1. Introduction
In recent years, with the rapid development of intelligent technology and the continuous promotion of industrial wisdom upgrading, intelligent mobile robots have been widely used in more and more fields, such as cargo handling, intelligent production, intelligent life, abnormal environment detection, underwater operation, space exploration and so on [
1]. Complete coverage path planning (CCPP) is a key research area in modern robotics, aiming to enable the mobile robot find a collision-free shortest path in a specific environment, meanwhile, it should traverse the entire accessible working area to form a continuous path that encompasses all accessible areas. In CCPP research, based on environmental characteristics, it can be categorized into CCPP problems in static environments and that in dynamic scenarios. Although dynamic scenarios are more common in real-world environments, there are also numerous practical applications in static scenarios. Examples include industrial robotic arms planning coverage paths on fixed workpieces for uniform welding or spraying tasks, automated guided vehicles (AGVs) optimizing paths in warehouses with fixed shelf layouts to cover all cargo access areas, and robots following fixed orchard tree distribution paths for pruning, harvesting, or monitoring. In these scenarios, the environment is typically fixed. Research on static CCPP methods can optimize efficiency and reduce time and energy consumption. Additionally, studies on static environments serve as a foundation for dynamic environment research. Many algorithms for dynamic environments require first addressing basic path planning in static environments before incorporating obstacle avoidance and real-time adjustment modules. If algorithms for static environments are inefficient, their performance in dynamic environments will also be affected.
CCPP algorithms can be categorized into three categories, classical algorithms, heuristic-based algorithms and hybrid algorithm. Classical algorithms are mainly as follows: the random walk algorithm [
2], chaotic coverage path planner [
3], the boustrophedon coverage algorithm [
4], the interior screw algorithm [
5], and the domain decomposition algorithm [
6]. These algorithms are easy to operate and the calculation speed is fast; however, when it comes to practical application, these algorithms have poor efficiency and a high coverage repetition ratio for the planned path [
7]. To solve the above problems, many scholars have improved the classical algorithms. Hou et al. [
8] divide the target coverage area into boundary and center regions for separate coverage. The boundary region is covered using a spiral path, which do not generate overlapping; in the center region, two steering paths with low overlap rates are designed, to solve the problem of existing spiral CCPP algorithms not meeting the kinematic constraints of robots and have a high overlap rate in the center region. Chaotic path planning is a prospective modern approach that use chaotic dynamical systems to generate trajectories throughout an environment. Moysis et al. [
9] proposed a chaotic path planning method for 3D area coverage using modified Logistic map and a modulo tactic. An area-coverage path planning which is controlled by a novel memristor-based double-stroll chaotic system has been proposed in [
10] to generate higher unpredictability, more even and faster scanning path. Chaotic CPP ensures high coverage efficiency in the entire workspace in terms of the robot’s trajectory, guaranteeing faster coverage in the working space because the motion is pre-determined [
11].
