1. Introduction
With the acceleration of urbanization and rapid population growth, the improvement of residents’ living standards has led to a diversification of consumption structures and a sharp increase in domestic waste. It is expected that global solid waste generation will reach 2.2 billion tons per year by 2025 [
1]. Effectively managing this growing amount of waste has become a significant challenge. While waste sorting and recycling are effective methods for dealing with urban waste and protecting the environment, the wide variety and shapes of waste require substantial human investment for accurate classification [
2]. Additionally, residents’ insufficient awareness of classification and incomplete implementation of relevant policies result in unsatisfactory waste classification outcomes [
3]. Accurate waste classification technology can effectively distinguish different types of waste, significantly improve the feasibility of harmless treatment, ensure hazardous waste is specially treated, and reduce threats to the environment. Automated waste processing technology, leveraging artificial intelligence and machine learning, further enhances sorting efficiency and reduces operating costs [
4,
5]. Therefore, developing effective automatic waste classification methods has significant academic and practical importance.
Manual waste classification poses significant challenges due to its reliance on human labor, which is inherently time-consuming, costly, and prone to errors [
6]. Workers are required to visually inspect and categorize heterogeneous waste materials—including plastics, metals, and organics—often under suboptimal conditions. This process is not only inefficient but also subject to inconsistencies arising from human fatigue and subjectivity, leading to frequent misclassification. For example, non-recyclable plastics may be incorrectly sorted as recyclable, thereby compromising the effectiveness of downstream recycling operations and increasing processing costs. The variability in waste appearance—caused by contamination, deformation, or degradation—further complicates accurate sorting, reducing throughput and diminishing resource recovery rates. These limitations place a growing burden on waste management systems, especially in the context of escalating urban waste volumes. Moreover, improper sorting of hazardous materials, such as batteries, can result in significant environmental risks, including soil and water contamination. In light of these challenges, there is an urgent need for robust, automated classification solutions. Leveraging the capabilities of deep learning, such systems promise substantial improvements in accuracy, efficiency, scalability, and overall cost-effectiveness, making them a critical advancement for modern waste management [
7].
Previous studies have applied deep learning to waste classification with promising results. In 2016, Yang et al. from Stanford University introduced the TrashNet dataset, comprising 2527 images, which has become a cornerstone for developing waste classification models [
8]. Subsequent research has leveraged transfer learning and innovative architectures to enhance performance. For example, Zhang et al. applied DenseNet169 to their NWNU-TRASH dataset, outperforming other algorithms despite high computational costs [
9]. Wu et al. improved the VGG architecture for better feature extraction, though it struggled with varying object scales and interpretability [
10]. Similarly, Lin et al. developed MSWNet using ResNet50 for urban waste sorting, boosting efficiency via transfer learning but requiring substantial resources [
11]. Hossen et al. proposed GCDN-Net, enhancing interpretability with activation mapping (Score-CAM), yet it demands extensive labeled data and processing power [
12]. Despite these advancements, limitations such as limited sample diversity, insufficient accuracy, and high computational demands persist. To address these, Transformer models have emerged as a promising alternative. Hu et al.’s Swin Transformer improved accuracy and efficiency but faced challenges with imbalanced datasets and complex environments [
13]. Alrayes et al. achieved 95.8% accuracy on TrashNet using an enhanced Transformer, though it too required significant resources [
14]. For resource-constrained settings, lightweight models have been explored. Xia et al.’s YOLO-MTG offers robust multi-target detection under varying lighting, albeit with slower inference on some hardware [
15]. Gupta et al.’s SmartBin, built on InceptionNet and Raspberry Pi, enables real-time classification but still demands considerable power [
16]. While these methods have propelled waste classification forward, their practical deployment is often hindered by resource demands, scalability, and adaptability. Thus, selecting and tailoring models to specific application needs is critical for achieving optimal results. Existing studies have combined image classification technology and machine learning methods to improve waste classification based on image recognition, but they still have certain limitations. These limitations include (1) low diversity of waste image samples, far from actual samples; (2) insufficient accuracy of waste classification models to meet actual needs; (3) deficiencies in real-time response and deployment, hindering timely and effective waste classification; and (4) limited generalization ability, restricting applicability in different scenarios.
To overcome the limitations of existing automated classification systems, this study introduces an efficient hybrid–modal fusion approach named HFWC-Net. ‘Hybrid–modal fusion’ refers to the integration of multiple image features through a hybrid architecture that combines convolutional neural networks (CNNs) and Transformer models, enhancing the model’s ability to perceive complex waste types. Unlike traditional multi-scale fusion, which focuses on extracting features at different spatial scales, or multimodal fusion, which emphasizes integrating information from distinct data sources (e.g., images and text), hybrid–modal fusion achieves finer-grained feature integration at the architectural level. Specifically, HFWC-Net leverages CNNs for local feature extraction and Transformers for global feature perception, employing a layered design and an Agent Attention mechanism to effectively fuse diverse image characteristics. This hybrid structure not only improves adaptability to complex backgrounds and varied waste types but also enhances computational efficiency and training speed through the LionBatch optimization strategy. By incorporating this approach, HFWC-Net addresses key challenges in waste classification, offering a robust solution for modern waste management.
The main contributions of this study include (1) constructing a new dataset, MixTrash, containing 135 categories of waste, with highly diverse image data meeting real-world classification needs; (2) integrating a new attention mechanism, Agent Attention, into the backbone model to effectively manage computing resources and focus on relevant input data, improving model performance with high expressiveness and low computational complexity; (3) proposing a new optimization strategy, LionBatch, combining model pruning technology with a new optimizer to reduce computational requirements and improve operational efficiency, thereby reducing resource consumption while maintaining high accuracy.
2. Materials and Methods
2.1. Self-Built Dataset MixTrash
Currently, there are few public datasets available in the field of waste identification, with most related studies relying on the TrashNet dataset [
8]. The TrashNet dataset is a small collection of recyclable waste images, including six categories: glass, paper, cardboard, plastic, metal, and general waste, comprising a total of 2527 photos. However, this dataset has several shortcomings: the sample size is too small; the distribution of different types of waste is uneven; the background of the images is too uniform, which does not reflect real-world conditions and hinders the generalization ability of trained models. To address these limitations, we constructed a new waste image dataset, MixTrash, using Internet searches and manual photography. The MixTrash dataset includes 135 different categories of waste, such as banana peels, old toothbrushes, cans, old clothes, wastepaper, leftovers, and waste batteries, totaling 52,324 images (
Figure 1). The images in MixTrash feature varied backgrounds, and the number of images for different types of waste is balanced, ensuring high data diversity that better meets the needs of real-world scenarios.
