Indoor Abnormal Behavior Detection for the Elderly: A Review


Abstract
1. Introduction
- (1)
- We analyze the existing methods and technologies from the perspective of data sources, divide the existing methods into sensor-based, video-based, other modality methods (WiFi, radar, infrared, etc.), and multimodal fusion methods, and analyze the advantages and disadvantages of the existing methods.
- (2)
- We present the challenges and existing solutions for the detection of indoor behavioral anomalies and give suggestions for the development of the field based on the latest innovative content.
- (3)
- According to the latest technology, we combine audio, pressure sensor, robot, and other technologies to build an indoor Internet of Things abnormal behavior detection system, which is expected to provide a more comprehensive security guarantee for the elderly.
2. Survey on Existing Reviews
2.1. Human Activity Recognition (HAR)
2.2. Video Abnormal Detection
2.3. Fall Detection
3. Single Modality Approach
3.1. Sensor-Based Approach
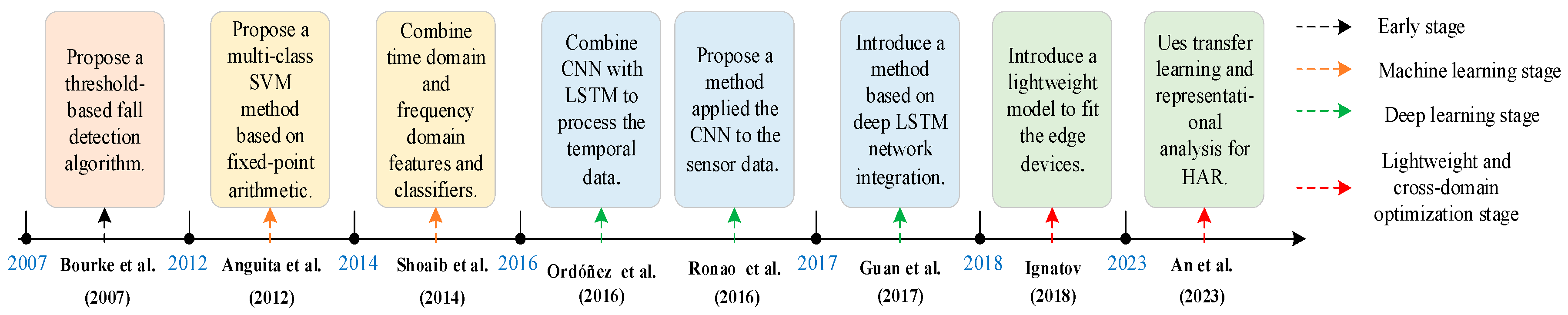
3.2. Vision-Based Approach
3.2.1. Traditional Approach
3.2.2. Deep Learning Approach
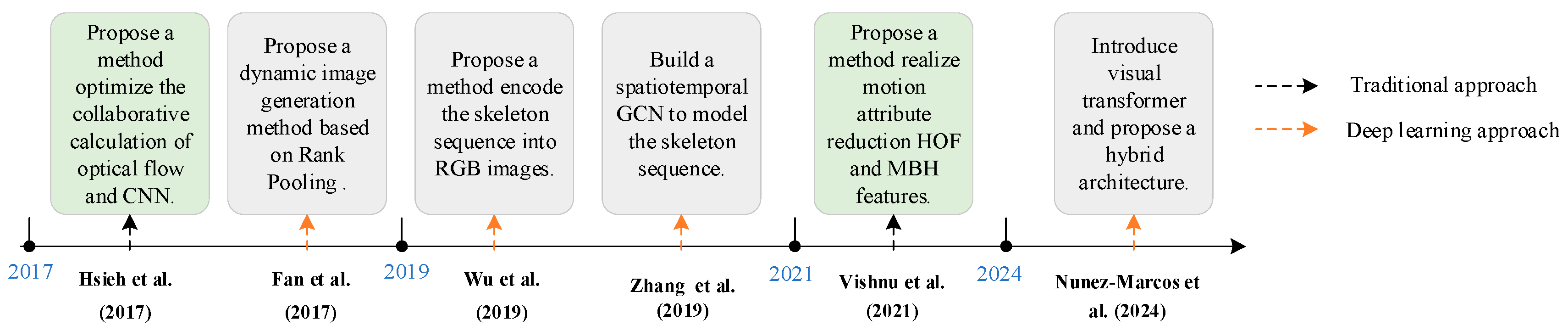
3.3. Other Modality Approach
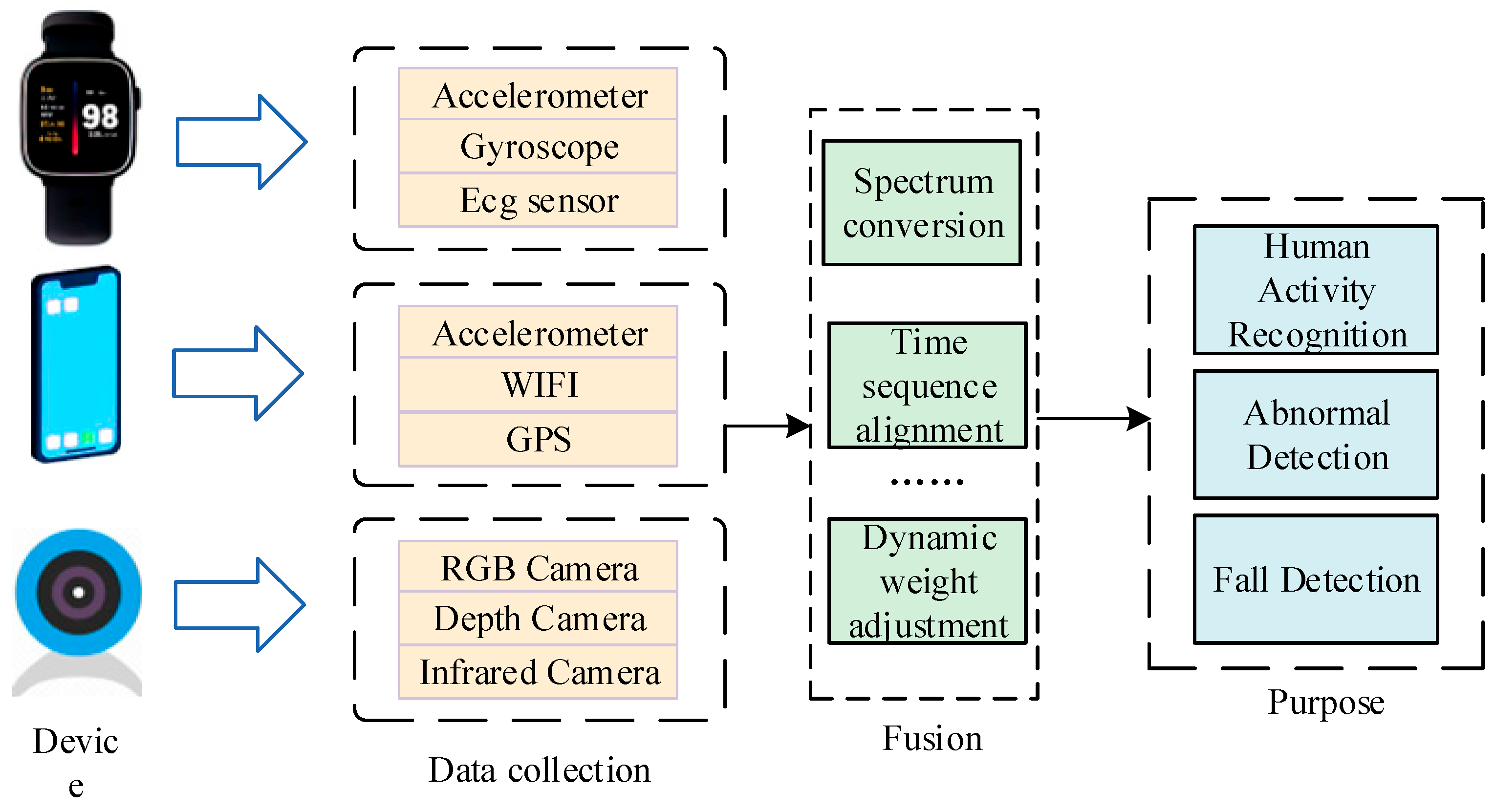
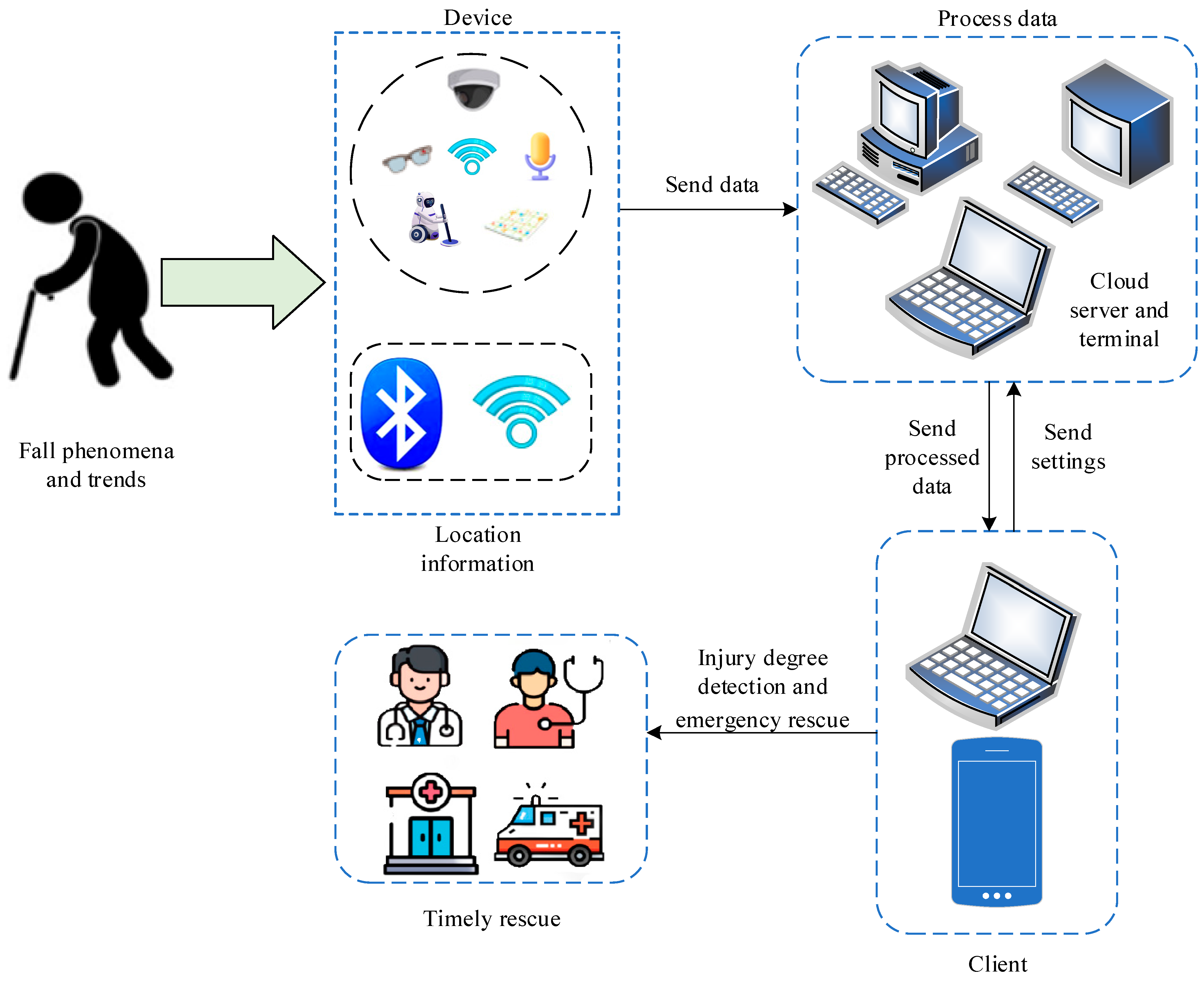
4. Multimodal Approach
5. Datasets
5.1. Sensor-Based Dataset
5.2. Video-Based Dataset
6. Challenges and Future Directions
6.1. Multimodal Dataset Issues
6.2. Privacy Issues
6.3. Indoor Environmental Issues
6.4. Wearable Device Issues
6.5. System Integration and Model Deployment Issues
6.6. Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kamiya, Y.; Lai, N.M.S.; Schmid, K. World Population Ageing 2020 Highlights; United Nations Department of Economic and Social Affairs: New York, NY, USA, 2022. [Google Scholar]
- Kwan, M.M.-S.; Close, J.C.T.; Wong, A.K.W.; Lord, S.R. Falls Incidence, Risk Factors, and Consequences in Chinese Older People: A Systematic Review. J. Am. Geriatr. Soc. 2011, 59, 536–543. [Google Scholar] [CrossRef] [PubMed]
- Masud, T.; Morris, R.O. Epidemiology of Falls. Age Ageing 2001, 30, 3–7. [Google Scholar] [CrossRef]
- Garnett, M.F.; Weeks, J.D.; Spencer, M.R. Unintentional Fall Deaths Among Adults Aged 65 and Over: United States, 2020; National Center for Health Statistics: Hyattsville, ML, USA, 2022. [Google Scholar] [CrossRef]
- James, S.L.; Lucchesi, L.R.; Bisignano, C.; Castle, C.D.; Dingels, Z.V.; Fox, J.T.; Hamilton, E.B.; Henry, N.J.; Krohn, K.J.; Liu, Z. The Global Burden of Falls: Global, Regional and National Estimates of Morbidity and Mortality from the Global Burden of Disease Study 2017. Inj. Prev. 2020, 26, i3–i11. [Google Scholar] [CrossRef] [PubMed]
- Moreland, B. Trends in Nonfatal Falls and Fall-Related Injuries among Adults Aged ≥ 65 Years—United States, 2012–2018. MMWR-Morb. Mortal. Wkly. Rep. 2020, 69, 875–881. [Google Scholar] [CrossRef]
- Burns, E. Deaths from Falls among Persons Aged ≥ 65 Years—United States, 2007–2016. MMWR-Morb. Mortal. Wkly. Rep. 2018, 67, 509–514. [Google Scholar] [CrossRef]
- Perez, A.J.; Zeadally, S. Recent Advances in Wearable Sensing Technologies. Sensors 2021, 21, 6828. [Google Scholar] [CrossRef]
- Liu, X.; Wei, Y.; Qiu, Y. Advanced Flexible Skin-Like Pressure and Strain Sensors for Human Health Monitoring. Micromachines 2021, 12, 695. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Cheng, T.; Wang, Z.L. Self-Powered Sensors and Systems Based on Nanogenerators. Sensors 2020, 20, 2925. [Google Scholar] [CrossRef]
- Javaid, S.; Fahim, H.; Zeadally, S.; He, B. Self-Powered Sensors: Applications, Challenges, and Solutions. IEEE Sens. J. 2023, 23, 20483–20509. [Google Scholar] [CrossRef]
- Wu, H.; Yang, G.; Zhu, K.; Liu, S.; Guo, W.; Jiang, Z.; Li, Z. Materials, Devices, and Systems of On-Skin Electrodes for Electrophysiological Monitoring and Human–Machine Interfaces. Adv. Sci. 2021, 8, 2001938. [Google Scholar] [CrossRef]
