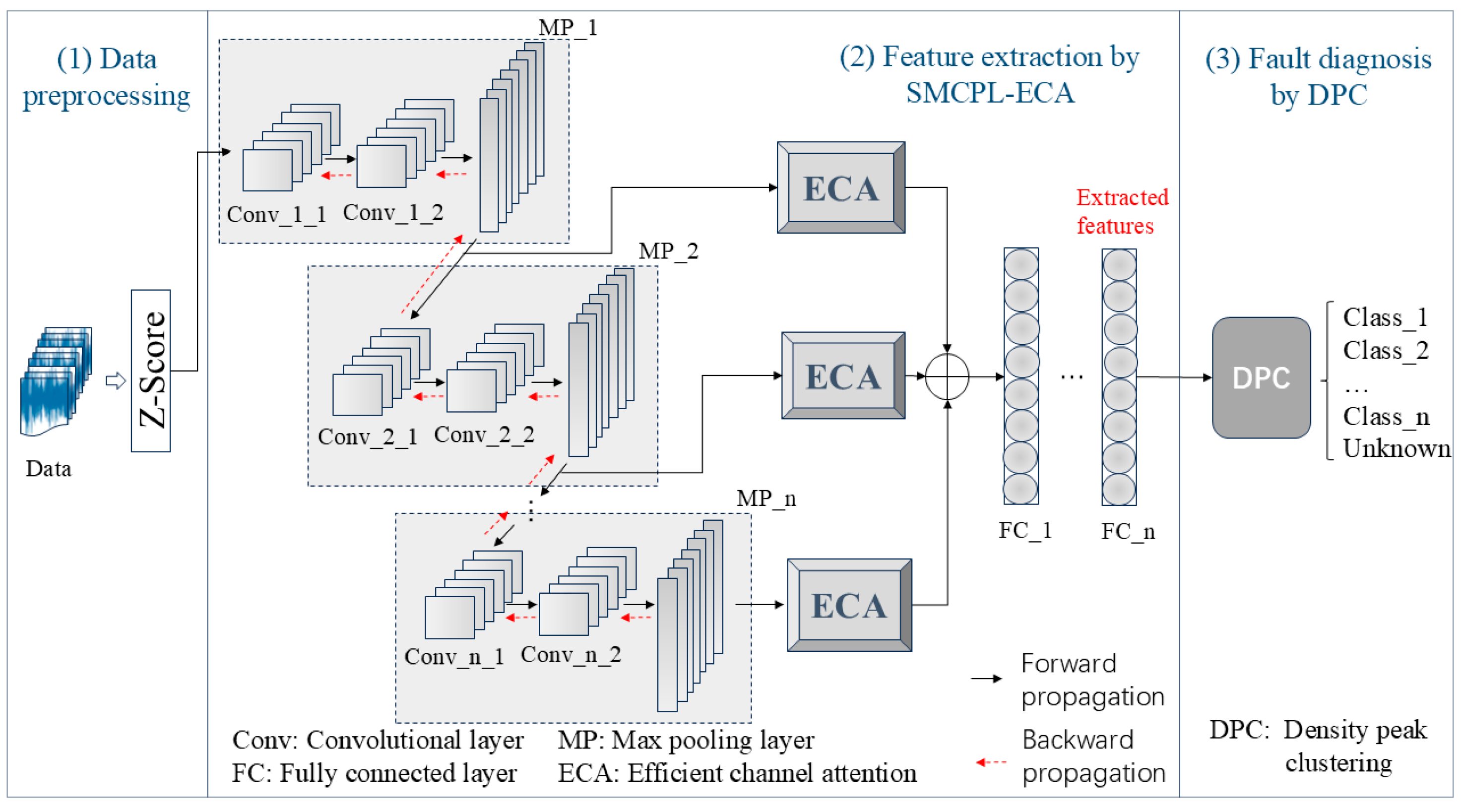
This section presents the performance evaluation and analysis of the SMCPL-ECA-DPC framework, based on metrics such as NA, NF1, J, and feature visualization.
