
Real-Time Aerial Multispectral Object Detection with Dynamic Modality-Balanced Pixel-Level Fusion



Abstract
1. Introduction
- We revisit pixel-level fusion by proposing the MLWF module, which contains a fine-designed two-tier cascade reconstruction sub-module, accomplishing real-time and full-time aerial object detection with satisfactory performances.
- We propose the DMDTM training augmentation strategy, which enables the model to balance attraction between both modalities and focus on infrared images in low-light conditions. To the best of our knowledge, we are the first to propose augmentation methods specialized for inherent characteristic imbalance between different modalities in multispectral object detection.
- We design an OBB head for the base YOLOv10s model and adjust the loss function for aerial small object detection. Our model exhibits an mAP of 76.80 and an FPS of 132, accomplishing competitive accuracy with outstanding speed among state-of-the-art models.
2. Related Work
2.1. Deep Learning-Based Object Detection Models
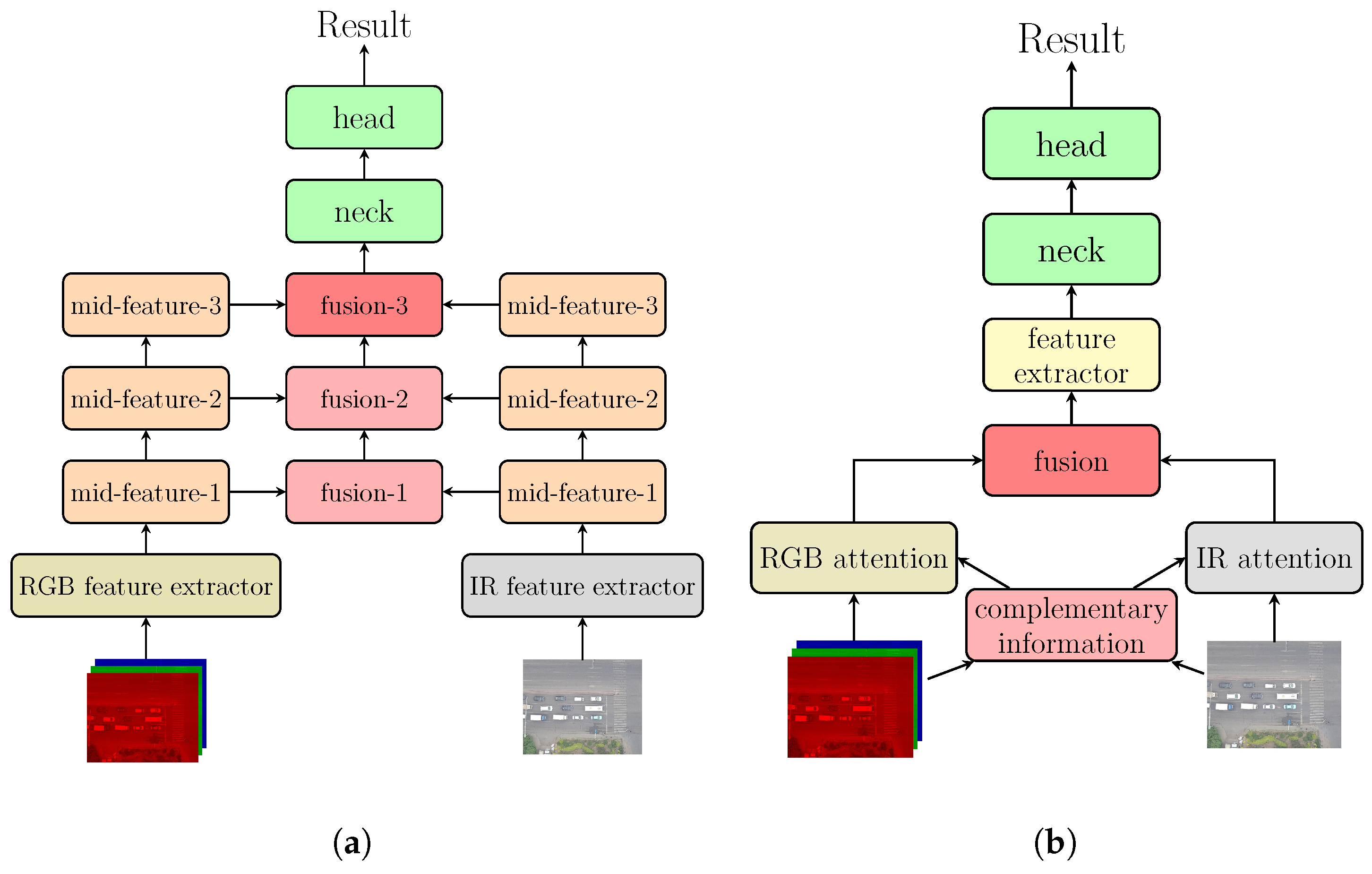
2.2. Multispectral Aerial Object Detection
3. Materials and Methods
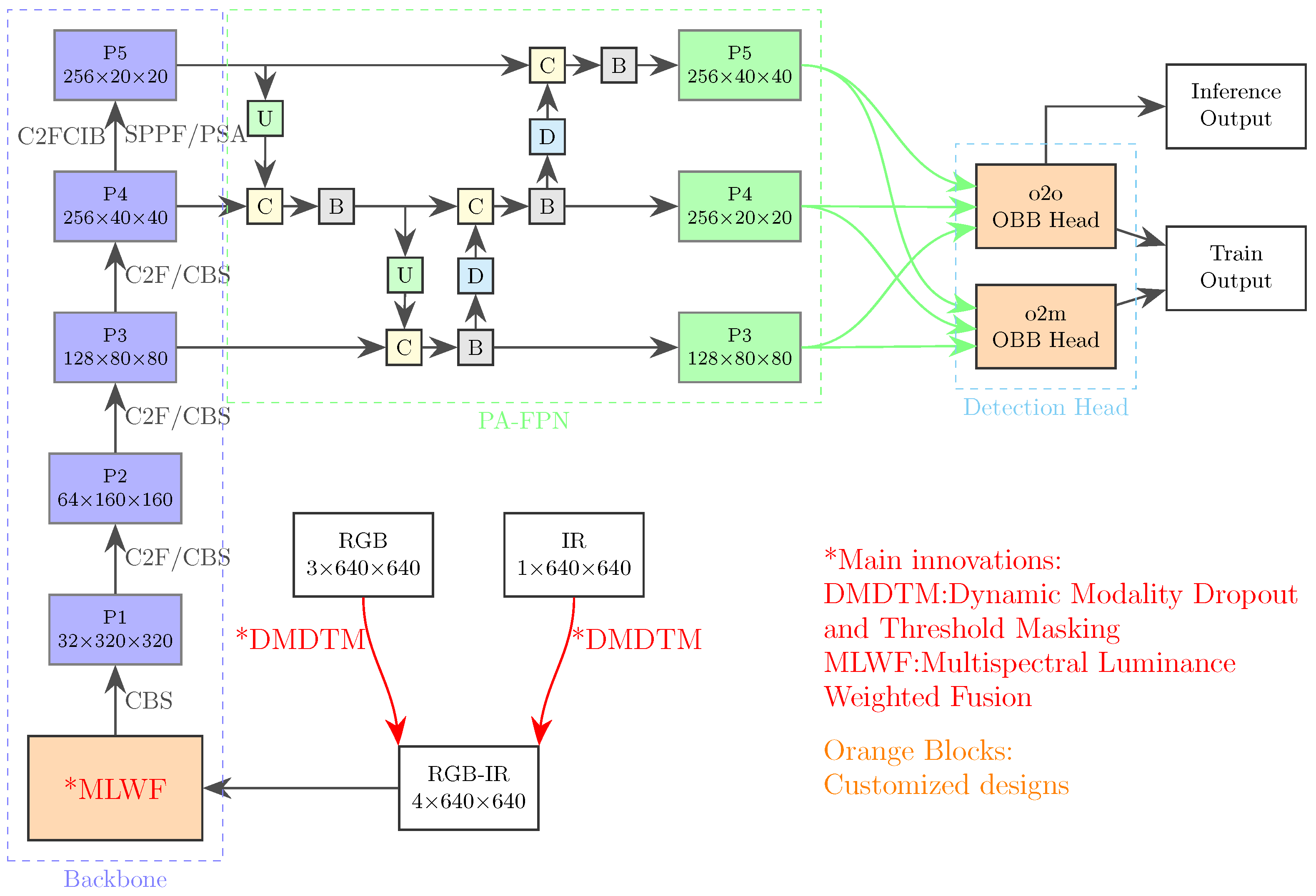
3.1. Overall Architecture
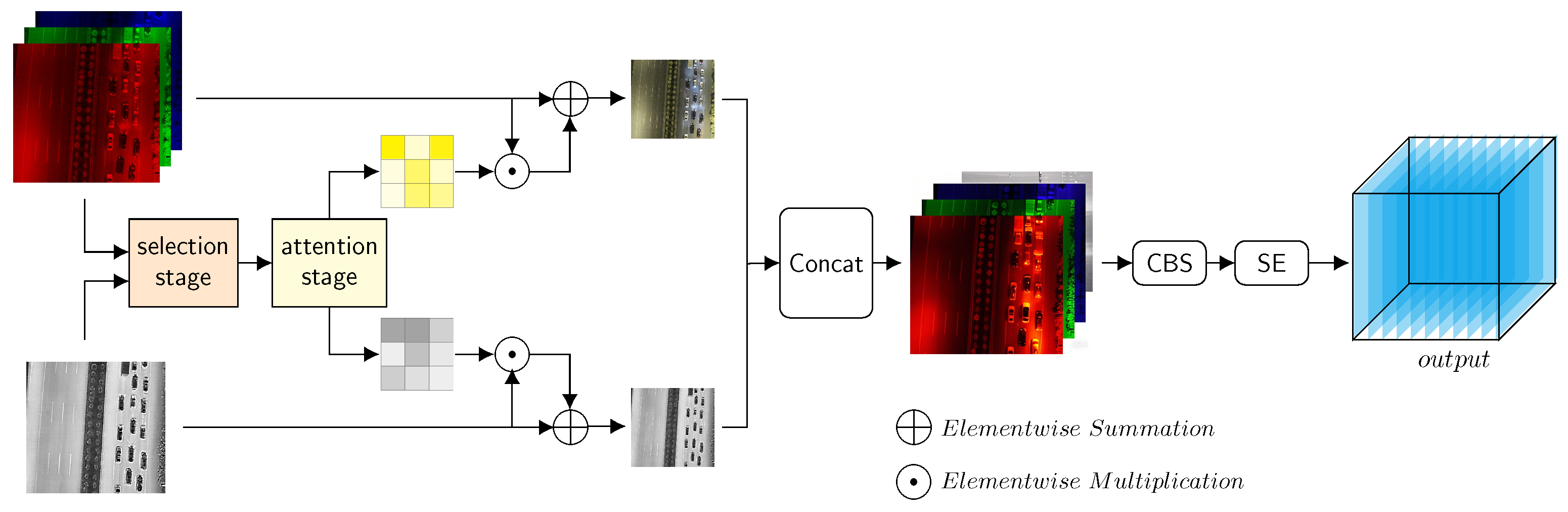
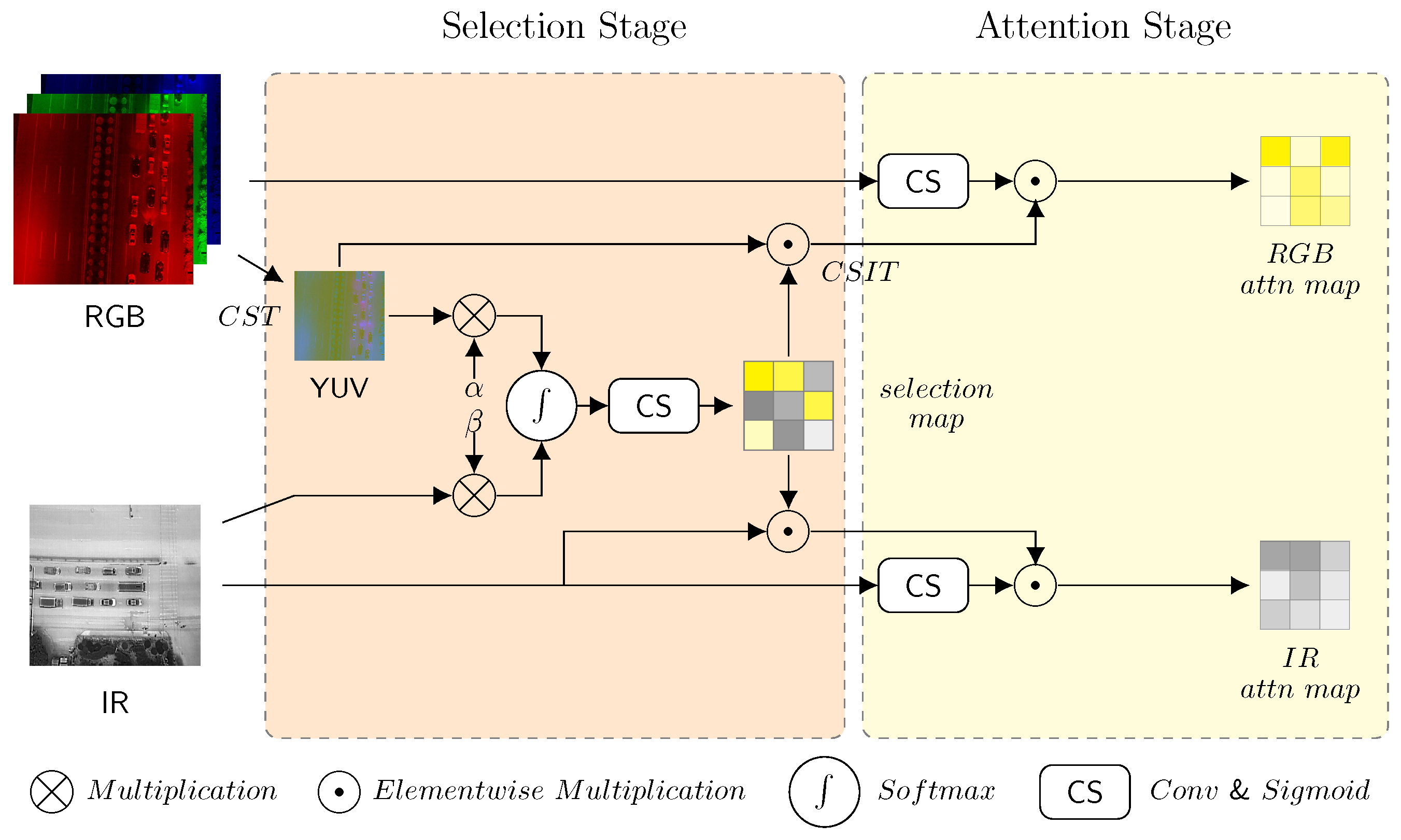
3.2. MLWF Module
3.3. Dynamic Modality Dropout and Threshold Masking
3.4. Aerial Object Detection Specialized Designs
4. Results
4.1. Experimental Settings
4.2. Dataset and Metrics
4.3. Ablation Studies
4.3.1. Effectiveness of YUV Color Space Transformation
4.3.2. Effectiveness of MLWF Sub-Modules
4.3.3. Effectiveness of DMDTM Augmentation Strategy
4.4. Comparisons
5. Discussion
5.1. Effectiveness Interpretation of YUV Transformation
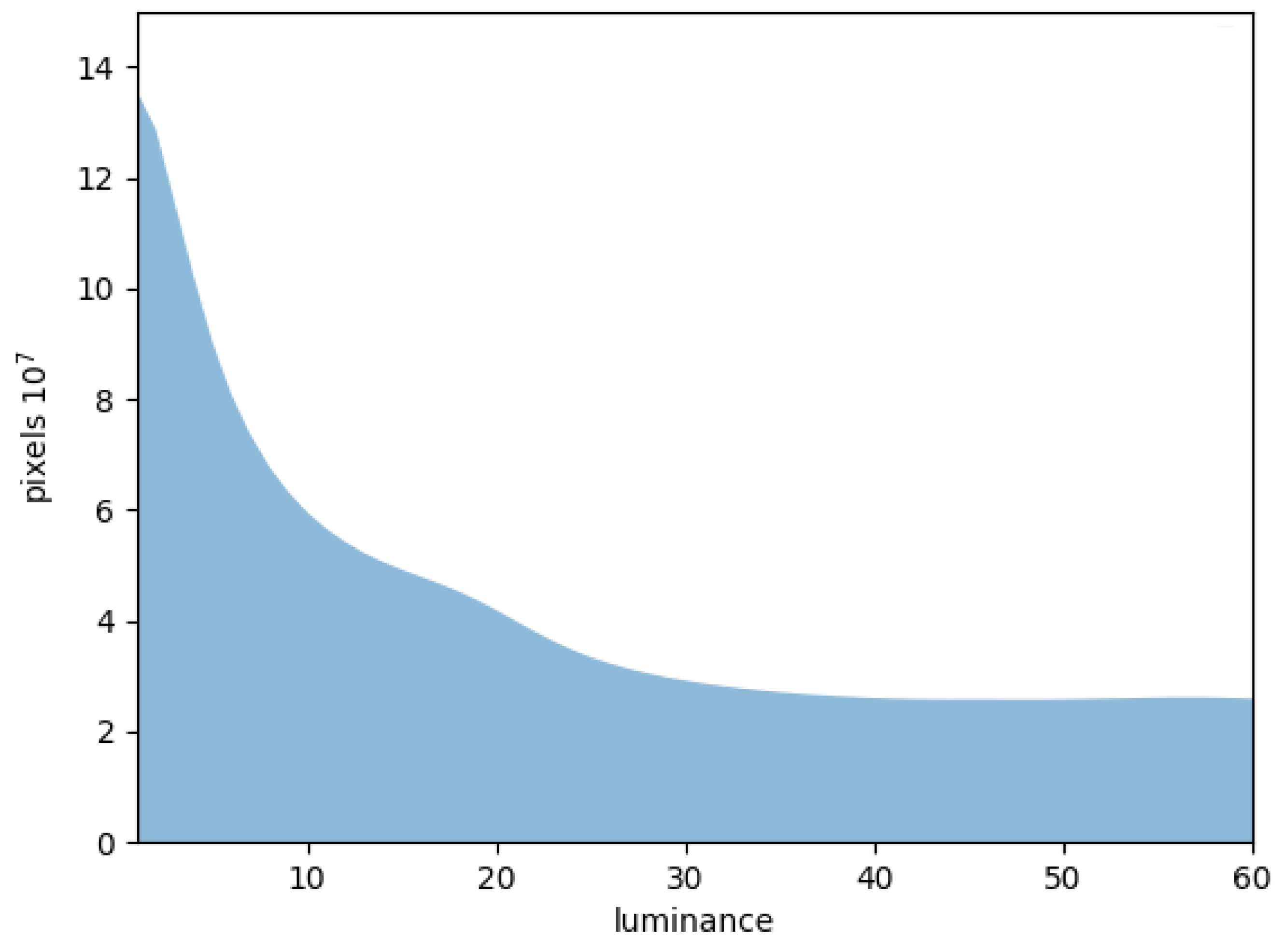
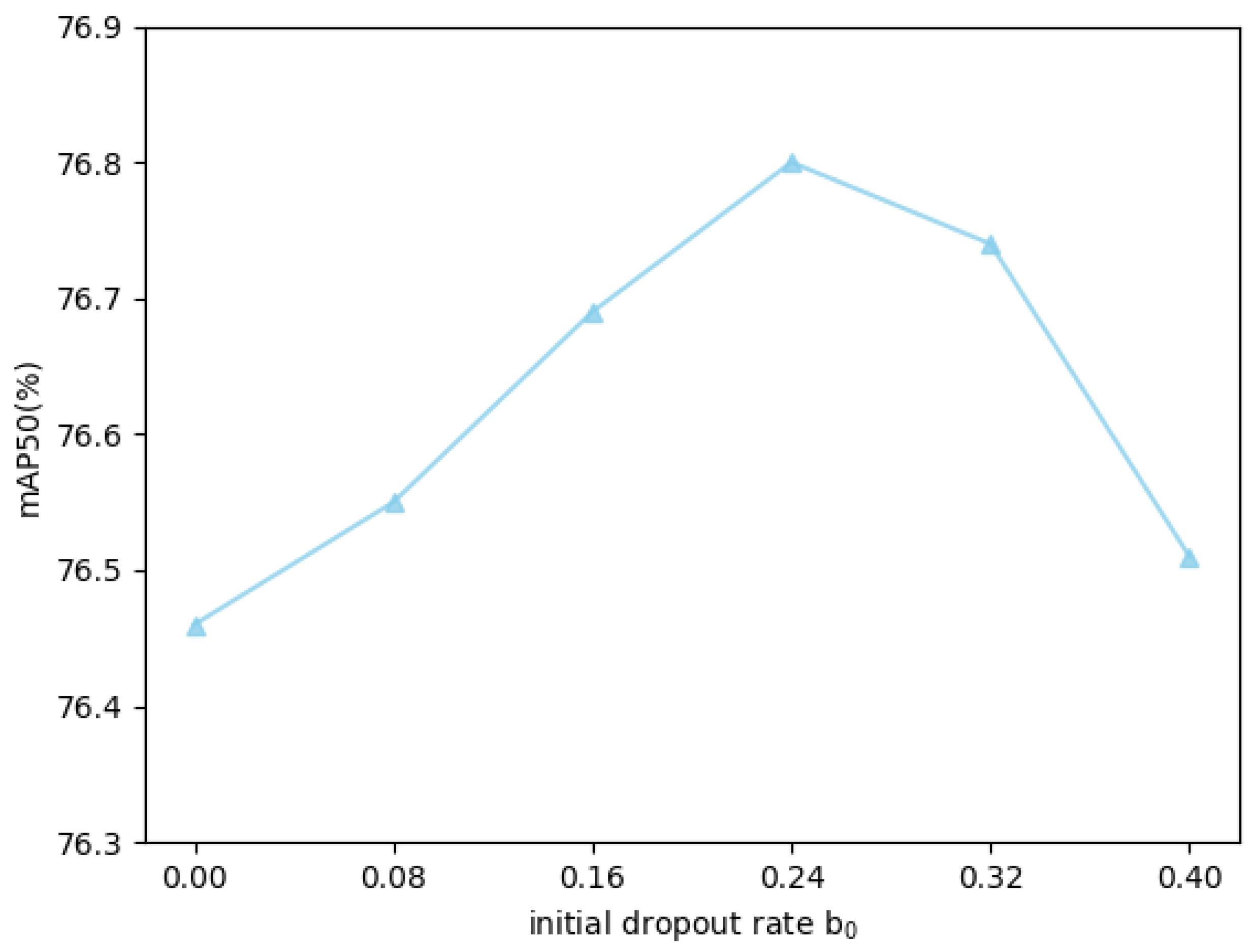
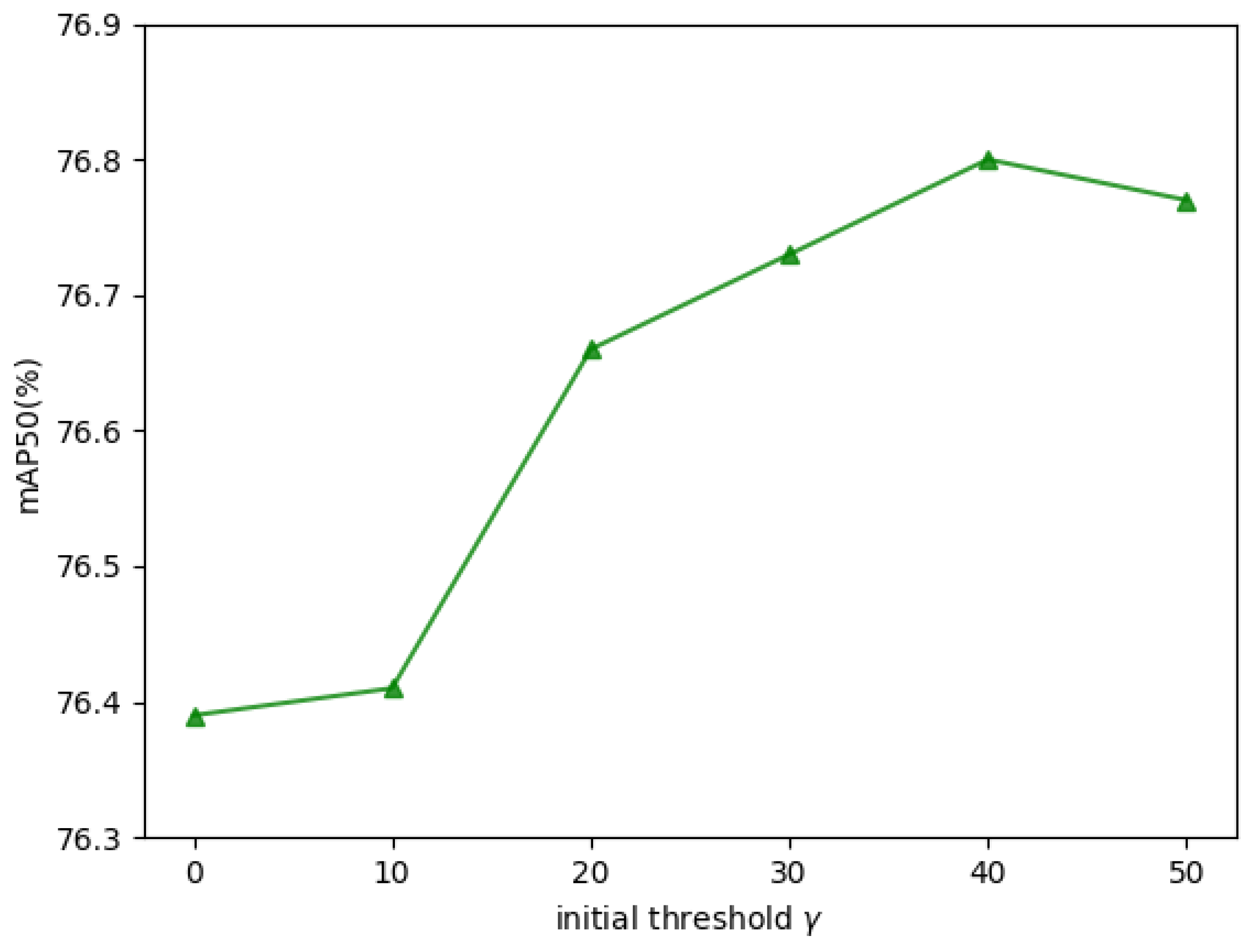