- Qi, P.-D.; Li, N.; Liu, Y.; Qu, C.-B.; Li, M.; Ma, J.-L.; Huang, G.-W.; Xiao, H.-M. Understanding the Cycling Performance Degradation Mechanism of a Graphene-Based Strain Sensor and an Effective Corresponding Improvement Solution. ACS Appl. Mater. Interfaces 2020, 12, 23272–23283. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Munsif, M.; Khan, S.U.; Khan, N.; Baik, S.W. Attention-Based Deep Learning Framework for Action Recognition in a Dark Environment. Hum. Centric Comput. Inf. Sci. 2024, 14, 1–22. [Google Scholar] [CrossRef]
- Wang, B.; Zheng, Z.; Guo, Y.-X. Millimeter-Wave Frequency Modulated Continuous Wave Radar-Based Soft Fall Detection Using Pattern Contour-Confined Doppler-Time Maps. IEEE Sens. J. 2022, 22, 9824–9831. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, K.; Ni, L.M. Wifall: Device-Free Fall Detection by Wireless Networks. IEEE Trans. Mob. Comput. 2016, 16, 581–594. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, D.; Wang, Y.; Ma, J.; Wang, Y.; Li, S. RT-Fall: A Real-Time and Contactless Fall Detection System with Commodity WiFi Devices. IEEE Trans. Mob. Comput. 2016, 16, 511–526. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI Based Passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, Y.; Zhang, Q. Rethinking Fall Detection with Wi-Fi. IEEE Trans. Mob. Comput. 2022, 22, 6126–6143. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.-H.; Kim, Y.-J.; Kamal, S.; Kim, D. Robust Human Activity Recognition from Depth Video Using Spatiotemporal Multi-Fused Features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, R.; Wang, Z.; Yang, H. TagCare: Using RFIDs to Monitor the Status of the Elderly Living Alone. IEEE Access 2017, 5, 11364–11373. [Google Scholar] [CrossRef]
- Abbate, S.; Avvenuti, M.; Corsini, P.; Light, J.; Vecchio, A. Monitoring of Human Movements for Fall Detection and Activities Recognition in Elderly Care Using Wireless Sensor Network: A Survey. Wirel. Sens. Netw. Appl. Centric Des. 2010, 1, 0326. [Google Scholar]
- El-Bendary, N.; Tan, Q.; Pivot, F.C.; Lam, A. Fall Detection and Prevention for the Elderly: A Review of Trends and Challenges. Int. J. Smart Sens. Intell. Syst. 2013, 6, 1230–1266. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep Learning Algorithms for Human Activity Recognition Using Mobile and Wearable Sensor Networks: State of the Art and Research Challenges. Expert. Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Shao, J.; Kang, K.; Change Loy, C.; Wang, X. Deeply Learned Attributes for Crowded Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4657–4666. [Google Scholar] [CrossRef]
- Haria, A.; Subramanian, A.; Asokkumar, N.; Poddar, S.; Nayak, J.S. Hand Gesture Recognition for Human Computer Interaction. Procedia Comput. Sci. 2017, 115, 367–374. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, R.; Wang, Y.; Sun, S.; Chen, J.; Zhang, X. A Swarm Intelligence Assisted IoT-Based Activity Recognition System for Basketball Rookies. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 8, 82–94. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Kevin, I.; Wang, K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-Learning-Enhanced Human Activity Recognition for Internet of Healthcare Things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.C. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2014, 15, 1321–1330. [Google Scholar] [CrossRef]
- Lentzas, A.; Vrakas, D. Non-Intrusive Human Activity Recognition and Abnormal Behavior Detection on Elderly People: A Review. Artif. Intell. Rev. 2020, 53, 1975–2021. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-Aware Activity Recognition with Wearable Devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Kang, J.; Kim, J.; Lee, S.; Sohn, M. Transition Activity Recognition Using Fuzzy Logic and Overlapped Sliding Window-Based Convolutional Neural Networks. J. Supercomput. 2020, 76, 8003–8020. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Saligrama, V.; Konrad, J.; Jodoin, P.-M. Video Anomaly Identification. IEEE Signal Process. Mag. 2010, 27, 18–33. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series; Presses Universitaires de Louvain: Louvain-la-Neuve, Belgium, 2015; Volume 89, p. 94. [Google Scholar]
- Pate, R.R.; O’neill, J.R.; Lobelo, F. The Evolving Definition of “Sedentary”. Exerc. Sport Sci. Rev. 2008, 36, 173–178. [Google Scholar] [CrossRef] [PubMed]