5.1. CWRU Experimental Results
The computational complexity of different models on the CWRU dataset is shown in
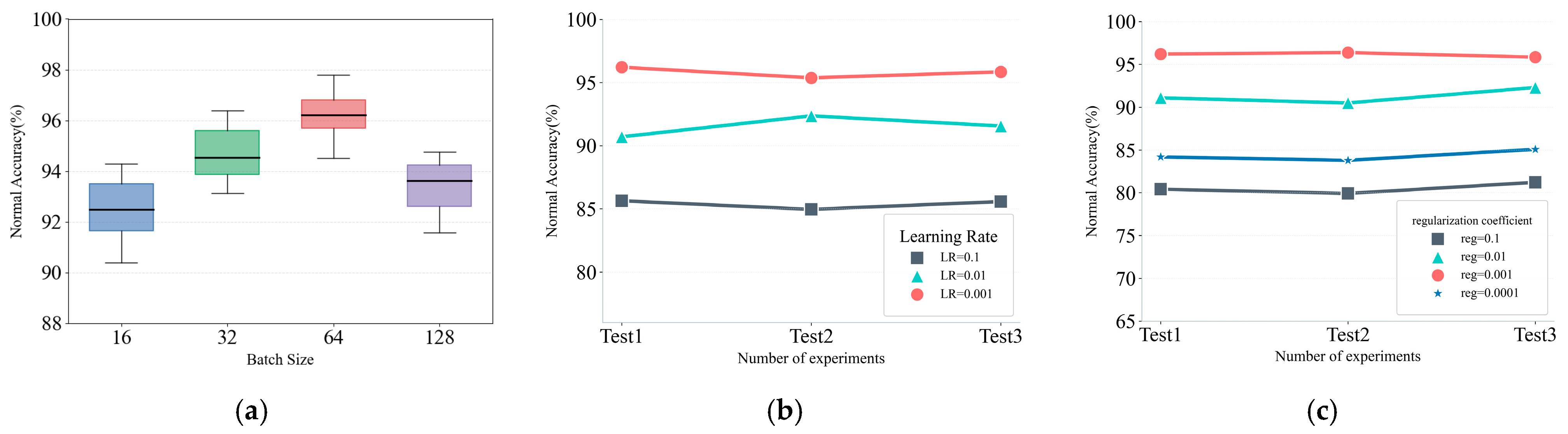
Table 8. Due to the limitation of the experimental environment, this study conducts training and inference on the CPU platform; so, the average inference time for a single sample is relatively long. If GPU acceleration is used, the inference efficiency is expected to be significantly improved. Although the inference time of the SMCPL-ECA-DPC model is longer compared with simple CNN and CPL, its response time is still suitable for practical system monitoring and fault diagnosis. The sampling frequency of the CWRU dataset is 12 kHz, and each input sample contains 1024 data points, as described in this article. The sample generation time is calculated to be 1024/12,000 ≈ 85.3 ms. The inference time of the SMCPL-ECA-DPC model is 8.1 ms, which is much lower than the sample generation time of 85.3 ms. Therefore, the SMCPL-ECA-DPC model can be used for real-time monitoring of bearing health.
