
A Method for Predicting Coal-Mine Methane Outburst Volumes and Detecting Anomalies Based on a Fusion Model of Second-Order Decomposition and ETO-TSMixer


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Preprocessing
2.1.1. Data Cleaning
2.1.2. Data Smoothing
2.2. Mode Decomposition
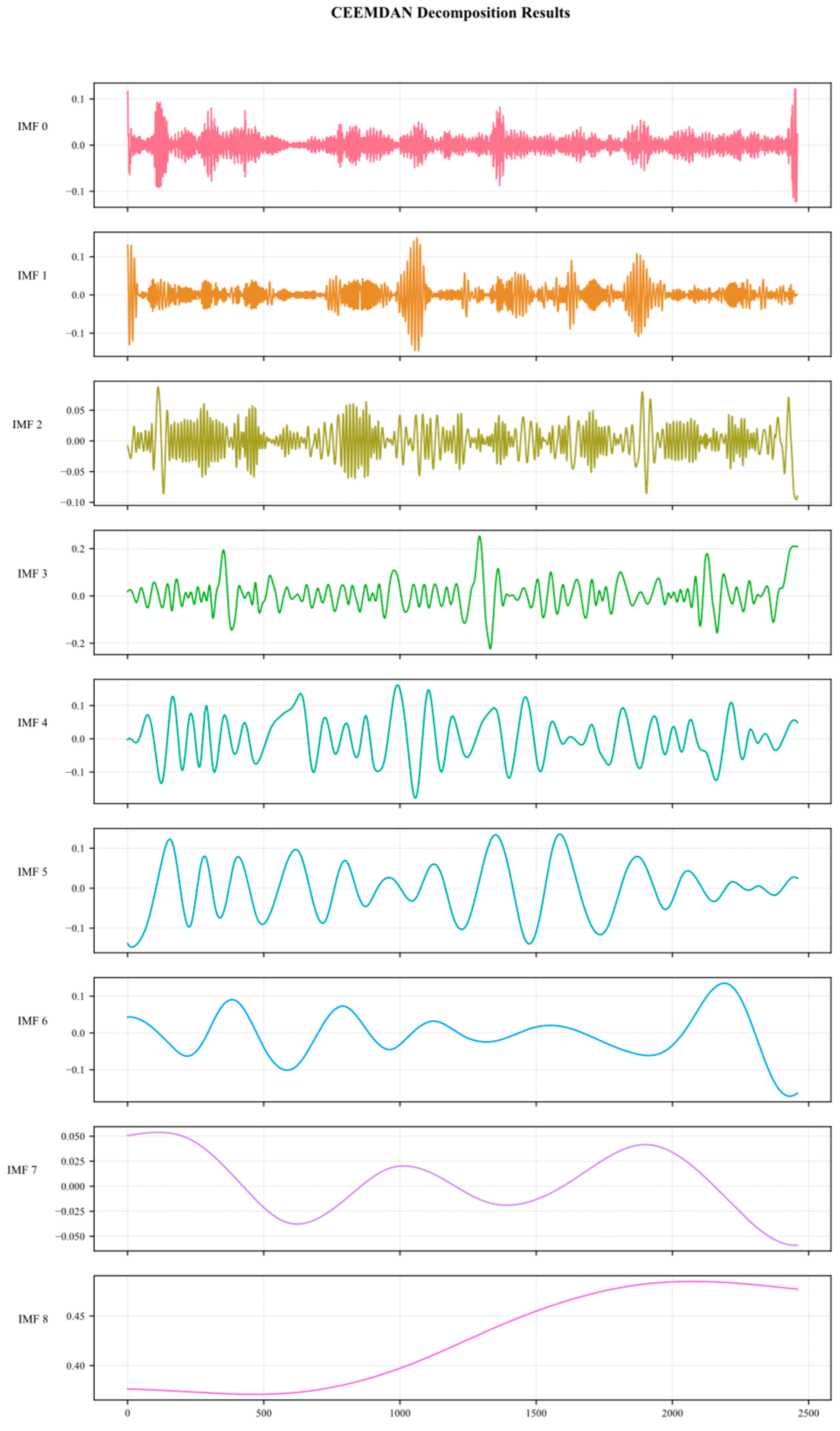
2.2.1. CEEMDAN
2.2.2. K-Means
2.2.3. VMD
2.2.4. ETO Algorithm
- (1)
- Constraint Exploration Strategy
- (2)
- Initialization and Population Generation
- (3)
- Exploration Mechanism
- (4)
- Development Mechanism
- (5)
- Exploration–Development Adaptive Transition
2.3. Time Series Model
2.4. Anomaly Detection in Lonely Forest
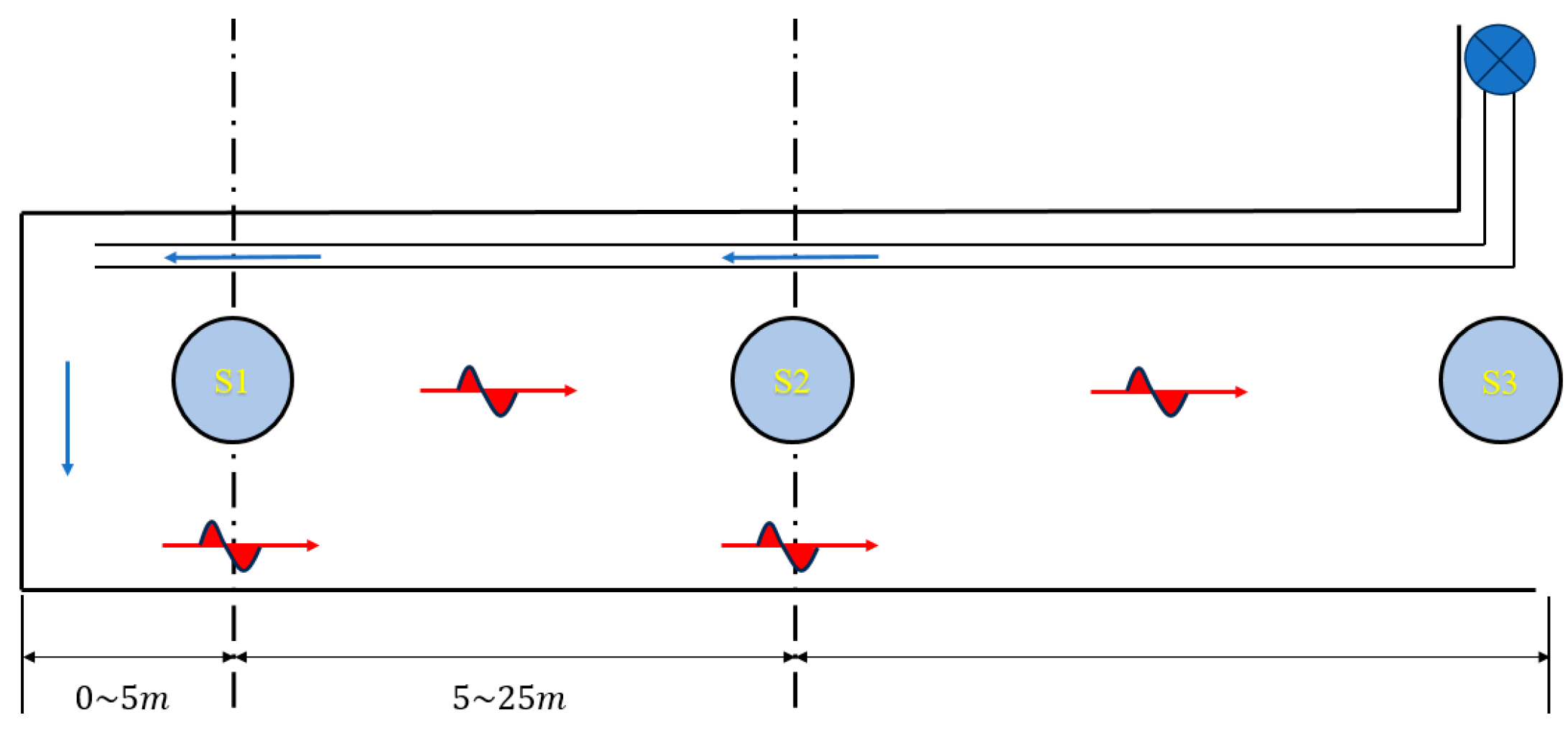
2.5. Optimal Deployment of Gas Monitoring Sensors in Roadway Headings
3. Results and Discussion
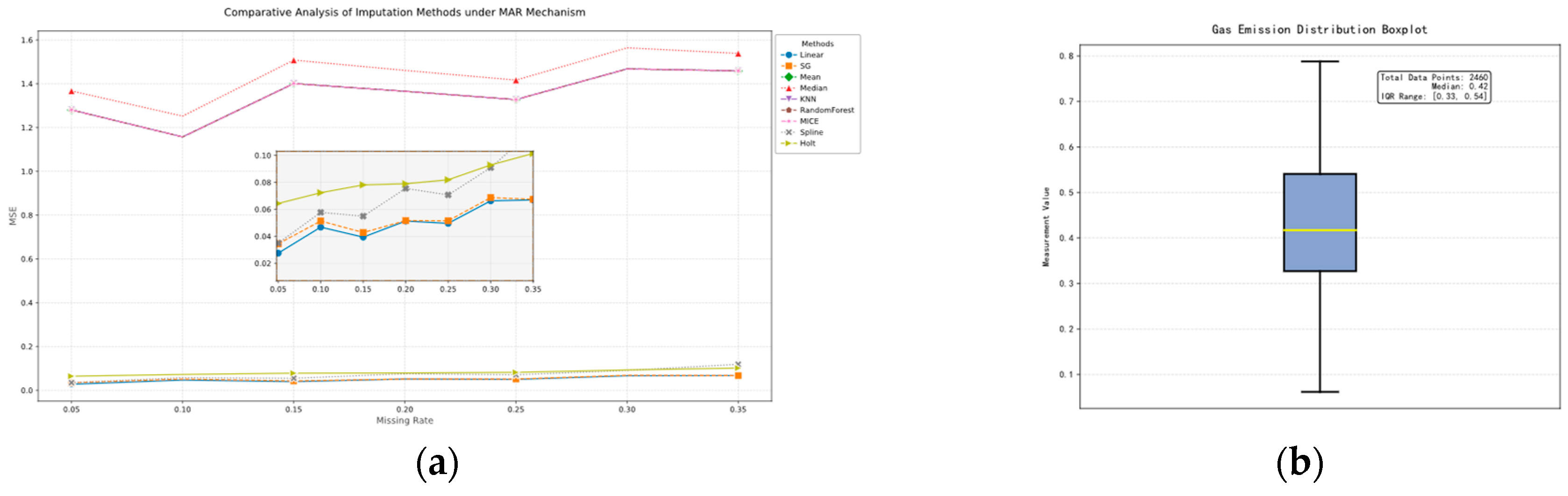
3.1. Data Collection and Preprocessing
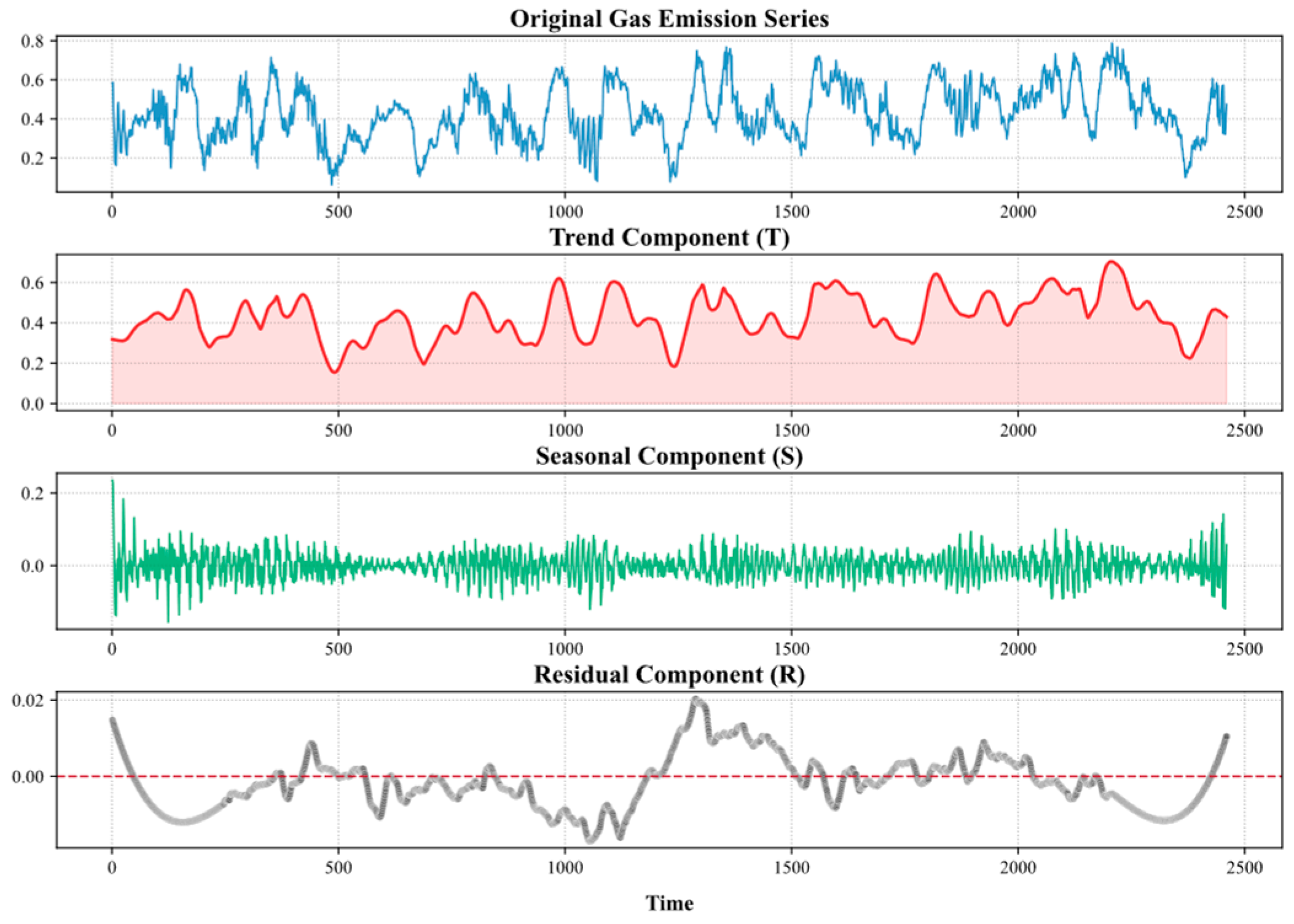
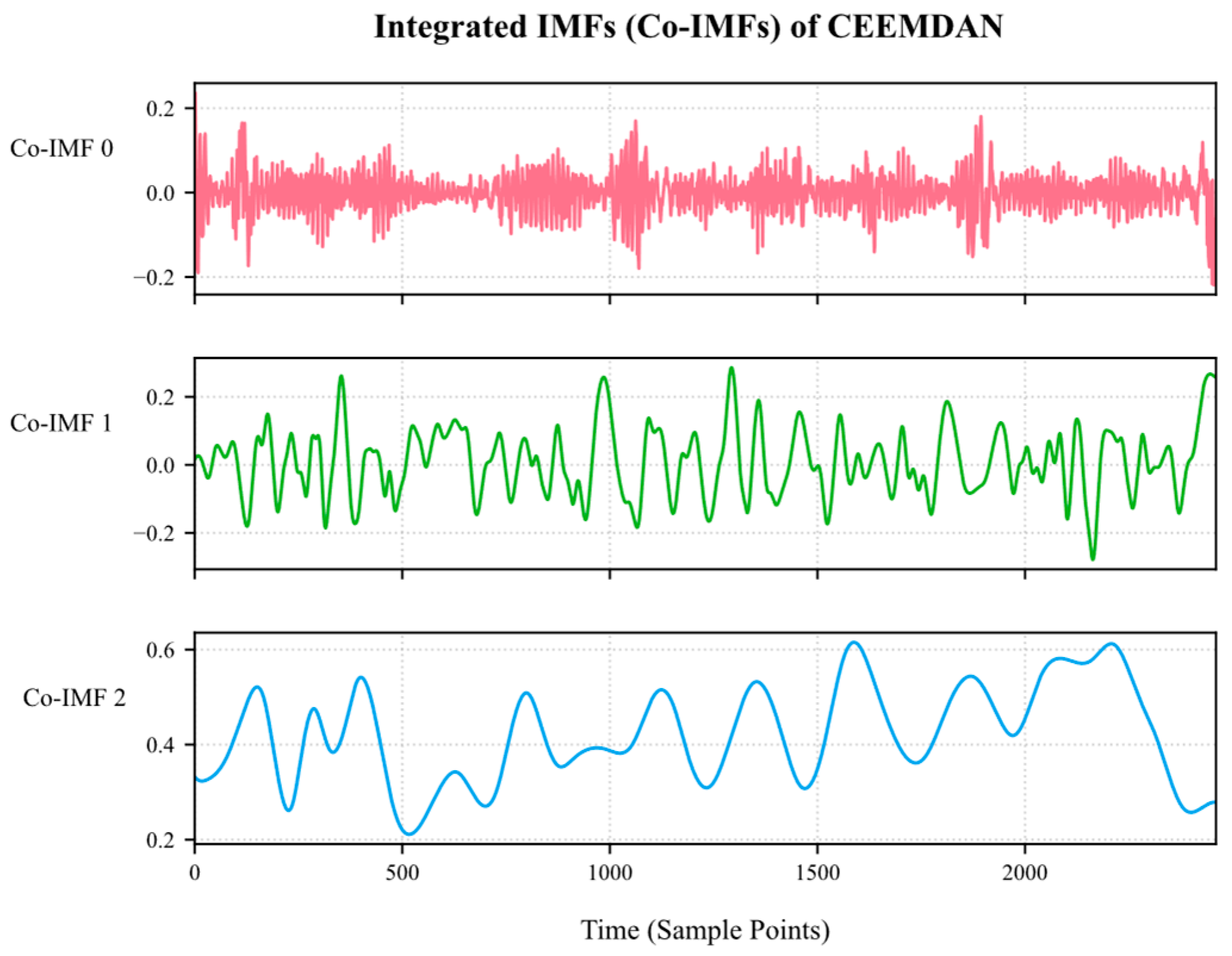
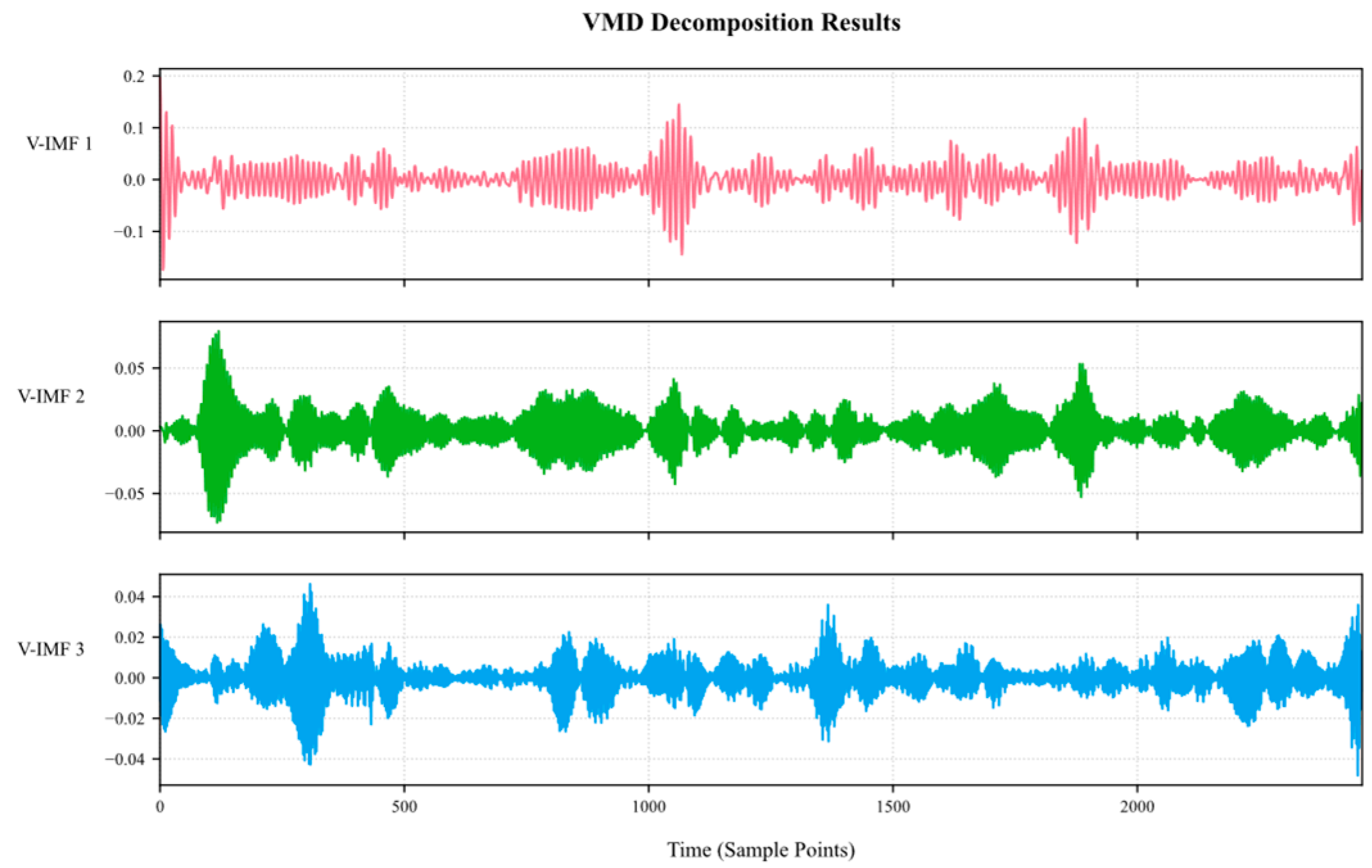
3.2. Time Series Decomposition of Gas Emission Data
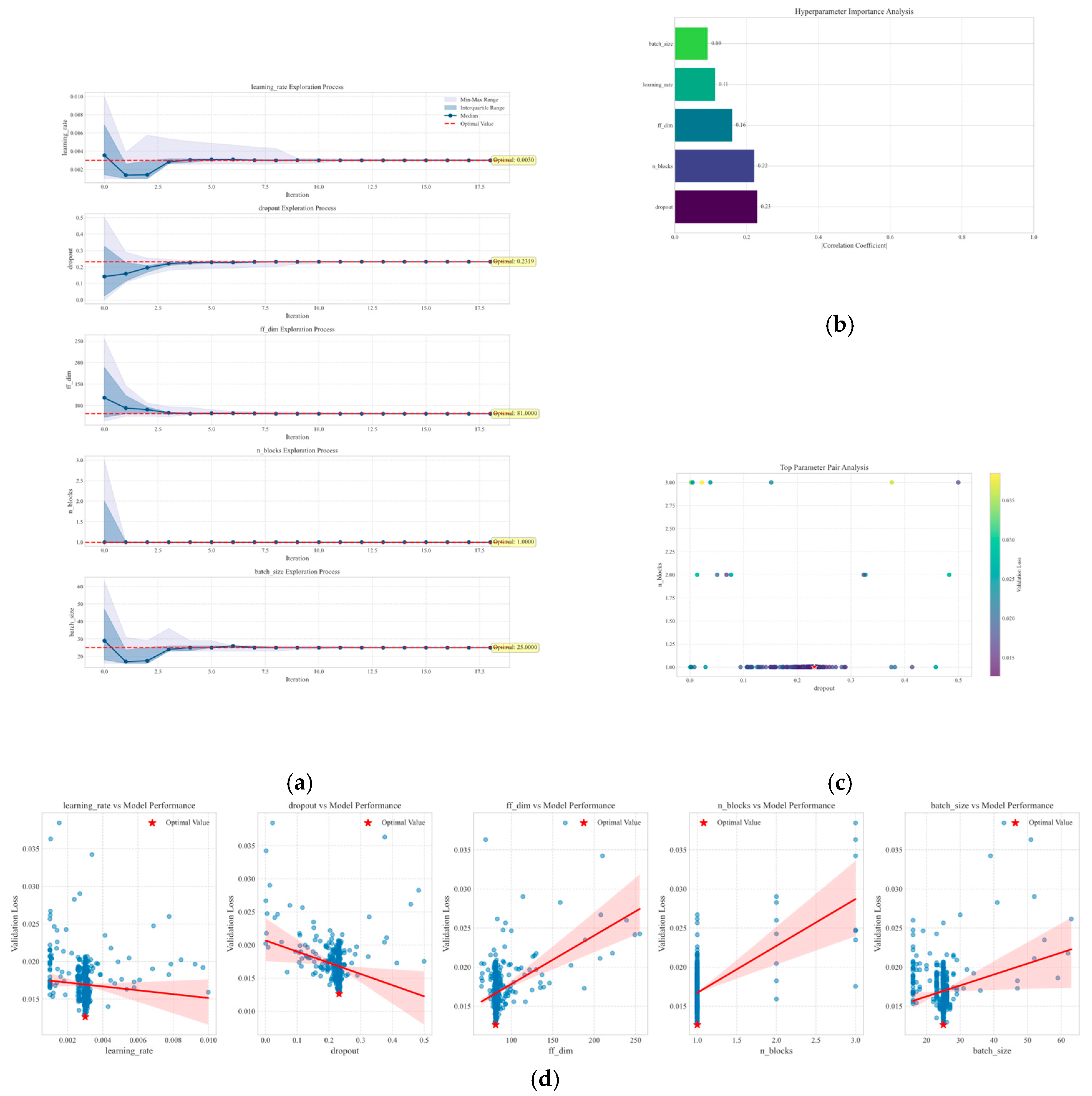
