GCAFlow: Multi-Scale Flow-Based Model with Global Context-Aware Channel Attention for Industrial Anomaly Detection


Abstract
1. Introduction
- We modify the subnetwork in the flow model to refine its probability estimation by hierarchical convolution and inverted bottleneck.
- We propose a global context-aware (GCA) channel attention mechanism and insert it into the flow-based model to optimize anomaly detection and localization.
- We conduct extensive experiments and GCAFlow performs well on the MvTeC AD, VisA, and BTAD benchmark datasets.
2. Related Work
2.1. Unsupervised Anomaly Detection
2.2. Normalizing Flows
2.3. Flow-Based Methods for UAD
2.4. Attention Mechanisms
3. Methods
3.1. Theoretical Background of Normalizing Flows
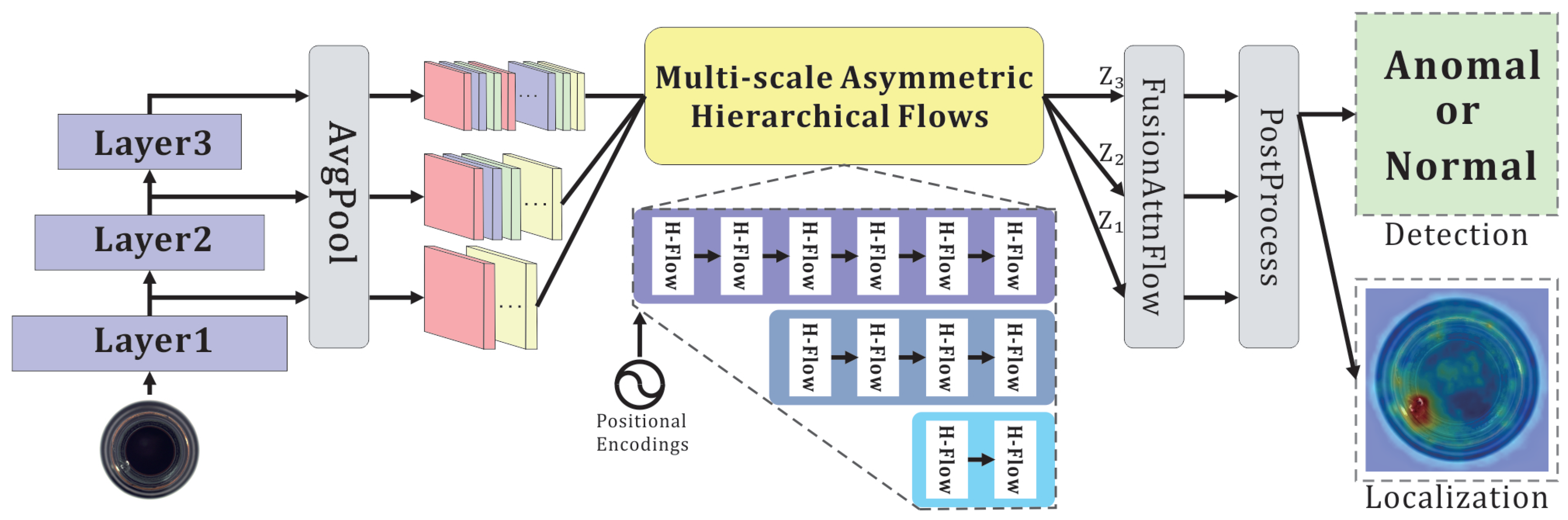
3.2. Overview
3.3. Feature Extractor
3.4. Hierarchical Convolutional Subnetwork
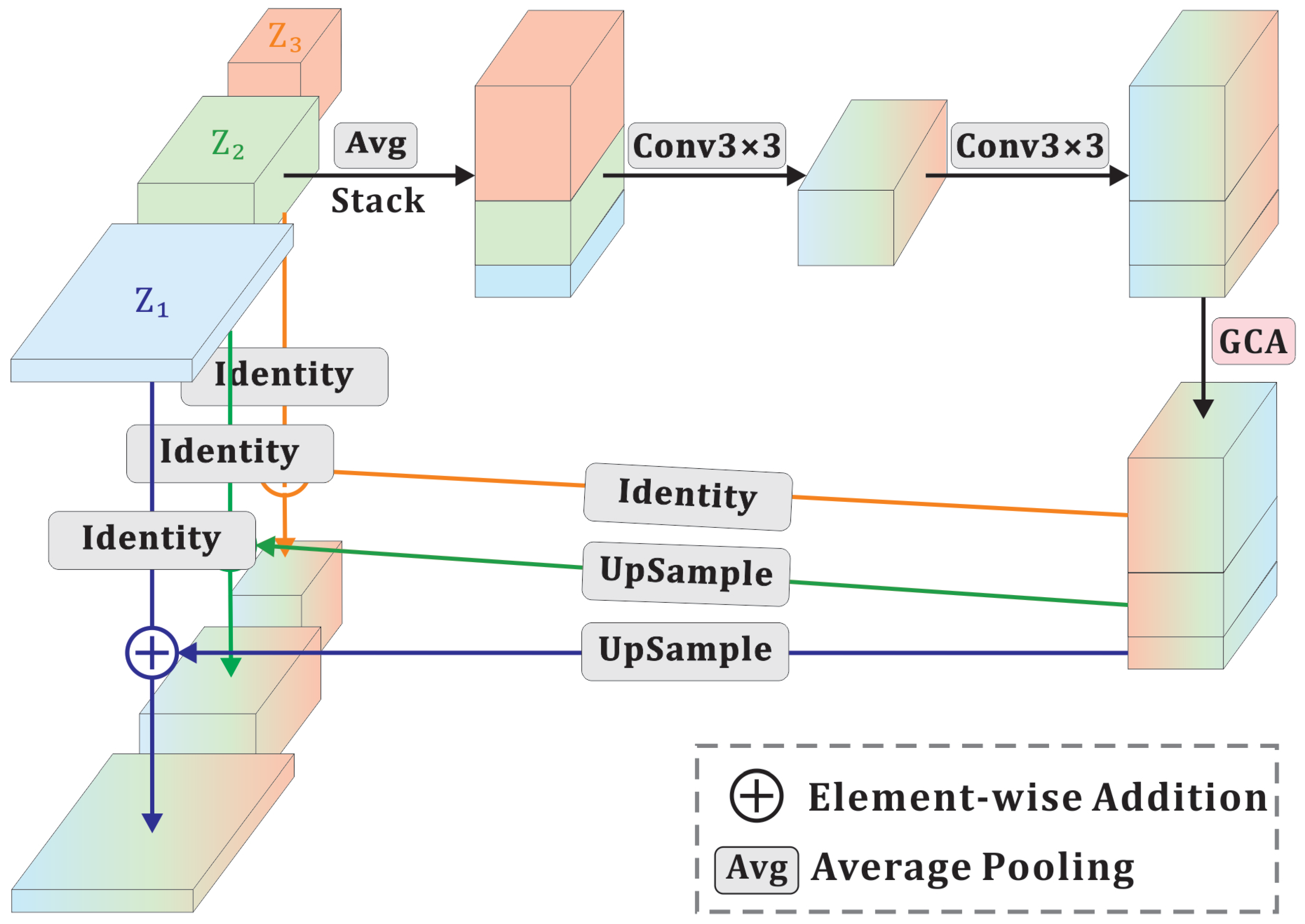
3.5. Global Context-Aware Module
3.6. FusionAttnFlow
3.7. Anomaly Score Generation
4. Experiments
4.1. Dataset
4.2. Evaluation Indicators
4.3. Implementation Details
4.4. Comparisons with Other Methods
4.5. Ablation Study
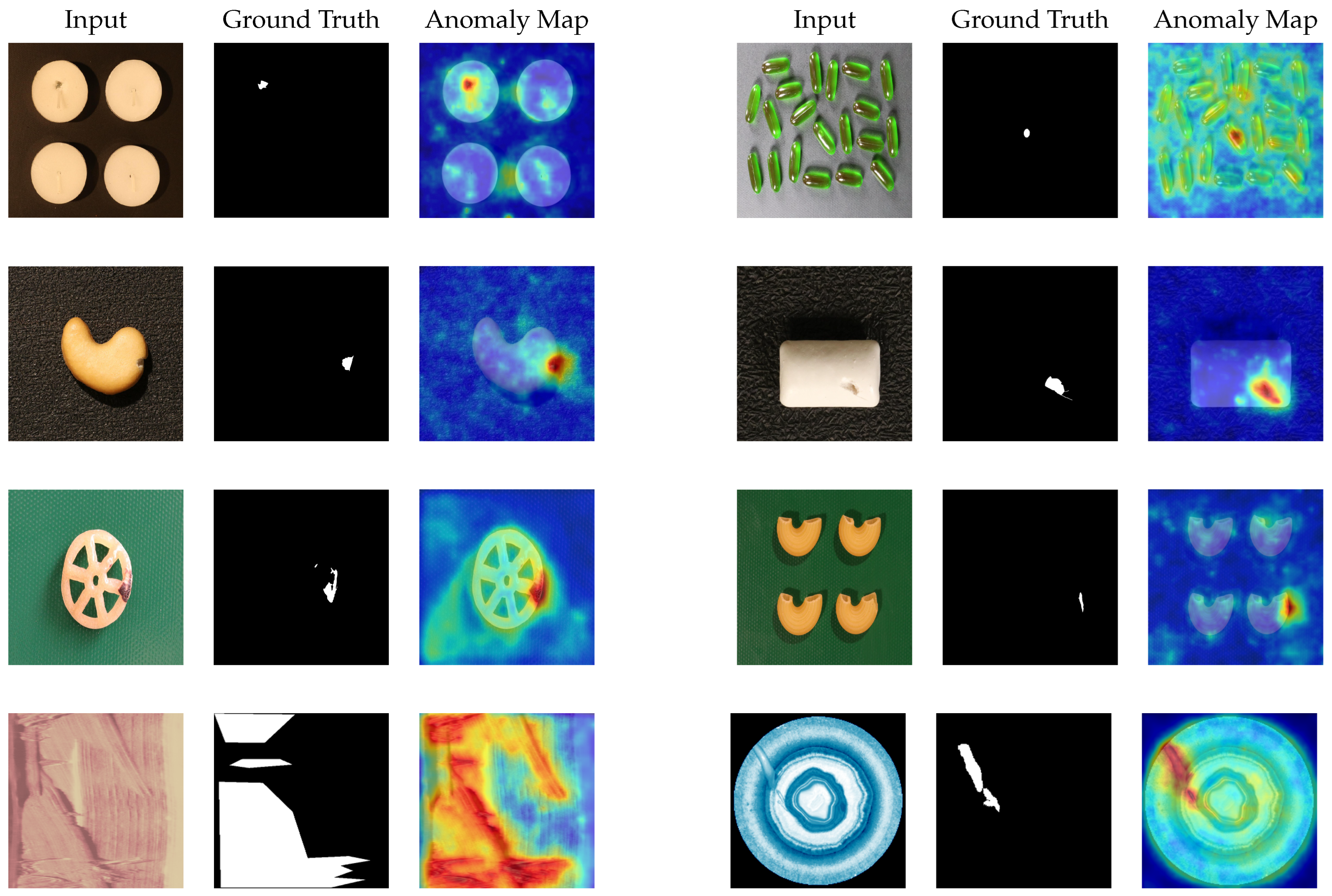
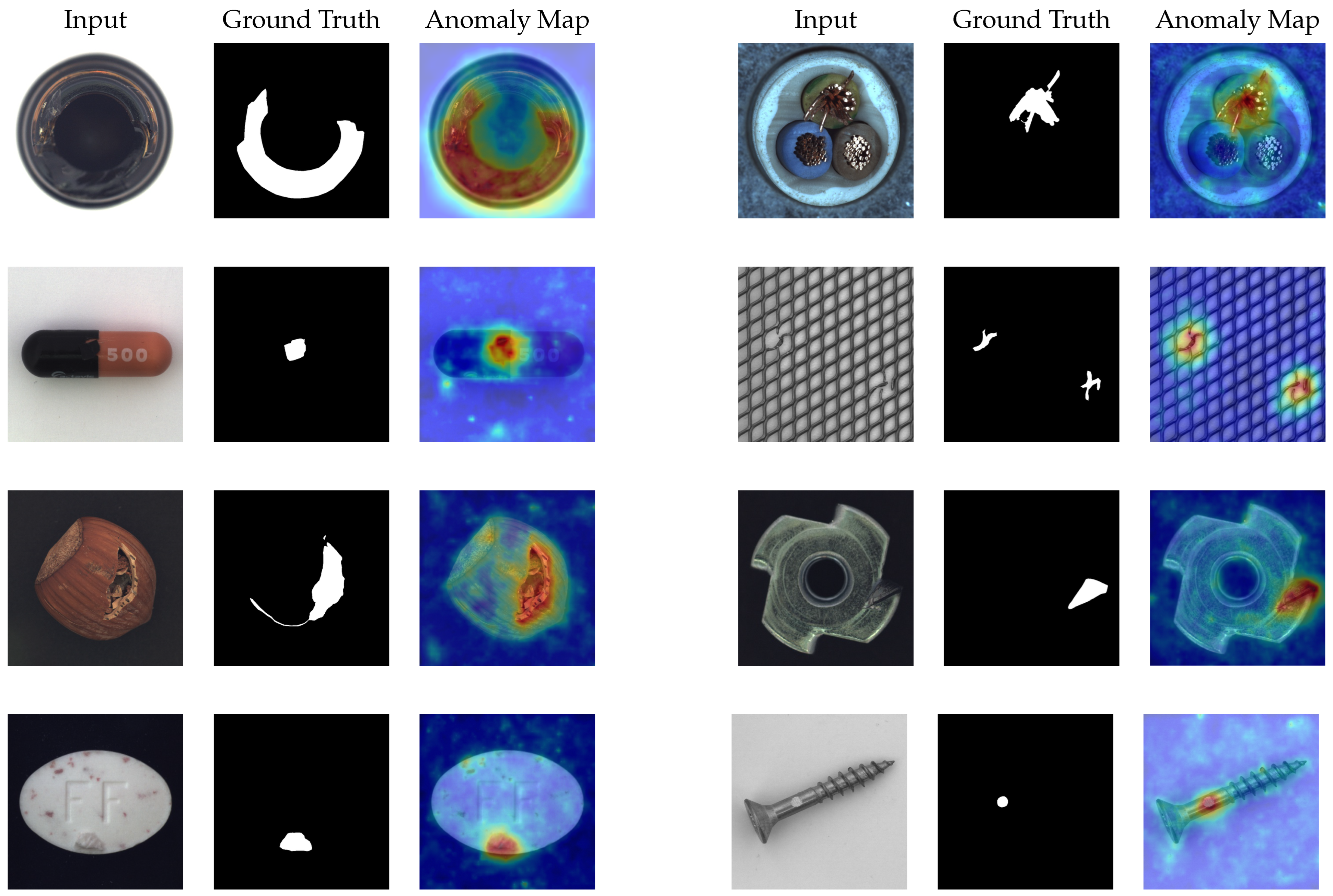
4.6. Visualization Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GCA | Global context-aware |
| AD | Anomaly detection |
| UAD | Unsupervised anomaly detection |
| H-Flow | Hierarchical flow |
| NLL | Negative log-likelihood |
References
- Fu, K.; Cheng, D.; Tu, Y.; Zhang, L. Credit card fraud detection using convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing, Kyoto, Japan, 16–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–490. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 322–339. [Google Scholar]
- Liu, Y.; Fan, L.; Zhang, C.; Zhou, T.; Xiao, Z.; Geng, L.; Shen, D. Incomplete multi-modal representation learning for Alzheimer’s disease diagnosis. Med. Image Anal. 2021, 69, 101953. [Google Scholar] [CrossRef] [PubMed]
