1. Introduction
As an information carrier for understanding and perceiving the underwater environment, underwater images play an important role in marine resource exploration, marine biodiversity research, underwater rescue, target identification, real-time tracking, etc. However, underwater images are often affected by light absorption and scattering caused by particles in the water, which can significantly reduce the color and contrast of underwater images. In addition, light of different wavelengths can also affect the quality of imaging. Due to the poor underwater imaging environment, color casts, color artifacts, and blurred details are common, even in high-end cameras. Underwater image enhancement technology was invented to improve the quality of underwater images. Therefore, the use of underwater image enhancement technology to obtain clear underwater images plays a vital role in various fields such as scientific research and resource development. Existing underwater image enhancement methods are generally divided into three categories: methods based on traditional physical models, methods based on visual priors, and methods based on deep learning.
Traditional physical models can enhance underwater images of specific scenes. He, K., Sun, J., & Tang, X et al. [
1] proposed a single-image dehazing method based on dark channel prior, which effectively removed the haze of underwater images by simulating the atmospheric scattering model. Drews, P., Nascimento, et al. [
2] proposed an algorithm for estimating underwater image transmission using the atmospheric scattering model, which effectively improved the clarity and contrast of the image. Although the physical model-based method can restore the appearance of underwater images, it relies on specific parameter estimation and cannot distinguish between texture detail information and noise in the image. While improving image details, it also inevitably increases noise. For images with uneven lighting, fog, high noise, etc., local areas are prone to over-enhancement, while background areas are prone to under-enhancement. The visual prior-based method ignores the physical model and improves the image visual quality by adjusting the image pixel values of contrast, brightness and saturation to comprehensively evaluate the image quality. Zhang et al. [
3] proposed an enhancement method based on Retinex theory. By applying filters to each component in the Lab color space, they successfully eliminated noise and halo artifacts in the image, significantly improving the image quality. Drews, P., Nascimento, E., et al. [
4] proposed an image restoration method based on depth estimation, which removes turbidity and improves image quality by estimating the depth of underwater scenes. Although it has strong adaptability and robustness and can provide consistent results in complex environments, its effect may be limited by specific prior knowledge or statistical characteristics, and may not perform as expected in low-contrast or high-noise images, resulting in artifacts, color deviation, oversaturation, and other problems in the generated images.
In recent years, more and more researchers have begun to build different deep learning model structures and have achieved good results and high efficiency. Most of the underwater image enhancement methods based on deep learning [
5] are centered on end-to-end models and use pairs of degraded underwater images and high-quality corresponding images to train the model to effectively enhance the image contrast and correct the image color. However, after a large number of experiments on challenging datasets, we found that some methods often lead to blurred images or introduce unrealistic color changes. This is because the model ignores certain information under its powerful correction ability. Convolutional neural network [
6] is the most classic network in computer vision. Underwater images are enhanced using a convolutional neural network. Although convolutional networks can effectively achieve high-precision local enhancement, it is difficult for convolution to model global long-range relationships, which seriously limits the development of underwater image enhancement tasks. To address the above problems, some articles use the self-attention module of Transformer [
7] to expand the model’s ability to capture global long-range relationships. However, although Transformer has shown excellent performance in visual tasks, it lacks effective inductive bias and cannot encode the two-dimensional position information of the image. It needs to embed relative or absolute position encoding, which may lead to its encoding and generalization capabilities being inferior to convolutional networks. We believe that there are four reasons for this weakening. First, Transformer can effectively handle the dependencies between tokens, but its complexity is quadratic with the resolution of the image, that is,
, which can easily lead to insufficient GPU memory, low computational efficiency, and long training time. Secondly, due to the lack of interaction between windows in the square window of Transformer, the receptive field increases slowly, which affects the capture and processing of global information. In addition, the traditional feedforward layer MLP in Transformer is mainly used to process the information interaction of feature dimensions. Although the structure is simple and universal, the existence of GELU will truncate some data, resulting in the loss of key information, and more importantly, MLP cannot actively select which information needs to be retained or suppressed. Finally, Transformer mainly relies on global attention, cannot encode the two-dimensional position information of the image, and is difficult to model local information, resulting in a lack of local receptive fields and insufficient attention to details.
In order to solve the above problems, this paper proposes a dual-branch underwater image enhancement algorithm, MixRformer, that integrates CNN and Transformer in the wavelet domain. It is based on the U-Net structure. The convolutional layer of the original U-Net is replaced by a dual-branch feature extraction module (DFCB) for local and global interaction of multi-scale features and combined with jump connections to improve feature fusion and spatial information recovery.
