
ATDMNet: Multi-Head Agent Attention and Top-k Dynamic Mask for Camouflaged Object Detection



Abstract
1. Introduction
2. Related Work
2.1. Camouflaged Object Detection
2.2. Transformers in Computer Vision
3. Proposed ATDMNet
3.1. Overall Architecture
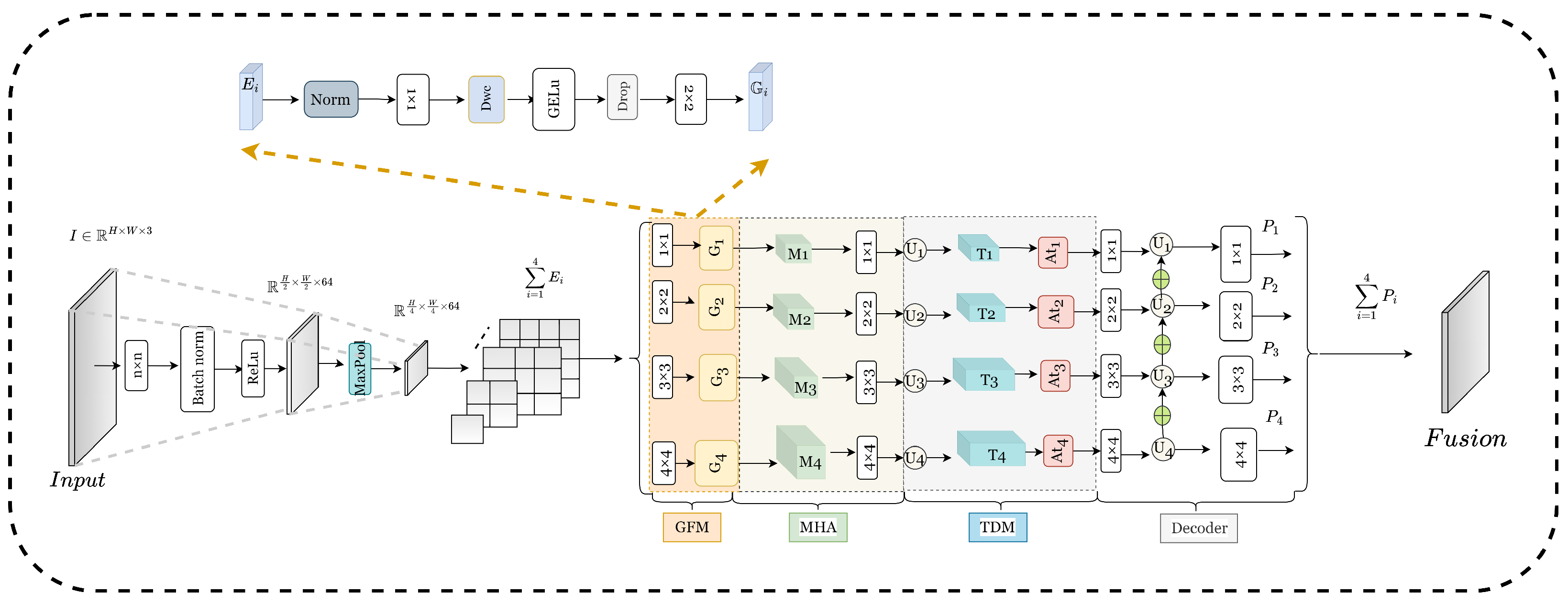
3.2. Agent Top-k Dynamic Mask (ATDM)
3.2.1. Multi-Head Agent (MHA)
3.2.2. Top-k Dynamic Mask (TDM)
3.3. Loss Function
4. Experimental Results
4.1. Experiment Setup
4.2. Qualitative Evaluation
Visualization Predictions
4.3. Quantitative Evaluation
4.3.1. Comparison with Existing COD Methods
4.3.2. Computational Efficiency Analysis
4.4. Ablative Studies
4.4.1. Validation of Module Combination
4.4.2. Feature Visualization
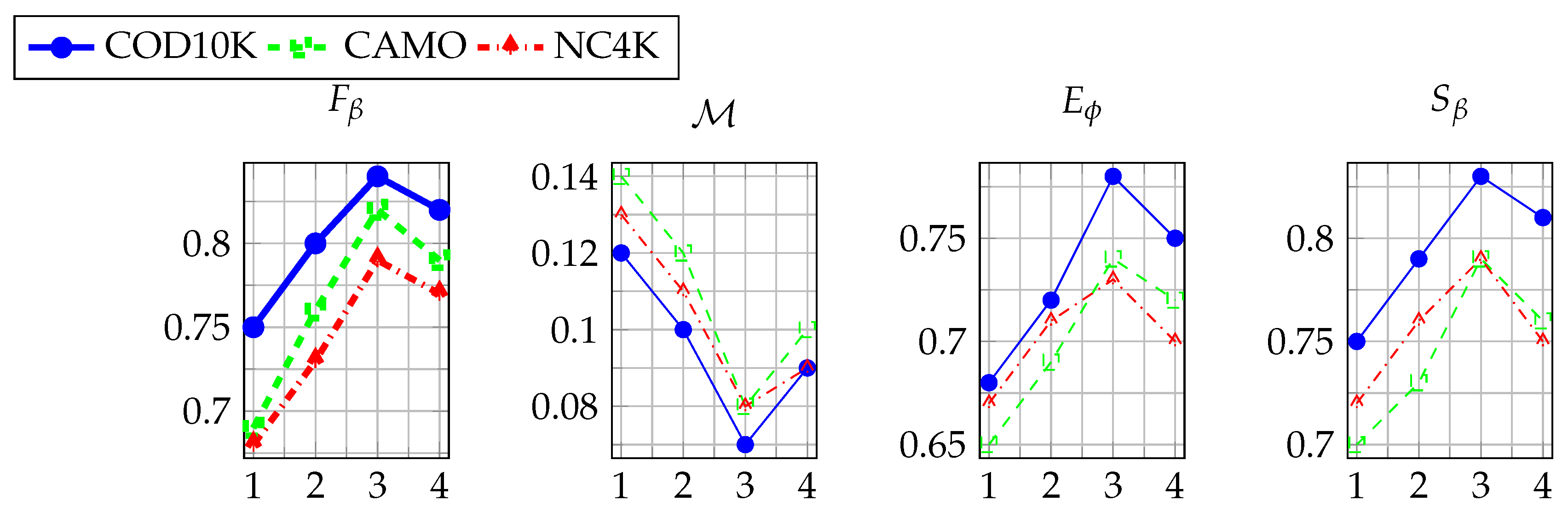
4.4.3. Balance Analysis of the Number of MHA Agent Nodes
4.4.4. Adaptability Analysis of TDM Top-k Ratio
4.4.5. Optimization Analysis of Dynamic Mask Level
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Liu, S.J.; Sun, Y.J.; Ji, G.P.; Wu, Y.F.; Zhou, T. Camouflaged object detection via context-aware cross-level fusion. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6981–6993. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Chen, C.; Xiang, T.Z. Boundary-guided camouflaged object detection. arXiv 2022, arXiv:2207.00794. [Google Scholar]
- Lyu, Y.; Zhang, H.; Li, Y.; Liu, H.; Yang, Y.; Yuan, D. UEDG:Uncertainty-Edge Dual Guided Camouflage Object Detection. IEEE Trans. Multimed. 2024, 26, 4050–4060. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, X.; Wang, F.; Sun, J.; Sun, F. Efficient Camouflaged Object Detection Network Based on Global Localization Perception and Local Guidance Refinement. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5452–5465. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N.; Fan, D.P. Simultaneously localize, segment and rank the camouflaged objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11591–11601. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2777–2787. [Google Scholar]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Hall, J.R.; Cuthill, I.C.; Baddeley, R.; Shohet, A.J.; Scott-Samuel, N.E. Camouflage, detection and identification of moving targets. Proc. R. Soc. B Biol. Sci. 2013, 280, 20130064. [Google Scholar] [CrossRef]
- Li, P.; Yan, X.; Zhu, H.; Wei, M.; Zhang, X.P.; Qin, J. Findnet: Can you find me? boundary-and-texture enhancement network for camouflaged object detection. IEEE Trans. Image Process. 2022, 31, 6396–6411. [Google Scholar] [CrossRef]