The MixTrash dataset is a multi-category image dataset specifically designed for waste recognition tasks, comprising four primary waste categories—recyclables, kitchen waste, hazardous waste, and other waste—encompassing a total of 135 subclasses (
Table 1). The dataset is developed based on a standardized waste classification system: recyclables include 74 subclasses such as metal tools (e.g., anvils, scissors), plastic products (e.g., shampoo bottles, plastic bottles), wooden items (e.g., chair, wooden shovels), textiles (e.g., old clothes), and paper products (e.g., books, paper cups); kitchen waste comprises 21 subclasses covering easily perishable organic matter (e.g., fruit cores, peels) and processed food residues (e.g., sausages, biscuits); hazardous waste includes 15 subclasses such as toxic metal items (e.g., thermometers, button batteries) and pure electronic waste (e.g., power banks, circuit boards); and other waste features 26 subclasses like contaminated composite materials (e.g., wet wipes, old gloves). All images were captured in real-world settings (e.g., kitchens, streets) under varied lighting conditions and object variations. Compared to existing datasets such as TrashNet, MixTrash provides notable enhancements in sample scale, inter-class balance, and environmental diversity, offering essential data support for the development of efficient and robust waste classification models.
2.2. HFWC-Net
The Transformer architecture, with its self-attention mechanism, can effectively capture global features by focusing on the relationships between various regions in an image. Traditional convolutional neural networks (CNNs) primarily process information through local receptive fields, which can limit their ability to capture broader contextual information, resulting in inferior performance in complex image analysis tasks. Additionally, the hierarchical structure of CNNs often requires more layers to expand the receptive field, leading to larger, harder-to-optimize models. To address these shortcomings, the Transformer architecture is not only better suited for complex image analysis tasks, but its design also naturally supports parallel computing. This makes Transformers more efficient in processing large-scale datasets and accelerating the training process. To further enhance performance, this study proposes a new network architecture, HFWC-Net. HFWC-Net is designed to combine the efficient self-attention mechanism of the CSWin Transformer with deep feature processing capabilities specifically tailored for complex images. This approach leverages the CSWin Transformer’s strengths in multi-scale and multi-dimensional information processing. HFWC-Net addresses the limitations of CNN models in image processing through fine-grained feature fusion and efficient optimization strategies, thereby improving the model’s overall performance and adaptability.
HFWC-Net’s hybrid–modal fusion framework effectively integrates the strengths of both CNNs and Transformers into a unified architecture. This fusion is achieved through a hybrid design that combines the local feature extraction capabilities of CNNs with the global context modeling power of Transformers. Specifically, the network first employs a convolutional token embedding layer to capture fine-grained local features from input waste images, such as edges and textures. This is followed by a sequence of CSWin blocks and HFWC blocks, which leverage cross-shaped Window Attention and Agent Attention mechanisms to model long-range dependencies and multi-scale contextual relationships. Merge Blocks play a crucial role in progressively reducing spatial dimensions while increasing channel depth, thereby enabling seamless integration of local and global features within the network’s four-stage hierarchical structure. This hybrid fusion strategy offers several advantages: by incorporating the global perceptual ability of Transformers, it overcomes the limited receptive field of CNNs; and through a coarse-to-fine integration scheme, it enriches feature diversity while reducing computational overhead. These characteristics make HFWC-Net a highly practical and efficient solution for intelligent waste classification tasks.
The overall architecture of HFWC-Net is shown in the image (
Figure 2). This neural network utilizes a four-layer pyramid structure to efficiently process and abstract image features. Each layer’s design goals and structures are carefully configured to optimize feature extraction and representation capabilities. The first three layers of the network form the basic feature extraction and processing modules, each comprising multiple CSWin Blocks. These blocks employ the self-attention mechanism of a cross-shaped window to process image data, which is particularly suited for capturing local features and their spatial correlations. In this four-layer pyramid structure, the spatial resolution of the image is gradually reduced through the fusion module, Merge Block, while the channel dimension is doubled at each upward layer. This design allows the network to progressively enhance the abstraction ability of features while maintaining a low computational cost. The Merge Block is primarily responsible for reducing the number of tokens and merging features from adjacent layers, enabling the model to capture more comprehensive and high-level features as the number of layers increases.
Through this pyramid setting, the first three layers are primarily responsible for feature extraction, ranging from basic to relatively complex. The CSWin Block in each layer refines and strengthens the features at different scales, preparing them for advanced feature integration. The final layer utilizes the HFWC Block, which replaces the traditional cross-shaped window self-attention mechanism with the Agent Attention mechanism. This effectively reduces the number of features involved in the calculation. The introduction of agent tokens allows the attention calculation to focus on significant features, avoiding redundant computations of the full-size feature matrix. This achieves linear complexity and significantly improves the model’s computational efficiency. By optimizing the processing flow and reducing the computational burden, the HFWC Block not only enhances the model’s capability to handle complex data but also improves its ability to capture details and distinguish different categories. Through innovative structural design, HFWC-Net effectively improves the depth and breadth of feature processing, enhances the model’s expressiveness, and optimizes computational efficiency. This enables HFWC-Net to more accurately understand objects in complex categories, making it particularly effective for challenging tasks such as waste classification.
2.3. Cswin Transformer Block (CST Block)
The CSWin Transformer is an innovative Transformer architecture designed for computer vision tasks, proposed by Microsoft Research Asia in 2021 [
17]. Through its novel self-attention mechanism and position encoding method, the CSWin Transformer optimizes the theoretical applicability of the Transformer architecture and demonstrates significant performance advantages in actual vision tasks.
