
Forest Fire Detection Algorithm Based on Improved YOLOv11n


Abstract
1. Introduction
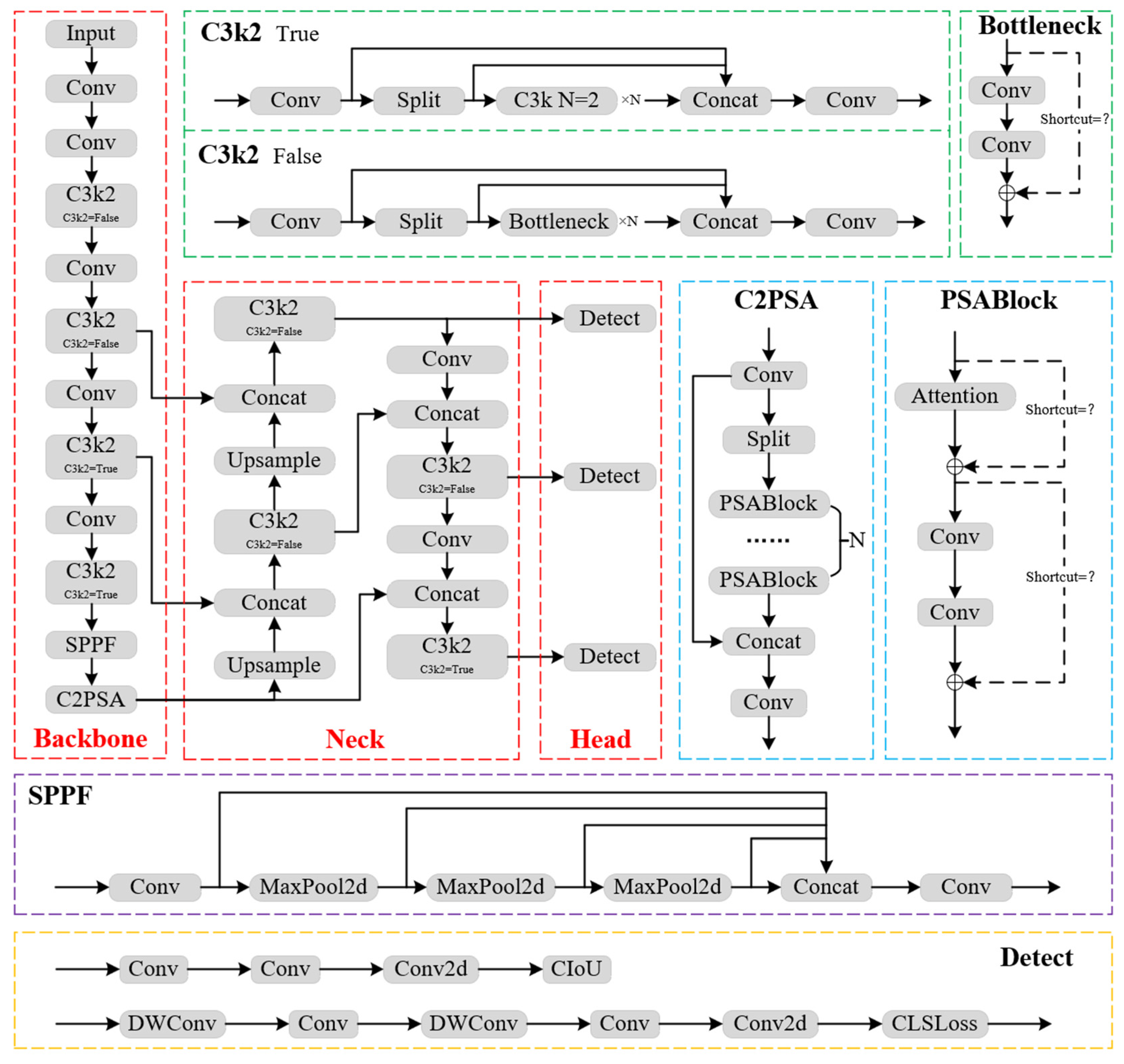
2. YOLOv11 Algorithm
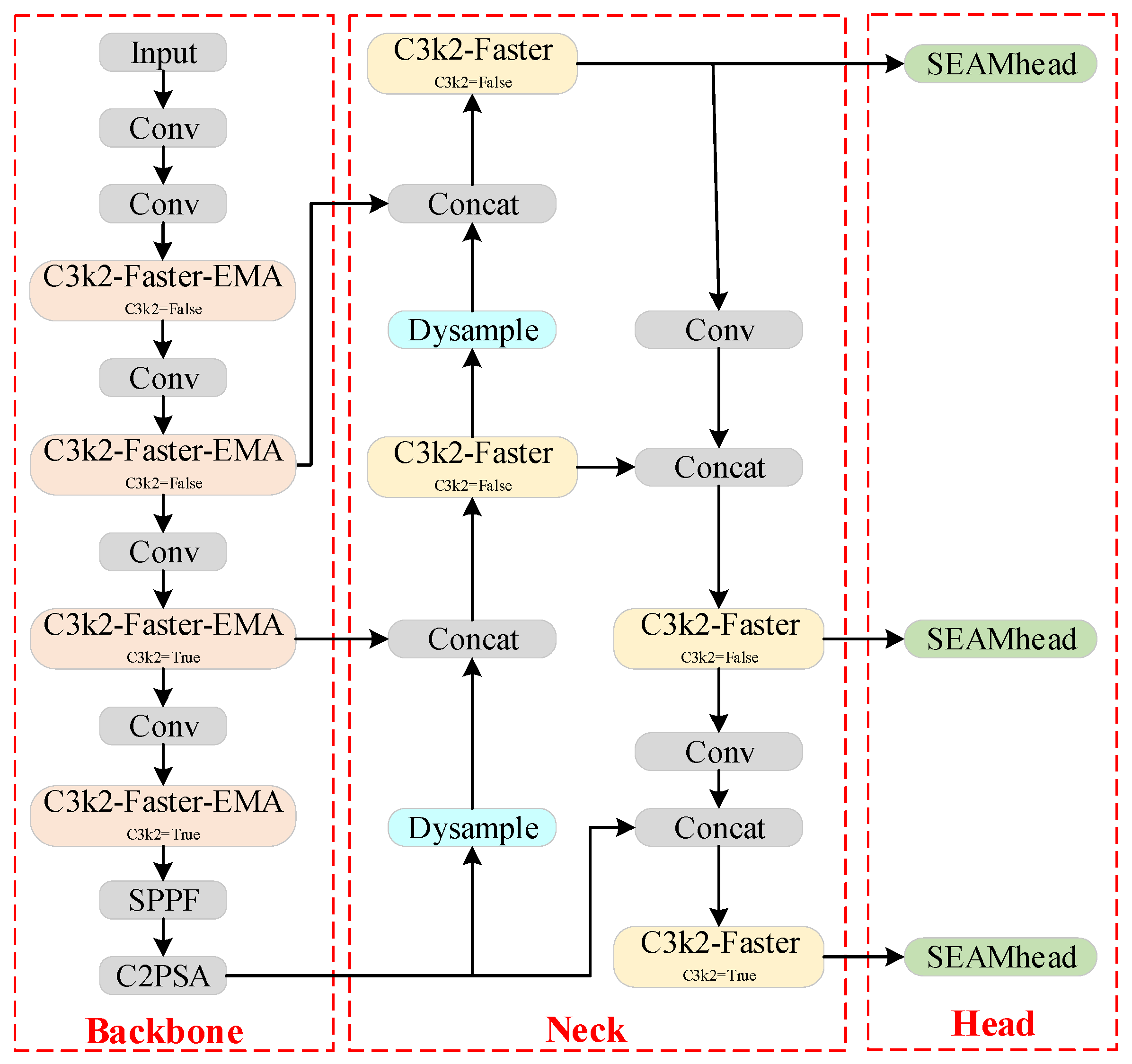
3. Materials and Methods
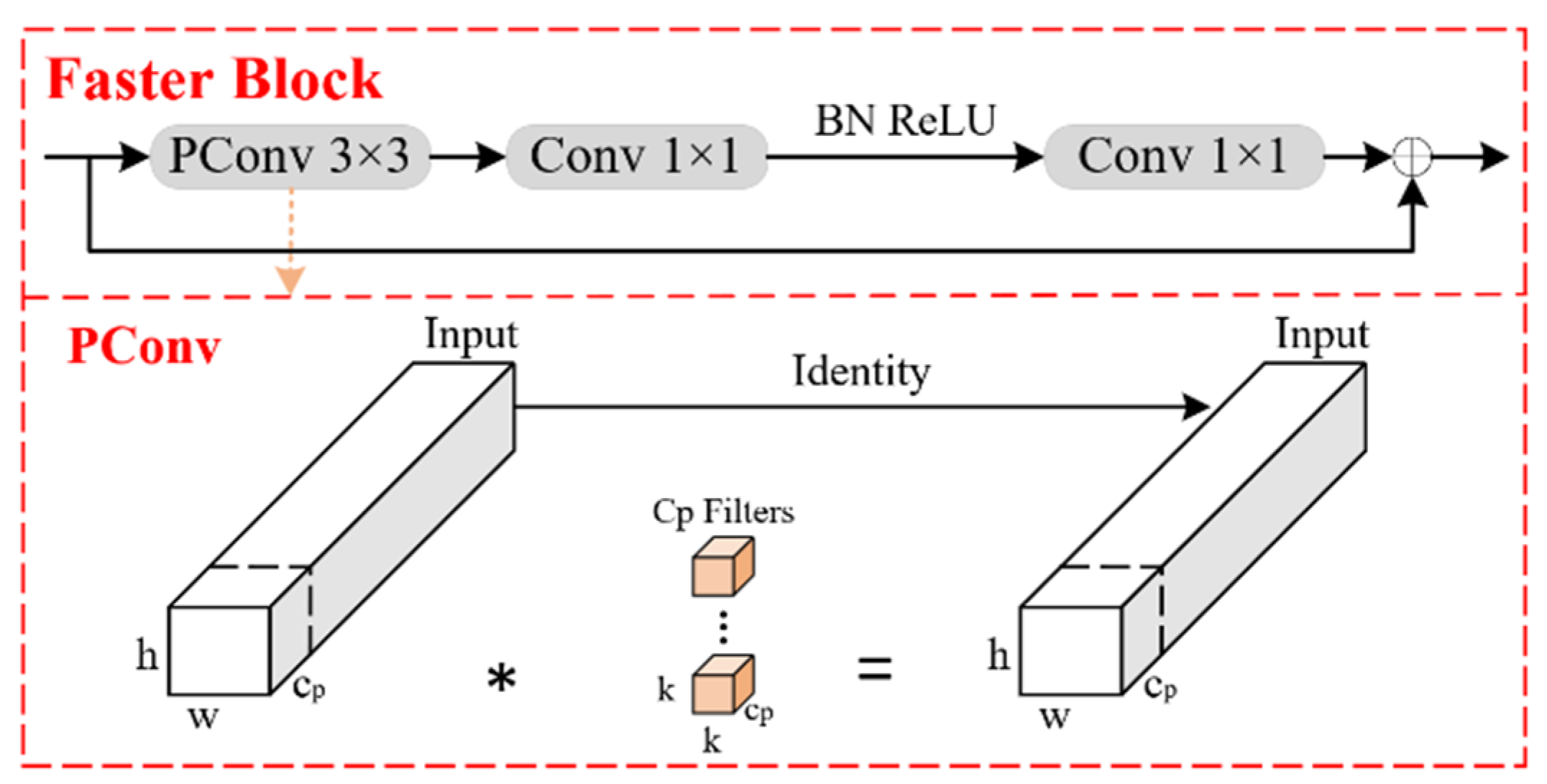
3.1. FasterBlock
3.2. Attention Mechanism: EMA
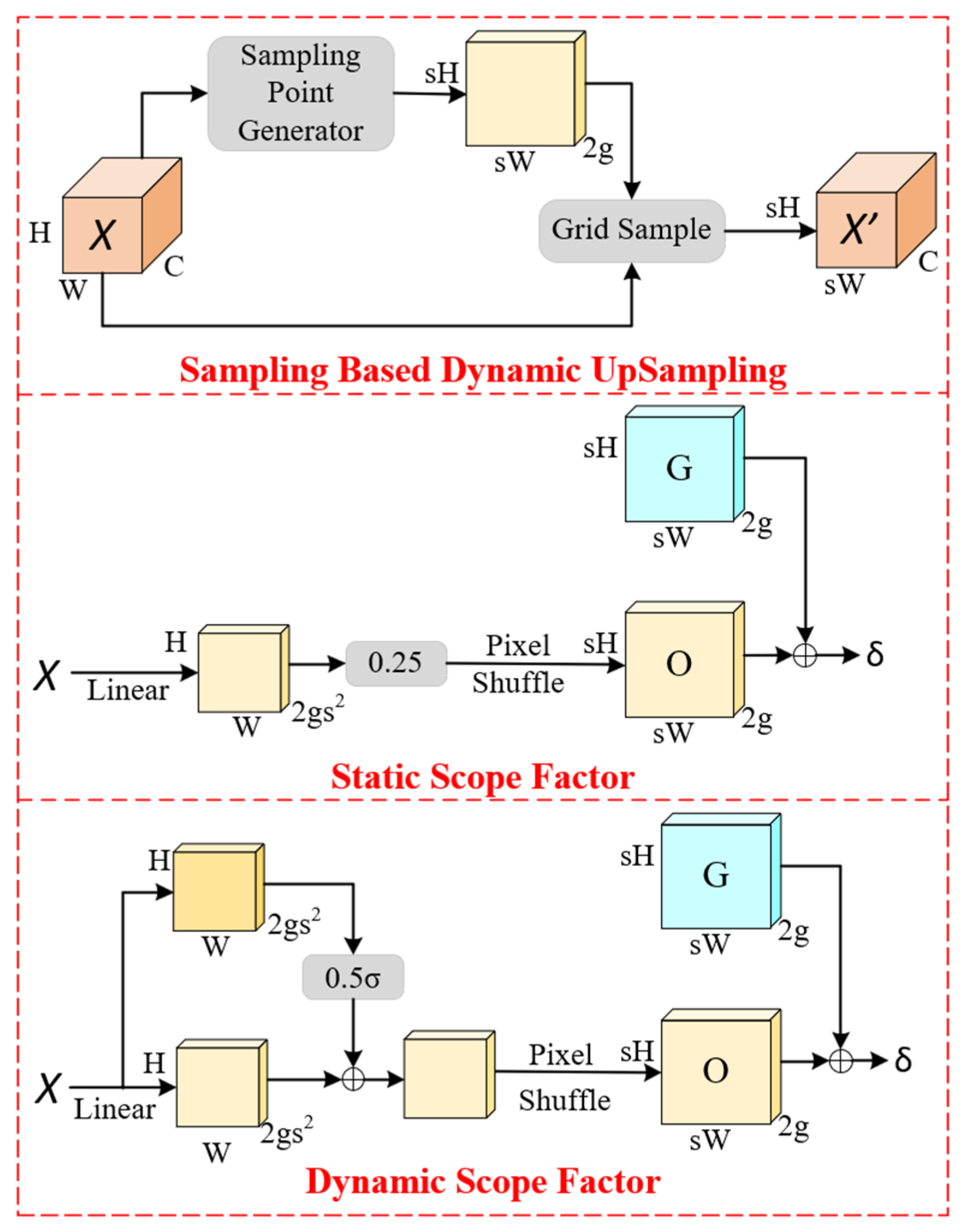
3.3. DySample
3.4. SEAMhead
4. Results
4.1. Dataset
4.2. Model Operating Environment and Parameter Settings
4.3. Evaluation Metrics
4.4. Experimental Results and Analysis
4.4.1. Ablation Experiment
4.4.2. Comparison with Common YOLO Models
4.4.3. Comparison with Other Mainstream Object Detection Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fujii, H.; Sato, M.; Managi, S. Decomposition analysis of forest ecosystem services value. Sustainability 2017, 9, 687. [Google Scholar] [CrossRef]
- Bonan, G.B. Forests and climate change: Forcings, feedbacks, and the climate benefits of forests. Science 2008, 320, 1444–1449. [Google Scholar] [CrossRef] [PubMed]