- Xiao, C.; Xu, X.; Lei, Y.; Zhang, K.; Liu, S.; Zhou, F. Counterfactual graph learning for anomaly detection on attributed networks. IEEE Trans. Knowl. Data Eng. 2023, 35, 10540–10553. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Rudolph, M.; Wandt, B.; Rosenhahn, B. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1907–1916. [Google Scholar]
- Milković, F.; Posilović, L.; Medak, D.; Subašić, M.; Lončarić, S.; Budimir, M. FRAnomaly: Flow-based rapid anomaly detection from images. Appl. Intell. 2024, 54, 3502–3515. [Google Scholar] [CrossRef]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 98–107. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1088–1097. [Google Scholar]
- Zhou, Y.; Xu, X.; Song, J.; Shen, F.; Shen, H.T. Msflow: Multiscale flow-based framework for unsupervised anomaly detection. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 2437–2450. [Google Scholar] [CrossRef] [PubMed]
- Zhong, J.; Song, Y. UniFlow: Unified Normalizing Flow for Unsupervised Multi-Class Anomaly Detection. Information 2024, 15, 791. [Google Scholar] [CrossRef]
- Tailanian, M.; Pardo, Á.; Musé, P. U-flow: A u-shaped normalizing flow for anomaly detection with unsupervised threshold. J. Math. Imaging Vis. 2024, 66, 678–696. [Google Scholar] [CrossRef]
- Song, C.; Li, Z.; Li, Y.; Zhang, H.; Jiang, M.; Hu, K.; Wang, R. Research on blast furnace tuyere image anomaly detection, based on the local channel attention residual mechanism. Appl. Sci. 2023, 13, 802. [Google Scholar] [CrossRef]
