
A Parts Detection Network for Switch Machine Parts in Complex Rail Transit Scenarios


Abstract
1. Introduction
- (1)
- Aiming at the problems of low detection accuracy and missed detection in traditional detection of rail transit switch machine parts, a complex scene rail transit switch machine Parts Detection network YOLO-SMPDNet based on YOLO is proposed, which can effectively improve the detection accuracy of switch machine parts.
- (2)
- YOLO-SMPDNet introduces MobileNetV3 to improve the YOLOv8s backbone network, further reducing the number of network parameters, and designs a parameter-free attention-enhanced ResAM module. After introducing the SPPF front and four Concat feature layers of the network, it forms a lightweight detection network together with the MobileNetV3 network to enhance the representation ability of the detection network.
- (3)
- Due to the relatively vague definition of aspect ratio in CIoU Loss of YOLOv8s, YOLO-SMPDNet introduces Focal IoU Loss to more accurately define the scale information of the prediction box, alleviate the problem of imbalanced positive and negative samples, accelerate network convergence, and improve regression accuracy.
- (4)
- This work further validates the practical application performance of YOLO-SMPDNet by incorporating it into the SLAM system and running it as an independent parallel thread. The results show that YOLO-SMPDNet has a more significant improvement in accuracy for camera mobile shooting compared with static shooting, has a smaller absolute trajectory error and better real-time performance, and further validates the generalization and robustness of YOLO-SMPDNet.
2. Related Work
2.1. Two-Stage Object Detection Method
2.2. One-Stage Object Detection Method
3. YOLO-SMPDNet
3.1. Feature Extraction Based on the MobileNetV3 Network
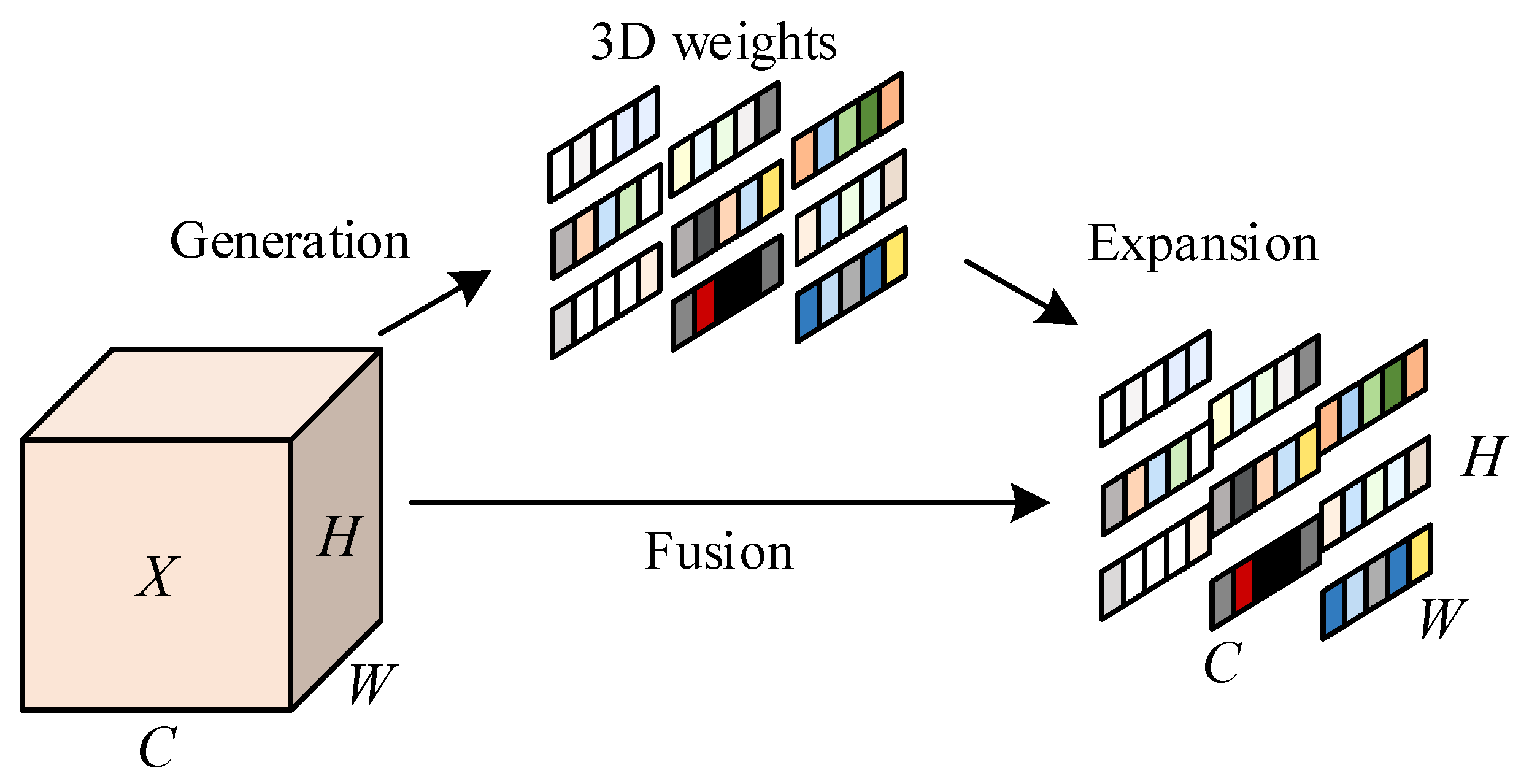
3.2. Lightweight Module ResAM Based on Parameter-Free Attention Enhancement
3.3. Loss Function of YOLO-SMPDNet
4. Experiment and Result Analysis
4.1. Dataset
- (1)
- Label the visible parts of the eight types of parts with tangents closely attached to the edges.
- (2)