In order to reduce the computational complexity of the Transformer and improve the inference speed, we introduce a wavelet transform (DWT-IWT) for up-sampling and down-sampling [
8], which reduces the resolution while retaining key features. In addition, inspired by CAT [
9], we propose the Rectangle GLU-Window Transformer module, which combines horizontal and vertical rectangular window attention mechanisms to expand the receptive field without increasing the computational complexity and enhances the information interaction between windows through Axial-Shift. The feedforward network is also crucial for the Transformer. We use ConvGLU instead of MLP, introduce a gating mechanism to dynamically adjust channel activation, selectively retain or suppress information, and use convolution instead of SE modules to enhance local feature modeling ability. Given that images are different from sequence data and have a two-dimensional spatial structure, the Transformer is less efficient in extracting local features (such as edges, textures) and encoding two-dimensional information. Compared with the recent CNN-Transformer model, we first introduced the wavelet transform into a dual-branch structure for underwater enhancement tasks. At the same time, on the basis of reducing the computational complexity and parameter quantity, we combined the frequency domain information to synergistically improve various indicators of underwater images. Therefore, combining the advantages of CNN and Transformer is an effective way to improve the image enhancement effect.
In general, the unique contributions of this paper are summarized as follows:
This work proposes, for the first time, an underwater image enhancement algorithm structure, MixRformer, that effectively combines the wavelet transform with CNN-Transformer. The introduction of the wavelet transform is not only conducive to restoring the detailed features of the image, but also can reduce the image resolution, thereby reducing GPU memory consumption and reducing the amount of calculation of Transformer, so that MixRformer can better restore the color and texture of the image.
We propose a dual-branch feature capture block (DFCB), which consists of a simple surface information extraction block, ConvBlock, and an innovative Rectangle GLU-Window Transformer block, which are used to extract surface details and capture global features, respectively.
We construct a multi-loss function and introduce MSE Loss and VGG Perceptual Loss to train the model for restoring underwater distorted images. Compared with several state-of-the-art underwater image enhancement (UIE) methods, our proposed method shows extremely excellent performance in both objective indicators and visual quality. In particular, it has significant advantages in eliminating color casts and improving image clarity.
3. Proposed Approach
In this section, we first present the details of the proposed MixRformer model architecture, which is designed for underwater image enhancement with good robustness. Next, we elaborate on the key components of the network and finally introduce the loss function used for training.
3.1. Network Architecture
Our main goal is to develop a model that combines the characteristics of Transformer and CNN for underwater image enhancement in the wavelet transform domain by effectively co-optimizing the low- and high-frequency features in the wavelet transform domain. In computer vision tasks, the low frequencies in the wavelet transform domain mainly contain the main structure and basic texture information of the image, while the high frequencies correspond to the edges and detail features of the image. Low- and high-frequency information plays an important role in image restoration. Transformer and convolutional neural networks (CNNs) each have their own advantages. Transformer is good at capturing global dependencies and long-range relationships, but its computational complexity is high, which limits its application in high-resolution images. On the contrary, the CNN efficiently extracts detail features through local convolution operations, with low computational overhead, and is particularly suitable for processing edges and textures in images.