With the rapid advancement of technologies associated with artificial intelligence, heuristic algorithms have been increasingly and extensively applied in CCPP. By integrating intelligent optimization strategies, this type of algorithms can effectively address the challenge of CCPP in complex environments. It particularly demonstrates substantial advantages in scenarios characterized by dynamic environments, multiple constraints, and high real-time requirements. It mainly includes A* algorithm [
12], D* algorithm [
13], Theta* algorithm [
14], evolutionary algorithms, swarm intelligence algorithms, the biologically inspired neural network algorithms and reinforcement learning, etc. In [
15], the objective function is optimized based on evolutionary algorithms such as the genetic algorithm (GA) and ant colony optimization (ACO) of the traveling salesman problem (TSP) and estimates the shortest path that connects all waypoints. Considering full-load travel distance, unloading position distribution and the area of the turning area simultaneously, a full coverage path planning methods of harvesting robot with multi-objective constraints is proposed by using the shuttle method and the improved ACO algorithm [
16]. The biologically inspired neural network algorithms do not require training the model, nor do they need to predict environmental information, and have a relatively fast computing speed. Therefore, it has been widely studied and applied by many scholars. In this algorithm, the map is shown as a grid map, and each grid is considered as a neuron. The adjacent neurons are connected, and the robot’s mobile path is chosen by calculating the neuronal activity value. Muthugala et al. [
17] put forward an online path planning approach based on the Glasius Bio-inspired Neural network to enhance the energy efficiency and coverage effect of hull maintenance robots. By introducing a comprehensive energy model and a dynamic tracking method, this approach not only boosts the adaptability and energy efficiency in a dynamic environment but also strengthens the global coverage capability. Zhang et al. [
18] brought in the domain neuron status criterion, which increased the biologically inspired path planning efficiency near isolated island obstacles. Li et al. [
19] raised a 2D adaptive cell decomposition method, which strengthens the positive correlation between the obstacle density and the closure of the map grid. They incorporated the consideration of obstacle distribution and grid level into the bypass equation of the biologically informed neural networks (BINN) algorithm, thereby enhancing the efficiency and effectiveness of the CCPP for the bulldozer. On the other hand, the rapid development of reinforcement learning and deep learning brings a whole new solution to path planning. Elfoly et al. [
20] proposed to use a modified Q-learning geometric learning algorithm to generate an optimal path by iteratively exploring and exploiting the state-action space. An improved deep reinforcement learning algorithm, the re-DQN algorithm, is proposed by Wang et al. [
21] to solve the traversal order of each region. The reinforcement learning method possesses a strong ability for decision making and can find the global optimal solution; however, it costs much more time during the learning process than a generic algorithm, so its application has not been widely used [
7].
Recent trends include the use of hybrid algorithm methods, combination of classical algorithms and heuristic algorithms, or combination of both heuristic algorithms to optimize CCPP solutions. Although the hybrid algorithm incurs a high computation time, it delivers better coverage efficiency. A convolutional neural network (CNN) with long short term memory (LSTM) layer was trained using the actor-critic experience replay (ACER) reinforcement learning algorithm in [
22], and a complete area coverage planning module for the modified hTrihex, a honeycomb-shaped tiling robot, based on the deep reinforcement learning technique is proposed. Xu et al. [
23] proposed a complete coverage neural network (CCNN) algorithm, which simplified the calculation process of neural activity. It also combined a modified A* algorithm to improve the covering efficiency. Tan et al. [
7] presented a biologically inspired neural network algorithm based on Q-learning, which proceeds with path planning based on the biologically inspired neural network algorithm, and when it comes to the position change of a reachable path point, processes path optimization by adopting Q-learning to avoid falling into a locally optimal solution. Cheng et al. [
24] proposed an improved PSO combined gray wolf optimization (IPSO-GWO) algorithm with chaos and a new adaptive inertial weight. Qian et al. [
25] combined the interior screw search and the biologically inspired neural network algorithm, which reduced the calculating time of the path repetition ratio. Kvitko et al. [
26] presented a path-planning algorithm based on the chaotic behavior of the Courbage–Nekorkin neuron model with a coverage control parameter to reduce the number of iterations required to cover the chosen investigated area.
