
A Predictive Approach for Enhancing Accuracy in Remote Robotic Surgery Using Informer Model

Abstract
1. Introduction
- Enhancement of the Transformer-based Informer architecture for real-time position estimation while maintaining its computational complexity of . This includes modifying the ProbSparse attention mechanism to prioritize position-critical features, improving accuracy without increasing computational overhead.
- Integration of a differentiable optimization layer within the Informer model, embedding constraints related to energy efficiency, smoothness, and robustness into the training process.
- Development of a four-state HMM-based packet loss model to simulate realistic network-induced disruptions, including random and burst errors, for comprehensive model evaluation.
- Incorporation of network parameters such as latency, jitter, and packet loss into the Informer model, ensuring adaptability to varying network conditions.
2. Related Work
3. Problem Statement
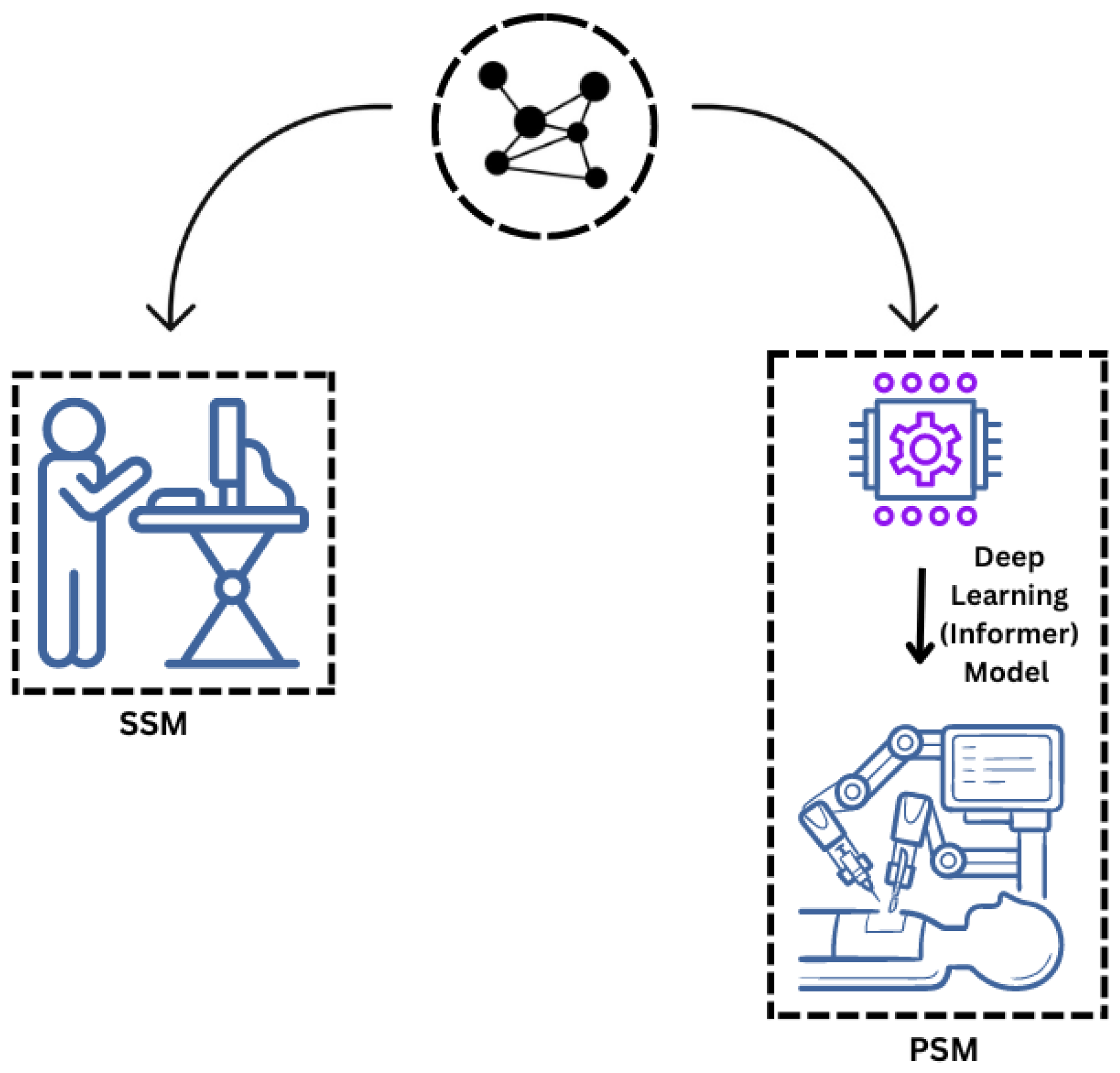
3.1. System Model
3.2. System Overview
3.3. Network Errors and Challenges
- Burst Errors: These errors occur in clusters, where multiple consecutive packets are lost, leading to significant gaps in transmitted data.