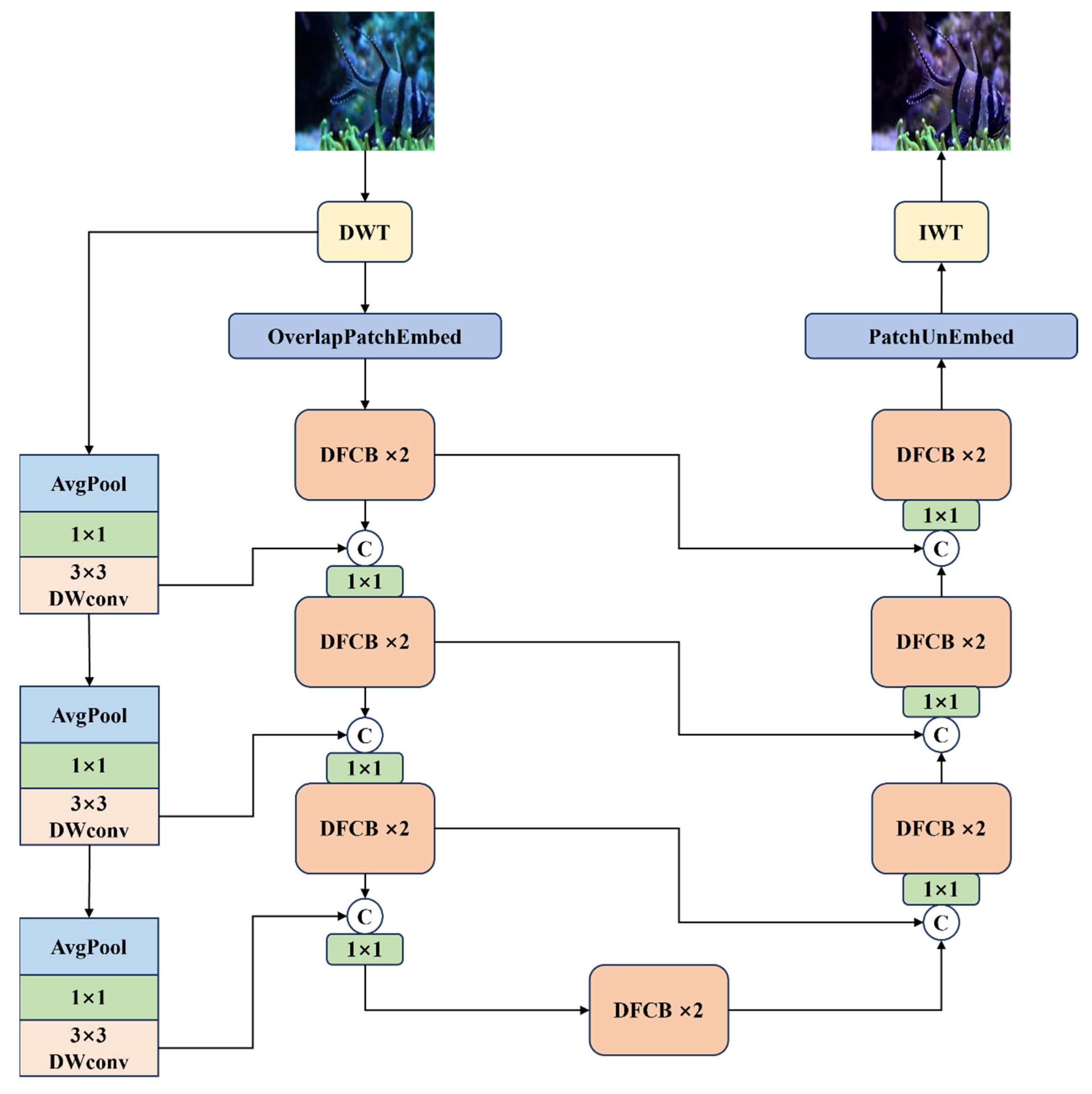
Therefore, combining Transformer with CNN can take advantage of the advantages of both: Transformer captures global information, and CNN extracts surface features. This combination not only improves the performance of the model, but also optimizes computational efficiency. As shown in
Figure 1, the model MixRformer proposed in this study mainly consists of four parts: discrete wavelet transform (DWT), dual-branch feature extraction module (DFCB), inverse wavelet transform (IWT) and coarse skip-connection. Specifically, the model is built on a U-shaped architecture [
23]. First, because the resolution of the input image is large, the model downsamples the input image through DWT, effectively extracting the high and low frequency information of the image while reducing the image resolution.
First, due to the large resolution of the input image, the model samples the input image through DWT, effectively extracting the high-frequency and low-frequency information of the image while reducing the image resolution, and concatenates the low-frequency and high-frequency four frequency domain image information to form a new input feature map, so that the feature map contains low-frequency and high-frequency information. The main part of the model uses the DFCB feature extraction module to perform feature processing on the new feature map after concatenation. We use DFCB to replace the pure convolution operation in the U-shaped structure, where the encoder gradually extracts the features of the input image through convolution layers and pooling layers and reduces the spatial resolution. On the other hand, at each stage of the encoding stage, our model sets a coarse skip connection. The role of this connection is to supplement the original features of the input data. It consists of a series of operations, including average pooling, pixel-level convolution, and depth convolution. Such a setting enables the encoder to focus more effectively on learning the residual caused by the absorption of light by water. In the encoder part, we give the network input as
, In order to extract the wavelet domain information of the image and obtain low and high frequency information, DWT downsampling
converts the input picture
into four wavelet images:
where
are 4 sub-images with different frequencies. Then, we connect the four sub-bands into a shallow feature
. In order to fuse the low-frequency and high-frequency information,
is subjected to a convolution operation for adaptive learning to fuse the features of each frequency and divide them into patches. These features are sent to the encoder composed of DFCB to further extract more effective features. In order to preserve the integrity of the image and reduce distortion, each layer of the encoder is combined with the shallow features of the upper layer through a coarse skip layer. When the network enters the bottleneck part, the bottleneck layer provides richer feature support for the decoder through global feature extraction and information compression to improve the enhancement effect. This part consists of only two dual-branch feature extraction modules. The decoder part is used for image reconstruction and adopts the same structure as the encoder part, retaining the dual-branch feature extraction module. Finally, in order to restore the image to the RGB channel, the IWT operation is used to convert the features to the original resolution and reconstruct the restored image.