- Zhai, L.; Zhang, Y.; Zhang, D. Sedentary Behaviour and the Risk of Depression: A Meta-Analysis. Br. J. Sports Med. 2015, 49, 705–709. [Google Scholar] [CrossRef]
- Arroyo, R.; Yebes, J.J.; Bergasa, L.M.; Daza, I.G.; Almazán, J. Expert Video-Surveillance System for Real-Time Detection of Suspicious Behaviors in Shopping Malls. Expert. Syst. Appl. 2015, 42, 7991–8005. [Google Scholar] [CrossRef]
- Popoola, O.P.; Wang, K. Video-Based Abnormal Human Behavior Recognition—A Review. IEEE Trans. Syst. Man Cybern. C 2012, 42, 865–878. [Google Scholar] [CrossRef]
- Stone, E.E.; Skubic, M. Fall Detection in Homes of Older Adults Using the Microsoft Kinect. IEEE J. Biomed. Health Inform. 2015, 19, 290–301. [Google Scholar] [CrossRef]
- Alam, E.; Sufian, A.; Dutta, P.; Leo, M. Vision-Based Human Fall Detection Systems Using Deep Learning: A Review. Comput. Biol. Med. 2022, 146, 105626. [Google Scholar] [CrossRef]
- Casilari-Pérez, E.; García-Lagos, F. A Comprehensive Study on the Use of Artificial Neural Networks in Wearable Fall Detection Systems. Expert. Syst. Appl. 2019, 138, 112811. [Google Scholar] [CrossRef]
- Rassekh, E.; Snidaro, L. Survey on Data Fusion Approaches for Fall-Detection. Inf. Fusion. 2025, 114, 102696. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In Pervasive Computing; Ferscha, A., Mattern, F., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Heidelberg, 2004; Volume 3001, pp. 1–17. ISBN 978-3-540-21835-7. [Google Scholar] [CrossRef]
- Bourke, A.K.; O’brien, J.V.; Lyons, G.M. Evaluation of a Threshold-Based Tri-Axial Accelerometer Fall Detection Algorithm. Gait Posture 2007, 26, 194–199. [Google Scholar] [CrossRef] [PubMed]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human Activity Recognition on Smartphones Using a Multiclass Hardware-Friendly Support Vector Machine. In Ambient Assisted Living and Home Care; Bravo, J., Hervás, R., Rodríguez, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Heidelberg, 2012; Volume 7657, pp. 216–223. ISBN 978-3-642-35394-9. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed]
- Plötz, T.; Hammerla, N.Y.; Olivier, P. Feature Learning for Activity Recognition in Ubiquitous Computing. In Proceedings of the IJCAI Proceedings-International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; Volume 22, p. 1729. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.-B. Human Activity Recognition with Smartphone Sensors Using Deep Learning Neural Networks. Expert. Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and Lstm Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Guan, Y.; Plötz, T. Ensembles of Deep LSTM Learners for Activity Recognition Using Wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Chen, L.; Li, R.; Zhang, H.; Tian, L.; Chen, N. Intelligent Fall Detection Method Based on Accelerometer Data from a Wrist-Worn Smart Watch. Measurement 2019, 140, 215–226. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A Semisupervised Recurrent Convolutional Attention Model for Human Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef]
- García, E.; Villar, M.; Fáñez, M.; Villar, J.R.; de la Cal, E.; Cho, S.-B. Towards Effective Detection of Elderly Falls with CNN-LSTM Neural Networks. Neurocomputing 2022, 500, 231–240. [Google Scholar] [CrossRef]
- Ignatov, A. Real-Time Human Activity Recognition from Accelerometer Data Using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Yhdego, H.; Li, J.; Morrison, S.; Audette, M.; Paolini, C.; Sarkar, M.; Okhravi, H. Towards Musculoskeletal Simulation-Aware Fall Injury Mitigation: Transfer Learning with Deep CNN for Fall Detection. In Proceedings of the 2019 Spring Simulation Conference (SpringSim), Tucson, AZ, USA, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Al-Qaness, M.A.; Dahou, A.; Abd Elaziz, M.; Helmi, A.M. Multi-ResAtt: Multilevel Residual Network with Attention for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Ind. Inform. 2022, 19, 144–152. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, L.; Min, F.; He, J. Multiscale Deep Feature Learning for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Ind. Electron. 2022, 70, 2106–2116. [Google Scholar] [CrossRef]