Having said all of above, the current CCPP methods exhibit diverse characteristics when responding to the demands of different scenarios. Classical algorithms are known for their fast computing speed, but they are difficult to meet the requirements of efficient coverage due to the high path repetition rate. The A* algorithm and the D* algorithm are relatively sensitive to heuristic functions, and the computational overhead of the D* algorithm is relatively large. Evolutionary algorithms and swarm intelligence algorithms maintain the excellent global exploration performance of the Monte Carlo method and have a strong local exploitation capability. However, balancing exploration and development is a challenge, and there is a hidden danger of falling into local optimum. The self-learning and parallelism characteristics of the neural network algorithm can improve the coverage efficiency of the CCPP algorithm, while it can realize automatic obstacle avoidance and escape from the deadlocks [
27]. however, it is more computationally intensive [
19]. Moreover, there is no optimal value for parameters of the neural network model, which can only be determined by repeated experiments [
28]. The continuous motion of chaotic CCPP enables the robot to move in searching and finding the target effectively with a more uniform coverage density. However, the existing literature only highlighted the coverage rate, ignoring the cost of coverage time. The unpredictable trajectory is also hugely dependent on the kinematic motion of the robot subjected to kinematic constraint, and it needs to be studied [
11]. In addition, the notable dependence of the space coverage rate on the starting point of the autonomous robot’s path is the key shortcoming of chaos-based path-planning methods [
26]. The hybrid algorithm attempts to balance efficiency and quality, but the increase in complexity and scene dependence have become new bottlenecks. Therefore, this paper proposes a complete-coverage path-planning algorithm based on transition probability and learning perturbation operator (CCPP-TPLP) to achieve efficient path planning within a concise algorithm framework. In the initialization stage of the algorithm, a greedy initialization strategy based on transition probability is proposed to generate high-quality initial solutions. The creation process of each solution takes both the adjacent properties of the grid and the requirement of the shortest path distance into account, ensuring that each initial solution is approximate optimal and laying a solid foundation for the subsequent optimization of the algorithm. A learning perturbation operator is proposed for algorithm iteration, thereby enhancing the diversity of the population and the convergence speed. Simulation results show that compared with five representative optimization algorithms, CCPP-TPLP achieves the best effect of complete coverage path planning under various obstacle densities and map scales. In the CCPP problem of an electric tractor in complex agricultural terrain, the complete coverage optimal path with the lowest energy consumption, shortest path length, and lowest repetition rate can be acquired by CCPP-TPLP.
This paper is structured as follows:
Section 1 presents the problem description of CCPP;
Section 2 introduces the related distance calculation method;
Section 3 describes the complete coverage path planning method based on transfer probability and learning perturbation operator;
Section 4 validates the effectiveness of the proposed algorithm in this paper through the ablation experiments, algorithmic comparison experiments, and algorithmic simulation experiments in 3D maps of motorized tractors; and
Section 5 concludes with the summary and discussion.
2. Description of the Problem
CCPP pertains to obtaining the shortest path that traverses all areas except for obstacles within a closed region. The commonly employed map construction methods include the grid method [
29], the topological method [
30], and the geometric method [
31]. Among them, grid maps possess duality and can represent the occupancy of obstacles in the workspace, thus being widely utilized in robot path planning. In this paper, the grid method is employed to quantize the robot’s working environment into several grids. The obstacles are represented by regular and complete grids, and two state values of 0 and 1 are used to represent the open space grid and the obstacle grid respectively.
In the grid map, the size of the grid is set to the size of the robot’s own coverage area. It is assumed that once the robot passes through the center of the grid, the grid is regarded as having been covered. The grid map consists of rows and columns. The row and column coordinates corresponding to the
grid are denoted by
, where
represents the sequence number of the grid. Then the transformation relationship between
and grid coordinates is presented in Equation (1).
where
represents the number of grids contained in a column of the map. Let
denote the set of all grid indices, and
represents the maximum number of grid.
denote the set of subsets formed by picking s elements from the set
with replacement, which
. If the set
, then the number of elements in
is
, and the total number of complete permutations for all elements in
is
. Let
be a complete permutation of all elements in
. It is known that
.
represents a path formed by connecting the grids in
sequentially. Then, the mathematical model of the CCPP problem can be expressed as shown in Equation (2).
where
denotes the path length of the path
. Since
already contains all grid indices, and
is the set of subsets formed by picking s elements from
with replacement, in other words, every element of
has already appeared once in
, thus, the smaller
is, the fewer overlapping elements exist between
and
are, the less the number of repeated grids in the path is, and the lower repetition rate of the nodes in the path is.