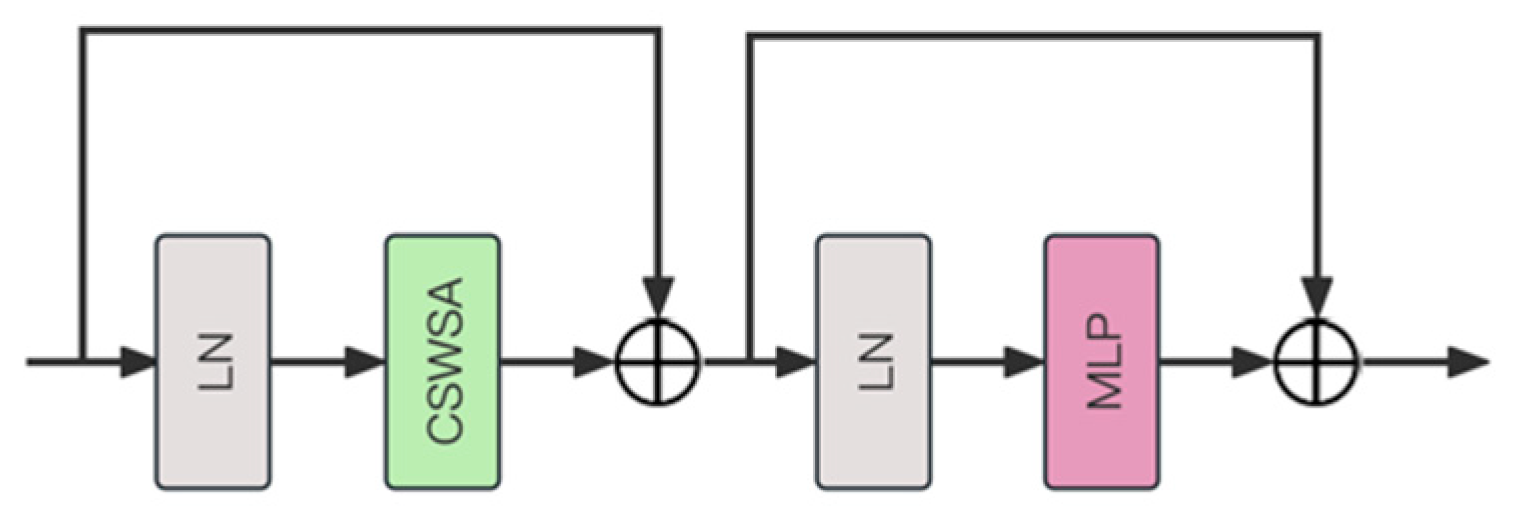
The structure of the CSWin Transformer Block is shown in the image (
Figure 3). Layer normalization (LN) is used at the beginning and middle of the module to normalize the mean and variance of the input layer [
18]. Between the two layer normalization stages, the cross-shaped window self-attention mechanism (CSWSA) is employed. CSWSA allows the model to focus on key regions of the image while maintaining computational efficiency by forming a cross-shaped window on the input image or feature map. Following CSWSA is a multilayer perceptron (MLP), which typically consists of several fully connected layers and uses nonlinear activation functions such as ReLU between these layers [
19]. The MLP further processes the output of the self-attention layer, increasing the nonlinearity of the network and enabling the model to learn more complex feature representations.
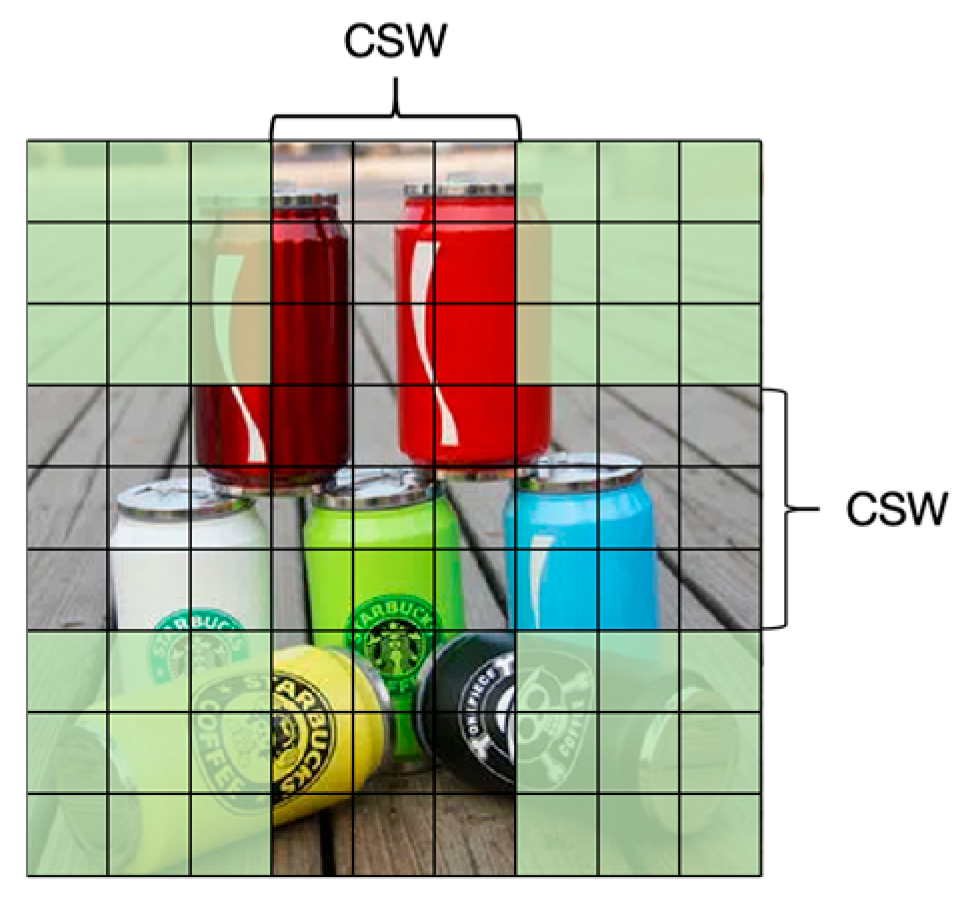
One of the core features of the CSWin Transformer is its cross-shaped window self-attention mechanism. Unlike traditional Transformers that apply self-attention across the entire image or within fixed-size windows, CSWSA first splits the input image into multiple small windows. Each window is further divided into a cross center and four corners, with the center window forming a cross shape covering strips in the horizontal and vertical directions (
Figure 4). Within each cross-shaped window, the model calculates self-attention independently, meaning it evaluates the relationship of each patch within the window with all other pixels in the same window. This design allows the model to more effectively capture long-range dependencies in the image while reducing computational complexity.