- If a part of the annotated target is obscured, its shape needs to be fully supplemented before annotation.
- (3)
- Images that are blurry, too dark, or overexposed are not framed.
- (4)
- Each target object needs to be individually framed.
- (5)
- Ensure that the box coordinates are not on the image boundary to prevent out of bounds errors when loading data.
- (6)
- For small targets, as long as they can be distinguished by human eyes, they should be marked with frames.
4.2. Ablation Experiment
4.3. Comparative Experimental Analysis
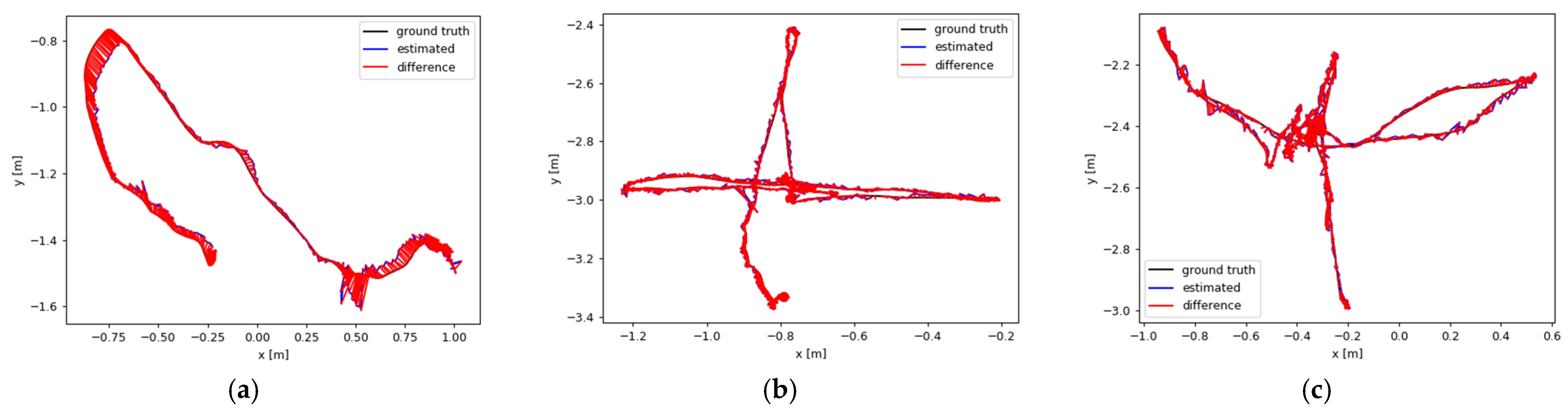
4.4. Application Performance Analysis
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chi, H.; Wu, C.; Huang, N.; Tsang, K.; Radwan, A. A survey of network automation for industrial internet-of-things toward industry 5.0. IEEE Trans. Ind. Inform. 2023, 19, 2065–2077. [Google Scholar] [CrossRef]
- Elhanashi, A.; Saponara, S.; Dini, P.; Zheng, Q.; Morita, D.; Raytchev, B. An integrated and real-time social distancing, mask detection, and facial temperature video measurement system for pandemic monitoring. J. Real-Time Image Process. 2023, 20, 95. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27 June–2 July 2004; IEEE Press: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Pechenin, V.A.; Bolotov, M.A.; Pechenina, E.Y. Neural network model of machine parts classification by optical scanning results. J. Phys. Conf. Ser. 2020, 1515, 052008. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 580–587. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 25 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 6608–6617. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Geetha, A.; Hussain, M. A Comparative Analysis of YOLOv5, YOLOv8, and YOLOv10 in Kitchen Safety. arXiv 2024, arXiv:2407.20872. [Google Scholar]
- Tian, L.; Fang, Z.; Jiang, H.; Liu, S.; Zhang, H.; Fu, X. Evaluation of tomato seed full-time sequence germination vigor based on improved YOLOv8s. Comput. Electron. Agric. 2025, 230, 109871. [Google Scholar] [CrossRef]
- Wang, C.; Yeh, I.; Mark, L. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2025. [Google Scholar]