3.3. ETO of TSMixer Model
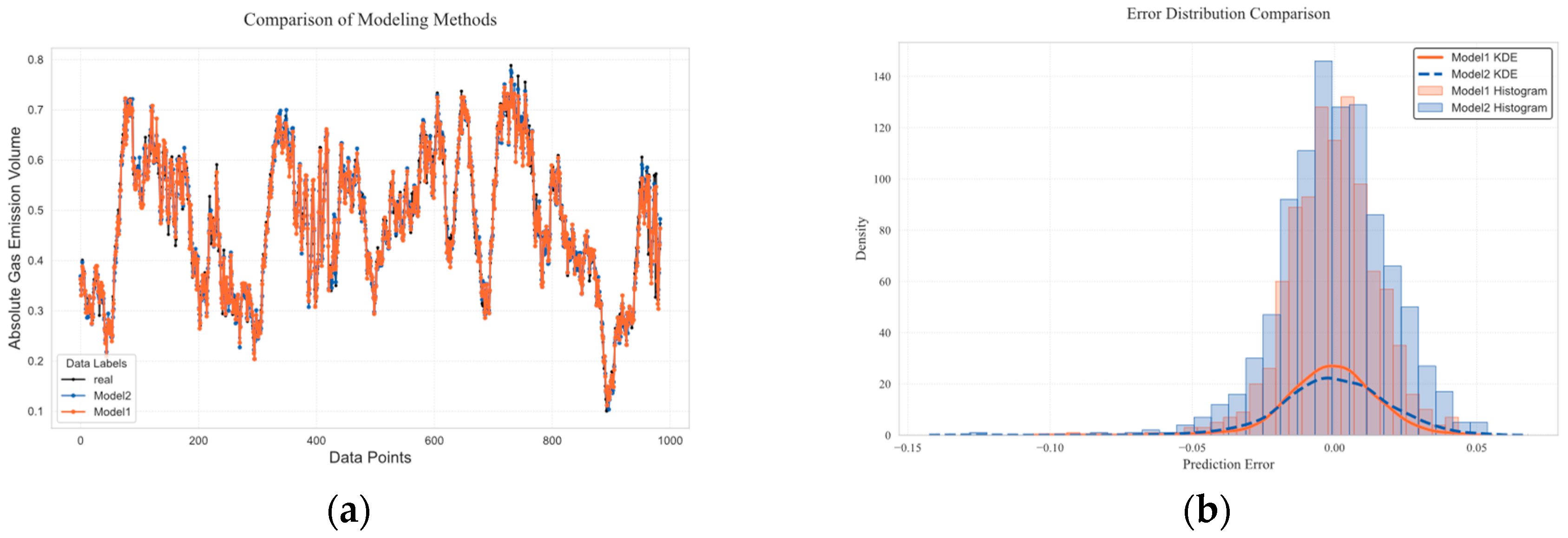
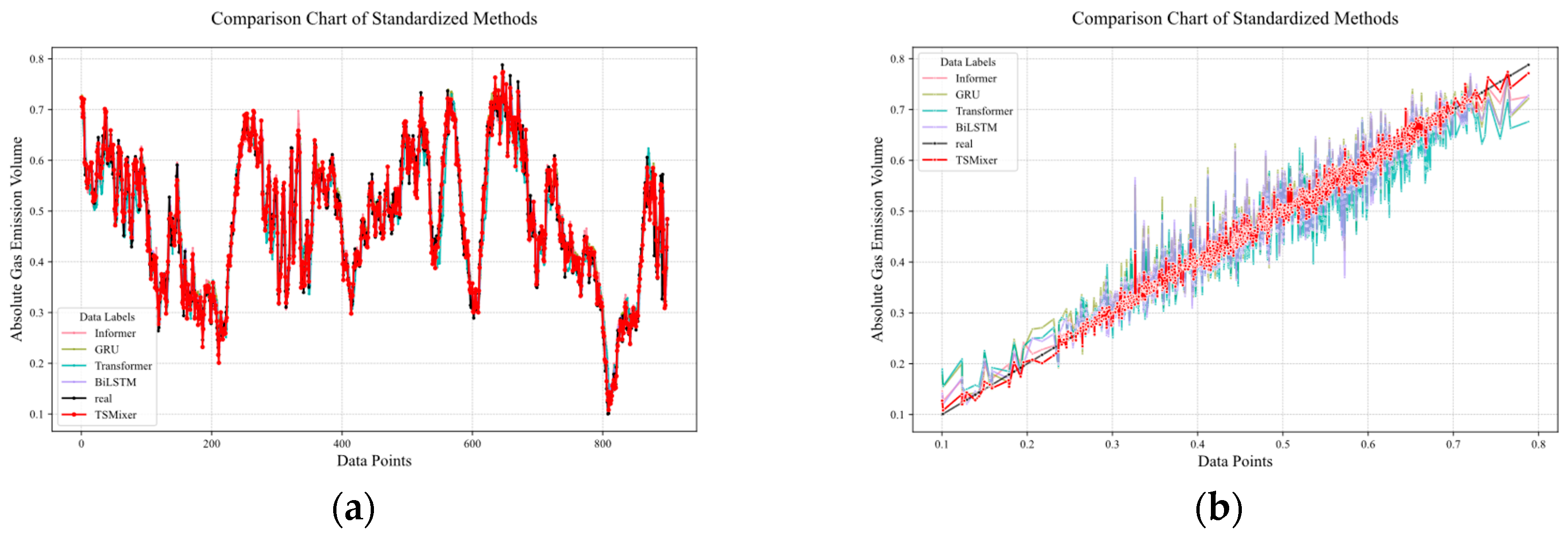
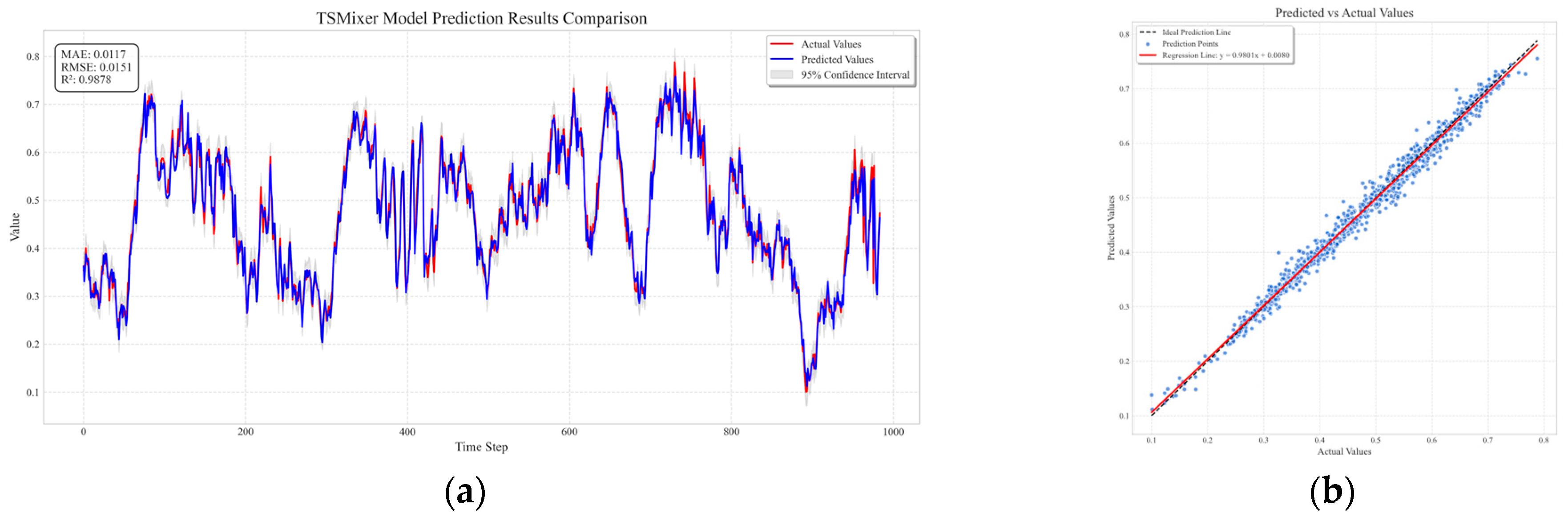
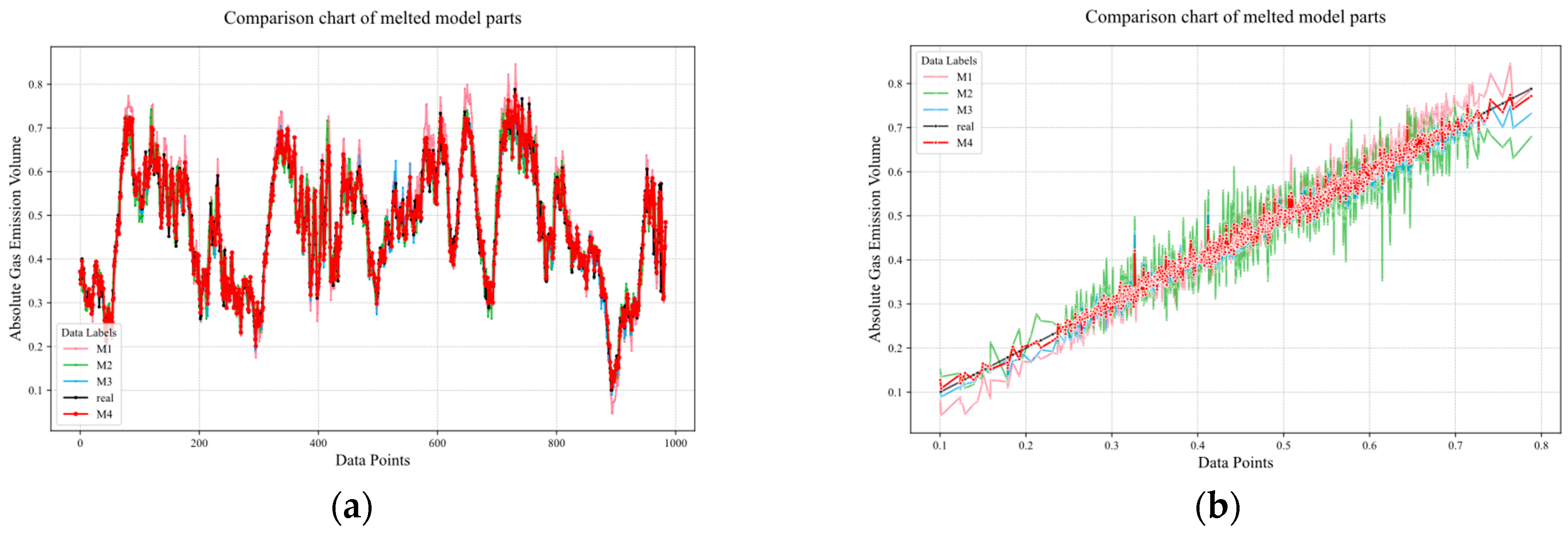
3.4. Time-Series Prediction Model for Gas Emission Forecasting
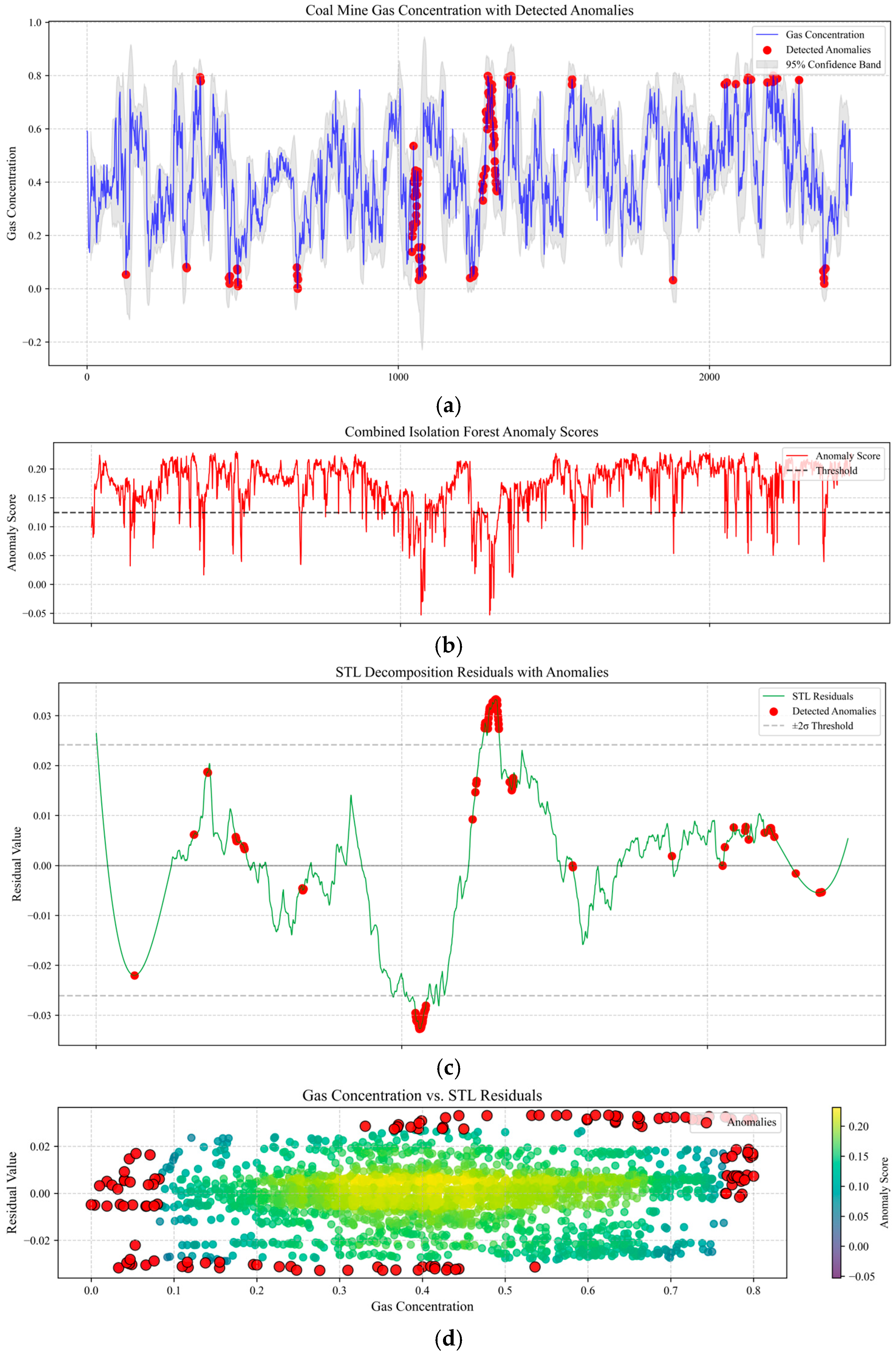
3.5. Unsupervised Early-Warning Model for Time Series
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, C.; Cheng, Y. Role of coal deformation energy in coal and gas outburst: A review. Fuel 2023, 332, 126019. [Google Scholar] [CrossRef]
- Li, L.; Kong, D.; Liu, Q.; Xiong, Y.; Chen, F.; Zhang, H.; Chu, Y. Comprehensive identification of surface subsidence evaluation grades of mines in southwest China. Mathematics 2022, 10, 2664. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, K.; Reniers, G.; You, G. Statistical analysis the characteristics of extraordinarily severe coal mine accidents (ESCMAs) in China from 1950 to 2018. Process. Saf. Environ. Prot. 2020, 133, 332–340. [Google Scholar] [CrossRef]