2.4. Merge Block
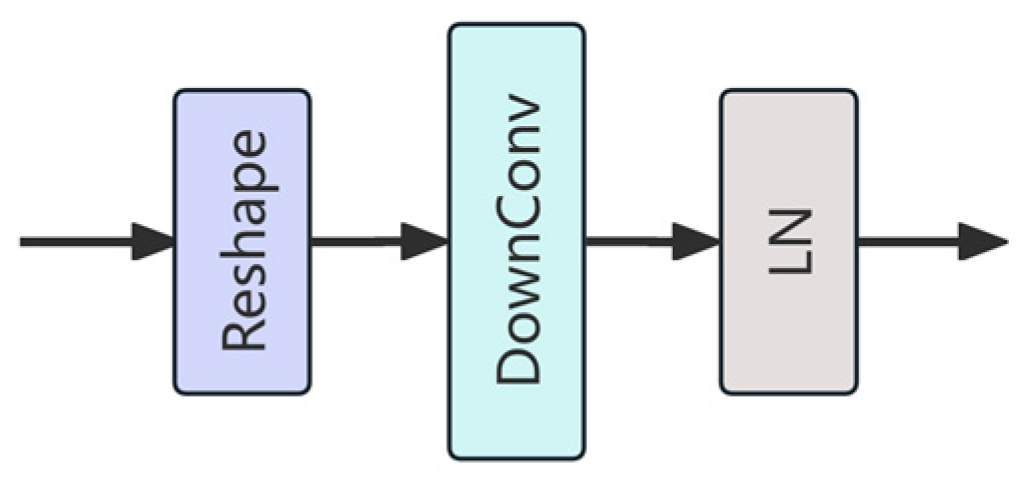
Merge Block is a dedicated module in this study designed to enhance feature fusion by enabling efficient integration and transmission of multi-level feature information. The module comprises three core stages: reshaping, convolution-based downsampling, and normalization (
Figure 5). First, the input sequence of tokens is reshaped to reconstruct its spatial structure, enabling the model to reestablish spatial correlations among features. This transformation is essential for bridging the gap between sequence-based representations and spatial operations. Next, a 3 × 3 convolution with a stride of 2 (denoted as “DownConv”) is applied to simultaneously reduce spatial resolution and expand the channel dimension, thereby enriching the semantic content while reducing computational cost. Finally, LN is applied to stabilize the feature distribution and facilitate more robust training dynamics. Unlike traditional vision Transformer modules—such as ViT’s fixed Patch Merging or Swin Transformer’s window-based downsampling—the Merge Block leverages learnable convolutional operations, allowing it to adaptively capture local spatial dependencies and contextual information during the fusion process. Its CNN-based design not only enhances local detail modeling but also ensures higher computational efficiency and better compatibility with modern hardware. Within the HFWC-Net framework, the Merge Block serves as a crucial inter-stage connector, promoting seamless and effective feature propagation across hierarchical layers.
2.5. HFWC Block
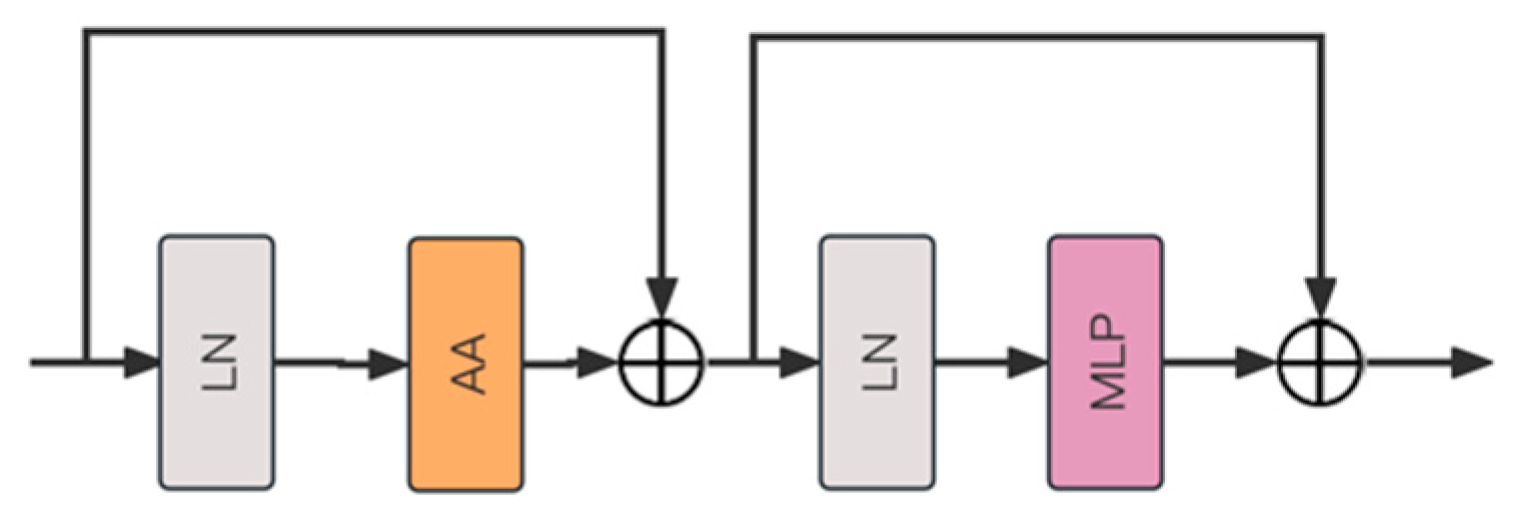
HFWC Block features an advanced Agent Attention Mechanism (AA) to optimize information processing flow (
Figure 6). The module employs layer normalization (LN) at both the initial and middle stages to standardize the mean and variance of the input layer. Between these two layer normalization stages, the Agent Attention Mechanism is integrated. This mechanism optimizes attention calculation by introducing agent tokens, which reduces the complexity of direct calculations and improves the efficiency and accuracy of information processing. Following the Agent Attention Mechanism, the module also incorporates a multilayer perceptron (MLP), which consists of several fully connected layers and embeds nonlinear activation functions between layers. The HFWC Block with Agent Attention excels in computational efficiency and fast processing, making it suitable for various application scenarios.