- Tedim, F.; Leone, V.; Amraoui, M.; Bouillon, C.; Coughlan, M.R.; Delogu, G.M.; Fernandes, P.M.; Ferreira, C.; McCaffrey, S.; McGee, T.K.; et al. Defining extreme wildfire events: Difficulties, challenges, and impacts. Fire 2018, 1, 9. [Google Scholar] [CrossRef]
- Canning, J.R.; Edwards, D.B.; Anderson, M.J. Development of a fuzzy logic controller for autonomous forest path navigation. Trans. ASAE 2004, 47, 301–310. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018. [Google Scholar]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Li, J.; Tang, H.; Li, X.; Dou, H.; Li, R. LEF-YOLO: A lightweight method for intelligent detection of four extreme wildfires based on the YOLO framework. Int. J. Wildland Fire 2023, 33, WF23044. [Google Scholar] [CrossRef]
- Wang, Y.; Hua, C.; Ding, W.; Wu, R. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Process. 2022, 16, 1109–1116. [Google Scholar] [CrossRef]
- Bahhar, C.; Ksibi, A.; Ayadi, M.; Jamjoom, M.M.; Ullah, Z.; Soufiene, B.O.; Sakli, H. Wildfire and smoke detection using staged YOLO model and ensemble CNN. Electronics 2023, 12, 228. [Google Scholar] [CrossRef]