- Xiong, Y.; Kong, D.; Cheng, Z.; Wu, G.; Zhang, Q. The comprehensive identification of roof risk in a fully mechanized working face using the cloud model. Mathematics 2021, 9, 2072. [Google Scholar] [CrossRef]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A review of deep learning models for time series prediction. IEEE Sens. J. 2019, 21, 7833–7848. [Google Scholar] [CrossRef]
- Xue, S.; Zheng, X.; Yuan, L.; Lai, W.; Zhang, Y. A review on coal and gas outburst prediction based on machine learning. J. China Coal Soc. 2024, 49, 664–694. [Google Scholar]
- Karacan, C.Ö. Forecasting gob gas venthole production performances using intelligent computing methods for optimum methane control in longwall coal mines. Int. J. Coal Geol. 2009, 79, 131–144. [Google Scholar] [CrossRef]
- Krzemień, A. Fire risk prevention in underground coal gasification (UCG) within active mines: Temperature forecast by means of MARS models. Energy 2019, 170, 777–790. [Google Scholar] [CrossRef]
- Dey, P.; Chaulya, S.K.; Kumar, S. Hybrid CNN-LSTM and IoT-based coal mine hazards monitoring and prediction system. Process Saf. Environ. Prot. 2021, 152, 249–263. [Google Scholar] [CrossRef]