3. Basic Theory
At present, the frequently employed distance calculation methods in the CCPP problem comprise Euclidean algorithm [
32], Manhattan distance algorithm [
33] nearest neighbor algorithm [
34], Dijkstra algorithm [
35], Floyd algorithm [
36], and so forth. Among them, Euclidean algorithm and nearest neighbor algorithm are employed to calculate the straight-line distance between two points, regardless of the existence of obstacles. However, they do not give thought to the existence of obstacles. Manhattan distance algorithm merely reflects on the actual total moving distance from one point to another in the horizontal and vertical directions, without considering diagonal movement and the presence of obstacles. Dijkstra algorithm addresses the single-source shortest path problem, where each execution calculates the shortest paths from one starting node to all other nodes in the graph. While Floyd algorithm solves the all-pairs shortest path problem, computing the shortest paths between all node pairs in a single run. In the CCPP problem for grid maps, assuming the total number of grids is
, it is necessary to obtain the shortest distances between all nodes. If Dijkstra algorithm is used, the time complexity for a single execution is
. Calculate the shortest distances between all nodes requires running Dijkstra algorithm once for each node as the starting point, resulting in a total time complexity of
. In contrast, Floyd algorithm computes all-pairs shortest paths in a single run with a fixed time complexity of
. Since Dijkstra algorithm exhibits significantly reduced computational efficiency in grid maps with a large number of nodes and may lead to local optima in complex scenarios, this work adopts Floyd algorithm to calculate the shortest distances between grids.
Floyd algorithm is a classic algorithm for addressing the shortest path problem in weighted networks, and its core lies in an idea of gradual approximation. By gradually incorporating intermediate nodes between any two nodes, the initial direct path distance between the two nodes is gradually extending to the path distance connected by multiple intermediate nodes, and the shortest path is chosen and retained throughout the process, so as to obtain the shortest distance between the two nodes. The basic steps are as follows.
- (1)
Initialize the distance matrix
The distance matrix is constructed, where is the number of nodes in the graph, and denotes the distance from grid to grid . If there is a direct edge connection between and , represents the weight of the edge. If there is no weight value, then . If there is no direct edge connecting and , then . Specifically, if , then .
- (2)
Update the distance matrix
For each pair of grids
and
, and for each potential intermediate grid
, let
iterates from
to
to update the shortest distance between grids
and
. When the shortest distance between
and
can be attained via the intermediate node
, then
is updated, and the update formula is Equation (3).
After the traversal and iteration of all nodes, the distance matrix is updated, and represents the shortest path from node to node .
4. CCPP Method Based on Transition Probability and Learning Perturbation Operator
4.1. Greedy Initialization Strategy Based on Transition Probability
In the path planning problem, if the population is randomly initialized, that is, a complete coverage path is randomly generated, the length of the initial path may be long, and too many nodes are visited repeatedly. Utilizing such a path as the initial one to participate in the subsequent iteration will significantly reduce the search efficiency of the algorithm. If the length of the initial path is short, the quality of the initial population can be improved. To this end, this paper proposes a greedy initialization strategy based on transition probability. At first, the map is transformed into a grid map. Then for all accessible grids, the shortest distance between any two grids is calculated by Floyd algorithm. Finally, during the path initialization process, the subsequent accessible grids are selected one by one from the starting grid. The grids closer to the current grid have a higher probability of being selected, thereby obtaining a short initial path.
The specific implementation procedures of the greedy initialization strategy based on transition probability are as follows.
- (1)
State matrix and adjacency matrix
The map is converted into a grid map, and it is assumed that the processed map contains
N ×
M grids, as depicted in
Figure 1a, where the black grids represent obstacles and the white grids represent accessible grids. The state matrix
of the map is constructed based on whether there is obstacle in the grid, as shown in
Figure 1b.
represents the element located in row
and column
of the state matrix
,
,
. The state matrix
is constructed by Equation (4).
Based on the state matrix
, the adjacency matrix
of the accessible grids is further constructed. Suppose that there are
elements with a value of 0 in
, that is, there are
accessible grids. The adjacency matrix
with size of
needs to be established, where the element located in row
and column
of
is denoted as
and represents the adjacent relationship between grid
and grid
. Suppose that the position indexes of grid
and grid
in the state matrix
are
and
respectively, the Manhattan distance between grid
and grid
is calculated by Equation (5) to determine their adjacent relationship, then the adjacency matrix
is constructed.
- (2)
Distance matrix and transition probability matrix
For all accessible grids, the adjacency matrix
and Floyd algorithm are employed to calculate the shortest distance between any two grids and obtain the distance matrix
, as shown in Equation (6).