Agent Attention was proposed by Han et al. to balance computational efficiency and representation capabilities [
20]. In visual Transformers, the traditional global attention mechanism has high expressive ability but also high computational complexity, limiting its application in high-resolution scenes. The cross-attention mechanism expands the attention area of each token within the Transformer block by performing self-attention in horizontal and vertical strips. However, processing high-resolution images and large-scale data can still pose a high computational burden. Agent Attention combines the advantages of Softmax [
21] and linear attention [
22]. It introduces agent tokens, simplifies the aggregation process of global information, maintains high expressive ability, and reduces computational complexity, thus overcoming the performance bottlenecks encountered by the cross-attention mechanism in processing large-scale data. This attention mechanism can more effectively focus on key areas of the image, thereby improving classification accuracy and efficiency, which is particularly advantageous for processing large amounts of data and complex tasks.
The Agent Attention mechanism inserts an additional set of token
into the attention triplet
calculation to form a new quadruple attention paradigm
. The Agent Attention mechanism consists of two traditional Softmax operations (
Figure 7). The first Softmax is applied to the triplet
, where token
is used as a query to aggregate information from the value
to form a new agent value
. The attention matrix is between
and
, effectively reducing the need to directly process all data and greatly reducing computational complexity. The second Softmax is calculated on the triple
, where
is the result of the first step. The newly introduced token
acts as a “proxy” for query
, as they directly collect information from
and
and then pass the results to
. Query token
no longer needs to communicate directly with the original key
and value
. This feature reduces the quadratic complexity of Softmax to linear complexity, while retaining the global context modeling capability.
The algorithm of the Agent Attention mechanism is as follows. First, we simplify Softmax and linear attention to
where
represent query, key, and value matrices, and Agent Attention can be written as
equivalent to
The Agent Attention mechanism consists of two Softmax operations, responsible for agent aggregation and agent broadcasting, respectively. Specifically, the agent token
is first regarded as a query, and attention calculation is performed between
,
, and
to aggregate the agent feature
from all values. Subsequently,
is used as the key and
as the value in the second attention calculation of the query matrix
to broadcast the global information of the agent feature to each query token, obtaining the final output O. The newly defined agent token
essentially acts as an agent of
, aggregating global information from
and
, and then broadcasting it back to
, maintaining the global context modeling capability. To better utilize the position information, the Agent Attention adds carefully designed agent biases
,
:
Based on these designs, the Agent Attention mechanism can be expressed as
Modern Transformer models typically use sparse attention [
23] or Window Attention [
17] to reduce the computational burden of Softmax attention. Benefiting from linear complexity, these attention mechanisms enjoy the advantages of large and even global receptive fields while ensuring manageable computational costs. Agent Attention integrates these two forms of attention, drawing on their strengths to balance computational efficiency and expressiveness. By introducing agent tokens, relevant information, Agent Attention effectively focuses the model’s capacity on important features within the input data.
2.6. New Optimization Strategy LionBatch
AdamW has become a cornerstone optimizer in deep learning due to its decoupled weight decay mechanism, which separates regularization from gradient updates to enhance training stability [
24]. However, despite its effectiveness, AdamW has some significant drawbacks, particularly in terms of memory consumption and computational efficiency. AdamW stores multiple moving averages of gradients and squared gradients for each parameter, which can quickly become resource-intensive, especially in models with numerous parameters. This architecture leads to inefficient GPU memory utilization and elevated computational costs during backpropagation. Furthermore, AdamW exhibits pronounced sensitivity to hyperparameter configurations (e.g., learning rate,
momentum coefficients, weight decay coefficient), necessitating meticulous tuning to avoid suboptimal convergence or training instability. To address these limitations, Lion optimizer introduces a resource-efficient paradigm by redefining momentum utilization [
25]. Unlike AdamW’s adaptive learning rate mechanism, Lion employs a sign-based update rule that retains only a single momentum buffer, reducing memory consumption while eliminating redundant gradient magnitude calculations. This design enables linear computational scaling with model size, enhancing training throughput for deep architectures. Crucially, Lion replaces AdamW’s complex hyperparameter dependencies with a simplified two-parameter framework (learning rate,
momentum), demonstrating superior robustness across tasks. This simplicity allows Lion to converge more quickly and efficiently, especially on large datasets, without the need for fine-tuning complex learning rates or momentum parameters. This makes Lion more accessible and effective for researchers, especially when dealing with complex models and large datasets that require both speed and accuracy.
Traditional pruning techniques reduce model size and computational complexity by removing some weights or neurons in the network, including unimportant weight pruning and random pruning [
26]. While traditional pruning helps improve model running speed and reduce storage requirements, it often leads to a decline in model performance, especially when the pruning ratio is high, as the model may lose key information. To address the shortcomings of traditional pruning techniques, Qin et al. from the National University of Singapore proposed an unbiased dynamic data pruning method, InfoBatch [
27]. Traditional pruning methods often introduce biases in gradient expectations by discarding important samples that help the model generalize. InfoBatch avoids this bias by adjusting the gradient weights of the remaining samples while pruning them (called gradient rescaling), maintaining the same gradient expectations as the unpruned dataset.
To better optimize the model, this paper proposes a new optimization strategy, LionBatch, which combines the Lion optimizer and InfoBatch pruning. The main algorithm flow is shown in the image and table (
Figure 8 and Algorithm 1). By integrating these two technologies, our new optimization strategy not only improves the training speed and resource utilization efficiency of the model but also significantly reduces the computing resources required during the training process while maintaining high classification accuracy. LionBatch tracks momentum during model training and computes updates through symbolic operations, thereby reducing memory overhead and ensuring update magnitudes are consistent across all dimensions. LionBatch implements dynamic pruning, allowing pruning decisions to be adjusted based on the real-time performance of the data during training. This allows for more detailed control of the training process. Through this dynamic and unbiased pruning method, LionBatch can reduce training costs while maintaining model performance, achieving lossless training acceleration. These innovative designs demonstrate significant advantages in improving model efficiency and effectiveness.