- An, S.; Bhat, G.; Gumussoy, S.; Ogras, U. Transfer Learning for Human Activity Recognition Using Representational Analysis of Neural Networks. ACM Trans. Comput. Healthc. 2023, 4, 1–21. [Google Scholar] [CrossRef]
- Zhou, Y.; Xie, J.; Zhang, X.; Wu, W.; Kwong, S. Energy-Efficient and Interpretable Multisensor Human Activity Recognition via Deep Fused Lasso Net. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 3576–3588. [Google Scholar] [CrossRef]
- Espinosa, R.; Ponce, H.; Gutiérrez, S.; Martínez-Villaseñor, L.; Brieva, J.; Moya-Albor, E. A Vision-Based Approach for Fall Detection Using Multiple Cameras and Convolutional Neural Networks: A Case Study Using the UP-Fall Detection Dataset. Comput. Biol. Med. 2019, 115, 103520. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, Y.-Z.; Jeng, Y.-L. Development of Home Intelligent Fall Detection IoT System Based on Feedback Optical Flow Convolutional Neural Network. IEEE Access 2017, 6, 6048–6057. [Google Scholar] [CrossRef]
- Carlier, A.; Peyramaure, P.; Favre, K.; Pressigout, M. Fall Detector Adapted to Nursing Home Needs through an Optical-Flow Based CNN. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5741–5744. [Google Scholar] [CrossRef]
- Chhetri, S.; Alsadoon, A.; Al-Dala’in, T.; Prasad, P.W.C.; Rashid, T.A.; Maag, A. Deep Learning for Vision-based Fall Detection System: Enhanced Optical Dynamic Flow. Comput. Intell. 2021, 37, 578–595. [Google Scholar] [CrossRef]
- Vishnu, C.; Datla, R.; Roy, D.; Babu, S.; Mohan, C.K. Human Fall Detection in Surveillance Videos Using Fall Motion Vector Modeling. IEEE Sens. J. 2021, 21, 17162–17170. [Google Scholar] [CrossRef]
- Cai, X.; Liu, X.; Li, S.; Han, G. Fall Detection Based on Colorization Coded Mhi Combining with Convolutional Neural Network. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 2 January 2020; IEEE: Piscataway, NJ, USA, 2019; pp. 1694–1698. [Google Scholar] [CrossRef]
- Fan, Y.; Levine, M.D.; Wen, G.; Qiu, S. A Deep Neural Network for Real-Time Detection of Falling Humans in Naturally Occurring Scenes. Neurocomputing 2017, 260, 43–58. [Google Scholar] [CrossRef]
- Solbach, M.D.; Tsotsos, J.K. Vision-Based Fallen Person Detection for the Elderly. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1433–1442. [Google Scholar] [CrossRef]
- Wu, J.; Wang, K.; Cheng, B.; Li, R.; Chen, C.; Zhou, T. Skeleton Based Fall Detection with Convolutional Neural Network. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5266–5271. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, D.; Yang, L.; Zhou, Z. Fall Detection and Recognition Based on Gcn and 2d Pose. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 558–562. [Google Scholar] [CrossRef]
- Chen, W.; Jiang, Z.; Guo, H.; Ni, X. Fall Detection Based on Key Points of Human-Skeleton Using Openpose. Symmetry 2020, 12, 744. [Google Scholar] [CrossRef]
- Wu, L.; Huang, C.; Fei, L.; Zhao, S.; Zhao, J.; Cui, Z.; Xu, Y. Video-Based Fall Detection Using Human Pose and Constrained Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2179–2194. [Google Scholar] [CrossRef]
- Doulamis, N. Vision Based Fall Detector Exploiting Deep Learning. In Proceedings of the 9th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu Island, Greece, 29 June 2016; ACM: New York, NY, USA, 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, Z.; Ma, X.; Wu, H.; Li, Y. Fall Detection in Videos with Trajectory-Weighted Deep-Convolutional Rank-Pooling Descriptor. IEEE Access 2018, 7, 4135–4144. [Google Scholar] [CrossRef]
- Carneiro, S.A.; da Silva, G.P.; Leite, G.V.; Moreno, R.; Guimaraes, S.J.F.; Pedrini, H. Multi-Stream Deep Convolutional Network Using High-Level Features Applied to Fall Detection in Video Sequences. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 293–298. [Google Scholar] [CrossRef]
- Wu, L.; Huang, C.; Zhao, S.; Li, J.; Zhao, J.; Cui, Z.; Yu, Z.; Xu, Y.; Zhang, M. Robust Fall Detection in Video Surveillance Based on Weakly Supervised Learning. Neural Netw. 2023, 163, 286–297. [Google Scholar] [CrossRef] [PubMed]
- Kong, X.; Chen, L.; Wang, Z.; Chen, Y.; Meng, L.; Tomiyama, H. Robust Self-Adaptation Fall-Detection System Based on Camera Height. Sensors 2019, 19, 3768. [Google Scholar] [CrossRef]
