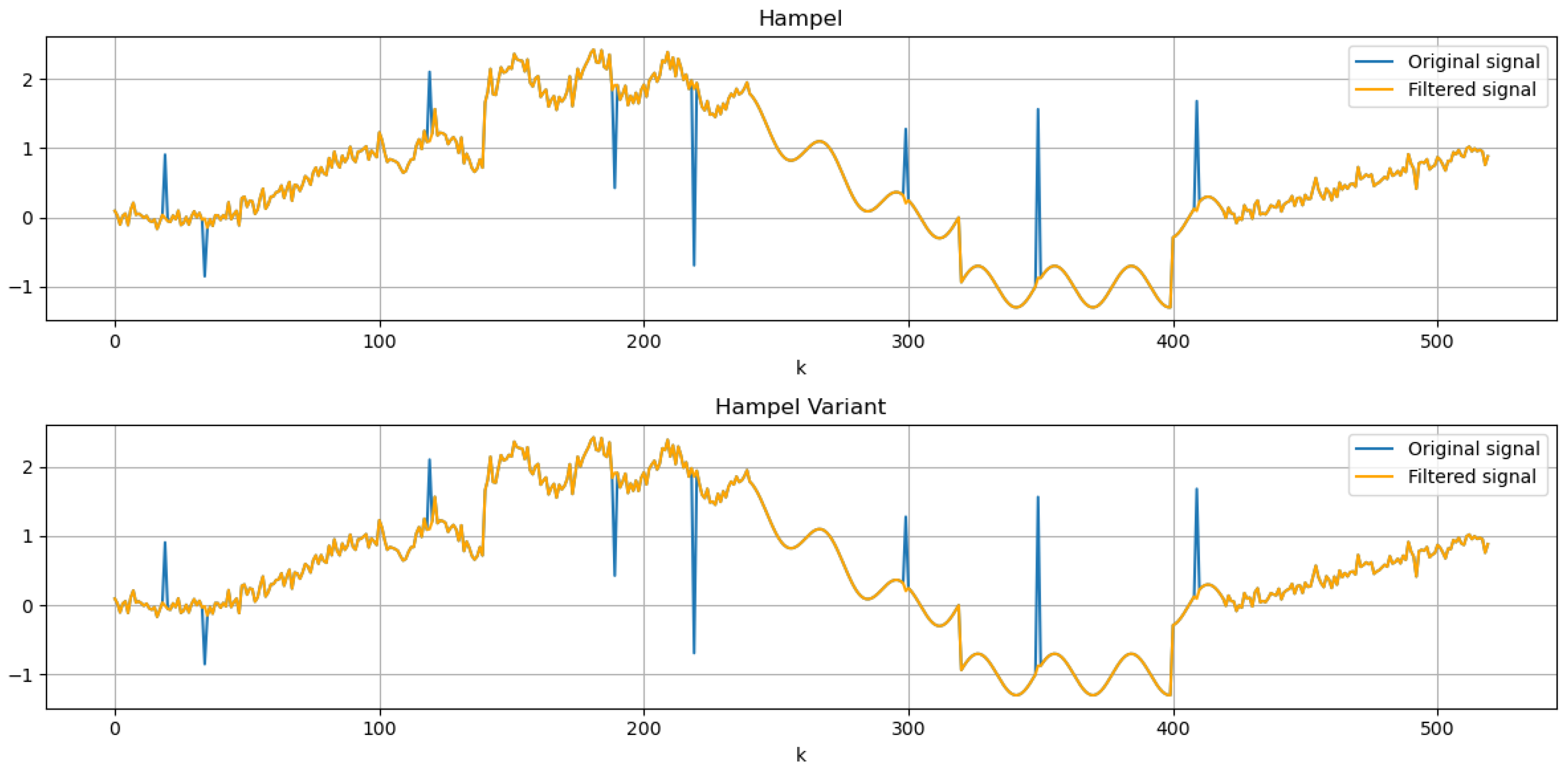
3.1. Evaluating Hampel Filter Performance with Synthetic Data
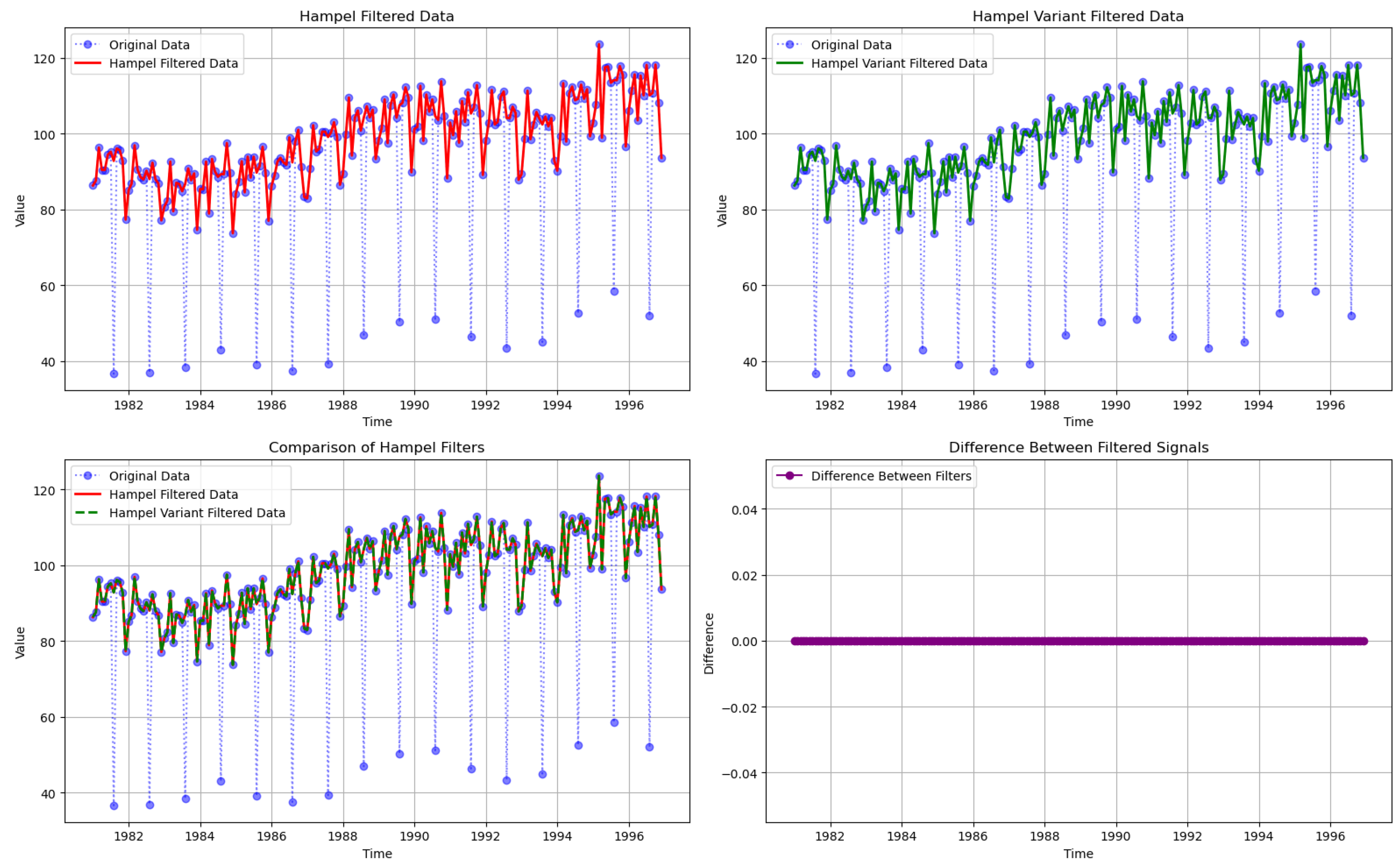
3.2. Real Data Example
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Adams, J.; Hayunga, D.; Mansi, S.; Reeb, D.; Verardi, V. Identifying and treating outliers in finance. Financ. Manag. 2019, 48, 345–384. [Google Scholar] [CrossRef]
- Mahajan, M.; Kumar, S.; Pant, B.; Tiwari, U.K. Incremental Outlier Detection in Air Quality Data Using Statistical Methods. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Leonardi, A.; Murphy, C.; Hobson, S.; Rohera, V.; Guler, U. Outlier Detection and Removal Signal Processing for Wearable Transcutaneous Oxygen Sensor. In Proceedings of the 2023 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 6–8 October 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Mun, J.H.; Yoo, J.; Kim, H.; Ryu, N.; Kim, S. Domain-knowledge-informed functional outlier detection for line quality control systems. Comput. Ind. Eng. 2024, 189, 109936. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in Outlier Detection Techniques: A Survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Sullivan, J.H.; Warkentin, M.; Wallace, L. So many ways for assessing outliers: What really works and does it matter? J. Bus. Res. 2021, 132, 530–543. [Google Scholar] [CrossRef]
- Boukerche, A.; Zheng, L.; Alfandi, O. Outlier Detection: Methods, Models, and Classification. ACM Comput. Surv. 2020, 53, 55. [Google Scholar] [CrossRef]