- Jiang, T.; Zhong, Y. ODverse33: Is the New YOLO Version Always Better? A Multi Domain Benchmark from YOLO v5 to v11. arXiv 2025, arXiv:2502.14314. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Koonce, B. MobileNetV3. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Springer: Berlin/Heidelberg, Germany, 2021; pp. 125–144. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, London, UK, 18–24 July 2021; PMLR: Cambridge, MA, USA, 2021; pp. 11863–11874. [Google Scholar]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.-S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Carlos, C.; Richard, E. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar]
- Lee, J.H.; Lee, S.; Zhang, G.; Lim, J.; Chung, W.K.; Suh, I.H. Outdoor place recognition in urban environments using straight lines. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE Press: New York, NY, USA, 2014; pp. 5550–5557. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, L. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associate: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollar, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Recognition and Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9454–9468. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Recall/% | mAP50/% |
|---|---|---|
| YOLOv8x | 91.3 | 92.1 |
| YOLOv8s | 91.6 | 91.5 |
| MobileNetV3 | 91.8 | 91.6 |
| ResAM | 92.5 | 94.2 |
| MobileNetV3 + ResAM | 95.0 | 98.3 |
| Model | mAP50 (%) | mAP50-95 (%) | Parameter Quantity (M) |
|---|---|---|---|
| YOLOv8s-MobileNetV3 | 91.6 | 84.3 | 5.1 |
| +ResAM-SE | 97.3 | 86.3 | 13.1 |
| +ResAM-CBAM | 97.8 | 87.1 | 11.9 |
| +ResAM-SimAM | 98.3 | 88.9 | 5.9 |
| Model | Recall | mAP50 | mAP50-95 |
|---|---|---|---|
| CIoU | 94.8 | 98.3 | 88.9 |
| +EIoU | 94.9 | 98.2 | 88.9 |
| +Focal-EIoU | 95.1 | 98.6 | 89.2 |
| Category | SSD | YOLOv5 | YOLOv8s | YOLOv8x | YOLOv11 | YOLO-SMPDNet | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | mAP50 | Recall | mAP50 | Recall | mAP50 | Recall | mAP50 | Recall | mAP50 | Recall | mAP50 | |
| Displacement contactor | 94.8 | 91.4 | 92.2 | 92.8 | 93.2 | 93.3 | 96.2 | 94.9 | 97.3 | 97.3 | 96.2 | 99.1 |
| Automatic shutter | 91.9 | 92.0 | 92.0 | 93.6 | 91.0 | 92.1 | 92.0 | 93.6 | 91.5 | 95.1 | 100 | 99.2 |