- Asif, U.; Mashford, B.; Von Cavallar, S.; Yohanandan, S.; Roy, S.; Tang, J.; Harrer, S. Privacy Preserving Human Fall Detection Using Video Data. In Proceedings of the Machine Learning for Health Workshop, PMLR, Virtual, 11 December 2020; pp. 39–51. [Google Scholar]
- Mobsite, S.; Alaoui, N.; Boulmalf, M.; Ghogho, M. Semantic Segmentation-Based System for Fall Detection and Post-Fall Posture Classification. Eng. Appl. Artif. Intell. 2023, 117, 105616. [Google Scholar] [CrossRef]
- Núñez-Marcos, A.; Arganda-Carreras, I. Transformer-Based Fall Detection in Videos. Eng. Appl. Artif. Intell. 2024, 132, 107937. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Z.; Dong, T. A Review of Wearable Technologies for Elderly Care That Can Accurately Track Indoor Position, Recognize Physical Activities and Monitor Vital Signs in Real Time. Sensors 2017, 17, 341. [Google Scholar] [CrossRef]
- Su, Y.; Liu, D.; Wu, Y. A Multi-Sensor Based Pre-Impact Fall Detection System with a Hierarchical Classifier. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1727–1731. [Google Scholar] [CrossRef]
- Wu, Y.; Su, Y.; Hu, Y.; Yu, N.; Feng, R. A Multi-Sensor Fall Detection System Based on Multivariate Statistical Process Analysis. J. Med. Biol. Eng. 2019, 39, 336–351. [Google Scholar] [CrossRef]
- Boutellaa, E.; Kerdjidj, O.; Ghanem, K. Covariance Matrix Based Fall Detection from Multiple Wearable Sensors. J. Biomed. Inform. 2019, 94, 103189. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A Review of Multimodal Human Activity Recognition with Special Emphasis on Classification, Applications, Challenges and Future Directions. Knowl. Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Galvão, Y.M.; Ferreira, J.; Albuquerque, V.A.; Barros, P.; Fernandes, B.J.T. A Multimodal Approach Using Deep Learning for Fall Detection. Expert. Syst. Appl. 2021, 168, 114226. [Google Scholar] [CrossRef]
- Shu, X.; Yang, J.; Yan, R.; Song, Y. Expansion-Squeeze-Excitation Fusion Network for Elderly Activity Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5281–5292. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Piccialli, F. FL-FD: Federated Learning-Based Fall Detection with Multimodal Data Fusion. Inf. Fusion. 2023, 99, 101890. [Google Scholar] [CrossRef]
- Islam, M.; Nooruddin, S.; Karray, F.; Muhammad, G. Multi-Level Feature Fusion for Multimodal Human Activity Recognition in Internet of Healthcare Things. Inf. Fusion. 2023, 94, 17–31. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the Esann, Bruges, Belgium, 24–26 April 2013; Volume 3, pp. 3–4. [Google Scholar]
- Reiss, A.; Stricker, D. Creating and Benchmarking a New Dataset for Physical Activity Monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion Crete, Greece, 6 June 2012; ACM: New York, NY, USA, 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A Daily Activity Dataset for Ubiquitous Activity Recognition Using Wearable Sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5 September 2012; ACM: New York, NY, USA, 2016; pp. 1036–1043. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Xue, B.; Zhou, M.; Ji, B.; Li, Y. Depth-Based Human Fall Detection via Shape Features and Improved Extreme Learning Machine. IEEE J. Biomed. Health Inform. 2014, 18, 1915–1922. [Google Scholar] [CrossRef]
- Vadivelu, S.; Ganesan, S.; Murthy, O.V.R.; Dhall, A. Thermal Imaging Based Elderly Fall Detection. In Computer Vision—ACCV 2016 Workshops; Chen, C.-S., Lu, J., Ma, K.-K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 10118, pp. 541–553. ISBN 978-3-319-54525-7. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A Short Note about Kinetics-600. arXiv 2018. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A Short Note on the Kinetics-700 Human Action Dataset. arXiv 2022. [Google Scholar] [CrossRef]
- Li, A.; Thotakuri, M.; Ross, D.A.; Carreira, J.; Vostrikov, A.; Zisserman, A. The AVA-Kinetics Localized Human Actions Video Dataset. arXiv 2020. [Google Scholar] [CrossRef]