- Random Errors: These errors result in the loss of individual packets at random intervals, creating sporadic gaps in the transmitted position data.
3.4. Optimization Problem
4. Proposed Model
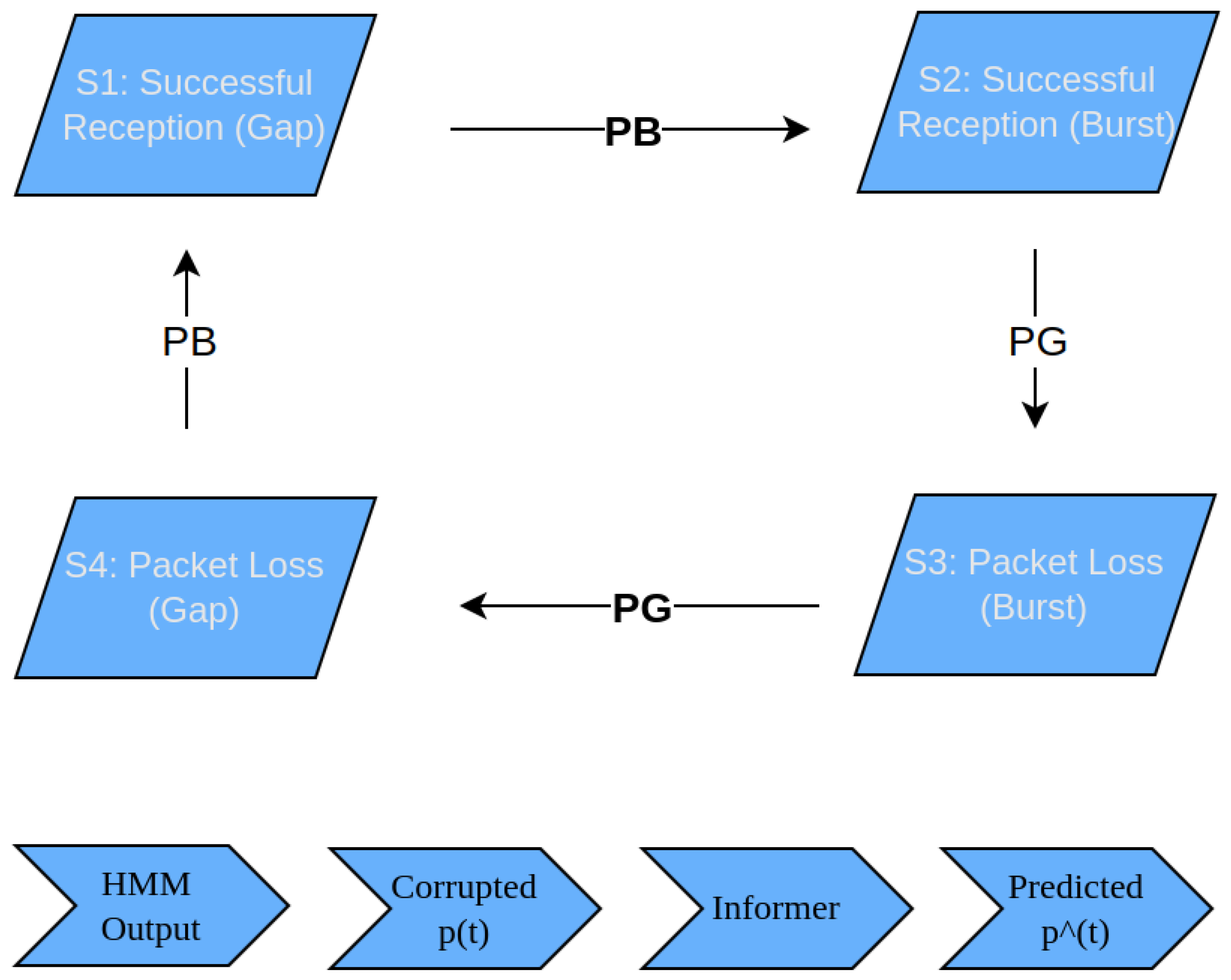
4.1. Modeling Packet Loss
- State 1 (): Successful packet reception during a gap period.
