
MCFNet: Multi-Scale Contextual Fusion Network for Salient Object Detection in Optical Remote Sensing Images



Abstract
1. Introduction
- 1.
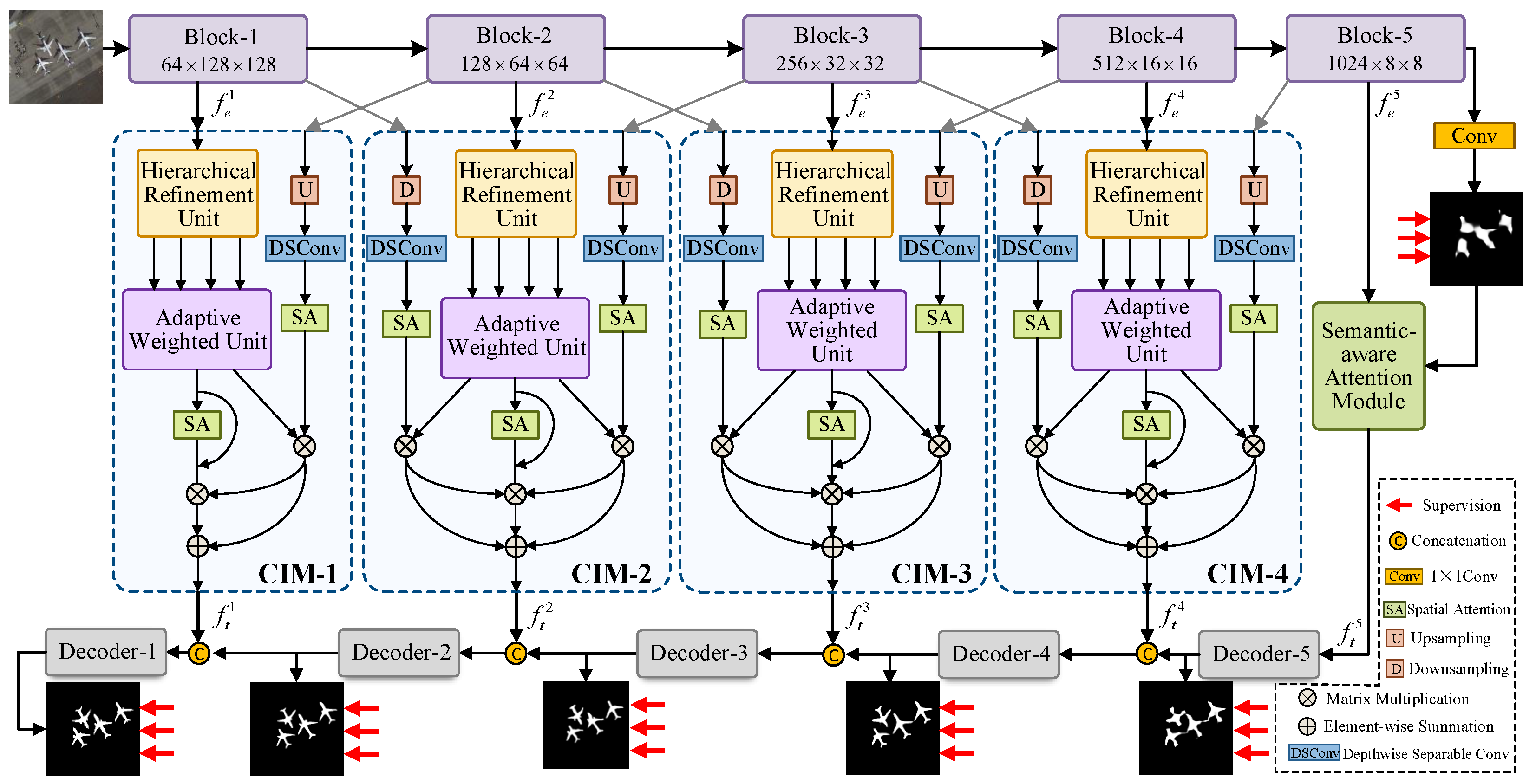
- We introduce a Multi-scale Contextual Fusion Network (MCFNet) built upon an encoder–decoder framework, designed to effectively extract high-level semantic cues while promoting the integration of low-level detailed features with high-level contextual information via a cross-level interconnection strategy.