- Smaira, L.; Carreira, J.; Noland, E.; Clancy, E.; Wu, A.; Zisserman, A. A Short Note on the Kinetics-700-2020 Human Action Dataset. arXiv 2020. [Google Scholar] [CrossRef]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. PKU-MMD: A Large Scale Benchmark for Continuous Multi-Modal Human Action Understanding. arXiv 2017. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A Large Video Database for Human Motion Recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2556–2563. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. Ntu Rgb+ d: A Large Scale Dataset for 3d Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and PATTERN Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 1010–1019. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.-Y.; Kot, A.C. Ntu Rgb+ d 120: A Large-Scale Benchmark for 3d Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota Smarthome: Real-World Activities of Daily Living. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Nogas, J.; Khan, S.S.; Mihailidis, A. DeepFall: Non-Invasive Fall Detection with Deep Spatio-Temporal Convolutional Autoencoders. J. Heal. Inf. Res. 2020, 4, 50–70. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 510–526. ISBN 978-3-319-46447-3. [Google Scholar] [CrossRef]
- Alzantot, M.; Chakraborty, S.; Srivastava, M. Sensegen: A Deep Learning Architecture for Synthetic Sensor Data Generation. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 188–193. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Gu, Y.; Xiao, Y.; Pan, H. Sensorygans: An Effective Generative Adversarial Framework for Sensor-Based Human Activity Recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-CGAN: Conditional Generative Adversarial Network for Data Augmentation in Noisy Time Series with Irregular Sampling. arXiv 2019. [Google Scholar] [CrossRef]
- Sultani, W.; Shah, M. Human Action Recognition in Drone Videos Using a Few Aerial Training Examples. Comput. Vis. Image Underst. 2021, 206, 103186. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting Sensory Data against Sensitive Inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems, Porto, Portugal, 23 April 2018; ACM: New York, NY, USA, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Sozinov, K.; Vlassov, V.; Girdzijauskas, S. Human Activity Recognition Using Federated Learning. In Proceedings of the 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, VIC, Australia, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1103–1111. [Google Scholar] [CrossRef]
- Li, C.; Niu, D.; Jiang, B.; Zuo, X.; Yang, J. Meta-HAR: Federated Representation Learning for Human Activity Recognition. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19 April 2021; ACM: New York, NY, USA, 2016; pp. 912–922. [Google Scholar] [CrossRef]
- Xiao, Z.; Xu, X.; Xing, H.; Song, F.; Wang, X.; Zhao, B. A Federated Learning System with Enhanced Feature Extraction for Human Activity Recognition. Knowl. Based Syst. 2021, 229, 107338. [Google Scholar] [CrossRef]
- Tu, L.; Ouyang, X.; Zhou, J.; He, Y.; Xing, G. FedDL: Federated Learning via Dynamic Layer Sharing for Human Activity Recognition. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra, Portugal, 15 November 2021; ACM: New York, NY, USA, 2016; pp. 15–28. [Google Scholar] [CrossRef]
- Rogalski, A.; Chrzanowski, K. Infrared Devices and Techniques. In Handbook of Optoelectronics; CRC Press: Boca Raton, FL, USA, 2017; pp. 633–686. [Google Scholar]
- Doukas, C.N.; Maglogiannis, I. Emergency Fall Incidents Detection in Assisted Living Environments Utilizing Motion, Sound, and Visual Perceptual Components. IEEE Trans. Inf. Technol. Biomed. 2010, 15, 277–289. [Google Scholar] [CrossRef]
- Gjoreski, M.; Gjoreski, H.; Luštrek, M.; Gams, M. How Accurately Can Your Wrist Device Recognize Daily Activities and Detect Falls? Sensors 2016, 16, 800. [Google Scholar] [CrossRef] [PubMed]
- Seneviratne, S.; Hu, Y.; Nguyen, T.; Lan, G.; Khalifa, S.; Thilakarathna, K.; Hassan, M.; Seneviratne, A. A Survey of Wearable Devices and Challenges. IEEE Commun. Surv. Tutor. 2017, 19, 2573–2620. [Google Scholar] [CrossRef]
- Casilari, E.; Álvarez-Marco, M.; García-Lagos, F. A Study of the Use of Gyroscope Measurements in Wearable Fall Detection Systems. Symmetry 2020, 12, 649. [Google Scholar] [CrossRef]
- Homayounfar, S.Z.; Andrew, T.L. Wearable Sensors for Monitoring Human Motion: A Review on Mechanisms, Materials, and Challenges. SLAS Technol. 2020, 25, 9–24. [Google Scholar] [CrossRef]