- Simões, F.; Kowerko, D.; Schlosser, T.; Battisti, F.; Teichrieb, V. Attention modules improve image-level anomaly detection for industrial inspection: A differnet case study. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 8246–8255. [Google Scholar]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Xiao, C.; Gou, Z.; Tai, W.; Zhang, K.; Zhou, F. Imputation-based time-series anomaly detection with conditional weight-incremental diffusion models. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 2742–2751. [Google Scholar]
- Zhang, H.; Wang, Z.; Wu, Z.; Jiang, Y.G. Diffusionad: Denoising diffusion for anomaly detection. arXiv 2023, arXiv:2303.08730. [Google Scholar]
- Zhang, X.; Xu, M.; Zhou, X. Realnet: A feature selection network with realistic synthetic anomaly for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16699–16708. [Google Scholar]
- Cohen, N.; Hoshen, Y. Sub-image anomaly detection with deep pyramid correspondences. arXiv 2020, arXiv:2005.02357. [Google Scholar]
- Yi, J.; Yoon, S. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Proceedings of the International Conference on Pattern Recognition, Shanghai, China, 15–17 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 475–489. [Google Scholar]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14318–14328. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Papamakarios, G.; Nalisnick, E.; Rezende, D.J.; Mohamed, S.; Lakshminarayanan, B. Normalizing flows for probabilistic modeling and inference. J. Mach. Learn. Res. 2021, 22, 1–64. [Google Scholar]
- Xiao, C.; Jiang, X.; Du, X.; Yang, W.; Lu, W.; Wang, X.; Chetty, K. Boundary-enhanced time series data imputation with long-term dependency diffusion models. Knowl.-Based Syst. 2025, 310, 112917. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Dinh, L.; Krueger, D.; Bengio, Y. Nice: Non-linear independent components estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1 × 1 convolutions. Adv. Neural Inf. Process. Syst. 2018, 31, 10236–10245. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10440–10450. [Google Scholar]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 392–408. [Google Scholar]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. VT-ADL: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8330–8339. [Google Scholar]