- Niu, Y.; Wang, E.; Li, Z.; Gao, F.; Zhang, Z.; Li, B.; Zhang, X. Identification of coal and gas outburst-hazardous zones by electric potential inversion during mining process in deep coal seam. Rock Mech. Rock Eng. 2022, 55, 3439–3450. [Google Scholar] [CrossRef]
- Wang, W.; Cui, X.; Qi, Y.; Xue, K.; Liang, R.; Bai, C. Prediction model of coal gas permeability based on improved DBO optimized BP neural network. Sensors 2024, 24, 2873. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Zhang, X.; Zhang, T.; Li, Z. A Graph Convolutional Encoder-Decoder Model for Methane Concentration Forecasting in Coal Mines. IEEE Access 2023, 11, 72665–72678. [Google Scholar] [CrossRef]
- Xue, H.; Gui, X.; Wang, G.; Yang, X.; Gong, H.; Du, F. Prediction of gas drainage changes from nitrogen replacement: A study of a TCN deep learning model with integrated attention mechanism. Fuel 2024, 357, 129797. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, Z.; Yan, Z.; Deng, J.; Huang, Y.; Zhang, L.; Cao, Y.; Wang, Y. Research on Coal and Gas Outburst Prediction and Sensitivity Analysis Based on an Interpretable Ali Baba and the Forty Thieves–Transformer–Support Vector Machine Model. Fire 2025, 8, 37. [Google Scholar] [CrossRef]
- Huang, Y.; Yan, L.; Cheng, Y.; Qi, X.; Li, Z. Coal thickness prediction method based on VMD and LSTM. Electronics 2022, 11, 232. [Google Scholar] [CrossRef]
- Xu, N.; Wang, X.; Meng, X.; Chang, H. Gas concentration prediction based on IWOA-LSTM-CEEMDAN residual correction model. Sensors 2022, 22, 4412. [Google Scholar] [CrossRef] [PubMed]
- Ji, P.; Shi, S.; Shi, X. Research on early warning of coal and gas outburst based on HPO-BiLSTM. IEEE Trans. Instrum. Meas. 2023, 72, 1–8. [Google Scholar] [CrossRef]
- Yu, K.; Zhou, L.; Jin, W.; Chen, Y. Prediction of coal mine risk based on BN-ELM: Gas risk early warning including human factors. Resour. Policy 2024, 98, 105295. [Google Scholar] [CrossRef]
- Blu, T.; Thévenaz, P.; Unser, M. Linear interpolation revitalized. IEEE Trans. Image Process. 2004, 13, 710–719. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, J.; Jiang, S. Forecasting the short-term metro ridership with seasonal and trend decomposition using loess and LSTM neural networks. IEEE Access 2020, 8, 91181–91187. [Google Scholar] [CrossRef]