The detailed steps of the LionBatch algorithm are as follows.
| Algorithm 1. LionBatch Optimization Strategy |
not converged
sign
|
First, calculate the average loss of the entire dataset and directly prune the part with smaller loss. After each epoch or several epochs of training, recalculate the average loss of the entire dataset. For pruned and untrained samples, use the previous loss; for pruned samples, use the updated loss after training. For data samples with losses less than the average loss, perform pruning with a certain probability . Due to the reduction in the number of samples, the gradient of the entire dataset will change, leading to inconsistency with the expected gradient of the original dataset. To address this, rescale the gradient of the data samples with losses less than the average loss. Then, use the Lion optimizer to optimize the pruned data subset, and calculate the current update momentum using the gradient and the previous momentum . Use the function to specify the update direction to update the model parameter . Combine the previous momentum and the current gradient to update the exponential moving average (EMA). Finally, repeat the above process to gradually optimize the model parameters until the desired performance indicators are achieved.
The LionBatch optimization strategy significantly reduces training time and computing resource consumption while maintaining high classification accuracy. By employing dynamic learning rates and momentum terms, LionBatch enables the model to converge to the global optimal solution faster, reducing the number of training iterations. This strategy not only makes the optimization process more efficient and stable but also reduces the risk of over-fitting and under-fitting. Additionally, LionBatch