- Ristea, N.C.; Madan, N.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B.; Shah, M. Self-supervised predictive convolutional attentive block for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13576–13586. [Google Scholar]
- Deng, H.; Li, X. Anomaly detection via reverse distillation from one-class embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9737–9746. [Google Scholar]
- Liu, Z.; Zhou, Y.; Xu, Y.; Wang, Z. Simplenet: A simple network for image anomaly detection and localization. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 20402–20411. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SPADE [22] | DRAEM [46] | PathCore [25] | RealNet [21] | Fastflow [39] | MSFlow [10] | Ours |
|---|---|---|---|---|---|---|---|
| candle | 91.0 | 91.8 | 98.6 | 96.1 | 92.8 | 98.3 | 98.4 |
| capusle | 61.4 | 74.7 | 81.6 | 93.2 | 71.2 | 96 | 96.8 |
| cashew | 97.8 | 95.1 | 97.3 | 97.8 | 91.0 | 98.6 | 98.2 |
| chewinggum | 85.8 | 94.8 | 99.1 | 99.9 | 91.4 | 99.6 | 99.4 |
| fryum | 88.6 | 97.4 | 96.2 | 97.1 | 88.6 | 99.6 | 99.6 |
| macaroni1 | 95.2 | 97.2 | 97.5 | 99.8 | 98.3 | 97.6 | 98.2 |
| macaroni2 | 87.9 | 85.0 | 78.1 | 95.2 | 86.3 | 89.4 | 92.3 |
| pcb1 | 72.1 | 47.6 | 98.5 | 98.5 | 77.4 | 99 | 98.9 |
| pcb2 | 50.7 | 89.8 | 97.3 | 97.6 | 61.9 | 97.8 | 98.5 |
| pcb3 | 90.5 | 92.0 | 97.9 | 99.1 | 74.3 | 99.8 | 99 |
| pcb4 | 83.1 | 98.6 | 99.6 | 99.7 | 80.9 | 98.2 | 99.8 |
| pipe_fryum | 81.1 | 100 | 99.8 | 99.9 | 72.0 | 98.8 | 99.5 |
| Average | 82.1 | 88.7 | 95.1 | 97.8 | 82.2 | 97.7 | 98.2 |
| Method | SPADE [22] | DRAEM [46] | PathCore [25] | RealNet [21] | Fastflow [39] | MSFlow [10] | Ours |