- Yin, D.; Cheng, P.; Huang, Y. YOLO-EPF: Multi-scale smoke detection with enhanced pool former and multiple receptive fields. Digit. Signal Process. 2024, 149, 104511. [Google Scholar] [CrossRef]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; Halin, A.A. Fire-Net: A deep learning framework for active forest fire detection. J. Sens. 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A novel lightweight CNN model for real-time video fire–smoke detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Almeida, J.S.; Jagatheesaperumal, S.K.; Nogueira, F.G.; de Albuquerque, V.H.C. EdgeFireSmoke++: A novel lightweight algorithm for real-time forest fire detection and visualization using internet of things-human machine interface. Expert Syst. Appl. 2023, 221, 119747. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Wang, D.; Tan, J.; Wang, H.; Kong, L.; Zhang, C.; Pan, D.; Li, T.; Liu, J. SDS-YOLO: An improved vibratory position detection algorithm based on YOLOv11. Measurement 2025, 244, 116518. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Yang, W.; Qiu, X. A lightweight and efficient model for grape bunch detection and biophysical anomaly assessment in complex environments based on YOLOv8s. Front. Plant Sci. 2024, 15, 1395796. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-Facev2: A scale and occlusion aware face detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Fu, Z.; Ling, J.; Yuan, X.; Li, H.; Li, H.; Li, Y. YOLOv8n-FADS: A study for enhancing miners’ helmet detection accuracy in complex underground environments. Sensors 2024, 24, 3767. [Google Scholar] [CrossRef] [PubMed]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Poznanski, J.; Yu, L.; Rai, P.; Ferriday, R.; et al. ultralytics/yolov5: v3.0; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. YOLOv10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BackBone | Neck | P/% | R/% | mAP50 /% | mAP50-95 /% | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | C3k2 | C3k2 | 75.9 | 71.9 | 77.1 | 43.0 | 25.8 | 6.3 | 48.2 |