- Hampel, F.R. The influence curve and its role in robust estimation. J. Am. Stat. Assoc. 1974, 69, 383–393. [Google Scholar] [CrossRef]
- Bhowmik, S.; Jelfs, B.; Arjunan, S.P.; Kumar, D.K. Outlier removal in facial surface electromyography through Hampel filtering technique. In Proceedings of the 2017 IEEE Life Sciences Conference (LSC), Sydney, Australia, 13–15 December 2017; pp. 258–261. [Google Scholar] [CrossRef]
- Kumuda, D.K.; Srihari, P.; Sheshagiri, D.; Kumar, P.R.; Pardhasaradhi, B. Clipping and Hampel Filtering Algorithm to Mitigate Mutual Interference for Automotive Radars. In Proceedings of the 2023 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 14–16 July 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Yao, Z.; Xie, J.; Tian, Y.; Huang, Q. Using hampel identifier to eliminate profile-isolated outliers in laser vision measurement. J. Sens. 2019, 2019, 3823691. [Google Scholar] [CrossRef]
- Sohrab, H.H. Basic Real Analysis; Birkhäuser: Basel, Switzerland, 2003; p. 559. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1987. [Google Scholar] [CrossRef]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; Wiley: Hoboken, NJ, USA, 2009; pp. 1–354. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Raffel, C. median-filter/Mediator.h at Master · Craffel/Median-Filter · GitHub. Available online: https://github.com/craffel/median-filter/blob/master/Mediator.h (accessed on 22 May 2025).
- Pearson, R.K.; Neuvo, Y.; Astola, J.; Gabbouj, M. Generalized Hampel Filters. Eurasip J. Adv. Signal Process. 2016, 2016, 87. [Google Scholar] [CrossRef]