Tests were conducted according to the OSR experiment serial number in
Table 2, and the results of the evaluation indexes obtained from the experiments are shown in
Table 9. According to the three key performance indicators listed, the SMCPL-ECA-DPC model proposed in this paper exhibits either optimal or suboptimal performance in terms of overall performance for all 10 types of data jointly involved in the OSR experiments.
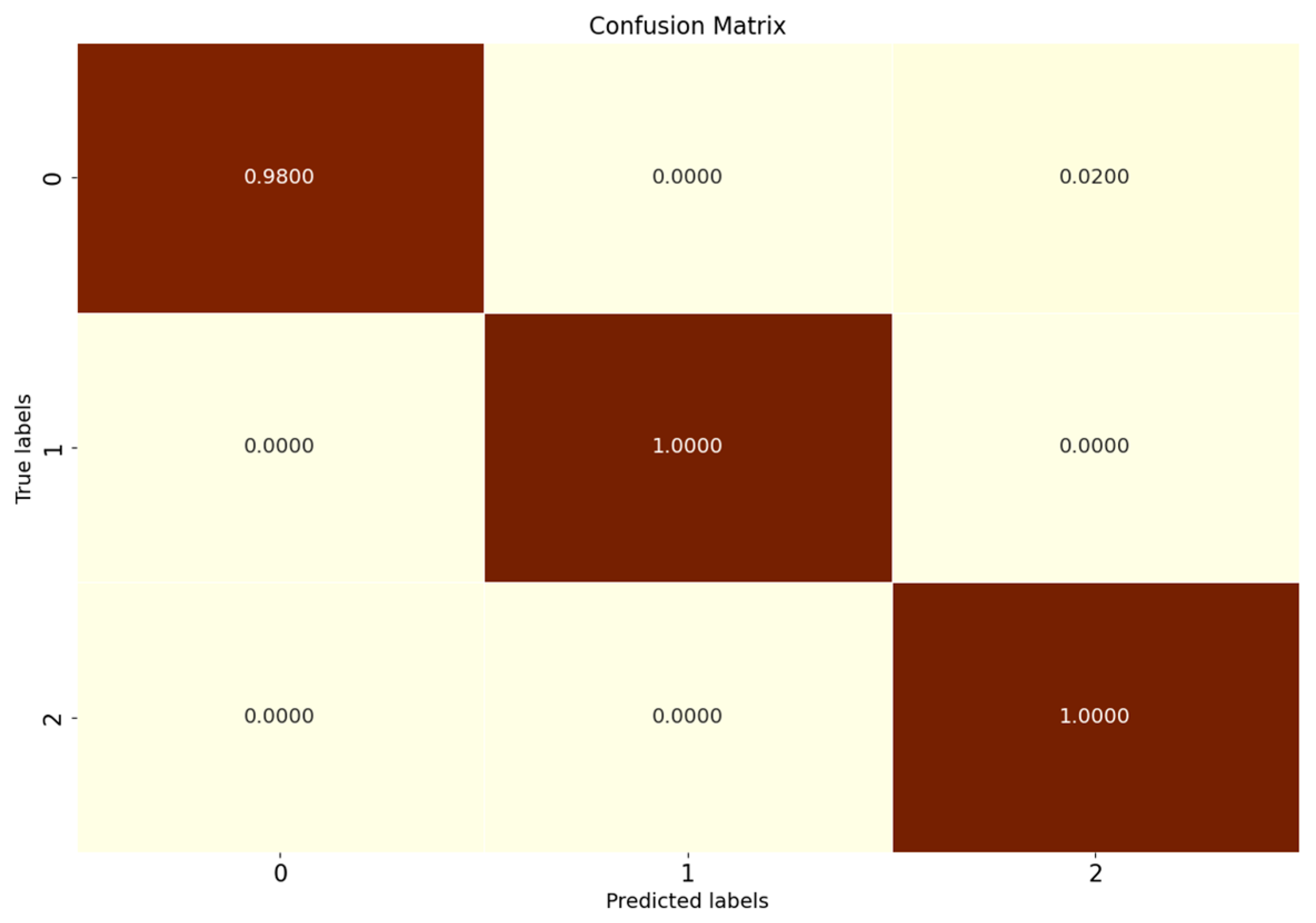
Figure 8 shows the full closed-set fault diagnosis effect of SMCPL-ECA-DPC with an accuracy of 99.57% on the test set, which indicates that the model proposed in this paper is extremely effective for the extraction of critical fault signals and can provide accurate and reliable diagnosis results.
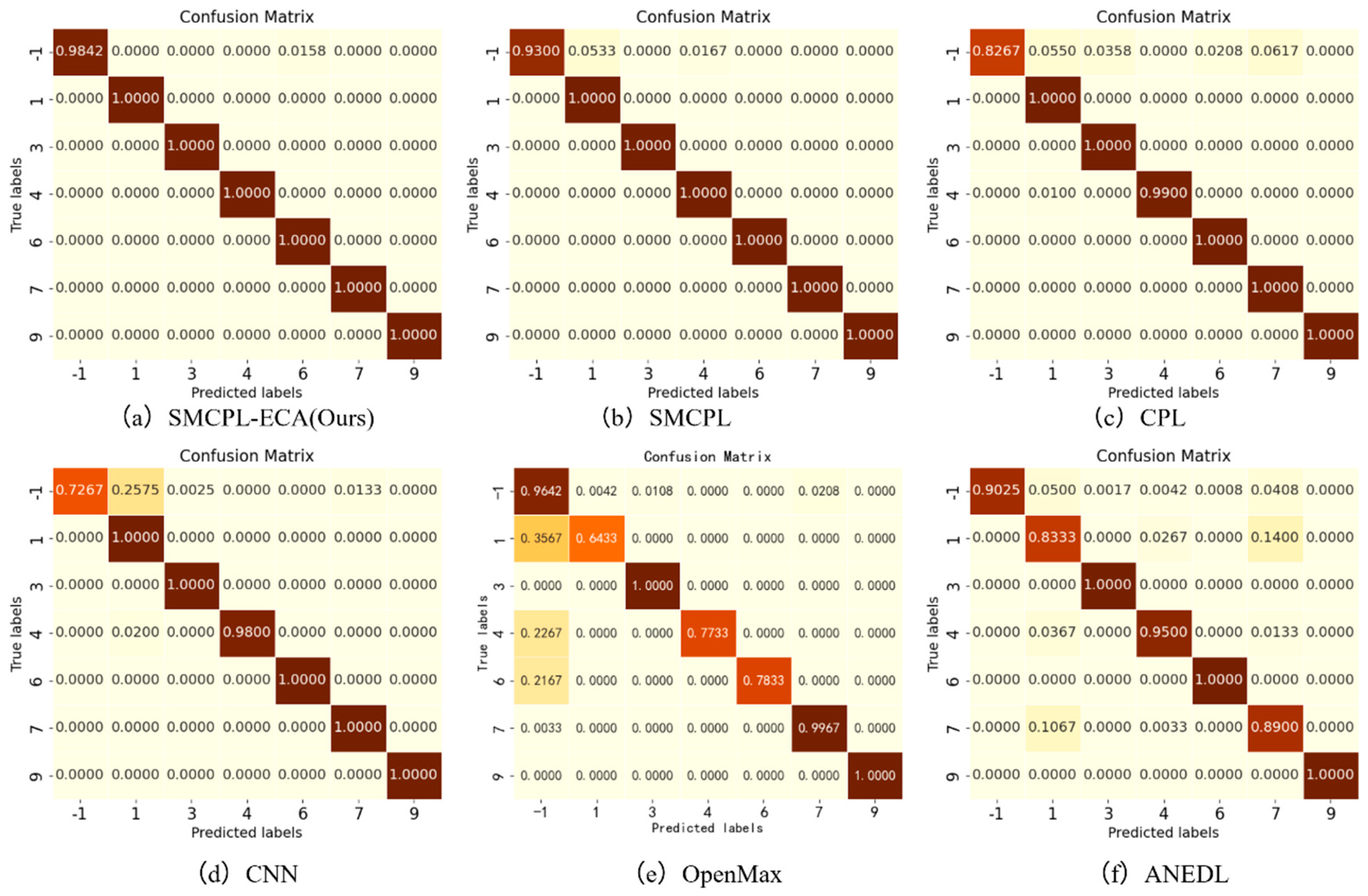
In the specific test scenario of AE2, the SMCPL-ECA-DPC model achieves a 100% recognition rate of unknown classes, which fully proves its excellent ability in