- 2.
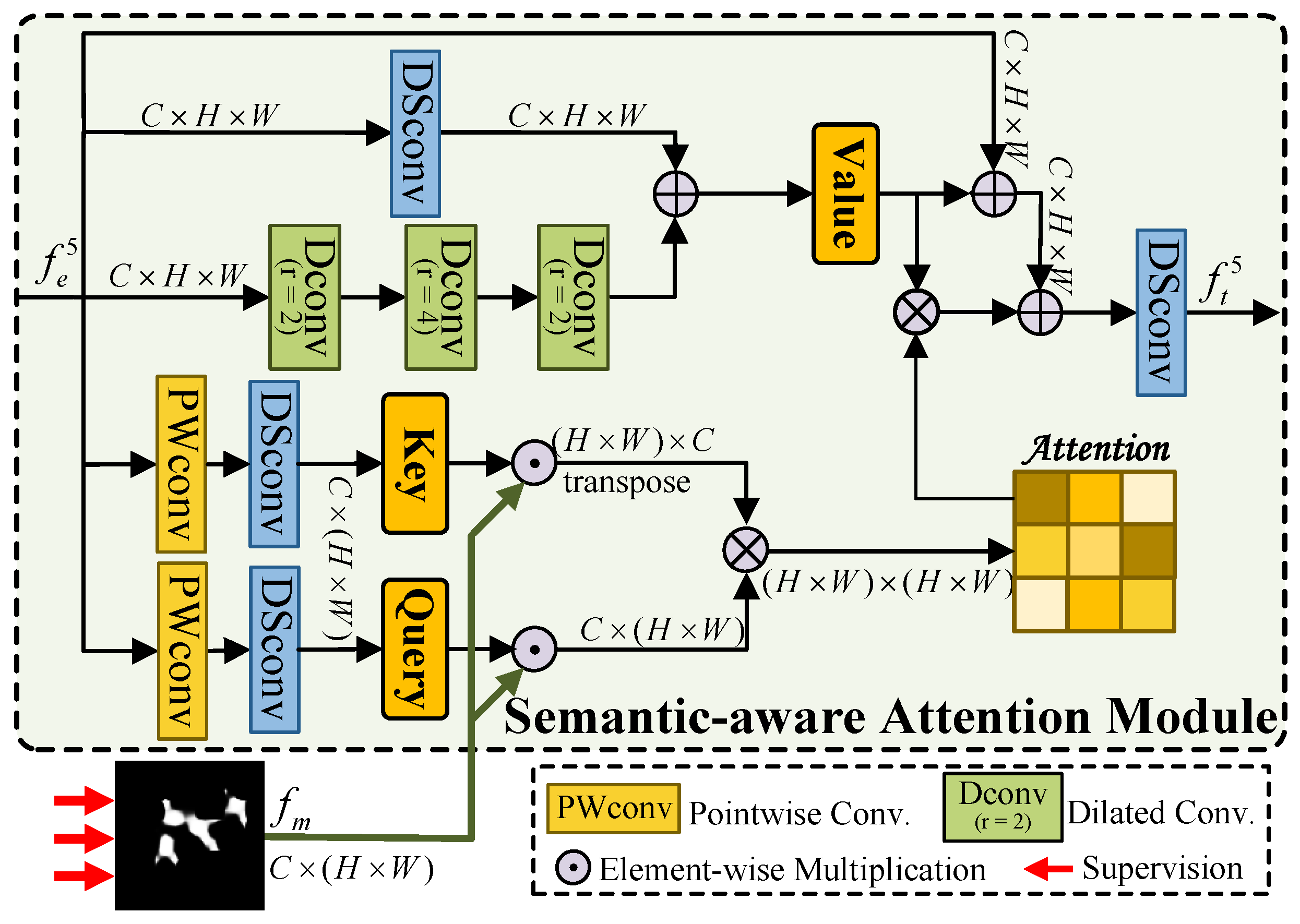
- We introduce a Semantic-Aware Attention Module (SAM), which leverages preliminary semantic masks to guide the extraction of deep semantic information in ORSIs, thereby enhancing the ability to localize salient targets under complex conditions.