- Schafer, R.W. What is a savitzky-golay filter? [lecture notes]. IEEE Signal Process. Mag. 2011, 28, 111–117. [Google Scholar] [CrossRef]
- Lv, Y.; Yuan, R.; Wang, T.; Li, H.; Song, G. Health degradation monitoring and early fault diagnosis of a rolling bearing based on CEEMDAN and improved MMSE. Materials 2018, 11, 1009. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, L.; Ni, C. Chatter detection in milling process based on VMD and energy entropy. Mech. Syst. Signal Process. 2018, 105, 169–182. [Google Scholar] [CrossRef]
- Luan, T.M.; Khatir, S.; Tran, M.T.; De Baets, B.; Cuong-Le, T. Exponential-trigonometric optimization algorithm for solving complicated engineering problems. Comput. Methods Appl. Mech. Eng. 2024, 432, 117411. [Google Scholar] [CrossRef]
- Chen, S.; Li, C.; Yoder, N.; Arik, S.O.; Pfister, T. Tsmixer: An all-mlp architecture for time series forecasting. arXiv 2023, arXiv:2303.06053. [Google Scholar]
- Xu, H.; Pang, G.; Wang, Y.; Wang, Y. Deep isolation forest for anomaly detection. IEEE Trans. Knowl. Data Eng. 2023, 35, 12591–12604. [Google Scholar] [CrossRef]
- Lin, H.; Liu, S.; Zhou, J.; Xu, P.; Shuang, H. Prediction method and application of gas emission from mining workface based on STL-EEMD-GA-SVR. Coal Geol. Explor. 2022, 50, 14. [Google Scholar]
- Zou, Y.; Deng, G.; Zhang, Q.; Zhao, X. Discussion of layout position of gas emission warning sensor in heading face. Ind. Mine Autom. 2013, 39, 44–47. [Google Scholar]
- Srimani, S.; Parai, M.; Ghosh, K.; Rahaman, H. A statistical approach of analog circuit fault detection utilizing kolmogorov–smirnov test method. Circuits Syst. Signal Process. 2021, 40, 2091–2113. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE | MAE | MSE | |
|---|---|---|---|---|
| M1 | 0.024490 | 0.018685 | 0.000599 | 0.977127 |
| M2 | 0.029455 | 0.022865 | 0.000867 | 0.953183 |
| M3 | 0.018559 | 0.014061 | 0.000344 | 0.981404 |