|---|---|---|---|---|---|---|---|
| candle | 97.9 | 96.6 | 99.5 | 99.1 | 94.9 | 99.4 | 99.4 |
| capusle | 60.7 | 98.5 | 99.5 | 98.7 | 75.3 | 99.7 | 99.7 |
| cashew | 86.4 | 83.5 | 98.9 | 98.3 | 91.4 | 99.1 | 98.8 |
| chewinggum | 98.6 | 96.8 | 99.1 | 99.8 | 98.6 | 99.4 | 99.3 |
| fryum | 96.7 | 87.2 | 93.8 | 96.2 | 97.3 | 92.7 | 94.5 |
| macaroni1 | 96.2 | 99.9 | 99.8 | 99.9 | 97.3 | 99.8 | 99.8 |
| macaroni2 | 87.5 | 99.2 | 99.1 | 99.6 | 89.2 | 99.6 | 99.6 |
| pcb1 | 66.9 | 88.7 | 99.9 | 99.7 | 75.2 | 99.8 | 99.8 |
| pcb2 | 71.1 | 91.3 | 99.0 | 98.0 | 67.3 | 99.2 | 99.2 |
| pcb3 | 95.1 | 98.0 | 99.2 | 98.8 | 94.8 | 99.3 | 99.4 |
| pcb4 | 89.0 | 96.8 | 98.6 | 98.6 | 89.9 | 98.5 | 99.1 |
| pipe_fryum | 81.8 | 85.8 | 99.1 | 99.2 | 87.3 | 99.1 | 99.2 |
| Average | 85.6 | 93.5 | 98.8 | 98.8 | 88.2 | 98.8 | 99.0 |
| Method | DRAEM [46] | SSPCAB [47] | RD4AD [48] | PatchCore [25] | Simplenet [49] | CS-Flow [9] | MSFlow [10] | Ours |
|---|---|---|---|---|---|---|---|---|
| Carpet | 97.0 | 98.2 | 98.9 | 98.7 | 99.7 | 100 | 100 | 100 |
| Grid | 99.9 | 100 | 100 | 98.2 | 99.7 | 99.0 | 99.8 | 99.8 |
| Leather | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Tile | 99.6 | 100 | 99.3 | 98.7 | 99.8 | 100 | 100 | 100 |
| Wood | 99.1 | 99.5 | 99.2 | 99.2 | 100 | 100 | 100 | 99.8 |
| Average.textuer | 99.1 | 99.5 | 99.5 | 99.0 | 99.8 | 99.8 | 100 | 99.9 |
| Bottle | 99.2 | 98.4 | 100 | 100 | 100 | 99.8 | 100 | 100 |
| Cable | 91.8 | 96.9 | 95.0 | 99.5 | 99.9 | 99.1 | 99.5 | 99.6 |
| Capsule | 98.5 | 99.3 | 96.3 | 98.1 | 97.7 | 97.1 | 99.2 | 99.3 |
| Hazelnt | 100 | 100 | 99.9 | 100 | 100 | 99.6 | 100 | 100 |
| Metal_Nut | 98.7 | 100 | 100 | 100 | 100 | 99.1 | 100 | 100 |
| Pill | 98.9 | 99.8 | 96.6 | 96.6 | 99.0 | 98.6 | 99.6 | 99.4 |
| Screw | 93.9 | 97.9 | 97.0 | 98.1 | 98.2 | 97.6 | 97.8 | 97.9 |
| Toothbrush | 100 | 100 | 99.5 | 100 | 99.7 | 91.9 | 100 | 99.6 |