- State 2 (): Successful packet reception during a burst period.
- State 3 (): Packet loss during a burst period.
- State 4 (): Packet loss during a gap period.
- Burst Density (): Probability of entering or remaining in a burst state.
- Gap Density (): Probability of entering or remaining in a gap state.
- For States or (packet loss), the data point is set to zero.
- For States or (packet reception), the data point is preserved.
4.2. Informer Model-Based Predictive Approach
4.3. Description of the Informer Model
4.3.1. Optimized Attention Mechanism
4.3.2. Identifying Relevant Queries
4.3.3. ProbSparse Attention Mechanism
4.3.4. Streamlined Self-Attention Distilling
4.3.5. Efficient Encoder for Long Sequences
4.3.6. Fast Generative Decoder
5. Integration of Optimization Problem
5.1. Optimization as a Layer
- Objective Function: Position accuracy and energy efficiency are incorporated as primary and secondary terms in the loss function:where represents energy consumption, ensures smoothness, and addresses robustness to network uncertainties.
- Constraints: Operational feasibility is maintained through penalties for violating constraints, ensuring the model adheres to real-time requirements.
5.2. ProbSparse Attention for Position-Critical Features
5.3. Encoder-Guided Constraint Adherence
5.4. Decoder for Real-Time Position Estimation
5.5. Incorporating Network Information
5.6. Solvability and Convergence Analysis
6. Experimental Setup and Results
6.1. Dataset
6.2. Simulation Setup
| Algorithm 1 Informer-Based Position Prediction under HMM-Induced Packet Loss | |
| 1: | Input: Kinematic data, number of time steps T, HMM parameters , |
| 2: | Output: Predicted position , performance metrics (MAE, MSE, RMSE) |
| 3: | Initialization: |
| 4: | Load Cartesian position data from JIGSAWS dataset |
| 5: | Define 4-state HMM using , transition probabilities |
| 6: | Simulate packet loss to create corrupted data |
| 7: | for to T do |
| 8: | if HMM state at t is S3 or S4 then |
| 9: | |
| 10: | else |
| 11: | |
| 12: | end if |
| 13: | end for |
| 14: | Normalize and preprocess |
| 15: | Split into training and testing sets |
| 16: | Initialize Informer model using PyTorch |
| 17: | Train Informer: as input, as target |
| 18: | Predict: Informer() |
| 19: | Evaluation: |
| 20: | Compute MAE, MSE, RMSE for x, y, and z |
| 21: | Compare with LSTM, RNN, TCN models |
6.3. Results and Discussion
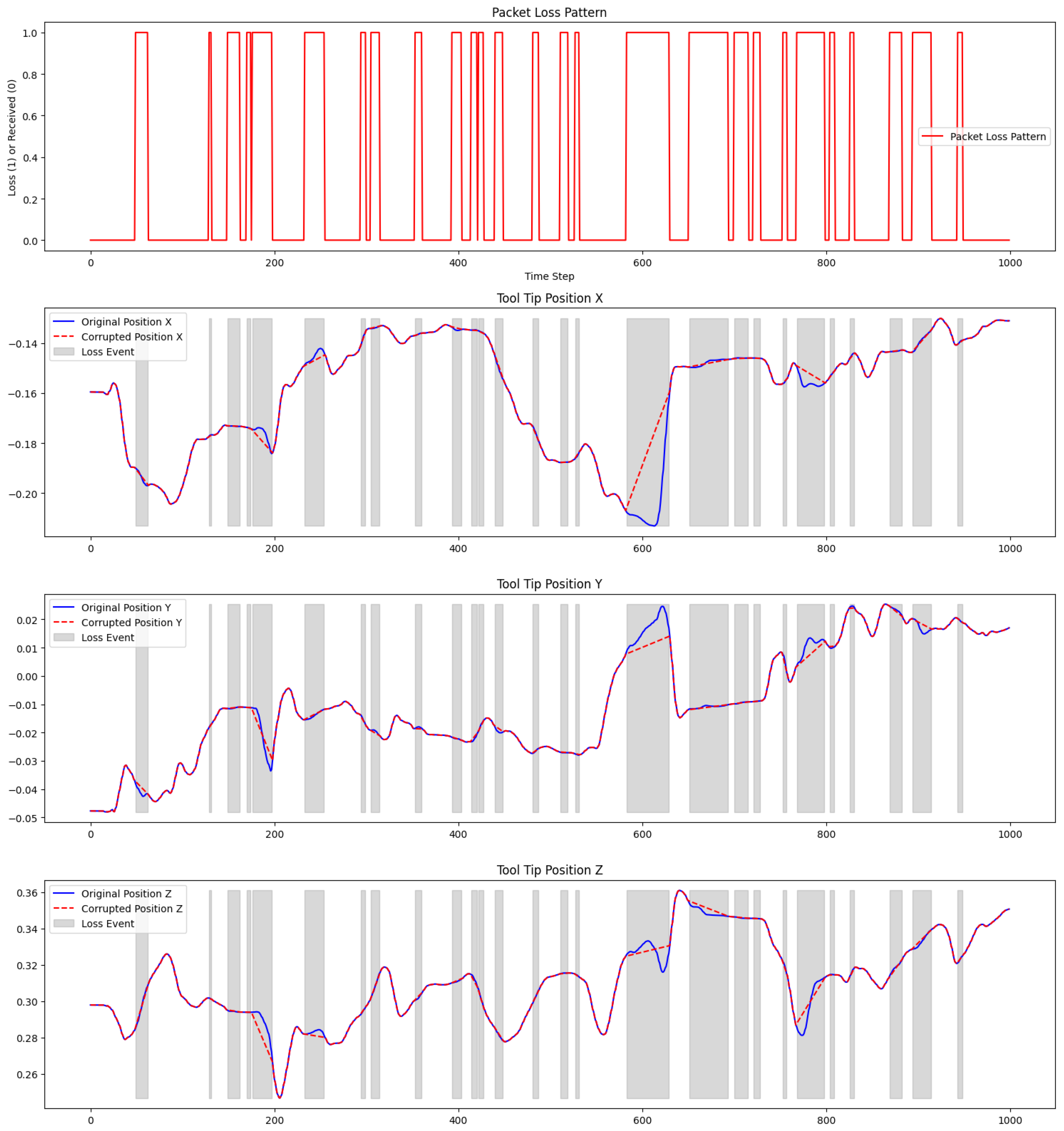
6.3.1. Impact of Packet Loss on Position Estimation
6.3.2. Performance of the Model Under Packet Loss
- The X position prediction accuracy is 96.68%. The model achieves high accuracy in predicting the X-axis position. The predicted position closely follows the actual position, with very few deviations, indicating that the model handles packet loss well for this axis.
- Y position prediction accuracy is 95.96%. Similarly, the model performs effectively in predicting the Y-axis position. The predicted values align almost perfectly with the actual values, except for minor deviations during sharp transitions, demonstrating the robustness of the model.