- 3.
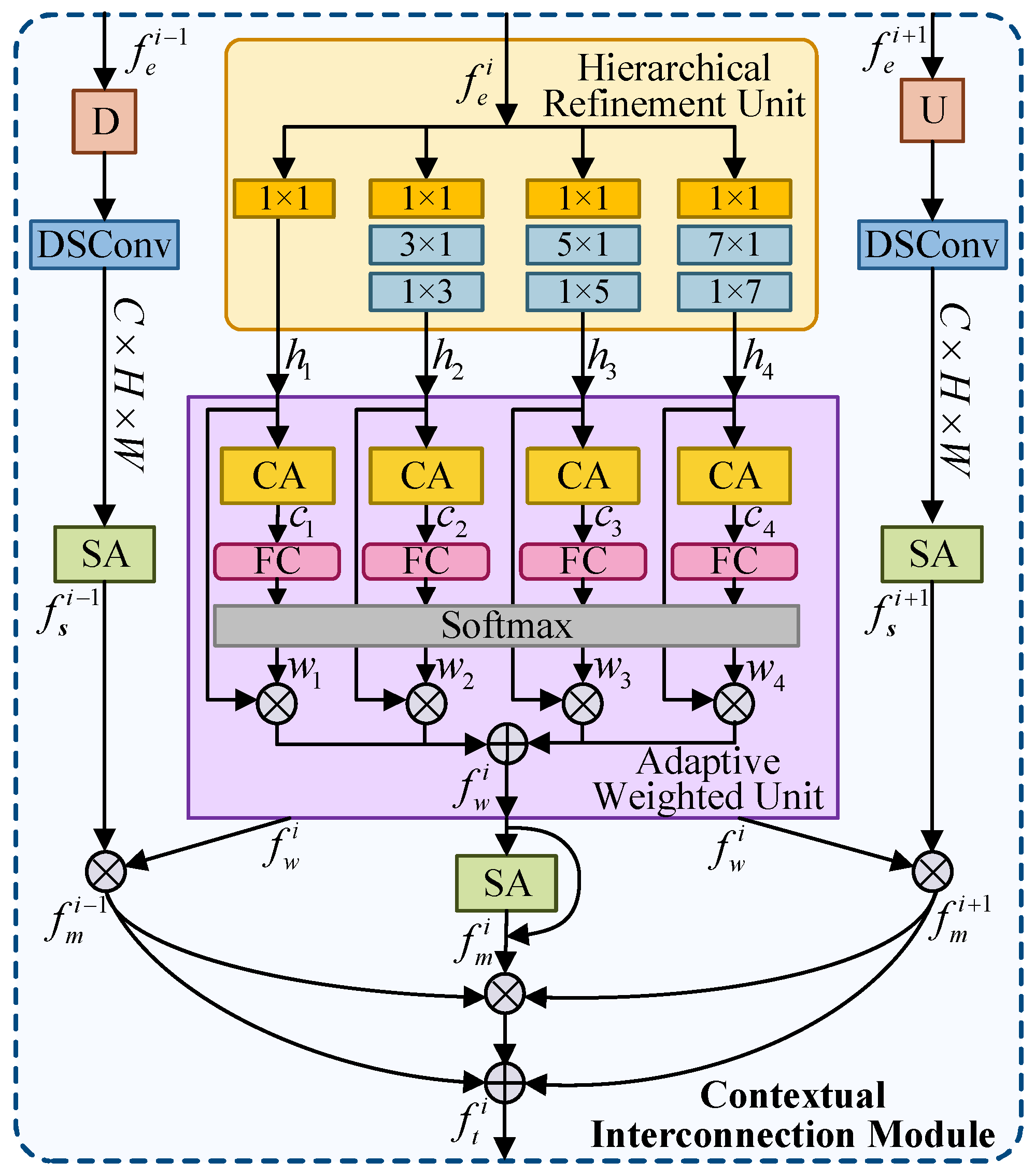
- We design a Contextual Interconnection Module (CIM) that enriches texture representations across multiple scales by refining local features and adaptively fusing contextual information from adjacent layers.