3.2. Wavelet-Based Image Enhancement
In the image enhancement task, the low-frequency and high-frequency information in the image is a very important key factor for image restoration. The low-frequency sub-band contains the main structure and overall contrast information of the image, while the high-frequency sub-band corresponds to details such as edges and textures. At the same time, due to the large resolution of the general input image, the computational cost of the model for processing large-resolution images will be greatly increased. In order to solve the above problems, many methods have been proposed so far, such as convolution or pooling operations. However, some of these operations will cause irreversible information loss in the image, which is not conducive to image enhancement processing. Therefore, in order to solve the above problems, we introduced the wavelet transform into the model, which reduced the resolution of the image while introducing low-frequency and high-frequency information, greatly reducing the inference time and computational cost of the model.
Multi-scale frequency domain feature extraction [
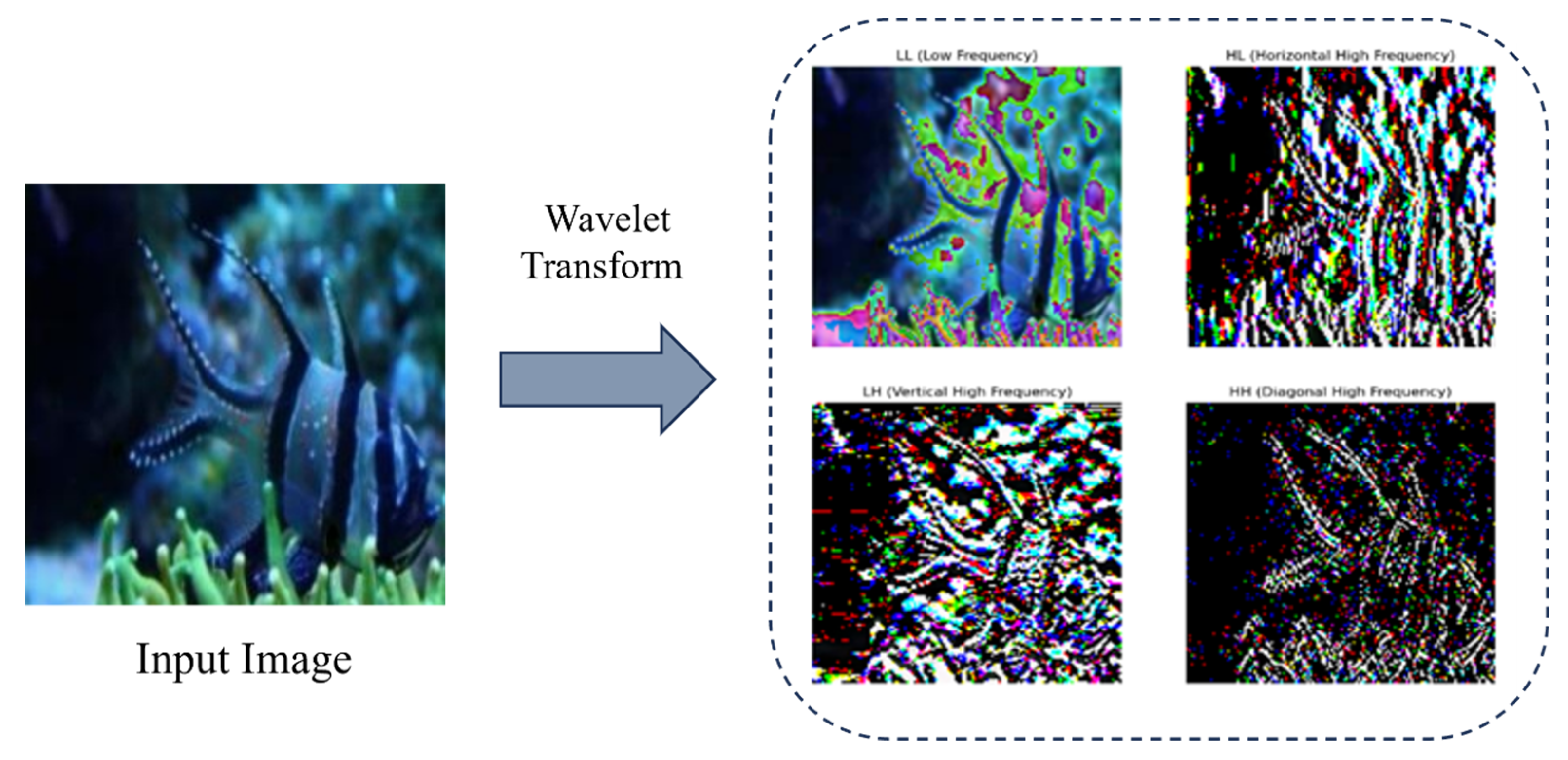
24] plays an important role in image enhancement tasks. As shown in
Figure 2, the input image is subjected to multi-resolution analysis using a discrete wavelet transform (DWT), which can be decomposed into four sub-band components with different spatial frequency characteristics. A large number of studies and experiments have shown that the sub-bands decomposed by wavelet carry multi-dimensional feature representations of the image: the low-frequency component (LL) retains the global structure of the original image as a basic approximate representation; the vertical high-frequency component (HL) and the horizontal high-frequency component (LH), respectively, record the edge contour features in the corresponding directions; and the diagonal high-frequency component (HH) contains important oblique texture details. Combining features of different frequencies with the deep model of the Unet architecture can effectively guide the network to focus on visual features of different scales, thereby enhancing the model’s ability to restore image texture.