| 2 | C3k2-Faster | C3k2-Faster | 73.9 | 70.7 | 76.2 | 40.7 | 22.9 | 5.8 | 42.9 |
| 3 | C3k2-Faster-EMA | C3k2-Faster | 75.2 | 72.2 | 77.5 | 43.2 | 22.9 | 5.8 | 30.6 |
| 4 | C3k2-Faster | C3k2-Faster-EMA | 74.6 | 69.1 | 75.4 | 40.2 | 22.9 | 5.8 | 31.6 |
| 5 | C3k2-Faster-EMA | C3k2-Faster-EMA | 76.3 | 71.1 | 77.4 | 42.7 | 29.3 | 5.9 | 23.5 |
| Model | P/% | R/% | mAP50/% | mAP50-95/% | GFLOPs | FPS | |
|---|---|---|---|---|---|---|---|
| YOLOv11n | 75.9 | 71.9 | 77.1 | 43.0 | 25.8 | 6.3 | 48.2 |
| YOLOv11n + DySample | 76.2 | 72.8 | 78.0 | 44.1 | 25.9 | 6.3 | 78.4 |
| YOLOv11n + SEAMHead | 76.0 | 71.2 | 76.8 | 42.3 | 24.9 | 5.8 | 70.6 |
| YOLOv11n + DySample + SEAMHead | 76.4 | 73.3 | 79.0 | 44.9 | 25.0 | 5.8 | 68.9 |
| Model 3 | 75.2 | 72.2 | 77.5 | 43.2 | 22.9 | 5.8 | 30.6 |
| Model 3 + DySample | 75.7 | 73.0 | 78.1 | 44.6 | 23.0 | 5.8 | 87.2 |
| Model 3 + SEAMHead | 75.4 | 70.8 | 76.7 | 41.8 | 22.0 | 5.3 | 81.3 |
| Model 3 + DySample + SEAMHead | 76.8 | 73.8 | 79.2 | 45.3 | 22.1 | 5.3 | 71.8 |