Here,
represents the shortest distance between grid
and grid
. Based on the distance matrix
, the transition probability matrix
is defined as presented in Equation (7).
where
represents the probability of transfer from grid
to grid
, which is calculated in accordance with Equation (8).
where
is defined as a greedy factor. The smaller
is, the larger
is, and the higher the probability that grid
will be selected when the next transfer grid is chosen from grid
.
- (3)
Population initialization of greedy strategy
Since there are
accessible grids, the individual of creating population is
, which represents a path covering all accessible grids, and its arbitrary dimension variable
is the sequence number of accessible grids.
is the sequence number of specified starting grid. To complete the individual initialization, set the degree of greediness
and generate the random number
. If
, grid
is selected as
in accordance with Equation (9).
Otherwise, the cumulative sum probability of each row in is computed, and a accessible grid is chosen as through the roulette—wheel selection method.
According to the aforesaid method, the subsequent grid numbers are determined in turn to complete the initialization of the individual. Populations are created based on the population size and the dimensions of decision variables. For each individual initialization, random number is generated. If , an individual is generated based on the starting point and transition probability matrix , using the above-mentioned greedy strategy. Otherwise, each decision variable is randomly generated to construct a random individual. By setting the degree of greediness , the algorithm can strike a balance between the greedy strategy and the random strategy. If is low, the algorithm is more inclined towards the greedy strategy, which is conducive to finding high-quality solutions rapidly. While is high, the algorithm prefers random selection, which is conducive to increasing the diversity of the population and avoiding premature convergence.
Through the greedy initialization strategy based on transition probability, a high-quality initial population can be constructed simply and effectively. The creation process of each individual takes into account the adjacent characteristics of grids and the requirement that the path length must be the shortest, ensuring that each individual is an approximately optimal solution.
4.2. The Operation of Learning and Perturbation
To update the population, this paper proposes a learning perturbation operator to enhance the diversity and convergence of the population and assist the algorithm in escaping the local optimum. The objective function of CCPP is the shortest path length, and the main factor influencing the path length is the selected sequence of accessible grids. When the selection order of the accessible grids varies, it will result in obvious differences in the path length. The individuals are classified into different subgroups based on their fitness. Subsequently, different degrees of learning or perturbation strategies are employed for individuals in different subgroups to alter the sequence of the accessible grid, thereby influencing the fitness value of each individual. The specific implementation procedures are as follows.
- (1)
Hierarchical division of the population
The individuals within the population are managed in a hierarchical manner based on their fitness values. This hierarchy can assist the algorithm in exploring the solution space more effectively, enhance the search efficiency, and facilitate the maintenance of population diversity. In this paper, the individuals within the population are sorted based on the fitness value from small to large, and the individual possessing the best fitness value is classified into the first subgroup, namely,
.The remaining individuals are categorized into three subgroups, namely
,
and
. The proportion of the hierarchy can be set according to the need. Different update strategies will be employed for individuals in different subgroups.
Figure 2 presents a schematic illustration of the hierarchical division of the population, with different colors signifying different subgroups.
- (2)
Perturbation operation
Perturbation operation includes strong perturbation and weak perturbation. The aim of strong perturbation is to cause individuals to undergo significant random changes, thereby encouraging them to escape from the local optimal state as much as possible and explore a new solution space. While the weak perturbation is intended to decelerate the convergence process of the individual to the current optimum, thereby expecting to discover new and better solutions.