- Zhong, Y.; Li, B.; Tang, L.; Kuang, S.; Wu, S.; Ding, S. Detecting camouflaged object in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4504–4513. [Google Scholar]
- Sun, Y.; Xu, C.; Yang, J.; Xuan, H.; Luo, L. Frequency-spatial entanglement learning for camouflaged object detection. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; Springer: Berlin, Germany, 2025; pp. 343–360. [Google Scholar]
- Cong, R.; Sun, M.; Zhang, S.; Zhou, X.; Zhang, W.; Zhao, Y. Frequency perception network for camouflaged object detection. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1179–1189. [Google Scholar]
- Zhang, S.; Kong, D.; Xing, Y.; Lu, Y.; Ran, L.; Liang, G.; Wang, H.; Zhang, Y. Frequency-Guided Spatial Adaptation for Camouflaged Object Detection. arXiv 2024, arXiv:2409.12421. [Google Scholar] [CrossRef]
- Zhao, X.; Pang, Y.; Ji, W.; Sheng, B.; Zuo, J.; Zhang, L.; Lu, H. Spider: A Unified Framework for Context-dependent Concept Segmentation. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Wang, H.; Wu, Z.; Liu, Z.; Cai, H.; Zhu, L.; Gan, C.; Han, S. Hat: Hardware-aware transformers for efficient natural language processing. arXiv 2020, arXiv:2005.14187. [Google Scholar]
- Yao, S.; Sun, H.; Xiang, T.Z.; Wang, X.; Cao, X. Hierarchical graph interaction transformer with dynamic token clustering for camouflaged object detection. IEEE Trans. Image Process. 2024, 33, 5936–5948. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Dai, H.; Xiang, T.Z.; Wang, S.; Chen, H.X.; Qin, J.; Xiong, H. Feature shrinkage pyramid for camouflaged object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5557–5566. [Google Scholar]
- Yin, B.; Zhang, X.; Fan, D.P.; Jiao, S.; Cheng, M.M.; Van Gool, L.; Hou, Q. Camoformer: Masked separable attention for camouflaged object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10362–10374. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-guided transformer reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4146–4155. [Google Scholar]
- Dickson, M.C.; Bosman, A.S.; Malan, K.M. Hybridised loss functions for improved neural network generalisation. In Proceedings of the Pan-African Artificial Intelligence and Smart Systems Conference, Windhoek, Namibia, 6–8 September 2021; Springer: Berlin, Germany, 2021; pp. 169–181. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Bi, H.; Zhang, C.; Wang, K.; Tong, J.; Zheng, F. Rethinking camouflaged object detection: Models and datasets. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 5708–5724. [Google Scholar] [CrossRef]