5.2. Parameter Ablation and Analysis in DMDTM
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Reilly, V.; Idrees, H.; Shah, M. Detection and tracking of large number of targets in wide area surveillance. In Computer Vision—ECCV 2010: 11th European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 186–199. [Google Scholar]
- Xie, X.; Li, B.; Wei, X. Ship detection in multispectral satellite images under complex environment. Remote Sens. 2020, 12, 792. [Google Scholar] [CrossRef]
- Akhyar, A.; Zulkifley, M.A.; Lee, J.; Song, T.; Han, J.; Cho, C.; Hyun, S.; Son, Y.; Hong, B.W. Deep artificial intelligence applications for natural disaster management systems: A methodological review. Ecol. Indic. 2024, 163, 112067. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, W. Frequency mining and complementary fusion network for RGB-infrared object detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Sánchez-Azofeifa, A.; Rivard, B.; Wright, J.; Feng, J.L.; Li, P.; Chong, M.M.; Bohlman, S.A. Estimation of the distribution of Tabebuia guayacan (Bignoniaceae) using high-resolution remote sensing imagery. Sensors 2011, 11, 3831–3851. [Google Scholar] [CrossRef] [PubMed]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented r-cnn for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Kim, J.H.; Batchuluun, G.; Park, K.R. Pedestrian detection based on faster R-CNN in nighttime by fusing deep convolutional features of successive images. Expert Syst. Appl. 2018, 114, 15–33. [Google Scholar] [CrossRef]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-Infrared Object Detection by Reducing Cross-Modality Redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Jin, X.; Jiang, Q.; Yao, S.; Zhou, D.; Nie, R.; Hai, J.; He, K. A survey of infrared and visual image fusion methods. Infrared Phys. Technol. 2017, 85, 478–501. [Google Scholar] [CrossRef]