feature extraction and classification tasks. For example, AE12 sets B007(0), B021(2), IR021(5), and OR021(8) as unknown classes. In this task, the proposed model is 2.71%, 7.96%, 6.81%, 13.14%, and 7.7% higher than SMCPL, CPL, ANEDL, CNN, and OpenMax on Na, respectively; on NF1, it is 0.0224, 0.068, 0.0592, 0.1048, and 0.093 higher than SMCPL, CPL, ANEDL, CNN, and OpenMax, respectively; on J, it is 0.0253, 0.0747, 0.0762, 0.1225, and 0.1031 higher than SMCPL, CPL, ANEDL, CNN, and OpenMax, respectively. In order to observe and compare the advantages and disadvantages of the six models more intuitively, the output of Fully connected layer 3 (i.e., the features extracted by the framework) is reduced from 256 dimensions to 2 dimensions for display.
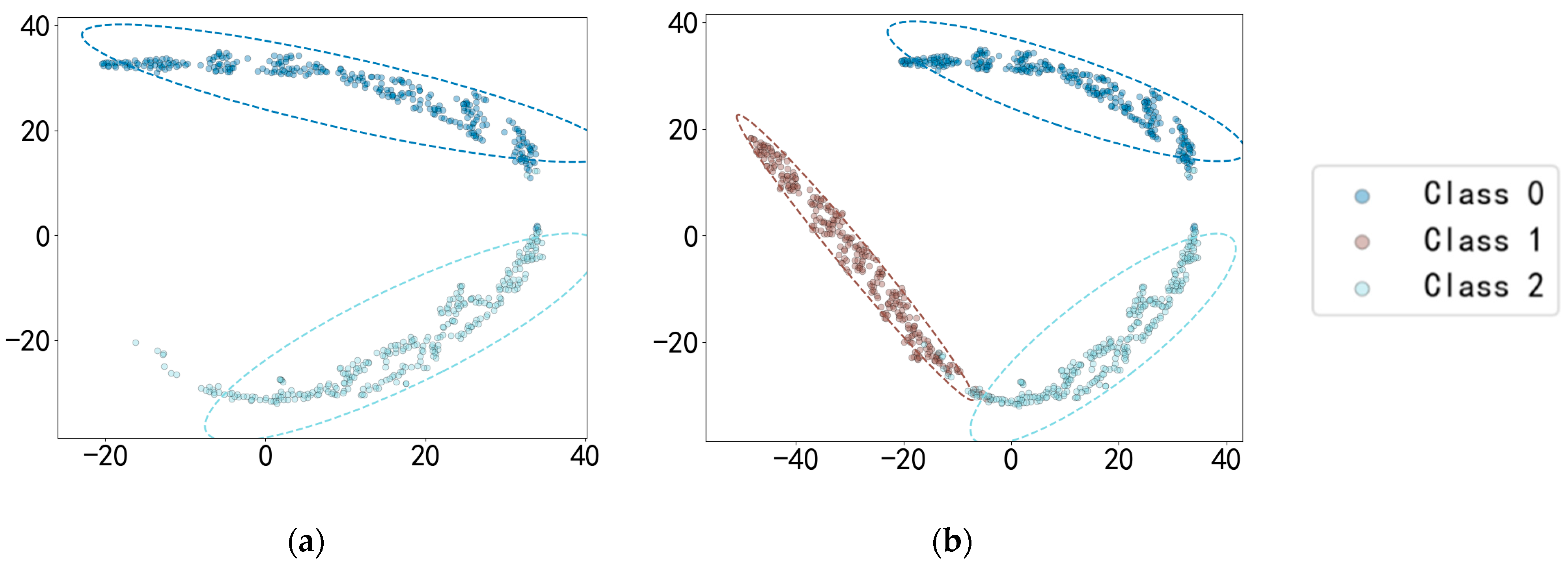
Figure 9 shows the spatial distribution of features extracted by AE12 using different models, and the t-distributed Stochastic Neighbor Embedding (t-SNE) algorithm is selected for the visualization algorithm [
37].