- Chen, Y.; Zhuang, Z.; Chen, C. Object Detection Method Based on PVTv2. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 26–28 May 2023; pp. 730–734. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Koonce, B.; Koonce, B. ResNet 50. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Springer: Berlin, Germany, 2021; pp. 63–72. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Zhou, X.; Wu, Z.; Cong, R. Decoupling and Integration Network for Camouflaged Object Detection. IEEE Trans. Multimed. 2024, 26, 7114–7129. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Ma, Z.; Li, T.; Li, X.; Ma, J. RUPT-FL: Robust Two-layered Privacy-preserving Federated Learning Framework with Unlinkability for IoV. IEEE Trans. Veh. Technol. 2024, 74, 5528–5541. [Google Scholar] [CrossRef]
- Xing, H.; Gao, S.; Wang, Y.; Wei, X.; Tang, H.; Zhang, W. Go Closer to See Better: Camouflaged Object Detection via Object Area Amplification and Figure-Ground Conversion. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5444–5457. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Xiang, T.Z.; Zhang, L.; Lu, H. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2160–2170. [Google Scholar]
- Zhu, H.; Li, P.; Xie, H.; Yan, X.; Liang, D.; Chen, D.; Wei, M.; Qin, J. I can find you! boundary-guided separated attention network for camouflaged object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 3608–3616. [Google Scholar]
- Jia, Q.; Yao, S.; Liu, Y.; Fan, X.; Liu, R.; Luo, Z. Segment, magnify and reiterate: Detecting camouflaged objects the hard way. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4713–4722. [Google Scholar]
- He, C.; Li, K.; Zhang, Y.; Tang, L.; Zhang, Y.; Guo, Z.; Li, X. Camouflaged Object Detection With Feature Decomposition and Edge Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 22046–22055. [Google Scholar]
- He, C.; Li, K.; Zhang, Y.; Zhang, Y.; Guo, Z.; Li, X.; Danelljan, M.; Yu, F. Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects. arXiv 2024, arXiv:2308.03166. [Google Scholar]
- Song, Y.; Li, X.; Qi, L. Camouflaged Object Detection with Feature Grafting and Distractor Aware. arXiv 2023, arXiv:2307.03943. [Google Scholar]
- Cong, R.; Sun, M.; Zhang, S.; Zhou, X.; Zhang, W.; Zhao, Y. Frequency Perception Network for Camouflaged Object Detection. arXiv 2024, arXiv:2308.08924. [Google Scholar]