| Model | P/% | R/% | mAP50/% | mAP50-95/% | GFLOPs | FPS | |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 73.3 | 68.6 | 73.9 | 38.5 | 25.0 | 7.1 | 54.4 |
| YOLOv8n | 71.9 | 69.4 | 73.5 | 39.2 | 30.1 | 8.1 | 64.8 |
| YOLOv10n | 72.7 | 71.0 | 74.2 | 40.6 | 26.9 | 8.2 | 41.9 |
| YOLOv11n | 75.9 | 71.9 | 77.1 | 43.0 | 25.8 | 6.3 | 48.2 |
| FEDS-YOLOv11n | 76.8 | 73.8 | 79.2 | 45.3 | 22.1 | 5.3 | 71.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, K.; Jiang, S. Forest Fire Detection Algorithm Based on Improved YOLOv11n. Sensors 2025, 25, 2989. https://doi.org/10.3390/s25102989
Zhou K, Jiang S. Forest Fire Detection Algorithm Based on Improved YOLOv11n. Sensors. 2025; 25(10):2989. https://doi.org/10.3390/s25102989
Chicago/Turabian StyleZhou, Kangqian, and Shuihai Jiang. 2025. "Forest Fire Detection Algorithm Based on Improved YOLOv11n" Sensors 25, no. 10: 2989. https://doi.org/10.3390/s25102989
APA StyleZhou, K., & Jiang, S. (2025). Forest Fire Detection Algorithm Based on Improved YOLOv11n. Sensors, 25(10), 2989. https://doi.org/10.3390/s25102989