| Transistor | 93.1 | 92.9 | 96.7 | 100 | 100 | 99.3 | 100 | 100 |
| Zipper | 100 | 100 | 98.5 | 98.8 | 99.9 | 99.7 | 100 | 100 |
| Average.Object | 97.4 | 98.5 | 98.0 | 99.1 | 99.5 | 98.2 | 99.6 | 99.6 |
| Total.average | 98.0 | 98.9 | 98.5 | 99.1 | 99.6 | 98.7 | 99.7 | 99.7 |
| Method | DRAEM [46] | SSPCAB [47] | RD4AD [48] | PatchCore [25] | Simplenet [49] | CS-Flow [9] | MSFlow [10] | Ours |
|---|---|---|---|---|---|---|---|---|
| Carpet | 95.5 | 95.0 | 98.9 | 99.1 | 98.2 | 95.2 | 99.4 | 99.4 |
| Grid | 99.7 | 99.5 | 99.3 | 98.7 | 98.8 | 94.4 | 99.4 | 99.4 |
| Leather | 98.6 | 99.5 | 99.4 | 99.3 | 99.2 | 89.3 | 99.7 | 99.7 |
| Tile | 99.2 | 99.3 | 95.6 | 95.9 | 97.0 | 90.7 | 98.2 | 98.0 |
| Wood | 96.4 | 96.8 | 95.3 | 95.1 | 94.5 | 91.2 | 97.1 | 96.2 |
| Average.texture | 97.9 | 98.0 | 97.7 | 97.6 | 97.5 | 92.2 | 98.8 | 98.5 |
| Bottle | 99.1 | 98.8 | 98.7 | 98.6 | 98.0 | 88.5 | 99.0 | 98.8 |
| Cable | 94.7 | 96.0 | 97.4 | 98.5 | 97.6 | 96.1 | 98.5 | 98.1 |
| Capsule | 94.3 | 93.1 | 98.7 | 98.9 | 98.9 | 98.1 | 99.1 | 99.2 |
| Hazelnut | 99.7 | 99.8 | 98.9 | 98.7 | 97.9 | 96.1 | 98.7 | 98.7 |
| Metal_Nut | 99.5 | 98.9 | 97.3 | 98.4 | 98.8 | 96.0 | 99.3 | 99.2 |
| Pill | 97.6 | 97.5 | 98.2 | 97.6 | 98.6 | 95.8 | 98.8 | 99.1 |
| Screw | 97.6 | 99.8 | 99.6 | 99.4 | 99.3 | 98.3 | 99.1 | 99.4 |
| Toothbrush | 98.1 | 98.1 | 99.1 | 98.7 | 98.5 | 97.4 | 98.5 | 98.4 |
| Transistor | 90.9 | 87.0 | 92.5 | 96.4 | 97.6 | 96.3 | 98.3 | 94.0 |
| Zipper | 98.8 | 99.0 | 98.2 | 98.9 | 98.9 | 95.8 | 99.2 | 99.1 |
| Average.object | 97.0 | 96.8 | 97.9 | 98.4 | 98.4 | 95.8 | 98.8 | 98.4 |
| Total.average | 97.3 | 97.2 | 97.8 | 98.1 | 98.1 | 94.6 | 98.8 | 98.4 |
| Method | Patch-SVDD [23] | RealNet [21] | MSFlow [10] | Ours |
|---|---|---|---|---|
| Category 01 | 95.7/91.6 | 100.0/98.2 | 99.8/96.8 | 99.8/97.0 |