- Z position prediction accuracy is 90.37%. The Z-axis shows a slightly lower accuracy than the X and Y axes, with some noticeable deviations during time steps where the actual position exhibits rapid changes. However, the overall prediction still captures the trend of position movements, showing that the model can still predict reasonably well in challenging packet loss scenarios.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TI | Tactile Internet |
| PSM | Patient Side Manipulator |
| SSM | Surgeon Side Manipulator |
| HMM | Hidden Markov Model |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| JHU-ISI | Johns Hopkins University—Intuitive Surgical Inc. |
| JIGSAWS | JHU-ISI Gesture and Skill Assessment Working Set |
| KF | Kalman Filter |
| TCN | Temporal Convolutional Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
References
- Fettweis, G.P. The tactile internet: Applications and challenges. IEEE Veh. Technol. Mag. 2014, 9, 64–70. [Google Scholar] [CrossRef]
- Holland, O.; Steinbach, E.; Prasad, R.V.; Liu, Q.; Dawy, Z.; Aijaz, A. The IEEE 1918.1 “tactile internet” standards working group and its standards. Proc. IEEE 2019, 107, 256–279. [Google Scholar] [CrossRef]
- Kumar, P.; Jolfaei, A.; Kant, K. Guest Editorial of the Special Section on Tactile Internet for Consumer Internet of Things Opportunities and Challenges. IEEE Trans. Consum. Electron. 2024, 70, 4965–4967. [Google Scholar] [CrossRef]
- Sengupta, J.; Dey, D.; Ferlin, S.; Ghosh, N.; Bajpai, V. Accelerating Tactile Internet with QUIC: An Exploration of its Security and Privacy Attacks. arXiv 2024, arXiv:2401.06657. [Google Scholar]
- Li, C.; Tong, Y.; Long, Y.; Si, W.; Yeung, D.C.M.; Chan, J.Y.-K. Extended Reality With HMD-Assisted Guidance and Console 3D Overlay for Robotic Surgery Remote Mentoring. IEEE Robot. Autom. Lett. 2024, 9, 9135–9142. [Google Scholar] [CrossRef]
- Gupta, R.; Tanwar, S.; Tyagi, S.; Kumar, N. Tactile-internet-based telesurgery system for healthcare 4.0: An architecture, research challenges, and future directions. IEEE Netw. 2019, 33, 22–29. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, J.; Zhao, G. Towards 5G enabled tactile robotic telesurgery. arXiv 2018, arXiv:1803.03586. [Google Scholar]
- Li, S.; Hendrich, N.; Liang, H.; Ruppel, P.; Zhang, C.; Zhang, J. A dexterous hand-arm teleoperation system based on hand pose estimation and active vision. IEEE Trans. Cybern. 2022, 54, 1417–1428. [Google Scholar] [CrossRef]
- Patil, H.; Negi, H.S.; Devarani, P.A.; Barve, A.; Maranan, R. Enhancing Tactile Internet Experiences through Control Mechanisms and Predictive AI. In Proceedings of the 2024 2nd International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 2–3 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 235–239. [Google Scholar]
- Szabo, D.; Gulyas, A.; Fitzek, F.H.; Lucani, D.E. Towards the tactile internet: Decreasing communication latency with network coding and software defined networking. In Proceedings of the European Wireless 2015 21th European Wireless Conference, Budapest, Hungary, 20–22 May 2015; VDE: Osaka, Japan, 2015; pp. 1–6. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Bejar, B.; Hager, G.D.; et al. Jhu-isi gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling. MICCAI Workshop M2cai 2014, 3, 3. [Google Scholar]