- 4.
- Comprehensive evaluations conducted on three datasets, ORSSD, EORSSD, and ORSI4199, show that our approach achieves superior performance compared to existing methods. Furthermore, ablation studies confirm the contribution and effectiveness of each proposed module.
2. Related Work
2.1. Salient Object Detection Methods in NSIs
2.2. Salient Object Detection Methods in ORSIs
3. Method
3.1. Network Overview
3.2. Semantic-Aware Attention Module
3.3. Contextual Interconnection Module
3.4. Decoder and Loss Function
4. Experiments and Results
4.1. Experiment Protocol
4.2. Comparison with State-of-the-Art Methods
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, B.; Liu, D.; Cao, Y.; Liu, H.; Yan, Z.; Chen, H. CFRNet: Cross-Attention-Based Fusion and Refinement Network for Enhanced RGB-T Salient Object Detection. Sensors 2024, 24, 7146. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Zhai, Z.; Feng, M. SLMSF-Net: A Semantic Localization and Multi-Scale Fusion Network for RGB-D Salient Object Detection. Sensors 2024, 24, 1117. [Google Scholar] [CrossRef]
- Zhao, J.; Wen, X.; He, Y.; Yang, X.; Song, K. Wavelet-Driven Multi-Band Feature Fusion for RGB-T Salient Object Detection. Sensors 2024, 24, 8159. [Google Scholar] [CrossRef]
- Chen, C.; Mo, J.; Hou, J.; Wu, H.; Liao, L.; Sun, W.; Yan, Q.; Lin, W. TOPIQ: A Top-Down Approach From Semantics to Distortions for Image Quality Assessment. IEEE Trans. Image Process. 2024, 33, 2404–2418. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Feng, H.; Xu, H.; Liu, X.; He, J.; Gan, L.; Wang, X.; Wang, S. Surface Vessels Detection and Tracking Method and Datasets with Multi-Source Data Fusion in Real-World Complex Scenarios. Sensors 2025, 25, 2179. [Google Scholar] [CrossRef]
- Liu, S.; Shen, X.; Xiao, S.; Li, H.; Tao, H. A Multi-Scale Feature-Fusion Multi-Object Tracking Algorithm for Scale-Variant Vehicle Tracking in UAV Videos. Remote Sens. 2025, 17, 1014. [Google Scholar] [CrossRef]
- Cho, D.; Park, J.; Oh, T.H.; Tai, Y.W.; So Kweon, I. Weakly-and Self-Supervised Learning for Content-Aware Deep Image Retargeting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4558–4567. [Google Scholar]
- Zheng, J.; Quan, Y.; Zheng, H.; Wang, Y.; Pan, X. ORSI Salient Object Detection via Cross-Scale Interaction and Enlarged Receptive Field. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6003205–6003209. [Google Scholar] [CrossRef]
- Tong, N.; Lu, H.; Ruan, X.; Yang, M.H. Salient Object Detection via Bootstrap Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1884–1892. [Google Scholar]
- Song, H.; Liu, Z.; Du, H.; Sun, G.; Le Meur, O.; Ren, T. Depth-Aware Salient Object Detection and Segmentation via Multiscale Discriminative Saliency Fusion and Bootstrap Learning. IEEE Trans. Image Process. 2017, 26, 4204–4216. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Yang, Z.; Zhou, Z.; Hu, D. Salient Region Detection Using Diffusion Process on a Two-Layer Sparse Graph. IEEE Trans. Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef]