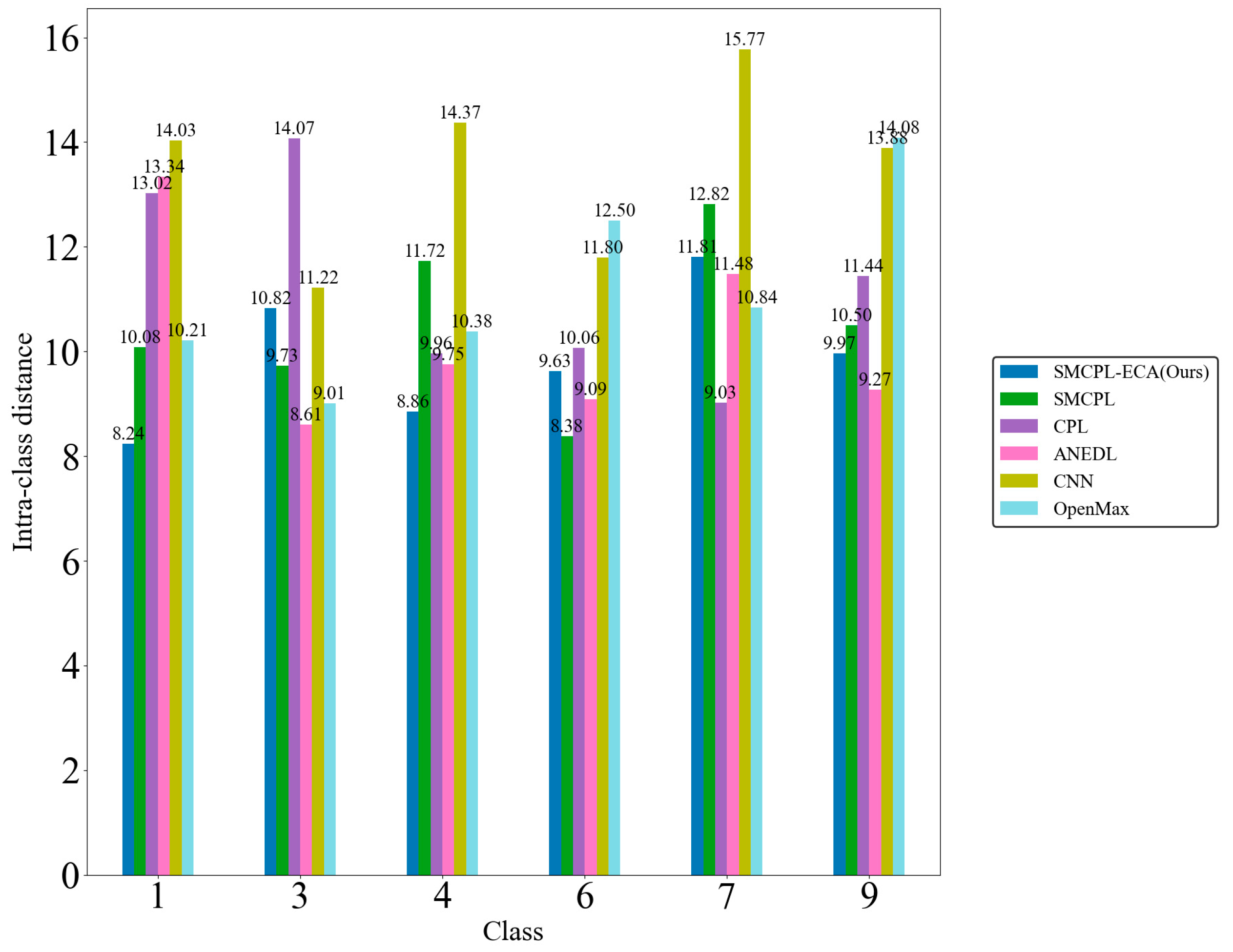
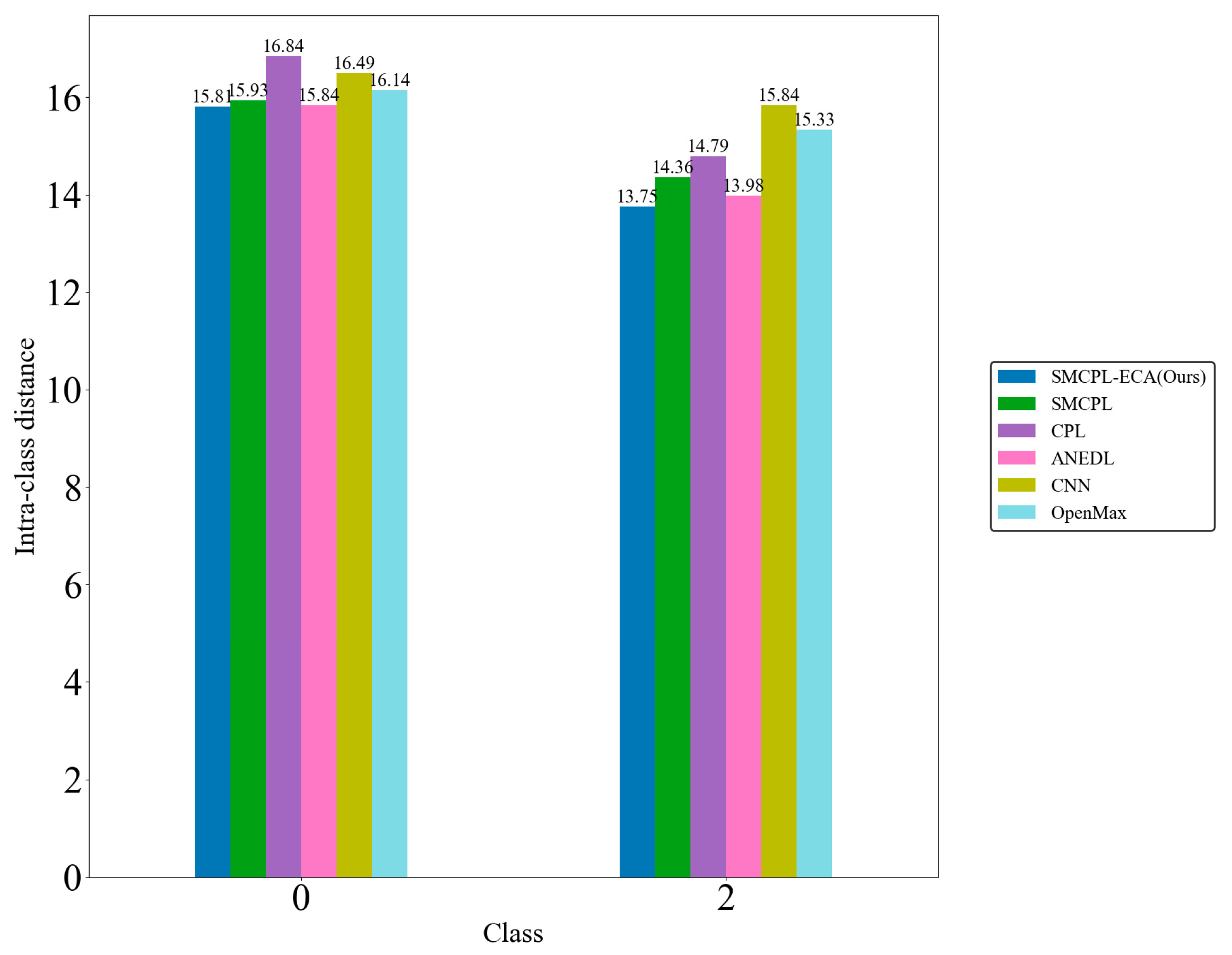
Figure 9d shows that the CNN extracts the known fault feature B014(1) with a low degree of data dispersion and aggregation, whereas the other models for this class of data extraction still have a small number of data points outside the plotted intra-class range, but it can be clearly observed that the data points of the proposed model in this paper for the extraction of B014(1) are all centrally aggregated into a complete, continuous cluster of points with a complete distribution within the intra-class range, which is also significantly reduced according to the intra-class distance visualization in
Figure 10. Intra-class distances are calculated for each class by calculating the Euclidean distance from each sample in the class to the class center and then averaging them, with the input being the Z-score-normalized features and thus dimensionless; inter-class distances are the Euclidean distances between different class centers. The number of interclass distances is extremely high, so it is not convenient to display them. Based on the intra-class distance visualization results and statistical metrics observed in
Figure 10 and
Table 10, SMCPL-ECA-DPC has the lowest mean (9.89), which is smaller than the comparison model’s, indicating that this model has the smallest intra-class distance and the most compact features. It is reduced by 0.64, 1.37, 0.37, 3.62, and 1.28 compared to SMCPL, CPL, ANEDL, CNN, and OpenMax, respectively. In addition to this, SMCPL-ECA-DPC has the smallest coefficient of variation (CV = 0.127), which indicates that the intra-class distances are the least fluctuating and are more robust.