| Category 02 | 72.1/93.6 | 88.6/96.3 | 91.4/97.4 | 92.7/97.5 |
| Category 03 | 82.1/91.0 | 99.6/99.4 | 99.3/99.4 | 99.6/99.5 |
| Average | 83.3/92.1 | 96.1/97.9 | 96.8/97.8 | 97.3/98.0 |
| I-AUROC | P-AUROC | |||||
|---|---|---|---|---|---|---|
| 3 × 3 | 5 × 5 | 7 × 7 | 3 × 3 | 5 × 5 | 7 × 7 | |
| candle | 98.2 | 98.2 | 98.7 | 99.4 | 99.4 | 99.4 |
| capsule | 97.2 | 96.6 | 96.1 | 98.6 | 99.7 | 99.6 |
| cashew | 98.6 | 97.7 | 97.9 | 98.4 | 98.9 | 99.1 |
| chewinggum | 99.5 | 99.2 | 99.6 | 99.4 | 99.3 | 99.3 |
| fryum | 99.4 | 99.8 | 99.7 | 93.8 | 94.1 | 94.2 |
| macaroni1 | 98.4 | 98.1 | 97.6 | 99.8 | 99.7 | 99.8 |
| macaroni2 | 90.5 | 90.5 | 90.7 | 99.6 | 99.6 | 99.6 |
| pcb1 | 99.2 | 99.1 | 98.7 | 99.8 | 99.8 | 99.8 |
| pcb2 | 98.6 | 98.9 | 98.8 | 98.9 | 99.3 | 99.3 |
| pcb3 | 98.1 | 98.6 | 98.6 | 99.3 | 99.3 | 99.4 |
| pcb4 | 99.8 | 99.8 | 99.8 | 99.0 | 99.0 | 99.0 |
| pipe_fryum | 99.2 | 99.6 | 99.0 | 99.2 | 99.2 | 99.2 |
| Average | 98.05 | 98.00 | 97.93 | 98.76 | 98.94 | 98.97 |
| I-AUROC | P-AUROC | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |
| candle | 98.3 | 98.3 | 98.2 | 98.2 | 99.4 | 99.4 | 99.4 | 99.4 |
| capsule | 95.8 | 96.9 | 96 | 96.6 | 99.6 | 99.6 | 99.7 | 99.7 |
| cashew | 97.8 | 98 | 98.3 | 97.7 | 99.2 | 98.8 | 98.9 | 98.9 |
| chewinggum | 99.2 | 99.2 | 99.2 | 99.2 | 99.3 | 99.4 | 99.4 | 99.3 |
| fryum | 98.6 | 99.7 | 99.2 | 99.8 | 93.7 | 94.1 | 93.5 | 94.1 |
| macaroni1 | 98.2 | 97.1 | 98.3 | 98.1 | 99.7 | 99.7 | 99.7 | 99.7 |
| macaroni2 | 88.9 | 89.2 | 89.8 | 90.5 | 99.5 | 99.6 | 99.6 | 99.6 |
| pcb1 | 98.8 | 98.8 | 98.8 | 99.1 | 99.8 | 99.8 | 99.8 | 99.8 |
| pcb2 | 98.7 | 98.3 | 98.6 | 98.9 | 99.2 | 98.9 | 99.2 | 99.3 |
| pcb3 | 98.6 | 98.3 | 98.5 | 98.6 | 99.3 | 99.3 | 99.4 | 99.3 |
| pcb4 | 99.8 | 99.8 | 99.8 | 99.8 | 99 | 99 | 99 | 99.0 |
| pipe_fryum | 99.2 | 99.4 | 99.7 | 99.6 | 99 | 99 | 99 | 99.2 |