- Ding, L.; Wang, X.; Li, D. Visual Saliency Detection in High-Resolution Remote Sensing Images Using Object-Oriented Random Walk Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4698–4707. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and Balance: A Simple Gated Network for Salient Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 35–51. [Google Scholar]
- Xu, B.; Liang, H.; Liang, R.; Chen, P. Locate Globally, Segment Locally: A Progressive Architecture With Knowledge Review Network for Salient Object Detection. In Proceedings of the 25th AAAI Conference on Artificial Intelligence (AAAI 21), Online, 2–9 February 2021; pp. 3004–3012. [Google Scholar]
- Li, J.; Pan, Z.; Liu, Q.; Wang, Z. Stacked U-Shape Network With Channel-Wise Attention for Salient Object Detection. IEEE Trans. Multimed. 2020, 23, 1397–1409. [Google Scholar] [CrossRef]
- Lee, S.; Cho, S.; Park, C.; Park, S.; Kim, J.; Lee, S. LSHNet: Leveraging Structure-Prior With Hierarchical Features Updates for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5642516–5642531. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Hu, W.; Zhang, G.; Wu, J.; Li, X. TCM-Net: Mixed Global–Local Learning for Salient Object Detection in Optical Remote Sensing Images. Remote Sens. 2023, 15, 4977. [Google Scholar] [CrossRef]
- Huo, L.; Hou, J.; Feng, J.; Wang, W.; Liu, J. Global and multiscale aggregate network for saliency object detection in optical remote sensing images. Remote Sens. 2024, 16, 624. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested Network with Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Cybern. 2022, 60, 5607913–5607926. [Google Scholar] [CrossRef]
- Zeng, X.; Xu, M.; Hu, Y.; Tang, H.; Hu, Y.; Nie, L. Adaptive Edge-Aware Semantic Interaction Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617416–5617431. [Google Scholar] [CrossRef]
- Liu, Z.; Zou, W.; Le Meur, O. Saliency tree: A novel saliency detection framework. IEEE Trans. Image Process. 2014, 23, 1937–1952. [Google Scholar]
- Yu, J.G.; Zhao, J.; Tian, J.; Tan, Y. Maximal entropy random walk for region-based visual saliency. IEEE Trans. Cybern. 2013, 44, 1661–1672. [Google Scholar]
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Reversion correction and regularized random walk ranking for saliency detection. IEEE Trans. Image Process. 2017, 27, 1311–1322. [Google Scholar] [CrossRef]
- Zhou, Y.; Huo, S.; Xiang, W.; Hou, C.; Kung, S.Y. Semi-Supervised Salient Object Detection Using a Linear Feedback Control System Model. IEEE Trans. Cybern. 2019, 49, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Pan, C.; Liu, J.; Yan, W.Q.; Cao, F.; He, W.; Zhou, Y. Salient Object Detection Based on Visual Perceptual Saturation and Two-Stream Hybrid Networks. IEEE Trans. Image Process. 2021, 30, 4773–4787. [Google Scholar] [CrossRef] [PubMed]
- Liang, M.; Hu, X. Feature selection in supervised saliency prediction. IEEE Trans. Cybern. 2014, 45, 914–926. [Google Scholar] [CrossRef]
- Jang, S.W.; Yan, L.; Kim, G.Y. Deep Supervised Attention Network for Dynamic Scene Deblurring. Sensors 2025, 25, 1896. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Ma, F.; Zhang, F.; Yin, Q.; Xiang, D.; Zhou, Y. Fast SAR Image Segmentation With Deep Task-Specific Superpixel Sampling and Soft Graph Convolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5214116–5214131. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Xiang, D.; Yin, Q.; Zhou, Y. Fast Task-Specific Region Merging for SAR Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222316–5222331. [Google Scholar] [CrossRef]