For
, because of its optimal fitness value, it has a strong guiding effect on the entire population. To prevent the population from falling into the local optimum, the order of the accessible grid of the individual in
is randomly adjusted to cause a significant change in its fitness value, which is defined as the strong perturbation operation. Take
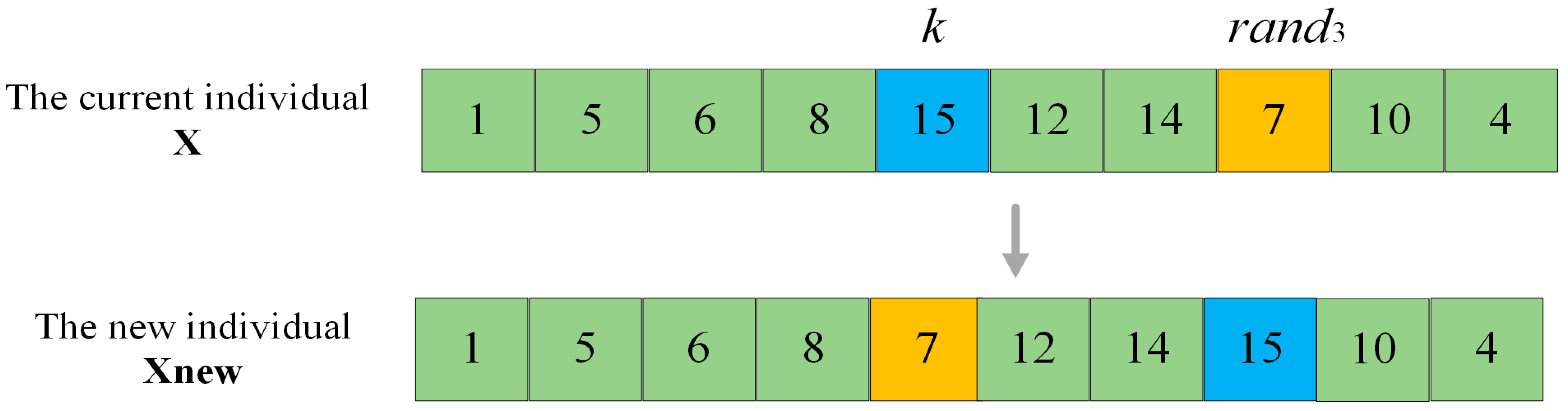
Figure 3 as an example. Suppose that the current individual is x, and the accessible grid index to be operated is
k. Firstly, random number
rand3 within the range of [1,K] is generated. Then the accessible grid indexed by
rand3 in x and the accessible indexed by
k are swapped to complete the strong perturbation operation and obtain a new individual
Xnew. As depicted in
Figure 3, the calculation of the fitness value of x encompasses the shortest distance between grid 8 and grid 15, between grid 15 and grid 12, between grid 14 and grid 7, as well as between grid 7 and grid 10. However, for the perturbed individual
Xnew, the above-mentioned four distances have transformed into the shortest distance between grid 8 and grid 7, between grid 7 and grid 12, between grid 14 and grid 15, and between grid 15 and grid 10. It can be observed that the strong perturbation operation alters the order of the accessible grids in the original individual to the greatest extent, and it will affect the shortest path among the four grids, thus having the greatest impact on the individual’s fitness value.
For
, which is the farthest from the current optimum, in order to slow down its convergence towards the current optimum and thereby have the opportunity to discover new and more optimal solutions, it is operated with weak perturbation. Take
Figure 4 as an example. Suppose that the current individual is
, and the accessible grid index to be operated is
. Generate a random number
between
, all the accessible grids between the position of the index
in
and the position of the index
are reordered in reverse order to complete the weak perturbation operation, so as to obtain a new individual
. In
Figure 4, the fitness value calculation of
encompasses the shortest distances between grid 8 and grid 15, as well as between grid 7 and grid 10. However, for
, the above two distances turn into the shortest distance between grid 8 and grid 7, and between grid 15 and grid 10. It can be observed that the change in the order of the accessible grid in the original individual resulting from the weak perturbation operation is less significant than that from the strong perturbation operation, for it only leads to the alteration of two distances. Therefore, the impact on the individual fitness value is minor.