| M4 | 0.015060 | 0.011677 | 0.000226 | 0.987754 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Q.; Li, C.; Yang, B.; Yan, Z.; Qin, Z. A Method for Predicting Coal-Mine Methane Outburst Volumes and Detecting Anomalies Based on a Fusion Model of Second-Order Decomposition and ETO-TSMixer. Sensors 2025, 25, 3314. https://doi.org/10.3390/s25113314
Zheng Q, Li C, Yang B, Yan Z, Qin Z. A Method for Predicting Coal-Mine Methane Outburst Volumes and Detecting Anomalies Based on a Fusion Model of Second-Order Decomposition and ETO-TSMixer. Sensors. 2025; 25(11):3314. https://doi.org/10.3390/s25113314
Chicago/Turabian StyleZheng, Qiangyu, Cunmiao Li, Bo Yang, Zhenguo Yan, and Zhixin Qin. 2025. "A Method for Predicting Coal-Mine Methane Outburst Volumes and Detecting Anomalies Based on a Fusion Model of Second-Order Decomposition and ETO-TSMixer" Sensors 25, no. 11: 3314. https://doi.org/10.3390/s25113314
APA StyleZheng, Q., Li, C., Yang, B., Yan, Z., & Qin, Z. (2025). A Method for Predicting Coal-Mine Methane Outburst Volumes and Detecting Anomalies Based on a Fusion Model of Second-Order Decomposition and ETO-TSMixer. Sensors, 25(11), 3314. https://doi.org/10.3390/s25113314