- He, C.Y.; Patel, N.; Kobilarov, M.; Iordachita, I. Real Time Prediction of Sclera Force with LSTM Neural Networks in Robot-Assisted Retinal Surgery. Appl. Mech. Mater. 2020, 896, 183–194. [Google Scholar] [CrossRef]
- Khodabandelou, G.; Jung, P.G.; Amirat, Y.; Mohammed, S. Attention-based gated recurrent unit for gesture recognition. IEEE Trans. Autom. Sci. Eng. 2020, 18, 495–507. [Google Scholar] [CrossRef]
- Djelal, N.; Ouanane, A.; Bouriachi, F. LSTM-Based Visual Control for Complex Robot Interactions. J. Eur. Syst. Autom. 2023, 56, 863–870. [Google Scholar] [CrossRef]
- Wen, X.; Li, W. Time series prediction based on LSTM-attention-LSTM model. IEEE Access 2023, 11, 48322–48331. [Google Scholar] [CrossRef]
- Vaswani, A. Attention Is All You Need. Advances in Neural Information Processing Systems. 2017. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 28 October 2024).
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Hasan, M.K.; Chowdhury, M.M.; Ahmed, S.; Sabuj, S.R.; Nibhen, J.; Bakar, K.A. Optimum energy harvesting model for bidirectional cognitive radio networks. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 199. [Google Scholar] [CrossRef]
- Cao, Y.; Ding, Y.; Jia, M.; Tian, R. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Zhou, H.; Li, J.; Zhang, S.; Zhang, S.; Yan, M.; Xiong, H. Expanding the prediction capacity in long sequence time-series forecasting. Artif. Intell. 2023, 318, 103886. [Google Scholar] [CrossRef]
- Li, Y.; Raison, N.; Ourselin, S.; Mahmoodi, T.; Dasgupta, P.; Granados, A. AI solutions for overcoming delays in telesurgery and telementoring to enhance surgical practice and education. J. Robot. Surg. 2024, 18, 403. [Google Scholar] [CrossRef]
- Milan, G.; Sacido, J.; Martín-Pérez, J. FoReCo: A forecast-based recovery mechanism for real-time remote control of robotic manipulators. In Proceedings of the SIGCOMM’22 Poster and Demo Sessions, Amsterdam, The Netherlands, 22–26 August 2022; pp. 7–9. [Google Scholar]
- Motiwala, Z.Y.; Desai, A.; Bisht, R.; Lathkar, S.; Misra, S.; Carbin, D.D. Telesurgery: Current status and strategies for latency reduction. J. Robot. Surg. 2025, 19, 153. [Google Scholar] [CrossRef]
- Hanif, L.M.; Batayneh, W.; Khokhar, A. Enhancing Precision in Tactile Internet-Enabled Remote Robotic Surgery: Kalman Filter Approach. In Proceedings of the 2024 International Wireless Communications and Mobile Computing (IWCMC), Ayia Napa, Cyprus, 27–31 May 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Lashari, M.H.; Batayneh, W.; Khokhar, A.; Ahmed, S. Enhanced Position Estimation in Tactile Internet-Enabled Remote Robotic Surgery Using MOESP-Based Kalman Filter. arXiv 2025, arXiv:2501.16485. [Google Scholar]
- Parikh, K.; Kim, J. The Role of Network Packet Loss Modeling in Reliable Transport of Broadcast Audio. GatesAir. Available online: https://www.gatesair.com/documents/papers/Parikh-K130115-Network-Modeling-Revised-02-05-2015.pdf (accessed on 28 October 2024).