- (3)
Learning operation
Learning operation includes learning from the optimal individual and learning from the random individual. For
, to better maintain excellent genes, it should learn from the best individual
. However, for
, to slow down its convergence to the current optimum, it is made to learn from random individuals within the population. Learning is accomplished through gene fragment learning, the specific learning operation is depicted in
Figure 5. Suppose that the current individual is
, the individual being learned is
, the index of the accessible grid to be operated in
is
, whose grid sequence number is
. In
, locate index
, whose grid sequence number is also
, select the grid sequence number
, whose index is
in
, and then return to the
to find the index
, whose grid sequence number is
in
. Finally, all the accessible grids in
between the position of the index
and the position of the index
are reordered in reverse order, such that
and
become adjacent accessible grids in
. It can be observed that through the learning operation, the individual can acquire part of the gene fragment from the learning object. If the learning object is
, the learned gene fragment might be an outstanding gene combination. And if the learning object is a random individual, the diversity of the individual can be enhanced.
4.3. Steps of the Algorithm
The implementation steps of the complete-coverage path-planning algorithm based on transition probability and learning perturbation operator are as follows.
Step 1: Define the iteration number , the maximum iteration number , the population size , the degree of greediness , and the greedy factor . Obtain the map information, set the starting and ending points of the path, and calculate the state matrix of the map by means of Equation (4). The adjacency matrix and distance matrix of the map are respectively calculated by Equation (5) and Equation (6). The transition probability matrix for each accessible grid transferring to other accessible grids is computed by Equation (7).
Step 2: Create an individual , and utilize the specified starting grid number as the first element of , i.e., . Generate the random number . If , then employ the greedy initialization strategy based on transition probability to generate the individual and proceed to Step 3. Otherwise, the individual is randomly generated and proceed to Step 4.
Step 3: Generate the random number . If , the next node in is generated according to the transition probability matrix and Equation (9). Otherwise, the cumulative sum probability of each row of is calculated, and an accessible grid is selected as the next node in by using the roulette—wheel selection method.
Step 4: Determine whether the individual encompasses all accessible grids. If yes, go to Step 5. Otherwise, execute Step 3.
Step 5: If the population size reaches , Repair population to guarantee that the starting grids and end grids of all individuals meet the path requirements. Then Step 6 will be executed. If not, Step 2 will be executed and new individuals will be generated.
Step 6: If , go to Step 9. Otherwise, go to Step 7.
Step 7: Arrange the fitness of all individuals in descending order and divide the population into four subgroups according to this order. Different learning or perturbation operations are carried out for individuals in different subgroups to generate a new population.
Step 8: Repair population to guarantee that the starting grids and end grids of all individuals meet the path requirements. Increase the number of iterations by one and return to Step 6.
Step 9: Output the optimal solution of the population.
The repair operation mentioned in Steps 5 and 8 is designed to ensure that the starting grids and ending grids of all individuals comply with the path requirement. For each individual in the population, it is necessary to guarantee that the path begins at the designated starting grid and terminates at the specified ending grid. As illustrated in the figure below, assuming the map’s starting point is grid 1 and the endpoint is grid 10, a generated path shown in
Figure 6 does not start at grid 1 nor end at grid 10. This requires repair operations, which is swapping the position of grid 1 with the first node in the path and exchanging grid 10 with the last node in the path, as demonstrated in
Figure 7. Through these repair operations, the starting grid is placed at the beginning, and the ending grid is positioned at the end of the path.
Figure 8 presents the flowchart of the CCPP-TPLP algorithm.








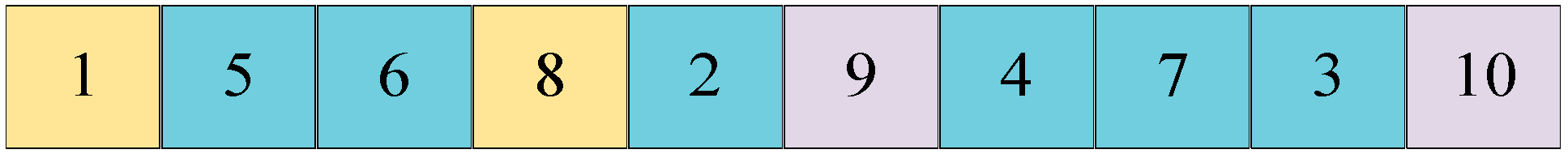












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}