- Zheng, X.; Cui, H.; Lu, X. Multiple source domain adaptation for multiple object tracking in satellite video. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions. arXiv 2021, arXiv:2112.08088. [Google Scholar] [CrossRef]
- Dhanaraj, M.; Sharma, M.; Sarkar, T.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. Vehicle detection from multi-modal aerial imagery using YOLOv3 with mid-level fusion. In Proceedings of the Big Data II: Learning, Analytics, and Applications, Online, 27 April–8 May 2020; pp. 22–32. [Google Scholar]
- Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object detection in multimodal remote sensing imagery. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 1497–1508. [Google Scholar] [CrossRef]
- Fang, Q.; Wang, Z. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognit. 2022, 130, 108786–108799. [Google Scholar]
- Zhang, Z.; Li, C.; Wang, C.; Lv, J. DualYOLO: Remote small target detection with dual detection heads based on multi-scale feature fusion. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 2558–2564. [Google Scholar]
- Zhu, J.; Chen, X.; Zhang, H.; Tan, Z.; Wang, S.; Ma, H. Transformer based remote sensing object detection with enhanced multispectral feature extraction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5001405. [Google Scholar] [CrossRef]
- Tian, T.; Cai, J.; Xu, Y.; Wu, Z.; Wei, Z.; Chanussot, J. RGB-infrared multi-modal remote sensing object detection using CNN and transformer based feature fusion. In Proceedings of the IGARSS 2023—2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 5728–5731. [Google Scholar]
- Yuan, M.; Shi, X.; Wang, N.; Wang, Y.; Wei, X. Improving RGB-infrared object detection with cascade alignment-guided transformer. Inf. Fusion 2024, 105, 102246. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Available online: https://github.com/ultralytics/yolov5 (accessed on 26 June 2020).
- Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2024).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Zhang, X.; Zhang, Y.; Guo, Z.; Zhao, J.; Tong, X. Advances and perspective on motion detection fusion in visual and thermal framework. J. Infrared Millim. Waves 2011, 30, 354–359. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Fang, Q.; Han, D.; Wang, Z. Cross-Modality Fusion Transformer for Multispectral Object Detection. arXiv 2022, arXiv:2111.00273. [Google Scholar]
- Bao, C.; Cao, J.; Hao, Q.; Cheng, Y.; Ning, Y.; Zhao, T. Dual-YOLO architecture from infrared and visible images for object detection. Sensors 2023, 23, 2934. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 1958–1974. [Google Scholar] [CrossRef]
- Li, B.; Peng, F.; Hui, T.; Wei, X.; Wei, X.; Zhang, L.; Shi, H.; Liu, S. RGB-T Tracking With Template-Bridged Search Interaction and Target-Preserved Template Updating. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 634–649. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: Gated fusion double SSD for multispectral pedestrian detection. arXiv 2019, arXiv:1903.06999. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 72–80. [Google Scholar]
- Zhang, X. Deep learning-based multi-focus image fusion: A survey and a comparative study. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4819–4838. [Google Scholar] [CrossRef] [PubMed]
- Qi, G.; Chang, L.; Luo, Y.; Chen, Y.; Zhu, Z.; Wang, S. A precise multi-exposure image fusion method based on low-level features. Sensors 2020, 20, 1597. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Cai, W.; Li, M.; Li, X.-Y. Infrared and visible image fusion scheme based on contourlet transform. In Proceedings of the 2009 Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 516–520. [Google Scholar]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral pedestrian detection using deep fusion convolutional neural networks. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016; pp. 509–514. [Google Scholar]
- French, G.; Finlayson, G.; Mackiewicz, M. Multi-spectral pedestrian detection via image fusion and deep neural networks. In Proceedings of the Color and Imaging Conference, 26th Color and Imaging Conference Final Program and Proceedings, Vancouver, BC, Canada, 12–16 November 2018; pp. 176–181. [Google Scholar]
- Vandersteegen, M.; Van Beeck, K.; Goedemé, T. Real-time multispectral pedestrian detection with a single-pass deep neural network. In Proceedings of the 15th International Conference on Image Analysis and Recognition, Póvoa de Varzim, Portugal, 27–29 June 2018; pp. 419–426. [Google Scholar]
- Tan, H.; Huang, X.; Tan, H.; He, C. A comparative analysis of pixel-level image fusion based on sparse representation. In Proceedings of the 2012 International Conference on Computational Problem-Solving (ICCP), Leshan, China, 19–21 October 2012; pp. 332–334. [Google Scholar]
- Rehman, N.U.; Ehsan, S.; Abdullah, S.M.U.; Akhtar, M.J.; Mandic, D.P.; McDonald-Maier, K.D. Multi-scale pixel-based image fusion using multivariate empirical model decomposition. Sensors 2015, 15, 10923–10947. [Google Scholar] [CrossRef]
- Li, L.; Liu, Z.; Zou, W.; Zhang, X.; Le Meur, O. Co-saliency detection based on region-level fusion and pixel-level refinement. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Fu, Y.; Cao, L.; Guo, G. Multiple feature fusion by subspace learning. In Proceedings of the 2008 International Conference on Content-Based Image and Video Retrieval, Niagara Falls, ON, Canada, 7–9 July 2008; pp. 127–134. [Google Scholar]
- Li, H.; Wu, X.-J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Liu, J.; Dian, R.; Li, S.; Liu, H. SGFusion: A saliency guided deep-learning framework for pixel-level image fusion. Inf. Fusion 2023, 91, 205–214. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Available online: https://github.com/albumentations-team/albumentations (accessed on 26 September 2018).
- Available online: https://docs.ultralytics.com/ (accessed on 12 November 2023).
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Available online: https://imbalanced-learn.org/stable/ (accessed on 20 December 2024).