- Luo, Y.; Abidian, M.R.; Ahn, J.-H.; Akinwande, D.; Andrews, A.M.; Antonietti, M.; Bao, Z.; Berggren, M.; Berkey, C.A.; Bettinger, C.J.; et al. Technology Roadmap for Flexible Sensors. ACS Nano 2023, 17, 5211–5295. [Google Scholar] [CrossRef]
- Bhat, G.; Tuncel, Y.; An, S.; Lee, H.G.; Ogras, U.Y. An Ultra-Low Energy Human Activity Recognition Accelerator for Wearable Health Applications. ACM Trans. Embed. Comput. Syst. 2019, 18, 1–22. [Google Scholar] [CrossRef]
- Islam, B.; Nirjon, S. Zygarde: Time-Sensitive On-Device Deep Inference and Adaptation on Intermittently-Powered Systems. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–29. [Google Scholar] [CrossRef]
- Dibble, J.; Bazzocchi, M.C. Bi-Modal Multiperspective Percussive (BiMP) Dataset for Visual and Audio Human Fall Detection. IEEE Access 2025, 13, 26782–26797. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage of Development | Approaches | Advantages | Disadvantages |
|---|---|---|---|
| Early stage | Simple classifier [46] and threshold [47] | High computing efficiency. Simple implementation, suitable for resource-constrained devices. | Insufficient generalization performance and poor effect in complex scenarios. Relying on manually set thresholds, with poor adaptability. |
| Machine learning stage | Traditional machine learning model [48] and manual feature extraction [49] | The recognition accuracy is improved compared to the threshold method. The expression ability is enhanced by combining time-frequency domain features. | Feature extraction relies on manual design, which is time-consuming and may miss deep information. Insufficient capture of long-term dependencies on time series. |
| Deep learning stage | Deep learning models (CNN [50,51], LSTM [53], hybrid models [52,55,56]) | Automatically extract features to reduce manual intervention. End-to-end learning to enhance accuracy and robustness. Supports multimodal data fusion. | High demand for computing resources. Reliance on a large amount of labeled data. High model complexity and difficult deployment. |
| Lightweight and cross-domain optimization stage | Model compression [60], transfer learning [58,61], and attention mechanism [59,62] | High real-time performance, suitable for mobile devices. Strong adaptability across users/devices. Reduces the need for data preprocessing and feature engineering. | Model lightweighting may sacrifice some performance. Transfer learning relies on the data distribution of pre-trained models. Some methods still need to adjust user-specific parameters. |
| Method Type | Advantages | Disadvantages |
|---|---|---|
| Traditional approach [64,65,66,67,68] | The calculation is transparent, and the implementation is simple. | The ability to express features is limited. |
| Dynamic features that rely on manual design do not require complex models and have lower computational costs. | Poor adaptability: Insufficient robustness to complex scenarios such as illumination changes and multi-object interactions. | |
| Deep learning approach [69,70,71,72,73,74,75,76,77,78,79,80,81,82] | Powerful spatiotemporal modeling capability: Automatic feature extraction. | High computing cost: Complex networks require a large amount of resources and are difficult to deploy in real time. |
| Reduce data requirements through self-supervised or weakly supervised learning | Poor interpretability: The decision-making of the black box model lacks transparency. | |
| Insufficient robustness: The performance of the RGB algorithm declines under complex lighting conditions, and the skeleton method is limited by the accuracy of pose estimation. |
| Data Source | Method | Proposer | Core Technology | Targeted Problem |
|---|---|---|---|---|
| Infrared | AIR-Net | Munsif et al. [15] | EfficientNetB7 + CBAM (Convolutional Block Attention Module) + BiLSTM (Bidirectional Long and Short-Term Memory); Fine-tune InceptionV3 to extract scene context information | Infrared images are blurred, have missing textures and insufficient feature extraction, and inadequately use context information. |
| Radar | PCC-DT | Wang et al. [16] | The threshold determines the high power density region; Hampel filter denoising | The DT (Doppler time) diagram has many redundant information and large noise interference, which leads to detection errors. |