optimizes the model structure by dynamically removing redundant neurons, avoiding unnecessary computational burden and ensuring the model’s accuracy. The LionBatch strategy excels in optimizing computing resource consumption, which is particularly important for resource-constrained environments such as embedded or mobile devices, making it feasible to deploy deep learning models on these platforms.
2.7. Experimental Environment Set-Up
After building the HFWC-Net model, we used the PyTorch deep learning framework to train it in graphics processing unit (GPU) mode. In this experiment, two computer devices were used for the entire training and validation process. The detailed characteristics of the two devices are shown in the tables (
Table 2 and
Table 3). Machine 1 is primarily used to train CNN and Transformer architecture networks due to its strong computing power and efficient video memory management. This capability allows Machine 1 to handle a large number of matrix operations and data processing effectively. Machine 2, on the other hand, is used to run VMamba, as VMamba is more compatible with the Linux system, making its training on this device more efficient and convenient.
2.8. Experimental Evaluation Metrics
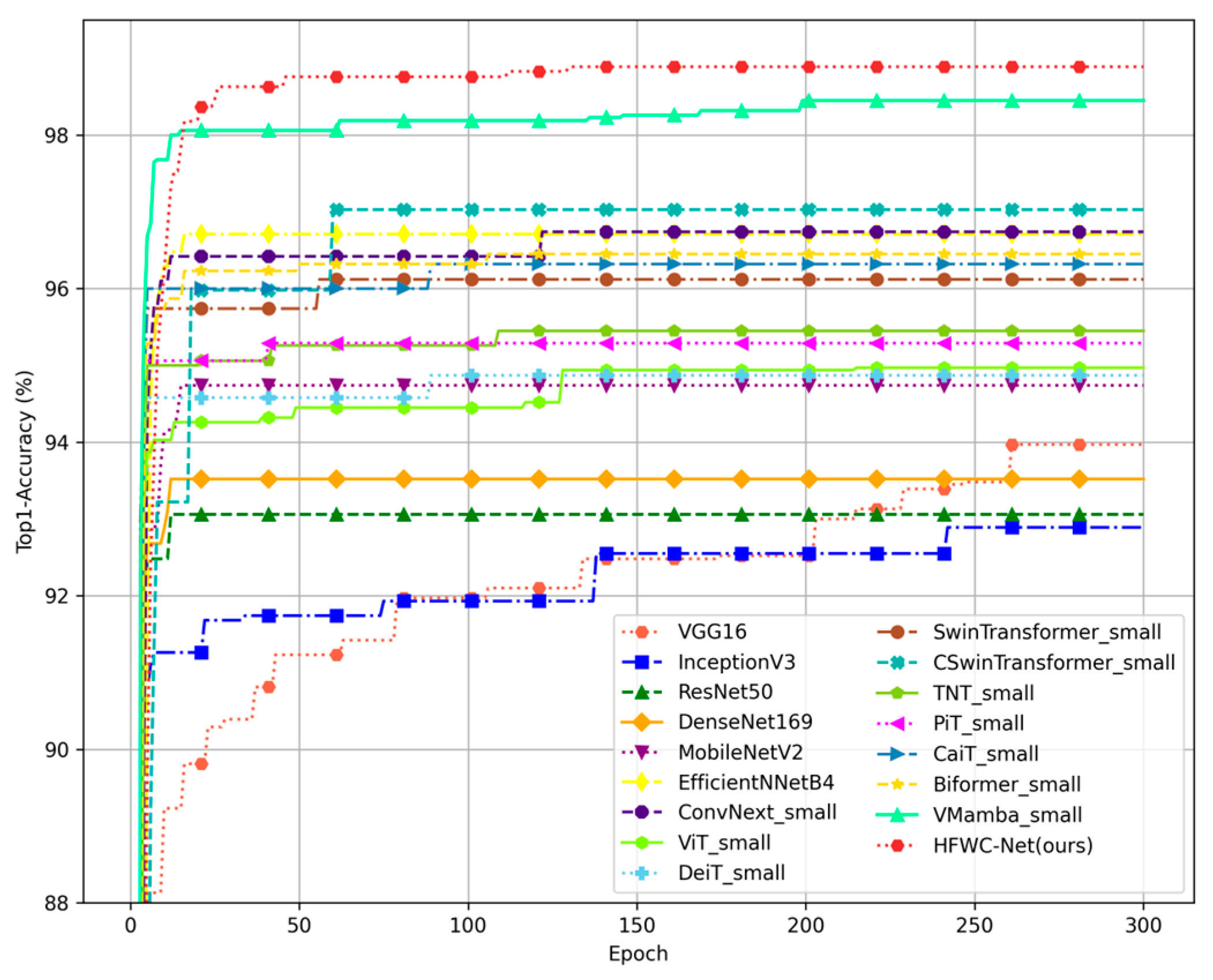
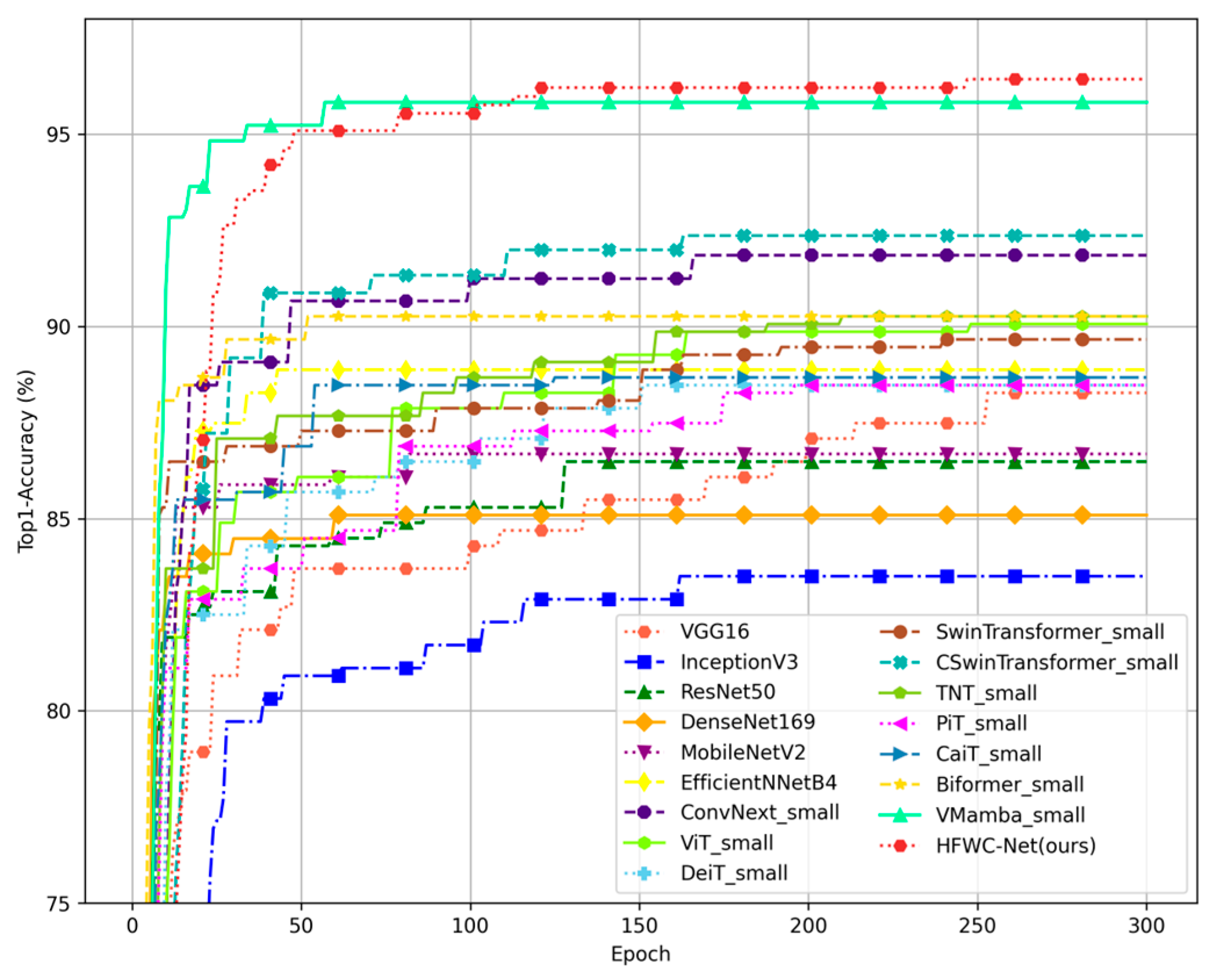
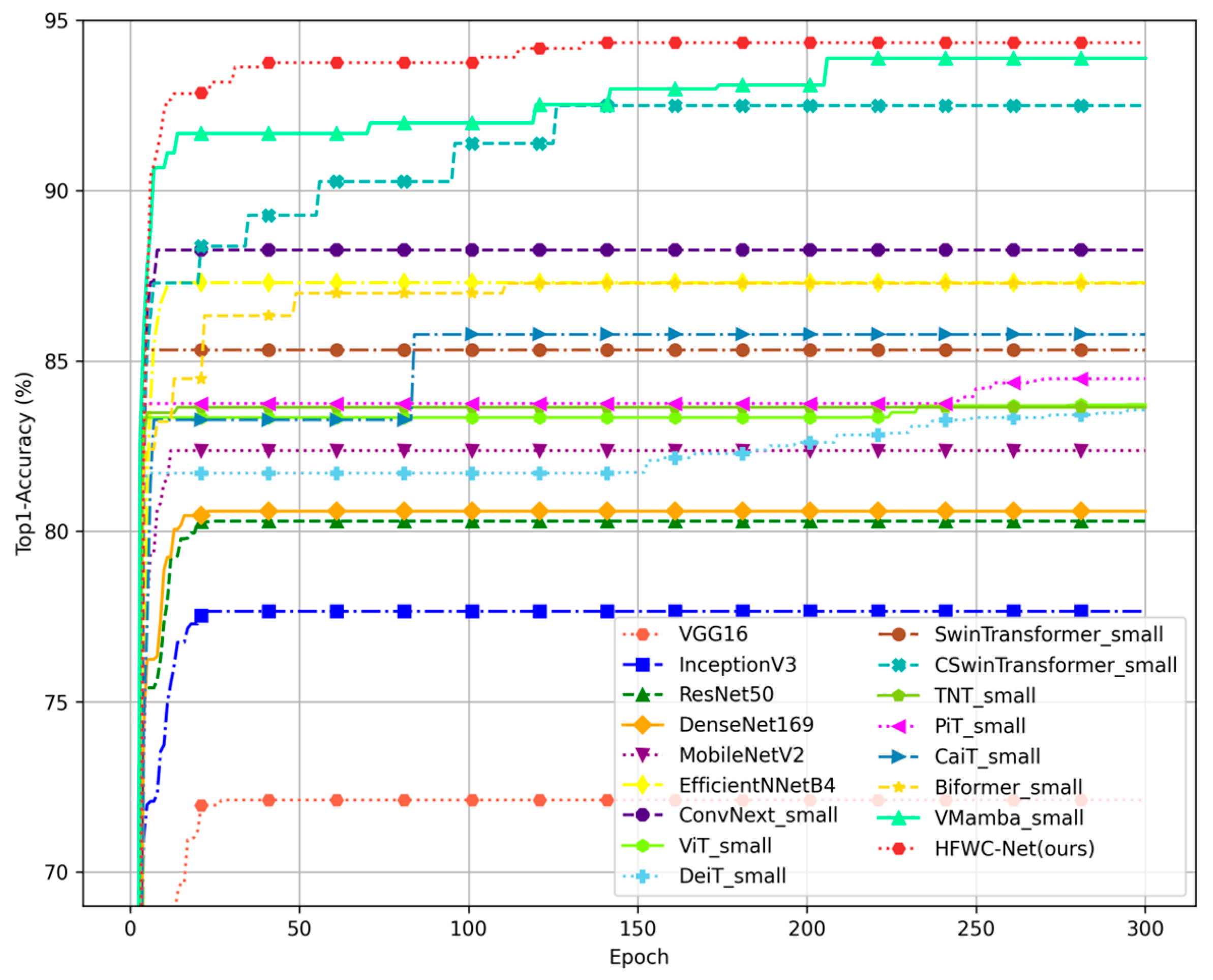
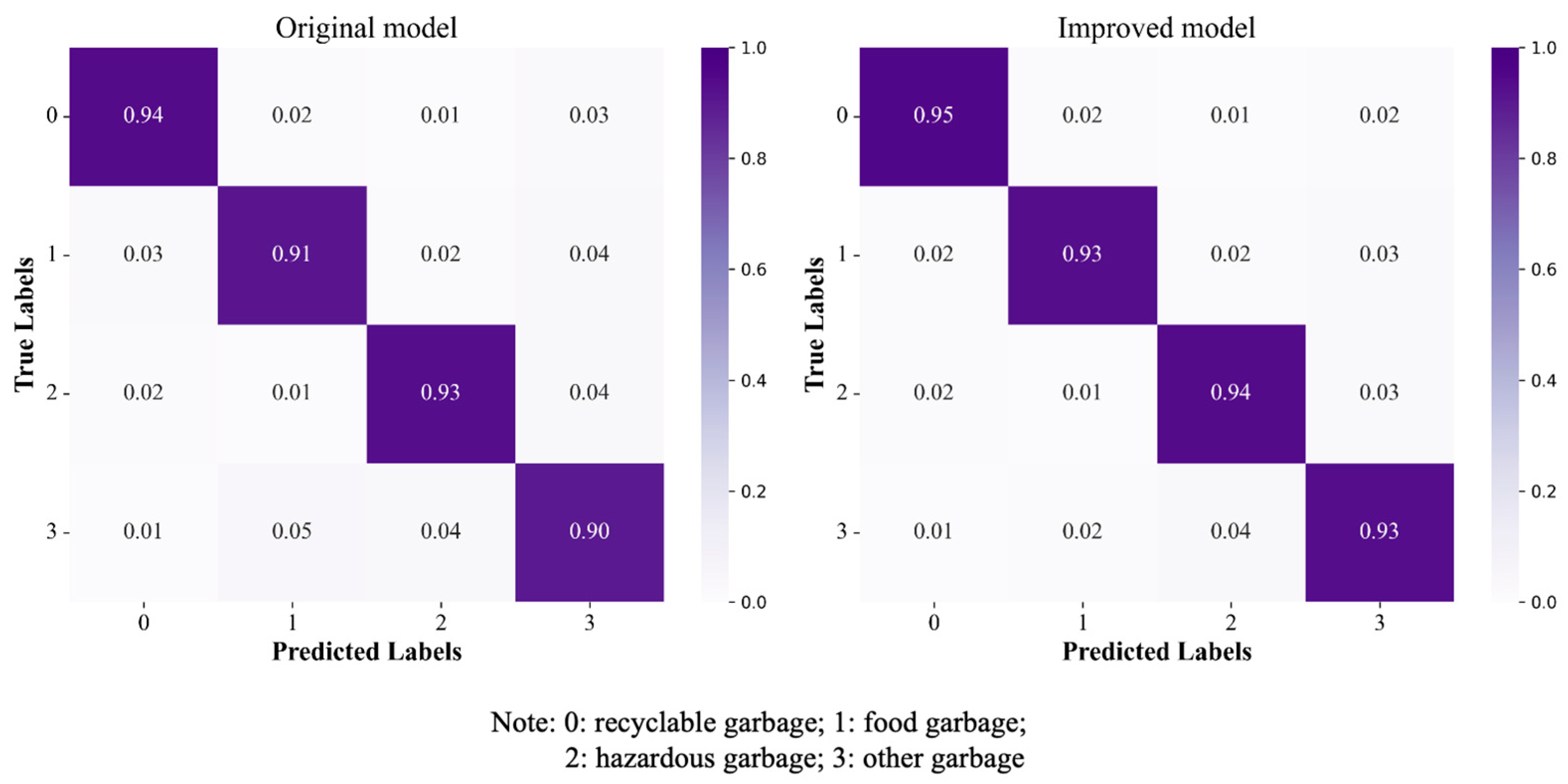
In this study, we used various deep learning models to conduct experiments on multiple datasets. To properly evaluate the performance of these models, we adopted established evaluation metrics, including Top1-Accuracy (Top1-Acc), precision, recall, and F1 score. These metrics are computed using data extracted from the confusion matrix, which contains key parameters such as the total number of test samples (ATs), true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). All values are calculated using the global confusion matrix, which consists of the results from cross-validation [
28].
5. Conclusions
This study proposes a new Transformer-based framework called HFWC-Net. By integrating the local feature extraction capabilities of CNNs with the global contextual understanding of hybrid–modal visual Transformers, HFWC-Net leverages this CNN-Transformer synergy, enhanced by the innovative Agent Attention architecture. The use of agent tokens overcomes the limitations of traditional triple attention, enhancing the model’s flexibility, adaptability, and information capture capabilities, thereby improving training efficiency. Additionally, HFWC-Net employs the unbiased dynamic selection and adaptive adjustment pruning method, LionBatch, which dynamically reduces the number of samples in each training iteration. This approach improves computational efficiency, significantly speeds up model training, and optimizes the utilization of computing resources.
However, challenges remain, such as limited performance on low-resolution images and unseen categories, highlighting constraints in feature extraction and generalization. Future work will focus on developing adaptive learning techniques and robust preprocessing methods to improve performance in complex scenarios. Additionally, efforts will be directed toward optimizing the model for resource-constrained environments. Overall, HFWC-Net offers a powerful and efficient solution for waste classification, with the potential to advance environmental sustainability and improve urban waste management practices.




 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}