- Luo, H.; Liang, B. Semantic-Edge Interactive Network for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6980–6994. [Google Scholar] [CrossRef]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. ORSI Salient Object Detection via Multiscale Joint Region and Boundary Model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607913–5607925. [Google Scholar] [CrossRef]
- Gu, Y.; Xu, H.; Quan, Y.; Chen, W.; Zheng, J. ORSI Salient Object Detection via Bidimensional Attention and Full-stage Semantic Guidance. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5603213–5603225. [Google Scholar] [CrossRef]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient object detection in optical remote sensing images driven by transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-Guided Recurrent Positioning Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Cybern. 2023, 53, 539–552. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-Measure: A New Way to Evaluate Foreground Maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-Alignment Measure for Binary Foreground Map Evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1698–1704. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-Tuned Salient Region Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3Net: Recurrent Residual Refinement Network for Saliency Detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404–107416. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9410–9419. [Google Scholar]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-Aware Multiscale Feature Integration Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605315–5605330. [Google Scholar] [CrossRef]
- Lin, Y.; Sun, H.; Liu, N.; Bian, Y.; Cen, J.; Zhou, H. Attention Guided Network for Salient Object Detection in Optical Remote Sensing Images. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; pp. 25–36. [Google Scholar]
- Li, G.; Liu, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617712–5617733. [Google Scholar] [CrossRef]
- Quan, Y.; Xu, H.; Wang, R.; Guan, Q.; Zheng, J. ORSI Salient Object Detection via Progressive Semantic Flow and Uncertainty-Aware Refinement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608013–5608025. [Google Scholar] [CrossRef]
- Zhao, J.; Jia, Y.; Ma, L.; Yu, L. Adaptive Dual-Stream Sparse Transformer Network for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5173–5192. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, L.; Wang, Z.; Liu, Y.; Cheng, M.M.; Lu, S.P. Pyramid Constrained Self-Attention Network for Fast Video Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10869–10876. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Type | Params | ORSSD | EORSSD | ORSI4199 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R3Net18 [44] | CN | 56.2 | 0.8141 | 0.0399 | 0.8681 | 0.8913 | 0.7383 | 0.7456 | 0.8184 | 0.0171 | 0.8294 | 0.9483 | 0.6302 | 0.7498 | 0.8392 | 0.0401 | 0.9021 | 0.9141 | 0.8127 | 0.8250 |