The innovative advantages of the wavelet transform we have made are as follows: specifically, the wavelet transform can be completely reversible for images and achieve lossless reconstruction of image information; secondly, the resolution of feature maps can be effectively reduced by multi-level the wavelet transform, which can greatly reduce the consumption of computing resources compared with traditional reduction methods, and does not introduce additional trainable parameters, significantly improving the efficiency of model reasoning; thirdly, sub-band components have dual representation capabilities of spatial position and frequency domain features, which is conducive to the network capturing geometric structure features in different directions; overall, the multi-scale characteristics of wavelet functions can expand the receptive field of the network, and on this basis, the multi-level feature fusion mechanism is used to enhance the model’s ability to express complex textures, providing an effective physical prior guidance for the model.
3.3. Dual-Branch Feature Capture Block
According to most previous Transformer-based methods, we found that they simply use the convolutional layer network for feature aggregation or sampling. However, the computational complexity of the Transformer itself is too large, which not only consumes a lot of computing resources but also causes the model performance to decrease due to multiple stacking of Transformers.
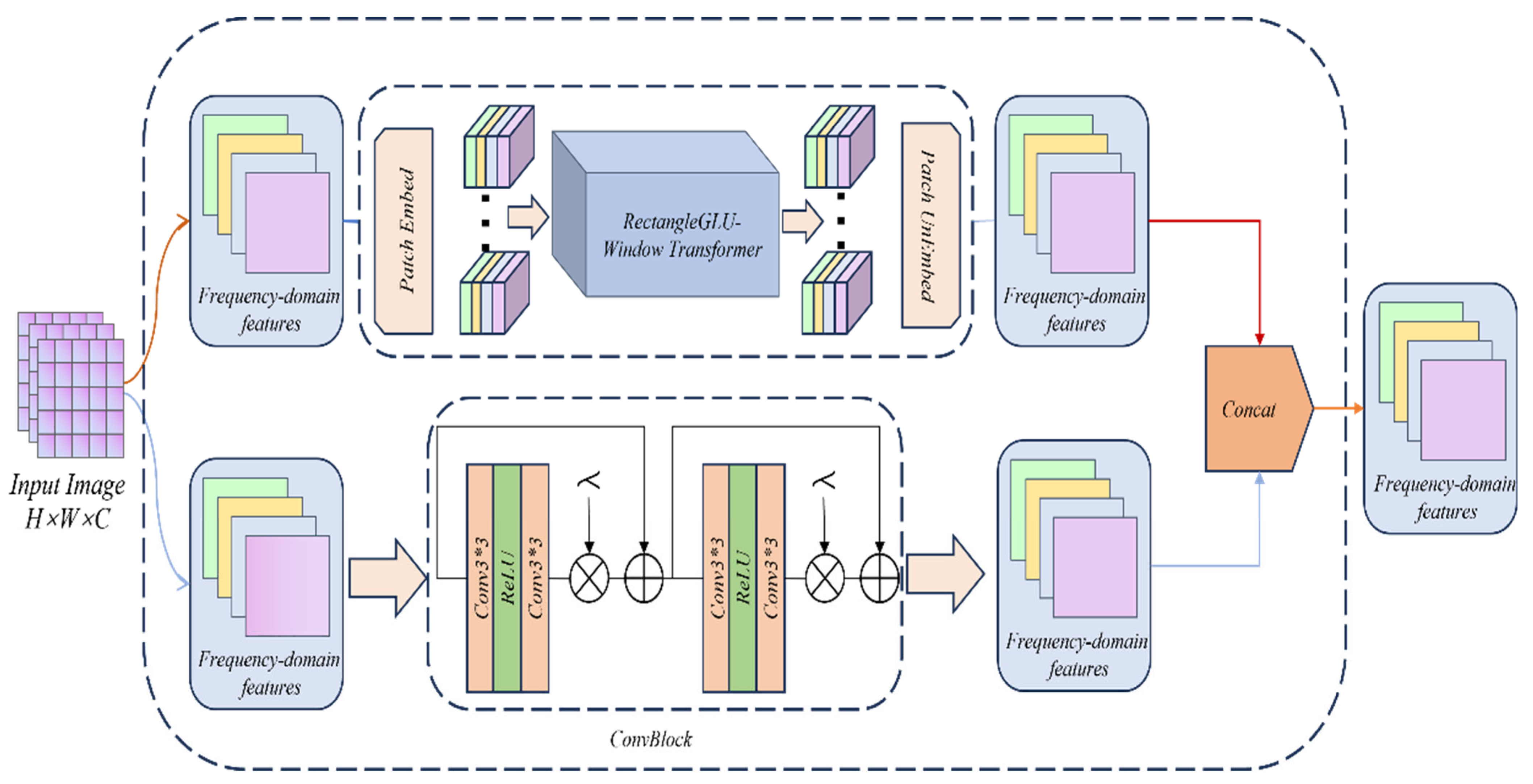
At present, CNN has been used as the backbone network in image processing. Its ability to extract local features and image location information is innate. Compared with Transformer’s artificial location encoding ability, it is far from CNN’s ability to automatically learn location information. However, Transformer can directly model global features through self-attention, allowing each pixel to pay attention to all pixels in the entire image. At the same time, Transformer itself can adaptively pay attention to information of different scales. Like CNN, it has its own natural multi-scale modeling ability, especially in dealing with complex details. Therefore, considering the