- Yu, X.; Modestino, J.W.; Tian, X. The accuracy of Gilbert models in predicting packet-loss statistics for a single-multiplexer network model. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 4, pp. 2602–2612. [Google Scholar]
- Ellis, M.; Pezaros, D.P.; Kypraios, T.; Perkins, C. A two-level Markov model for packet loss in UDP/IP-based real-time video applications targeting residential users. Comput. Netw. 2014, 70, 384–399. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Gupta, A.; Rush, A.M. Dilated convolutions for modeling long-distance genomic dependencies. arXiv 2017, arXiv:1710.01278. [Google Scholar]
- Brandon, A.; Kolter, J.Z. Optnet: Differentiable optimization as a layer in neural networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Breckenridge, CO, USA, 2017. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Type | Complexity | Sequential Handling | Suitability for Long Sequences | Strength |
|---|---|---|---|---|---|
| RNN | Recurrent | Yes | Moderate | Simplicity | |
| LSTM | Recurrent | Yes | Good | Handles long-term dependencies | |
| TCN | Convolutional | No | Good | Parallelizable with long-range capture via dilation | |
| Informer | Transformer | No | Excellent | Handles long sequences with reduced cost |
| Burst Density | Gap Density | Burst Length | Gap Length | MSE | MAE | RMSE | Accuracy X (%) | Accuracy Y (%) | Accuracy Z (%) |
|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.95 | 4 | 8 | 0.0105 | 0.0725 | 0.1027 | 94.27 | 94.25 | 93.40 |
| 0.4 | 0.90 | 5 | 7 | 0.0119 | 0.0771 | 0.1090 | 93.45 | 92.30 | 91.22 |
| 0.5 | 0.85 | 6 | 6 | 0.0116 | 0.0768 | 0.1078 | 92.88 | 91.78 | 90.33 |
| 0.6 | 0.80 | 8 | 5 | 0.0123 | 0.0785 | 0.1109 | 91.33 | 90.22 | 89.12 |
| 0.7 | 0.75 | 10 | 4 | 0.0130 | 0.0792 | 0.1131 | 90.50 | 89.45 | 88.55 |
| 0.8 | 0.70 | 12 | 3 | 0.0136 | 0.0811 | 0.1166 | 89.12 | 88.90 | 87.50 |
| Model | MSE | MAE |
|---|---|---|
| Informer | 0.0192 | 0.1082 |
| TCN | 0.0724 | 0.1313 |
| RNN | 0.1368 | 0.1982 |
| LSTM | 0.1472 | 0.2004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lashari, M.H.; Ahmed, S.; Batayneh, W.; Khokhar, A. A Predictive Approach for Enhancing Accuracy in Remote Robotic Surgery Using Informer Model. Sensors 2025, 25, 3067. https://doi.org/10.3390/s25103067
Lashari MH, Ahmed S, Batayneh W, Khokhar A. A Predictive Approach for Enhancing Accuracy in Remote Robotic Surgery Using Informer Model. Sensors. 2025; 25(10):3067. https://doi.org/10.3390/s25103067
Chicago/Turabian StyleLashari, Muhammad Hanif, Shakil Ahmed, Wafa Batayneh, and Ashfaq Khokhar. 2025. "A Predictive Approach for Enhancing Accuracy in Remote Robotic Surgery Using Informer Model" Sensors 25, no. 10: 3067. https://doi.org/10.3390/s25103067
APA StyleLashari, M. H., Ahmed, S., Batayneh, W., & Khokhar, A. (2025). A Predictive Approach for Enhancing Accuracy in Remote Robotic Surgery Using Informer Model. Sensors, 25(10), 3067. https://doi.org/10.3390/s25103067