| PoolNet19 [30] | CN | 53.6 | 0.8403 | 0.0358 | 0.8650 | 0.9343 | 0.6999 | 0.7706 | 0.8207 | 0.0210 | 0.8193 | 0.9292 | 0.6406 | 0.7545 | 0.8184 | 0.0573 | 0.8028 | 0.8159 | 0.7332 | 0.7457 |
| EGNet19 [13] | CN | 108.1 | 0.8721 | 0.0216 | 0.9013 | 0.9731 | 0.7500 | 0.8332 | 0.8601 | 0.0110 | 0.8775 | 0.9570 | 0.6967 | 0.7880 | 0.8362 | 0.0424 | 0.8916 | 0.9008 | 0.8223 | 0.8368 |
| SUCA20 [16] | CN | 115.6 | 0.9285 | 0.0102 | 0.9611 | 0.9698 | 0.8723 | 0.8885 | 0.9126 | 0.0079 | 0.9396 | 0.9644 | 0.9029 | 0.8535 | 0.8294 | 0.0428 | 0.8271 | 0.8340 | 0.7813 | 0.7927 |
| U2Net20 [45] | CN | 44.0 | 0.9162 | 0.0166 | 0.9387 | 0.9539 | 0.8492 | 0.9738 | 0.9199 | 0.0076 | 0.9373 | 0.9649 | 0.8329 | 0.8732 | 0.8379 | 0.0391 | 0.8988 | 0.9034 | 0.8201 | 0.8325 |
| GateNet20 [14] | CN | 128.6 | 0.9204 | 0.0110 | 0.9560 | 0.9708 | 0.8741 | 0.9035 | 0.9071 | 0.0081 | 0.9364 | 0.9634 | 0.8294 | 0.8646 | 0.8501 | 0.0377 | 0.9155 | 0.9264 | 0.8347 | 0.8489 |
| MINet20 [46] | CN | 47.6 | 0.9040 | 0.0144 | 0.9454 | 0.9545 | 0.8574 | 0.8761 | 0.9040 | 0.0093 | 0.9346 | 0.9442 | 0.8174 | 0.8344 | 0.8498 | 0.0367 | 0.9098 | 0.9163 | 0.8322 | 0.8473 |
| PA-KRN21 [15] | CN | 141.1 | 0.9239 | 0.0139 | 0.9620 | 0.9680 | 0.8727 | 0.8890 | 0.9192 | 0.0104 | 0.9536 | 0.9616 | 0.8358 | 0.8639 | 0.8428 | 0.0385 | 0.9121 | 0.9241 | 0.8257 | 0.8432 |
| DAFNet21 [37] | CR | 29.4 | 0.9191 | 0.0113 | 0.9539 | 0.9771 | 0.8511 | 0.8928 | 0.9166 | 0.0060 | 0.9290 | 0.9659 | 0.7842 | 0.8612 | 0.8653 | 0.0344 | 0.9167 | 0.9365 | 0.8244 | 0.8470 |
| EMFINet22 [47] | CR | 95.1 | 0.9432 | 0.0095 | 0.9726 | 0.9813 | 0.9000 | 0.9155 | 0.9319 | 0.0075 | 0.9598 | 0.9712 | 0.8505 | 0.8742 | 0.8591 | 0.0452 | 0.9022 | 0.9116 | 0.8100 | 0.8169 |
| AGNet22 [48] | CR | 24.6 | 0.9389 | 0.0091 | 0.9728 | 0.9811 | 0.8956 | 0.9098 | 0.9287 | 0.0067 | 0.9656 | 0.9752 | 0.8516 | 0.8758 | 0.8627 | 0.0337 | 0.9276 | 0.9386 | 0.8536 | 0.8614 |
| MJRBM22 [34] | CR | 43.5 | 0.9193 | 0.0146 | 0.9472 | 0.9631 | 0.8544 | 0.8850 | 0.9180 | 0.0107 | 0.9339 | 0.9631 | 0.8274 | 0.8638 | 0.8582 | 0.0372 | 0.9071 | 0.9343 | 0.8305 | 0.8511 |
| ACCoNet22 [21] | CR | 127.0 | 0.9437 | 0.0088 | 0.9754 | 0.9796 | 0.8971 | 0.9149 | 0.9290 | 0.0074 | 0.9653 | 0.9727 | 0.8552 | 0.8837 | 0.8675 | 0.0314 | 0.9342 | 0.9412 | 0.8610 | 0.8646 |
| CorrNet22 [49] | CR | 4.1 | 0.9380 | 0.0098 | 0.9764 | 0.9790 | 0.9002 | 0.9129 | 0.9289 | 0.0083 | 0.9646 | 0.9696 | 0.8620 | 0.8778 | 0.8623 | 0.0366 | 0.9206 | 0.9330 | 0.8513 | 0.8560 |
| BAFS-Net23 [35] | CR | 31.0 | 0.9378 | 0.0083 | 0.9773 | 0.9820 | 0.9016 | 0.9106 | 0.9250 | 0.0061 | 0.9697 | 0.9729 | 0.8564 | 0.8653 | 0.8661 | 0.0314 | 0.9339 | 0.9399 | 0.8588 | 0.8633 |
| ERPNet23 [38] | CR | 77.2 | 0.9352 | 0.0114 | 0.9604 | 0.9738 | 0.8798 | 0.9036 | 0.9252 | 0.0082 | 0.9366 | 0.9665 | 0.8269 | 0.8743 | 0.8652 | 0.0367 | 0.9167 | 0.9284 | 0.8387 | 0.8538 |
| AESINet23 [22] | CR | 51.6 | 0.9455 | 0.0085 | 0.9741 | 0.9814 | 0.8962 | 0.9160 | 0.9347 | 0.0064 | 0.9647 | 0.9757 | 0.8496 | 0.8792 | 0.8702 | 0.0309 | 0.9357 | 0.9423 | 0.8626 | 0.8676 |