| WIFI | WiFall | Wang et al. [17] | CSI (Channel State Information) time-frequency features + weighted moving average noise reduction + SVD (Singular Value Decomposition) dimensionality reduction + SVM / random forest | Detection falls based on WiFi signal and daily activities. |
| - | Wang et al. [18] | CSI phase difference ratio + time-frequency domain power steep drop mode | Automatic segmentation and detection of falls during natural continuous activity. | |
| ABLSTM | Chen et al. [19] | Bidirectional LSTM + attention mechanism-weighted features | Differential in feature contribution of passive activity recognition in WiFi CSI signal. | |
| FallDar | Yang et al. [20] | Human trunk speed characteristics + VAE (DNN-based Generative Model) generated adversarial data + adversarial learning de-identity information | The influence of environmental diversity, action diversity, and user diversity on WiFi detection. | |
| RFID | TagCare | Jalal et al. [21] | RSS (Received Signal Sntensity) static detection + DFV (Doppler Frequency Values) mutation detection; wavelet denoising + SVM classification | Passive RFID tag detects the status of the elderly living alone and improves the accuracy of fall identification. |
| Depth | Multi-fusion features of an online HAR system | Zhu et al. [22] | Depth contour + skeletal joint features (trunk distance, joint angle, etc.) + vector quantification + HMM (Hidden Markov Model) online identification | Online activity segmentation and recognition, fusion of space-time multi-features to improve robustness. |
| Dataset | Device | Activity Category | Subjects | Characteristic |
|---|---|---|---|---|
| UCI HAR [92] | Smartphone (accelerometer + gyroscope) | 6 | 30 | Manual annotation, clear division, basic action recognition support |
| PAMAP2 [93,94] | IMU+ heart rate monitor | 18 | 9 | Supporting activity identification and intensity estimation, containing multimodal data |
| USC-HAD [95] | MotionNode (accelerometer + gyroscope + magnetometer) | 12 | 14 | Support for indoor and outdoor scenes, and provide MATLAB analysis tools |
| WISDM [96] | Smartphone (accelerometer) | 6 | 29 | The goal is to classify daily activities with a moderate amount of data |
| Dataset | Modalities | Activity Categories | The Number of Videos | Characteristic |
|---|---|---|---|---|
| URFD [97] | D | 2(Fall+ADL) | 70 | Contains empty frames and characters in the scene for fall detection. |
| SDU [98] | D | 6(Fall+ADL) | 1197 | Generates a 163,573-window training model with empty frames and characters in and out of scenes. |
| Thermal [99] | Thermal imagery | 2(Fall+ADL) | 44 | Thermal imaging data, containing a large number of empty frames and characters entering the scene. |
| Kinetics [100,101,102,103,104] | RGB | 400–700 | >10,000 | Covers a wide range of human-interactive movements, suitable for complex action recognition. |
| PKU-MMD [105] | RGB+D+IR+Skeleton | 51 (Phase1)/49 (Phase2) | 1076 | Multi-view, long continuous sequence, supporting action detection and multimodal analysis. |
| HMDB51 [106] | RGB | 51 | 6849 | Challenges to the camera motion, need to align frames, labeled according to action category and scene attributes. |
| NTU RGB+D [107,108] | RGB+D+IR+Skeleton | 60→120 | 56,880→114,480 | High environmental diversity and support for multimodal action recognition. |
| Toyota Smarthomes [109] | RGB+D+Skeleton | 31 | 16,115 | Real family activity scene, including object interaction, multi-perspective coverage. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, T.; Tang, M. Indoor Abnormal Behavior Detection for the Elderly: A Review. Sensors 2025, 25, 3313. https://doi.org/10.3390/s25113313
Gu T, Tang M. Indoor Abnormal Behavior Detection for the Elderly: A Review. Sensors. 2025; 25(11):3313. https://doi.org/10.3390/s25113313
Chicago/Turabian StyleGu, Tianxiao, and Min Tang. 2025. "Indoor Abnormal Behavior Detection for the Elderly: A Review" Sensors 25, no. 11: 3313. https://doi.org/10.3390/s25113313
APA StyleGu, T., & Tang, M. (2025). Indoor Abnormal Behavior Detection for the Elderly: A Review. Sensors, 25(11), 3313. https://doi.org/10.3390/s25113313