multi-scale modeling ability, we found that introducing a multi-branch structure into the model can better extract visual features of different granularities. The multi-branch structure adopts a parallel structure to extract different features without interfering with each other. This design can avoid the problem of information sparsity caused by deep network stacking. As shown in
Figure 3, our DFCB uses CNN and Transformer as two different branches, as surface information extraction branch and global information extraction branch, respectively. When shallow features are input into DFCB, they will enter both branches at the same time. Specifically, the surface information extraction branch contains a lightweight ConvBlock, which is a simple module consisting of two convolutional layers and a ReLU activation function. It introduces local residual connections to enhance feature reuse while retaining the surface information of the image. In the global information extraction branch, we designed an RGLUWin Transformer module to expand the attention receptive field without increasing the amount of computation, thereby maintaining the suppression or retention of information.
Rectangle GLU-Window Transformer Block
The RGLUWin Transformer module is a key part of our dual-branch feature extraction module. As shown in
Figure 3, the RGLUWin Transformer is used to extract the global context information of the image. It is more suitable for image restoration than the previous Transformer structure. Because the Transformer enables all image blocks to interact through global dependency modeling capabilities, its complexity is quadratic with the resolution of the image. Although local window self-attention reduces the computational complexity, the fixed division limits the cross-window interaction, resulting in limited receptive field expansion and insufficient modeling capabilities, affecting image restoration performance. For the above problems, we adopt a rectangular window self-attention mechanism, which is divided into a horizontal rectangular window (H-Rwin) and a vertical rectangular window (V-Rwin), and used in parallel for different attention heads. By aggregating features across