| SFANet24 [50] | CR | 25.1 | 0.9453 | 0.0077 | 0.9789 | 0.9830 | 0.9063 | 0.9192 | 0.9349 | 0.0058 | 0.9726 | 0.9769 | 0.8680 | 0.8833 | 0.8761 | 0.0292 | 0.9385 | 0.9447 | 0.8659 | 0.8710 |
| ADSTNet24 [51] | CR | 62.1 | 0.9379 | 0.0086 | 0.9740 | 0.9807 | 0.9042 | 0.9124 | 0.9311 | 0.0065 | 0.9709 | 0.9769 | 0.8716 | 0.8804 | 0.8710 | 0.0318 | 0.9356 | 0.9433 | 0.8653 | 0.8698 |
| LSHNet24 [17] | CR | - | 0.9491 | 0.0075 | 0.9764 | 0.9824 | 0.9054 | 0.9200 | 0.9370 | 0.0064 | 0.9692 | 0.9761 | 0.8643 | 0.8844 | 0.8759 | 0.0299 | 0.9392 | 0.9462 | 0.8690 | 0.8758 |
| MCFNet (Ours) | CR | 29.6 | 0.9472 | 0.0075 | 0.9793 | 0.9835 | 0.9070 | 0.9202 | 0.9374 | 0.0058 | 0.9733 | 0.9769 | 0.8712 | 0.8851 | 0.8768 | 0.0290 | 0.9398 | 0.9467 | 0.8695 | 0.8760 |
| Method | ORSSD | EORSSD | ORSI4199 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 0.9203 | 0.0112 | 0.9659 | 0.8964 | 0.9198 | 0.0097 | 0.9676 | 0.8685 | 0.8498 | 0.0352 | 0.9267 | 0.8485 |
| w/o CIM | 0.9342 | 0.0093 | 0.9707 | 0.9105 | 0.9213 | 0.0075 | 0.9701 | 0.8742 | 0.8661 | 0.0336 | 0.9390 | 0.8588 |
| w/o SAM | 0.9401 | 0.0081 | 0.9739 | 0.9146 | 0.9296 | 0.0069 | 0.9722 | 0.8783 | 0.8683 | 0.0314 | 0.9402 | 0.8655 |
| MCFNet | 0.9472 | 0.0075 | 0.9835 | 0.9202 | 0.9374 | 0.0058 | 0.9769 | 0.8851 | 0.8768 | 0.0290 | 0.9467 | 0.8760 |
| Method | ORSSD | EORSSD | ORSI4199 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o CB | 0.9375 | 0.0088 | 0.9726 | 0.8976 | 0.9245 | 0.0070 | 0.9647 | 0.8637 | 0.8673 | 0.0322 | 0.9316 | 0.8591 |
| w/o AB | 0.9402 | 0.0082 | 0.9741 | 0.9009 | 0.9309 | 0.0064 | 0.9692 | 0.8664 | 0.8709 | 0.0316 | 0.9338 | 0.8604 |
| MCFNet | 0.9472 | 0.0075 | 0.9793 | 0.9070 | 0.9374 | 0.0058 | 0.9733 | 0.8712 | 0.8768 | 0.0290 | 0.9398 | 0.8695 |
| Method | ORSSD | EORSSD | ORSI4199 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MCFNet-VGG | 0.9434 | 0.0080 | 0.9813 | 0.9142 | 0.9328 | 0.0065 | 0.9724 | 0.8819 | 0.8705 | 0.0299 | 0.9411 | 0.8711 |
| MCFNet-PVT | 0.9408 | 0.0083 | 0.9802 | 0.9108 | 0.9299 | 0.0066 | 0.9700 | 0.8793 | 0.8683 | 0.0307 | 0.9387 | 0.8684 |
| MCFNet-ResNet | 0.9463 | 0.0078 | 0.9820 | 0.9193 | 0.9351 | 0.0062 | 0.9753 | 0.8842 | 0.8735 | 0.0296 | 0.9436 | 0.8734 |
| MCFNet(Ours) | 0.9472 | 0.0075 | 0.9835 | 0.9202 | 0.9374 | 0.0058 | 0.9769 | 0.8851 | 0.8768 | 0.0290 | 0.9467 | 0.8760 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, J.; Quan, Y.; Xu, H. MCFNet: Multi-Scale Contextual Fusion Network for Salient Object Detection in Optical Remote Sensing Images. Sensors 2025, 25, 3035. https://doi.org/10.3390/s25103035
Ding J, Quan Y, Xu H. MCFNet: Multi-Scale Contextual Fusion Network for Salient Object Detection in Optical Remote Sensing Images. Sensors. 2025; 25(10):3035. https://doi.org/10.3390/s25103035
Chicago/Turabian StyleDing, Jinting, Yueqian Quan, and Honghui Xu. 2025. "MCFNet: Multi-Scale Contextual Fusion Network for Salient Object Detection in Optical Remote Sensing Images" Sensors 25, no. 10: 3035. https://doi.org/10.3390/s25103035
APA StyleDing, J., Quan, Y., & Xu, H. (2025). MCFNet: Multi-Scale Contextual Fusion Network for Salient Object Detection in Optical Remote Sensing Images. Sensors, 25(10), 3035. https://doi.org/10.3390/s25103035