- Huang, Z.; Dai, H.; Xiang, T.Z.; Wang, S.; Chen, H.X.; Qin, J.; Xiong, H. Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers. arXiv 2023, arXiv:2303.14816. [Google Scholar]
- Luo, Z.; Liu, N.; Zhao, W.; Yang, X.; Zhang, D.; Fan, D.P.; Khan, F.; Han, J. VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17169–17180. [Google Scholar]
- Wang, L.; Yang, J.; Zhang, Y.; Wang, F.; Zheng, F. Depth-Aware Concealed Crop Detection in Dense Agricultural Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 17201–17211. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Backbone | CAMO (250) | COD10K (2026) | NC4K (4121) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50-based Methods | |||||||||||||||||
| BGNet [3] | 22IJCAI | ResNet | 0.812 | 0.749 | 0.073 | 0.789 | 0.870 | 0.831 | 0.722 | 0.033 | 0.753 | 0.901 | 0.851 | 0.788 | 0.044 | 0.820 | 0.907 |
| BSANet [36] | 22AAAI | ResNet | 0.794 | 0.717 | 0.079 | 0.763 | 0.851 | 0.818 | 0.699 | 0.034 | 0.738 | 0.891 | 0.842 | 0.771 | 0.048 | 0.808 | 0.897 |
| SegMaR [37] | 22CVPR | ResNet | 0.816 | 0.753 | 0.071 | 0.795 | 0.874 | 0.833 | 0.724 | 0.034 | 0.757 | 0.899 | 0.841 | 0.781 | 0.046 | 0.821 | 0.896 |
| ZoomNet [35] | 22CVPR | ResNet | 0.820 | 0.752 | 0.066 | 0.793 | 0.877 | 0.838 | 0.729 | 0.029 | 0.766 | 0.888 | 0.853 | 0.784 | 0.043 | 0.818 | 0.896 |
| C2FNetV2 [2] | 22TCSVT | ResNet | 0.799 | 0.730 | 0.077 | 0.770 | 0.859 | 0.811 | 0.691 | 0.036 | 0.725 | 0.887 | 0.840 | 0.770 | 0.048 | 0.802 | 0.896 |
| FEDER [38] | 23CVPR | ResNet | 0.802 | 0.738 | 0.071 | 0.781 | 0.867 | 0.822 | 0.716 | 0.032 | 0.751 | 0.900 | 0.847 | 0.789 | 0.044 | 0.824 | 0.907 |
| ICEG [39] | 24ICLR | ResNet | 0.810 | 0.727 | 0.068 | 0.789 | 0.879 | 0.826 | 0.698 | 0.030 | 0.747 | 0.906 | 0.849 | 0.760 | 0.044 | 0.814 | 0.908 |
| CamoFormer [19] | 24ICLR | ResNet | 0.817 | 0.752 | 0.067 | 0.792 | 0.866 | 0.838 | 0.723 | 0.029 | 0.753 | 0.906 | 0.849 | 0.760 | 0.044 | 0.814 | 0.908 |
| ATDM-R50 | Ours | ResNet | 0.815 | 0.754 | 0.068 | 0.797 | 0.885 | 0.835 | 0.742 | 0.029 | 0.773 | 0.910 | 0.854 | 0.800 | 0.041 | 0.832 | 0.915 |
| Res2Net50-based Methods | |||||||||||||||||
| FDNet [40] | 22CVPR | Res2Net | 0.838 | 0.774 | 0.063 | 0.806 | 0.897 | 0.834 | 0.727 | 0.030 | 0.753 | 0.921 | 0.828 | 0.748 | 0.052 | 0.780 | 0.894 |
| SINetV2 [1] | 22TPAMI | Res2Net | 0.820 | 0.743 | 0.071 | 0.782 | 0.882 | 0.815 | 0.680 | 0.037 | 0.718 | 0.887 | 0.847 | 0.770 | 0.048 | 0.805 | 0.903 |
| DINet [32] | 24TMM | Res2Net | 0.821 | 0.748 | 0.068 | 0.790 | 0.873 | 0.832 | 0.724 | 0.031 | 0.761 | 0.903 | 0.856 | 0.790 | 0.043 | 0.825 | 0.909 |