| Average | 97.65 | 97.75 | 97.87 | 98.00 | 98.89 | 98.88 | 98.88 | 98.94 |
| I-AUROC | P-AUROC | |||||
|---|---|---|---|---|---|---|
| AM | SEBlock | ECA | Ours | SEBlock | ECA | Ours |
| candle | 98.4 | 98.4 | 98.4 | 99.4 | 99.2 | 99.4 |
| capusle | 96.4 | 96.4 | 96.8 | 99.7 | 99.7 | 99.7 |
| cashew | 98.3 | 98.4 | 98.2 | 98.8 | 98.7 | 98.8 |
| chewinggum | 99.3 | 99.6 | 99.4 | 99.4 | 99.3 | 99.4 |
| fryum | 99.5 | 99.7 | 99.6 | 93.7 | 93.8 | 94.5 |
| macaroni1 | 98.0 | 98.5 | 98.2 | 99.7 | 99.8 | 99.8 |
| macaroni29 | 91.7 | 91.4 | 92.3 | 99.6 | 99.6 | 99.6 |
| pcb1 | 98.8 | 98.8 | 98.9 | 99.8 | 99.8 | 99.8 |
| pcb2 | 98.8 | 98.2 | 98.5 | 99.2 | 99.2 | 99.2 |
| pcb3 | 98.7 | 98.8 | 99.0 | 99.4 | 99.4 | 99.4 |
| pcb4 | 99.8 | 99.8 | 99.8 | 98.9 | 99 | 99.1 |
| fryum | 99.3 | 99.2 | 99.5 | 99.1 | 99.1 | 99.2 |
| Average | 98.07 | 98.10 | 98.21 | 98.88 | 98.89 | 98.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, L.; Lu, C.; Gao, Y.; Yu, H.; Cai, B. GCAFlow: Multi-Scale Flow-Based Model with Global Context-Aware Channel Attention for Industrial Anomaly Detection. Sensors 2025, 25, 3205. https://doi.org/10.3390/s25103205
Liao L, Lu C, Gao Y, Yu H, Cai B. GCAFlow: Multi-Scale Flow-Based Model with Global Context-Aware Channel Attention for Industrial Anomaly Detection. Sensors. 2025; 25(10):3205. https://doi.org/10.3390/s25103205
Chicago/Turabian StyleLiao, Lin, Congde Lu, Yujie Gao, Hao Yu, and Biao Cai. 2025. "GCAFlow: Multi-Scale Flow-Based Model with Global Context-Aware Channel Attention for Industrial Anomaly Detection" Sensors 25, no. 10: 3205. https://doi.org/10.3390/s25103205
APA StyleLiao, L., Lu, C., Gao, Y., Yu, H., & Cai, B. (2025). GCAFlow: Multi-Scale Flow-Based Model with Global Context-Aware Channel Attention for Industrial Anomaly Detection. Sensors, 25(10), 3205. https://doi.org/10.3390/s25103205