After introducing the unknown class to participate in the test, by observing
Figure 9d–f, it is found that among the known class and unknown class features extracted using CNN, OpenMax, and ANEDL, B007(0) and B021(2) as the unknown classes have a lower recognition rate of the unknown class because they are not involved in the training, and some of their features are distributed in the B014(1) space. For this problem, SMCPL-ECA-DPC greatly improved the separation of unknown and known classes, and the recognition performance is also substantially improved, as shown in
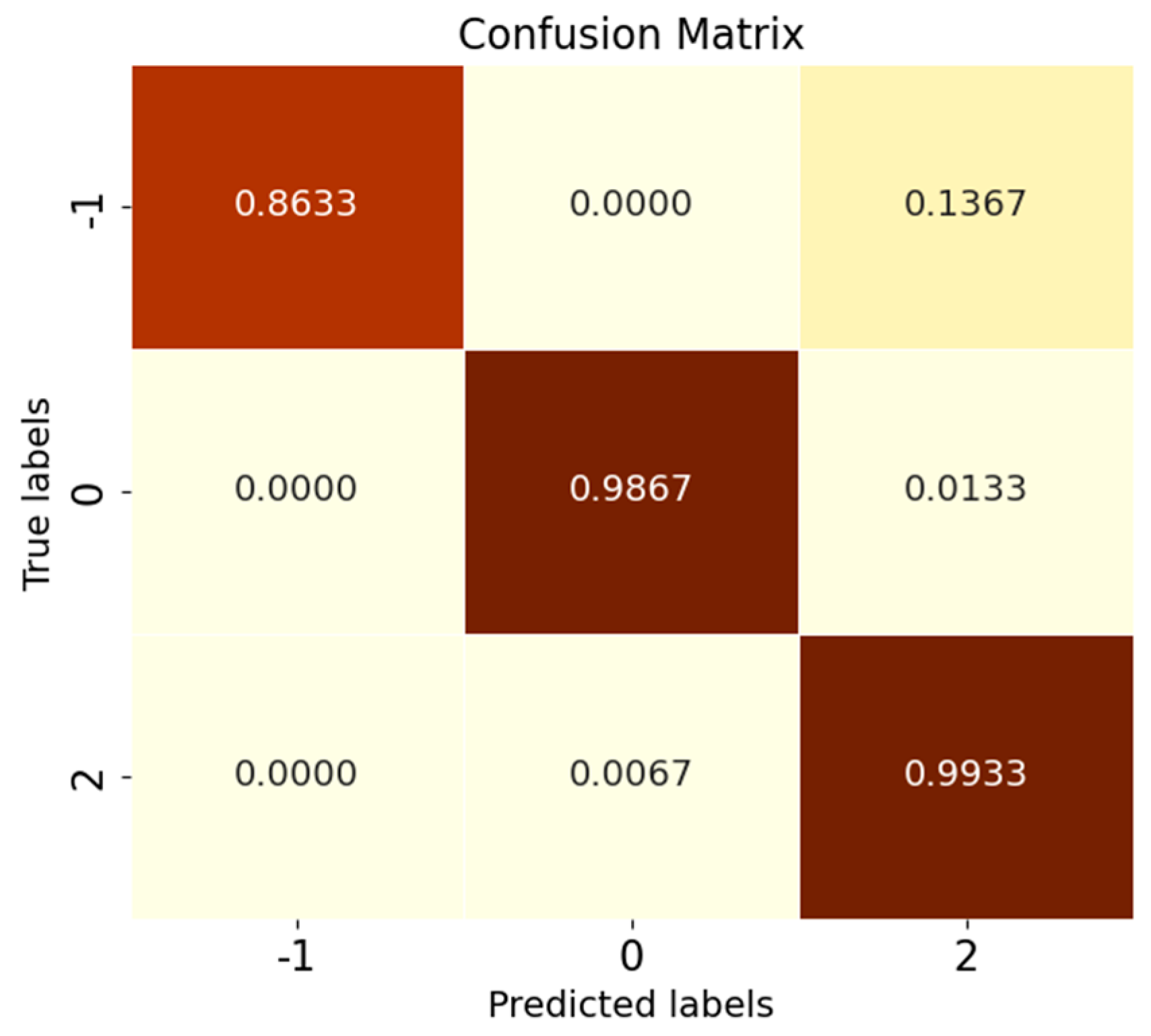
Figure 9a. The corresponding normalized confusion matrix for AE12 is shown in
Figure 11, in which the unknown class fault is labeled as −1. In the normalized confusion matrix, the rows and columns denote the true labels and predicted labels, respectively, and the numerical values in the matrix represent the correct predicted label samples’ number to the total number of true label samples. The confusion matrix classification results also confirm the superiority of the proposed model in OSR experiments.