different windows, the attention area is expanded without increasing the computational complexity, and the rectangular window self-attention is realized. In addition, the rectangular window can capture the different features of each pixel in the horizontal and vertical directions and aggregate the features of different windows to expand the receptive field, so that the model can build a differentiated receptive field, while the traditional square window is difficult to take into account the multi-scale and multi-directional feature expression requirements. The RGLUWin Transformer is shown in the
Figure 4.
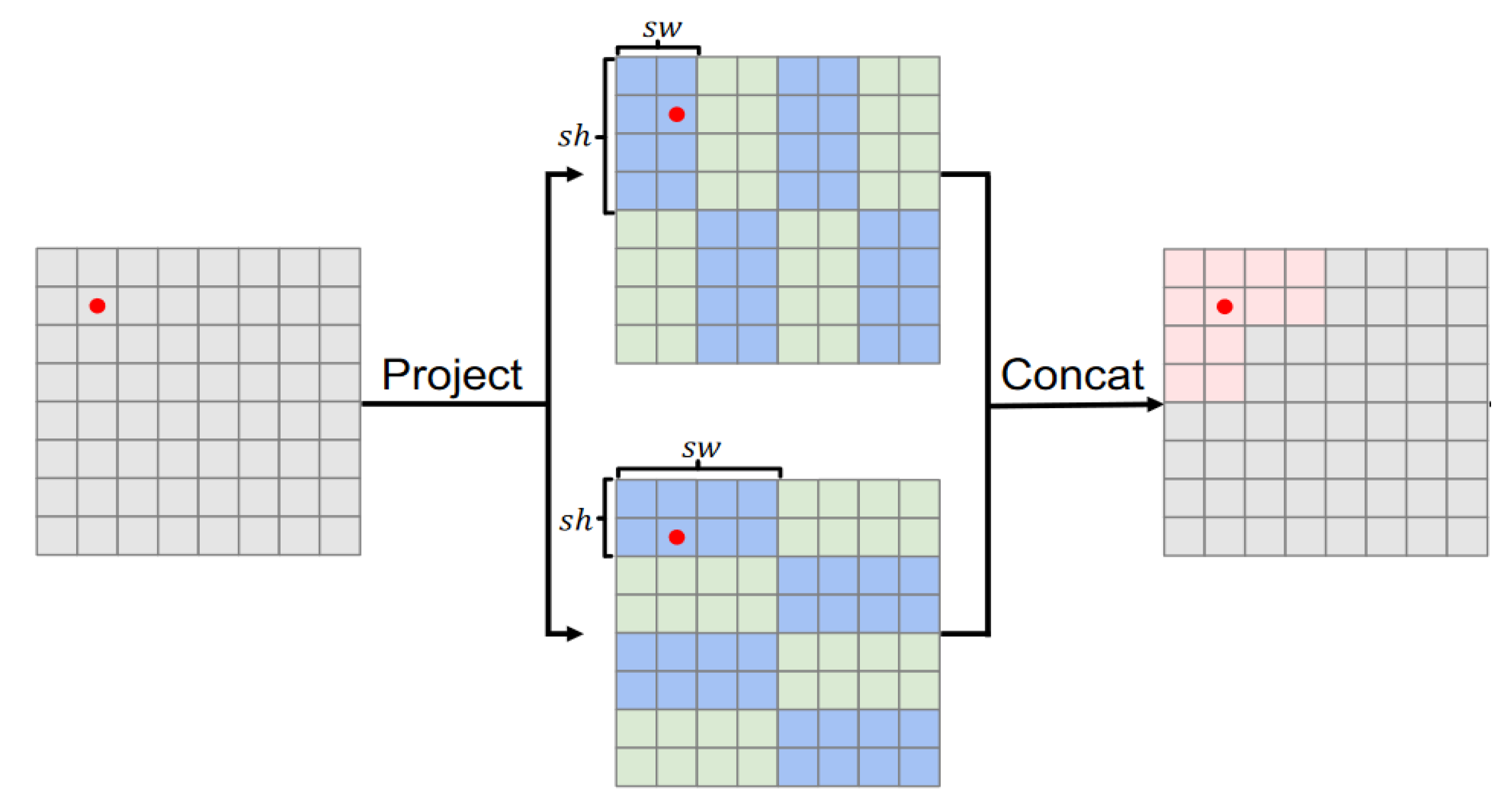
The special RGLUWin Transformer uses a rectangular window as shown in the
Figure 5. (
) instead of square windows (
), where
and
represent the height and width of the rectangle, respectively. In addition, we divide the rectangular window into horizontal windows (
, denoted as H-Rwin) and vertical windows (
, denoted as V-Rwin), and use them for parallel computation of different attention heads. In general,
attention heads are performed in parallel on the input feature
. For each attention head,
is split into non-overlapping
rectangular windows, and the
-th rectangular window feature is represented as
where
then the self-attention of the
-th head can be calculated as follows:
where
is the attention feature of
in the
m-th head,
represent the projection matrices of the query, key and value of the head, respectively,
is the channel dimension of each head, and
B is the dynamic relative position encoding. Performing attention operations on all
, and reshaping and merging in the partitioning order, we can obtain the attention feature
of the entire
X.
Assuming that the number of attention heads
is even, the attention heads are evenly divided into two parts, and H-Rwin is performed on the first part and V-Rwin is performed on the second part. The outputs of the last two parts are concatenated according to the channel dimension. The calculation formula of this process can be expressed as follows:
Among them, are output using the H-Rwin head, and are output using the V-Rwin head. represents the projection matrix of feature fusion.