| FCOCM [33] | 24TCSVT | Res2Net | 0.836 | 0.781 | 0.063 | 0.815 | 0.893 | 0.837 | 0.726 | 0.030 | 0.755 | 0.903 | 0.860 | 0.799 | 0.041 | 0.827 | 0.913 |
| ATDM-R2N | Ours | Res2Net | 0.840 | 0.787 | 0.063 | 0.820 | 0.899 | 0.845 | 0.743 | 0.028 | 0.775 | 0.912 | 0.861 | 0.806 | 0.042 | 0.835 | 0.915 |
| Transformer-based Methods | |||||||||||||||||
| FPNet [41] | 23ACMMM | PVT | 0.851 | 0.802 | 0.056 | 0.836 | 0.905 | 0.850 | 0.755 | 0.028 | 0.782 | 0.912 | - | - | - | - | - |
| FSPNet [42] | 23CVPR | VIT | 0.856 | 0.799 | 0.050 | 0.830 | 0.899 | 0.851 | 0.735 | 0.026 | 0.769 | 0.895 | 0.879 | 0.816 | 0.035 | 0.843 | 0.915 |
| SARNet [34] | 23TCSVT | PVT | 0.868 | 0.828 | 0.047 | 0.850 | 0.927 | 0.864 | 0.777 | 0.024 | 0.800 | 0.931 | 0.886 | 0.842 | 0.032 | 0.863 | 0.937 |
| UEDG [4] | 23TMM | PVT | 0.863 | 0.817 | 0.048 | 0.840 | 0.922 | 0.858 | 0.766 | 0.025 | 0.791 | 0.924 | 0.879 | 0.830 | 0.035 | 0.851 | 0.929 |
| VSCode [43] | 24CVPR | Swin | 0.873 | 0.820 | 0.046 | 0.844 | 0.925 | 0.869 | 0.780 | 0.023 | 0.806 | 0.931 | 0.891 | 0.841 | 0.032 | 0.863 | 0.935 |
| RISNet [44] | 24CVPR | PVT | 0.870 | 0.827 | 0.050 | 0.844 | 0.922 | 0.873 | 0.799 | 0.025 | 0.817 | 0.931 | 0.882 | 0.834 | 0.037 | 0.854 | 0.926 |
| PRNet [5] | 24TCSVT | SMT | 0.872 | 0.831 | 0.050 | 0.855 | 0.922 | 0.874 | 0.799 | 0.023 | 0.822 | 0.937 | 0.891 | 0.848 | 0.031 | 0.869 | 0.935 |
| ATDM-PVT | Ours | PVT | 0.882 | 0.846 | 0.044 | 0.867 | 0.933 | 0.879 | 0.804 | 0.021 | 0.823 | 0.940 | 0.895 | 0.852 | 0.030 | 0.872 | 0.940 |
| ATDM-Swin | Ours | Swin | 0.879 | 0.836 | 0.041 | 0.858 | 0.932 | 0.868 | 0.781 | 0.023 | 0.803 | 0.934 | 0.891 | 0.845 | 0.031 | 0.864 | 0.940 |
| Method | Backbone | Params (M) | MACs (G) | Speed (FPS) |
|---|---|---|---|---|
| BGNet [3] | ResNet50 | 26.5 | 45.2 | 62.1 ± 1.2 |
| ZoomNet [35] | ResNet50 | 45.7 | 68.7 | 58.3 ± 1.5 |
| CamoFormer [19] | ResNet50 | 38.2 | 53.9 | 74.5 ± 1.1 |
| ATDM-RN (Ours) | ResNet50 | 28.3 | 47.8 | 68.2 ± 1.2 |
| FDNet [40] | Res2Net50 | 28.7 | 45.6 | 85.6 ± 2.1 |
| DINet [40] | Res2Net50 | 45.2 | 62.5 | 72.5± 1.6 |
| SINetV2 [40] | Res2Net50 | 51.1 | 68.5 | 65.3 ± 2.6 |
| ATDM-R2N (Ours) | Res2Net50 | 29.5 | 43.2 | 88.4 ± 1.3 |
| FPNet [41] | PVT | 68.4 | 89.2 | 45.3 ± 3.4 |
| SARNet [34] | PVT | 52.1 | 89.4 | 38.2 ± 3.4 |
| ATDM-PVT (Ours) | PVT | 36.8 | 62.1 | 89.5 ± 1.8 |
| PRNet [5] | SMT | 34.6 | 76.8 | 45.1 ± 1.7 |
| ATDM-Swin (Ours) | Swin-T | 27.2 | 58.6 | 92.5 ± 2.3 |