| Reducer | 92.4 | 92.1 | 91.1 | 92.8 | 91.0 | 91.2 | 90.1 | 93.1 | 95.2 | 97.9 | 96.4 | 98.9 |
| Main shaft | 94.6 | 93.5 | 94.0 | 95.5 | 94.8 | 95.5 | 92.3 | 92.5 | 94.7 | 93.4 | 100 | 99.5 |
| Indication rod | 95.3 | 91.1 | 87.5 | 93.2 | 95.0 | 93.2 | 91.0 | 92.2 | 94 | 95.7 | 95.1 | 99.5 |
| Control lever | 79.0 | 78.3 | 86.3 | 76.3 | 85.0 | 84.8 | 85.0 | 84.5 | 89.7 | 82.7 | 75.0 | 94.5 |
| Motor | 83.2 | 90.8 | 93.0 | 94.5 | 86.5 | 83.5 | 85.7 | 91.8 | 93.2 | 94.3 | 97.9 | 99.5 |
| Tooth block | 90.4 | 87.6 | 88.7 | 82.1 | 96.3 | 98.4 | 98.1 | 94.2 | 99.4 | 96.5 | 100 | 98.9 |
| Average value | 90.2 | 89.6 | 90.6 | 90.1 | 91.6 | 91.5 | 91.3 | 92.1 | 94.4 | 94.1 | 95.1 | 98.6 |
| Model | Parameter Quantity/M | GFLOPs | Real Time/FPS |
|---|---|---|---|
| YOLOv3 | 68.5 | 66.7 | 32 |
| YOLOv5 | 12.6 | 18.8 | 133 |
| YOLOv8 | 11.2 | 25.7 | 123 |
| YOLOv11 | 7.3 | 15.1 | 137 |
| YOLO-SMPDNet | 5.9 | 16.8 | 142 |
| Sequence | RMSE | Error Reduction Amplitude/% | |
|---|---|---|---|
| ORB-SLAM3 | YOLO-SMPDNet | ||
| sitting_static | 0.009 | 0.005 | 44.5 |
| sitting_xyz | 0.044 | 0.010 | 77.3 |
| sitting_halfsphere | 0.047 | 0.009 | 80.6 |
| walking_static | 0.015 | 0.006 | 60.5 |
| walking_xyz | 0.270 | 0.011 | 95.9 |
| walking_halfsphere | 0.291 | 0.016 | 94.5 |
| Average frame rate/fps | 49.3 | 53.6 | 8.0 |
| Time consumption per frame/ms | 27.2 | 19.1 | 29.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yong, J.; Dang, J.; Deng, W. A Parts Detection Network for Switch Machine Parts in Complex Rail Transit Scenarios. Sensors 2025, 25, 3287. https://doi.org/10.3390/s25113287
Yong J, Dang J, Deng W. A Parts Detection Network for Switch Machine Parts in Complex Rail Transit Scenarios. Sensors. 2025; 25(11):3287. https://doi.org/10.3390/s25113287
Chicago/Turabian StyleYong, Jiu, Jianwu Dang, and Wenxuan Deng. 2025. "A Parts Detection Network for Switch Machine Parts in Complex Rail Transit Scenarios" Sensors 25, no. 11: 3287. https://doi.org/10.3390/s25113287
APA StyleYong, J., Dang, J., & Deng, W. (2025). A Parts Detection Network for Switch Machine Parts in Complex Rail Transit Scenarios. Sensors, 25(11), 3287. https://doi.org/10.3390/s25113287