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-modality interactive attention network for multispectral pedestrian detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5127–5137. [Google Scholar]
- Yuan, M.; Wei, X. C2former: Calibrated and complementary transformer for RGB-infrared object detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- He, X.; Tang, C.; Zou, X.; Zhang, W. Multispectral object detection via cross-modal conflict-aware learning. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1465–1474. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FPS | mAP |
|---|---|---|
| RGB | 126 | 75.64 |
| YUV (ours) | 132 | 76.19 |
| HSV | 115 | 76.02 |
| Methods | SS | AS | SE | GFLOPs | FPS | mAP |
|---|---|---|---|---|---|---|
| baseline | 26.212 | 147 | 74.42 | |||
| 1 | ✓ | 26.218 | 141 | 74.35 | ||
| 2 | ✓ | 26.220 | 139 | 75.36 | ||
| 3 | ✓ | ✓ | 26.226 | 134 | 75.67 | |
| 4 | ✓ | 26.220 | 144 | 74.88 | ||
| 5 | ✓ | ✓ | 26.227 | 138 | 74.83 | |
| 6 | ✓ | ✓ | 26.228 | 137 | 75.66 | |
| FMPFNet | ✓ | ✓ | ✓ | 26.234 | 132 | 76.19 |
| Detectors | Daylight | Dim Light | Dark | Overall |
|---|---|---|---|---|
| baseline | 82.03 | 75.94 | 70.60 | 76.19 |
| RO (1:2:3) | 81.50 | 75.80 | 71.35 | 76.21 |
| SMOTE (1:2:3) | 81.63 | 75.74 | 71.39 | 76.25 |
| RO (1:3:5) | 80.32 | 75.64 | 71.76 | 75.91 |
| SMOTE (1:3:5) | 80.54 | 75.63 | 71.80 | 75.99 |
| DMDTM (ours) | 81.64 | 75.87 | 72.88 | 76.80 |
| Detectors | GFLOPs | FPS | Car | Trunk | Bus | Van | Freight Car | mAP |
|---|---|---|---|---|---|---|---|---|
| YOLOv8s (OBB) | 29.5 | 103 | 94.61 | 70.37 | 92.86 | 54.18 | 54.68 | 73.34 |
| YOLOv10s (OBB) 1 | 26.2 | 147 | 94.84 | 70.62 | 93.64 | 55.62 | 57.39 | 74.42 |
| YOLOv11s (OBB) | 24.6 | 130 | 94.77 | 71.83 | 93.07 | 53.94 | 56.03 | 73.93 |
| UA-CMDet [63] | - | - | 87.51 | 60.70 | 87.08 | 37.95 | 46.80 | 64.01 |
| Halfway Fusion [38] | 77.31 | 31 | 89.85 | 60.34 | 88.97 | 46.28 | 55.51 | 68.19 |
| CIAN [66] | 70.36 | 32 | 89.98 | 62.47 | 88.90 | 49.59 | 60.22 | 70.23 |
| AR-CNN [67] | 104.3 | 28 | 90.08 | 64.82 | 89.38 | 51.51 | 62.12 | 71.58 |
| C2Former [68] | 100.9 | 30 | 90.21 | 68.26 | 89.81 | 58.47 | 64.62 | 74.23 |
| YOLO Fusion [19] | 25.7 | 61 | 91.46 | 72.71 | 90.58 | 57.62 | 60.35 | 74.54 |
| CAGTDet [23] | 120.6 | 26 | 90.82 | 69.65 | 90.46 | 55.62 | 66.28 | 74.57 |
| CALNet [69] | 174.54 | - | 90.30 | 76.15 | 89.11 | 58.46 | 62.97 | 75.40 |
| FMCFNet [4] | 200.43 | - | 90.33 | 77.71 | 89.35 | 60.71 | 65.65 | 76.75 |
| FMPFNet (Ours) 2 | 26.3 | 132 | 95.23 | 73.61 | 94.45 | 58.01 | 59.66 | 76.19 |
| FMPFNet (Ours) | 26.3 | 132 | 95.18 | 76.79 | 94.46 | 57.08 | 60.47 | 76.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhang, Q. Real-Time Aerial Multispectral Object Detection with Dynamic Modality-Balanced Pixel-Level Fusion. Sensors 2025, 25, 3039. https://doi.org/10.3390/s25103039
Wang Z, Zhang Q. Real-Time Aerial Multispectral Object Detection with Dynamic Modality-Balanced Pixel-Level Fusion. Sensors. 2025; 25(10):3039. https://doi.org/10.3390/s25103039
Chicago/Turabian StyleWang, Zhe, and Qingling Zhang. 2025. "Real-Time Aerial Multispectral Object Detection with Dynamic Modality-Balanced Pixel-Level Fusion" Sensors 25, no. 10: 3039. https://doi.org/10.3390/s25103039
APA StyleWang, Z., & Zhang, Q. (2025). Real-Time Aerial Multispectral Object Detection with Dynamic Modality-Balanced Pixel-Level Fusion. Sensors, 25(10), 3039. https://doi.org/10.3390/s25103039