- López-de Lacalle, J. tsoutliers: Detection of Outliers in Time Series, R package version 0.6-10; The Comprehensive R Archive Network (CRAN): Vienna, Austria, 2014; Available online: https://CRAN.R-project.org/package=tsoutliers (accessed on 22 May 2025).
- Nolan, J.P. Univariate Stable Distributions: Models for Heavy Tailed Data; Springer Series in Operations Research and Financial Engineering; Springer: Cham, Switzerland, 2009; pp. 1–323. [Google Scholar]
- Kaiser, R.; Maravall, A. Seasonal Outliers in Time Series; Technical Report Working Paper No. 9915; Banco de España, Servicio de Estudios: Madrid, Spain, 1999. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roos-Hoefgeest Toribio, M.; Garnung Menéndez, A.; Roos-Hoefgeest Toribio, S.; Álvarez García, I. A Novel Approach to Speed Up Hampel Filter for Outlier Detection. Sensors 2025, 25, 3319. https://doi.org/10.3390/s25113319
Roos-Hoefgeest Toribio M, Garnung Menéndez A, Roos-Hoefgeest Toribio S, Álvarez García I. A Novel Approach to Speed Up Hampel Filter for Outlier Detection. Sensors. 2025; 25(11):3319. https://doi.org/10.3390/s25113319
Chicago/Turabian StyleRoos-Hoefgeest Toribio, Mario, Alejandro Garnung Menéndez, Sara Roos-Hoefgeest Toribio, and Ignacio Álvarez García. 2025. "A Novel Approach to Speed Up Hampel Filter for Outlier Detection" Sensors 25, no. 11: 3319. https://doi.org/10.3390/s25113319
APA StyleRoos-Hoefgeest Toribio, M., Garnung Menéndez, A., Roos-Hoefgeest Toribio, S., & Álvarez García, I. (2025). A Novel Approach to Speed Up Hampel Filter for Outlier Detection. Sensors, 25(11), 3319. https://doi.org/10.3390/s25113319