Anomaly analysis: In some experiments, such as AE2, AE5, and AE6, the diagnostic performance of CPL is lower than that of CNN, specifically because the loss function used by CPL is different from that of CNN, which makes the same class of data closer, and because of this, misclassification may exist. Because the original data belonging to an unknown class and a known class feature distribution are too close, the training instead of the inter-class distance between the two will be so close that it cannot be separated and recognized. This is precisely why the CNN achieves optimal recognition performance in AE7, as our experimental results show that B007(0), serving as an unknown class, has feature distributions extremely similar to those of B021(2), which is also a rolling element fault, making it indistinguishable after intra-class distance reduction.
5.2. XJTU-SY Experimental Results
Comparison tests are conducted according to the OSR experiment serial numbers in
Table 4, and the results of the evaluation metrics on the XJTU-SY dataset are obtained as shown in
Table 11.
Figure 12 shows the full closed-set fault diagnosis results of SMCPL-ECA-DPC on this dataset with 100% test set accuracy.
Table 11 demonstrates the OSR strong diagnostic performance of SMCPL-ECA-DPC on the XJTU-SY dataset, and the classification performances are all higher than those of other models. Taking BE3 (the unknown class is IORF(2)) as an example, the proposed framework in this paper achieves a 100 percent recognition rate of the unknown class with both CPL and SMCPL, and the computed NA, NF1, and J metrics are improved by 1.35%, 0.0126, and 0.0037, respectively, compared to ANEDL; by 25.67%, 0.1832, and 0.2622, respectively, compared to CNN; and by 21.42%, 0.2144, and 0.2834, respectively, compared to OpenMax.
Figure 13 demonstrates the distribution of features extracted by experiment BE3 using the model of this paper. According to the intra-class distance visualization results and the statistical metrics observed in
Figure 14 and
Table 12, SMCPL-ECA-DPC has the lowest mean value (14.01), which is 0.98, 1.89, 0.76, 2.56, and 1.74 lower than that of SMCPL, CPL, ANEDL, CNN, and OpenMax, respectively, which indicates that the present model is better than other models for the aggregation of intra-class distances.
Figure 15 represents the normalized confusion matrix of SMCPL-ECA-DPC.
Anomaly analysis: The reason for the low diagnostic performance of all methods in the BE2, BE5, and BE6 experimental results is that the distributions of ORF(0) and CF(1) in the XJTU-SY dataset are extremely similar in the feature space, which would be difficult to differentiate if both of them were not set up as known classes to be trained to increase the inter-class distance. If any one of the two classes is an unknown class, then the original part of the data distribution belonging to the unknown class during testing will be distributed in the same space with the distribution of the other class so that it cannot be separated and identified. The experiment where both are trained as known classes is BE3, analyzed as above. In experiment BE4, both ORF(0) and CF(1) are used as unknown classes, and the recognition performance of all models is very good precisely because the spatial distributions of these two classes are similar, which are very different from those of IORF(2), and thus the recognition rate of unknown classes reaches 100%.
5.3. PU Experimental Results
Comparison tests are conducted according to the OSR experiment serial numbers in
Table 6, and the results of the evaluation metrics on the Paderborn dataset are obtained as shown in
Table 13, where the classification performance of SMCPL-ECA-DPC is higher than that of other models in all cases, which once again verifies its strong diagnostic capability for OSR on the real bearing dataset PU, which is a much larger dataset with a much higher noise level.
Figure 16 shows the full closed-set fault diagnosis effect of SMCPL-ECA-DPC on this dataset, with an accuracy of 99.33% on the test set. Taking CE2 (unknown class as IR (1)) as an example, the NA, NF1, and J metrics computed by the proposed framework in this paper are higher than those of other models.
Figure 17 demonstrates the feature distribution of experiment CE2 extracted using the model of this paper. According to the intra-class distance visualization results and statistical metrics observed in
Figure 18 and
Table 14, SMCPL-ECA-DPC has the lowest mean value (14.78), which is 0.365, 1.035, 0.13, 1.385, and 0.955 lower than that of SMCPL, CPL, ANEDL, CNN, and OpenMax, respectively, which once again verifies that the present model is more effective for intra-class distance approximation.
Figure 19 represents the normalized confusion matrix of SMCPL-ECA-DPC.
Overall, according to the analysis of the experimental results of the three rolling bearing datasets, the framework based on SMCPL-ECA-DPC proposed in this paper can effectively improve the separation of known and unknown classes in the field of rolling bearings, and the diagnostic performance of the unknown classes is better than that of the comparison method, which provides support for the research of OSR.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}