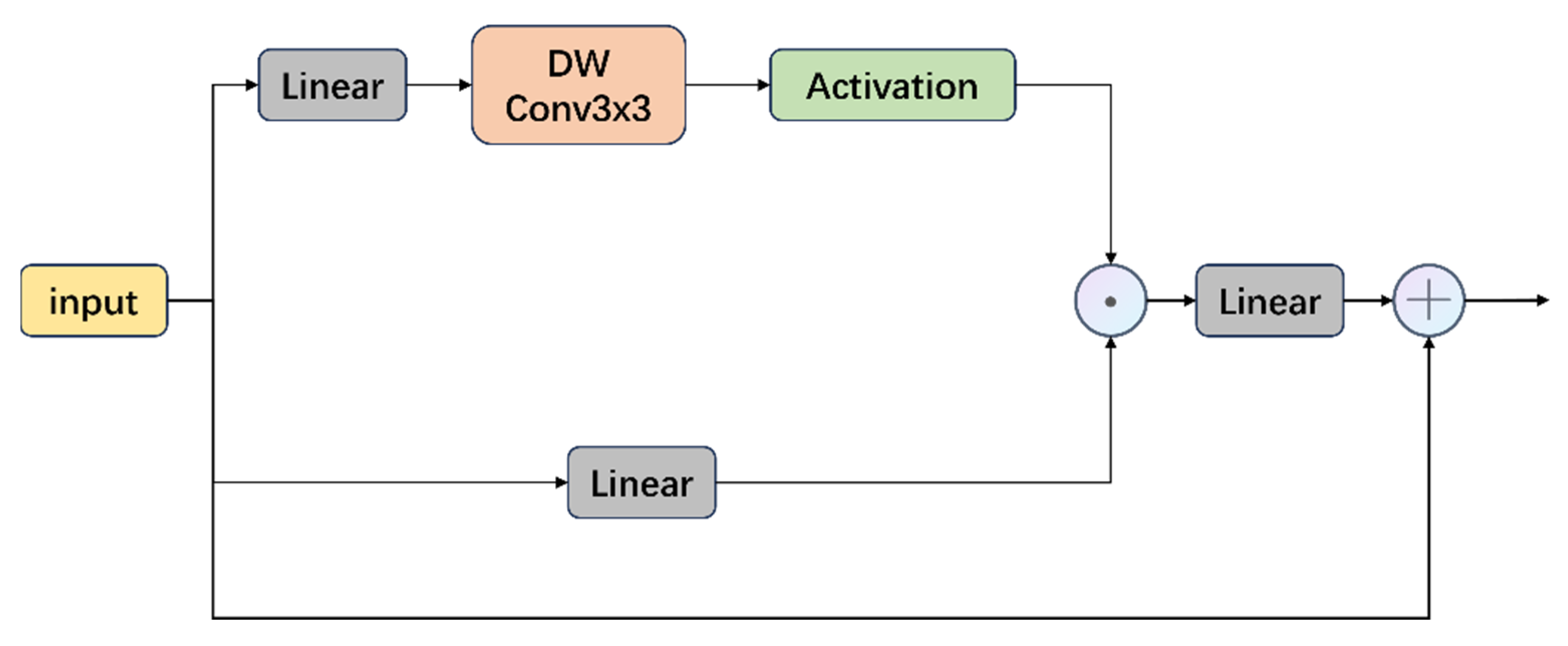
At the same time, we found that the traditional MLP layer has inevitable shortcomings for underwater images. The GELU in the MLP will truncate the data, resulting in information loss. It also lacks selective information suppression or retention, and is not sufficient for position encoding. Inspired by [
25], as shown in
Figure 6 each token in the ConvGLU has a unique gating signal based on its most recent fine-grained feature. The gating mechanism suppresses the noise channel and strengthens the transmission of important features. At the same time, by introducing the 3 × 3 deep convolution, not only the shortcomings of the excessive coarse-grained global average pooling in the SE mechanism are solved, but also the deep convolution can provide position encoding. The 3×3 deep convolution retains spatial locality and makes up for the shortcomings of the Transformer in fine-grained texture modeling. In addition, the value branch of this design still maintains the same depth as the MLP and GLU, which is friendly to its back-propagation. Its calculation expression can be expressed as follows:
Among them, DWConv is a depth-wise separable convolution, and ⊙ represents element-by-element multiplication.
In general, the RGLUWin Transformer block we proposed helps the model capture the global information of the image through a rectangular window, and combines it with the GLU module to enable the model to retain useful information or suppress interference information in long-dependency information.
3.4. Loss Function
To train our model, we formulate a multinomial loss function which consists of two parts.
3.4.1. MSE Loss
The mean square error loss is one of the basic functions in regression tasks. The model error is quantified by calculating the squared average of the difference between the generated image
and the reference image
. Its mathematical expression is as follows:
3.4.2. VGG Perceptual Loss
The calculation of mean square error loss is to optimize the model by the difference of pixel values. Excessive pursuit of pixel alignment may lead to overly smooth results and lack of details. Compared with mean square error loss, content-aware loss extracts high-level features through a pre-trained deep network (VGG) to measure the similarity between the generated content and the target in the feature space. In this chapter, a pre-trained 19-layer VGG network is used as a feature extractor [
26], and the perceptual loss function is defined with a ReLU activation layer. Specifically, let
be the
th convolutional layer (after activation) of the VGG19 network
pre-trained on the ImageNet dataset. The perceptual loss function is constructed by calculating the distance between the enhanced image
and the reference image
in the feature space, and its mathematical expression is as follows:
where
represents the number of samples in each batch during training;
represent the number, height and width of the feature map of the
th convolutional layer in the VGG19 network, which together define the dimension of the feature map.
In general, the total loss function can be expressed as follows:
The coefficients are the weights of each loss, and we empirically set and to 1 and 1.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}