| Model Configuration | CAMO | COD10K | NC4K | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Baseline (Res2Net) | 0.721 | 0.862 | 0.075 | 0.742 | 0.887 | 0.032 | 0.738 | 0.890 | 0.045 |
| Baseline + MHA | 0.748 | 0.880 | 0.068 | 0.769 | 0.903 | 0.029 | 0.761 | 0.902 | 0.041 |
| Baseline + TDM | 0.743 | 0.875 | 0.070 | 0.763 | 0.896 | 0.030 | 0.756 | 0.899 | 0.042 |
| ATDMNet | 0.765 | 0.895 | 0.063 | 0.785 | 0.915 | 0.025 | 0.778 | 0.778 | 0.038 |
| Agent Nodes | COD10K | CAMO | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 0.72 | 0.12 | 0.68 | 0.75 | 0.69 | 0.14 | 0.65 | 0.70 | 0.68 | 0.13 | 0.67 | 0.72 |
| 8 | 0.78 | 0.10 | 0.72 | 0.78 | 0.75 | 0.12 | 0.69 | 0.73 | 0.73 | 0.11 | 0.71 | 0.76 |
| 16 | 0.83 | 0.08 | 0.76 | 0.82 | 0.81 | 0.09 | 0.74 | 0.78 | 0.79 | 0.09 | 0.69 | 0.79 |
| 32 | 0.81 | 0.09 | 0.74 | 0.80 | 0.79 | 0.10 | 0.72 | 0.76 | 0.77 | 0.10 | 0.70 | 0.75 |
| 64 | 0.79 | 0.11 | 0.71 | 0.79 | 0.77 | 0.11 | 0.70 | 0.75 | 0.75 | 0.12 | 0.68 | 0.73 |
| Top-k Ratios | COD10K | CAMO | NC4K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50% | 0.78 | 0.10 | 0.72 | 0.78 | 0.73 | 0.11 | 0.68 | 0.74 | 0.71 | 0.12 | 0.66 | 0.70 |
| 60% | 0.81 | 0.09 | 0.75 | 0.80 | 0.78 | 0.10 | 0.71 | 0.76 | 0.75 | 0.10 | 0.69 | 0.73 |
| 70% | 0.84 | 0.07 | 0.78 | 0.83 | 0.80 | 0.08 | 0.74 | 0.79 | 0.79 | 0.08 | 0.72 | 0.77 |
| 80% | 0.81 | 0.08 | 0.76 | 0.81 | 0.81 | 0.09 | 0.73 | 0.77 | 0.77 | 0.09 | 0.70 | 0.75 |
| 90% | 0.80 | 0.09 | 0.74 | 0.80 | 0.79 | 0.10 | 0.71 | 0.76 | 0.76 | 0.10 | 0.69 | 0.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, R.; Li, Y.; Chen, C.-C.; Duan, Y.; Yao, P.; Zhou, K. ATDMNet: Multi-Head Agent Attention and Top-k Dynamic Mask for Camouflaged Object Detection. Sensors 2025, 25, 3001. https://doi.org/10.3390/s25103001
Fu R, Li Y, Chen C-C, Duan Y, Yao P, Zhou K. ATDMNet: Multi-Head Agent Attention and Top-k Dynamic Mask for Camouflaged Object Detection. Sensors. 2025; 25(10):3001. https://doi.org/10.3390/s25103001
Chicago/Turabian StyleFu, Rui, Yuehui Li, Chih-Cheng Chen, Yile Duan, Pengjian Yao, and Kaixin Zhou. 2025. "ATDMNet: Multi-Head Agent Attention and Top-k Dynamic Mask for Camouflaged Object Detection" Sensors 25, no. 10: 3001. https://doi.org/10.3390/s25103001
APA StyleFu, R., Li, Y., Chen, C.-C., Duan, Y., Yao, P., & Zhou, K. (2025). ATDMNet: Multi-Head Agent Attention and Top-k Dynamic Mask for Camouflaged Object Detection. Sensors, 25(10), 3001. https://doi.org/10.3390/s25103001